知识工程及语义网技术(一)-XML、RDF(S)、OWL-2020.3.5第一节
https://www.bilibili.com/video/BV16E411x7jK/?spm_id_from=333.788.recommend_more_video.-1


W3c是万维网上发布各种规则、规范和协议一个联盟。





XML的设计宗旨不是显示所以他没有任何的行为,不像HTML那样。主要用来显示。



XML使用Unicode作为它的默认编码。


1的地方多了一个空格,2的地方多了一个换行。所以这三个数据是不同的数据。



红框里面的内容是HTML的内容。他的格式是HTML格式的。

有了cdata,解析器就不会去解释这些尖括号,单引号,双引号的问题。





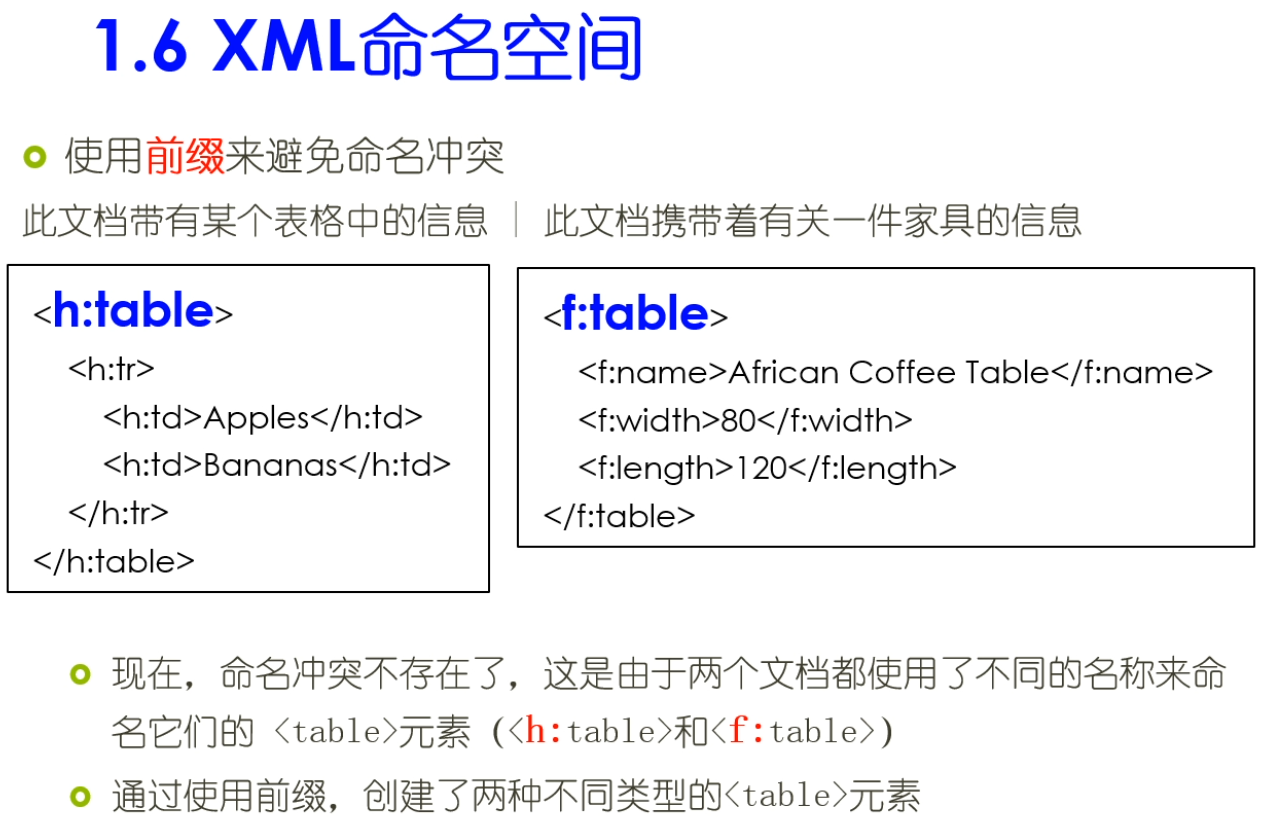
名域格式是固定的,内容也是固定的。XMLNs nS指的是namespace。
eltOnly指的是elementOnly。就是说在这个元素的数据里面不能写一些文本了。
只能写成下面那种形式了。就是包含year,month和day的元素的那种形式。


Resume嵌套了birthday这个元素。而birthday这个元素又嵌套了元素year,month和day。所以XML的schema约束是一个嵌套的结构。




蓝色字体表示下面这一块是一个XML文档。

href表示hyperlink reference。表示对于超链接的引用。







这个地方实际上是定义一个模板。




URL和urn合起来叫做URI.

你现在有一个xml,它很大,你这时候就可以选择sax解析。
dom4j。实际上是模拟了DOM的方式,但是它本质上是用SAX解析。所以它占用的资源比较少。但是速度也比较快。它结合了DOM解析和sax解析的优点。

下面看和语义网更相关的rdf和owl标记语言。
资源描述框架,它是想用一个统一的模式去描述关于某些事物的数据。或者说某个领域的数据。


rdf可以使用XML文档格式作为它的一种表示方式。在这个rdf里面,它是一个XML文档,它也可以用XML的解析器去解析。
但是呢rdf是一种数据模型。它借用了XML的语法结构。它也可以基于一些其它的语法结构。比如说tripe格式、json格式等等。所以它不仅仅是局限在XML格式。但是呢xml格式的话很多人比较熟悉。用它去写rdf呢感觉也比较自然。

思考一下river在什么命名空间下?

#号表明了这个网址下面定了一个叫river的元素。
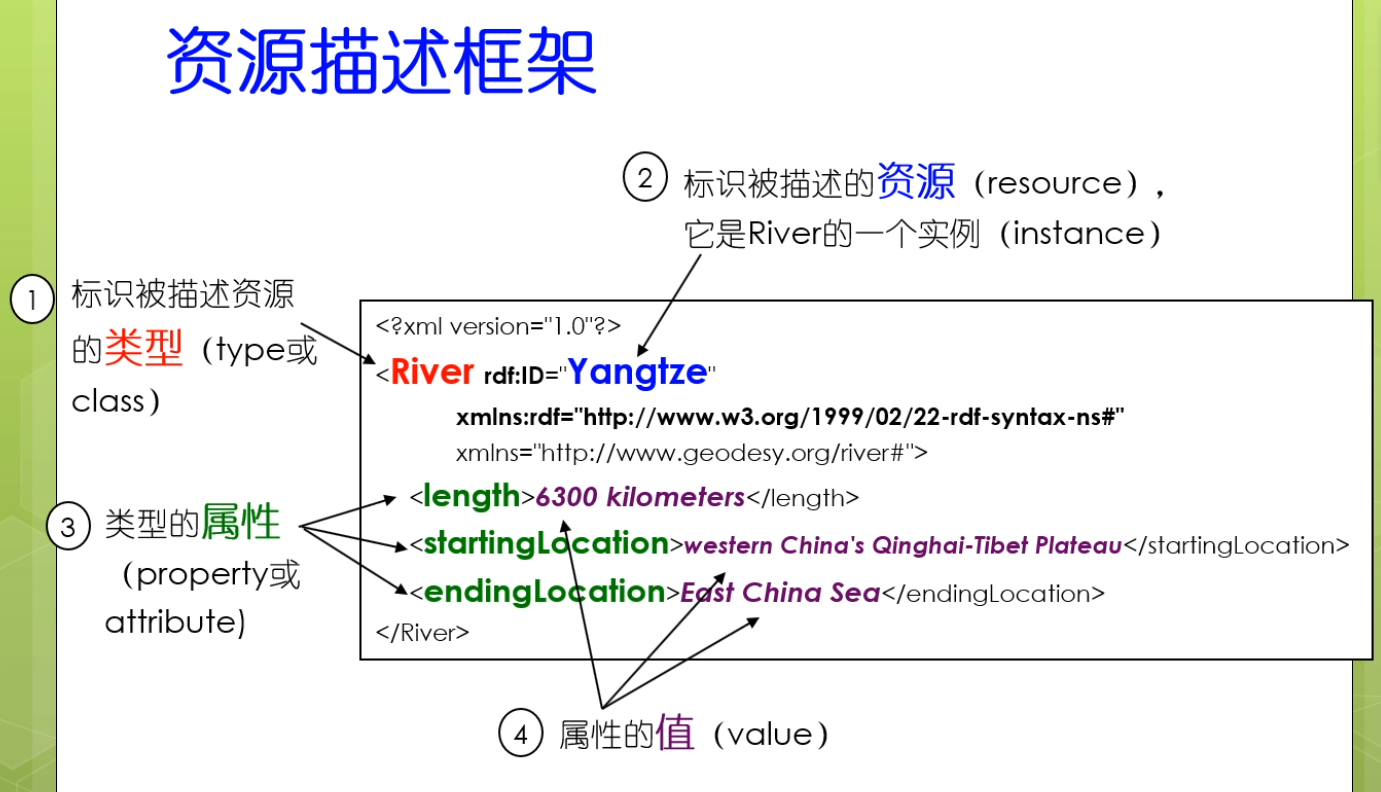
为什么杨子江是river的一个实例呢?他是有rdf:id来标识的。rdf:id的含义是有w3c官方文档来定义的。扬子江的类型是一条河。
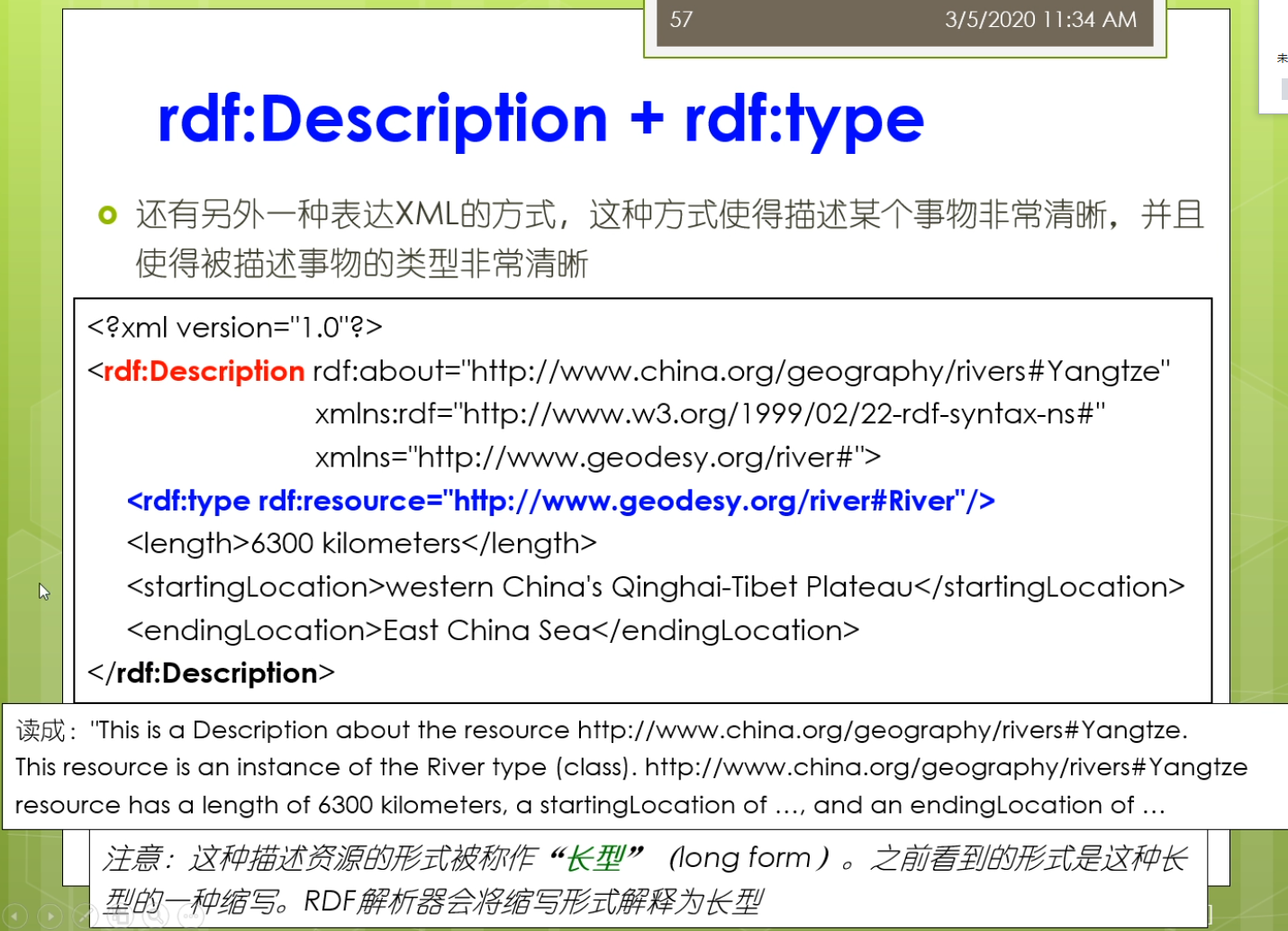
下面是一个标准的资源描述框架RDF的结构:

我做一个class,他的实例里面有一个是resource。第三行代表rdf的命名空间是固定的。第四行代表我可以对这个文档起一个默认的命名空间。第五行和第六行代表我这个类可以有它的属性以及相对应的属性值。
这就是一个标准的资源描述框架的结构。写rdf的话就按照这个结构写。

互操作性是指我有很多不同的工具或者软件。这些软件之间使用数据进行交换和共享的时候。互相之间可以去方便的用别人的数据。
rdf:id就是一个标准化的词汇。是可以让大家都使用一种规范的词汇对文件进行结构化的设计。
rdf格式提供一种结构化的方法来设计是XML文档。指的是二RDF使用的是一种三元组的方式。即主谓宾结构。这个结构呢比XML文档更加严谨。这使得rdf的结构化更强。使用起来更严谨。
语义网是一种人工智能的知识表示的方法。最大的特点就是他能够进行语义推理。



默认的命名空间和文档的相对位置的URI是不一样的。


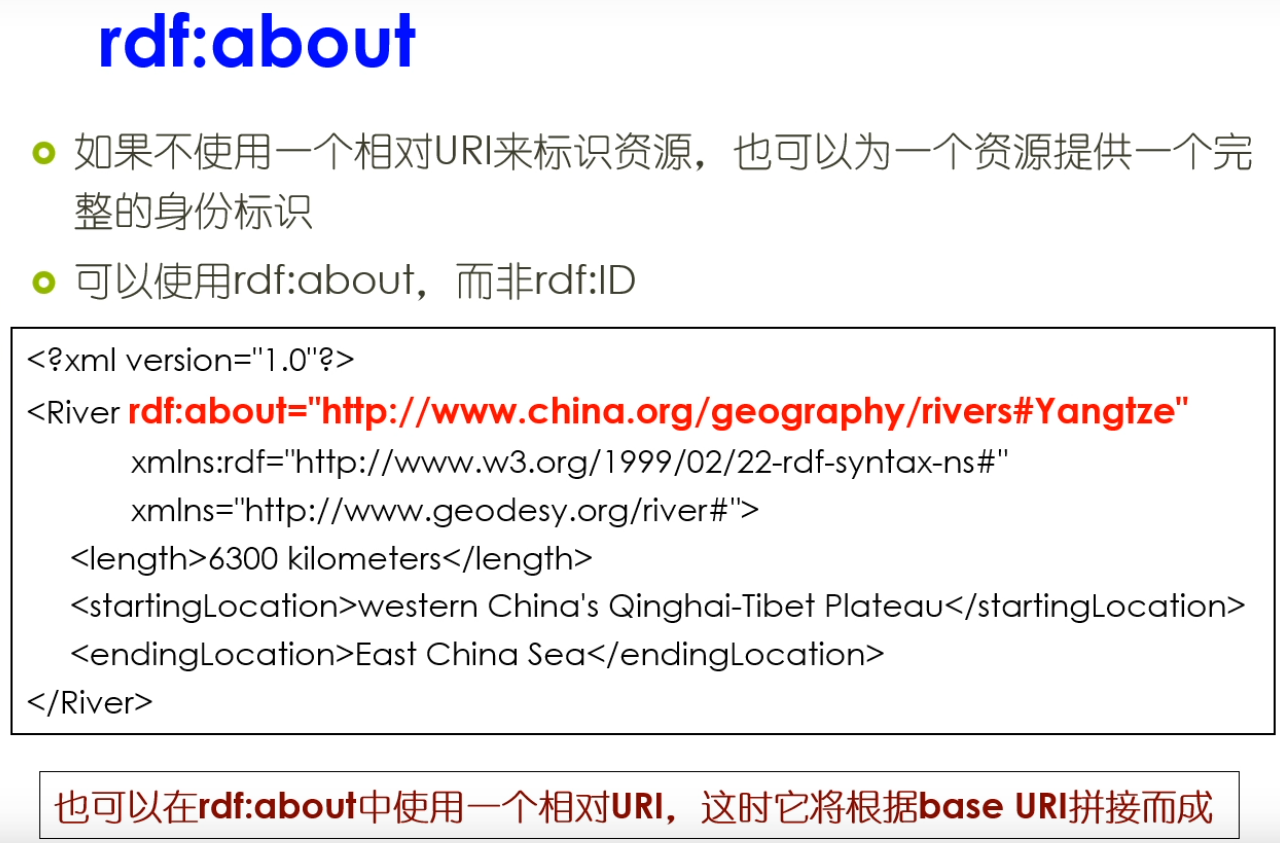

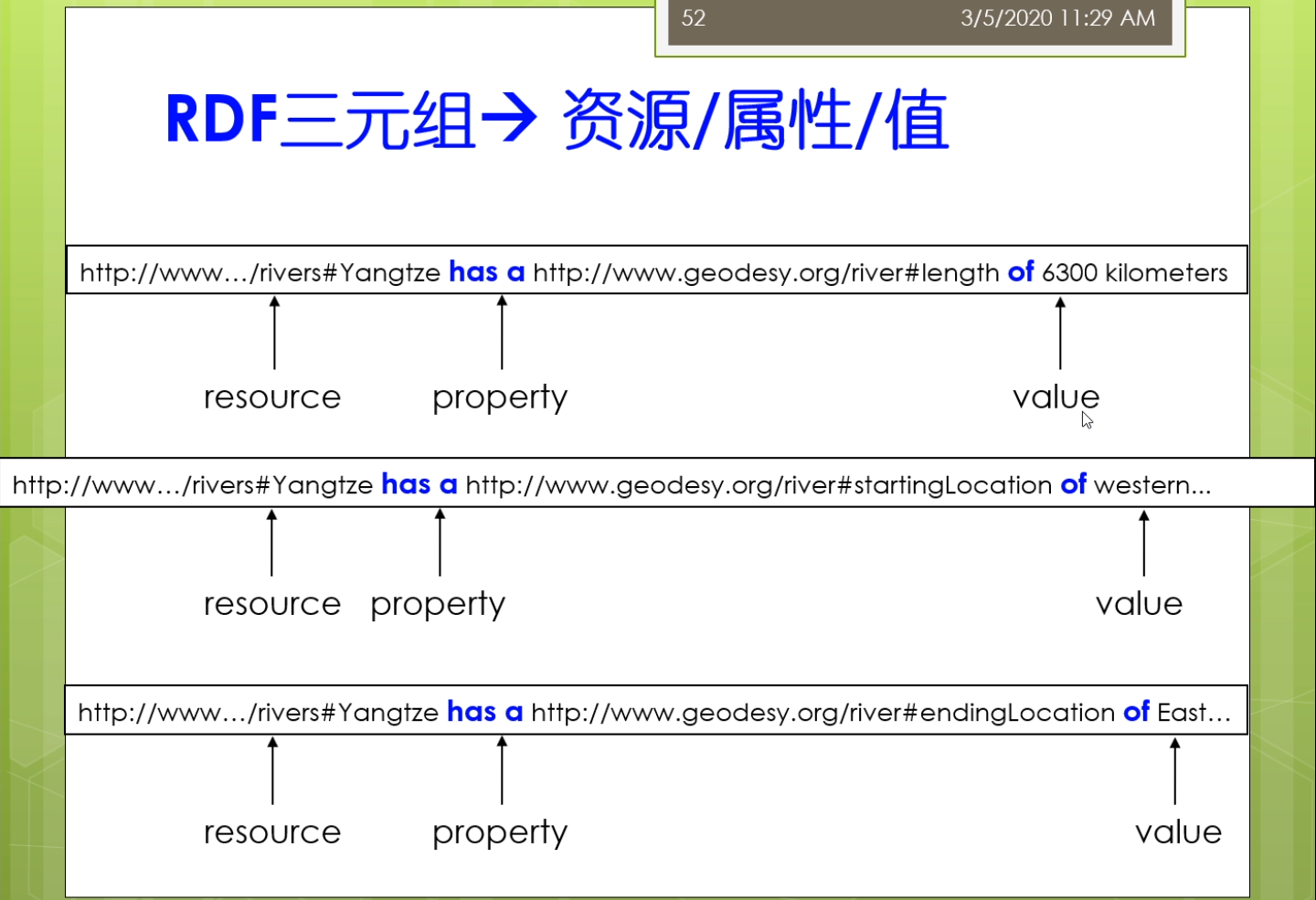

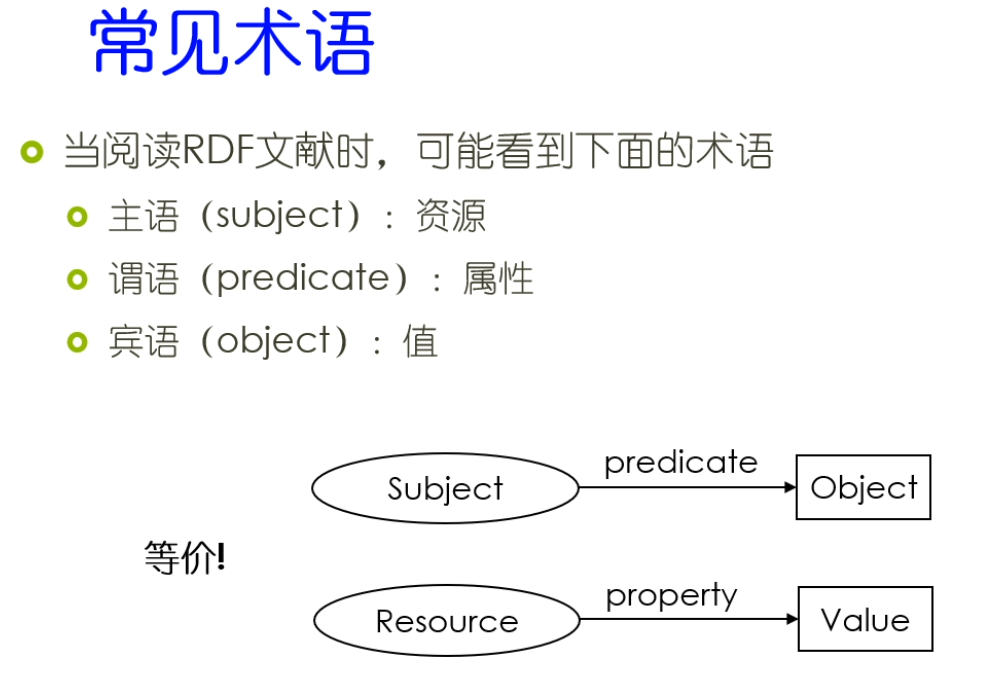
主语,谓语和宾语,这样的话就和一般的自然语言最基本的结构比较接近。

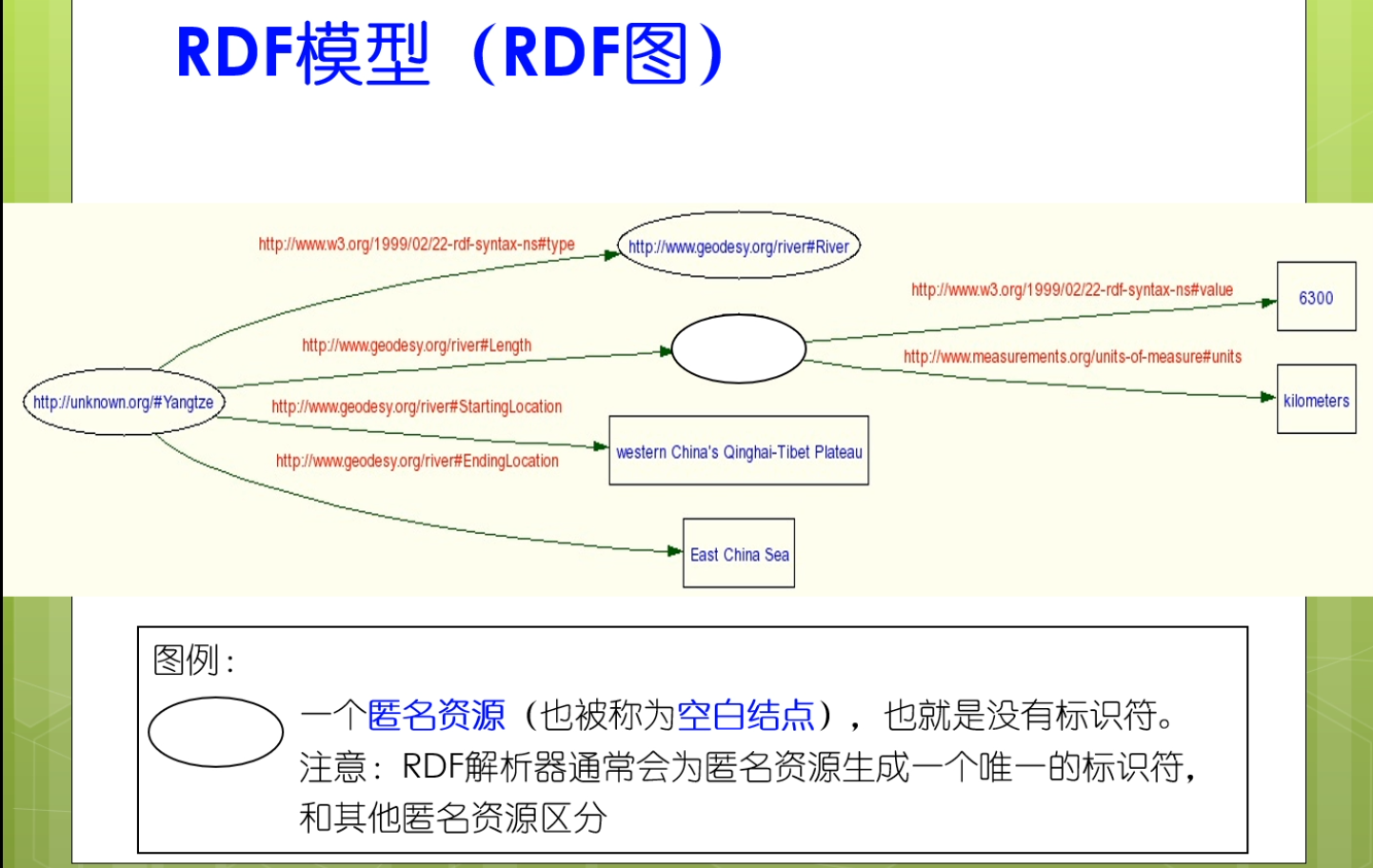
rdf图是一种有向图。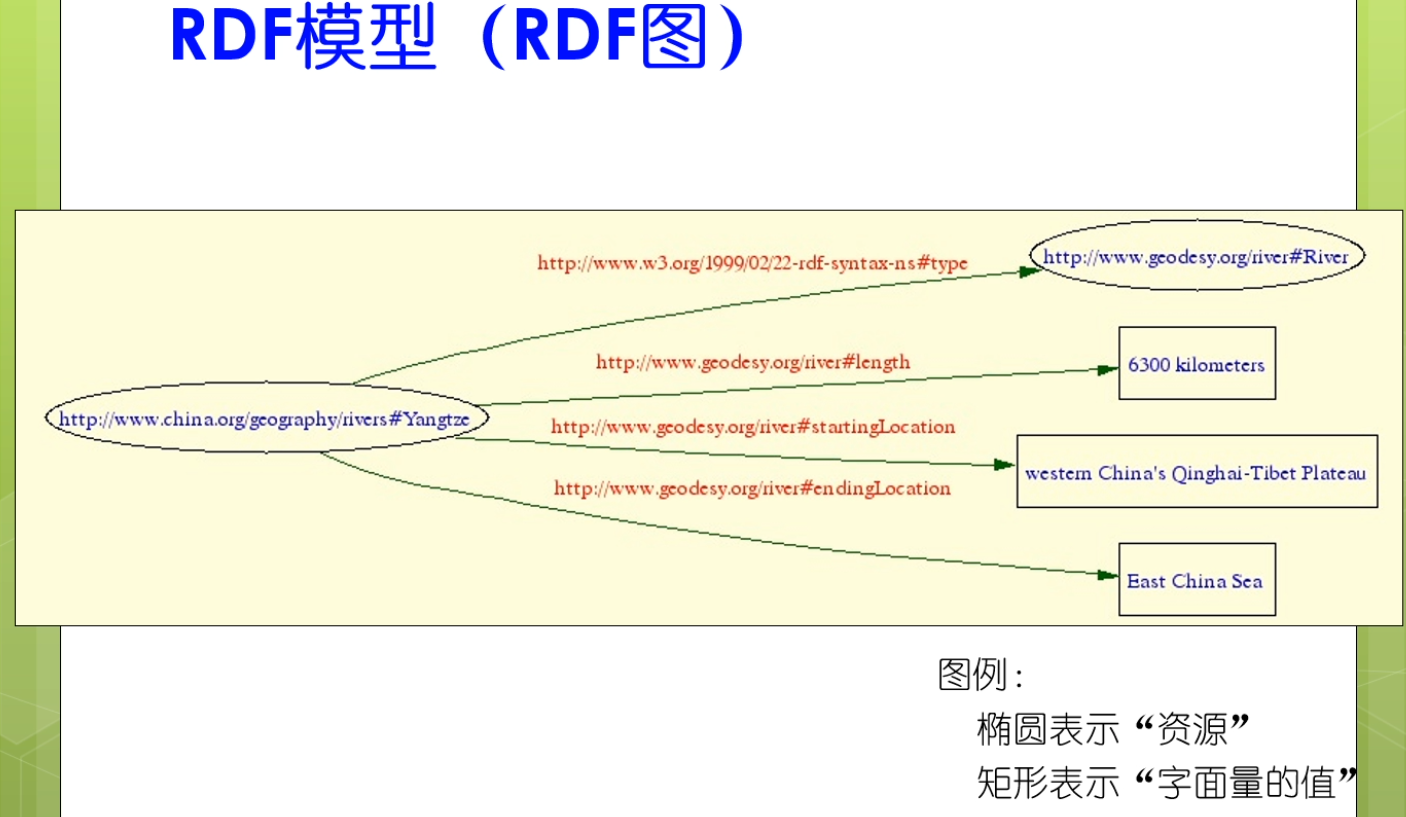
rdf可以用来XML写,但是他并不依赖于xml也可以用Json来写。
椭圆一般表示资源矩形一边表示字面量的值,这是一种约定俗成的表示方法。
其实呢,ending也可能有自己的属性和值,他也可以作为一个节点。但是呢,在这种简单的有限图上,不太好表示。所以就用超链接去表示。因为他有形成一个Hyperlink.


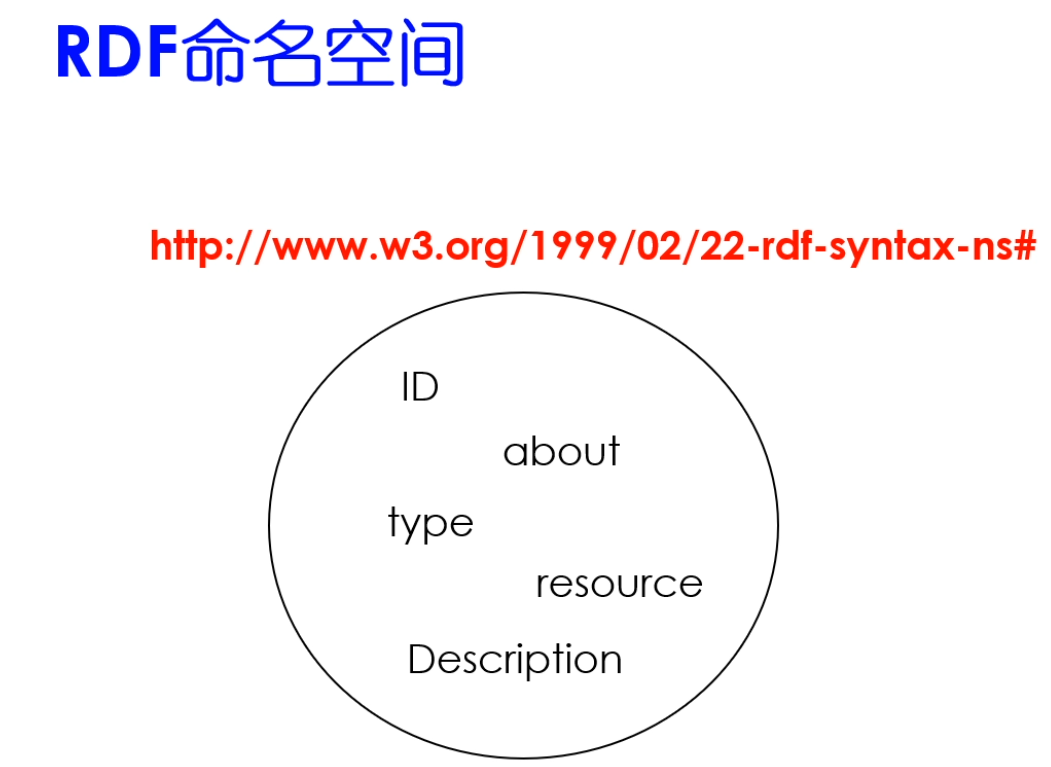
RDF的命名空间包含这几个关键词。






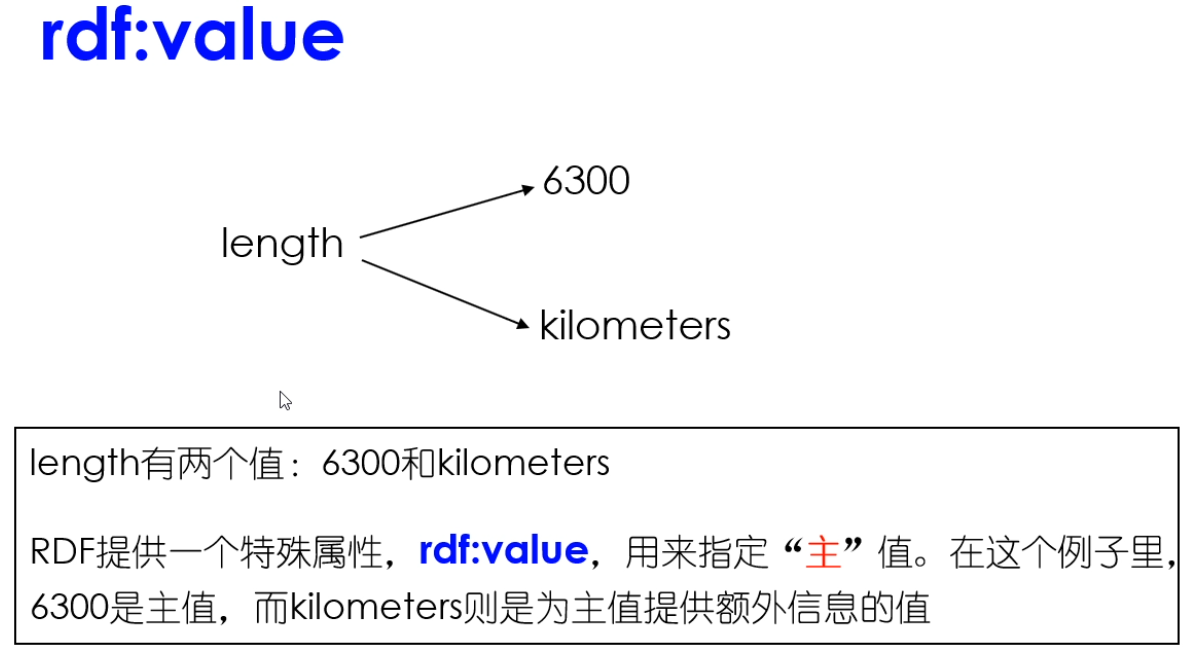

此处扬子江它的长度是一个匿名资源。这个匿名资源又有两个属性。一个是它的取值,一个是它的单位。
并没有给红色字体部分一个URI。实际上也没有必要给他做这个标识。所以这一块只是一个描述信息。但是你一定要看出来扬子江它的长度是一个匿名资源。