第一次个人编程作业
| 主管作业属于哪个课程 | 软工2024 |
|---|---|
| 这个作业要求在哪里 | 链接 |
| 这个作业的目标 | 实现自己的第一个个人项目,增强对项目开发的理解 ,编写代码实现查重功能,学习使用PSP表格,学习commit规范 |
一、个人仓库
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| · Estimate | 估计这个任务需要多少时间 | 500 | 650 |
| Development | 开发 | 350 | 500 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 80 |
| · Design Spec | 生成设计文档 | 25 | 25 |
| Design Review | 设计复审 | 30 | 40 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| Design | 具体设计 | 20 | 30 |
| · Coding· | 具体编码 | 60 | 100 |
| Code Review | · 代码复审 | 60 | 50 |
| Test | · 测试(自我测试,修改代码,提交修改) | 70 | 60 |
| Reporting | 报告 | 120 | 100 |
| Test Repor · | 测试报告 | 60 | 100 |
| Size Measurement | · 计算工作量 | 20 | 50 |
| Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 1455 | 1865 |
三、计算模块接口的设计与实现过程
3.1 类
PaperCheckMain:main 方法所在的类
HammingUtils:计算海明距离的类
SimHashUtils:计算 SimHash 值的类
TxtIOUtils:读写 txt 文件的工具类
ShortStringException:处理文本内容过短的异常类
3.2 函数调用流程
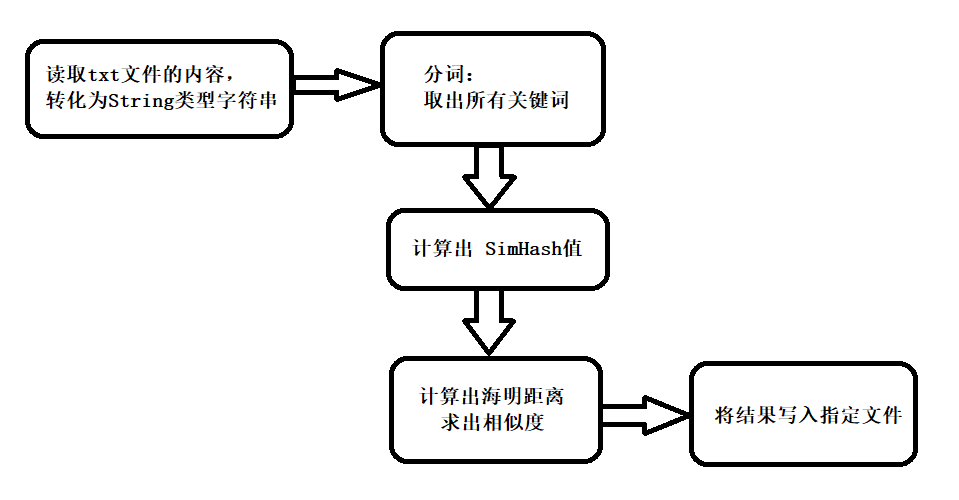
3.3 关键函数路程图

3.4 算法的关键及独到之处

3.5 海明距离模块:HammingUtil
分别通过getHammingDistance()、getSimilarity() 方法输入两个Simhash值计算海明距离distance,然后根据海明距离计算相似度。
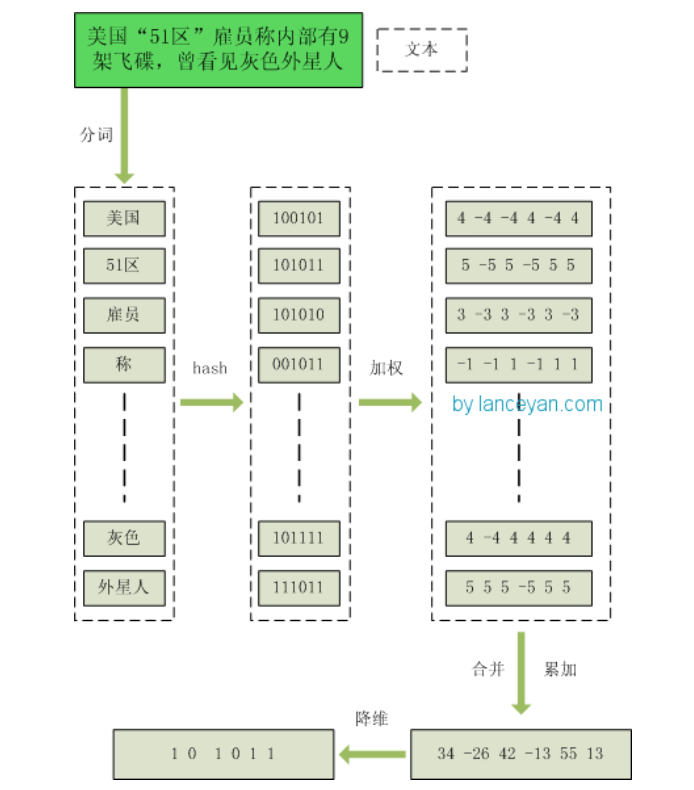
海明距离原理 主要的算法是:
分词:把需要判断文本分词形成这个文章的特征单词;
hash:通过hash算法把每个词编程hash值;
加权:根据gethas() 和 getSimhash() 计算结果,对单词的权重形成加权数字串;
合并:把各个单词计算序列值相加;
降维:把数字串形成最终的simhash。
原理如图:
四、计算模块接口设计与实现过程
4.1 读写txt文件的模块
类:TxtIOUtils
包含了两个静态方法:
1、readTxt:读取txt文件
2、writeTxt:写入txt文件
4.2 SimHash模块
类:SimHashUtils
包含两个静态方法:
1、getHash:传入String,计算出它的hash值,并以字符串形式输出,(使用了MD5获得hash值)
2、getSimHash:传入String,计算出它的simHash值,并以字符串形式输出,(需要调用 getHash 方法)
getSimHash 是核心算法,主要流程如下:
1、分词(使用了外部依赖 hankcs 包提供的接口)
List
2、获取hash值
String keywordHash = getHash(keyword);
if (keywordHash.length() < 128) {
// hash值可能少于128位,在低位以0补齐
int dif = 128 - keywordHash.length();
for (int j = 0; j < dif; j++) {
keywordHash += "0";
}
}
3、加权、合并
for (int j = 0; j < v.length; j++) {
// 对keywordHash的每一位与'1'进行比较
if (keywordHash.charAt(j) == '1') {
//权重分10级,由词频从高到低,取权重10~0
v[j] += (10 - (i / (size / 10)));
} else {
v[j] -= (10 - (i / (size / 10)));
}
}
4、降维
String simHash = "";// 储存返回的simHash值
for (int j = 0; j < v.length; j++) {
// 从高位遍历到低位
if (v[j] <= 0) {
simHash += "0";
} else {
simHash += "1";
}
}
4.3 海明距离模块
类:HammingUtils
包含两个静态方法:
1、getHammingDistance:输入两个 simHash 值,计算出它们的海明距离 distance。
for (int i = 0; i < simHash1.length(); i++) {
// 每一位进行比较
if (simHash1.charAt(i) != simHash2.charAt(i)) {
distance++;
}
}
2、getSimilarity:输入两个 simHash 值,调用 getHammingDistance 方法得出海明距离 distance,在由 distance 计算出相似度。
return 0.01 * (100 - distance * 100 / 128);
4.4 main模块
方法的主要流程:
从命令行输入的路径名读取对应的文件,将文件的内容转化为对应的字符串
根据字符串得出对应的 simHash值
由 simHash值求出相似度
把相似度写入最后的结果文件中
退出
五、计算模块接口部分的性能改进
5.1 改进计算模块性能的耗时记录40mins
5.2 描述改进思路
通过各种工具或手段,初步定位性能瓶颈点,通过各种工具或手段,初步定位性能瓶颈点,具体性能优化为getSimHash函数。
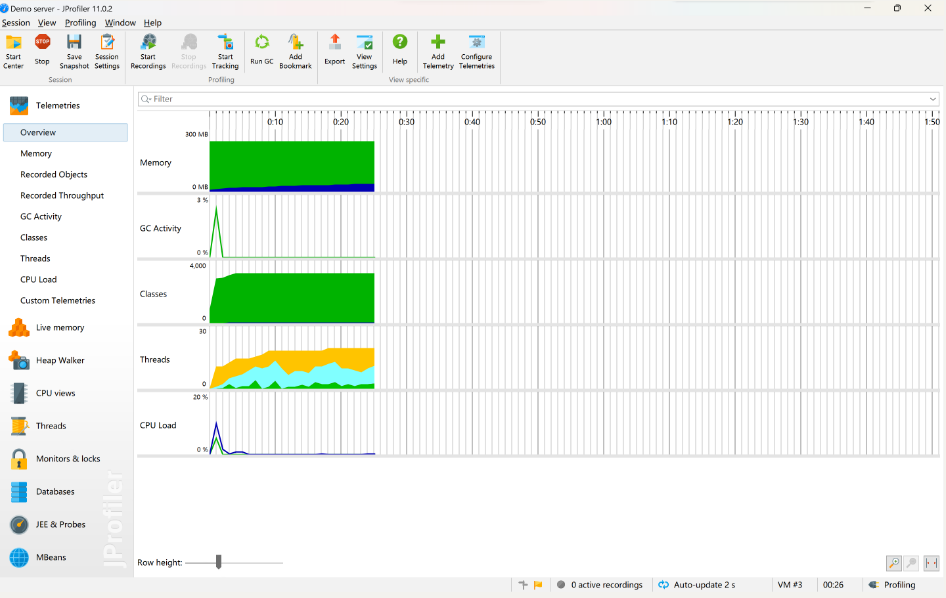
5.3 分析(VS2017/JProfiler)
5.3.1 性能分析图
5.3.2 方法调用情况

5.4 耗时最大的函数展示
此函数由于调用了HanLP,因此耗时最大。
public static String getSimHash(String str) {
// 用数组表示特征向量,取128位,从 0 1 2 位开始表示从高位到低位
int[] v = new int[128];
// 1、分词
List<String> keywordList = HanLP.extractKeyword(str, str.length());//取出所有关键词
// hash
int size = keywordList.size();
int i = 0;//以i做外层循环
for (String keyword : keywordList) {
// 2、获取hash值
StringBuilder keywordHash = new StringBuilder(getHash(keyword));
if (keywordHash.length() < 128) {
int dif = 128 - keywordHash.length();
for (int j = 0; j < dif; j++) {
keywordHash.append("0");
}
}
// 3、加权、合并
for (int j = 0; j < v.length; j++) {
if (keywordHash.charAt(j) == '1') {
v[j] +=1;
} else {
v[j] -= 1;
}
}
i++;
}
六、测试模块
6.1 测试函数的说明
class SimHashUtilTest {
@Test
void getHash() {
System.out.println(SimHashUtil.getHash("213123"));
}
@Test
void getSimHash() {
System.out.println(SimHashUtil.getSimHash("124123123"));
}
@Test
void getHammingDistance() {
}
@Test
void getSimilarity() {
String simHash1 = SimHashUtil.getSimHash("hasdoihasiodhoiasd");
String simHash2 = SimHashUtil.getSimHash("hasdoihasiodhoiasd");
System.out.println(SimHashUtil.getSimilarity(simHash1,simHash2));
}
}
6.2 测试数据的思路构建
功能测试的测试思路:测试每个部分的功能是否能达到预期结果
2.1 模块接口测试:后台的数据集成在测试框架中,检查测试代码块之间的接口, 和数据的传输等问题。
2.2 执行测试用例:利用下发的测试用例,执行用例将所有需求跑一遍,确认测试需求是否有功能点遗漏,查漏补缺。
6.3 读写txt文件模块
1、测试正常读取
2、测试正常写入
3、测试错误读取
4、测试错误写入
public class TxtIOUtilsTest {
@Test
public void readTxtTest() {
// 路径存在,正常读取
String str = TxtIOUtils.readTxt("D:/test/orig.txt");
String[] strings = str.split(" ");
for (String string : strings) {
System.out.println(string);
}
}
@Test
public void writeTxtTest() {
// 路径存在,正常写入
double[] elem = {0.11, 0.22, 0.33, 0.44, 0.55};
for (int i = 0; i < elem.length; i++) {
TxtIOUtils.writeTxt(elem[i], "D:/test/ans.txt");
}
}
@Test
public void readTxtFailTest() {
// 路径不存在,读取失败
String str = TxtIOUtils.readTxt("D:/test/none.txt");
}
@Test
public void writeTxtFailTest() {
// 路径错误,写入失败
double[] elem = {0.11, 0.22, 0.33, 0.44, 0.55};
for (int i = 0; i < elem.length; i++) {
TxtIOUtils.writeTxt(elem[i], "User:/test/ans.txt");
}
}
}
测试结果
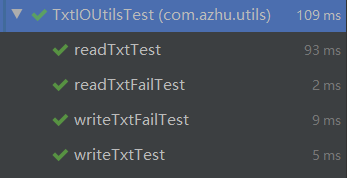
代码覆盖率

6.4 SimHash模块
public class SimHashUtilsTest {
@Test
public void getHashTest(){
String[] strings = {"余华", "是", "一位", "真正", "的", "作家"};
for (String string : strings) {
String stringHash = SimHashUtils.getHash(string);
System.out.println(stringHash.length());
System.out.println(stringHash);
}
}
@Test
public void getSimHashTest(){
String str0 = TxtIOUtils.readTxt("D:/test/orig.txt");
String str1 = TxtIOUtils.readTxt("D:/test/orig_0.8_add.txt");
System.out.println(SimHashUtils.getSimHash(str0));
System.out.println(SimHashUtils.getSimHash(str1));
}
}
测试结果
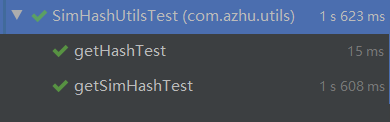
代码覆盖率

6.5海明距离模块
public class HammingUtilsTest {
@Test
public void getHammingDistanceTest() {
String str0 = TxtIOUtils.readTxt("D:/test/orig.txt");
String str1 = TxtIOUtils.readTxt("D:/test/orig_0.8_add.txt");
int distance = HammingUtils.getHammingDistance(SimHashUtils.getSimHash(str0), SimHashUtils.getSimHash(str1));
System.out.println("海明距离:" + distance);
System.out.println("相似度: " + (100 - distance * 100 / 128) + "%");
}
}
测试结果
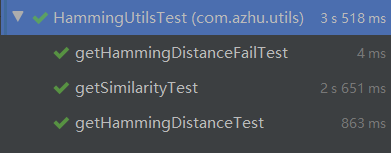
覆盖率

七、计算模块部分异常处理说明
7. 1 异常设计目标的介绍
设计目标:为防止文本长度不满足要求而设置的规范长度异常
对应场景:当读取的文本内容少于300字符时将抛出。
7.2 异常单元测试样例与检错

八、测试结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号