

P5 字典特征数据抽取
https://www.bilibili.com/video/BV184411Q7Ng?p=5

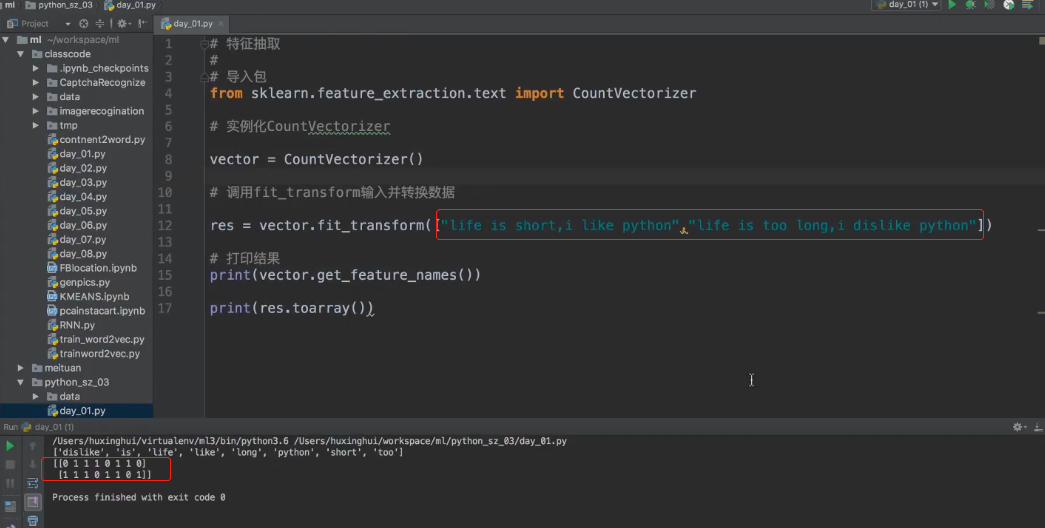
注解:
- 把一句英文转变成了一个二维数组。

注解:
- 计算机理解不了英文文章,只能理解数据。




特征抽取的示例代码:

""" 演示字典的特征抽取, DictVectorizer是一个类的名字 """ from sklearn.feature_extraction import DictVectorizer def dictvec(): """ 字典数据抽取 :return: 加入参数sparse=False可以把转换成的数据转换成数组 """ dict=DictVectorizer(sparse=False) #实例化 sparse=False data=dict.fit_transform([{'city':'北京','temperature':100},{'city':'上海','temperature':60},{'city':'深圳','temperature':30}]) # 调用fit_transform就是把字符串数据转化成特征,返回的是个data print(data) #print(dict.get_feature_names()) return None if __name__=="__main__": dictvec()
上面的字典数据特征抽取的结果:

注解:
- 上面的结果是没有加参数dict=DictVectorizer()。
- 下面的结果是加了参数的结果,dict=DictVectorizer(sparse=False)
- (1,3) 60.0意思是:第2行第4列的数据是60.0
""" 演示字典的特征抽取, DictVectorizer是一个类的名字 """ from sklearn.feature_extraction import DictVectorizer def dictvec(): """ 字典数据抽取 :return: 加入参数sparse=False可以把转换成的数据转换成数组 """ dict=DictVectorizer(sparse=False) #实例化 sparse=False data=dict.fit_transform([{'city':'北京','temperature':100},{'city':'上海','temperature':60},{'city':'深圳','temperature':30}]) # 调用fit_transform就是把字符串数据转化成特征,返回的是个data #print(data) print(dict.get_feature_names()) return None if __name__=="__main__": dictvec()
运行结果:
C:\Users\TJ\AppData\Local\Programs\Python\Python37\python.exe D:/qcc/python/mnist/feature_abstract.py
['city=上海', 'city=北京', 'city=深圳', 'temperature']
Process finished with exit code 0

['city=上海', 'city=北京', 'city=深圳', 'temperature']



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
2019-12-30 ultraedit字体设置
2019-12-30 伤秦姝行