

知识工程及语义网技术 2020-03-12 (第二节)、RDF(S)、OWL
https://www.bilibili.com/video/BV1PE411j72x/?spm_id_from=333.788.recommend_more_video.2
https://www.bilibili.com/video/BV1PE411j7xq/?spm_id_from=333.788.recommend_more_video.4

rdf实际上是语义Web上的一个数据模型。只是定义了语法结构并没有说明真正的含义。
字面量指的是文本或者数字这些标量的值。





类成员的关系。比如说父类和子类的关系。
不能引用XML之外的事物,也就是说只能引用或者描述XML文档内的事物。
这就限制了XML在语义Web上的应用。与意外不知使用xml或者DTD Schema,它实际上是不够用的。
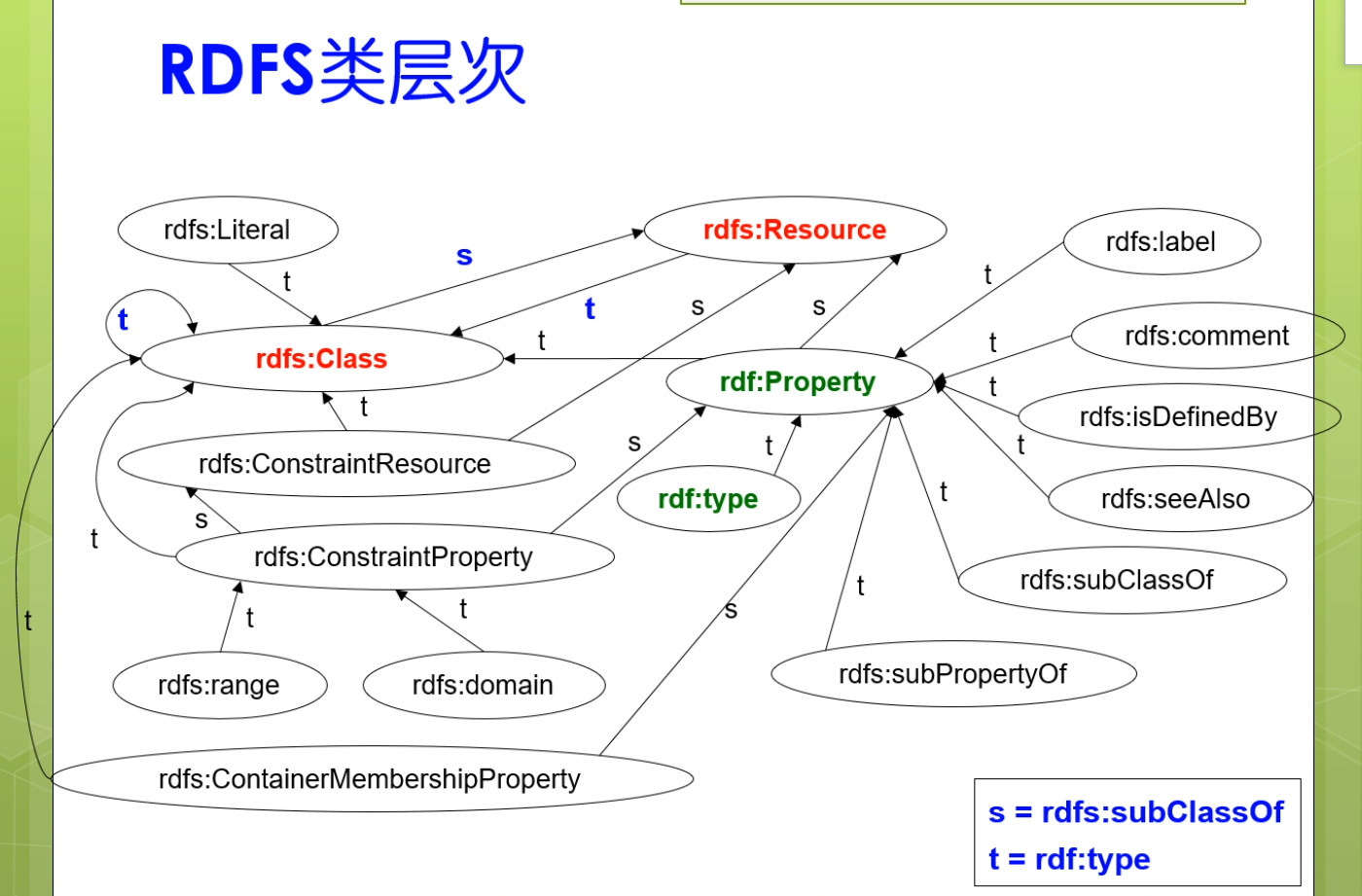
对于rdf属性来讲,它其实又有一些具体的属性。比如说label表示标签。
Comment表示注释。
Seealso是一个参见的关系。
subClassof 表示子类
subProperty of表示子属性。
它们都是RDF:property的一个实例。
另一方面,rdf的property。它其实是一种资源。所以呢property它又是资源的一个子类。
rdfs的resource。它的类型实际上是rdfs:Class。而rdfs的class他又是rdfs:resource的一个子类。它们两者的关系。形成了一个类似环状的结构。
这个就是我们之前所说的基本的rdf。rdfs允许我们在rdf的基础上进行扩展。比如说我们可以自己去定义什么是一个子类。比如什么是rdfs:class的一个子类。我们也可以定义一个具体的类。

我们把rdfs模式里面的一些基本类叫做核心类。其中第一个核心的就是rdfs的resource。

rdf实际上是一个命名空间。对property而言,它没有定义在rdfs:property之下。而是直接定义了定义在了rdf:property下。所以这是一个遗留问题,处理的有一点点不好。
虽然在二dfs里面定义了Property的语义。但是呢?他的命名空间还是和之前的一致。

rdfs除了有一些核心类,他还有一些核心属性。 
和rdfs:property类似。rdf:type的命名空间是在rds里面,而不是在二rdfs里面。



Is defined by也是一种参见。他的说明会更具体一点。他表示在另外一个地方,定义了这个事情。而不仅仅是普通的参见。




lang:language
支持多语言的文档模式。

下面是rdfs标记语言写的一个小的例子:
第一行是rdf的一个标签,相当于XML文档的根。
第二句第三句定义了rdf和rdfs的命名空间。
第四句定义了一个人类别。说明rdf Person的类型是一个rdf:class。rdf:id实际上它指的是一个rdf的一个type。
那么对于这个personal我们就可以有一些描述。
第五行添加了一个注释。the Class of people. 表示的是所有人的一个类。
第六行subclassof表示。人类Person是Animal的一个子类。
第九行定义了一个属性婚姻状况。ID面前少了一个rdf:。
第十行是说maritalstatus是一个类。
第11行是说定义域是Person.

社会安全号的定义域是一个person。人才有社会安全号。值域是integer。
年龄也是一个整数值。
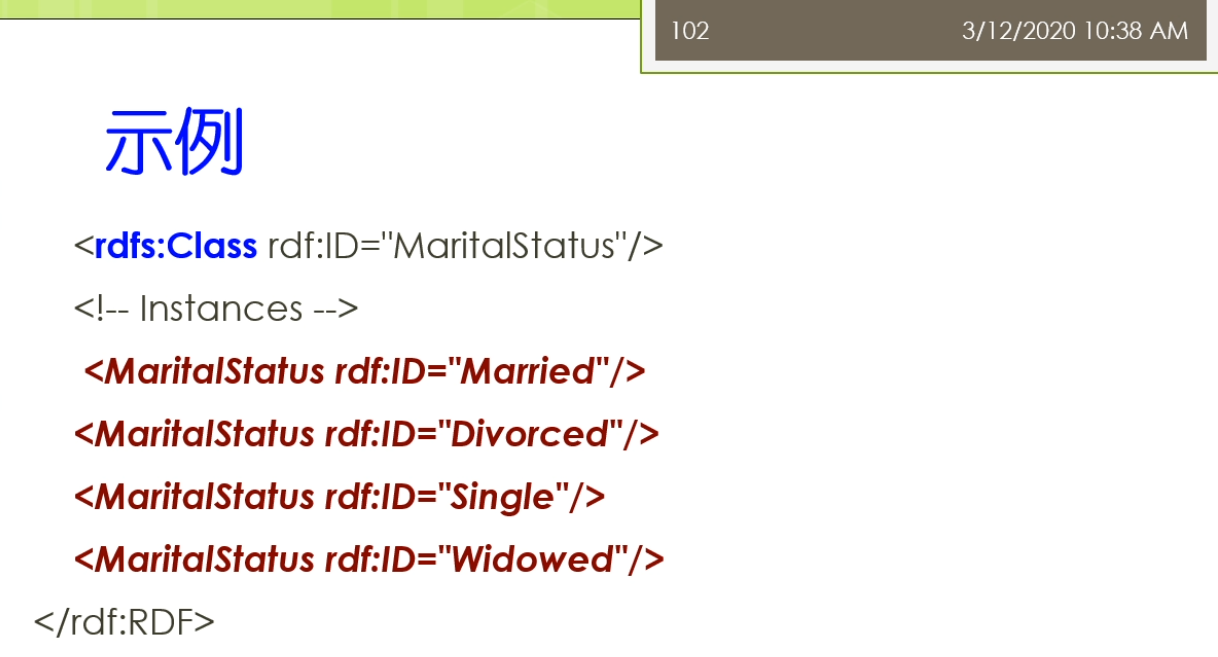
如果我要定义一个具体的人的时候,我就可以利用这个rdfs模式。比如我可以定义张三,他的年龄是20岁。定义李四,他的婚姻状况是未婚。




修改了DTD格式(文档模式)

A的外延都是B的外延的一个子集。

RDFS只能定义hasChild属性的值域是动物。再如定义它的值域是人的话。那么大象在使用hasChild的属性的时候。他的值域也会是人。
在存在/数量约束方面,在rdf的模式里面不能把这些东西进行精确的定义。
A是B的一部分B是C的一部分,那么A是C的一部分。这就是传递属性。rDFS不能传递属性。
rdfs不能定义相反的属性。
touch属性,你碰到我以后,我碰到你一下,这样的对称属性也不能被定义。

Web本体语言就是我们所说的owl。设计人员觉得应该具备以上特征。

Owl Fool他的想法或者说特点是让owl的语言可以使用RDF的形式去表达。任何一个RDF的东西,它可以写成owl full这种语言。
DL指的是description logic.描述逻辑是一阶逻辑的一个子集。这时候方便进行高效的推理。Owl Dl的表达能力大致相当于DAML加oil语言的表达能力。
Owl lite是owl dl的最容易实现的子集。Owl Lite比Owl dl还简单,但是描述能力来说的话,弱化了一点。
Ow语言有一个语义分层的东西,在rdf里面我们太强调分层。强调的是任何东西和任何东西之间都可以联系。任何的东西他们之间都可以形成任何的关系。但是在Owl. 语言里面我们比较强调它的语义网络分层,那也是我们后面进行推理的一个基础。

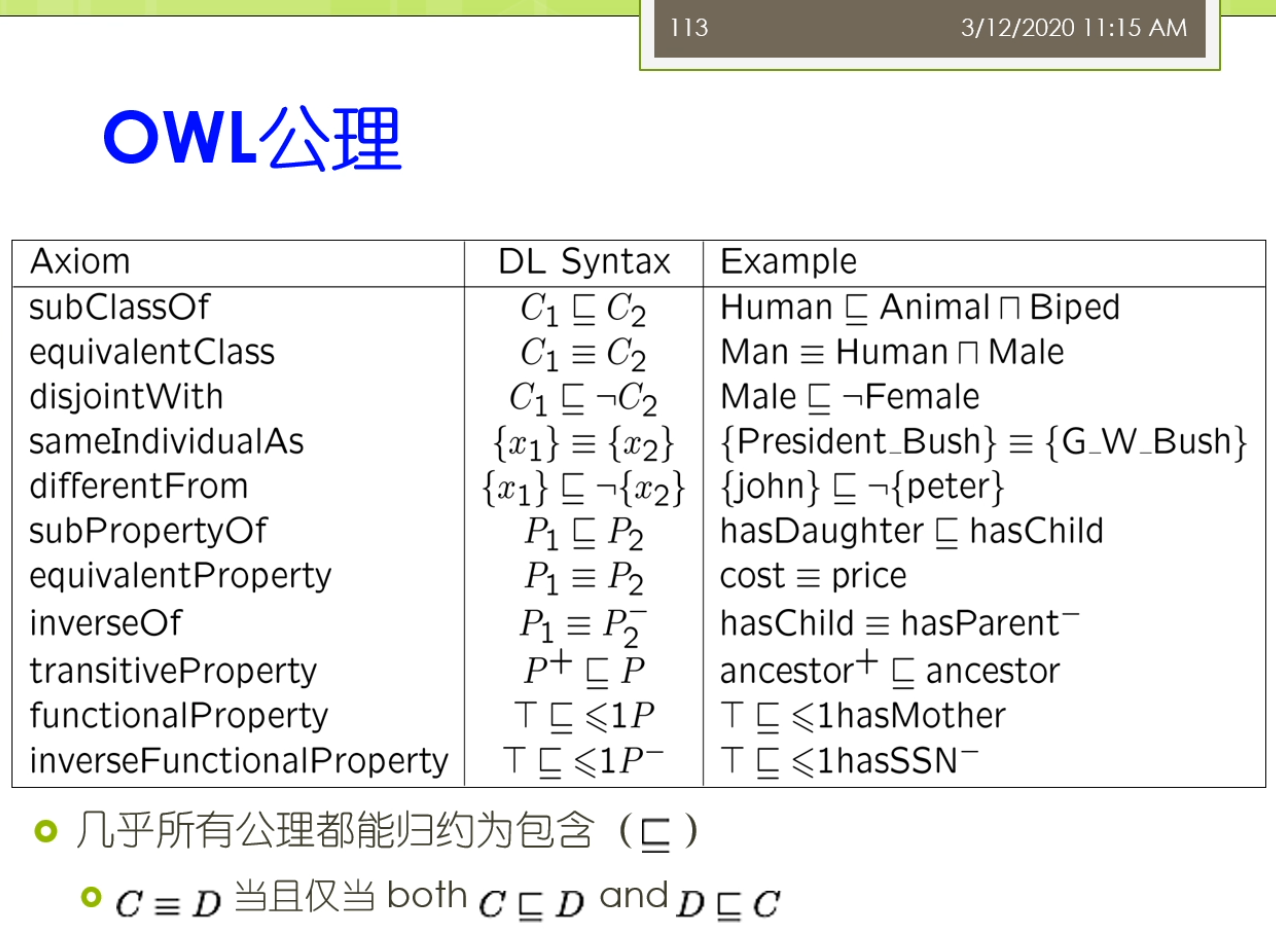
Constructor代表构造子。
第一行代表交集,第二行代表并集,第三行代表补集。第四行代表其中一个,比如说世界上所有的家是一个集合。中国就是其中一个国家。第五行代表所有的取值来自于,比如说所有的孩子都是医生。第六行代表其中的取值来源于什么?举例来说,有一个孩子是律师。存在一个孩子是律师。第七行代表最大的基数,比如说最多不超过一个孩子。。第八行代表最小的基数。比如说最少有两个孩子。
例如一个人的年龄是一个非负整数。
Person与任意一个孩子是医生取交集。然后与存在一个孩子是医生取并集。
表明了这个人,要么他所有的孩子是医生,要么他还有一个孩子是医生。

giraffe:长颈鹿。
前四行说明 giraffe是animal的一个子类。
红色字体定义了一个约束。约束是什么呢?长颈鹿是另外一个东西的子类。这个东西我们没有给他名字。

它实际上是一个匿名节点。这个匿名节点是什么呢?是一个约束。我给这个约束并没有起一个名字。因为这个约束我不想有一个全局的名字。实际上有的话也没有意义。我只说明了giraffe它要满足某一个约束。这个约束是什么呢?这个约束他有一个属性叫做eats,他的所有的取值呢来源于leaf。也就是说这个长颈鹿它应该是吃树叶的。

在RDFS里面。我们只定义了rdf的 property。不去做严格的区分。而在owl里面我们是做了很严格的区分。这个严格的区分。就是一个叫做对象类型的属性,一个叫做数据类型的属性。对象类型的属性,它的取值一定是一个对象。数据类型的属性的取值一定是一个字面量。比如说我们说的整型数,实数和字符串。这个区别是owl语言的一个很重要的一个特点。

比如说数据类型也是一种类啊。比如说Integer,我也可以把它看成是整数类啊。这里为什么要做区分呢?这个主要是设计上的一种选择。

这里还是以rdf的语言来写owl。
这个Owl头实际上是最下面本体的元数据的一些描述信息。也就是说刚才我订了一个本体,那这些本体是关于什么的呢?叫什么名字呢?这些东西会在Owl头里面写。这里面有一些描述,description。它相当于一些元数据信息。

比如说我可以定一个owl类。名字叫planttype。是所有植物的类型。我还可以定义一个owl类,叫做flowers。他是planttype的一个子类。
然后呢我还可以定义一个具体的类型的花。叫做Magnolia。他的类型呢是flowers。Magnolia是一个个体。Flowers是Planttype 的一个子类。
这里用到了分层。Planttype和flowers都是我们的概念。我们称为是tbox的东西。
而下面的这个花Magnolia,它通过一个type链接到flowers。是flower的一个实例子。他就是我们的abox。
这个地方的分层就是前面我们所说的概念和个体之间的分层。

在他的基础上,我还可以定义owl属性。比如说我可以定义一个叫datatype的属性。叫family。我可以定义另外一个花,它的类型是flowers,它是属于family家族也就是科目的。
Owl. 对属性进行了分类。一种是数据类型的属性,一种是对象的属性。而他们在取值上面不一样。数据类型的属性,它的取值就是一个字符串。

而对象的属性,它的取值是另外一个对象。

他们两者之间是不相交的关系。
前面讲的是owl第一版,那么最近几年又出来一个owl第二版。

DL:description logic
这三个计算复杂性不同的概图实际上是三个不同的子语言。

比如说我有一个很大的图书馆的分类的目录。我去检查这个类型之间的可满足性有没有错误。那么这个owl 2 el就比较适合。
Q:query owl 2 ql他擅长的是实例层次的东西。
R:rule
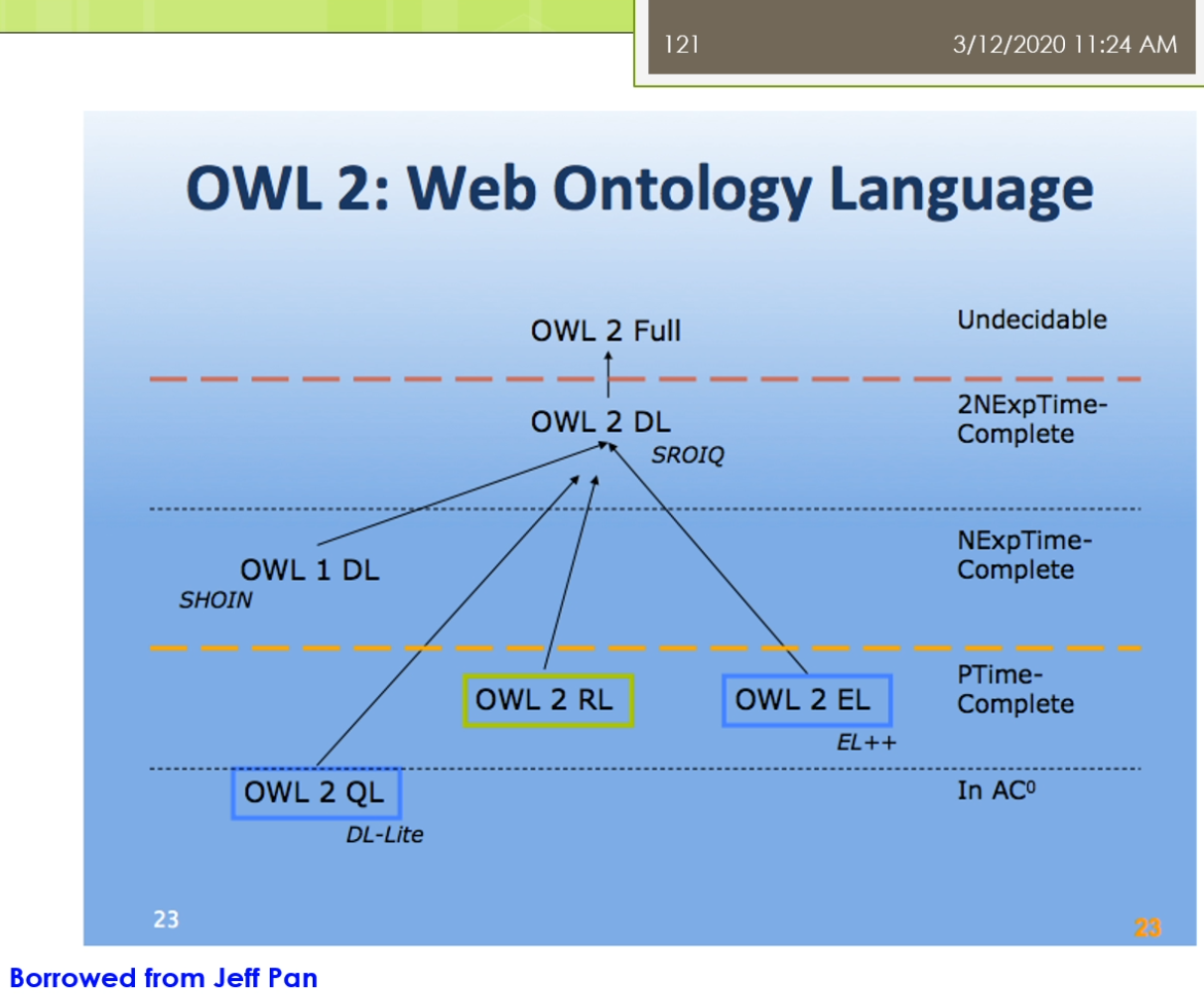
undecidable 意思是不可判定的。越往上面复杂度越高。
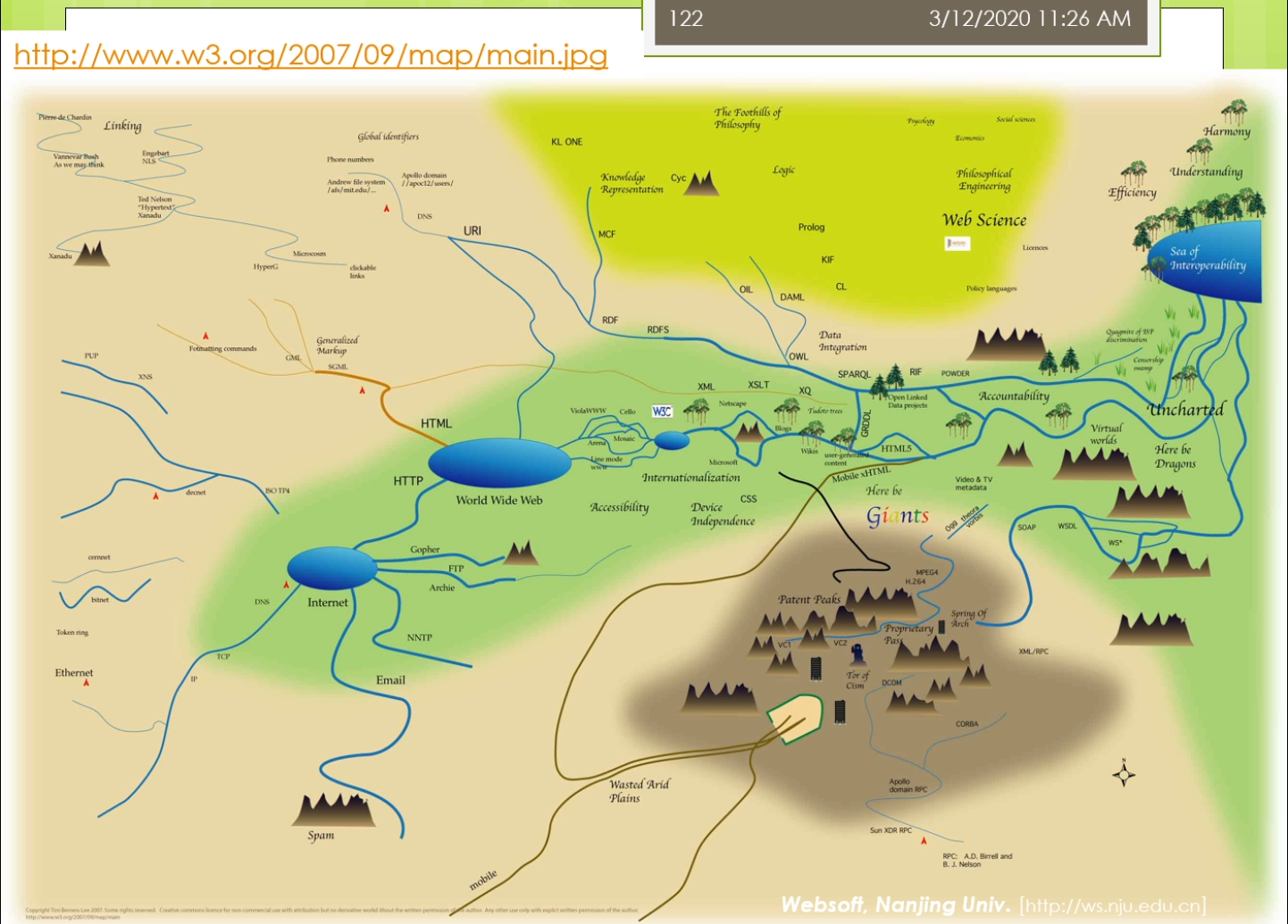
这个图是整个万维网的相关规范了一些发展脉络。
sparql是rdf的查询语言。
如果想对万维网的发展历史像有一些了解的话,可以参考一下这个图。查一些相关的一些东西会很有意思。
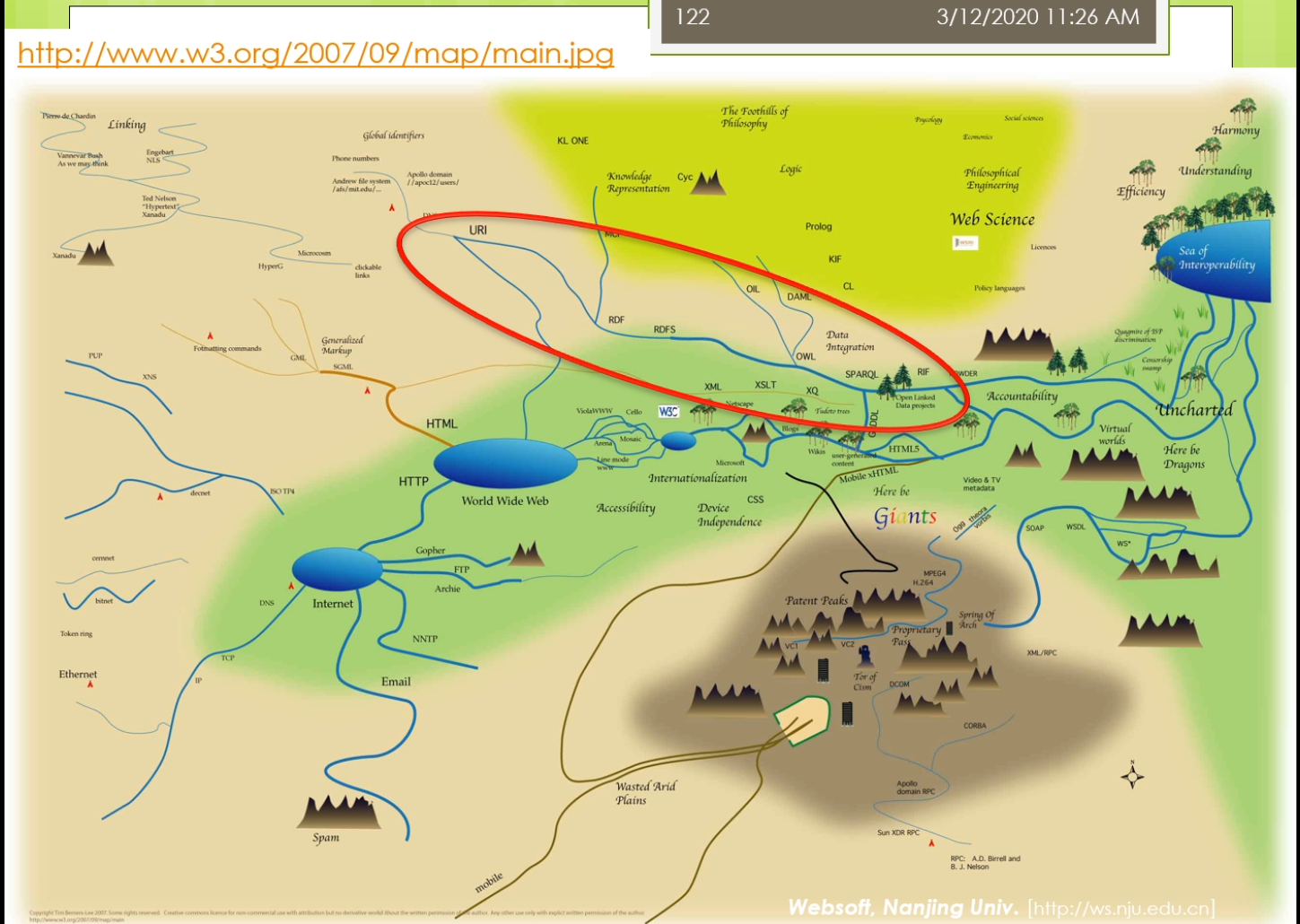
红圈里面的uri rdf rdfs owl xml 是我们讲过的一些东西,后面呢我们还会讲时sparql。
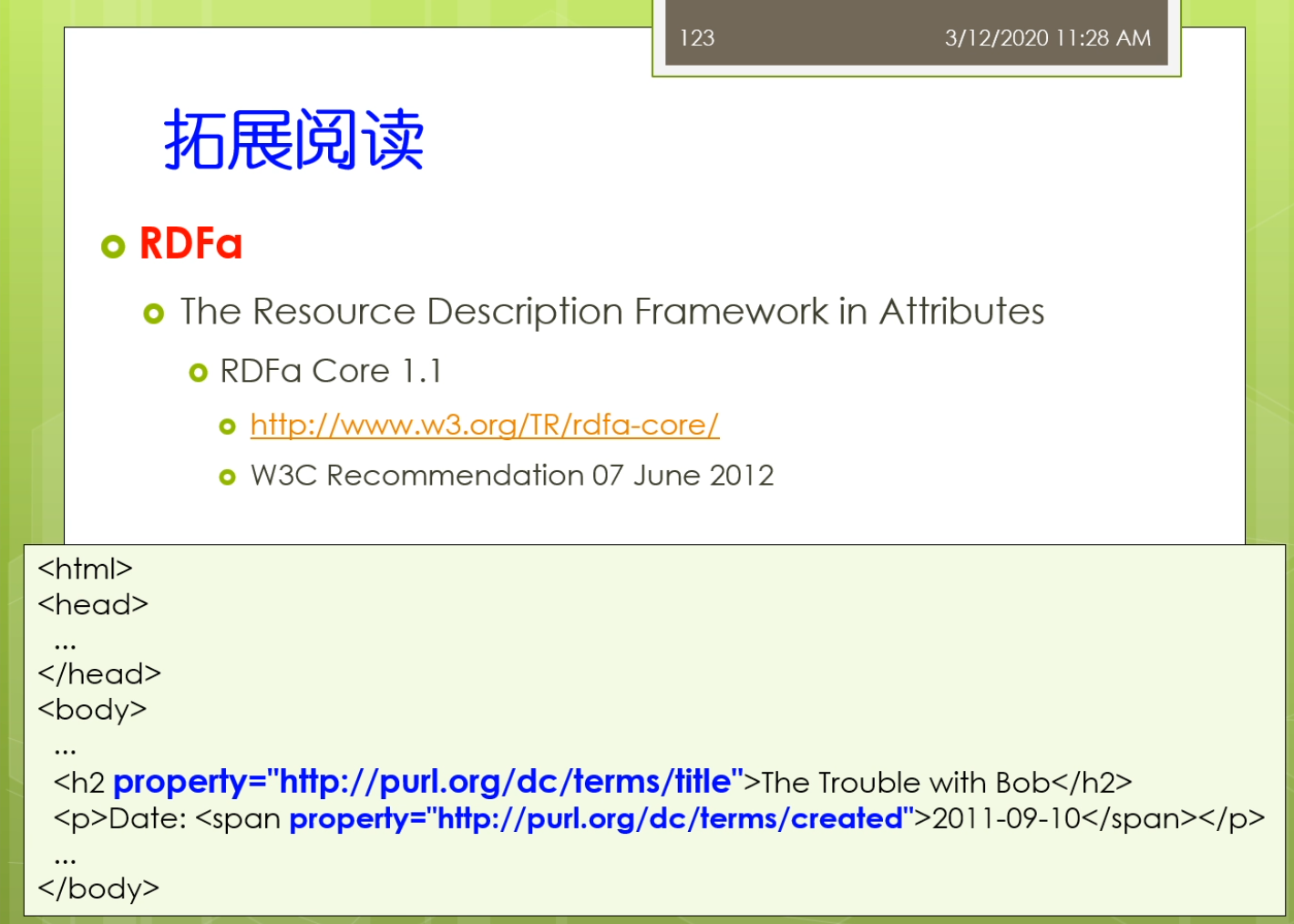
下面的HTML是我们的网页的一个片段。我们可以在HTML里面嵌入一个属性。说明了the trouble with Bob是整个网页的一个标题。我给这段文字一个显式的属性的定义。Created说明是这个文件创建的日期而不是修改的日期。也不是别的日期。所以通过添加嵌入式的属性。嵌入式的attributes。使得在使用搜索引擎的时候搜索引擎可以更好地理解这个网页里面各种文字背后的语义。
所以呢RDFa另外一种形式。他把我们刚才所学的rdf rdfs oWl. 等等的一些东西嵌入到传统的网页里面。使得网页后台对搜索引擎更友好。这样用户使用的时候更方便,更便于理解。

