LVS和keepalived 群集
一、Keepalived工具介绍
1、专为LVS和HA设计的一款健康检查工具
- 支持故障自动切换(Failover)
- 支持节点健康状态检查(Health Checking
- 官方网站:http://www.keepalived.org/
二、Keepalived工作原理
1、工作原理
- Keepalived 是一个基于VRRP协议来实现的LVS服务高可用方案,可以解决静态路由出现的单点故障问
- 在一个LVS服务集群中通常有主服务器(MASTER)和备份服务器(BACKUP)两种角色的服务器,但是对外表现为一个虚拟IP,主服务器会发送VRRP通告信息给备份服务器,当备份服务器收不到VRRP消息的时候,即主服务器异常的时候,备份服务器就会接管虚拟IP,继续提供服务,从而保证了高可用性
三、部署LVS+Keepalived 高可用群集
环境准备
主DR 服务器: 192.168.70.5
备DR 服务器: 192.168.70.10
Web 服务器1: 192.168.70.15
Web 服务器2: 192.168.70.20
nfs 服务器: 192.168.70.25
客户端:192.168.70.30
vip:192.168.70.100
1、配置负载调度器(主、备相同;192.168.70.5;192.168.70.10)
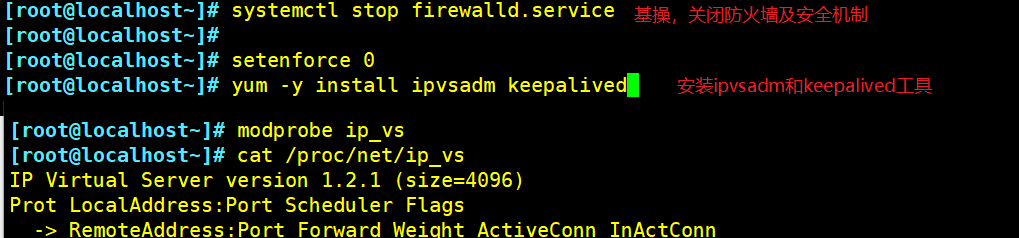
systemctl stop firewalld.service
setenforce 0
yum -y install ipvsadm keepalived
modprobe ip_vs
cat /proc/net/ip_vs
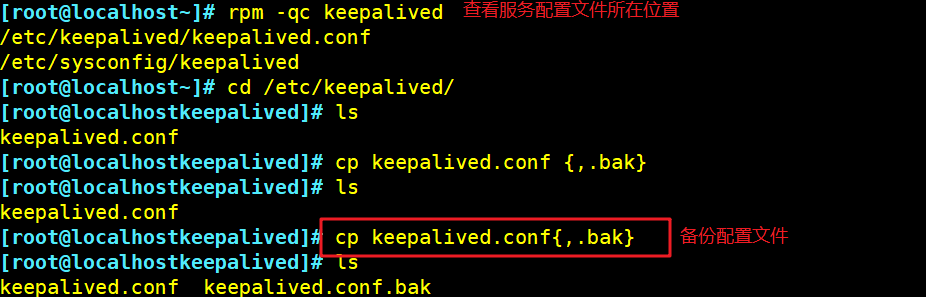
(1)配置keeplived(主、备DR 服务器上都要设置)
cd /etc/keepalived/
cp keepalived.conf keepalived.conf.bak
vim keepalived.conf
......
global_defs { #定义全局参数
--10行--修改,邮件服务指向本地
smtp_server 127.0.0.1
--12行--修改,指定服务器(路由器)的名称,主备服务器名称须不同,主为LVS_01,备为LVS_02
router_id LVS_01
}
vrrp_instance VI_1 { #定义VRRP热备实例参数
--20行--修改,指定热备状态,主为MASTER,备为BACKUP
state MASTER
--21行--修改,指定承载vip地址的物理接口
interface ens33
--22行--修改,指定虚拟路由器的ID号,每个热备组保持一致
virtual_router_id 10
--23行--修改,指定优先级,数值越大优先级越高,主为100,备为99
priority 100
advert_int 1 #通告间隔秒数(心跳频率)
authentication { #定义认证信息,每个热备组保持一致
auth_type PASS #认证类型
--27行--修改,指定验证密码,主备服务器保持一致
auth_pass 123456
}
virtual_ipaddress { #指定群集vip地址
192.168.70.100
}
}
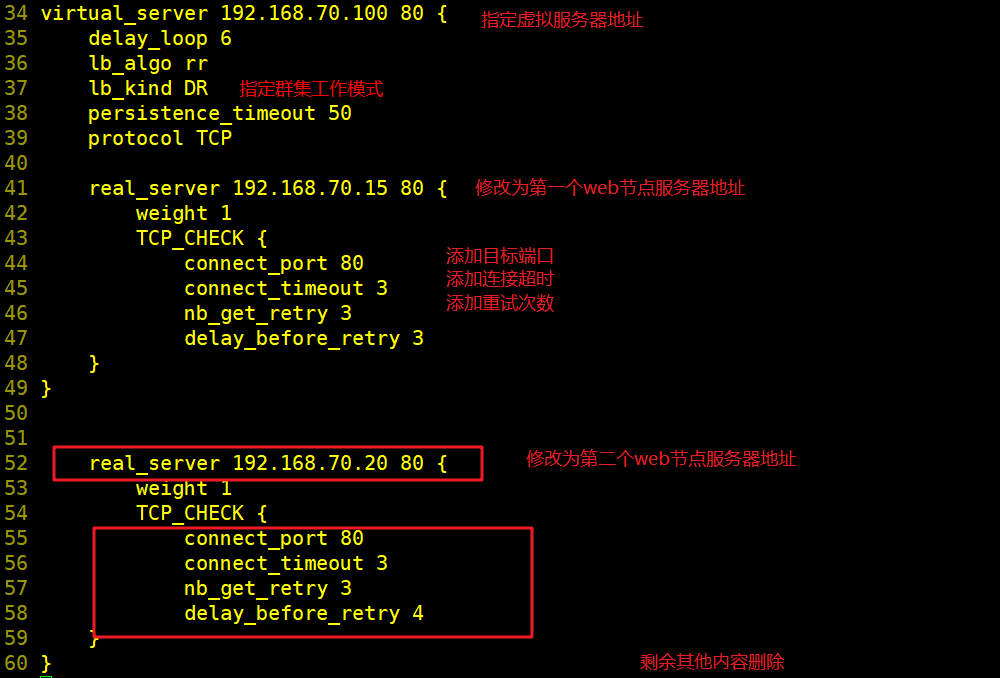
--36行--修改,指定虚拟服务器地址(VIP)、端口,定义虚拟服务器和Web服务器池参数
virtual_server 192.168.70.100 80 {
delay_loop 6 #健康检查的间隔时间(秒)
lb_algo rr #指定调度算法,轮询(rr)
--39行--修改,指定群集工作模式,直接路由(DR)
lb_kind DR
persistence_timeout 50 #连接保持时间(秒)
protocol TCP #应用服务采用的是 TCP协议
--43行--修改,指定第一个Web节点的地址、端口
real_server 192.168.70.15 80 {
weight 1 #节点的权重
--45行--删除,添加以下健康检查方式
TCP_CHECK {
connect_port 80 #添加检查的目标端口
connect_timeout 3 #添加连接超时(秒)
nb_get_retry 3 #添加重试次数
delay_before_retry 3 #添加重试间隔
}
}
real_server 192.168.70.20 80 { #添加第二个 Web节点的地址、端口
weight 1
TCP_CHECK {
connect_port 80
connect_timeout 3
nb_get_retry 3
delay_before_retry 4
}
}
##删除后面多余的配置##
}
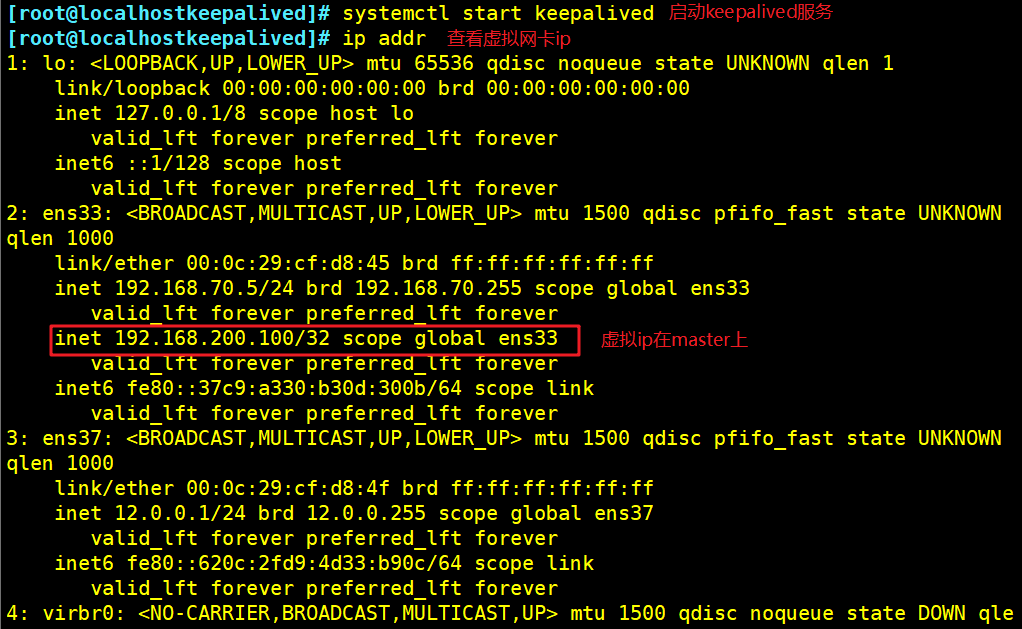
systemctl start keepalived
ip addr show dev ens33 #查看虚拟网卡vip

(2)配置分发策略(#keepalived配置好后,可以不用再配ipvsadm 分发策略)
ipvsadm-save > /etc/sysconfig/ipvsadm
systemctl start ipvsadm
ipvsadm -C
ipvsadm -A -t 192.168.70.100:80 -s rr
ipvsadm -a -t 192.168.70.100:80 -r 192.168.70.15:80 -g
ipvsadm -a -t 192.168.70.100:80 -r 192.168.70.20:80 -g
ipvsadm
ipvsadm -ln
ipvsadm-save > /etc/sysconfig/ipvsadm
#如果没有vip的分发策略。则重启keepalived 服务
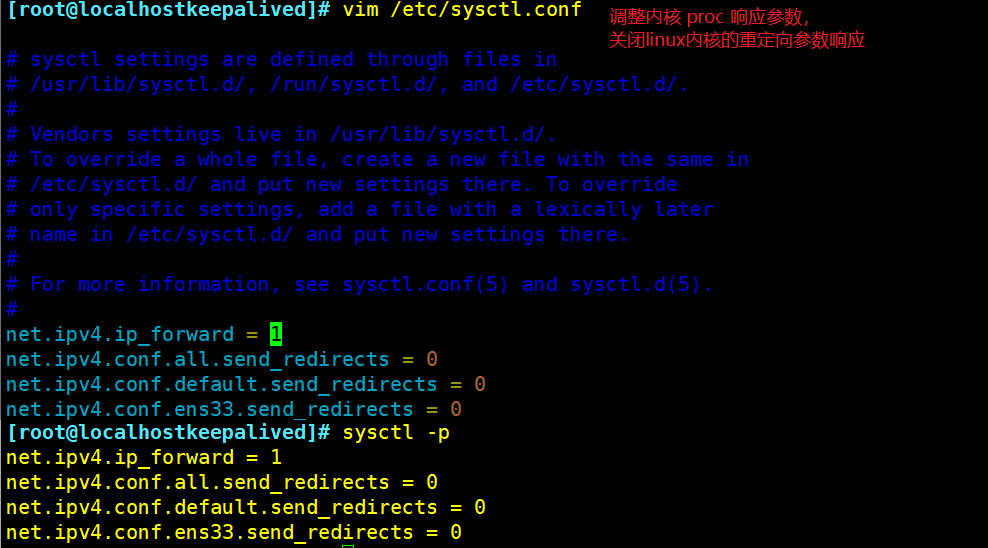
(3) 调整内核 proc 响应参数,关闭linux内核的重定向参数响应
vim /etc/sysctl.conf
net.ipv4.conf.all.send_redirects = 0
net.ipv4.conf.default.send_redirects = 0
net.ipv4.conf.ens33.send_redirects = 0
sysctl -p
注:备负载调度器配置和主负载调度器配置基本相同,贴图就不进行了
2、部署共享存储(NFS服务器:192.168.70.25)
systemctl stop firewalld.service
systemctl disable firewalld.service
setenforce 0
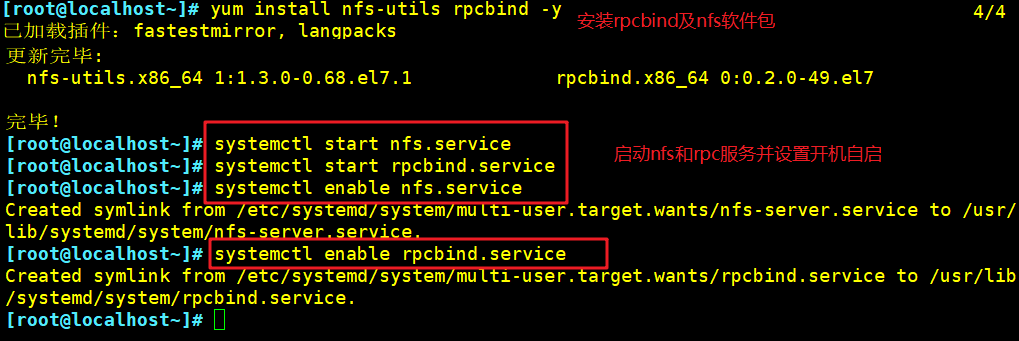
yum install nfs-utils rpcbind -y
systemctl start nfs.service
systemctl start rpcbind.service
systemctl enable nfs.service
systemctl enable rpcbind.service
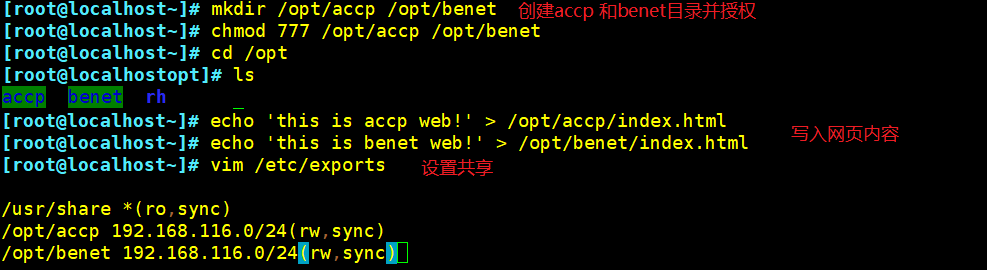
mkdir /opt/accp /opt/benet
chmod 777 /opt/accp /opt/benet
vim /etc/exports
/usr/share *(ro,sync)
/opt/accp 192.168.70.0/24(rw,sync)
/opt/benet 192.168.70.0/24(rw,sync)
--发布共享---
exportfs -rv


3、配置节点服务器(192.168.70.15;192.168.70.20)
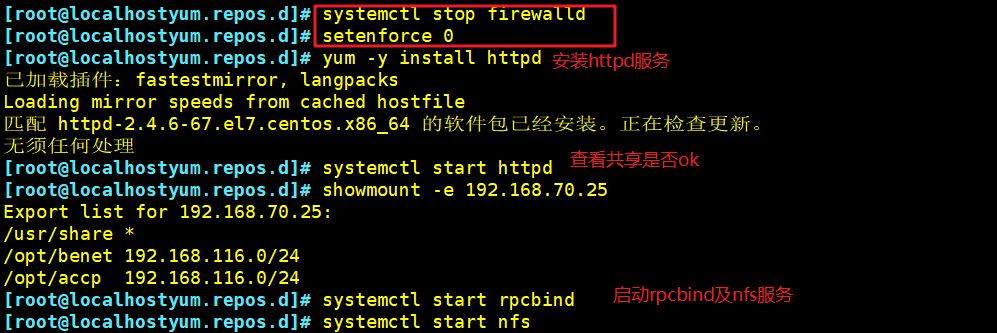
systemctl stop firewalld
setenforce 0
yum -y install httpd
systemctl start httpd
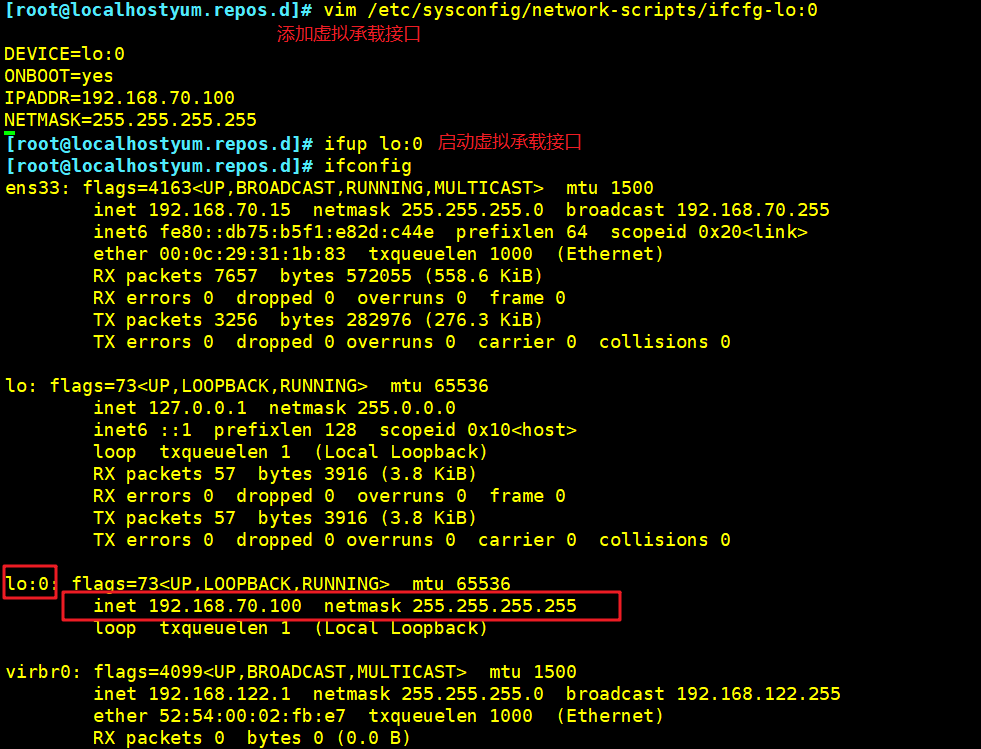
vim /etc/sysconfig/network-scripts/ifcfg-lo:0
DEVICE=lo:0
ONBOOT=yes
IPADDR=192.168.70.100
NETMASK=255.255.255.255
service network restart 或 systemctl restart network
ifup lo:0
ifconfig lo:0
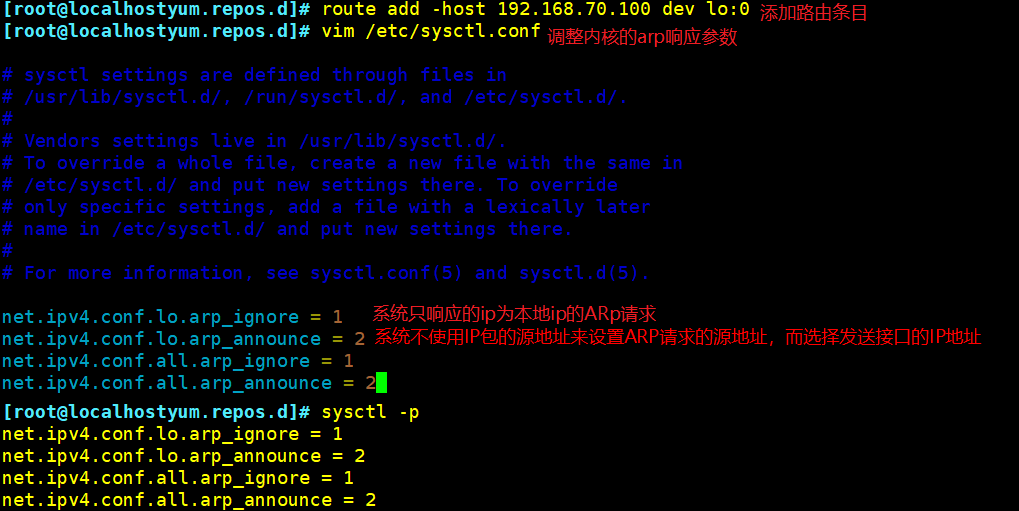
route add -host 192.168.70.100 dev lo:0
vim /etc/sysctl.conf
net.ipv4.conf.lo.arp_ignore = 1
net.ipv4.conf.lo.arp_announce = 2
net.ipv4.conf.all.arp_ignore = 1
net.ipv4.conf.all.arp_announce = 2
sysctl -p
--192.168.70.15---
mount.nfs 192.168.70.25:/opt/accp /var/www/html
--192.168.70.20---
mount.nfs 192.168.70.25:/opt/benet /var/www/html
注:节点服务器配置基本相同,服务器2贴图就不进行了
4、测试验证
-
在客户端访问 http://192.168.70.100/ ,默认网关指向 192.168.70.100
再在主服务器关闭 keepalived 服务后在测试,systemctl stop keepalived
补充:keepalived的抢占与非抢占模式
1、背景
- 俩节点haproxy通过keepalived实现高可用
2、说明
- harpxy的实际运行过程中,当master发生异常,且后期恢复master正常后,存在抢占或非抢占两种情况。简单点说抢占模式就是,当master宕机后,backup 接管服务。后续当master恢复后,vip漂移到master上,master重新接管服务,多了一次多余的vip切换,而在实际生产中是不需要这样。实际生产中是,当 原先的master恢复后,状态变为backup,不接管服务,这是非抢占模式。
3、接下来分4种情况说明
- 俩台都为master时,比如server1的优先级大于server2,keepalived启动后server1获得master,server2自动降级为backup。此时server1宕机的话,server2接替 服务,当server1恢复后,server1又变为master,重新接管服务,server2变为backup。属于抢占式。
- server1为master,server2位backup,且master优先级大于backup。keepalived启动后server1获得master,server2为backup。当server1宕机后, server2接管服务。当server1恢复后,server1重新接管服务变为master,而server2变为backup。属于抢占式
- server1为master,server2位backup,且master优先级低于backup。keepalived启动后server2获得master,server1为backup。当server2宕机后, server1接管服务。此时server2恢复后抢占服务,获得master,server1降级将为backup。属于抢占式
以上3种,只要级别高就会获取master,与state状态是无关的
- server1和server2都为backup。我们要注意启动server服务的启动顺序,先启动的升级为master,与优先级无关。。且配置nopreempt项
比如
- server1获得master权限,server2为backup。此时server1宕机后,server2接管服务升级为master。当server1恢复后权限将为backup,不会争抢 server2的master权限,server2将会继续master权限。属于非抢占式
重点
- 第4种非抢占式俩节点state必须为bakcup,且必须配置nopreempt
注意
- 这样配置后,我们要注意启动服务的顺序,优先启动的获取master权限,与优先级没有关系了
总结
- 抢占模式即MASTER从故障中恢复后,会将VIP从BACKUP节点中抢占过来。非抢占模式即MASTER恢复后不抢占BACKUP升级为MASTER后的VIP

