
[转]initrd.img, vmlinux
转自 https://blog.csdn.net/Geek_Tank/article/details/69479196
编译安装完内核后在/boot下没有initrd.img
vmlinuz自然就是内核了,initrd.img是一个小的映象,包含一个最小的linux系统。通常的步骤是先启动内核,然后内核挂载initrd.img,并执行里面的脚本来进一步挂载各种各样的模块,然后发现真正的root分区,挂载并执行/sbin/init... ...。
initrd.img当然是可选的了,如果没有initrd.img,内核就试图直接挂载root分区。
之所以要有initrd,那是为了启动的时候有更大的灵活性。比如,你把ext3支持编译成模块了。偏偏你的root分区又是ext3的。这下就麻烦了。因为内核需要挂载root分区之后才能加载ext3支持。但是没有ext3支持就没法挂载root分区。initrd就是用来解决这个问题的。
类似的用这个东西还可以做其他的事情,比如从usb盘启动linux也会面临上面类似的问题。用initrd就能搞定了。
一.vmlinuz
vmlinuz是可引导的、压缩的内核。“vm”代表 “Virtual Memory”。Linux 支持虚拟内存,不像老的操作系统比如DOS有640KB内存的限制。Linux能够使用硬盘空间作为虚拟内存,因此得名“vm”。vmlinuz是可执行的Linux内核,它位于/boot/vmlinuz,它一般是一个软链接。
-
vmlinuz的建立有两种方式
(1).编译内核时通过“make zImage”创建,然后通过下面代码产生:
cp /usr/src/linux-2.4/arch/i386/linux/boot/zImage /boot/vmlinuz
zImage适用于小内核的情况,它的存在是为了向后的兼容性。(2).内核编译时通过命令make bzImage创建,然后通过下面代码产生:
cp /usr/src/linux-2.4/arch/i386/linux/boot/bzImage /boot/vmlinuz
bzImage是压缩的内核映像,需要注意,bzImage不是用bzip2压缩的,bzImage中的bz容易引起误解,bz表示“big zImage”。 bzImage中的b是“big”意思。- Notice 1
zImage(vmlinuz)和bzImage(vmlinuz)都是用gzip压缩的。它们不仅是一个压缩文件,而且在这两个文件的开头部分内嵌有gzip解压缩代码。所以你不能用gunzip 或 gzip –dc解包vmlinuz。 - Notice 2
内核文件中包含一个微型的gzip用于解压缩内核并引导它。两者的不同之处在于,老的zImage解压缩内核到低端内存(第一个640K), bzImage解压缩内核到高端内存(1M以上)。如果内核比较小,那么可以采用zImage 或bzImage之一,两种方式引导的系统运行时是相同的。大的内核采用bzImage,不能采用zImage。 - Notice 3
vmlinux是未压缩的内核,vmlinuz是vmlinux的压缩文件。
例如:vmlinux-2.4.20-8是未压缩内核,vmlinuz-2.4.20-8是vmlinux-2.4.20-8的压缩文件。
- Notice 1
二.initrd.img
转自:http://blog.csdn.net/chrisniu1984/article/details/3907874
对我个人而言,学习一个系统的最好的方法就是随着其启动运行的过程一点一点跟进(就好象看一个程序的源码要从main函数或者说从入口函数开始步步跟进)。当然具体的学习过程重点不是找到入口点就OK的。中间还有很多技巧,比如什么时候这个应该跳过一个实现什么时候应该跟进等。这个具体方法就一言难尽了,我也不再多少说了。不多说的两个简单原因:1、正如我开始说的,这个方法也许只适合我。 2、并不是本篇文章的重点。
我前面那么多废话只是想带出我聊聊的的 initrd.img文件,因为它就是系统启动会加载的文件。
一般来讲大家很容易理解的是这样的:系统内核 vmlinuz被加载到内存后开始提供底层支持,在内核的支持下各种模块,服务等被加载运行。这样当然是大家最容易接受的方式,曾经的linux就是这样的运行的。假设你的硬盘是scsi 接口而你的内核又不支持这种接口时,你的内核就没有办法访问硬盘,当然也没法加载硬盘上的文件系统,怎么办?好办!把内核加入scsi驱动源码然后重新编译出一个新的内核文件替换原来vmlinuz。
需要改变标准内核默认提供支持的例子还有很多,如果每次都需要编译内核就太麻烦了。所以后来的linux就提供了一个灵活的方法来解决这些问题—initrd.img
ininrd.img是什么呢?initrd (initialized ramdisk)是用一部分内存模拟成磁盘,让操作系统访问。举个例子,不知道你用过没用过win pe他的衍生版比较有名的就是“深山红叶系统修复光盘”。当使用win pe 启动后会发现你的计算机就算没有硬盘也能在正常运行,其中有个文件系统B:/ 分区,这个分区就是内存模拟的磁盘。
- 直白一点,initrd就是一个带有根文件系统的虚拟RAM盘,里面包含了根目录‘/’,以及其他的目录,比如:bin,dev,proc,sbin,sys等linux启动时必须的目录,以及在bin目录下加入了一下必须的可执行命令。
- PC或者服务器linux内核使用这个initrd来挂载真正的根文件系统,然后将此initrd从内存中卸掉,这种情况下initrd其实就是一个过渡使用的东西。在现在的许多简单嵌入式linux中一般是不卸载这个initrd的,而是直接将其作为根文件系统使用,在这之前就需要把所需要的程序,命令还有其它文件都安装到这个文件系统中。其实现在的大多数嵌入式系统也是有自己的磁盘的,所以,initrd在现在大多数的嵌入式系统中也和一般的linux中的作用一样只是起过渡使用。
- Initrd的引导过程:‘第二阶段引导程序’,常用的是grub将内核解压缩并拷贝到内存中,然后内核接管了CPU开始执行,然后内核调用init()函数,注意,此init函数并不是后来的init进程!!!然后内核调用函数 initrd_load()来在内存中加载initrd根文件系统。Initrd_load()函数又调用了一些其他的函数来为RAM磁盘分配空间,并计算CRC等操作。然后对RAM磁盘进行解压,并将其加载到内存中。现在,内存中就有了initrd的映象。
- 然后内核会调用mount_root()函数来创建真正的根分区文件系统,然后调用sys_mount()函数来加载真正的根文件系统,然后chdir到这个真正的根文件系统中。
- 最后,init函数调用run_init_process函数,利用execve来启动init进程,从而进入 init的运行过程。
initrd.img文件就是个ramdisk的映像文件(其实是压缩过的,后面会解释)。ram disk是标准内核文件认识的设备(/dev/ram0)文件系统也是标准内核认识的文件系统。内核加载这个ram disk作为根文件系统并开始执行其中的”某个文件”(2.6内核是 init文件)来加载各种模块(支持scsi的驱动就可以放在这里),服务等(这时然后系统就更强大了)。经过一些配置和运行后,就可以去物理磁盘加载真正的root分区了,然后又是一些配置等,最后启动成功。
也就是你只需要定制适合自己的 initrd.img 文件就可以了。这要比重编内核简单多了,省时省事低风险。内核启动过程中具体执行了initrd.img 内的哪些文件和顺序不在本文讨论,下面只讲讲你怎样才能看到 initrd.img的内容。
这个方法是对kernel-2.5之后的版本适用的。因为这之前的initrd.img和之后的格式是不同的。这之后的版本一般被称为cpio-initrd。 initrd.img 是个gz压缩文件,initrd.img改名为initrd.gz能用windows下的winrar或linux下的gunzip解压,解压后会得到一个initrd文件。这个文件就是cpio格式的文件,只能在linux下用cpio命令解压(我没找到在windows下能解药cpio格式的工具,如果你找到了告诉我一下,谢谢) ,执行cpio -i < initrd
这篇只是简单的说了说 initrd.img 的作用,也许有表述的不严谨的地方,还请大家多多指教。
三.System.map
内核符号映射表,顾名思义就是将内核中的符号(也就是内核中的函数)和它的地址能联系起来的一个列表。是所有符号及其对应地址的一个列表。之所以这样就使为了用户编程方便,直接使用函数符号就可以了,而不用去记要使用函数的地址。当你编译一个新内核时,原来的System.map中的符号信息就不正确了。随着每次内核的编译,就会产生一个新的 System.map文件,并且需要用该文件取代原来的文件
System.map是一个特定内核的内核符号表。它是你当前运行的内核的System.map的链接。
内核符号表是怎么创建的呢? System.map是由“nm vmlinux”产生并且不相关的符号被滤出。
/proc/ksyms是一个“proc file”,在内核引导时创建。实际上,它并不真正的是一个文件,它只不过是内核数据的表示,却给人们是一个磁盘文件的假象,这从它的文件大小是0可以看出来。然而,System.map是存在于你的文件系统上的实际文件。
当你编译一个新内核时,各个符号名的地址要发生变化,你的老的System.map具有的是错误的符号信息。每次内核编译时产生一个新的 System.map,你应当用新的System.map来取代老的System.map。
虽然内核本身并不真正使用System.map,但其它程序比如klogd,lsof和ps等软件需要一个正确的System.map。如果你使用错误的或没有System.map,klogd的输出将是不可靠的,这对于排除程序故障会带来困难。没有System.map,你可能会面临一些令人烦恼的提示信息。
另外少数驱动需要System.map来解析符号,没有为你当前运行的特定内核创建的System.map它们就不能正常工作。
Linux的内核日志守护进程klogd为了执行名称-地址解析,klogd需要使用System.map。System.map应当放在使用它的软件能够找到它的地方。执行:manklogd可知,如果没有将System.map作为一个变量的位置给klogd,那么它将按照下面的顺序,在三个地方查找 System.map:
/boot/System.map
/System.map
/usr/src/linux/System.map
System.map也有版本信息,klogd能够智能地查找正确的映象(map)文件。
Linux启动过程综述
首先我们要理解如下两个概念:
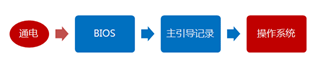
- BIOS
Basic Input-output System,是开机第一个被执行的程序,又被称之为固件。当它被启动后,会顺序加载磁盘前512字节,也就是我们所说的主引导记录(MBR),前440字节包含某个启动引导器,比如GRUB、Syslinux之类的第一启动阶段代码。然后启动引导器通过链式引导或者直接加载内核,以加载一个操作系统。
- UEFI
UEFI 不仅能读取分区表,还能自动支持文件系统。所以不像 BIOS,没有440 字节可执行代码即 MBR 的限制了,它完全用不到 MBR。虽然UEFI 主流都支持 MBR 和 GPT 分区表。但不管第一块上有没有 MBR,UEFI 都不会执行它。相反,它依赖分区表上的一个特殊分区,叫 EFI 系统分区,里面有 UEFI 所要用到的一些文件。
从前,内核在启动过程早期(挂载根目录和启动init之前)处理一切硬件的检测和初始化。然而,但随着技术的演进,这种做法变得十分繁琐。
如今,根文件系统可能位于各种硬件上,如SCSI设备、SATA设备、U盘,而这些硬件受控于形形色色的厂家所提供的五花八门的驱动之下。另外,根系统可以加密、压缩,可存放在RAID阵列中,或者一个逻辑卷组上。为了简化这复杂的过程,可以把管理权转入一个用户空间:初始化内存盘。
在archlinux上,当内核被加载后,它会解压mkinitcpio(一个创建初始内存盘的bash脚本),把它当做成一个已经初始化的根文件系统。内核接着会执行/init作为第一条进程。
注:初始内存盘本质上是一个很小的运行环境(早期用户空间),用于加载一些核心模块,并在 init 接管启动过程之前做必要的准备。有了这个环境,才能支持加密根文件系统、RAID上的根文件系统等高级功能。
在「早期用户空间」的最终环节里,当真正的根文件系统被挂载好后,就会替换掉原来的伪根文件系统。接着 /sbin/init 被执行,同样也替换掉原来的 /init 进程。Arch 御用的init 就是 systemd
init为每一个虚拟终端调用getty,一般有6个,每个虚拟终端都会初始化tty并请求输入用户名和密码。当在某个虚拟终端中输入密码后,其getty会通过/etc/passwd检查是否正确,如果正确会启动login程序,该程序会为用户启动一个设置里环境变量的【会话】,然后再次通过查看/etc/passwd内容的配置为用户启动专用shell。
一旦当用户的专用shell启动后,它会在显示命令提示符前执行一个配置文件,比如.bashrc。当然,如果用户设置statx at login,配置文件会调用starx或者xinit.它同样也会调用配置文件,如xinitrc。
Bootloader
在Alpha/AXP平台上引导Linux通常有两种方法,一种是由MILO及其他类似的引导程序引 导,另一种是由Firmware直接引导。MILO功能与i386平台的LILO相近,但内置有基本的磁盘 驱动程序(如IDE、SCSI等),以及常见的文件系统驱动程序(如ext2,iso9660等), firmware有ARC、SRM两种形式,ARC具有类BIOS界面,甚至还有多重引导的设置;而SRM则具 有功能强大的命令行界面,用户可以在控制台上使用boot等命令引导系统。ARC有分区 (Partition)的概念,因此可以访问到分区的首扇区;而SRM只能将控制转给磁盘的首扇区。 两种firmware都可以通过引导MILO来引导Linux,也可以直接引导Linux的引导代码。
“arch/alpha/boot”下就是制作Linux Bootloader的文件。“head.S”文件提供了对 OSF PAL/1的调用入口,它将被编译后置于引导扇区(ARC的分区首扇区或SRM的磁盘0扇区), 得到控制后初始化一些数据结构,再将控制转给“main.c”中的start_kernel(), start_kernel()向控制台输出一些提示,调用pal_init()初始化PAL代码,调用openboot() 打开引导设备(通过读取Firmware环境),调用load()将核心代码加载到START_ADDR(见 “include/asm-alpha/system.h”),再将Firmware中的核心引导参数加载到ZERO_PAGE(0) 中,最后调用runkernel()将控制转给0x100000的kernel,bootloader部分结束。
Bootloader中使用的所有“srm_”函数在“arch/alpha/lib/”中定义。
以上这种Boot方式是一种最简单的方式,即不需其他工具就能引导Kernel,前提是按照 Makefile的指导,生成bootimage文件,内含以上提到的bootloader以及vmlinux,然后将 bootimage写入自磁盘引导扇区始的位置中。
当采用MILO这样的引导程序来引导Linux时,不需要上面所说的Bootloader,而只需要 vmlinux或vmlinux.gz,引导程序会主动解压加载内核到0x1000(小内核)或0x100000(大 内核),并直接进入内核引导部分,即本文的第二节。
对于I386平台
i386系统中一般都有BIOS做最初的引导工作,那就是将四个主分区表中的第一个可引导 分区的第一个扇区加载到实模式地址0x7c00上,然后将控制转交给它。
在“arch/i386/boot”目录下,bootsect.S是生成引导扇区的汇编源码,它首先将自己 拷贝到0x90000上,然后将紧接其后的setup部分(第二扇区)拷贝到0x90200,将真正的内核 代码拷贝到0x100000。以上这些拷贝动作都是以bootsect.S、setup.S以及vmlinux在磁盘上 连续存放为前提的,也就是说,我们的bzImage文件或者zImage文件是按照bootsect,setup, vmlinux这样的顺序组织,并存放于始于引导分区的首扇区的连续磁盘扇区之中。
bootsect.S完成加载动作后,就直接跳转到0x90200,这里正是setup.S的程序入口。 setup.S的主要功能就是将系统参数(包括内存、磁盘等,由BIOS返回)拷贝到 0x90000-0x901FF内存中,这个地方正是bootsect.S存放的地方,这时它将被系统参数覆盖。 以后这些参数将由保护模式下的代码来读取。
除此之外,setup.S还将video.S中的代码包含进来,检测和设置显示器和显示模式。最 后,setup.S将系统转换到保护模式,并跳转到0x100000(对于bzImage格式的大内核是 0x100000,对于zImage格式的是0x1000)的内核引导代码,Bootloader过程结束。
对于2.4.x版内核
没有什么变化。
Kernel引导入口
对于I386平台
在i386体系结构中,因为i386本身的问题,在"arch/alpha/kernel/head.S"中需要更多的设置,但最终也是通过call SYMBOL_NAME(start_kernel)转到start_kernel()这个体系结构无关的函数中去执行了。
所不同的是,在i386系统中,当内核以bzImage的形式压缩,即大内核方式 (__BIG_KERNEL__)压缩时就需要预先处理bootsect.S和setup.S,按照大核模式使用$(CPP) 处理生成bbootsect.S和bsetup.S,然后再编译生成相应的.o文件,并使用 "arch/i386/boot/compressed/build.c"生成的build工具,将实际的内核(未压缩的,含 kernel中的head.S代码)与"arch/i386/boot/compressed"下的head.S和misc.c合成到一起,其中的head.S代替了"arch/i386/kernel/head.S"的位置,由Bootloader引导执行 (startup_32入口),然后它调用misc.c中定义的decompress_kernel()函数,使用 "lib/inflate.c"中定义的gunzip()将内核解压到0x100000,再转到其上执行 "arch/i386/kernel/head.S"中的startup_32代码。
对于2.4.x版内核
没有变化。
核心数据结构初始化--内核引导第一部分
start_kernel()中调用了一系列初始化函数,以完成kernel本身的设置。 这些动作有的是公共的,有的则是需要配置的才会执行的。
在start_kernel()函数中,
- 输出Linux版本信息(printk(linux_banner))
- 设置与体系结构相关的环境(setup_arch())
- 页表结构初始化(paging_init())
- 使用"arch/alpha/kernel/entry.S"中的入口点设置系统自陷入口(trap_init())
- 使用alpha_mv结构和entry.S入口初始化系统IRQ(init_IRQ())
- 核心进程调度器初始化(包括初始化几个缺省的Bottom-half,sched_init())
- 时间、定时器初始化(包括读取CMOS时钟、估测主频、初始化定时器中断等,time_init())
- 提取并分析核心启动参数(从环境变量中读取参数,设置相应标志位等待处理,(parse_options())
- 控制台初始化(为输出信息而先于PCI初始化,console_init())
- 剖析器数据结构初始化(prof_buffer和prof_len变量)
- 核心Cache初始化(描述Cache信息的Cache,kmem_cache_init())
- 延迟校准(获得时钟jiffies与CPU主频ticks的延迟,calibrate_delay())
- 内存初始化(设置内存上下界和页表项初始值,mem_init())
- 创建和设置内部及通用cache("slab_cache",kmem_cache_sizes_init())
- 创建uid taskcount SLAB cache("uid_cache",uidcache_init())
- 创建文件cache("files_cache",filescache_init())
- 创建目录cache("dentry_cache",dcache_init())
- 创建与虚存相关的cache("vm_area_struct","mm_struct",vma_init())
- 块设备读写缓冲区初始化(同时创建"buffer_head"cache用户加速访问,buffer_init())
- 创建页cache(内存页hash表初始化,page_cache_init())
- 创建信号队列cache("signal_queue",signals_init())
- 初始化内存inode表(inode_init())
- 创建内存文件描述符表("filp_cache",file_table_init())
- 检查体系结构漏洞(对于alpha,此函数为空,check_bugs())
- SMP机器其余CPU(除当前引导CPU)初始化(对于没有配置SMP的内核,此函数为空,smp_init())
- 启动init过程(创建第一个核心线程,调用init()函数,原执行序列调用cpu_idle() 等待调度,init())
至此start_kernel()结束,基本的核心环境已经建立起来了。
对于I386平台
i386平台上的内核启动过程与此基本相同,所不同的主要是实现方式。
对于2.4.x版内核
2.4.x中变化比较大,但基本过程没变,变动的是各个数据结构的具体实现,比如Cache。
外设初始化--内核引导第二部分
init()函数作为核心线程,首先锁定内核(仅对SMP机器有效),然后调用 do_basic_setup()完成外设及其驱动程序的加载和初始化。过程如下:
- 总线初始化(比如pci_init())
- 网络初始化(初始化网络数据结构,包括sk_init()、skb_init()和proto_init()三部分,在proto_init()中,将调用protocols结构中包含的所有协议的初始化过程,sock_init())
- 创建bdflush核心线程(bdflush()过程常驻核心空间,由核心唤醒来清理被写过的内存缓冲区,当bdflush()由kernel_thread()启动后,它将自己命名为kflushd)
- 创建kupdate核心线程(kupdate()过程常驻核心空间,由核心按时调度执行,将内存缓冲区中的信息更新到磁盘中,更新的内容包括超级块和inode表)
- 设置并启动核心调页线程kswapd(为了防止kswapd启动时将版本信息输出到其他信息中间,核心线调用kswapd_setup()设置kswapd运行所要求的环境,然后再创建 kswapd核心线程)
- 创建事件管理核心线程(start_context_thread()函数启动context_thread()过程,并重命名为keventd)
- 设备初始化(包括并口parport_init()、字符设备chr_dev_init()、块设备 blk_dev_init()、SCSI设备scsi_dev_init()、网络设备net_dev_init()、磁盘初始化及分区检查等等,device_setup())
- 执行文件格式设置(binfmt_setup())
- 启动任何使用__initcall标识的函数(方便核心开发者添加启动函数,do_initcalls())
- 文件系统初始化(filesystem_setup())
- 安装root文件系统(mount_root()) 真正根文件系统
至此do_basic_setup()函数返回init(),在释放启动内存段(free_initmem())并给内核解锁以后,init()打开/dev/console设备,重定向stdin、stdout和stderr到控制台,最后,搜索文件系统中的init程序(或者由init=命令行参数指定的程序),并使用 execve()系统调用加载执行init程序。
init()函数到此结束,内核的引导部分也到此结束了,这个由start_kernel()创建的第一个线程已经成为一个用户模式下的进程了。此时系统中存在着六个运行实体:
- start_kernel()本身所在的执行体,这其实是一个"手工"创建的线程,它在创建了init()线程以后就进入cpu_idle()循环了,它不会在进程(线程)列表中出现
- init线程,由start_kernel()创建,当前处于用户态,加载了init程序
- kflushd核心线程,由init线程创建,在核心态运行bdflush()函数
- kupdate核心线程,由init线程创建,在核心态运行kupdate()函数
- kswapd核心线程,由init线程创建,在核心态运行kswapd()函数
- keventd核心线程,由init线程创建,在核心态运行context_thread()函数
对于I386平台
基本相同。
对于2.4.x版内核
这一部分的启动过程在2.4.x内核中简化了不少,缺省的独立初始化过程只剩下网络 (sock_init())和创建事件管理核心线程,而其他所需要的初始化都使用__initcall()宏 包含在do_initcalls()函数中启动执行。
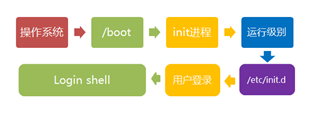
init进程和inittab引导指令
init进程是系统所有进程的起点,内核在完成核内引导以后,即在本线程(进程)空 间内加载init程序,它的进程号是1。
init程序需要读取/etc/inittab文件作为其行为指针,inittab是以行为单位的描述性(非执行性)文本,每一个指令行都具有以下格式:
id:runlevel:action:process其中id为入口标识符,runlevel为运行级别,action为动作代号,process为具体的执行程序。
id一般要求4个字符以内,对于getty或其他login程序项,要求id与tty的编号相同,否则getty程序将不能正常工作。
runlevel是init所处于的运行级别的标识,一般使用0-6以及S或s。0、1、6运行级别被系统保留,0作为shutdown动作,1作为重启至单用户模式,6为重启;S和s意义相同,表示单用户模式,且无需inittab文件,因此也不在inittab中出现,实际上,进入单用户模式时,init直接在控制台(/dev/console)上运行/sbin/sulogin。
在一般的系统实现中,都使用了2、3、4、5几个级别,在Redhat系统中,2表示无NFS支持的多用户模式,3表示完全多用户模式(也是最常用的级别),4保留给用户自定义,5表示XDM图形登录方式。7-9级别也是可以使用的,传统的Unix系统没有定义这几个级别。runlevel可以是并列的多个值,以匹配多个运行级别,对大多数action来说,仅当runlevel与当前运行级别匹配成功才会执行。
initdefault是一个特殊的action值,用于标识缺省的启动级别;当init由核心激活 以后,它将读取inittab中的initdefault项,取得其中的runlevel,并作为当前的运行级 别。如果没有inittab文件,或者其中没有initdefault项,init将在控制台上请求输入 runlevel。
sysinit、boot、bootwait等action将在系统启动时无条件运行,而忽略其中的runlevel,其余的action(不含initdefault)都与某个runlevel相关。各个action的定义在inittab的man手册中有详细的描述。
在Redhat系统中,一般情况下inittab都会有如下几项:
|
1 2 3 4 5 6 7 8 9 10 11 |
id:3:initdefault: #表示当前缺省运行级别为3--完全多任务模式; si::sysinit:/etc/rc.d/rc.sysinit #启动时自动执行/etc/rc.d/rc.sysinit脚本 l3:3:wait:/etc/rc.d/rc 3 #当运行级别为3时,以3为参数运行/etc/rc.d/rc脚本,init将等待其返回 0:12345:respawn:/sbin/mingetty tty0 #在1-5各个级别上以tty0为参数执行/sbin/mingetty程序,打开tty0终端用于 #用户登录,如果进程退出则再次运行mingetty程序 x:5:respawn:/usr/bin/X11/xdm -nodaemon #在5级别上运行xdm程序,提供xdm图形方式登录界面,并在退出时重新执行 |
rc启动脚本
上一节已经提到init进程将启动运行rc脚本,这一节将介绍rc脚本具体的工作。
一般情况下,rc启动脚本都位于/etc/rc.d目录下,rc.sysinit中最常见的动作就是激活交换分区,检查磁盘,加载硬件模块,这些动作无论哪个运行级别都是需要优先执行的。仅当rc.sysinit执行完以后init才会执行其他的boot或bootwait动作。
如果没有其他boot、bootwait动作,在运行级别3下,/etc/rc.d/rc将会得到执行,命令行参数为3,即执行/etc/rc.d/rc3.d/目录下的所有文件。rc3.d下的文件都是指向/etc/rc.d/init.d/目录下各个Shell脚本的符号连接,而这些脚本一般能接受start、stop、restart、status等参数。rc脚本以start参数启动所有以S开头的脚本,在此之前,如果相应的脚本也存在K打头的链接,而且已经处于运行态了(以/var/lock/subsys/下的文件作为标志),则将首先启动K开头的脚本,以stop作为参数停止这些已经启动了的服务,然后再重新运行。显然,这样做的直接目的就是当init改变运行级别时,所有相关的服务都将重启,即使是同一个级别。
rc程序执行完毕后,系统环境已经设置好了,下面就该用户登录系统了。
getty和login
在rc返回后,init将得到控制,并启动mingetty(见第五节)。mingetty是getty的简化,不能处理串口操作。getty的功能一般包括:
- 打开终端线,并设置模式
- 输出登录界面及提示,接受用户名的输入
- 以该用户名作为login的参数,加载login程序
注:用于远程登录的提示信息位于/etc/issue.net中。
login程序在getty的同一个进程空间中运行,接受getty传来的用户名参数作为登录 的用户名。
如果用户名不是root,且存在/etc/nologin文件,login将输出nologin文件的内容, 然后退出。这通常用来系统维护时防止非root用户登录。
只有/etc/securetty中登记了的终端才允许root用户登录,如果不存在这个文件, 则root可以在任何终端上登录。/etc/usertty文件用于对用户作出附加访问限制,如果 不存在这个文件,则没有其他限制。
当用户登录通过了这些检查后,login将搜索/etc/passwd文件(必要时搜索 /etc/shadow文件)用于匹配密码、设置主目录和加载shell。如果没有指定主目录,将 默认为根目录;如果没有指定shell,将默认为/bin/sh。在将控制转交给shell以前, getty将输出/var/log/lastlog中记录的上次登录系统的信息,然后检查用户是否有新 邮件(/usr/spool/mail/{username})。在设置好shell的uid、gid,以及TERM,PATH 等环境变量以后,进程加载shell,login的任务也就完成了。
bash
运行级别3下的用户login以后,将启动一个用户指定的shell,以下以/bin/bash为例继续我们的启动过程。
bash是Bourne Shell的GNU扩展,除了继承了sh的所有特点以外,还增加了很多特 性和功能。由login启动的bash是作为一个登录shell启动的,它继承了getty设置的TERM、PATH等环境变量,其中PATH对于普通用户为"/bin:/usr/bin:/usr/local/bin",对于root 为"/sbin:/bin:/usr/sbin:/usr/bin"。作为登录shell,它将首先寻找/etc/profile 脚本文件,并执行它;然后如果存在~/.bash_profile,则执行它,否则执行 ~/.bash_login,如果该文件也不存在,则执行~/.profile文件。然后bash将作为一个 交互式shell执行~/.bashrc文件(如果存在的话),很多系统中,~/.bashrc都将启动 /etc/bashrc作为系统范围内的配置文件。
当显示出命令行提示符的时候,整个启动过程就结束了。此时的系统,运行着内核, 运行着几个核心线程,运行着init进程,运行着一批由rc启动脚本激活的守护进程(如 inetd等),运行着一个bash作为用户的命令解释器。
附:XDM方式登录
如果缺省运行级别设为5,则系统中不光有1-6个getty监听着文本终端,还有启动了一个XDM的图形登录窗口。登录过程和文本方式差不多,也需要提供用户名和口令,XDM 的配置文件缺省为/usr/X11R6/lib/X11/xdm/xdm-config文件,其中指定了 /usr/X11R6/lib/X11/xdm/xsession作为XDM的会话描述脚本。登录成功后,XDM将执行这个脚本以运行一个会话管理器,比如gnome-session等。
除了XDM以外,不同的窗口管理系统(如KDE和GNOME)都提供了一个XDM的替代品,如gdm和kdm,这些程序的功能和XDM都差不多。
根文件系统
什么是根文件系统
然后来解释一下“根文件系统”这个名词的基本概念。同样引自百度百科的解释:
根文件系统首先是内核启动时所mount的第一个文件系统,内核代码映像文件保存在根文件系统中,而系统引导启动程序会在根文件系统挂载之后从中把一些基本的初始化脚本和服务等加载到内存中去运行。
展开来细说就是,根文件系统首先是一种文件系统,该文件系统不仅具有普通文件系统的存储数据文件的功能,但是相对于普通的文件系统,它的特殊之处在于,它是内核启动时所挂载(mount)的第一个文件系统,内核代码的映像文件保存在根文件系统中,系统引导启动程序会在根文件系统挂载之后从中把一些初始化脚本(如rcS,inittab)和服务加载到内存中去运行。我们要明白文件系统和内核是完全独立的两个部分。在嵌入式中移植的内核下载到开发板上,是没有办法真正的启动Linux操作系统的,会出现无法加载文件系统的错误。
根文件系统为什么这么重要
根文件系统之所以在前面加一个”根“,说明它是加载其它文件系统的”根“,那么如果没有这个根,其它的文件系统也就没有办法进行加载的。
根文件系统包含系统启动时所必须的目录和关键性的文件,以及使其他文件系统得以挂载(mount)所必要的文件。例如:
init进程的应用程序必须运行在根文件系统上;
根文件系统提供了根目录“/”;
linux挂载分区时所依赖的信息存放于根文件系统/etc/fstab这个文件中;
shell命令程序必须运行在根文件系统上,譬如ls、cd等命令;
总之:一套linux体系,只有内核本身是不能工作的,必须要rootfs(上的etc目录下的配置文件、/bin /sbin等目录下的shell命令,还有/lib目录下的库文件等···)相配合才能工作。
Linux启动时,第一个必须挂载的是根文件系统;若系统不能从指定设备上挂载根文件系统,则系统会出错而退出启动。成功之后可以自动或手动挂载其他的文件系统。因此,一个系统中可以同时存在不同的文件系统。在 Linux 中将一个文件系统与一个存储设备关联起来的过程称为挂载(mount)。使用 mount 命令将一个文件系统附着到当前文件系统层次结构中(根)。在执行挂装时,要提供文件系统类型、文件系统和一个挂装点。根文件系统被挂载到根目录下“/”上后,在根目录下就有根文件系统的各个目录,文件:/bin /sbin /mnt等,再将其他分区挂接到/mnt目录上,/mnt目录下就有这个分区的各个目录和文件。
rootfs是基于内存的文件系统,所有操作都在内存中完成;也没有实际的存储设备,所以不需要设备驱动程序的参与。基于以上原因,linux在启动阶段使用rootfs文件系统,当磁盘驱动程序和磁盘文件系统成功加载后,linux系统会将系统根目录从rootfs切换到磁盘文件系统。
(sysfs用来记录和展示linux驱动模型,sysfs先于rootfs挂载是为全面展示linux驱动模型做好准备??
sysfs - a filesystem for exporting kernel objects
The sysfs filesystem is a pseudo-filesystem which provides an
interface to kernel data structures. (More precisely, the files and
directories in sysfs provide a view of the kobject structures defined
internally within the kernel.) The files under sysfs provide
information about devices, kernel modules, filesystems, and other
kernel components.
The sysfs filesystem is commonly mounted at /sys. Typically, it is
mounted automatically by the system, but it can also be mounted
manually using a command such as:
mount -t sysfs sysfs /sys
ls /sys/
block bus class dev devices firmware fs hypervisor kernel module power
)
关于Linux启动时挂载rootfs的几种方式
一直对Linux启动时挂载根文件系统的过程存在着很多疑问,今天在水木精华区找到了有用的资料,摘录如下:
1、Linux启动时,经过一系列初始化之后,需要mount 根文件系统,为最后运行init进程等做准备,mount 根文件系统有这么几种方式:
1)文件系统已经存在于硬盘(或者类似的设备)的某个分区上了,kernel根据启动的命令行参数(root=/dev/xxx),直接进行mount。 这里有一个问题,在root文件系统本身还不存在的情况下,kernel如何根据/dev/xxx来找到对应的设备呢?注意:根文件系统和其他文件系统的mount方式是不一样的,kernel通过直接解析设备的名称来获得设备的主、从设备号,然后就可以访问对应的设备驱动了。所以在init/main.c中有很长一串的root_dev_names(如hda,hdab,sda,sdb,nfs,ram,mtdblock……),通过这个表就可以根据设备名称得到设备号。注意,bootloader或内核中设定的启动参数(root=/dev/xxx)只是一个代号,实际的根文件系统中不一定存在这个设备文件!
2)从软驱等比较慢的设备上装载根文件系统,如果kernel支持ramdisk,在装载root文件系统时,内核判断到需要从软盘(fdx)mount(root=/dev/fd0),就会自动把文件系统映象复制到ramdisk,一般对应设备ram0,然后在ram0上mount根文件系统。 从源码看,如果kernel编译时没有支持ramdisk,而启动参数又是root=/dev/fd0,系统将直接在软盘上mount,除了速度比较慢,理论上是可行的(没试过,不知道是不是这样?)
3)启动时用到initrd来mount根文件系统。注意理解ramdisk和initrd这两个概念,其实ramdisk只是在ram上实现的块设备,类似与硬盘操作,但有更快的读写速度,它可以在系统运行的任何时候使用,而不仅仅是用于启动;initrd(boot loaderinitialized RAMdisk)可以说是启动过程中用到的一种机制,具体的实现过程也使用ramdisk技术。就是在装载linux之前,bootloader可以把一个比较小的根文件系统的映象装载在内存的某个指定位置,姑且把这段内存称为initrd(这里是initrd所占的内存,不是ramdisk,注意区别),然后bootloader通过传递参数的方式告诉内核initrd的起始地址和大小(也可以把这些参数编译在内核中),在启动阶段就可以暂时的用initrd来mount根文件系统。initrd的最初的目的是为了把kernel的启动分成两个阶段:在kernel中保留最少最基本的启动代码,然后把对各种各样硬件设备的支持以模块的方式放在initrd中,这样就在启动过程中可以从initrd所mount的根文件系统中装载需要的模块。这样的一个好处就是在保持kernel不变的情况下,通过修改initrd中的内容就可以灵活的支持不同的硬件。在启动完成的最后阶段,根文件系统可以重新mount到其他设备上,但是也可以不再 重新mount(很多嵌入式系统就是这样)。initrd的具体实现过程是这样的:bootloader把根文件系统映象装载到内存指定位置,把相关参数传递给内核,内核启动时把initrd中的内容复制到ramdisk中(ram0),把initrd占用的内存释放掉,在ram0上mount根文件系统。从这个过程可以看出,内核需要对同时对ramdisk和initrd的支持(这种需要都编入内核,不能作为模块)。
2、嵌入式系统根文件系统的一种实现方法:对于kernel和根文件系统都存储在flash中的系统,一般可以利用linux启动的initrd的机制。具体的过程前面已经比较清楚了,还有一点就是在启动参数中传递root=/dev/ram0,这样使得用initrd进行mount的根文件系统不再切换,因为这个时候实际的设备就是ram0。还有就是initrd的起始地址参数为虚拟地址,需要和bootloader中用的物理地址对应。

