第六章 导学 深度前馈神经网络【重要】
http://bilibili.com/video/BV1kE4119726?p=9
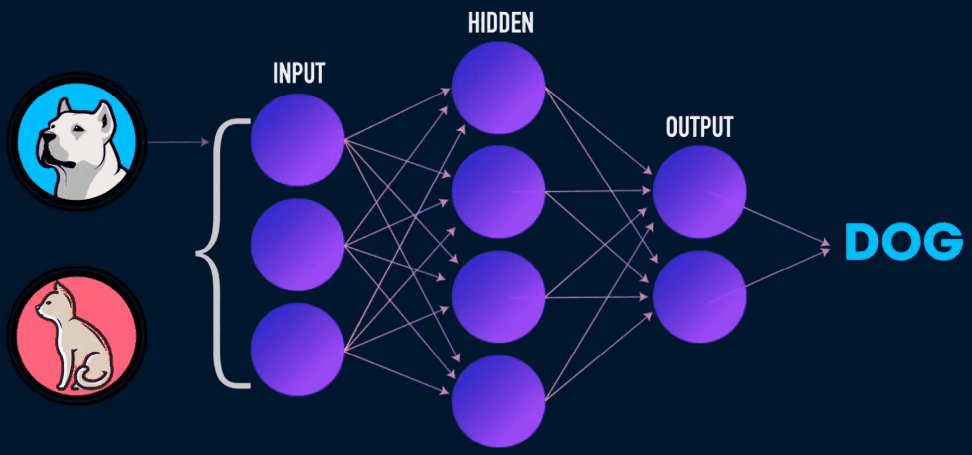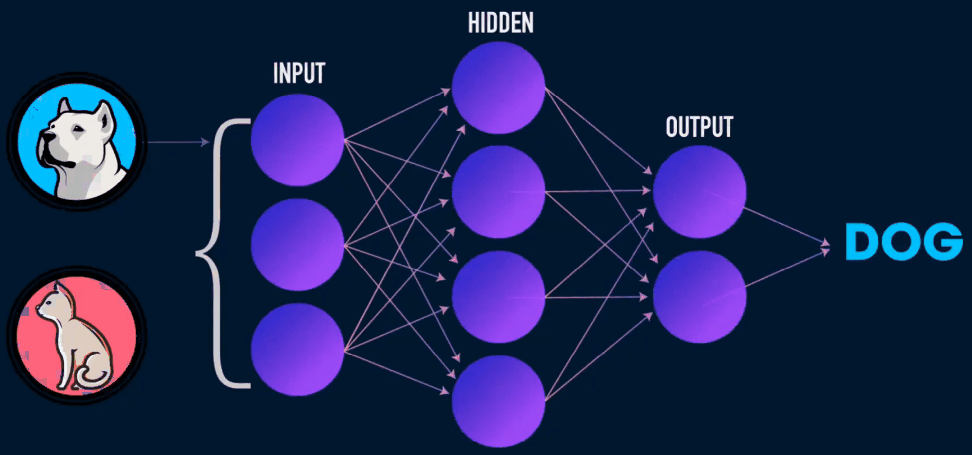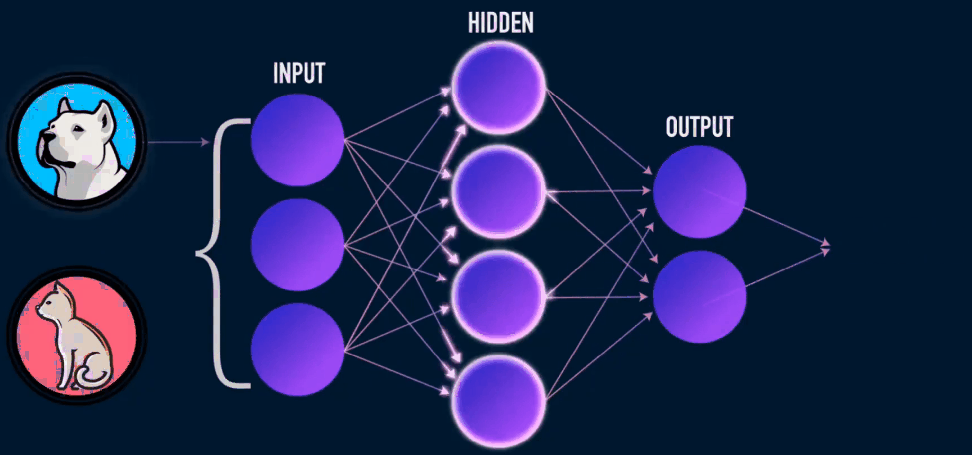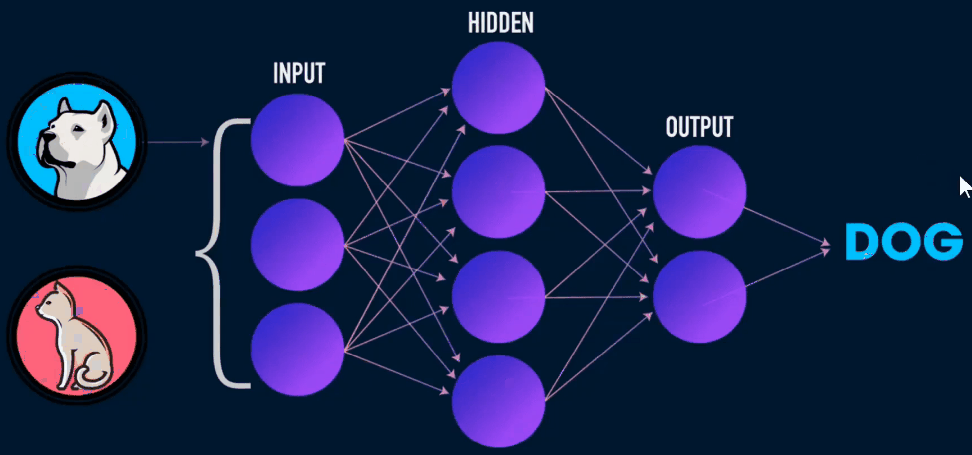
深度学习指用深度神经网络来解决机器学习问题。

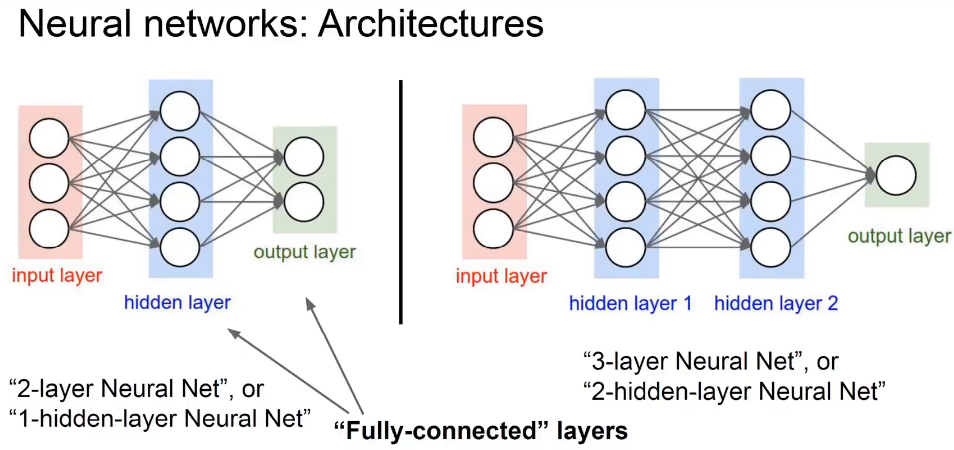
- 正是因为激活函数的存在,才能使得神经网络能够解决非线性问题。把很多个神经元一层一层的堆叠起来,就构成了前馈神经网络,也叫多层感知器、多层感知机、全连接神经网络。
- 通过计算图的方式构建模型,通过 反向传播求得损失函数相对于每一个权重的偏导数,就能知道每一个偏导数应该如何变化才能使得损失函数取最小值。
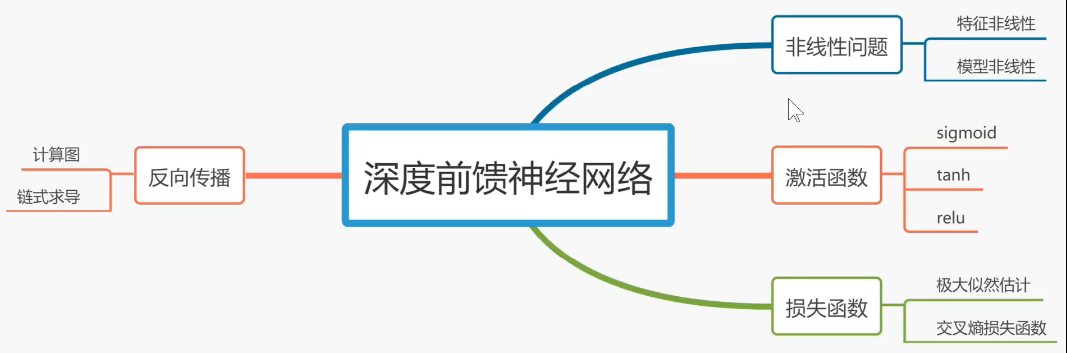
sigmoid----挤压函数
tanh----双曲正切激活函数
relu----修正线性单元激活函数
深度学习里面最常用的三种激活函数
损失函数的意义是:损失函数对每一个权重求偏导数,从而知道怎样对权重进行优化更新,即要变大还是变小。
面试题目:用numpy和sigmoid函数写一个逻辑回归,实现前向和反向传播。
面试题目:写一个包含一个隐含层的神经网络,用Python实现反向传播。

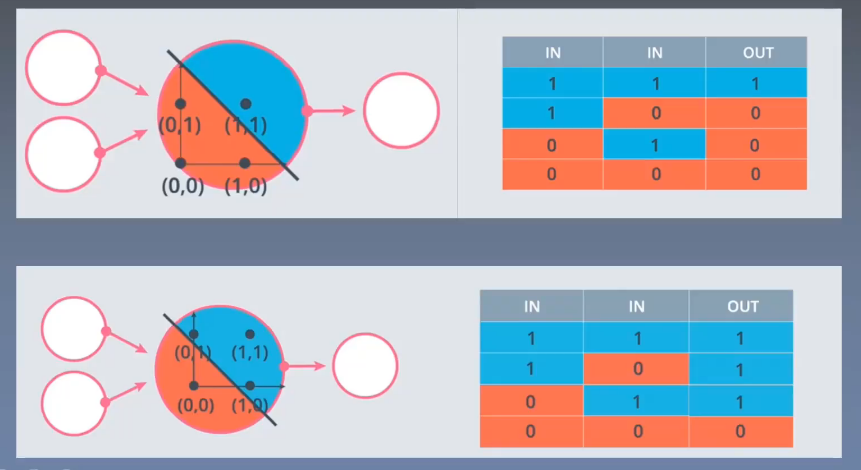
右上:且
右下:或
左上:用一根直线就能分开1,0,0,0, 这个就是线性模型问题。
左下:用一根直线就能分开1,1,1,0, 这个就是线性模型问题。
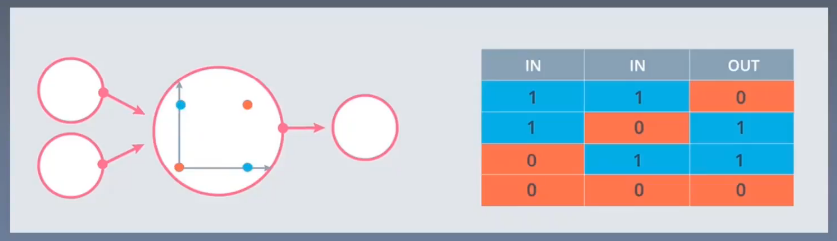
异或问题无法用一根直线解决,如上图,无法用一根直线分开红点和蓝点,除非筷子会拐弯,而神经网络能够通过一些列的操作解决这样的非线性问题。
如何用非线性模型或者思路解决问题:
1. 在样本的特征方面增加非线性的特征,让特征之间相乘。
2. 也可以在模型层面引入非线性特征,如引入非线性激活函数。

激活函数有以下几种:
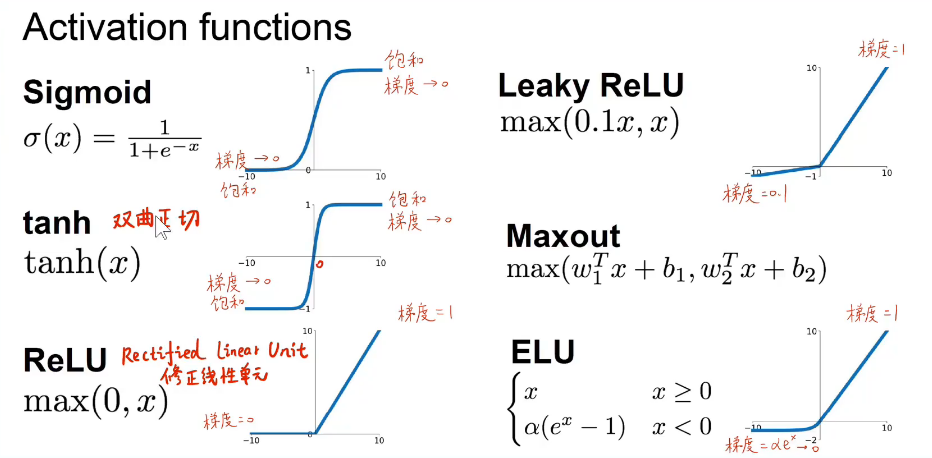
leaky relu和eLu让relu在自变量小于0的时候也有一定的梯度。
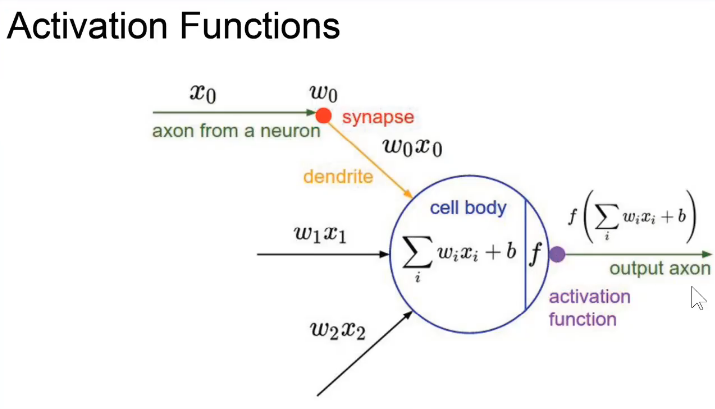
f就是非线性的激活函数。

小于0.5的值归类为一类,大于0.5的值被归类为另一类,经常应用于二分类问题。
自变量过小或者过大都会导致梯度消失。
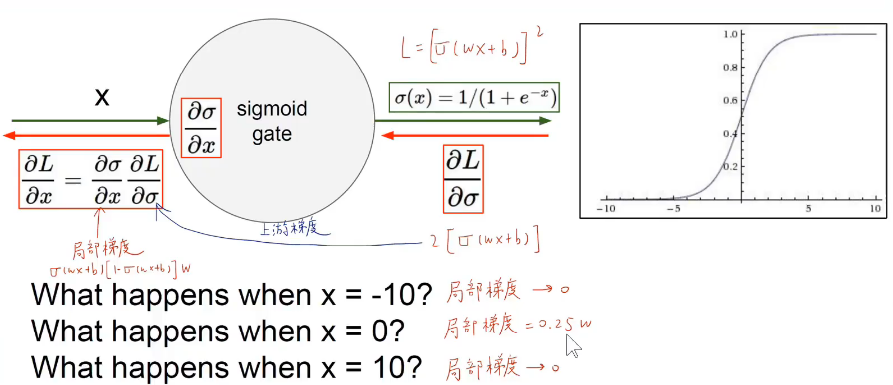
0.25w层层求导下来,会出现梯度消失的现象,这会给优化带来困难。

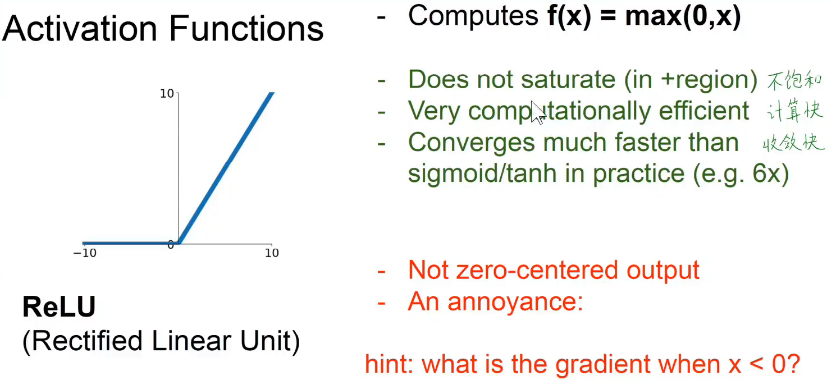
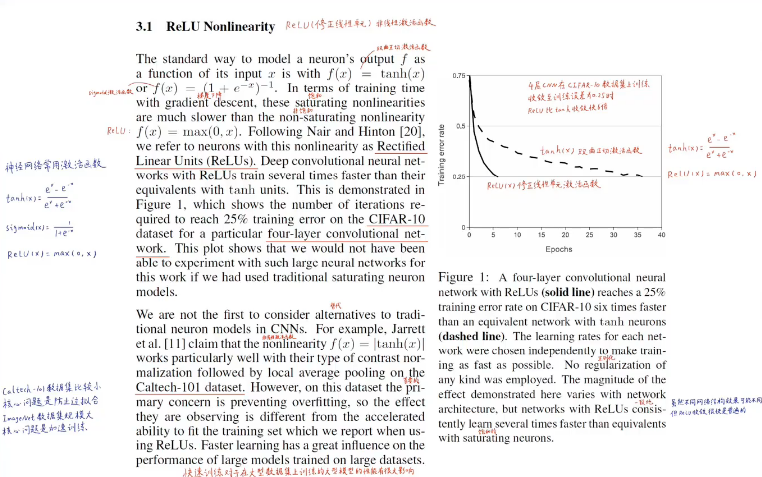
- 使用relu激活函数,其收敛速度是使用双曲正切函数的6倍。截图是alexnet(imagenet竞赛2012年的冠军)的论文截图。
relu函数的一个问题是,x小于0的时候梯度为0,无法继续训练。


x小于0的时候的斜率是可以自己选的,是一个超参数。