
SpringBoot批量插入探索
MybatisPlus批量插入探索
最近在最近开发过程中遇到一个问题,在项目智慧物联网的大背景下,通常需要由多个传感器和监测设备向服务器请求,原设定是每次从mq中拉取1000数据批量插入到表分片中,在生产环境正式使用后发现最后一次成功插入时发现每次耗时需要18s,怎么会这么慢呢(—?—)赶紧多加几个分片[狗头]
JDBC配置参数rewriteBatchedStatements=true
MySQL的JDBC连接的url中要加rewriteBatchedStatements参数,并保证5.1.13以上版本的驱动,才能实现高性能的批量插入。 MySQL JDBC驱动在默认情况下会无视executeBatch()语句,把我们期望批量执行的一组sql语句拆散,一条一条地发给MySQL数据库,批量插入实际上是单条插入,直接造成较低的性能。 只有把rewriteBatchedStatements参数置为true, 驱动才会帮你批量执行SQL 另外这个选项对INSERT/UPDATE/DELETE都有效
我的pom文件


<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent> <artifactId>shardingjdbcdemo</artifactId> <groupId>com.atguigu</groupId> <version>0.0.1-SNAPSHOT</version> </parent> <modelVersion>4.0.0</modelVersion> <artifactId>mpkt</artifactId> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </dependency> <!--mybatis-plus--> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.4.3.3</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <scope>runtime</scope> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-aop</artifactId> </dependency> <dependency> <groupId>cn.afterturn</groupId> <artifactId>easypoi-spring-boot-starter</artifactId> <version>4.2.0</version> </dependency> <dependency> <groupId>p6spy</groupId> <artifactId>p6spy</artifactId> <version>3.8.1</version> </dependency> </dependencies> <build> <resources> <resource> <directory>src/main/java</directory> <includes> <include>**/*.xml</include> </includes> </resource> <!--指定资源的位置--> <resource> <directory>src/main/resources</directory> <includes> <include>**/*.yml</include> <include>**/*.properties</include> <include>**/*.xml</include> </includes> </resource> </resources> </build> </project>
我用的是saveBatch这个方法插入的

jdbc后面加上参数后有明显的效率提升

查看源码发现在不加上rewriteBatchedStatements参数时其默认的会将sql拆分并一条条发给msql
InsertBatchSomeColumn扩展插件
MybatisPlus在extension中提供了InsertBatchSomeColumn这个几个扩展方法。
AlwaysUpdateSomeColumnById: 根据Id更新每一个字段,全量更新不忽略null字段,解决mybatis-plus中updateById默认会自动忽略实体中null值字段不去更新的问题; InsertBatchSomeColumn: 真实批量插入,通过单SQL的insert语句实现批量插入; Upsert: 更新or插入,根据唯一约束判断是执行更新还是删除,相当于提供insert on duplicate key update支持。
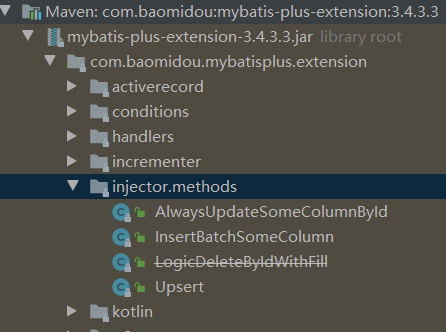
来看看官方的说法
先不管它有没有bug我们先来试试看:
1、新建一个MySqlInjector文件继承DefaultSqlInjector将需要用的method添加进去就好了
package com.mpkt.config; import com.baomidou.mybatisplus.annotation.FieldFill; import com.baomidou.mybatisplus.core.injector.AbstractMethod; import com.baomidou.mybatisplus.core.injector.DefaultSqlInjector; import com.baomidou.mybatisplus.core.metadata.TableInfo; import com.baomidou.mybatisplus.extension.injector.methods.AlwaysUpdateSomeColumnById; import com.baomidou.mybatisplus.extension.injector.methods.InsertBatchSomeColumn; import com.baomidou.mybatisplus.extension.injector.methods.Upsert; import org.springframework.stereotype.Component; import java.util.List; @Component public class MySqlInjector extends DefaultSqlInjector { @Override public List<AbstractMethod> getMethodList(Class<?> mapperClass, TableInfo tableInfo) { List<AbstractMethod> methodList = super.getMethodList(mapperClass, tableInfo); // 更新时自动填充的字段,不用插入值 methodList.add(new InsertBatchSomeColumn(i -> i.getFieldFill() != FieldFill.UPDATE)); methodList.add(new AlwaysUpdateSomeColumnById()); methodList.add(new Upsert()); return methodList; } }
2、新增一个名为SpiceBaseMapper的文件,把官方提供的注释copy下
3、userMapper改为继承这个新的文件就好啦
package com.mpkt.mapper; import com.baomidou.mybatisplus.core.mapper.BaseMapper; import java.util.List; public interface SpiceBaseMapper<T> extends BaseMapper<T> { /** * 批量插入 * @param entityList * @return */ int insertBatchSomeColumn(List<T> entityList); }
package com.mpkt.mapper; import com.baomidou.mybatisplus.extension.plugins.pagination.Page; import com.mpkt.entity.User; import org.apache.ibatis.annotations.Param; public interface UserMapper extends SpiceBaseMapper<User> { /** * 分页查询 * @param page * @return */ Page<User> queryAll(@Param("page") Page<User> page); /** * 创建表 * @param tableName */ void createTable(@Param("tableName") String tableName); }
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.mpkt.mapper.UserMapper"> <select id="queryAll" resultType="com.mpkt.entity.User"> select * from user </select> <update id="createTable"> CREATE TABLE ${tableName} ( `id` bigint(255) NOT NULL, `user_name` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '用户名', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic; </update> </mapper>
嗯,又快了一点点,也没发现什么bug。

接下来说下rewriteBatchedStatements的作用,这个参数的意义是:在底层jdbc是通过测试用例2这样的批量处理的方式插入数据的时候,如rewriteBatchedStatements设为true,jdbc驱动就会把sql在本地客户端拼接成insert into table (a,b,c) values (x,x,x),(x,x,x)...这样的sql发送到服务端(这里注意,数据量很多的时候,并不会把所有数据拼接成一条sql,而是分批次拼接,因为mysql每次传输的sql大小是有限制的),否则这样的批量插入和一条一条数据的插入没有任何区别。
其实还可以自己通过代码的方式拼接出来(这里就不介绍了),至于用那种方式就需要自己衡量了。
多线程分批次插入数据
在使用多线程之前需要先自定义下线程池
package com.mpkt.config; import java.util.concurrent.Executors; import java.util.concurrent.LinkedBlockingDeque; import java.util.concurrent.ThreadPoolExecutor; import java.util.concurrent.TimeUnit; public class ThreadPoolService { /** * CPU 密集型:核心线程数 = CPU核数 + 1 * <p> * IO 密集型:核心线程数 = CPU核数 * 2 * <p> * 注意:IO密集型 (某大厂实战经验) * 核心线程数 = CPU核数 / (1 - 阻塞系数) * 例如阻塞系数为0.8 ,CPU核数为 4 ,则核心线程数为 20 */ private static final int DEFAULT_CORE_SIZE = Runtime.getRuntime().availableProcessors() * 2; private static final int MAX_QUEUE_SIZE = 100; private static final int QUEUE_INIT_MAX_SIZE = 200; private volatile static ThreadPoolExecutor executor; private ThreadPoolService() { } // 获取单例的线程池对象 public static ThreadPoolExecutor getInstance() { if (executor == null) { synchronized (ThreadPoolService.class) { if (executor == null) { executor = new ThreadPoolExecutor(DEFAULT_CORE_SIZE,// 核心线程数 MAX_QUEUE_SIZE, // 最大线程数 Integer.MAX_VALUE, // 闲置线程存活时间 TimeUnit.MILLISECONDS,// 时间单位 new LinkedBlockingDeque<Runnable>(QUEUE_INIT_MAX_SIZE),// 线程队列 Executors.defaultThreadFactory()// 线程工厂 ); } } } return executor; } public void execute(Runnable runnable) { if (runnable == null) { return; } executor.execute(runnable); } // 从线程队列中移除对象 public void cancel(Runnable runnable) { if (executor != null) { executor.getQueue().remove(runnable); } } }
spring包含了方便的实用的工具StopWatch时钟(好用)
StopWatch是Spring核心包中的一个工具类,它是一个简单的秒表工具,可以计时指定代码段的运行时间以及汇总这个运行时间,
使用它可以隐藏使用 System.currentTimeMillis() ,提高应用程序代码的可读性并减少计算错误的可能性。
拿现有的代码改了一下,思路是在单次插入的数据进行分片,每个分片都是一个线程去执行插入。
package com.mpkt.service.impl; import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl; import com.google.common.collect.Lists; import com.mpkt.config.ThreadPoolService; import com.mpkt.entity.User; import com.mpkt.mapper.UserMapper; import com.mpkt.service.UserService; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.scheduling.annotation.Async; import org.springframework.stereotype.Service; import org.springframework.util.StopWatch; import java.util.ArrayList; import java.util.List; import java.util.concurrent.CompletableFuture; import java.util.concurrent.CountDownLatch; import java.util.concurrent.ThreadPoolExecutor; import java.util.concurrent.atomic.AtomicInteger; @Service public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService { @Autowired private UserMapper userMapper; @Override public void kks() { ArrayList<User> userList = new ArrayList<>(); for (int i = 0; i < 1000; i++) { User user = new User(); user.setAge(i); user.setUserName("zs"); user.setHobby("全民制作人"); userList.add(user); } StopWatch stopWatch = new StopWatch(); stopWatch.start(); // saveBatch(userList); // userMapper.insertBatchSomeColumn(userList); this.syncData(userList); stopWatch.stop(); System.out.println("-------------------总耗时:"+stopWatch.getTotalTimeSeconds()); } public void syncData(List<User> userList) { // 一个线程处理300条数据 int count = 300; List<List<User>> lists = Lists.partition(userList, count); int size = lists.size(); ThreadPoolExecutor executor = ThreadPoolService.getInstance(); AtomicInteger atomicInteger = new AtomicInteger(0); CountDownLatch countDownLatch = new CountDownLatch(size); for (List<User> i : lists) { CompletableFuture.runAsync(() -> { System.out.println("-----------------线程批量插入数据" + i.size()); userMapper.insertBatchSomeColumn(i); atomicInteger.getAndAdd(i.size()); countDownLatch.countDown(); }, executor); } try { countDownLatch.await(); } catch (InterruptedException e) { e.printStackTrace(); } } }
测试之后发现启用了多线程后在效率上比原先的快上一点。

使用10w条数据量进行测试康康,单次10直接j了超过最大packet了被mysql拒绝了[笑哭],统一改造成每批3k

出现了官方之前说的自增报错。。。

测试后发现在使用雪花算法和uuid时会出现这个问题,而数据库自增则不会
全部插入完成分批次插入10w花了15秒,这个效率还是可以接受的

改用多线程后测试时间为8秒有明显的效率提升

多线程结合事务管理
在主线程中开启了子线程,如果子线程出现异常的话,子线程会回滚吗?主线程会回滚吗?
在方法上面加上@Transactional后,(自定义抛出一个RuntimeException异常)很明显当线程异常时事务并没有生效,数据仍然插入成功。
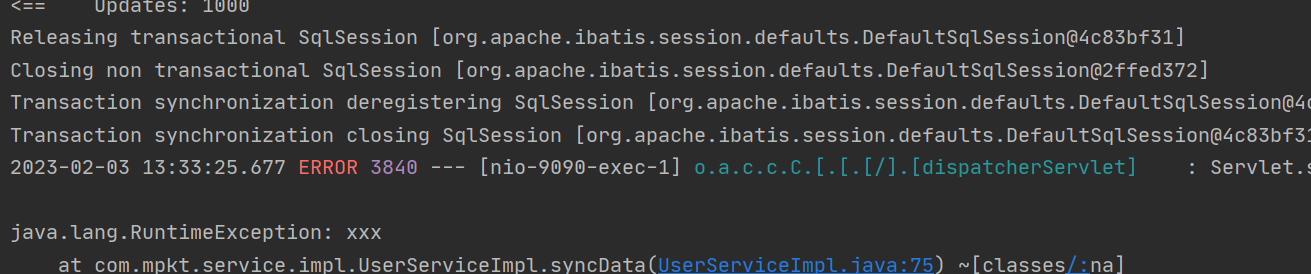
修改后的代码如下:
基本实现当主线程或者是子线程中出现一个异常,主、子线程中的sql操作都会回滚。
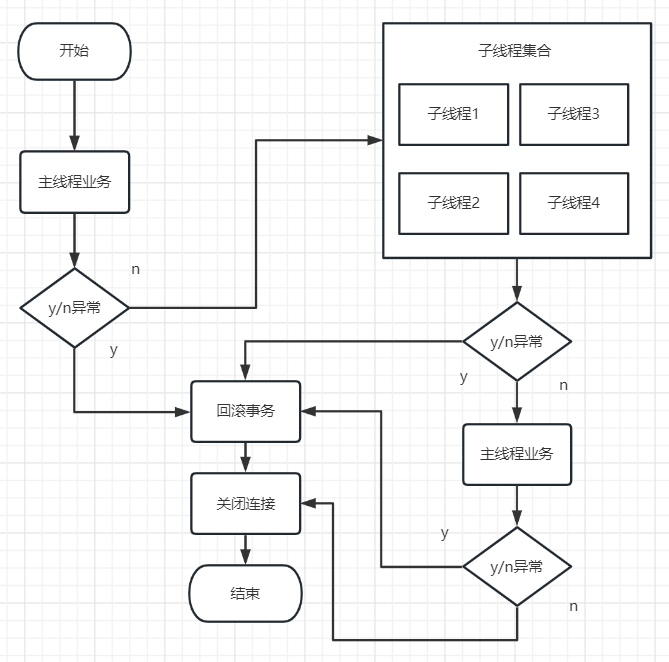
事务完成后测试插入(这里之所以快了可能是因为在测试事务的时候把表都清理过了)
package com.mpkt.config; import org.apache.ibatis.session.SqlSession; import org.apache.ibatis.session.SqlSessionFactory; import org.mybatis.spring.SqlSessionTemplate; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Component; import java.sql.Connection; @Component public class SqlContext { @Autowired private SqlSessionTemplate sqlSessionTemplate; public SqlSession getSqlSession(){ SqlSessionFactory sqlSessionFactory = sqlSessionTemplate.getSqlSessionFactory(); return sqlSessionFactory.openSession(); } public Connection getConnection() { return getSqlSession().getConnection(); } }
package com.mpkt.service.impl; import com.baomidou.mybatisplus.core.toolkit.Wrappers; import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl; import com.google.common.collect.Lists; import com.mpkt.config.SqlContext; import com.mpkt.config.ThreadPoolService; import com.mpkt.entity.User; import com.mpkt.mapper.UserMapper; import com.mpkt.service.UserService; import lombok.extern.slf4j.Slf4j; import org.apache.ibatis.session.SqlSession; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Service; import org.springframework.transaction.annotation.Transactional; import org.springframework.util.StopWatch; import java.sql.Connection; import java.sql.SQLException; import java.util.ArrayList; import java.util.List; import java.util.concurrent.CompletableFuture; import java.util.concurrent.CountDownLatch; import java.util.concurrent.ThreadPoolExecutor; import java.util.concurrent.atomic.AtomicBoolean; @Slf4j @Service public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService { @Autowired private SqlContext sqlContext; // @Transactional(rollbackFor = Exception.class) @Override public void kks() throws Exception { ArrayList<User> userList = new ArrayList<>(); for (int i = 0; i < 100000; i++) { User user = new User(); user.setAge(i); user.setUserName("zs"); user.setHobby("全民制作人"); userList.add(user); } StopWatch stopWatch = new StopWatch(); stopWatch.start(); // 获取sqlSession SqlSession sqlSession = sqlContext.getSqlSession(); Connection connection = sqlSession.getConnection(); // 关闭自动提交事务 connection.setAutoCommit(false); UserMapper userMapper = sqlSession.getMapper(UserMapper.class); ThreadPoolExecutor executor = ThreadPoolService.getInstance(); try { // 一个线程处理300条数据 int count = 3000; List<List<User>> lists = Lists.partition(userList, count); int size = lists.size(); AtomicBoolean atomicBoolean = new AtomicBoolean(false); CountDownLatch countDownLatch = new CountDownLatch(size); for (List<User> i : lists) { // 执行 CompletableFuture<Void> future = CompletableFuture.runAsync(() -> { System.out.println("-----------------线程批量插入数据" + i.size()); try { userMapper.insertBatchSomeColumn(i); // if (i.size()<count){ // throw new RuntimeException("出现异常"); // } } catch (Exception e) { log.error(e.getMessage()); atomicBoolean.set(true); } finally { countDownLatch.countDown(); } }, executor); } // 线程全部执行完毕 countDownLatch.await(); if (atomicBoolean.get()) { // 手动回滚事务 connection.rollback(); return; } // userMapper.delete(null); // if (true) { // throw new RuntimeException("出现异常"); // } // 手动提交事务 connection.commit(); } catch (SQLException e) { connection.rollback(); e.printStackTrace(); } finally { // 关闭连接 connection.close(); } stopWatch.stop(); System.out.println("-------------------总耗时:"+stopWatch.getLastTaskTimeMillis()); } }

分布式多数据源服务的情况
==

 浙公网安备 33010602011771号
浙公网安备 33010602011771号