【浅谈】 单元最短路径两种算法 & 在路由选择中的应用
- 写在前面:因为能力和记忆有限,为方便以后查阅,特写看上去 “不太正经” 的随笔。随笔有 “三” 随:随便写写;随时看看;随意理解。
注:本篇文章涉及数据结构(图),离散数学,算法,计算机网络相关知识,但都只为加深印象浅层剖析,读者可根据自身情况选择阅读,若求甚解,勿往下读,以免浪费时间。
不知道读者听说过的是哪个版本:单源最短路径,最短道路树,两结点间的最短路径;总的来说,没什么区别,注意与最小生成树 (也称最小支撑树或最小生成/支撑子图) 区分即可。
几种算法:
1.迪杰斯特拉 / 迪科斯彻(Dijkstra)算法:
步骤:
1)选择一个顶点作为起(源)点,用数组 dis[ ] 记录源点到其余各点的最短距离(distance),增加一个已访问(visited)点集 vis[ ],并将起点加入 vis[ ] 集合中;
2)由当前访问结点开始,更新由该点到其余未访问点的距离,若访问点与某点之间的道路不存在,则距离记为 +∞ ,只有当新距离<原来距离时,才能改变相应距离的值dis[ ]
设当前访问结点为 a,对于未访问结点 b 的距离更新,应判断 dis[a] + ab间的道路长度( 记为Edge(a,b) ) < dis[b] 是否成立,成立说明经过a再到b的道路更短,故可将dis[b]的值更新为 dis[a]+Edge(a,b);
3)在未访问点中选择 dis[] 值最小的一个结点,作为下一个访问点并加入vis[ ] 集合中;(可以看到每次选择的点的 dis[ ] 值已经固定)
4)回到步骤2,当所有结点已访问 (即所有点加入vis[ ]数组) 时,跳出循环,算法结束,此时 dis[ ] 数组存储的值即为源点到其它所有点的最短距离。
举个栗子:
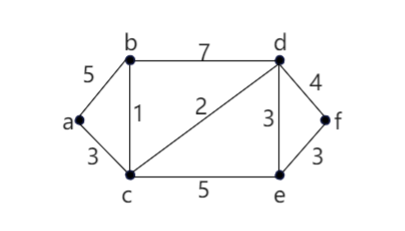
我们以结点a作为起始点,运用上述方法:
| 步骤 | 访问结点 | vis点集 | dis点集(加粗表示已访问) | 准备加入的边 |
| 0(初始化) | / | / |
dis[a]=0,dis[b]=∞ dis[c]=∞,dis[d]=∞ dis[e]=∞,dis[f]=∞ |
/ |
| 1 | a | a |
dis[a]=0,dis[b]=5(new) dis[c]=3(new),dis[d]=∞ dis[e]=∞,dis[f]=∞ |
ac |
| 2 | c | a,c |
dis[a]=0,dis[b]=4(new) dis[c]=3,dis[d]=5 dis[e]=8(new),dis[f]=∞ |
cb |
| 3 | b | a,c,b |
dis[a]=0,dis[b]=4 dis[c]=3,dis[d]=5 dis[e]=8,dis[f]=∞ |
cd |
| 4 | d | a,c,b,d |
dis[a]=0,dis[b]=4 dis[c]=3,dis[d]=5 dis[e]=8,dis[f]=9(new) |
ce |
| 5 | e | a,c,b,d,e |
dis[a]=0,dis[b]=4 dis[c]=3,dis[d]=5 dis[e]=8,dis[f]=9 |
df |
| 6 | f | a,c,b,d,e,f(结束end) |
不难发现每步选择访问的点是未访问结点中 dis[ ] 值最小的,
对于加入边的绘制,却依然要看图分析,这很明显不利于机器输出,这里提供一种解决方案:
加入一个新的数组集合 path[ ] ,记录相应结点的前驱即可,这样对于每个访问点,调用一次path可找到相应加入的边;此外,不断调用path找到前驱,直到path值为起点,就可以描绘出两点间的最短路径。
对于 path[ ] 相关值的更新也是比较巧妙的,表格上dis值中标有new(红色突出)的结点,说明经由当前访问结点后再到这些点的距离更小,进行数据更新,那么其前驱必定是当前访问结点,随之更新即可;
简而言之,初始将所有结点path值设为自身(∀m∈Graph,path[m]=m),设 k 为当前访问结点,对于未曾访问的结点 n,当 dis[k]+Edge(k,n)<dis[n] 成立 (为true) 时,dis[n]=dis[k]+Edge(k,n),path[n]=k;
例中最短道路树为 (见下图红色标注):
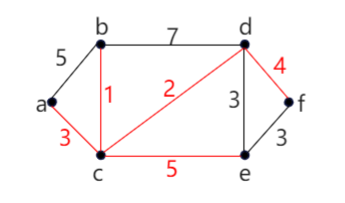
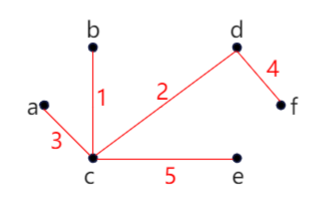
该方法绘制出的是无向树的结构,树是连通且无环的图,属于图的一种特殊形态。
=============相信读到这里的你对dijkstra算法核心部分的代码实现已经有了基本框架============
代码如下(可输入本例数据进行测试,结点名称换成数字编号即可):



// #include<bits/stdc++.h> #include<iostream> using namespace std; void CreateGraph(int m,int n,int** a){//生成无向邻接矩阵图 int u,v; float edge; cout<<"Enter the 1.from 2.to 3.weight:"<<endl; for (int i = 1; i <= n; i++){//initialize the Matrx for (int j = 1; j <= n; j++) a[i][j] = 0x7fffffff; a[i][i]=0; } for(int i=1;i<=m;++i){ cin>>u>>v>>edge; a[u][v]=a[v][u]=edge; } } // used即为visit数组,dist即为distance数组,k为每次所选结点编号; // amount为所有点单源最短路径之和,rec用于寻找路径(相当于path) void Dikjstra(int n,int** a){ int start; cout<<"Finding the lowest cost edge..."<<endl<<"Enter the start number:"; cin>>start;//选择起始点编号 int k,used[n+1]={0},amount=0; int *rec=new int[n+1];//路径数组,记录前驱结点编号 float dist[n+1]; used[start]=1; for(int i=1;i<=n;i++){//初始化,相当于第一个点选的是起点,对其余边松弛 dist[i] = a[start][i]; rec[i]=start; } //*******************执行n-1次,每次选一点同时更新dist值*****************// for(int i=1;i<n;i++){ int tmin = 0x7fffffff; //tmin最开始设置为无穷,然后在其他未选点中遍历dist值,更小则更新 //************该循环执行选点操作***********// for(int j=1;j<=n;j++) if( !used[j] && tmin >dist[j]){ tmin = dist[j]; k = j; //编号也随之更新决定下一次选点 } cout<<"Choose "<<k<<endl; used[k] = 1;//选k点 //**********该循环执行松弛操作更新dist值*********// for(int j=1;j<=n;j++) if(dist[k] + a[k][j] < dist[j] && !used[j]){ dist[j] = dist[k] + a[k][j]; rec[j]=k;//j的前驱为k,即经过k到j } } //************************************************************************// cout<<"dist[] value is:"<<endl; for(int i=1;i<=n;i++){ printf("%f ",dist[i]); amount+=dist[i]; } cout<<endl<<"The whole cost is:"<<amount<<endl; } int main(){ int m,n;//边数m,点数n int** a;//邻接矩阵 cout<<"Enter the number of the node & edge..."<<endl; cin>>n>>m; a=new int* [n+1]; for (int i =1; i<=n+1; i++) a[i]=new int[n+1]; CreateGraph(m,n,a); Dikjstra(n,a); }
算法分析:
Dijkstra算法每一步选择dis值最小的点作为局部最优解,不考虑子问题的解(贪心与动态规划的区别在此),属于贪心算法。
因此对于(所有)贪心算法,我们可以采用以下格式分析,框架部分就不列举了,直接拿该实例品尝:
①贪心策略:对于带权图,规定Edge(i,j)表示 i 到 j 的距离,即边权,且所有权重非负,dis[ ]表示只经过vis(已访问)点集,各点相对于起点的最短路径长度,short[ ]表示完整图上各点相对起点的最短距离。设 s 为起始点。
②命题:当算法进行至第 k 步时,对于vis中每个结点 i,有dis[ i ] = short[ i ]。
③对命题的证明:采用步数归纳法。
当k=1时,vis中只有点s,dis[s]=short[s]=0;
设算法进行至第 k 步时,命题成立,即dis[k]=short[k],验证k+1步:
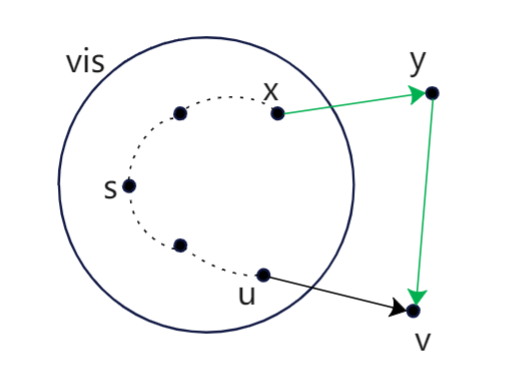
如图所示,vis点集为圈内所示,虚线为目前vis数组选择点组成的最短道路树。假设用该算法选择的是v点,对应最后一次出vis的点是u,可知dis[v]在vis外为最小,但是k+1步算法正确性不可知,不能确定选择v点最优,此类证明中大致都套用反证的思想,不妨假设存在一条新的到v点的道路(绿色箭头标出),使得dis[v]取得最小值,那么此时k+1步选择的不是v,我们假设为y点,对应最后一次出vis点也会随之变化,也不妨假设为x点,由前述条件显然dis[y]>dis[v],那么dis[y]+Edge(y,v)>dis[v]同样成立,此时不能保证dis[v]最小,故第k+1步选择的必定是v点,证毕。
④时间复杂度分析:初始化dis数组花费O(n),对于当前访问结点与所有未访问点间的比较(更新dis值的那部分),vis每次加入一个点,共比较(n-1)+(n-2)+...+2+1=O(n2),综合两部分,时间复杂度为O(n2)。
=============2022-02-07,21:22:57,才疏学浅,多有疏漏,随缘更新============
Dijkstra算法的弊端在于解决不了负边权的问题,这里与大家一起考虑一下,如果存在负边权,那么当目前所访问的结点正好与该边有关的话,与该边关联的另一个结点必定会更新dis值,并且值会比当前访问节点小;这里考虑一下我们的贪心策略,每次选择dis值最小的,后面加入的点的最短道路树会包含前k步生成的最短道路树(这个在上文证明过程中有所体现),后选的结点dis值会更大,但负边权会让dis值不增反减,就不满足dis小的先选的贪心策略,故不可使用Dijkstra算法。
注:真正遇到说明Dijkstra算法局限性时请举例说明!
接下来引入的算法可以解决负边权问题,因为它不是一次选一个点,固定部分子图结构,而是每次考虑所有可能更新dis值的情况,通过松弛操作收敛于正确值。
2.贝尔曼-福特(Bellman-Ford)算法:
Bellman-Ford算法的核心在于松弛操作,其实松弛操作与Dijkstra更新dis值的判断条件无异,区别在于执行对象与次数,下面介绍松弛操作。
松弛操作:
我们一般称对图上的某边进行松弛操作,记该边Edge(u,v),u为起点,v为终点,边松弛操作即是判断经过该边是否更短,即dis值更小。
这一块代码反而更容易理解:
void Relax(u,v){//Relax方法/函数,就是以u为中间结点判断uv边加入后dis[v]值是否更新 if(dis[v]>dis[u]+Edge(u,v)){ dis[v]=dis[u]+Edge(u,v); path[v]=u; } }
Bellman-Ford算法就是对每一条边进行松弛操作,重复n-1次,得到更新后的dis值;最后再对每一条边执行松弛操作判断是否存在总长为负值的环路,并将该环上及该环可达的结点dis值修改为 -∞ 即可,也可直接让该算法返回False。
步骤:
1)选择起点并初始画图,dis值初始化与Dijkstra一样,可见DIjkstra实例表格第0步
2)n-1次重复对每条边进行松弛操作,这里使用伪代码说明:
1 for i=1 to n-1: 2 for each Edge(u,v) in Graph: 3 Relax(u,v)//可直接替换为松弛相应代码
3)负权环的检查与判断:
1 for each Edge(u,v) in Graph: 2 if dis[v]>dis[u]+Edge(u,v)://判断条件与松弛操作相同 3 return FALSE //执行的操作不同
实例1(以Dijkstra中使用栗子为例):
step1:Initialize 初始化
为方便起见,之后把记录表称为备忘录。
| a为起点的距离记录表 | dis[a] | dis[b] | dis[c] | dis[d] | dis[e] | dis[f] |
| a -> others | 0 | ∞ | ∞ | ∞ | ∞ | ∞ |
step2:First Relax of the Graph 整个图的第一次松弛
要点:1.每次松弛一条边,对每一条边都要进行一次松弛操作,顺序可自定
2.dis值的更新可以在当前备忘录基础上改,这样每次松弛操作的结果会有所不同,但整个算法结束后会得到相同的结果
3.第2点的操作完全正确,但为了方便起见,我们每次更新dis时只使用上一个step的备忘录,也就是把更新的值记录到新的备忘录中,当整个图遍历完成后生成新的备忘录
不妨执行一次step2试试:
以初始的备忘录为参照,假设松弛顺序为 ab,ba,ac,ca,bc,cb,bd,db,cd,dc,ce,ec,de,ed,df,fd,ef,fe
其中只有ab,ac的松弛更新了dis值:
①ab(a到b,对应Relax中的u,v):dis[b]=+∞,dis[a]+Edge(a,b)=0+5=5;得dis[b]>dis[a]+Edge(a,b),更新dis[b]对应值于下表。进行下一条边松弛时依然用初始的备忘录,更新数据只对下一个step有效,以此类推。
②ba(b到a,对应Relax中的u,v):dis[a]=0,dis[b]+Edge(b,a)=+∞+5=+∞;得dis[a]<dis[b]+Edge(b,a),不满足更新条件,dis[a]值不变,写入新表。进行下一条边松弛时依然用初始的备忘录,新备忘录数据只对下一个step有效,以此类推。
③ac(a到c,对应Relax中的u,v):dis[c]=+∞,dis[a]+Edge(a,c)=0+3=3;得dis[c]>dis[a]+Edge(a,c),更新dis[c]对应值于下表。进行下一条边松弛时依然用初始的备忘录,更新数据只对下一个step有效,以此类推。
④ca之后就不作详细分析,step2执行一次后生成的新备忘录如下表所示:
| a为起点的距离记录表 | dis[a] | dis[b] | dis[c] | dis[d] | dis[e] | dis[f] |
| a -> others | 0 | 5 | 3 | ∞ | ∞ | ∞ |
step3:Loop 重复step2直至step2执行n-1次,生成第n个备忘录作为新备忘录。
step4:Check Negative Circle 判断负权环
要点:对图的每一条边进行与松弛操作等同的条件判断,满足条件返回FALSE;换句话说,就是再执行一次step2,如果还有dis值更新(满足更新条件判断),就返回FALSE
本例最终结果如下表所示,结果与Dijkstra算法一样,不存在负权环,返回TRUE。
| a为起点的距离记录表 | dis[a] | dis[b] | dis[c] | dis[d] | dis[e] | dis[f] |
| a -> others | 0 | 4 | 3 | 5 | 8 | 9 |
实例2(为了理解记忆的极简例子):
 图片来源于百度百科,个人觉得不错就借用了。
图片来源于百度百科,个人觉得不错就借用了。
第1行初始化,2,3,4,5行执行了4次例一中的step2。
可见每对图的所有边松弛一次,相当于在上一个step2的基础上多走一步,即累计执行k次step2,新备忘录记录的是从起点到其他点最多走k步(经过k条边)所得到的dis的最小值。
上图:第2行最多可走1步,故只有B可达,对应的dis值更新
第3行最多可走2步,或是说在第2行的基础上再走一步,故只有B、C可达,对应的dis值更新
第4行最多可走3步,第5行最多可走4步
对于顶点数为n的连通图来说,当可行步数为n-1时,可以保证经过最短路径走到所有的点;对于有向图来说,则是保证走到所有可达点。
大多数图在不到n-1步时备忘录就不变了,因为深度不到n-1,不需要走这么多步便可遍历完所有非环路径,本例反而是特殊。
算法分析:
有了实例2的理解基础,下面内容应该也不难掌握。
我们发现Bellman-Ford算法从走1步出发到n-1步,每一次都在上一步的基础上不做选择对每条边松弛,使得步数深度+1,生成新的备忘录。
原问题根据步数划分为若干子问题,并且始终记录下所有最短路径状态给下一步提供重要依据,这种依据就是我们说的备忘录。具有上述特点的Bellman-Ford算法属于动态规划,而动态规划问题最核心的状态转移方程要求我们写出:
dis[v]=min(dis[v],dis[u]+Edge(u,v) ) ------ for each edge u->v
path[v]=u ------ if dis[v]>dis[u]+Edge(u,v)
此外,对于负权环为何可用松弛条件判断不做证明,就简单地理解一下:
已知执行n-1步时我们已经可以画出最短道路树,n个顶点,n-1条边,当再执行一遍时就可找到走n步最短的dis值,此时若某点的dis值更新,说明该点的前驱改变,此时图中必定有环路产生,并且说明经过该环路这点dis值会变小,是负权环,走∞次该环,相应dis值为-∞。
=============2022-02-11,16:36:58,未完待续……============
路由选择问题上的应用:
前言:路由选择问题分为算法与协议两部分,一种协议与一种算法匹配,一定要懂得对号入座。
1.路由选择算法(繁琐的分类是在算法部分):
我们所接触的以下两种算法,都属于动态路由算法,并且都是负载迟钝的,至于第三种分类方式,LS是全局式,DV是分散式路由选择算法。
1)链路状态(Link State,LS)算法:
a.对应OSPF协议
b.全局式路由选择算法,全局网络拓扑结构已知(就是整个图的数据结构)
c.使用Dijkstra算法,详情见算法介绍部分
2)距离向量(Distance-Vector,DV)算法:
a.对应RIP协议
b.分散式路由选择算法,每个点维护本地路由表,信息只能从邻居结点获取(就是根据邻居的路由表计算更新本地路由表)
c.使用Bellman-Ford算法,详情见算法介绍部分
2.路由选择协议(与路由选择算法对应):
1)开放最短路优先协议 (Open Shortest Path First,OSPF):
内部网关协议,基于LS算法,适用于大型网络。
2)路由选择信息协议 (Routing Information Protocol,RIP):
内部网关协议,基于D-V算法,适用于小型网络。
3.练手例题:
1)利用Dijkstra算法找到A到其它点的最短路径及距离

Answer:
| step | visited | dis(B),path(B) | dis(C),path(C) | dis(D),path(D) | dis(E),path(E) | dis(F),path(F) |
| 1 | A | 3,A(choose B) | 5,A | ∞ | ∞ | ∞ |
| 2 | AB | 4,B(choose C) | 5,B | 5,B | ∞ | |
| 3 | ABC | 5,B(choose D) | 5,B | ∞ | ||
| 4 | ABCD | 5,B(choose E) | 7,D | |||
| 5 | ABCDE | 7,D(choose F) | ||||
| 6 | ABCDEF |
每列标有choose的为选定结点,对应值已不再更新,因此下文length值为choose结点dis值,路径只需根据path值不断找前驱即可。
A->B: length=3
A->B->C: length=4
A->B->D: length=5
A->B->E: length=5
A->B->D->F: length=7
2)利用Distance Vector(D-V)算法找到A到其它点的最短路径及距离
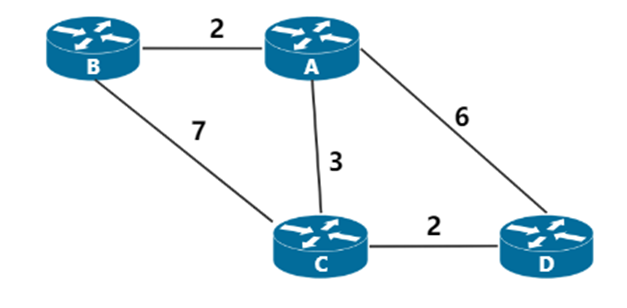
注:此为距离矢量法的第一次完整运算,因此写得比较详细,具体方法步骤参考Bellman-Ford算法部分实例一
超详细解法:
已知该路由选择算法每个结点都会维护一张自己的路由表,由题,要求起点为A,因此迭代完成后只需要取A点的路由表即可。
这里把各路由表分开解释(以行为单位保存各结点路由表更新数据):

这里有几点要事先说明:上图仅用来说明,自己熟练后解题有更快的书写方法;最初保存的路由表应该是深度为1的路由表而不是初始化表,因为初始化表不能完整地表示整个网络的抽象图数据结构(自己试试用第一行能画出来什么,You can try try),可以理解为没有初始化那一步;红字表示数据更新
以A表为例:
初始表如图所示,此时深度为1,仅能从A点走1步:
![]()
若要使其深度+1需要进行松弛操作,而在分散式网络中没有保存各边费用的集合,Bellman-Ford算法中的For each Edge(u,v)需要有所改变,因此我们只能根据从邻居结点获取的数据进行更新操作。
A有B、C、D三个邻居,分别获取它们的路由表:
![]()
然后分别进行计算,
对于表B(即经过B点),先看AB距离为2(见表A),再看B到其他点的距离(见表B),若距离和小于表A中所保存的值,更新A中相应值,并把相应path值更新为B。AB+BC=2+7=9>AC=3,值不变;AB+BD=2+∞>AD=6,值不变。
接着看表C,先看AC距离为3(见表A),再看C到其他点的距离(见表C)。比较AC+CB与AB;AC+CD与AD;可见AC+CD=3+2=5<AD=6,更新表A中的AC值,并设置path[C]=B(C的前驱是B)。
接着看表D,方法同上。
此时表A为深度=2的状态,如图
![]()
对于表BCD深度为2的状态更新方法同A (每个邻居的路由表都要进行判断),B获取的是AC的路由表,C获取的是ABD的路由表,D获取的是AC的路由表;BD不是邻居,不能获取对方的路由表。
迭代至深度为n-1(n为结点数),以达到图的最大深度,深度为n的迭代为判断负权环的操作,一般给的题目不会有负权环,因此路由表不发生变化,避免扣细节分我们选择迭代到深度n,关于迭代次数确定与负权环判断原理请见B-F算法实例二和算法分析部分。
更快地手撕写法:
如果我们把每个结点的路由表整合在一张n阶矩阵内可以简化书写,每生成一个新的矩阵深度+1,如图
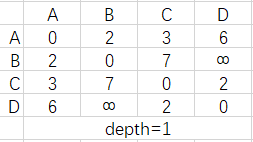
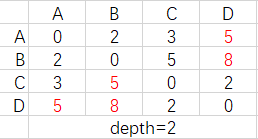

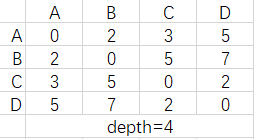
这里根据深度引入一个快速解题法,depth=k表示从每个点至多走k步到其他点,矩阵中的值就是在这个前提下所有路径中的最小值,一般D-V算法的题目结点数都不会太多,甚至是没有doge~,总之以程序化的方式走算法是真心不如直接看来得快。
小插曲:
以上所有内容都能清晰理解记忆,要是不能秒解题目请亲自提刀上门。
==============2022-03-22,14:04:56,完==============


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· AI 智能体引爆开源社区「GitHub 热点速览」