

Python中Pickle模块的dump()方法和load()方法
在机器学习中,我们常常需要把训练好的模型存储起来,这样在进行决策时直接将模型读出,而不需要重新训练模型,这样就大大节约了时间。Python提供的pickle模块就很好地解决了这个问题,它可以序列化对象并保存到磁盘中,并在需要的时候读取出来,任何对象都可以执行序列化操作。
Pickle模块中最常用的函数为:
(1)pickle.dump(obj, file, [,protocol])
函数的功能:将obj对象序列化存入已经打开的file中。
参数讲解:
obj:想要序列化的obj对象。
file:文件名称。
protocol:序列化使用的协议。如果该项省略,则默认为0。如果为负值或HIGHEST_PROTOCOL,则使用最高的协议版本。
(2)pickle.load(file)
函数的功能:将file中的对象序列化读出。
参数讲解:
file:文件名称。
(3)pickle.dumps(obj[, protocol])
函数的功能:将obj对象序列化为string形式,而不是存入文件中。
参数讲解:
obj:想要序列化的obj对象。
protocal:如果该项省略,则默认为0。如果为负值或HIGHEST_PROTOCOL,则使用最高的协议版本。
(4)pickle.loads(string)
函数的功能:从string中读出序列化前的obj对象。
参数讲解:
string:文件名称。
【注】 dump() 与 load() 相比 dumps() 和 loads() 还有另一种能力:dump()函数能一个接着一个地将几个对象序列化存储到同一个文件中,随后调用load()来以同样的顺序反序列化读出这些对象。
【代码示例】
pickleExample.py

#coding:utf-8 __author__ = 'MsLili' #pickle模块主要函数的应用举例 import pickle dataList = [[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']] dataDic = { 0: [1, 2, 3, 4], 1: ('a', 'b'), 2: {'c':'yes','d':'no'}} #使用dump()将数据序列化到文件中 fw = open('dataFile.txt','wb') # Pickle the list using the highest protocol available. pickle.dump(dataList, fw, -1) # Pickle dictionary using protocol 0. pickle.dump(dataDic, fw) fw.close() #使用load()将数据从文件中序列化读出 fr = open('dataFile.txt','rb') data1 = pickle.load(fr) print(data1) data2 = pickle.load(fr) print(data2) fr.close() #使用dumps()和loads()举例 p = pickle.dumps(dataList) print( pickle.loads(p) ) p = pickle.dumps(dataDic) print( pickle.loads(p) )
结果为:
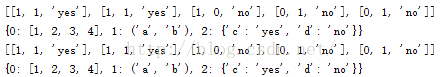
————————————————
版权声明:本文为CSDN博主「cute_Lily」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/coffee_cream/article/details/51754484


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
2019-10-10 变异系数