

P36 过拟合与欠拟合
http://bilibili.com/video/BV184411Q7Ng?p=36
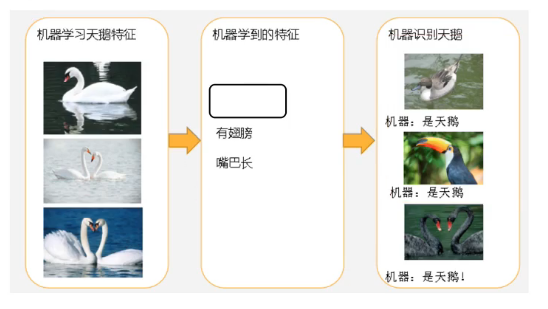
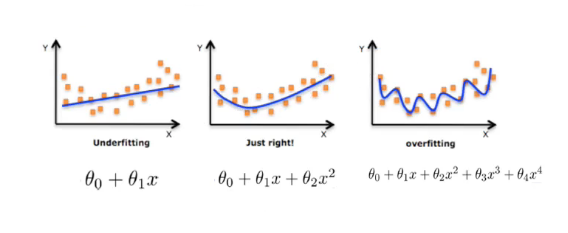
图1(欠拟合,习得的特征太少了)
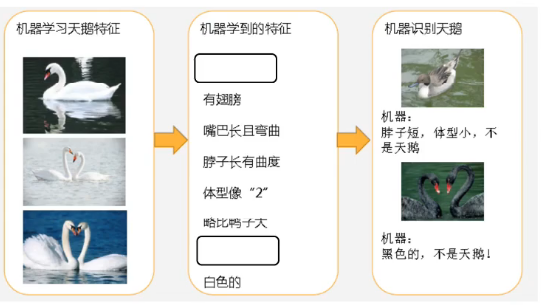
图2(过拟合,习得的特征太多了)


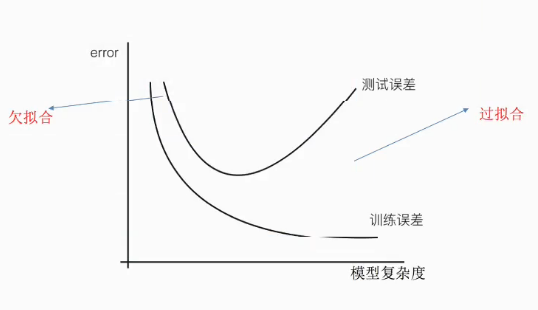
注解:
- 欠拟合的特点是训练和测试误差都大。
- 过拟合的特点是训练误差小,测试误差大。






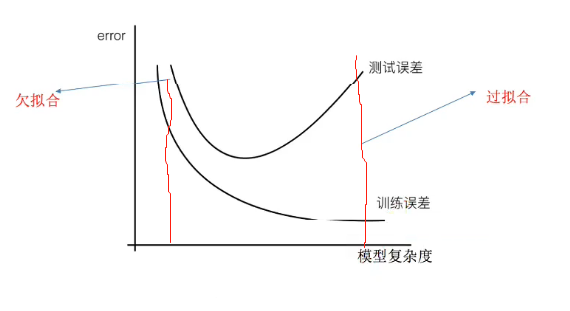
注解:
- 2.0和10.0代表的是均方误差,即过拟合的特点是训练集正确率很高,测试集正确率不高。
- 交叉验证不能解决过拟合,只能检测过拟合。
交叉验证的解释:
http://jianshu.com/p/a2f26022a21d
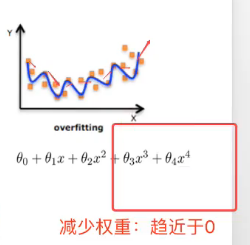
在随机梯度下降的过程中,更新导致曲线波动大的高次幂前面的权重,让其趋近于0,这就是正则化,这就是使用正则化的方法解决函数过拟合。






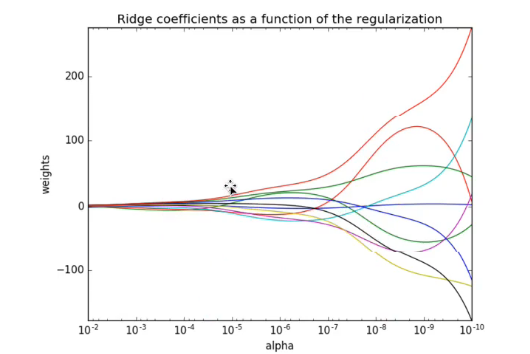
注解:
- 可以看到正则化力度大的时候,权重明显是变小了。
- L2正则化使得高次幂项的权重不断趋近于,但是不会等于0.
分类:
7天学会机器学习与深度学习


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
2019-12-23 ubuntu16.04卡死的解决办法