

精确率和召回率和F_score
2022.8.31更新:
Content
ConfusionMatrix
Example
Talbe ofconfusion
Preference
Confusion Matrix
在机器学习领域,混淆矩阵(confusion matrix),又称为可能性表格或是错误矩阵。它是一种特定的矩阵用来呈现算法性能的可视化效果,通常是监督学习(非监督学习,通常用匹配矩阵:matching matrix)。其每一列代表预测值,每一行代表的是实际的类别。这个名字来源于它可以非常容易的表明多个类别是否有混淆(也就是一个class被预测成另一个class)。
Example
假设有一个用来对猫(cats)、狗(dogs)、兔子(rabbits)进行分类的系统,混淆矩阵就是为了进一步分析性能而对该算法测试结果做出的总结。假设总共有 27 只动物:8只猫, 6条狗, 13只兔子。结果的混淆矩阵如下图:
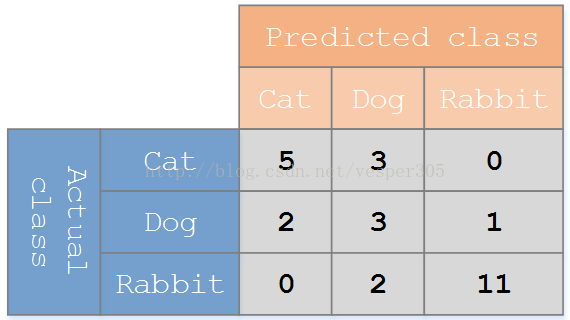
在这个混淆矩阵中,实际有 8只猫,但是系统将其中3只预测成了狗;对于 6条狗,其中有 1条被预测成了兔子,2条被预测成了猫。从混淆矩阵中我们可以看出系统对于区分猫和狗存在一些问题,但是区分兔子和其他动物的效果还是不错的。所有正确的预测结果都在对角线上,所以从混淆矩阵中可以很方便直观的看出哪里有错误,因为他们呈现在对角线外面。
注:
1.准确率和召回率的分子都在混淆矩阵的对角线上。
2.准确率和召回率的分母都是不变的。
3.召回率随着预测样本数的增加会接近于1。
Table of confusion
在预测分析中,混淆表格(有时候也称为混淆矩阵),是由false positives,falsenegatives,true positives和true negatives组成的两行两列的表格。它允许我们做出更多的分析,而不仅仅是局限在正确率。准确率对于分类器的性能分析来说,并不是一个很好地衡量指标,因为如果数据集不平衡(每一类的数据样本数量相差太大),很可能会出现误导性的结果。例如,如果在一个数据集中有95只猫,但是只有5条狗,那么某些分类器很可能偏向于将所有的样本预测成猫。整体准确率为95%,但是实际上该分类器对猫的识别率是100%,而对狗的识别率是0%。
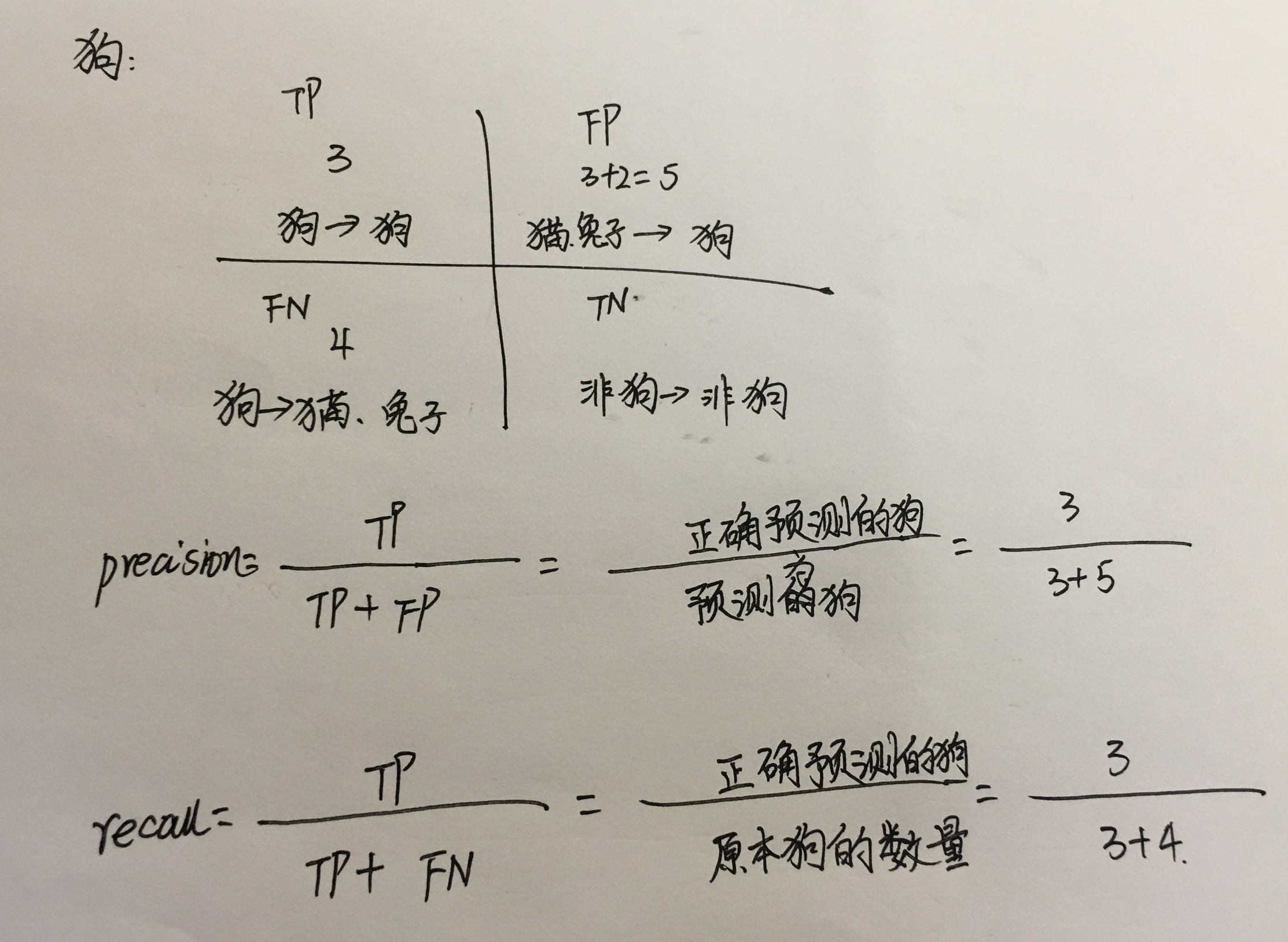
对于上面的混淆矩阵,其对应的对猫这个类别的混淆表格如下:



(39条消息) YOLOv5实战中国交通标志识别-1-课程介绍-白老师的在线视频教程-CSDN程序员研修院
precision随着预测的增加出现上下波动。
假定一个实验有 P个positive实例,在某些条件下有 N 个negative实例。那么上面这四个输出可以用下面的偶然性表格(或混淆矩阵)来表示:
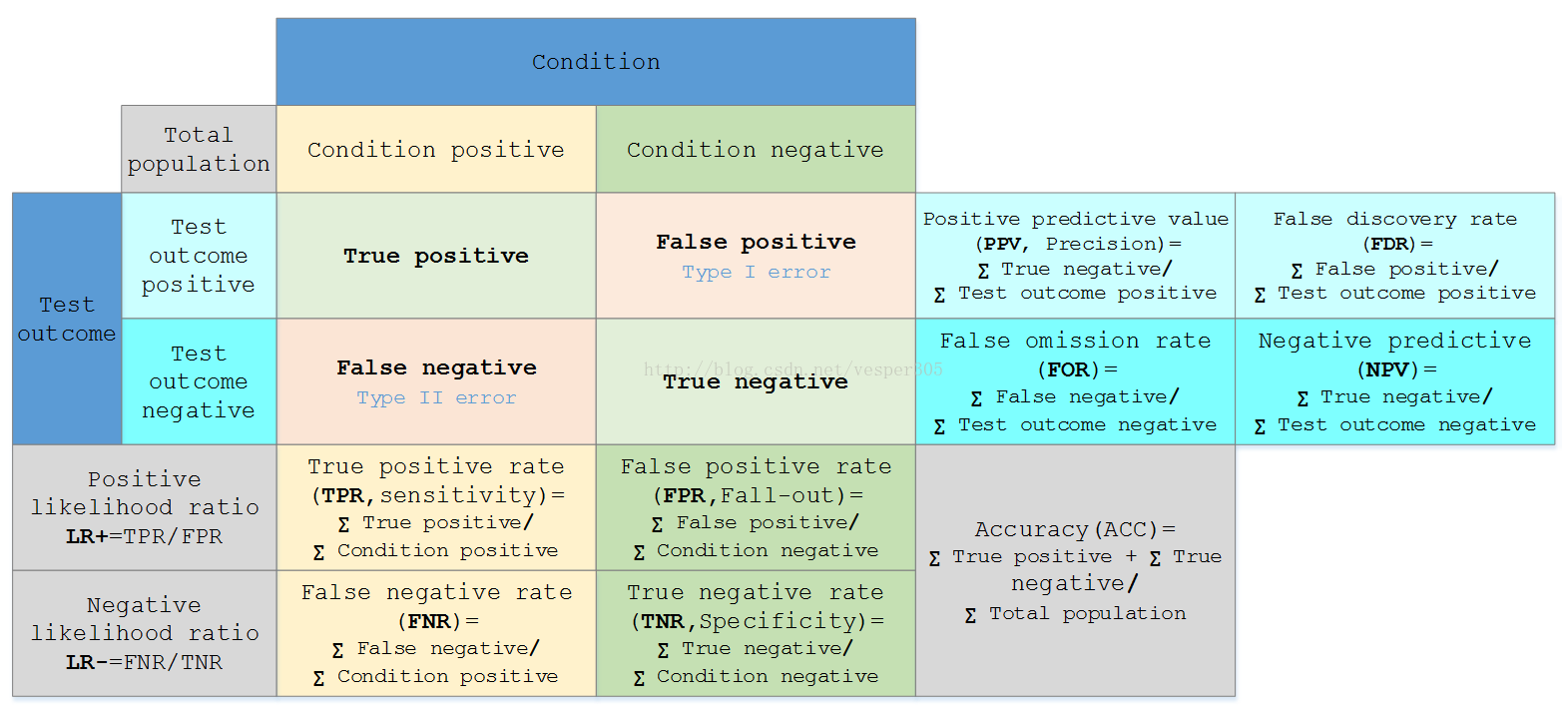
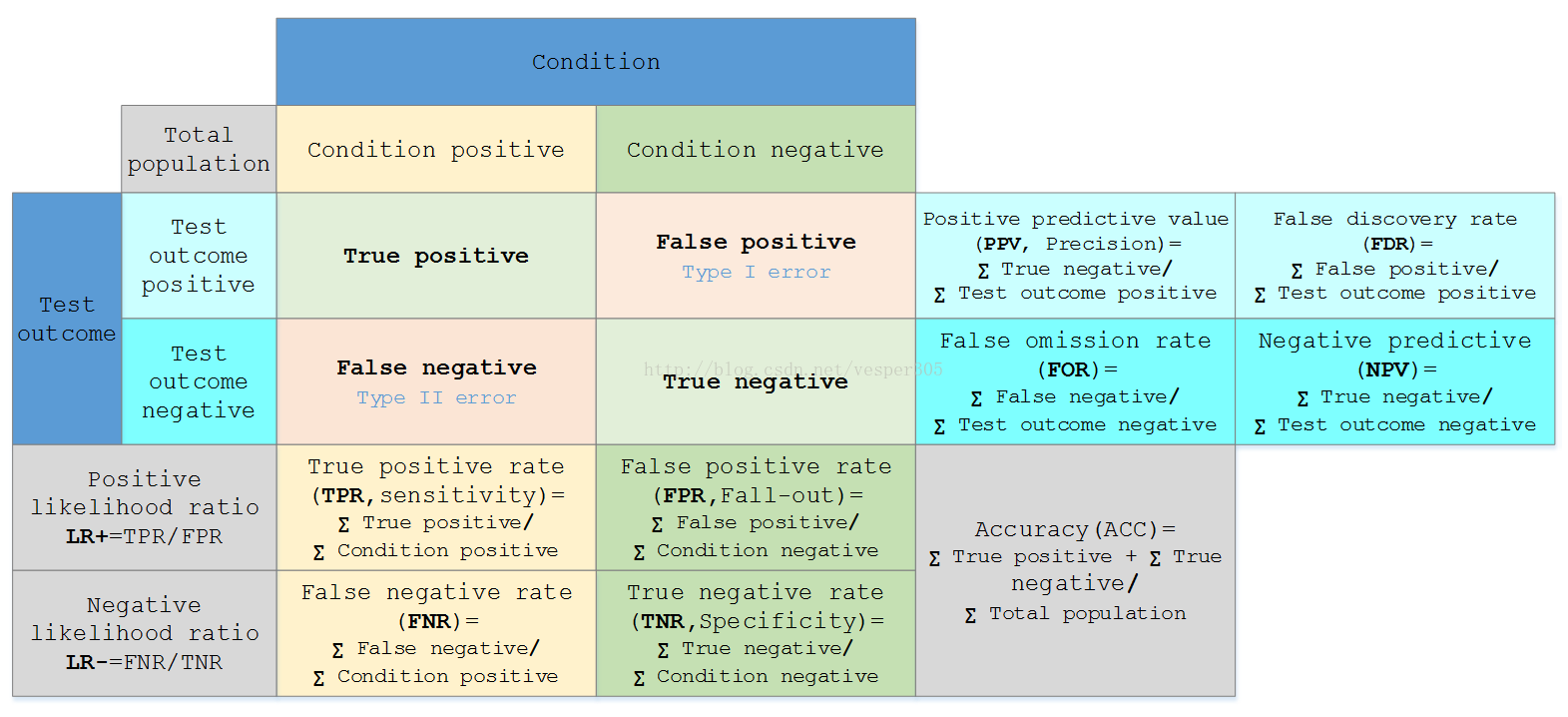
公式陈列、定义如下:
|
True positive(TP) |
eqv. with hit |
|
True negative(TN) |
eqv. with correct rejection |
|
False positive(FP) |
eqv. with false alarm, Type I error |
|
False negative(FN) |
eqv. with miss, Type II error |
|
Sensitivity ortrue positive rate(TPR) eqv. with hit rate, recall |
TPR = TP/P = TP/(TP + FN) |
|
Specificity(SPC)ortrue negative rate(TNR) |
SPC = TN/N = TN/(FP + TN) |
|
Precision orpositive prediction value(PPV) |
PPV = TP/(TP + FP) |
|
Negative predictive value(NPV) |
NPV = TN/(TN + FN) |
|
Fall-out orfalse positive rate(FPR) |
FPR = FP/N = FP/(FP + TN) |
|
False discovery rate(FDR) |
FDR = FP/(FP + TP) = 1 - PPV |
|
Miss Rate orFalse Negative Rate(FNR) |
FNR = FN/P = FN/(FN + TP) |
|
|
|
|
Accuracy(ACC) |
ACC = (TP + TN)/(P + N) |
Preference
WiKi:http://en.wikipedia.org/wiki/Confusion_matrix
精确率=270/300
通俗解释机器学习中的召回率、精确率、准确率,一文让你一辈子忘不掉这两个词(https://zhuanlan.zhihu.com/p/93586831)
赶时间的同学们看这里:提升精确率是为了不错报、提升召回率是为了不漏报
先说个题外话,暴击一下乱写博客的人,网络上很多地方分不清准确率和精确率,在这里先正确区分一下精确率和准确率,以及他们的别称

精确率:预测的正类中真正的正类所占的比例。
召回率:原集合中的正类中被准确预测的比例。
切入正题
很多人分不清召回率和精确率的区别,即使记住了公式,过段时间还是会忘掉,这里我会完全讲清楚这几个率的区别
准确率很好理解,被正确预测出来的数量 / 所有的样本,这里不在赘述,主要讲解精确率和召回率
精确率和召回率就是分母不一样,下面以预测地震为例
请听题:你的老板让你做一个地震预测模型(以天为单位记某一天地震为正样本,不地震为负样本),你需要预测接下来100天的地震情况。
假设你是拉普拉斯妖,你知道第50天和51天会地震,其余的1-49和51-100天不会地震。
现在假设你的模型已经做好,但是不能精确率和召回率二者不可得兼,摆在你面前的是提升其中的一个率,你应该怎么办?
通俗解释一下
咋一看他们只有分母不一样,但是为啥不一样呢?
精确率:分母是预测到的正类,精确率的提出是让模型的现有预测结果尽可能不出错(宁愿漏检,也不能让现有的预测有错)
以地震模型为例说就是宁愿地震了没报,也不能误报地震,比如说为了不错报,只预测了第50天可能发生地震,此时的
1.精确率:1/1=100%
2.召回率:1/2=50%
虽然有一次地震没预测到,但是我们做出的预测都是对的。
召回率:分母是原本的正类,召回率的提出是让模型预测到所有想被预测到的样本(就算多预测一些错的,也能接受)
以地震模型为例说这100次地震,比如说为了不漏报,预测了第30天、50天、51天、70天、85天地震,此时的
1.精确率:2/5=40%
2.召回率:2/2=100%
虽然预测错了3次,但是我们把会造成灾难的2次地震全预测到了。
应该如何取舍呢?
假设地震发生没有预测到会造成百亿级别的损失,而地震没发生误报了地震会造成百万级别的损失
显然,这种情况下我们应该接受为了不能漏掉一次地震而多次误报带来的损失,即提升召回率
精确率和召回率有什么用?为什么需要它?通俗讲解(人话)
上面我们已经讲的很清楚了,这里以两种需求为例
- 预测地震 - 不能接受漏报
- 人脸识别支付(银行人脸支付) - 不能接受误检
人脸识别支付:主要提升精确率,更倾向于不能出现错误的预测。
应用场景:你刷脸支付时就算几次没检测到你的脸,最多会让你愤怒,对银行损失不大,但是如果把你的脸检测成别人的脸,就会出现金融风险,让别人替你买单,对银行损失很大。所以宁愿让你付不了钱,也不会让别人帮你付钱。
预测地震:主要提升召回率,更倾向于宁愿多预测一些错的也不能漏检。
应用场景:地震预测时宁愿多预测一些错的,也不想漏掉一次地震,预测错误最多会让大家多跑几趟,造成少量损失。只要预测对一次,就会挽回百亿级别的损失,之前所有的损失都值了。
不同的应用场景,需要的评价标准不一样,所以才会有这些率。
链接:https://zhuanlan.zhihu.com/p/26387920
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
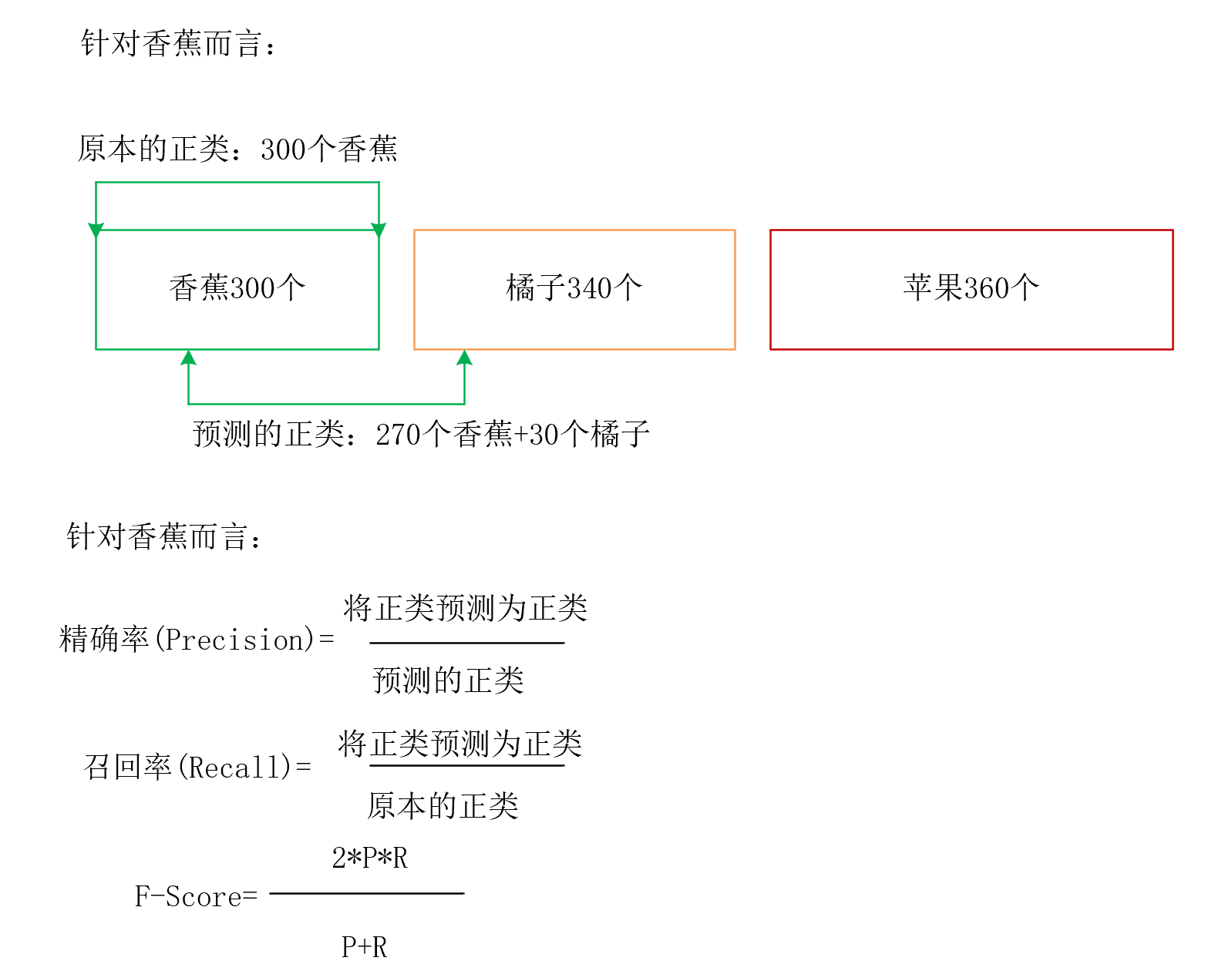
上面还是有点抽象,下面通过例子来解释一下上面说法:
准确率(P值)
假设我此时想吃香蕉,实验室里面每天都会安排10个水果,水果种类分别是6个香蕉,3个橘子,1个菠萝。哎,但是,实验室主任搞事情啊,为了提高我们吃水果的动力与趣味,告诉我们10个水果放在黑盒子中,每个人是看不到自己拿的什么,每次拿5个出来,哎,我去抽了,抽出了2个香蕉,2个橘子,1个菠萝。
下面我们来分别求求P值,R值,F值,哈哈!
按照一开始说的,精确率是针对我们预测结果而言的,它表示的是预测为正的样本中有多少是真正的正样本。
这里我们的正样本就是我想吃的香蕉!
在预测结果中,有2个香蕉,总个数是我拿的5个,那么P值计算如下:
召回率(R值)
按照开始总结所说。
召回率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确了。
我们这里的正类是我想吃的香蕉,而在样本中的香蕉个数是6个,召回率的召回也可以这么理解,代表了,原始样本中正类召回了多少。R值计算如下:
分母已经变成了样本中香蕉的个数啦
F值
可能很多人就会问了,有了召回率和准去率这俩个评价指标后,不就非常好了,为什么要有F值这个评价量的存在呢?
按照高中语文老师所说的,存在即合理的说法,既然F值存在了,那么一定有它存在的必要性,哈哈哈哈!
我们在评价的时候,当然是希望检索结果Precision越高越好,同时Recall也越高越好,但事实上这两者在某些情况下有矛盾的。
比如极端情况下,在我们这个例子中,我们只搜索出了一个结果,且是香蕉,那么Precision就是100%,但是Recall为1/6就很低;而如果我们抽取10个水果,那么比如Recall是100%,但是Precision为6/10,相对来说就会比较低。
因此P和R指标有时候会出现的矛盾的情况,这样就需要综合考虑他们,最常见的方法就是F-Measure,通过计算F值来评价一个指标!
我这里给出最常见的F1计算方法,如下:
F1 = (2*P*R)/(P+R)
F那么在我们这个例子中F1 = (2*2/5*2/6)/(2/5+2/6)(这里我就不算出来了,有这个形式,更加能体现公式特点!)
现在再回过头看 accuracy 的定义,你会发现 accuracy 相比于上面的 recall 和 precision 是一种更加全局化的衡量标准,于此同时,带来的问题是这种衡量标准比较粗糙。
F1 Score
假如我想同时控制风险 ( recall ) 和成本 ( precision )怎么办?那就用 F1 Score 。
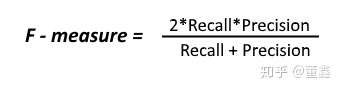
作者:董鑫
链接:https://www.zhihu.com/question/30643044/answer/1205433761
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
4、综合评价指标(F-Measure)
P和R指标有时候会出现的矛盾的情况,这样就需要综合考虑他们,最常见的方法就是F-Measure(又称为F-Score)。
F-Measure是Precision和Recall加权调和平均:
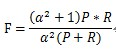
当参数α=1时,就是最常见的F1,也即
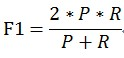
可知F1综合了P和R的结果,当F1较高时则能说明试验方法比较有效。
作者:沉淀星星
链接:https://zhuanlan.zhihu.com/p/337119937
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
FN:False Negative,被错误的判定为负样本。
FP:False Positive,被错误的判定为正样本。
TN:True Negative,被正确判定为负样本。
TP:True Positive,被正确的判定为正样本。
刚开始接触这两个概念的时候总搞混,时间一长就记不清了。
实际上非常简单,精确率是针对我们预测结果而言的,它表示的是预测为正的样本中有多少是真正的正样本。那么预测为正就有两种可能了,一种就是把正类预测为正类(TP),另一种就是把负类预测为正类(FP),也就是其实就是分母不同,一个分母是预测为正的样本数,另一个是原来样本中所有的正样本数。
而召回率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确了。那也有两种可能,一种是把原来的正类预测成正类(TP),另一种就是把原来的正类预测为负类(FN)。
作者:Charles Xiao
链接:https://www.zhihu.com/question/19645541/answer/91694636
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
FN:False Negative,被判定为负样本,但事实上是正样本。
FP:False Positive,被判定为正样本,但事实上是负样本。
TN:True Negative,被判定为负样本,事实上也是负样本。
TP:True Positive,被判定为正样本,事实上也是证样本。
那么有:
准确率:precesion = TP/(TP+FP) 即,检索结果中,都是你认为应该为正的样本(第二个字母都是P),但是其中有你判断正确的和判断错误的(第一个字母有T ,F)。
ee
召回率:recall = TP/(TP+FN)即,检索结果中,你判断为正的样本也确实为正的,以及那些没在检索结果中被你判断为负但是事实上是正的(FN)。
https://www.bilibili.com/video/BV184411Q7Ng?p=25


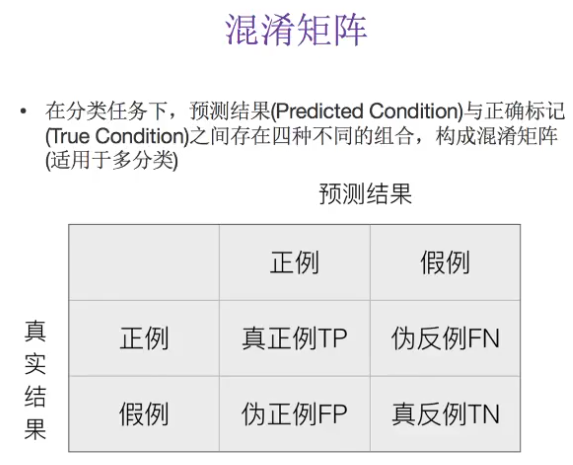

注解:
- 猫:猫----真正例 猫预测为猫
- 猫:不是猫----伪反例
- 不是猫:猫----伪正例
- 不是猫:不是猫----真反例
- 猫有一个混淆矩阵,每一个类别都有一个混淆矩阵,有多少类别就有多少个混淆矩阵。

注解:
- 评估标准除了准确率之外,还需要精确率和召回率。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理