
mysql8中窗口函数
引用自:
https://blog.csdn.net/yeshang_lady/article/details/102728513
在以前的MySQL版本中是没有窗口函数的,直到MySQL8.0才引入了窗口函数。窗口函数是对查询中的每一条记录执行一个计算,并且这个计算结果是用与该条记录相关的多条记录得到的。
1.窗口函数与聚合函数
窗口函数与聚合函数很像,他们都是在一组记录而不是整张表上执行的。但是,一个聚合函数在一组记录执行后只返回一条结果而窗口函却会对改分组内的每行记录都返回一个结果。
2.常见的窗口函数
MySQL8.0中定义的窗口函数主要有以下几种:
函数名 参数 描述 cume_dist() 否 累计分布值。即分组值小于等于当前值的行数与分组总行数的比值。取值范围为(0,1]。 dense_rank() 否 不间断的组内排序。使用这个函数时,可以出现1,1,2,2这种形式的分组。 first_value() 是;first_value(expr) 返回分组内截止当前行的第一个值。 lag() 是;lag(expr,[N,[default]]) 从当前行开始往前取第N行,如果N缺失默认为1。若没有没有,则默认返回default。default默认值为NULL last_value() 是;last_value(expr) 返回分组内截止当前行的最后一个值。 lead() 是;lead(expr,[N,[default]]) 从当前行开始往后取第N行。函数功能与lag()相反,其余与lag()相同。 nth_value() 是;nth_value(expr,N) 返回分组内截止当前行的第N行。first_value\last_value\nth_value函数功能相似,只是返回分组内截止当前行的不同行号的数据。 ntile() 是;ntile(N) 返回当前行在分组内的分桶号。在计算时要先将改分组内的所有数据划分成N个桶,之后返回每个记录所在的分桶号。返回范围从1到N percent_rank() 否 累计百分比。该函数的计算结果为:小于该条记录值的所有记录的行数/该分组的总行数-1. 所以改记录的返回值为[0,1] rank() 否 间断的组内排序。其排序结果可能出现如下结果:1,1,3,4,4,6 row_number() 否 当前行在其分组内的序号。不管其排序结果中是否出现重复值,其排序结果都为:1,2,3,4,5 注:‘参数’列说明该函数是否可以加参数。“否”说明该函数的括号内不可以加参数。expr即可以代表字段,也可以代表在字段上的计算,比如sum(col)等。以下相同。
3. over子句
over子句可以指定如何将记录划分分区以供窗口函数处理。如果over()为空,则是将整个查询记录作为一个分组。如果over子句不为空,则其可以指定查询记录划分分组的方式以及记录在分组内部的排序方式。除此之外,over子句也可以和聚合函数一起用。如果聚合函数后出现over子句,那么这些聚合函数也就变成了窗口函数。如果没有over子句,则他们仍然是聚合函数。可以使用over子句的聚合函数主要有以下几种:
avg()、bit_and()、bit_or()、bit_xor()、count()、max()、min()、stddev_pop()、stddev()、std()、stddev_samp()、sum()、var_pop()、variance()、var_samp()
而对于前一部分中介绍的窗口函数来说,over()子句是强制必须要有的。
over子句中常见的语法形式为:
over_clause:
{OVER (window_spec) | OVER window_name}
其中:
window_spec:
[window_name] [partition_clause] [order_clause] [frame_clause]
window_name: 是指在查询语句定义的window子句。如果遇到group by、having子句order by子句,那么window子句要放到having子句和order by子句中间。其语法如下:
WINDOW window_name AS (window_spec)
[, window_name AS (window_spec)] ...
而
window_spec:
[window_name] [partition_clause] [order_clause] [frame_clause]
从语法结构可以看出来window子句其实只是把放在over()括号中的内容单独抽出来。
partition_clause:即parittion by expr子句。用来指定记录分组方式。语法中的expr不仅可以是字段本身,也可以是计算表达式。比如,记录中有个timestramp类型的字段 ts,在MySQL中,partition by ts 和partition by hour(ts)都是有效的。
order_clause: 即 order by expr desc|asc,expr desc|asc。 用来指定分组内的排序方式。
frame_clause: 用来指定当前分组中的子集划分方式。frame可以在依据当前行的位置在每个分组内移动。使用frame来计算流水流水总和(从分区开始到当前行)及滚动平均(rolling averages)。
其语法结构如下:
frame_clause:
frame_units frame_extent
frame_units:
{ROWS | RANGE}
frame_extent:
{frame_start | frame_between}
frame_between:
BETWEEN frame_start AND frame_end
frame_start, frame_end:
{ CURRENT ROW
| UNBOUNDED PRECEDING
| UNBOUNDED FOLLOWING
|expr PRECEDING
| expr FOLLOWING
}
其中:
frame_units用来指示当前行和frame的关系
ROWS: 用来定义frame的开始行和结束行(偏移量依据的是位置);RANGE: 定义frame的区间。(偏移量的基准为当前行的值)
frame_entent用来指示frame的开始行和结束行。一种是通过指定start和end(frame_start,frame_end。frame_end可以不指定,没有明确给出的话当前行默认为结束行),另一种使用between(frame_between)。frame_between的语法很简单。下面来看frame_start和frame_end。
current row:和rows一起用时,边界就是当前行。和range一起用时,边界是当前行的对等点(个人理解,这里所说的对等点应为与当前行的值相等的所有记录)。
unbounded precceding:使用它时,每个分区的第一行即为边界。
unbounded following:使用它时,每个分区的第一行即为边界。
expr preceding\expr following: 可以由expr个性化的设置向上(preceding)向下(following)的偏移量。
4.代码示例
表结构如下:
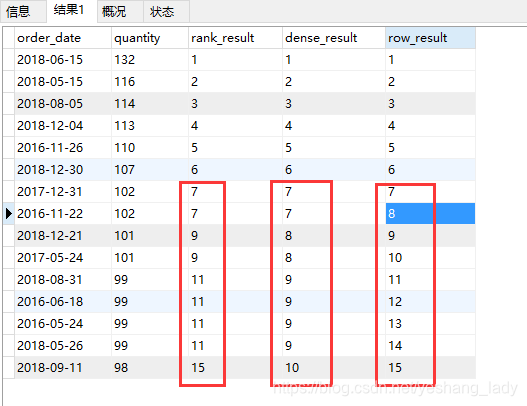
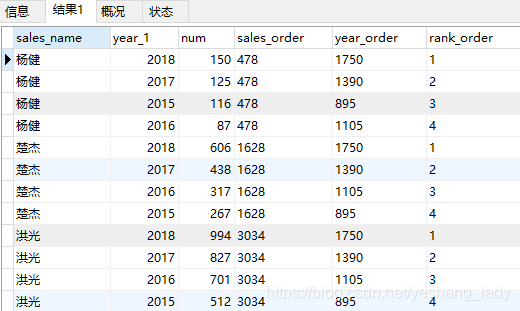
4.1 row_number\dense_rank\ rank
运行结果如下:
从上面结果看出:
- rank()函数一旦遇到重复值,序号会断。比如2个7之后下个出现的序号是9。
- dense_rank()函数中即使有重复值,但是序号是连续的。2个7之后下个出现的序号是8。
- row_number()不会出现相同的序号。
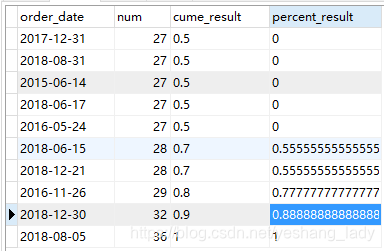
4.2 cume_dist\percent_rank
代码运行结果如下
分析如下:
- cume_dist():首先总的记录有10条。当num=27时,num小于等于27的值共有5个,所以其cume_dist()值为0.5;当num=28时,小于等于28的值共有7个,所以cume_dist()值为0.7; 以此类推。
- percent_rank().当num=27时,num小于27的记录数为0,所以percent_rank()为0;当num=28时,num<28的记录数共有5个,所以percent_rank()的值为5/9; 而当num=29时,其cume_dist()=7/9;以此类推,直到最大值36对应的值为1.
- 这两个函数的作用有点像计算中位数。
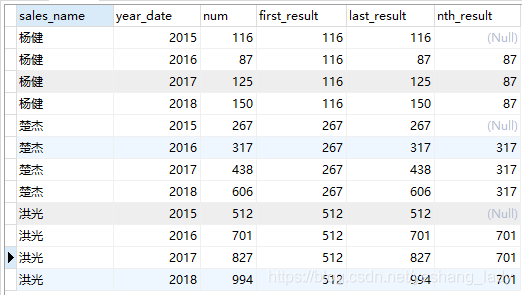
4.3 first_value\last_value\nth_value
代码运行结果如下(要注意,这三个函数计算结果都是截止当前行)
4.4 ntile()
代码运行结果如下:
从结果上进行分析:
- 首先,分桶号从1到N,都会出现;
- 其次,关于每个桶应该有多少条记录。可以假设有N个桶,m个球(球数为总记录数),标号从1到N,依次往1号桶到N号桶里投球,每次只投1个球。循环往复,直到m个球全都投入到N个桶中。最后每个桶里有多少球,现在每个桶里就有多少条记录。
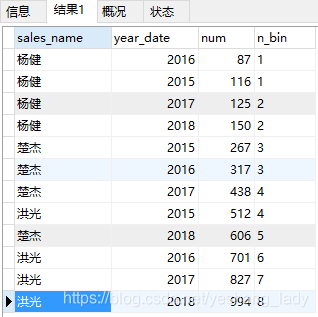
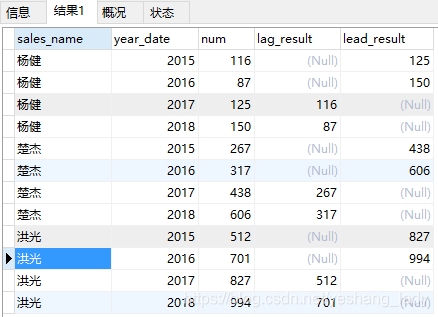
4.5 lag\lead
代码运行结果如下:
注意,lag()和lead()函数中出现的字段可以与over()子句中order by中出现的字段不一致。在代码lag(num,2)中2代表的想要取数的那一行相比当前行的偏移量(lead中也类似)。
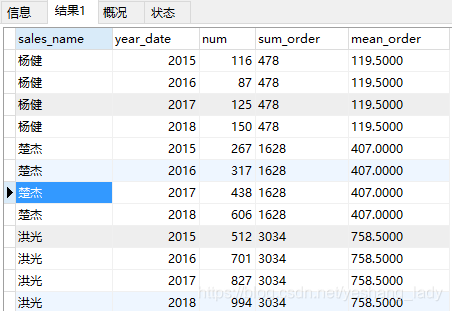
4.6 聚合函数
代码运行结果如下:
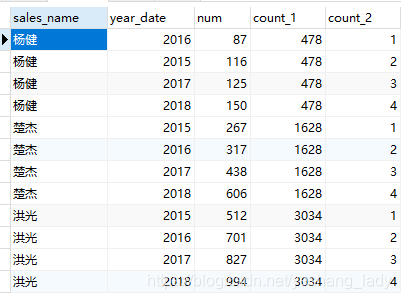
4.7 order by子句
代码运行结果如下:
当frame_clause不存在的时候,默认的frame与order by子句是否存在有关:
- 如果有order by子句,则默认的frame是从当前分区第一行到当前行。即在此种情况下,默认的frame为 RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
- 如果没有order by子句,则默认的frame是指该分区。如果此时也没有partition by子句,则相当于全部数据。
4.8 window子句
代码运行结果如下:
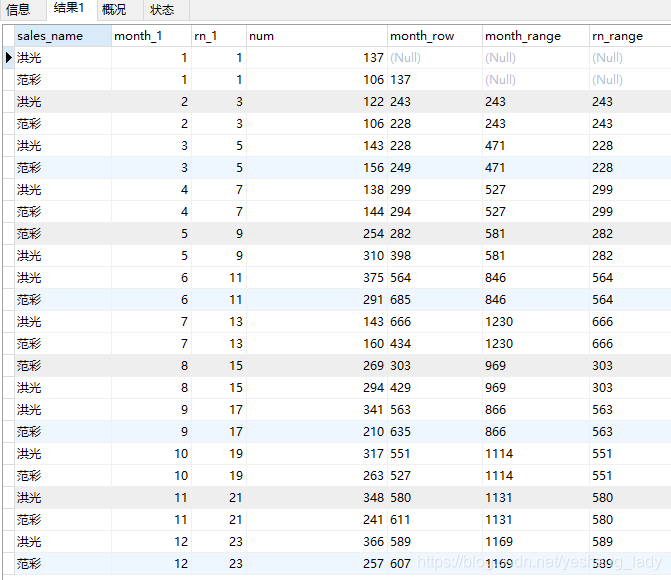
4.9 rows和range
rows和range是不能单独使用的,但是因为实在不理解这两个用法上的区别,所以就进行了单独的验证。
代码运行结果如下:
对以上代码分析:
首先,在这里我新建了一个rn_1列。rn_1列和month_1的区别在于,month_1的数据是连续的,而rn_1列是有中断的(两个1之后出现的是3,我是故意要创建一个中断的序列,来分析一下range的作用范围)
先来看month_row的区别,month_row列的计算结果为当前行在分区中按month_1升序排序之后排在其前面的两行(between and限定的)的sum求和值。所以rows后面的between and限定的偏移量是基于他们在分区中的排列位置的。
再来看month_range,通过分析其实验结果可以发现,month_range列的计算为分区内month_1=当前行-1和month_1=当前行-2(-1,-2是由between an子句决定的。preceding代表负,following代表正)所有列的sum求和值。再来看rn_range, rn_range列的计算结果为分区内month_1=当前行-2的所有里列的sum求和值。所以,rang后面的between and限定的偏移量依据的是当前行的数值。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了