


DS博客作业02--线性表
DS博客作业02--线性表
1.本周学习总结
1.1思维导图

1.2.谈谈你对线性表的认识及学习体会。
线性表因存储结构的不同,分为顺序表和链表。顺序表适合于查找、修改第i个结点的值(其时间复杂度为O(1)),但插入或者删除结点就要每次都移动数组,比较麻烦。链表适合用于插入删除某个结点,比较灵活,也比较绕(小声bb)。
在打pta的过程中,由于大多数都没有注意到一些基础函数,在打编程题的时候就一直各种错误,尤其是初始化链表,一直出现段错误,在链表中还要注意不能出现野指针,所以要提高正确率,最好要学会背代码....
2.PTA实验作业
2.1题目:
设计一个算法,从顺序表中删除重复的元素,并使剩余元素间的相对次序保存不变。
输入格式: 第一行输入顺序表长度。 第二行输入顺序表数据元素。中间空格隔开。
输出格式:数据之间空格隔开,最后一项尾部不带空格。
2.1.1设计思路(伪代码):
设计思路:
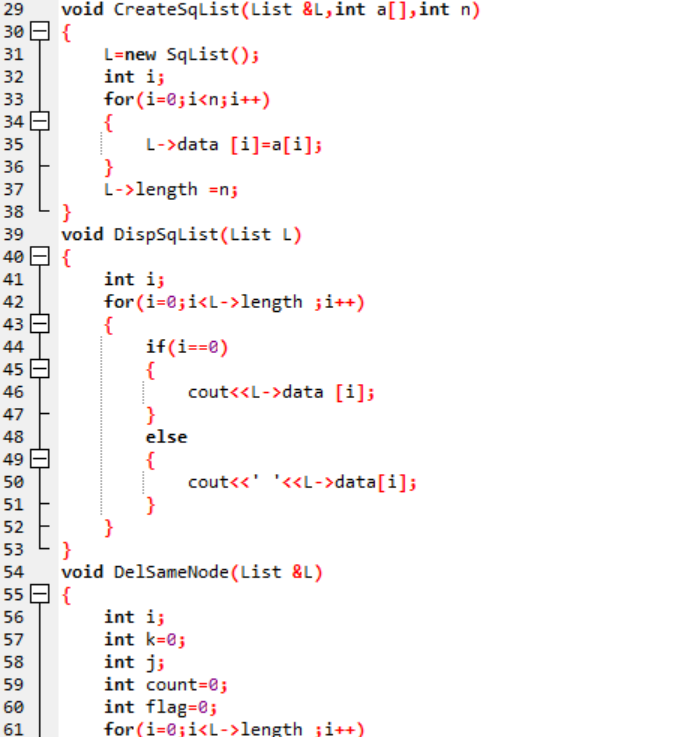
创建顺序表函数:
初始化顺序表;
将n个值一次存入顺序表;
顺序表长度=n;
输出顺序表函数:
数据之间空格隔开,最后一项尾部不带空格
删除顺序表重复元素函数:
用的是重构数组的方法:
for循环遍历顺序表{
再次遍历前面的顺序表:
如果前面已经存在这个数,就直接进入下一个循环;
如果前面不存在这个数,就将这个数放到顺序表中;
记下重复值的个数;
}
顺序表长度=原顺序表长度-重复的个数;
伪代码:
创建顺序表函数:
初始化顺序表;
for i=0 to i<n
将数组中的元素存入顺序表中;
end for
L->length=n;
输出顺序表函数:
for i=0 to i<n
if(i=0)
输出“L->data[0]”;
end if
if i!=0
输出“ L->data[i]”;
end if
end for
删除顺序表重复元素函数:
定义i,j为循环变量;
定义k为重构顺序表的下标;
定义count为顺序表内重复元素的个数,初始化count=0;
for i=0 to L->length
if 是第一个数,即i=0
L->data[k++]=L->data[i];
coutinue;
end if
/*开始遍历之前的顺序表(重构后的)*/
for j=0 to i
if 与前面的顺序表有重复
count++;
break;
end if
如果没有重复
if j=i
存入顺序表
L->data [k++]=L->data [i];
end if
end while
L->length-count;
2.1.2代码截图

2.1.3本题PTA提交列表说明

- Q1:最开始的错误是全部数据都是重复,那么我的做法就会把数据全部删除,一个不留。
- A1:在重构顺序表的时候,第一时间就是不管三七二十一,先把第一个数存入顺序表,这样无论是数据全部重复还是部分重复,都能留下一个重复的元素。
- Q2:第二个问题就是我担心它会不会运行超时(在顺序表长度取到很大很大的时候)
- A2:再加上了各种continue,break,尽量减少循环次数。
- Q3:一种时间复杂度更加小的算法
- A3:哈希数组。代码如下:

但是,我觉得哈希数组也有局限性。第一是顺序表的元素必须全部都是非负数,且要为整数。第二是 我们输入的时候并不知道我们输入的值会有多大,如果超出哈希数组的上限,那就崩了。
2.2题目2:
已知两个递增链表序列L1与L2,2个链表都是带头结点链表。设计函数实现L1,L2的合并,合并的链表仍然递增有序,头结点为L1的头结点。 合并后需要去除重复元素。
输入格式: 输入分两行,先输入数据项个数,再输入数据项,数字用空格间隔。
输出格式: 在一行中输出合并后新的递增链表,数字间用空格分开,结尾不能有多余空格;
2.2.1设计思路(伪代码):
思路:
创建一个新的链表L3
遍历L1和L2(如果有一个指到NULL直接退出)
比较两个链表指针所指的值
将较小的值用尾插法插入链表L3
有较小值的链表指针指向下一个结点
如果还有一个链表没有到达NULL
直接将剩下的都插入链表L3
伪代码:
初始化链表L3;
定义tempL1,tempL2分别为L1,L2的工作指针;
while(tempL1和tempL2的工作指针所指非空)
{
if(tempL1所指的值<tempL2所指的值){
把tempL1所指的值用尾插法插入L3中;
tempL1指向下一个结点;
跳过本轮循环;
}
end if
if(tempL1所指的值>tempL2所指的值){
把tempL2所指的值用尾插法插入L3中;
tempL2指向下一个结点;
跳过本轮循环;
}
end if
if(tempL1所指的值=tempL2所指的值){
把tempL1所指的值(或tempL2)用尾插法插入L3;
tempL1和tempL2都指向下一个结点;
跳过本轮循环;
}
end if
}
end while
再判断tempL1和tempL2是否到达NULL
if(tempL1!=NULL){
tempL1剩下的直接插入L3;
L1=L3;//因为题目最后的要求是利用L1的头结点
return;
}
end if
if(tempL2!=NULL){
tempL2剩下的直接插入L3;
L1=L3;//因为题目最后的要求是利用L1的头结点
return;
}
end if
L1=L3;
return;
2.2.2代码截图


2.2.3本题PTA提交列表说明
- Q1:最开始的时候,出现的段错误。
- A1:没有对L3进行初始化(也就是没有进行new)
- Q2:后来中间的部分错误->内存超限
- A2:因为在复制粘贴上一段的时候,忘记将tempL1改成tempL2。
2.3题目3:
链表L是一个有序的带头结点链表,实现有序链表插入删除操作。
2.3.1设计思路(伪代码):
思路:
插入函数:
遍历链表
if(p所指的值<预备插入的值)
p指到下一个结点;
一直到找到p->data>插入值;
把插入值插到p的前面;
删除函数:
若链表为空
直接return;
遍历链表
若p所指的值!=删除值
p指到下一个结点;
一直到找到p->data=删除值;
如果删除值不再链表中(p=NULL)
输出“找不到输出”;
p->next=p->next->next;
释放删除的结点;
伪代码:
插入函数:
p为遍历指针;
pre保存p的前一个结点;
while(p!=NULL且p<插入值)
{
pre=pre->next;
p=p->next;
}
end while
找到p>插入值
{
申请一个新结点存放插入值;
pre->next=s;
s->next=p;
}
插入函数:
p为遍历指针;
pre保存p的前一个结点;
if(p是空链){
直接return;
}
while(p!=NULL且p!=删除值) {
pre=pre->next;
p=p->next;
}
if(p=NULL){ //没有删除值
输出“找不到”;
直接return;
}
pre->next=p->next;
释放p;
2.3.2代码截图

2.3.3本题PTA提交列表说明

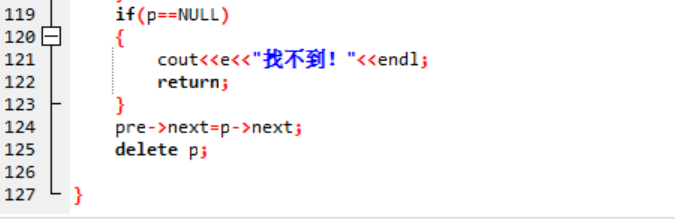
- Q1:其实这一题的操作和思路都是非常简单的,但是出现了段错误!!!(之前的PTA中经过调试,是改对了,然而我在上机考试中在这题上凉凉了,所以我想拿来说一下。)
- A1:段错误的出现是因为老师常说的一个错误——野指针!

这就是段错误的代码,第10行的while判断,如果p指的是NULL,那么p->data也就错误,这个就是问题所在,只要先把p!=NULL 提前就好。 - Q2:再后来是删除全部链表后的测试点过不去。也就是如果我链表一共有3个数 1,2,3.我输入删除的元素为1,2,3,4,它会在删除4的时候,会输出“4 找不到”,这就与样例不符。
- A2:在删除函数的while循环之前再加一个if(p==NULL)的判断,若是空链表,直接返回,不进行下面的操作。
3、阅读代码
3.1 题目
给定一个带有头结点 head 的非空单链表,返回链表的中间结点。
如果有两个中间结点,则返回第二个中间结点。
3.2 解题思路
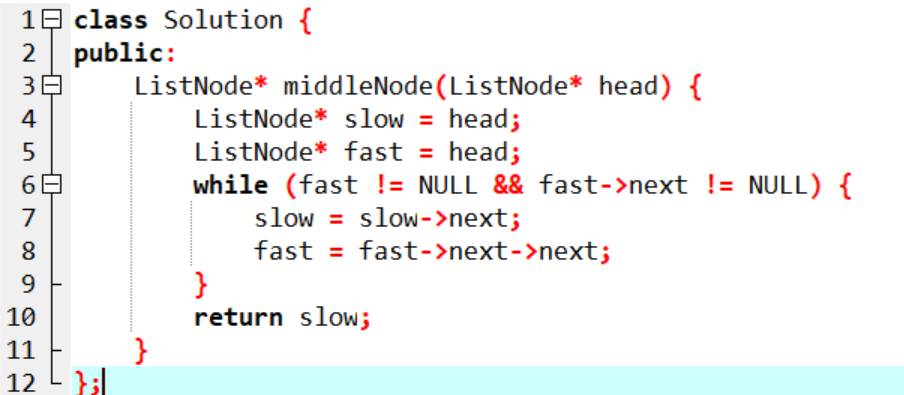
当用慢指针 slow 遍历列表时,让另一个指针 fast 的速度是它的两倍。当 fast 到达列表的末尾时,slow 必然位于中间。
3.3 代码截图
3.4 学习体会
- 其实这道题很简单,初学链表就可以解出来,一般思路是:先遍历一遍链表,记下结点的个数’然后再遍历一次链表,使指针到中间结点停下。其时间复杂度为O(3/2n)。而题解给出的算法很巧妙,巧妙在它的思路:利用快慢指针。slow指针每指向下一个结点,fast指针就指向下下个结点,fast指针的移动速度使slow的两倍,使时间复杂度只有O(n)。
- 运用两个指针来控制指针的移动速度,这个是以前没有想过的思路。现在其实我有一个很大的问题,就是陷入“怎么把题目解出来”,而不是“这题有没有更好、时间复杂度更小的解法”,总结起来就是懒于思考。这样子的下去,在遇到考研题就凉凉了。所以,应该在题目解出来之后,还要去思考最优解。也可以去阅读他人的优秀代码,提高思考能力。
