

第三单元 排序算法
# 排序 LowB 三人组:冒泡排序、选择排序、插入排序。
# 排序 NB 三人组:快速排序、堆排序、归并排序。
# 其他排序:希尔排序、计数排序、基数排序。
排序算法可以分为内部排序和外部排序。
内部排序是数据记录在内存中进行排序。
而外部排序是因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存。
常见的内部排序算法有:插入排序、希尔排序、选择排序、冒泡排序、归并排序、快速排序、堆排序、基数排序等。
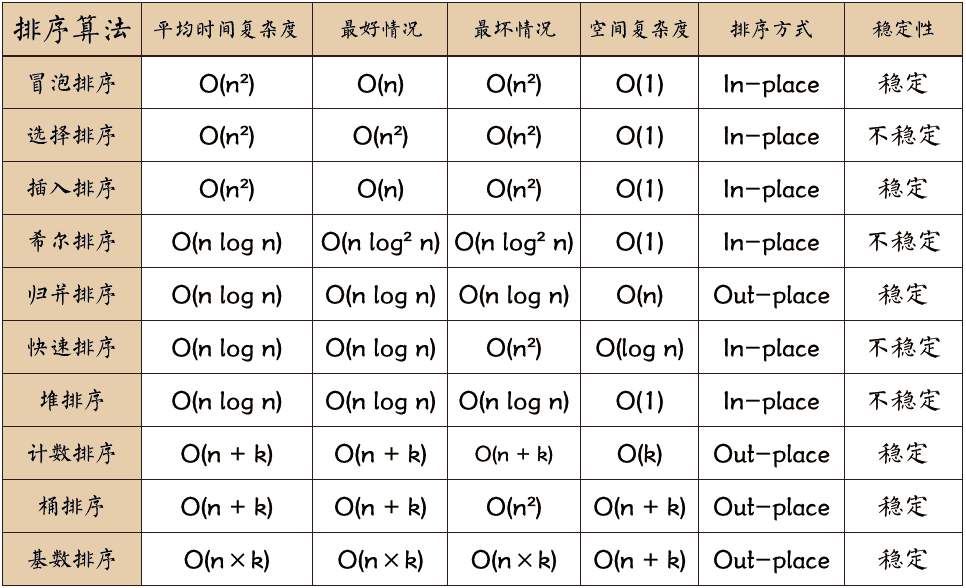
关于时间复杂度:
-
平方阶 (O(n2)) 排序 各类简单排序:直接插入、直接选择和冒泡排序。
-
线性对数阶 (O(nlog2n)) 排序 快速排序、堆排序和归并排序;
-
O(n1+§)) 排序,§ 是介于 0 和 1 之间的常数。 希尔排序
-
线性阶 (O(n)) 排序 基数排序,此外还有桶、箱排序。
关于稳定性:
-
稳定的排序算法:冒泡排序、插入排序、归并排序和基数排序。
-
不是稳定的排序算法:选择排序、快速排序、希尔排序、堆排序。
1. 冒泡排序
冒泡思想:
冒泡排序是通过比较两个相邻元素的大小实现排序,如果前一个元素大于后一个元素,就交换这两个元素。这样就会让每一趟冒泡都能找到最大一个元素并放到最后。
代码实现:
+ (NSArray *)bubbleSort:(NSArray *)unsortDatas {
NSMutableArray *unSortArray = [unsortDatas mutableCopy];
for (int i = 0; i < unSortArray.count -1 ; i++) {
BOOL isChange = NO;
for (int j = 0; j < unSortArray.count - 1 - i; j++) {
// 比较相邻两个元素的大小,后一个大于前一个就交换
if ([unSortArray[j] integerValue] > [unSortArray[j+1] integerValue]) {
NSNumber *data = unSortArray[j+1];
unSortArray[j+1] = unSortArray[j];
unSortArray[j] = data;
isChange = YES;
}
}
if (!isChange) {
// 如果某次未发生数据交换,说明数据已排序
break;
}
}
return [unSortArray copy];
}
冒泡排序的特点:
「 稳定性:它是指对同样的数据进行排序,会不会改变它的相对位置。比如 [ 1, 3, 2, 4, 2 ] 经过排序后,两个相同的元素 2 位置会不会被交换。 」
冒泡排序是比较相邻两个元素的大小,显然不会破坏稳定性。
空间复杂度:由于整个排序过程是在原数据上进行操作,故为 O(1);
时间复杂度:由于嵌套了 2 层循环,故为 O(n*n);
2. 选择排序
选择思想:(不断把最小 / 最大元素放在最后)
选择排序的思想是,依次从「无序列表」中找到一个最小的元素放到「有序列表」的最后面。首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。重复第二步,直到所有元素均排序完毕。
代码实现:
+ (NSArray *)seelectSort:(NSArray *)unsortDatas {
NSMutableArray *unSortArray = [unsortDatas mutableCopy];
for (int i = 0; i < unSortArray.count; i++) {
int mindex = i;
for (int j = i; j < unSortArray.count; j++) {
// 找到最小元素的index
if ([unSortArray[j] integerValue] < [unSortArray[mindex] integerValue]) {
mindex = j;
}
}
// 交换位置
NSNumber *data = unSortArray[i];
unSortArray[i] = unSortArray[mindex];
unSortArray[mindex] = data;
}
return [unSortArray copy];
}
特点
「 稳定性:排序过程中元素是按顺序进行遍历,相同元素相对位置不会发生变化,故稳定。 」
空间复杂度:在原序列进行操作,故为 O( 1 );
时间复杂度:需要 2 次循环遍历,故为 O( n * n );
3. 插入排序
插入思想:
-
将第一待排序序列第一个元素看做一个有序序列,把第二个元素到最后一个元素当成是未排序序列。
-
从头到尾依次扫描未排序序列,将扫描到的每个元素插入有序序列的适当位置。(如果待插入的元素与有序序列中的某个元素相等,则将待插入元素插入到相等元素的后面。)
代码实现:
+ (NSArray *)insertionSort:(NSArray *)unsortDatas {
NSMutableArray *unSortArray = [unsortDatas mutableCopy];
int preindx = 0;
NSNumber *current;
for (int i = 1; i < unSortArray.count; i++) {
preindx = i - 1;
// 必须记录这个元素,不然会被覆盖掉
current = unSortArray[i];
// 逆序遍历已经排序好的数组
// 当前元素小于排序好的元素,就移动到下一个位置
while (preindx >= 0 && [current integerValue] < [unSortArray[preindx] integerValue] ) {
// 元素向后移动
unSortArray[preindx+1] = unSortArray[preindx];
preindx -= 1;
}
// 找到合适的位置,把当前的元素插入
unSortArray[preindx+1] = current;
}
return [unSortArray copy];
}
特点
稳定性:它是从后往前遍历已排序好的序列,相同元素不会改变位置,故为稳定排序;
空间复杂度:它是在原序列进行排序,故为 O ( 1 );
时间复杂度:排序的过程中,首先要遍历所有的元素,然后在已排序序列中找到合适的位置并插入。共需要 2 层循环,故为 O ( n * n );
4. 希尔排序
希尔思想:
核心思想是把一个序列分组,对分组后的内容进行插入排序,这里的分组只是逻辑上的分组,不会重新开辟存储空间。它其实是插入排序的优化版,插入排序对基本有序的序列性能好,希尔排序利用这一特性把原序列分组,对每个分组进行排序,逐步完成排序。
-
选择一个增量序列 t1,t2,……,tk,其中 ti > tj, tk = 1;按增量序列个数 k,对序列进行 k 趟排序;每趟排序,根据对应的增量 ti,将待排序列分割成若干长度为 m 的子序列,分别对各子表进行直接插入排序。仅增量因子为 1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
以 arr = [ 8, 1, 4, 6, 2, 3, 5, 7 ] 为例,通过 floor(8/2) 来分为 4 组,8 表示数组中元素的个数。分完组后,对组内元素进行插入排序。
代码实现:
+ (NSArray *)shellSort:(NSArray *)unsortDatas {
NSMutableArray *unSortArray = [unsortDatas mutableCopy];
// len = 9
int len = (int)unSortArray.count;
// floor 向下取整,所以 gap的值为:4,2,1
for (int gap = floor(len / 2); gap > 0; gap = floor(gap/2)) {
// i=4;i<9;i++ (4,5,6,7,8)
for (int i = gap; i < len; i++) {
// j=0,1,2,3,4
// [0]-[4] [1]-[5] [2]-[6] [3]-[7] [4]-[8]
for (int j = i - gap; j >= 0 && [unSortArray[j] integerValue] > [unSortArray[j+gap] integerValue]; j-=gap) {
// 交换位置
NSNumber *temp = unSortArray[j];
unSortArray[j] = unSortArray[gap+j];
unSortArray[gap+j] = temp;
}
}
}
return [unSortArray copy];
}
特点
稳定性:它可能会把相同元素分到不同的组中,那么两个相同的元素就有可能调换相对位置,故不稳定。
空间复杂度:由于整个排序过程是在原数据上进行操作,故为 O(1);
时间复杂度:希尔排序的时间复杂度与增量序列的选取有关,例如希尔增量时间复杂度为O(n²),而Hibbard增量的希尔排序的时间复杂度为O(log n的3/2),希尔排序时间复杂度的下界是n*log2n
5. 快速排序
快速思想:
核心思想是对待排序序列通过一个「支点」(支点就是序列中的一个元素,别把它想的太高大上)进行拆分,使得左边的数据小于支点,右边的数据大于支点。然后把左边和右边再做一次递归,直到递归结束。支点的选择也是一门大学问,我们以 (左边index + 右边index)/ 2 来选择支点。
以 arr = [ 8, 1, 4, 6, 2, 3, 5, 7 ] 为例,选择一个支点, index= (L+R)/2 = (0+7)/2=3, 支点的值 pivot = arr[index] = arr[3] = 6,接下来需要把 arr 中小于 6 的移到左边,大于 6 的移到右边。
快速排序使用一个高效的方法做数据拆分。
用一个指向左边的游标 i,和指向右边的游标 j,逐渐移动这两个游标,直到找到 arr[i] > 6 和 arr[j] < 6, 停止移动游标,交换 arr[i] 和 arr[j],交换完后 i++,j--(对下一个元素进行比较),直到 i>=j,停止移动。
图中的 L,R 是指快速排序开始时序列的起始和结束索引,在一趟快速排序中,它们的值不会发生改变,直到下一趟排序时才会改变。
代码实现:
/**
快速排序
@param unSortArray 待排序序列
@param lindex 待排序序列左边的index
@param rIndex 待排序序列右边的index
@return 排序结果
*/
+ (NSArray *)quickSort:(NSMutableArray *)unSortArray leftIndex:(NSInteger)lindex rightIndex:(NSInteger)rIndex {
NSInteger i = lindex; NSInteger j = rIndex;
// 取中间的值作为一个支点
NSNumber *pivot = unSortArray[(lindex + rIndex) / 2];
while (i <= j) {
// 向左移动,直到找打大于支点的元素
while ([unSortArray[i] integerValue] < [pivot integerValue]) {
i++;
}
// 向右移动,直到找到小于支点的元素
while ([unSortArray[j] integerValue] > [pivot integerValue]) {
j--;
}
// 交换两个元素,让左边的大于支点,右边的小于支点
if (i <= j) {
// 如果 i== j,交换个啥?
if (i != j) {
NSNumber *temp = unSortArray[i];
unSortArray[i] = unSortArray[j];
unSortArray[j] = temp; }
i++;
j--;
}
}
// 递归左边,进行快速排序
if (lindex < j) {
[self quickSort:unSortArray leftIndex:lindex rightIndex:j];
}
// 递归右边,进行快速排序
if (i < rIndex) {
[self quickSort:unSortArray leftIndex:i rightIndex:rIndex];
}
return [unSortArray copy];
}快速排序的时间复杂度和归并排序一样,O(n log n),但这是建立在每次切分都能把数组一刀切两半差不多大的前提下,如果出现极端情况,比如排一个有序的序列,如[ 9,8,7,6,5,4,3,2,1 ],选取基准值 9 ,那么需要切分 n - 1 次才能完成整个快速排序的过程,这种情况下,时间复杂度就退化成了 O(n2),当然极端情况出现的概率也是比较低的。
所以说,快速排序的时间复杂度是 O(nlogn),极端情况下会退化成 O(n2),为了避免极端情况的发生,选取基准值应该做到随机选取,或者是打乱一下数组再选取。
另外,快速排序的空间复杂度为 O(1)。
6. 归并排序
归并思想:
归并排序,采用分治思想,先把待排序序列拆分成一个个子序列,直到子序列只有一个元素,停止拆分,然后对每个子序列进行边排序边合并。其实,从名字「归并」可以看出一丝「拆、合」的意思(妄加猜测)。
-
申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列;
-
设定两个指针,最初位置分别为两个已经排序序列的起始位置;
-
比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置;
-
重复步骤 3 直到某一指针达到序列尾;
-
将另一序列剩下的所有元素直接复制到合并序列尾。
代码实现:
+ (NSArray *)mergeSort:(NSArray *)unSortArray {
NSInteger len = unSortArray.count;
// 递归终止条件
if (len <= 1) {
return unSortArray;
}
NSInteger mid = len / 2;
// 对左半部分进行拆分
NSArray *lList = [self mergeSort:[unSortArray subarrayWithRange:NSMakeRange(0, mid)]];
// 对右半部分进行拆分
NSArray *rList = [self mergeSort:[unSortArray subarrayWithRange:NSMakeRange(mid, len-mid)]];
// 递归结束后执行下面的语句
NSInteger lIndex = 0;
NSInteger rIndex = 0;
// 进行合并
NSMutableArray *results = [NSMutableArray array];
while (lIndex < lList.count && rIndex < rList.count) {
if ([lList[lIndex] integerValue] < [rList[rIndex] integerValue]) {
[results addObject:lList[lIndex]];
lIndex += 1;
} else {
[results addObject:rList[rIndex]];
rIndex += 1;
}
}
// 把左边剩余元素加到排序结果中
if (lIndex < lList.count) {
[results addObjectsFromArray:[lList subarrayWithRange:NSMakeRange(lIndex, lList.count-lIndex)]];
}
// 把右边剩余元素加到排序结果中
if (rIndex < rList.count) {
[results addObjectsFromArray:[rList subarrayWithRange:NSMakeRange(rIndex, rList.count-rIndex)]];
}
return results;
}
特点
「 稳定性:在元素拆分的时候,虽然相同元素可能被分到不同的组中,但是合并的时候相同元素相对位置不会发生变化,故稳定。 」
空间复杂度:需要用到一个数组保存排序结果,也就是合并的时候,需要开辟空间来存储排序结果,故为 O ( n );
时间复杂度:最好最坏都为 O(nlogn);
7. 计数排序
计数思想:(统计元素的个数)
计数排序的核心思想是把一个无序序列 A 转换成另一个有序序列 B,从 B 中逐个“取出”所有元素,取出的元素即为有序序列。 这种算法比快速排序还要快「特定条件下」,它适用于待排序序列中元素的取值范围比较小。比如对某大型公司员工按年龄排序,年龄的取值范围很小,大约在(10-100)之间。
对数组 arr = [ 8, 1, 4, 6, 2, 3, 5, 4 ] 进行排序,使用计数排序需要找到与其对应的一个有序序列,可以使用数组的下标与 arr 做一个映射「数组的下标恰好是有序的」。
遍历 arr,把 arr 中的元素放到 counArr 中,counArr 的大小是由 arr 中最大元素和最小元素决定的。
算法步骤:
-
花O(n)的时间扫描一下整个序列 A,获取最小值 min 和最大值 max
-
开辟一块新的空间创建新的数组 B,长度为 ( max - min + 1)
-
数组 B 中 index 的元素记录的值是 A 中某元素出现的次数
-
最后输出目标整数序列,具体的逻辑是遍历数组 B,输出相应元素以及对应的个数
代码实现:
+ (NSArray *)countingSort:(NSArray *)datas {
// 1.找出数组中最大数和最小数
NSNumber *max = [datas firstObject];
NSNumber *min = [datas firstObject];
for (int i = 0; i < datas.count; i++) {
NSNumber *item = datas[i];
if ([item integerValue] > [max integerValue]) {
max = item;
}
if ([item integerValue] < [min integerValue]) {
min = item;
}
}
// 2.创建一个数组 countArr 来保存 datas 中元素出现的个数
NSInteger sub = [max integerValue] - [min integerValue] + 1;
NSMutableArray *countArr = [NSMutableArray arrayWithCapacity:sub];
for (int i = 0; i < sub; i++) {
[countArr addObject:@(0)];
}
// 3.把 datas 转换成 countArr,使用 datas[i] 与 countArr 的下标对应起来
for (int i = 0; i < datas.count; i++) {
NSNumber *aData = datas[i];
NSInteger index = [aData integerValue] - [min integerValue];
countArr[index] = @([countArr[index] integerValue] + 1);
}
// 4.从countArr中输出结果
NSMutableArray *resultArr = [NSMutableArray arrayWithCapacity:datas.count];
for (int i = 0; i < countArr.count; i++) {
NSInteger count = [countArr[i] integerValue];
while (count > 0) {
[resultArr addObject:@(i + [min integerValue])];
count -= 1;
}
}
return [resultArr copy];
}
特点
「 稳定性:在元素往 countArr 中记录时按顺序遍历,从 countArr 中取出元素也是按顺序取出,相同元素相对位置不会发生变化,故稳定。 」
空间复杂度:需要额外申请空间,复杂度为“桶”的个数,故为 O ( k ), k 为“桶”的个数,也就是 countArr 的长度;
时间复杂度:最好最坏都为 O(n+k), k 为“桶”的个数,也就是 countArr 的长度;
8. 桶排序
桶思想:
以 arr = [ 8, 1, 4, 6, 2, 3, 5, 7 ] 为例,排序前需要确定桶的个数,和确定桶中元素的取值范围:
第一步,自行设置桶的个数(此处创建3个空桶)。
每个桶存储元素的平均值space=(max-min+1)/桶数=(8-1+1)/3=2.66。
第二步,依次遍历数组,把数据逐步插入对应的桶中。
第三步,把桶中数据进行重组,即为有序数组。
算法步骤:
-
设置固定数量的空桶。
-
把数据放到对应的桶中。
-
对每个不为空的桶中数据进行排序。
-
拼接不为空的桶中数据,得到结果
代码实现:
+ (NSArray *)bucketSort:(NSArray *)datas {
// 1.找出数组中最大数和最小数
NSNumber *max = [datas firstObject];
NSNumber *min = [datas firstObject];
for (int i = 0; i < datas.count; i++) {
NSNumber *item = datas[i];
if ([item integerValue] > [max integerValue]) {
max = item;
}
if ([item integerValue] < [min integerValue]) {
min = item;
}
}
// 2.创建桶,桶的个数为 3
int maxBucket = 3;
NSMutableArray *buckets = [NSMutableArray arrayWithCapacity:maxBucket];
for (int i = 0; i < maxBucket; i++) {
NSMutableArray *aBucket = [NSMutableArray array];
[buckets addObject:aBucket];
}
// 3.把数据分配到桶中,桶中的数据是有序的
// a.计算桶中数据的平均值,这样分组数据的时候会把数据放到对应的桶中
float space = ([max integerValue] - [min integerValue] + 1) / (maxBucket*1.0);
for (int i = 0; i < datas.count; i++) {
// b.根据数据值计算它在桶中的位置
int index = floor(([datas[i] integerValue] - [min integerValue]) / space);
NSMutableArray *bucket = buckets[index];
int maxCount = (int)bucket.count;
NSInteger minIndex = 0;
for (int j = maxCount - 1; j >= 0; j--) {
if ([datas[i] integerValue] > [bucket[j] integerValue]) {
minIndex = j+1;
break;
}
}
[bucket insertObject:datas[i] atIndex:minIndex];
}
// 4.把桶中的数据重新组装起来
NSMutableArray *results = [NSMutableArray array];
[buckets enumerateObjectsUsingBlock:^(NSArray *obj, NSUInteger idx, BOOL * _Nonnull stop) {
[results addObjectsFromArray:obj];
}];
return results;
}
特点
稳定性:在元素拆分的时候,相同元素会被分到同一组中,合并的时候也是按顺序合并,故稳定。
空间复杂度:桶的个数加元素的个数,为 O ( n + k );
时间复杂度:最好为 O( n + k ),最坏为 O(n * n);
9. 基数排序
基数思想:
基数排序是从待排序序列找出可以作为排序的「关键字」,按照「关键字」进行多次排序,最终得到有序序列。比如对 100 以内的序列 arr = [ 3, 9, 489, 1, 5, 10, 2, 7, 6, 204 ]进行排序,排序关键字为「个位数」、「十位数」和「百位数」这 3 个关键字,分别对这 3 个关键字进行排序,最终得到一个有序序列。
以 arr = [ 3, 9, 489, 1, 5, 10, 2, 7, 6, 204 ] 为例,最大为 3 位数,分别对个、十、百位进行排序,最终得到的序列就是有序序列。可以把 arr 看成 [ 003, 009, 489, 001, 005, 010, 002, 007, 006, 204 ],这样理解起来比较简单。
数字的取值范围为 0-9,故可以分为 10 个桶。
算法步骤:
-
将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零
-
从最低位开始,依次进行一次排序
-
从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列
代码实现:
+ (NSArray *)radixSort:(NSArray *)datas {
NSMutableArray *tempDatas;
NSInteger maxValue = 0;
int maxDigit = 0;
int level = 0;
do {
// 1.创建10个桶
NSMutableArray *buckets = [NSMutableArray array];
for (int i = 0; i < 10; i++) {
NSMutableArray *array = [NSMutableArray array];
[buckets addObject:array];
}
// 2.把数保存到桶中
for (int i = 0; i < datas.count; i++) {
NSInteger value = [datas[i] integerValue];
// 求一个数的多次方
int xx = (level < 1 ? 1 : (pow(10, level)));
// 求个位数、十位数....
int mod = value / xx % 10;
[buckets[mod] addObject:datas[i]];
// 求最大数为了计算最大数
if (maxDigit == 0) {
if (value > maxValue) {
maxValue = value;
}
}
}
// 3.把桶中的数据重新合并
tempDatas = [NSMutableArray array];
for (int i = 0; i < 10; i++) {
NSMutableArray *aBucket = buckets[i];
[tempDatas addObjectsFromArray:aBucket];
}
// 4.求出数组中最大数的位数, 只需计算一次
if (maxDigit == 0) {
while(maxValue > 0){
maxValue = maxValue / 10;
maxDigit++;
}
}
// 5.继续下一轮排序
datas = tempDatas;
level += 1;
} while (level < maxDigit);
return tempDatas;
}
特点
稳定性:在元素拆分的时候,相同元素会被分到同一组中,合并的时候也是按顺序合并,故稳定。
空间复杂度:O ( n + k );
时间复杂度:最好最坏都为 O( n * k );
10. 堆排序(难,看动画理解,多复习)
动画:吴师兄学算法公众号——十大经典排序算法
算法步骤:
-
创建一个堆 H[0……n-1];
-
把堆首(最大值)和堆尾互换;
-
把堆的尺寸缩小 1,并调用 shift_down(0),目的是把新的数组顶端数据调整到相应位置;
-
重复步骤 2,直到堆的尺寸为 1。
参考代码
1//Java 代码实现
2public class HeapSort implements IArraySort {
3
4 @Override
5 public int[] sort(int[] sourceArray) throws Exception {
6 // 对 arr 进行拷贝,不改变参数内容
7 int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);
8
9 int len = arr.length;
10
11 buildMaxHeap(arr, len);
12
13 for (int i = len - 1; i > 0; i--) {
14 swap(arr, 0, i);
15 len--;
16 heapify(arr, 0, len);
17 }
18 return arr;
19 }
20
21 private void buildMaxHeap(int[] arr, int len) {
22 for (int i = (int) Math.floor(len / 2); i >= 0; i--) {
23 heapify(arr, i, len);
24 }
25 }
26
27 private void heapify(int[] arr, int i, int len) {
28 int left = 2 * i + 1;
29 int right = 2 * i + 2;
30 int largest = i;
31
32 if (left < len && arr[left] > arr[largest]) {
33 largest = left;
34 }
35
36 if (right < len && arr[right] > arr[largest]) {
37 largest = right;
38 }
39
40 if (largest != i) {
41 swap(arr, i, largest);
42 heapify(arr, largest, len);
43 }
44 }
45
46 private void swap(int[] arr, int i, int j) {
47 int temp = arr[i];
48 arr[i] = arr[j];
49 arr[j] = temp;
50 }
51
52}
堆排序和快速排序的时间复杂度都一样是 O(nlogn)。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧