

语义网
来源:http://zhuanlan.zhihu.com/p/208858014
1. 前言
刚学习语义网,希望这篇文章能够作为学习日志,又或者能帮助其他求学之人。
语义网(Semantic Web)是由万维网创始者,Tim Berners-Lee提出的,其目的是让机器不仅仅了解语法,也能了解语义。
用人话来说,让电脑懂得你说的话的意思。
首先解释两个概念,语法(Syntax)与语义(Semantic)。举个例子:
小猫是植物。
这是一句完整的话,主语是小猫,谓语是是,宾语是植物。这句话在语法上是成立的,因为它具有一句话所需要的所有要素,并且在语法上没有错误。但是他在语义上是错误的,因为小猫不是植物。
我们这时候再看语义网的定义就不难理解了:由于一开始的万维网上所具有的所有信息,都是基于合理的语法所编写,而没有在意语义上的对错,所以在文字处理和搜索等等方面,很多时候出来的都是错误的结果或者不准确的结果。这也是为什么我们要发展语义网,这也是让机器了解语义的意思。
要解释语义网,我想首先说一下语义网的架构,然后再说细节。下面一张图非常清楚的描述了语义网的架构。(别急,往下看)
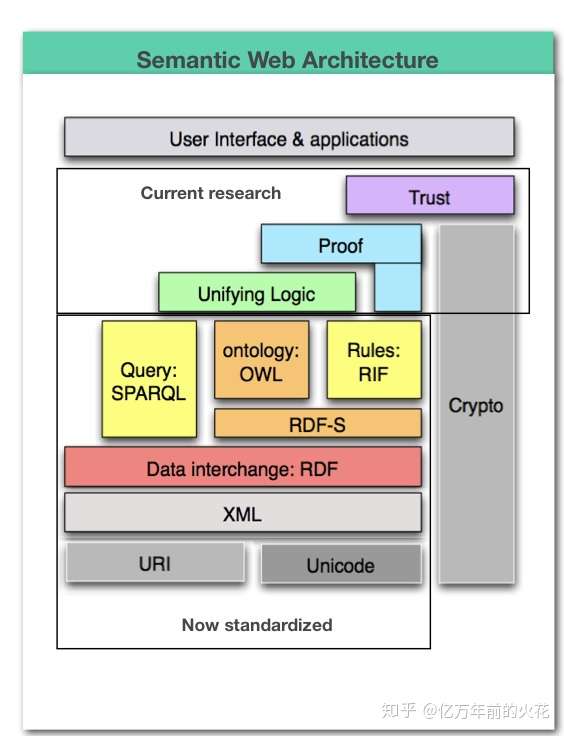 图1:一张图描述语义网结构
图1:一张图描述语义网结构
这张图有两种看法,从上往下或者从下往上。这里我们可以先停一下,想象一下我们现在上网的时候的过程。你打开浏览器,搜索后找到网页,点进来,看到这篇文章。你的这些所有的动作都在这张图的最上端执行,也就是User Interface&Applications,也就是用户端。而你为什么能看到这篇文章,为什么能搜索到这篇文章,这篇文章的内容从何而来,都是由表面看不见的下端所决定的。
而这里,我想从最底层开始说起。
2. URI与Unicode
2.1 URI
好的让我们从最底层开始看,我们遇到两个名词:URI与Unicode。
URI全称是Uniform Resource Identifier,中文就是统一资源标识符。他的作用就是为网上的各种资源做标记,以便与机器能够找到该资源。
这就好比是在现实世界中,想找到一个人,要知道他的地址和名字,也就是他在哪里,他叫什么,而地址与姓名我们可以称为这个人的标识或者标签。当然他也有很多其他的标识比如生日,喜欢的颜色等,不过通过这些标识你不太能寻找到这个人。
在语义网络世界中也是一样,一个资源同样也被标签所描述,也通过标签被找到后提取,而且在网络世界中所使用的标签,也是地址与名字。这也就产生了两个衍生概念:URL与URN。
或许你已经看出来了这两个名字里所含有的玄机。也许你没看出来,没事,我们把他们的英文全名写出来:Uniform Resource Location 与 Uniform Resource Name. 没错,URL与URN就是两种通过不同标签来做标识的URI,也就是标识方法。URL与URN都属于URI,也可以说,URI通过其做的标识是地址还是名字被分成了URL与URN(如图2)。
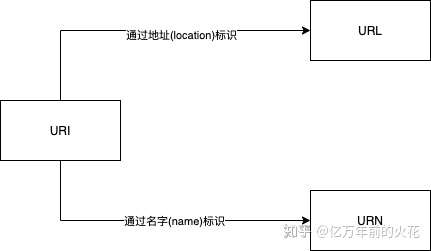 图2: URI通过标识种类分为URL与URN
图2: URI通过标识种类分为URL与URN
2.2 Unicode
这个也被称为万国码,国际码。没什么可解释的,相当于写英语时候写的字母,写汉子的时候写的每个汉子,是每个文章,句子的基本单位。
3. XML
XML的全称是(eXtensible Markup Language)。如果你问为什么不叫EML,根据我的调查,是因为程序员们认为XML说起来比较酷,秃头们的浪漫。
中文翻译过来就是可扩展标记语言。顾名思义,它可以扩展着写,用处是作为标记语言。那么问题来了,什么是标记语言?
在现实世界中,如果我看到一个妄自尊大的人,我心里会给他定义为SB。SB这个就是一个标记,在别人眼中是看不到的,因为我不会说出来。所以我们发现,每个事物背后都有各种标签,这些标签在网络世界中被称为metadata,也就是元数据。
元数据是隐藏在网络上文字背后的数据。如果你在网上找一个电影,你看到了电影的名字是:透けるノーブラ,这个名字背后的元数据是:Title,也就是标题。也就是说元数据描述了该事物的一个或多个性质。而标记性语言中包含了我们看到的数据与元数据。
<Movie>
<Title>
无间道
</Title>
<Type>
剧情、犯罪、警匪
</Type>
</Movie>上面我们看到的就是一个描述电影的标记语言语句。其中不带括号的字是我们在网页上看到的,带括号的就是元数据。
上一代我们用的标记语言是HTML(Hyper Text Markup Language)超文本标记语言,它的标签是预定义的,也就是后天不可改变,不可扩展。后来人们渐渐发现,这样虽然够用,但是太不灵活,所以就发明了XML。XML就灵活很多了,编辑者可以很灵活的对其扩展,任意设置所需要的标签。
3. RDF
RDF的全称是Resource Description Framework,翻译过来就是资源描述框架。
那这到底是个什么鬼呢?
大家应该都看过警匪片,或者扫毒剧,比如破冰行动之类的。其中经常出现一些片段,是这些警察在白板上有很多的关系图,比如图3:
 图3:剧中经常出现的显示主角智商的关系图
图3:剧中经常出现的显示主角智商的关系图
这个其实就是RDF所用到的思想。不要急,且听我慢慢道来。
别的人我不知道,就我个人身边的环境来讲,会发现,中国人往往在学语言的时候对语法非常的擅长,但是很害羞不敢说,导致口语比较差。
语法中大家知道有主谓宾定状补,一个句子可以按照这些成分来划分,从而分析它的结构。我们这里不用那么多的成分,我们只需要前三个:主(Subject)谓(predicate)宾(object)。
如果让你只用这三个成分描述下面一种情况:
福尔摩斯这个大侦探有个好基友是叫做华生的医生。
你会怎么描述?RDF的策略是把它分为多个SPO(Subject,predicate,object)三元组:
福尔摩斯(Subject)是(Predicate)大侦探(Object); 福尔摩斯(S)有(P)好朋友(O); 朋友叫华生; 华生是医生。
这样我们就用最简单的成分表达出来了一句复杂的语句。那么有没有更直观的方法呢?有,就是所谓的Triple图,三元图(在西方,Tri- 这个前缀是3的意思)。下面图4中所表示的就是一个三元图:
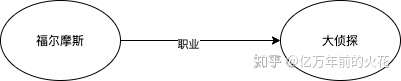 图4:最简单的三元图
图4:最简单的三元图
然后我们可以将很多三元图连起来:
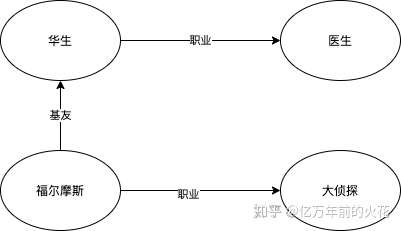 图5:由三元图组成的网
图5:由三元图组成的网
这样我们就有了一个网。这种表示方法被人称为RDF,也就是资源描述框架。相信到这里你对他的名字有了更深的理解。
序列化RDF数据的方法主要有这几种:RDF/XML,N-Triples,Turtle,RDFa,JSON-LD。这里不展开说。
4. RDF-S
从RDF-S开始,就更加抽象了。RDF-S中的S代表Schema,也就是模式。它是一种在RDF基础上开发出来的描述模式。我们拿图灵来举例。图灵是一个科学家,他的研究方向是人工智能。
图灵是真是存在的一个例子,人工智能也是现实中存在的一个例子,所以我们将他们看作是实体。
人工智能属于计算机技术的一种(type),图灵也是计算机科学家中的一个,像计算机技术与计算机科学家这样的一个集合体,我们称为类(class)。
而计算机技术属于技术的一种,计算机科学家又属于科学家的一种,所以我们说,计算机技术是技术的子类(subClass),同理计算机科学家也是科学家的子类。
那么我们用RDF-Schema表示出来是这样的:
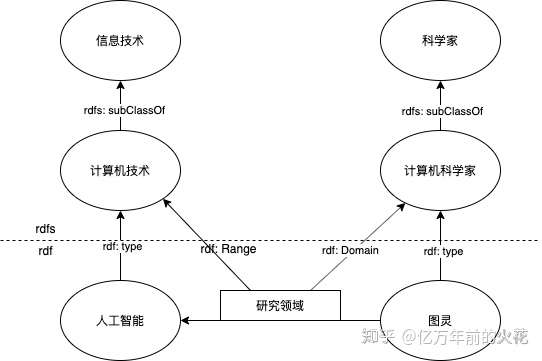 图6:一个简单的rdfs
图6:一个简单的rdfs
RDFS中描述资源的词汇是固定的,只有Class、type、subClassof、Property、subPropertyof、Domain和Range。
相对于RDF而言,RDFs可以描述一些关系,但是由于描述词汇是固定的,所以能描述的关系有局限性。所以我们需要一个更加强大的工具。这个工具就是比RDFs更高一级的(参见图1)OWL。
5. OWL
OWL的全称是Web Ontology Language,aka 网络本体语言。你要问我为什么它不叫WOL,我想可能是因为这个命名人很喜欢猫头鹰吧。
就我个人的理解,OWL是一个基于RDFs描述性词汇的扩展。OWL语言根据它的涵盖范围分为三种,OWL Full(全部的OWL),OWL DL(OWL 描述性语言,DL=Description Language)与OWL Lite。他们的关系是:
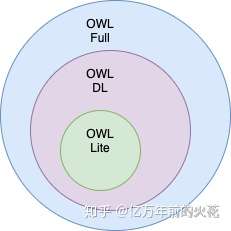 图7: 三个OWL语言包
图7: 三个OWL语言包
DL是从Full中摘取的一部分,Lite是从DL中摘取的一部分。这三个包的选用取决于我们对资源的描述的需求。
OWL所描述资源的组成又被分为Class,Rollen 与Individuen:
Rollen属于Class。
Individuen,也就是实例,又是Rollen中的一个例子。
比如在RDFs中我们说的图灵,就是一个Individuen。
OWL相对于RDFs提供了更多的描述性词汇,也就提供了更多的可能,比如对两个词汇做逻辑判断是否相等等等。当然他也具有像RDFs中具有的判断subClass这样的能力。
6. SPARQL
SPARQL是RDF数据库查询语言,它的核心思想是,根据给定的谓语动词,从三元组提取符合条件的主语或宾语。[2]
SPARQL类似于SQL数据库中的SELECT等命令。具体情况大家可以参考文献[2],里面关于RDF的解释也非常详尽。
7. 后记
对于语义网的简介就到这里了,是一个入门文章,记录且解释了一些自己刚开始时候遇到的迷惑。希望也能帮助到在求学之路上行走的人。
参考
- ^https://blog.csdn.net/baijinswpu/article/details/81185965
- ^http://www.ruanyifeng.com/blog/2020/02/sparql.html
来源:
语义网概念及技术综述
摘要:语义网是现有万维网的变革与延伸,是Web of documents向Web of data的转变。它的目标是让计算机可以像人脑一样理解信息的含义,从而完成智能代理的功能。本文对语义网结构、相关技术、规范做了简要的综述,分析了目前语义网研究所面临的挑战,并为下一步的研究工作明确了方向和重点。
关键词:语义Web 本体 OWL 资源描述框架
互联网之父、HTTP和HTML的发明人蒂姆·伯纳斯-李(Tim Berners-Lee)在1998年[1]提出了语义网(Semantic Web)的概念并在《科学美国人》杂志上发表了相关论文[2],由此揭开了世界范围内语义网研究的序幕。语义网被认为是下一代互联网即Web3.0的发展方向。Web已经成为了人们获取信息的主要渠道,深刻地影响着人类生活的方方面面:人们在Web上浏览国内外新闻、网上交易、搜索信息。然而,目前我们正在使用的Web是面向人的而不是面向机器的,换言之,很多繁琐的过程都要用户参与。面对海量的网页数据,人们准确全面、快速便捷地获取到有价值信息的难度越来越大。语义网是一种使用可以被计算机理解的方式描述事物的网络,它的基本思想就是让机器或者设备能够自动识别和理解万维网上的内容,自动化地处理、集成来自不同数据源的数据[3],使得Web信息获取更为智能便捷。
本文将从4个方面对语义网概念和技术作综合述评:(1)基本概念,对语义网的相关背景、概念做一个总体介绍。(2)体系结构,阐述语义网的体系结构。(3)关键技术,对语义网涉及的RDF(Resource Description Framework,即资源描述框架)和Ontology(本体论)等技术进行介绍。(4)面临挑战,结合当前国内外研究现状阐述语义Web面临的挑战。最后再对语义网技术进行总结和展望。
一、基本概念
从Web诞生并经历多年发展至今,Web上的网页数量呈指数级增长。尽管Web上存在海量的信息,但是当前的Web实际上只是一种面向人的存储和共享信息的媒介[4]。Web上的内容是提供给人而不是机器本身来理解和浏览的。由于Web内容没有采用形式化的表示方式,并且缺乏明确的语义信息,故而计算机“看到的”Web内容只是普通的二进制数据,对其内容无法进行识别。如果机器不能充分理解网页内容的含义,就无法实现Web内容的自动处理。
考虑到当前Web存在的上述问题,Berners-Lee提出了语义网。顾名思义,语义网是对现有Web增加了语义支持,它是现有万维网的延伸与变革,其目标是帮助机器在一定程度上理解Web信息的含义,使得高效的信息共享和机器智能协同成为可能。语义网将会为用户提供动态、主动的服务,从而更便于机器和机器、人和机器之间的对话及协同工作。简言之,语义网就是以Web数据的内容,即数据的语义为核心,用机器能够理解和处理的方式链接起来的海量分布式数据库[4]。
二、体系结构
Berners-Lee提出了最初的语义网体系结构[5],随着人们对语义网的深入研究,语义网的体系结构也在不断地发展演变。图2-1给出了语义Web的体系结构,各层的功能自下而上逐渐增强。
图2-1 语义网的体系结构
第1层:基础层,主要包含Unicode和URI(Uniform resource identifier)。其中Unicode是一种流行的字符集,采用两字节的全编码,可以表示65536个字符,这使得任何语言的字符都可以被机器容易地接受。URI即通用资源标识符是用于唯一标识抽象或物理资源的简单字符串。网络上的任何资源包括HTML文档、程序、图片、音视频等都有一个能被URI编码的地址,从而实现对Web资源的定位。
第2层:句法层,核心是XML及相关规范。XML是SGML(标准通用标记语言)的一个子集,它以一种自我描述的方式定义数据结构。在描述数据内容的同时能突出对结构的描述,从而体现出数据之间的联系[4]。用户可以在XML中自由地定义标记名称及元素的层次结构。为了便于程序或其他用户能够正确处理用户定义的内容,XML还定义了命名空间(Name Space)和XML模式规范(XML Schema)以提供更好地XML文档服务。
第3层:资源描述框架,主要包括RDF及相关规范。RDF是一种用于描述WWW上资源信息的通用框架,比如网页的内容、作者以及被创建和修改的日期等。RDF[7]本质上是一种数据模型,用主体(subject)、谓词或属性(predicate或property)、客体或属性值(object或property value)所构成的三元组来描述资源的元数据[8]。RDF也可以用于表达其它元数据,例如分子的结构、图书的书目信息等。正因为RDF的灵活性,它成为了诸如生物、化学等许多领域表达元数据的基本方法[11]。可以说,RDF已经成为知识表达的通用形式。如果把XML看成一种标准的元数据语法规范的话,那么RDF就可以看做一种标准的元数据语义描述规范。
第4层:本体层,即定义本体(Ontology)。该层在RDF的基础上定义了RDFS(RDF Schema)和OWL(Web Ontology Language)帮助用户构建应用领域相关的轻量级的本体。RDFS和OWL定义了语义,可以支持机器在用RDFS和OWL描述的知识库和本体中进行推理[4],以达到语义网的目标。
第5至7层分别是逻辑层(Logic)、验证层(Proof)、信任层(Trust)。逻辑层在前面各层的基础上进行逻辑推理操作。验证层根据逻辑陈述进行验证,以得出结论。信任层是语义网安全的组成部分,与加密不同的是,该层主要负责发布语义网所能支持的信任评估[4]。目前第6层和第7层正处于设想阶段。
基于语义Web的体系结构还在建设当中,科研人员及相关组织还在研究制定相关的规范、开发工具及软件包,为将来人们开发友好、可靠的语义网应用提供强有力的支撑。
三、关键技术
从图2-1不难看出,实现语义网需要三大技术的支持,即XML、RDF和Ontology。其中XML层作为句法层,RDF层作为数据层,Ontology层作为语义层。
如果说HTML被设计的目的是用来显示数据,焦点在于数据的外观,那么XML(extensible markup language),即可扩展标记语言提出的目的则是传输和存储数据。XML不仅能提供对资源内容的表示,也能描述资源的结构信息。XML严格遵守DTD或Schema定义的语义约束,天生具有良好的数据存储格式、可扩展性、高度结构化等优点,因而XML顺理成章地成为了语义网的支撑技术。事实上,目前国内外针对语义Web关键技术的研究主要集中于RDF和Ontology。
3.1 RDF
RDF是由万维网联盟(World Wide Web Consortium,W3C)组织的资源描述框架工作组于1999年提出的一个解决方案,并于2004年2月正式成为万维网联盟推荐标准。RDF是一种语义资源描述语言,可以视为一种由数据结构、操作符、查询语言和完整性规则组成的数据模型。该模型描述了用元数据表示的真实世界的实体信息,其目标是构建一个综合性的框架来整合不同领域的元数据,实现在Web上交换元数据,促进网络资源的自动化处理[8]。
RDF的基本数据模型包括资源(resource)、属性(property)及陈述(statements)。
(1)资源:一切能够使用RDF表示的对象都称为资源,包括网络上的所有信息、虚拟概念和现实事物等。资源用唯一的URI来表示,不同的资源拥有不同的URI,通常使用的URL只是它的一个子集。
(2)属性:用来描述资源的特征或资源间的关系。每一个属性都有其意义,用于定义资源的属性值(property value)、描述属性所属的资源形态、与其他属性或资源的关系。
(3)陈述:一条陈述包含三个部分,通常被称为RDF三元组<主体,属性,客体>。其中主体是被描述的资源,用URI表示。客体表示主体在该属性上的取值,可以是另外一个资源(由URI表示)或者是文本。
RDF三元组是语义网数据表示的基础。要实现从目前的万维网到语义网的转变,构建海量的RDF数据集是一项基础性工作。当用RDF描述资源时,任何人可以定义用于描述的词汇,但是这些词汇的具体含义、词汇之间的关系RDF没有定义。显然,这不便于机器处理数据,为此RDFS[15](RDF Schema)定义了一组标准类及属性的层次关系词汇,帮助用户构建轻量级的本体。换言之,RDF是领域无关的,没有定义任何领域的语义,这要由用户借助RDFS来完成。RDFS是一种模式语言,定义了特定领域的词汇的含义。RDFS的作用是:①定义资源以及属性的类别;②定义属性所应用的资源类以及属性值的类型;③定义上述类别声明的语法;④ 申明一些由其他机构或组织定义的元数据标准的属性类。RDFS描述类是通过资源rdfs:Class和rdfs:Resourc,特性rdf:type和rdfs:subClassOf来完成的。利用rdfs:subClassOf可以定义子类,形成层次结构。此外,在RDFS中对类的特性的描述是利用RDFS类rdf:Property和RDFS特性rdfs:domain(定义域)、rdfs:range(值域)和rdfs:subPropertyOf来进行声明和描述的。
3.2 Ontology
英文术语“ontology”一词源于哲学领域,且一直以来存在着许多不同的用法。在计算机科学领域,其核心意思是指一种模型,用于描述由一套对象类型(概念或者说类)、属性以及关系类型所构成的世界。尽管不同的本体对于这些构成成分的确切称谓有所不同,但它们却都是一部本体不可或缺的基本要素。一般来说,本体之中模型的那些特征应当非常类似于相应的现实世界[10]。上个世纪90年代初期,斯坦福大学计算机科学家Tom Gruber对于计算机科学术语“ontology”给出了审慎的定义:一种对于某一概念体系(概念表达或概念化过程)(conceptualization)的明确表述(specification)[9]。对于特定一个领域而言,本体表达的是其那套术语、实体、对象、类、属性及其之间的关系,提供的是形式化的定义和公理,用来约束对于这些术语的解释。值得一提的是Gruber便是时下iphone上流行的“Siri智能个人助理”(Siri intelligent personal assistant)的发明者,这项语音识别功能甚至一度成为iphone的卖点。
在语义网的实现中,ontology具有非常重要的地位。怎样构建本体一直是人们研究的热点。各国科研人员研发出了不少本体的构建、存储、和检索工具,其中较为常用的支持中文本体构建的软件是由斯坦福大学开发的Protégé,开发语言采用Java,属于开放源码软件[11-12]。本体的构建大多是面向特定的领域的,因此如果没有规范的方法,就难以在不同领域的本体构建中保持一致。也正因为本体是领域相关的,所以难以制定一个标准的、通用的ontology构建方法。在此背景下,本体工程学应运而生。本体工程研究的内容包括面向领域的本体开发过程、本体生命周期、本体构建方法及方法学,以及为这些方面提供支持的工具包和语言。
本体一般都是采用本体语言来编制的。本体语言是一种用于编制本体的形式化语言。目前已经诞生了不少本体描述语言,既包括专有的,也包括基于标准的。在众多本体语言中,网络本体语言(Web Ontology Language,OWL)是极为耀眼的一颗明星。OWL[16]旨在提供一种可用于描述网络文档和应用之中所固有的那些类及其之间关系的语言。OWL网络本体语言于2004 年2月成为一项 W3C 的推荐标准,它是万维网联盟认可的,用于编纂本体的知识表达语言家族。
为了适应不同的表达能力和计算效率的需要,OWL提供了3种表达能力递增、计算效率递减的子语言:OWL Lite、OWL DL、OWL Full。其中,OWL Lite用于提供给那些只需要一个分类层次和简单约束的用户。OWL Lite是OWL DL的一个子集,且仅支持部分的OWL语言要素。OWL DL包括了OWL Lite语言的所有成分,但有一定的约束:如一个类不能同时是一个个体或者属性,一个属性不能同时是一个个体或者类等。OWL DL适合于那些在拥有计算保证的前提下追求强大表达能力的用户使用。它的缺点是失去了与RDF的完全兼容。OWL Full是OWL语言的全集,包含所有的OWL语言要素并拥有与RDF一样的句法自由,它是面向那些需要RDF的最大限度表达能力的用户。OWL Full允许引入本体来扩展预定义的RDF/OWL词汇的含义。选择OWL DL还是OWL Full关键取决于用户在多大程度上需要RDF的元模型机制。同OWL DL相比,OWL Full对推理的支持难以预测[4]。
OWL弥补了RDFS的不足,运用人工智能(Artificial intelligence,AI)中的逻辑来赋予语义,支持多种形式的推理。在表达概念的语义灵活性、Web内容的机器可理解性等方面OWL比早前的XML、RDF、RDF-S等语言都要强。在RDFS/OWL之上,W3C还定义了规则互换格式(rule interchange format,RIF)和SWRL(Semantic Web Rule Language)来辅助推理。其中RIF支持在不同的规则格式里互操作[13]。
四、面临挑战
Tim Berners-Lee在《Weaving the Web》一文中说道“如果说 HTML 和 WEB 将整个在线文档变成了一本巨大的书,那么 RDF, schema, 和 inference languages 将会使世界上所有的数据变成一个巨大的数据库”[14]。语义网的愿景虽然很好,但是由于语义Web尚面临诸多问题和挑战,使得其迟迟没有得到大规模应用。语义网面临的主要挑战可以归结为三类,即数据问题、智能问题和安全问题。
(1)数据问题。在语义网中为了实现让计算机或其它设备能够自动识别、处理Web上的数据,需要在网页内容中加入标记,即采用标记语言。考虑到适应不同领域的需要,标记语言必须具备扩展性强的特点。虽然W3C定义了RDF、RDFS、OWL等语义网规范,但同时互联网上的绝大多数内容尚未加上符合语义网规范的标记。因此,如何自动化地给现有的Web内容加上符合语义Web规范的标记是语义网走向实用化面临的难题之一。这涉及到一系列技术:信息抽取、分类、表达、存储、查询等[18-20]。
(2)智能问题。如何让计算机或其它设备进行“思考”和“推断”是另一个技术难题,这涉及到本体、逻辑和规则等方面。对于本体来说,尽管一些概念比较持久,但是实际上它们并不是始终保持不变[4,17],必须把本体当成是可以演变的。如何将变化前后的本体对应起来、如何解决变化的本体可能导致知识库的不一致等都是当前面临的挑战。另外,描述逻辑语言在表达能力上存在一定的不足,某些应用可能要研究表达能力更强的描述逻辑。
(3)安全问题。未来,人们借助语义网技术所构建的数据互联网络能够迅速、准确地找到实体几乎全部的信息。无论是物理实体(如人、组织等),还是抽象实体(如概念),如果不处理好安全问题,一旦某些实体的信息,如个人私密信息、机构涉密信息落入不法之徒手里将可能导致严重的后果。因此,研究人员需要开发一些技术或机制来增强语义网的安全性。
五、结语
语义学的引入将从根本上改变万维网的性质,语义网是未来网络的发展方向,但是它的实现是一个漫长的过程,能否成功,没有人知道,但总有人去尝试。有研究人员以W3C提出的RDF数据模型为基础,借鉴和利用了当前数据库和图论的研究成果,在语义网数据的模型表示、存储结构、查询和索引等方面取得了长足的进展。本文从语义网概念入手,介绍了其相关技术、规范及面临挑战。未来还有许多研究工作需要深入下去,包括中文本体的构建方法、本体构建工具、海量RDF数据集的管理等等。
参考文献:
[1] 田春虎.国内语义Web研究综述 [J].情报学报,2005,24(2): 243-249.
[2] Berners-Lee T, Hendler J, Lassila O. The semantic web [J]. Scient -ific American,2001,284(5):34-43.
[3] T.Berners-Lee,James Hendler.Publishing on the semantic web[J].Na -ture, 2001 Apr 26,410(6832):1023-1024.
[4] 金海,袁平鹏.语义网数据管理技术及应用 [M].北京:科学出版社,2010.
[5] Berners-Lee.Semanticweb-XML2000[EB/OL].[2014-01-20].http://www.w3. org/2000/Talks/1206-xml2k-tbl/Overview.html.
[6] Signore O.Representing knowledge in the semantic web.Open Cultur- e: Accessing and Sharing Knowledge,2005.
[7] RDF Current Status.http://www.w3.org/standards/techs/rdf#w3c_all.
[8] 邹磊,陈跃国.海量RDF数据管理 [J].中国计算机学会通讯,2012,8(11): 33-39.
[9] http://zh.wikipedia.org/wiki/本体_(信息科学).
[10] Antoniou G, Harmelen F. A Semantic Web Primer [M]. Cambridge:
The MIT Press, 2008.
[11] 胡伟,瞿裕忠,黄智生.语义Web课程建设初探 [J].计算机教育,2013,
12:69-72.
[12] 凌绍东, 霍林, 王超.面向语义网的中文本体应用研究[J/OL]. 计算机技 术与发展, 2014 (02).http://www.cnki.net/kcms/detail/61.1450.TP. 20131129.0857.012.html
[13] 李洁,丁颖.语义网关键技术概述 [J].计算机工程与设计,2007,28(8):
1831-1836.
[14] T.Berners-Lee,Weaving the Web,The Original Design and Ultimate Destiny of the World Wide Web by Its Inventor. Harper Collins publishers Inc ,1999.
[15] Brickley D,Guha R V.RDF vocabulary description language 1.0:RDF schema[EB/OL].W3C,2004[2014-01-20].http://www.w3.org/TR/rdf-sche ma/.
[16] McGuinness D L,Harmelen F V.OWL web ontology language overview
[EB/OL].W3C,2004[2014-01-20].http://www.w3.org/TR/owl-features/.
[17] 李曼,杜小勇,王珊.语义Web环境中本体库管理系统体系结构研究 [J]. 计算机研究与发展,2006,43(Suppl.):39-45.
[18] 杜方,陈跃国,杜小勇.RDF数据查询处理技术综述 [J].软件学报,2013,
24(6):1223-1240.
[19] 吴鸿汉,瞿裕忠.RDF数据浏览的研究综述 [J].计算机科学,2009,36(2):
5-10.
[20] 张剑.国外语义网发展概述 [J].图书情报工作,2005,49(6):62-64.
————————————————
版权声明:本文为CSDN博主「程猿薇茑」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/hellozpc/article/details/21827045


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
2019-03-07 github之克隆
2019-03-07 ubuntu卸载软件
2019-03-07 linux下安装boost
2019-03-07 cmd(或者说DOS窗口)输出内容到文件