ceph monitor----初始化和选举
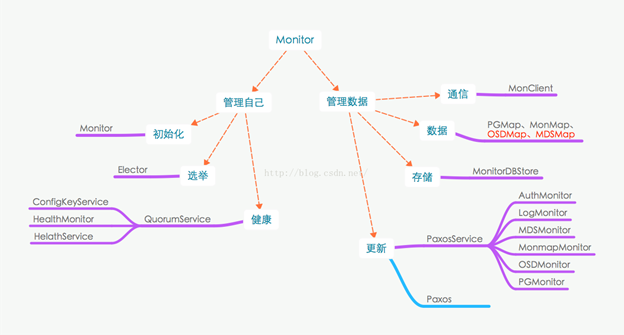

Monitor的初始化
Monitor的启动过程,相对比较简单,具体过程参见ceph_mon.cc这个源码文件。大概可以分为以下几部分:
- 介绍ceph_mon命令能够处理的参数以及使用方法
- 根据配置文件指定的mon_data目录创建名为store的MonitorDBStore实例并且打开数据目录。判断当前数据目录的使用情况是否超过报警限制。并且读出store的magic number确保store是正常的。
- mon第一次启动时,会执行mkfs操作构建monmap,之后的启动从store中读出monmap,并从中获取mon的ip地址以后Messengerbind使用以及mon的rank值。所以如果第一次mon配置错误,后续修改mon的配置文件,重新再启动mon是不会生效的。
- 创建一个Monitor数据通信的Messenger,并且设置messager的policy以及throttler。
- 创建并初始化Monitor实例mon。初始化分为两个阶段preinit()和init(),在preinit()阶段主要初始化了paxos和各个paxosservice以及health_monitor,在init()阶段主要是初始化timer定时器、将monitor添加到dispatcher列表中并进行bootstrap()。从bootstrap()开始也就进入了Monitor的选举流程,这个会在下一节详细介绍。
Monitor进程只创建了一个Messenger,也就意味着它只有一个dispatch_queue和一个dispatcher线程,所有的请求都会排队。另外,Monitor还会初始化一个timer,其会创建一个线程用来处理所有的消息超时event,包括probe、propose、lease等消息,所以这些消息也是串行处理的。这事Monitor中两个真正做事的线程。所以当你在集群中执行命令半天不返回时,八成是因为Monitor的dispatch队列堵有消息排队了,而根本原因可能是Monitor store数据更新缓慢造成的,这有可能是磁盘有问题,也有可能是LevelDB/RocksDB有大量冗余数据导致读取缓慢。
From <https://blog.csdn.net/scaleqiao/article/details/52242345>
每次monitor启动时都会按照monmap中的服务器地址去连接其他monitor服务器,并同步数据。这里有两种情况,一种是db中不存在monmap(需要执行mkfs重新产生),另一种是已经添加过的mon节点由于网络或者其他原因异常,恢复正常后的重启(直接从db中读取)。
很明显所有的节点都会从无到有,因此这里的两种情况其实只是单存的区分获取monmap的方式而已。注意一点:monmap很重要,一旦产生,之后的启动不会再重新配置,因此一定要确保配置的正确性。
From <https://blog.csdn.net/qq_36118718/article/details/79234737>
global_init() [src/global/global_init.cc] 全局初始化
{1
确保只运行一次,执行全局预初始化函数global_pre_init(),解析ceph.conf文件,初始化定义global_context和config全局变量
{2
CephContext *cct = common_preinit(iparams, code_env, flags);
cct->_conf->cluster = cluster;
global_init_set_globals(cct);

md_config_t *conf = cct->_conf;
2}
启动的flag更新 g_ceph_context->set_init_flags(flags)。
错误信号处理器加载,根据g_conf->fatal_signal_handlers决定是否install_standard_sighandlers()。
根据g_conf->log_flush_on_exit决定是否退出时清空log:g_ceph_context->_log->set_flush_on_exit()。
如果不是root用户,若配置了“--setuser root”,不操作?
g_ceph_context->set_uid_gid(uid, gid)。
g_conf->apply_changes(NULL);//更新配置文件的属性??
设置run_dir权限:int r = ::mkdir(g_conf->run_dir.c_str(), 0755)。
内存泄漏检测。
1}
start_service_thread()
main() [src/ceph_mon.cc]
{1
argv_to_vec(argc, argv, args);//把命令行解析插入到vector args中,如果 有-h 或--help,输出usage()。
flags设置。
global_init()
if(mkfs)每次monitor启动会由monmap中服务器地址去连接其他服务器同步数据,若db中不存在monmap,需mkfs重新产生
{2
mon_data目录不存在则创建,检测mon_data是否为空。
pick_addresses() 解析public_address
common_init_finish(g_ceph_context);//创建CephContext 中AdminSocket对象对应的线程
{3
初始化压缩库init_crypto()等。
cct->start_service_thread();//zym 创建AdminSocket对应的线程, Service_thread 启动一些服务类线程,比如:socket_admin线程和RGWAsyncRadosProcessor 和AsyncCompressor::compressor_tp线程等等。
3}
载入或者build_initial(g_ceph_context, oss)根据ceph.conf创建monmap。
检查monmap的quorum中是否有该mon,处理mon的name,addr,port。检查fsid。
MonitorDBStore store(g_conf->mon_data) 建立db,存储mon_data.
创建monitor实例mon :Monitor mon(g_ceph_context, g_conf->name.get_id(), &store, 0, 0, &monmap)
2}
创建子进程??
{4
global_init_prefork(g_ceph_context)
prefork()
global_init_postfork_start(g_ceph_context);
··········
4}
创建信号处理器SignalHandler: init_async_signal_handler()。
注册信号处理器 register_async_signal_handler(SIGHUP, sighup_handler) ??
{5
5}
MonitorDBStore *store = new MonitorDBStore(g_conf->mon_data) 又建一个db??子进程。
读出store的magic number判断store是否正常。
若创建时有--inject-monmap,(write the <filename> monmap to the local monitor store and exit)注入新的monmap?获取注入的monmap,并且获得、写入、保存最新的version的monmap:store->apply_transaction(t)。
{6
6}
有--extract-monmap选项:读取出monmap写到文件中。
决定要bind to的ipaddr:判断monmap中的ipaddr是否和ceph.conf中的一致;若ceph.conf中有不在monmap中的,build_initial。
绑定和messenger建立等:697行~
{7
先get_rank(),rank 代表在monmap中的位置(不在为-1选举时用)。
创建 msgr=messenger: Messenger::create(),创建messenger的policy和throttle机制。
msgr->bind(bind_addr);//绑定到bind_addr。
7}
和mgr模块通信的 Messenger *mgr_msgr = Messenger::create()。
mon = new Monitor(g_ceph_context, g_conf->name.get_id(), store,msgr, mgr_msgr, &monmap);并非新加入的monitor节点是从db中直接获取的了。Monitor 的构造函数里面创建了paxos和各种paxos_service。
mon->preinit();//1.preinit()阶段主要初始化了paxos和各个paxosservice以及health_monitor
{8
检查logger和clusterlogger。paxos初始化logger:paxos->init_logger()。
判断是否加入quorum:has_ever_joined。
保证store的一致性??mon-sync。
init_paxos();//调用paxos->init(),开启几个paxos service
{9
paxos->init() //加载时即从kv读出几个持久化变量last_pn,accepted_pn,last_committed,first_committed,//commit版本决定了是否需要向其他monitor sync数据。last_pn和accepted_pn主要用于paxos解决多个monitor数据一致性。
paxos_service[i]->init() 每个paxosService分别init。
refresh_from_paxos() 更新各服务信息。
9}
如果需要cephx认证,那么要获取keyring。
注册一些admin socket: admin_hook = new AdminHook(this);AdminSocket* admin_socket = cct->get_admin_socket(); register_command()。
8}
msgr->start(); //2.调用messenger->start()
mgr_msgr->start();
mon->init(); //3.初始化timer定时器、将monitor添加到dispatcher列表中并进行bootstrap()。从bootstrap()开始也就进入了Monitor的选举流程
{10
finisher.start();//finisher_thread.create()。
timer.init();// 初始化timer线程。
new_tick();// 加入time事件。
messenger->add_dispatcher_tail(this)。
mgr_client.init();mgr_messenger->add_dispatcher_tail(&mgr_client)。
bootstrap();// 启动.同步数据,建立多数派。
每次monitor server启动时都会按照monmap中的服务器地址去连接其他monitor服务器,并同步数据。
这个过程叫做bootstrap(). bootstrap的第一个目的是补全数据,从其他服务拉缺失的paxos log或
者全量复制数据库,其次是在必要时形成多数派建立一个paxos集群或者加入到已有的多数派中。
{11
rank相关的设置。
state = STATE_PROBING;先进入probing状态。
_reset();// 重置paxos及其服务。
只有一个monitor,没必要联系其他monitor进行leader选举win_standalone_election()。
reset_probe_timeout();//设置probe的时间。
给其他mon发送探测信息:messenger->send_message(new MMonProbe(monmap->fsid, MMonProbe::OP_PROBE, name, has_ever_joined),monmap->get_inst(i))。
11}
10}
1}
|
总结Monitor::bootstrap()做的事
|

https://blog.csdn.net/scaleqiao/article/details/52315468
节点收到的message由Monitor::dispatch_op(MonOpRequestRef op)判定并决定由哪个函数处理。MSG_MON_PROBE
收到OP_PROBE的信息,由handle_probe(op) -> handle_probe_probe(op) 处理
{1
- 如果missing feature,发送OP_MISSING_FEATURES的信息,结束。
- 若message的发送方的版本比自己新,无法通过paxos算法部分做数据修复,需要重新bootstrap()从对方主动拉数据。
- 正常流程,汇报paxos状态,last_commit,first_commit信息,发送OP_REPLY消息。
- 如果发现了一个peer,那么extra_probe_peers.insert(m->get_source_addr())。
1}
发送探测包的monitor节点,在最大超时时间内收到OP_REPLY,会调用handle_probe_reply函数进行下一步处理。
handle_probe(op) -> handle_probe_reply(op)
{1
- 先判断当前monitor所处的状态如果是Probing或者Electing,则直接退出。
- 比对对方的monmap和自己monmap的epoch版本,如果自己的monmap版本低,则更新自己的map,然后重新进入bootstrap()阶段。
- 如果当前Monitor处于synchronizing阶段,则直接返回
- 比对彼此的paxos的版本,如果对方的paxos版本较低,否则判断是否需要进行data的sync。这里有两种情况,如果自己的paxos版本是比对方的paxos_first_version纪录的版本低,则会进行sync操作。如果自己paxos的版本和对方的版本相差太远超过了设置的参数paxos_max_join_drift的值,也会先进行数据的sync而不会触发重新的选举操作。
- 如果从返回的消息中判断已经有一个quorum存在了,自己也在monmap中摒弃自己的ip地址不为空,则直接发起一个选举。否则,会请求加入这个quorum。
- 如果没有现成的quorum,并且自己在monmap中,则把peer添加到outside_quorum的集合中。如果此时outside_quorum中的成员大于等于monmap->size() / 2 + 1时,开始选举,否则返回,等待条件满足。
1}
Monitor::start_election (),在这里主要做了以下几件事。
{1
- 如果Paxos正在STATE_WRITING或者STATE_WRITING_PREVIOUS状态,则等待paxos的更新完成。
- 重置monitor中的服务,包括probe timeout事件、停止时间检查(mon time skew的检查)、health检查事件、scrub事件等,并且restart paxos以及所有的paxos service服务。
- 设置自己进入STATE_ELECTING状态,并增加l_mon_num_elections和l_mon_election_call这些统计数据。
- 调用elector的call_election()。
1}
Elector::call_election (),在这里主要做了以下几件事。
{1
- 从Mon store中读出mon的election_epoch存储在epoch中,更新epoch的值使其变为奇数,表明进入了选举cycle。epoch为偶数,表明已经形成了稳定的quorum。(init()函数)
- 把自己加入到acked_me map中,并设置electing_me为true,希望大家选自己当leader。
- 向monmap中的成员发送MMonElection::OP_PROPOSE消息。
1}
其它的Monitor收到消息后,经过dispatch逻辑,即Monitor:: ms_dispatch() --> Monitor::_ms_dispatch() --> Monitor::dispatch_op()--> Elector::dispatch(),之后进入消息处理流程。
{1
Elector::handle_propose(),首先确保收到消息的epoch版本是处于选举的版本(奇数)并且满足对feature的要求。
接着判断将自己的选举epoch设置为和消息中包含的epoch的值。
最后比对rank值,如果自己的rank值更小,则自己不ack此次选举,而是重新发起一轮选举。
如果自己的rank值更大,则进入Elector::defer()流程,发送MMonElection::OP_ACK消息,ack该轮选举。
1}
发起选举的Monitor收到ACK消息之后Elector::handle_ack(),进入处理流程:
{1
将ACK自己的peer加入到acked_me这个map中,如果acked_me的个数和monmap中成员的个数一样,则表明选举成功,进入victory流程。
这里有点需要搞清楚的是在有一个monitor down的情况下,剩余的monitor是如何选举成功的(acked_me的成员肯定和monmap的成员个数不相等)。
1}
Leader会进入Elector::victory(),具体处理流程如下:
{1
将acked_me中的成员加入到quorum中,并且将election epoch的值加一使其变成偶数,标志选举过程结束。
向quorum中的所有成员发送MMonElection::OP_VICTORY,消息通知大家选举结束。
告诉monitor自己选举成功。
1}
Leader进入Monitor::win_election(),具体处理流程如下:
{1
设置自己的状态为STATE_LEADER,清空outside_quorum中的成员。
调用paxos->leader_init()初始化paxos,以及所有的paxos_service服务。在paxos的初始化中会设置paxos的状态为STATE_RECOVERING,并且调用Paxos::collect()函数,同步mon之间的数据,这个会在后面的Paxos数据更新部分介绍。
启动health_monitor服务,目前主要是检查mon存储空间的使用情况。
启动timecheck检查,确保monitor之间的时差不超过mon_clock_drift_allowed,如果超过就会报告mon clockskew。
更新monitor的metadata,其主要纪录了以下信息:
1}
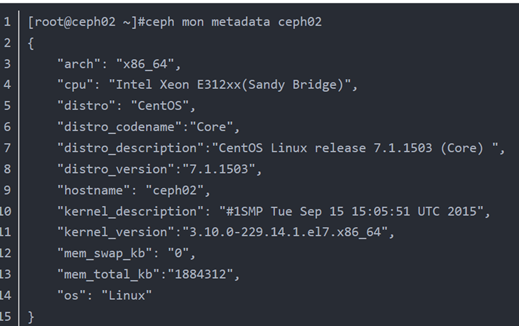
Peon在收到MMonElection::OP_VICTORY消息之后进入Elector::handle_victory(),具体处理流程如下:
{1
将自己的election epoch设置成消息中的epoch值。
进入Monitor::lose_election(),设置自己的状态为STATE_PEON,调用peon_init初始化paxos以及相关的paxosservice,更新logger信息。
取消自己的expire_event时间,即有参数mon_election_timeout控制的时间。
1}
至此,Monitor的选举过程就算结束了,但Paxos的状态还没有进入稳态,所以剩下的事情就是Leader来协调quorum中所有成员的数据同步了,这个主要是通过Paxos协议的两阶段提交机制来完成,整个过程相对比较复杂,会在后续数据更新机制中详细进行介绍。为了方便了解整个选举过程,我将主要的逻辑以时序图的形势展现出来,具体详见下图,图中主要以Leader为主线,给出了选举过程涉及的几个主要文件。
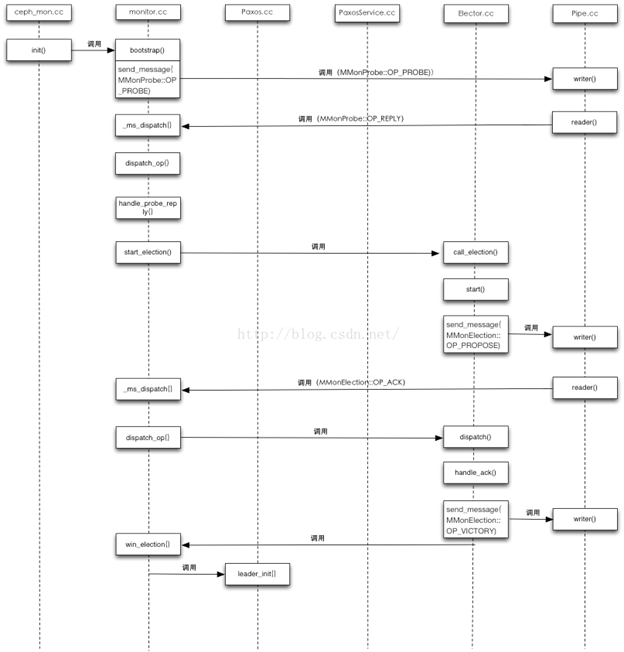

 浙公网安备 33010602011771号
浙公网安备 33010602011771号