Go语言入门学习
Go语言学习笔记
本文主要是go语言的学习笔记,学习go的目的是为后续学习分布式原理打基础,做准备。
本文禁止转载,违者必究!
学习过程中参考的资料已全部放在最后一章参考资料篇。
一、快速入门与基础
go环境安卓和开发编译环境搭建略,可见参考资料中的相关博客、笔记等自行安装
本文使用vscode+go插件进行开发学习
1.1 Hello World
package main
import "fmt"
func main() {
fmt.Println("Hello World!")
}
我们可以在terminal中使用go run命令运行此go程序,运行结果如下:
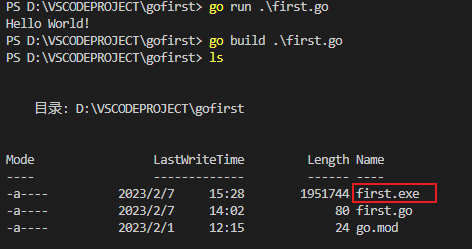
如果想编译,则可以用build子命令:go build ,运行结果见上(Windows系统下生成的可执行文件是helloworld.exe,增加了.exe后缀名)。
Go 语言的基础组成有以下几个部分:
- 包声明
- 引入包
- 函数
- 变量
- 语句 & 表达式
- 注释
以上面的程序为例:
//包声明:
/* Go语言的代码通过包(package)组织,包类似于其它语言里的库(libraries)或者模块(modules)。一个包由位于单个目录下的一个或多个.go源代码文件组成, 目录定义包的作用。每个源文件都以一条package声明语句开始
main包比较特殊。它定义了一个独立可执行的程序,而不是一个库。在main里的main 函数 也很特殊,它是整个程序执行时的入口(C系语言差不多都这样)。main函数所做的事情就是程序做的*/
package main
//包引入
/* 必须告诉编译器源文件需要哪些包,这就是import的作用。hello world例子只用到了一个包,大多数程序需要导入多个包。
同时必须恰当导入需要的包,缺少了必要的包或者导入了不需要的包,程序都无法编译通过。这项严格要求避免了程序开发过程中引入未使用的包。import声明必须跟在文件的package声明之后*/
import "fmt"
//一个函数的声明由func关键字、函数名、参数列表、返回值列表(这个例子里的main函数参数列表和返回值都是空的)以及包含在大括号里的函数体组成
func main() {
//语句&表达式
fmt.Println("Hello World!")
}
Go的标准库提供了100多个包,以支持常见功能,如输入、输出、排序以及文本处理。比如
fmt包,就含有格式化输出、接收输入的函数。Println是其中一个基础函数,可以打印以空格间隔的一个或多个值,并在最后添加一个换行符,从而输出一整行。Go语言不需要在语句或者声明的末尾添加分号,除非一行上有多条语句
如果想使用其他的项目,则需要引入包,并用包名.函数名进行调用,如下新建一个test文件夹,并编写一个Add函数:
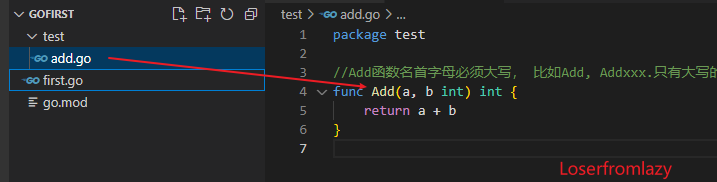
代码如下:
// test/add.go
package test
//Add函数名首字母必须大写, 比如Add, Addxxx.只有大写的才是Public权限,外面的包才能访问,否则只能自己文件夹下代码才能访问
func Add(a, b int) int {
return a + b
}
然后在刚才的first.go中调用:
package main
import (
"fmt"
"gofirst/test"
)
func main() {
a := 1
b := 2
//调用时,前面的这个test是包名,即package.funcName 这种格式进行调用
i := test.Add(a, b)
fmt.Printf("%d + %d = %d ", a, b, i)
}
1.2 go mod
java 里有一个叫 maven 的包管理工具, go 也有一个叫 go mod 的管理工具,可以管理项目引用的第三方包版本、自动识别项目中用到的包、自动下载和管理包。
为什么要使用go mod?
- 使用go mod仓库中可以不用再上传依赖代码包,防止代码仓库过大浪费以及多个项目同时用包时的浪费
- 可以管理引用包的版本,这一点是gopath(src模式)和vendor做不到的
- 如果依赖gopath不同项目如果引用了同一个软件包的不同版本,就会造成编译麻烦
gopath是go之前的默认策略,每个项目在运行时都要严格放在src目录下,而go mod不用
原来的包管理方式
- 在不使用额外的工具的情况下,
Go的依赖包需要手工下载, - 第三方包没有版本的概念,如果第三方包的作者做了不兼容升级,会让开发者很难受
- 协作开发时,需要统一各个开发成员本地
$GOPATH/src下的依赖包 - 引用的包引用了已经转移的包,而作者没改的话,需要自己修改引用。
- 第三方包和自己的包的源码都在
src下,很混乱。对于混合技术栈的项目来说,目录的存放会有一些问题
新的包管理模式解决了以上问题
- 自动下载依赖包
- 项目不必放在
$GOPATH/src内了 - 项目内会生成一个
go.mod文件,列出包依赖 - 所以来的第三方包会准确的指定版本号
- 对于已经转移的包,可以用
replace申明替换,不需要改代码
1.2.1 go mod配置
#打开go mod 模式
go env -w GO111MODULE="on"
#使用国内下载包代理
go env -w GOPROXY=https://proxy.golang.com.cn,direct
#初始化mod项目
go mod init 项目名
#自动增加包和删除无用包到 GOPATH 目录下(build的时候也会自动下载包加入到go.mod里面的)
go mod tidy
然后会自动创建go.mod文件,如下:
module gofirst
go 1.19
内容比较容易理解:
- 第一行:模块的引用路径
- 第二行:项目使用的 go 版本
- 第三行:项目所需的直接依赖包及其版本
实际上可能有更复杂的 go.mod 文件,比如下面这样(来自Go语言精进之路)
module github.com/BingmingWong/module-test go 1.14 require ( example.com/apple v0.1.2 example.com/banana v1.2.3 example.com/banana/v2 v2.3.4 example.com/pear // indirect example.com/strawberry // incompatible ) exclude example.com/banana v1.2.4 replace( golang.org/x/crypto v0.0.0-20180820150726-614d502a4dac = > github.com/golang/crypto v0.0.0-20180820150726-614d502a4dac golang.org/x/net v0.0.0-20180821023952-922f4815f713 = > github.com/golang/net v0.0.0-20180826012351-8a410e7b638d golang.org/x/text v0.3.0 = > github.com/golang/text v0.3.0 )其中exclude和replace的含义如下:
- exclude:忽略指定版本的依赖包
- replace:由于在国内访问golang.org/x的各个包都需要FQ,你可以在go.mod中使用replace替换成github上对应的库。
注意上面的代码片段中出现了两个特殊的注释
incompatible表示不兼容标识,假如其当前版本为v3.6.0,因为其Module名字未遵循Golang所推荐的风格,即Module名中附带版本信息,我们称这个Module为不规范的Module。 在使用上没有区别,如果是我们自己开发的module,需要从xxx.com/xxx变到xxx.com/xxx/v2indirect是指间接依赖的包,比如 a module 使用了 b module,但b module的go.mod不完整,或者未启用 go module的话,会把未记录在b的go.mod中又依赖了的包作为间接依赖,放到a的go.mod文件里
1.2.2 go mod的相关命令
- go mod init:初始化go mod, 生成go.mod文件,后可接参数指定 module 名。
- go mod download:手动触发下载依赖包到本地cache(默认为$GOPATH/pkg/mod目录)
- go mod graph:打印项目的模块依赖结构
- go mod tidy :添加缺少的包,且删除无用的包
- go mod verify :校验模块是否被篡改过
- go mod why:查看为什么需要依赖
- go mod vendor :导出项目所有依赖到vendor下
写入go.mod有两种方法:
- 你只要在项目中有 import 并使用或者使用下划线强制占用,然后 go build 时 go module 就会自动下载并添加。
go mod tidy
1.2.3 go mod tips
-
包会下到哪里?
依赖的第三方包被下载到了
$GOPATH/pkg/mod路径下。 -
GO111MODULE 的三个参数 auto 、 on 、 off的区别?
auto根据是否在src下自动判定,on只用go.mod,off只用src。 -
依赖包中的地址失效了怎么办?比如 golang. org/x/… 下的包都无法下载怎么办?
在
go.mod文件里用replace替换包,例如replace golang.org/x/text => github.com/golang/text latest这样, go会用
github.com/golang/text替代golang.org/x/text -
在 go mod
模式中,项目自己引用自己中的某些模块怎么办?go.mod文件里的第一行会申明
module main,把这个main改为你的项目名,引用的时候就import "项目名/模块名"即可。
根据官方的说法,从
Go 1.13开始,模块管理模式将是 Go 语言开发的默认模式。
1.3 go常量和变量
1.3.1 变量声明与使用
var声明语句可以创建一个特定类型的变量,然后给变量附加一个名字,并且设置变量的初始值。
变量的声明有两种方式:
第一种语法为var 变量名字 类型 = 表达式。例子如下:
var name string
name = "s"
//也可以根据赋值自动判断类型,这里因为name是字符串类型,所以p也是同类型
var p = name
如果要一次声明多个变量,写法如下:
//多变量声明,int类型不赋值自动赋值为0,比如d e f
var a, b, c = 1, 2, 3
var d, e, f int
//类型不同的多个变量,难看的要死
var (
k int
l string
)
//这样好看
var m, n, o = "a", 1, true
第二种方式是精简的写法,如下:
//直接声明并赋值(必须是初次声明才有冒号)
p2 := "as"
// 多个变量一次性声明并赋值
h, i, j := 1, 2, 3
1.3.2 常量声明与使用
常量表达式的值在编译期计算,而不是在运行期。每种常量的潜在类型都是基础类型:boolean、string或数字。
一个常量的声明语句定义了常量的名字,和变量的声明语法类似,常量的值不可修改,这样可以防止在运行期被意外或恶意的修改。例如,常量比变量更适合用于表达像π之类的数学常数,因为它们的值不会发生变化:
const pi = 3.14159 // approximately; math.Pi is a better approximation
和变量声明一样,可以批量声明多个常量;这比较适合声明一组相关的常量:
const (
e = 2.71828182845904523536028747135266249775724709369995957496696763
pi = 3.14159265358979323846264338327950288419716939937510582097494459
)
所有常量的运算都可以在编译期完成,这样可以减少运行时的工作,也方便其他编译优化。当操作数是常量时,一些运行时的错误也可以在编译时被发现,例如整数除零、字符串索引越界、任何导致无效浮点数的操作等。
常量间的所有算术运算、逻辑运算和比较运算的结果也是常量。
一个常量的声明也可以包含一个类型和一个值,但是如果没有显式指明类型,那么将从右边的表达式推断类型。
如果是批量声明的常量,除了第一个外其它的常量右边的初始化表达式都可以省略,如果省略初始化表达式则表示使用前面常量的初始化表达式写法,对应的常量类型也一样的。例如:
const (
a = 1
b
c = 2
d
)
fmt.Println(a, b, c, d) // "1 1 2 2"
如果只是简单地复制右边的常量表达式,其实并没有太实用的价值。但是它可以带来其它的特性,那就是iota常量生成器语法。
1.3.3 iota常量生成器
常量声明可以使用iota常量生成器初始化,它用于生成一组以相似规则初始化的常量,但是不用每行都写一遍初始化表达式。在一个const声明语句中,在第一个声明的常量所在的行,iota将会被置为0,然后在每一个有常量声明的行加一。
下面是来自time包的例子,它首先定义了一个Weekday命名类型,然后为一周的每天定义了一个常量,从周日0开始。在其它编程语言中,这种类型一般被称为枚举类型。
type Weekday int
const (
Sunday Weekday = iota
Monday
Tuesday
Wednesday
Thursday
Friday
Saturday
)
周日将对应0,周一为1,如此等等。
我们也可以在复杂的常量表达式中使用iota,下面是来自net包的例子,用于给一个无符号整数的最低5bit的每个bit指定一个名字:
type Flags uint
const (
FlagUp Flags = 1 << iota // is up
FlagBroadcast // supports broadcast access capability
FlagLoopback // is a loopback interface
FlagPointToPoint // belongs to a point-to-point link
FlagMulticast // supports multicast access capability
)
随着iota的递增,每个常量对应表达式1 << iota,是连续的2的幂,分别对应一个bit位置。使用这些常量可以用于测试、设置或清除对应的bit位的值。
下面是一个更复杂的例子,每个常量都是1024的幂:
const (
_ = 1 << (10 * iota)
KiB // 1024
MiB // 1048576
GiB // 1073741824
TiB // 1099511627776 (exceeds 1 << 32)
PiB // 1125899906842624
EiB // 1152921504606846976
ZiB // 1180591620717411303424 (exceeds 1 << 64)
YiB // 1208925819614629174706176
)
不过iota常量生成规则也有其局限性。例如,它并不能用于产生1000的幂(KB、MB等),因为Go语言并没有计算幂的运算符。
1.4 条件和循环语句
1.4.1 if else
与其他语言都类似,写法如下:
//if写法
if 20>0{
fmt.Println("yes")
}
//if else写法
if 20<0{
}else{
fmt.Println("no")
}
1.4.2 switch
与其他语言都类似,写法如下
switch name {
case "coding3min":
fmt.Println("welcome" + name)
default:
fmt.Println("403 forbidden:" + name)
return
}
和c++不同,不需要给每个case都手动加入break,当然switch语句会逐个匹配case语句,一个一个的判断过去,直到有符合的语句存在,执行匹配的语句内容后跳出switch。
func switchDemo(number int) {
//注意switch后可以跟空,因为上面已经出现过number变量
switch {
case number >= 90:
fmt.Println("优秀")
case number >= 80:
fmt.Println("良好")
case number >= 60:
fmt.Println("凑合")
default:
fmt.Println("太搓了")
}
}
如果没有一个是匹配的,就执行default后的语句。
1.4.3 循环
go 语言的循环和其他的没什么不同,只是语法上略微有些差别。写法如下:
for 循环方式 1 和 c++、java 相似
nums := []int{1, 2, 3, 4, 5, 6}
for i := 0; i < len(nums); i++ {
fmt.Println(i)
}
for 循环方式 2 省略赋值和++
a, b := 1, 5
for a < b {
fmt.Println(a)
a++
}
for 循环方式 3 迭代
- 优点:不用引入无意义的变量
- 缺点:不是直接索引,如果数据量极大会有性能损耗
for index, value := range nums {
fmt.Printf("key: %v , value: %v
\n", index, value)
}
当然,你可以把方式 3 中 index 去掉,用_忽略掉key
for _, v := range nums {
fmt.Printf("value: %v \n", v)
}
如果你想忽略掉 value,直接用 key也是可以的,这样就消除了迭代方式的缺点!
for i := range nums {
fmt.Printf("value: %v \n", nums[i])
}
range迭代可能会有坑,见下面的例子:
tmp := []struct{
int
string
}{
{1, "a"},
{2, "b"},
}
由于range遍历时value是值的拷贝,如果这个时候遍历上面声明的结构体时,修改value,原结构体不会发生任何变化!
func TestRange() {
tmp := []struct {
int
string
}{
{1, "a"},
{2, "b"},
}
for k, v := range tmp {
fmt.Printf("k:%v, v:%v \n", k, v)
}
for _, v := range tmp {
v.int = 2
}
for k, v := range tmp {
fmt.Printf("k:%v, v:%v \n", k, v)
}
}
两次输出一致
k:0, v:{1 a}
k:1, v:{2 b}
k:0, v:{1 a}
k:1, v:{2 b}
- 遍历
channel时,如果channel中没有数据,可能会阻塞- 遍历过程中可以适情况放弃接收
index或value,可以一定程度上提升性能- 尽量避免遍历过程中修改原数据
1.5 go 数据类型
在 Go 编程语言中,数据类型用于声明函数和变量。
数据类型的出现是为了把数据分成所需内存大小不同的数据,编程的时候需要用大数据的时候才需要申请大内存,就可以充分利用内存。
Go 语言按类别有以下几种数据类型:
- 数字类型
- 布尔类型
- 字符串类型
- 复合数据类型
- 数组
- Slice
- Map
- 结构体
- 指针
- 接口
- ......等等
数字类型主要包括整形、浮点型和复数,如下面表格(来自菜鸟教程)
整型:
| 序号 | 类型和描述 |
|---|---|
| 1 | uint8 无符号 8 位整型 (0 到 255) |
| 2 | uint16 无符号 16 位整型 (0 到 65535) |
| 3 | uint32 无符号 32 位整型 (0 到 4294967295) |
| 4 | uint64 无符号 64 位整型 (0 到 18446744073709551615) |
| 5 | int8 有符号 8 位整型 (-128 到 127) |
| 6 | int16 有符号 16 位整型 (-32768 到 32767) |
| 7 | int32 有符号 32 位整型 (-2147483648 到 2147483647) |
| 8 | int64 有符号 64 位整型 (-9223372036854775808 到 9223372036854775807) |
其中有符号整数采用2的补码形式表示,也就是最高bit位用来表示符号位,一个n-bit的有符号数的值域是从2^(n-1)到2^(n-1)-1。无符号整数的所有bit位都用于表示非负数,值域是0到2^n-1。例如,int8类型整数的值域是从-128到127,而uint8类型整数的值域是从0到255。
浮点型和复数:
| 序号 | 类型和描述 |
|---|---|
| 1 | float32 IEEE-754 32位浮点型数 |
| 2 | float64 IEEE-754 64位浮点型数 |
| 3 | complex64 32 位实数和虚数 |
| 4 | complex128 64 位实数和虚数 |
内置的complex函数用于构建复数,内建的real和imag函数分别返回复数的实部和虚部:
var x complex128 = complex(1, 2) // 1+2i
var y complex128 = complex(3, 4) // 3+4i
fmt.Println(x*y) // "(-5+10i)"
fmt.Println(real(x*y)) // "-5"
fmt.Println(imag(x*y)) // "10"
大多数类型都是接触过的,这里不过多赘述,用到时语法可以查工具书。
1.5.1 数组
数组是一个由固定长度的特定类型元素组成的序列,一个数组可以由零个或多个元素组成。因为数组的长度是固定的,因此在Go语言中很少直接使用数组。和数组对应的类型是Slice(切片),它是可以增长和收缩的动态序列,slice功能也更灵活,但是要理解slice工作原理的话需要先理解数组。
数组的每个元素可以通过索引下标来访问,索引下标的范围是从0开始到数组长度减1的位置。内置的len函数将返回数组中元素的个数。数组的使用如下:
//定义数组
var a1 [10]int
//初始化数组
var b1 = [5]float32{1000.0, 2.0, 3.4, 7.0, 50.0}
默认情况下,数组的每个元素都被初始化为元素类型对应的零值,对于数字类型来说就是0。
多维数组
//声明二维数组,只要 任意加中括号,可以声明更多维,相应占用空间指数上指
var arr [3][3]int
//赋值
arr = [3][3]int{
{1, 2, 3},
{2, 3, 4},
{3, 4, 5},
}
//在数组的长度位置出现的是“...”省略号,则表示数组的长度是根据初始化值的个数来计算
q := [...]int{1, 2, 3}
遍历数组
// Print the indices and elements.
for i, v := range a {
fmt.Printf("%d %d\n", i, v)
}
// Print the elements only.
for _, v := range a {
fmt.Printf("%d\n", v)
}
1.5.2 Slice切片
类比c语言,一个int型数组int a[10],a的类型是int*,也就是整型指针,而c语言中可以使用malloc()动态的分配一段内存区域,c++中可以用new()函数。例如:
int* a = (int *)malloc(10);
int* b = new int(4);
此时,a和b的类型也是int*,a和b此时分配内存的方式类似于go语言中的切片。Go的数组和切片都是从c语言中延续过来的设计。和c不同的是,go可以声明一个空切片(默认值为nil)如下,然后再增加值的过程中动态的改变切片值大小。
var sliceTmp []int
动态增加的方式只有一种,使用append函数追加。
sliceTmp = append(sliceTmp, 4)
sliceTmp = append(sliceTmp, 5)
每个切片有长度len和容量cap两个概念,长度是我们最熟知的,和数组长度相同,可以直接用来遍历。
for _,v := range slice1{
fmt.Println(v)
}
每个切片,在声明或扩建时会分配一段连续的空间,称为容量cap,是不可见的;真正在使用的只有一部分连续的空间,称为长度len,是可见的。每次append时,如果发现cap已经不足以给len使用,就会重新分配原cap两倍的容量,把原切片里已有内容全部迁移过去。
普通切片的声明方式,长度和容量是一致的,如下:
slice1 := []int{1, 2, 3} //len=3 cap=3 slice=[1 2 3]
但是我们可以自己控制长度和容量,如下:
slice1 = make([]int, 3, 5) // 3 是长度 5 是容量
//长度 4 容量5
slice1 = append(slice1, 4)
//长度 5 容量5
slice1 = append(slice1, 5)
// 到这里长度超过了容量,长度不变,容量自动翻倍为 5*2
slice2 = append(slice2, 6)
在go中可以用copy函数进行拷贝:
slice2 := make([]int, len(slice1), cap(slice1))
/* 拷贝 slice1 的内容到 slice2 */
copy(slice2, slice1) // 注意是后面的拷贝给前面
当然切片还有一种方式复制方式,比较快速,如下
slice3 := slice2[:]
但是有一种致命的缺点,即这是浅拷贝,slice3和slice2是同一个切片,无论改动哪个,另一个都会产生变化。
和数组不同的是,slice之间不能比较,因此我们不能使用==操作符来判断两个slice是否含有全部相等元素。不过标准库提供了高度优化的bytes.Equal函数来判断两个字节型slice是否相等([]byte),但是对于其他类型的slice,我们必须自己展开每个元素进行比较。
1.5.3 Map
Go语言提供的映射关系容器为 map ,map 使用散列表hash实现。查找复杂度为O(1),和数组一样,最坏的情况下为O(n),n为元素总数。
这就是Go中map的定义格式。
map[keyType] valueType
注意了,map 是一种引用类型,初值是nil,定义时必须用make来创建,否则会报错
panic: assignment to entry in nil map
必须要申请空间,所有的引用类型都要这么做
var m map[string]string
m = make(map[string]string)
当然,也可以这么写
m := make(map[string]string)
我们也可以用map字面值的语法创建map,同时还可以指定一些最初的key/value:
ages := map[string]int{
"alice": 31,
"charlie": 34,
}
//等价于
ages := make(map[string]int)
ages["alice"] = 31
ages["charlie"] = 34
Map中的元素通过key对应的下标语法访问:
ages["alice"] = 32
fmt.Println(ages["alice"]) // "32"
//使用内置的delete函数可以删除元素:
delete(ages, "alice") // remove element ages["alice"]
所有这些操作是安全的,即使这些元素不在map中也没有关系;如果一个查找失败将返回value类型对应的零值,例如,即使map中不存在“bob”下面的代码也可以正常工作,因为ages["bob"]失败时将返回0。
ages["bob"] = ages["bob"] + 1 // happy birthday!
//x += y和x++等简短赋值语法也可以用在map上,所以上面的代码可以改写成
ages["bob"] += 1
ages["bob"]++
但是map中的元素并不是一个变量,因此我们不能对map的元素进行取址操作:
_ = &ages["bob"] // compile error: cannot take address of map element
禁止对map元素取址的原因是map可能随着元素数量的增长而重新分配更大的内存空间,从而可能导致之前的地址无效。
要想遍历map中全部的key/value对的话,可以使用range风格的for循环实现,和之前的slice遍历语法类似。下面的迭代语句将在每次迭代时设置name和age变量,它们对应下一个键/值对:
for name, age := range ages {
fmt.Printf("%s\t%d\n", name, age)
}
for key := range m {
// 不用Printf也可以完成拼接输出啊!
fmt.Println("key:", key, ",value:", m[key])
}
1.5.4 结构体
结构体是一种聚合的数据类型,是由零个或多个任意类型的值聚合成的实体。每个值称为结构体的成员。用结构体的经典案例是处理公司的员工信息,每个员工信息包含一个唯一的员工编号、员工的名字、家庭住址、出生日期、工作岗位、薪资、上级领导等等。所有的这些信息都需要绑定到一个实体中,可以作为一个整体单元被复制,作为函数的参数或返回值,或者是被存储到数组中,等等。
下面举个使用的例子:例子中声明了一个叫Employee的命名的结构体类型,并且声明了一个Employee类型的变量dilbert,同时还包括一些用法:
type Employee struct {
ID int
Name string
Address string
DoB time.Time
Position string
Salary int
ManagerID int
}
func TestStruct() {
var dilbert Employee
//结构体变量的成员可以通过点操作符访问
dilbert.ID = 1
dilbert.Name = "Bob"
dilbert.Address = "南湖社区"
fmt.Println(dilbert)
//或者是对成员取地址,然后通过指针访问:
position := &dilbert.Position
*position = "定位 " + *position
fmt.Println(dilbert.Position)
//点操作符也可以和指向结构体的指针一起工作:
var employeeOfTheMonth *Employee = &dilbert
employeeOfTheMonth.Position += "测试123"
fmt.Println(dilbert)
//相当于下面语句
(*employeeOfTheMonth).Position += "test 456"
fmt.Println(dilbert)
}
结构体值也可以用结构体字面值表示,结构体字面值可以指定每个成员的值。
type Point struct{ X, Y int }
p := Point{1, 2}
这里有两种形式的结构体字面值语法,上面的是第一种写法,要求以结构体成员定义的顺序为每个结构体成员指定一个字面值。它要求写代码和读代码的人要记住结构体的每个成员的类型和顺序,不过结构体成员有细微的调整就可能导致上述代码不能编译。因此,上述的语法一般只在定义结构体的包内部使用,或者是在较小的结构体中使用
面向对象的语言,其中有一个叫类的概念,但是 go 里面没有。go 用一种特殊的方式,把结构体本身看作一个类。一个成熟的类,具备成员变量和成员函数,结构体本身就有成员变量,所以go提供了一种方式绑定上成员函数。
type people struct {
name string
}
//给 people 结构体绑定了一个函数
func (p people) toString() {
fmt.Println(p.name)
fmt.Printf("p的地址 %p \n", &p)
}
//使用 * 绑定函数,那么这种对象就是单例的,引用的是同一个结构体。
func (p *people) sayHello() {
fmt.Printf("Hello! %v \n", p.name)
fmt.Printf("*p的地址 %p \n", p)
}
//调用此函数
func TestStructFunc() {
p1 := people{"TestStructFuncP1"}
p1.toString()
p1.sayHello()
p2 := &people{"TestStructFuncP2"}
p2.sayHello()
}
调用TestStructFunc函数后会输出
TestStructFuncP1
p的地址 0xc00004e270
Hello! TestStructFuncP1
*p的地址 0xc00004e260
Hello! TestStructFuncP2
*p的地址 0xc00004e2a0
这里可以看到p1和p2的地址调用sayHello后是一样的。
1.5.5 指针
c 中有指针的概念,在 go 中也有,但是实际上用的比较少,因为指针容易出错,而且不易阅读。
每个变量都有他的地址,可以通过&取地址
var a int
fmt.Printf("a 的地址是:%p \n", &a)
//输出
//a 的地址是:0xc0000b2008
指针用来存地址,如下:
//声明 变量名 + 指针类型 , 命令规则以ptr结尾
var ptr *int /* 指向整型*/
// var fp *float32 /* 指向浮点型 */
ptr = &a // 变量内部存的值是普通类型,指针内部存的值是地址
fmt.Printf("ptr 存的值是:%p \n", ptr)
//输出
//ptr 存的值是:0xc0000b2008
根据输出,可以看到 ptr 存的值就是 a 的地址。
除此之外,还可以用*来取内容,比如ptr存的就是 a 的地址,ptr 的指向*ptr 肯定就是 a 本身了。
if a == *ptr {
fmt.Println("a == *ptr")
}
//输出
//a == *ptr
指针的作用有很多,比如说可以消灭掉返回值,直接对参数做改变。
例子如下:
定义一个交换函数,形参为指针类型
func swap(x *int, y *int) { var temp int temp = *x /* 保存 x 地址的值 */ *x = *y /* 将 y 赋值给 x */ *y = temp /* 将 temp 赋值给 y */ }调用
a := 100 b := 200 //操作地址,不需要返回 swap(&a, &b) fmt.Printf("交换后 a 的值 : %d\n", a) fmt.Printf("交换后 b 的值 : %d\n", b)输出
交换后 a 的值 : 200
交换后 b 的值 : 100
在Java中没有指针的概念,但是有引用的概念,在C++中比较常见,我们操作内存一定会用到指针,存储了变量的地址。
二、函数
函数,几乎是每种编程语言的必备语法,通过函数把一系列的动作汇总起来,在不同的地方重复使用。
2.1 函数声明
函数声明包括函数名、形式参数列表、返回值列表(可省略)以及函数体。
func name(parameter-list) (result-list) {
body
}
形式参数列表描述了函数的参数名以及参数类型。这些参数作为局部变量,其值由参数调用者提供。返回值列表描述了函数返回值的变量名以及类型。如果函数返回一个无名变量或者没有返回值,返回值列表的括号是可以省略的。如果一个函数声明不包括返回值列表,那么函数体执行完毕后,不会返回任何值。下面以add函数举例:
func AddXY(x, y float64) float64 {
return x + y
}
fmt.Println(test.AddXY(1.0, 3.5))
//输出4.5
如果一组形参或返回值有相同的类型,我们不必为每个形参都写出参数类型。下面2个声明是等价的:
func f(i, j, k int, s, t string) { /* ... */ }
func f(i int, j int, k int, s string, t string) { /* ... */ }
你可能会偶尔遇到没有函数体的函数声明,这表示该函数不是以Go实现的。这样的声明定义了函数标识符。
package math
func Sin(x float64) float //implemented in assembly language
2.2 多返回值
如果说是有多个返回值,要用打括号括起来。
//多个返回值
func funReturnMany() (int, int) {
return 1, 2
}
上面的返回值全部都是匿名的,可以赐他一个名字,函数中不用定义返回值,可以省略几行代码。
//返回值有名称
func funReturnName() (res int) {
//var res int 省掉了
res = 1 + 1
return
}
用返回就有接收,函数外部用这种方式接收
//接收多个返回值
a, b := funReturnMany()
2.3 函数作为参数
和python、c++、javascript一样,go中也有把函数当作参数传递的语法。
如下,functionValue函数的形参里有一个名为do的函数,需要提前指定do函数有什么参数和返回值。
func functionValue(a, b int, do func(int, int) int) {
fmt.Println(do(a, b))
}
然后do(a,b)是在functionValue内部调用的。这种特性有什么用呢?定义两个参数为int,返回为int的函数。
func add(a, b int) int {
return a + b
}
func sub(a, b int) int {
return a - b
}
因为规则符合do函数的规则,两个都可以传递过去,看!这就不用修改函数内部而出现了两种效果。
functionValue(1, 1, add)
functionValue(1, 1, sub)
在设计模式里,这种方式叫装饰器模式(Decorator Pattern)
2.4 匿名函数
在上面的例子中,也不必每次传递函数的时候都定义一个新函数,可以用匿名函数代替,写法如下:
//匿名函数
functionValue(1, 1, func(i1 int, i2 int) int {
return i1 * i2
})
同时也不是只有把函数当变量传递的时候才用到匿名函数,比如下面这样:
f := func(i int) {
fmt.Println(i)
}
f(1)
把匿名函数赋值给一个变量(这里是f),f就是他的函数名,后面就可以直接调用。
2.5 闭包
有一种情况,常常要定义好多全局变量来共享数据,这时go有一种办法,可以通过重复调用同一个函数,来修改函数内部的变量,这个东西就叫闭包:
闭包的简单实现,把函数定义在函数内部,并当作返回值返回。
func closureSample() func() {
count := 0
return func() {
count ++
fmt.Printf("调用次数 %v \n", count)
}
}
这里可以引申一下这样用,先调用两次closureSample函数,得到两个函数c1、c2,这两个函数就是closureSample函数的返回值,类型是一个匿名函数,然后调用几次函数如下:
func ClosePack() {
c1, c2 := closureSample(), closureSample()
c1()
c1()
c1()
c1()
c2()
c2()
}
//输出:
调用次数 1
调用次数 2
调用次数 3
调用次数 4
调用次数 1
调用次数 2
这是因为各个函数是独立使用一套自己的内部变量,互相不影响。通过上面的例子,不难发现闭包内部的匿名函数可以使用到外部的变量。
闭包还有其他形式,就是立即执行函数,声明完以后加括号,用以表示即刻调用,例子如下:
func() {
// to do something
}()
2.6 可变参数
在go语言中语言级别自带了一种语法,可以声明可变参数:
func 函数名(固定参数,v ...T) (返回参数列表){
函数体
}
例子如下:
func sum(t ...int) (res int) {
for _, v := range t {
res += v
}
return res
}
fmt.Println(sum(1, 2, 3, 4, 5))
//输出
//15
如果不知道参数类型,那么就可以配合switch进行使用:
func sumNum(t ...interface{}) (res float64) {
for _, tmp := range t {
switch v := tmp.(type) {
case int, int8, int16,
int32, int64, uint,
uint8, uint16, uint32,
uint64, float32, float64,
complex64, complex128:
convertStr := fmt.Sprintf("%v", v)
convertFloat64, _ := strconv.ParseFloat(convertStr, 64)
res += convertFloat64
}
}
return res
}
三、方法
在函数声明时,在其名字之前放上一个变量,即是一个方法。这个附加的参数会将该函数附加到这种类型上,即相当于为这种类型定义了一个独占的方法。例子如下:
package geometry
import "math"
type Point struct{ X, Y float64 }
// traditional function
func Distance(p, q Point) float64 {
return math.Hypot(q.X-p.X, q.Y-p.Y)
}
// same thing, but as a method of the Point type
func (p Point) Distance(q Point) float64 {
return math.Hypot(q.X-p.X, q.Y-p.Y)
}
上面的代码里那个附加的参数p,叫做方法的接收器(receiver),早期的面向对象语言留下的遗产将调用一个方法称为“向一个对象发送消息”。在方法调用过程中,接收器参数一般会在方法名之前出现。这和方法声明是一样的,都是接收器参数在方法名字之前。下面是例子:
p := Point{1, 2}
q := Point{4, 6}
fmt.Println(Distance(p, q)) // "5", function call
fmt.Println(p.Distance(q)) // "5", method call
可以看到,上面的两个函数调用都是Distance,但是却没有发生冲突。第一个Distance的调用实际上用的是包级别的函数geometry.Distance,而第二个则是使用刚刚声明的Point,调用的是Point类下声明的Point.Distance方法。
四、异常处理
4.1 异常
在 go 语言里是没有 try catch 的概念的,因为 try catch 会消耗更多资源,而且不管从 try 里面哪个地方跳出来,都是对代码正常结构的一种破坏。
所以 go 语言的设计思想中主张
- 如果一个函数可能出现异常,那么应该把异常作为返回值,没有异常就返回
nil - 每次调用可能出现异常的函数时,都应该主动进行检查,并做出反应,这种
if语句术语叫卫述语句
所以异常应该总是掌握在我们的手上,保证每次操作产生的影响达到最小,保证程序即使部分地方出现问题,也不会影响整个程序的运行,及时的处理异常,这样就可以减轻上层处理异常的压力。
同时也不要让未知的异常使你的程序崩溃。
我们应该让异常以这样的形式出现
func Demo() (int, error)
我们应该让异常以这样的形式处理
_,err := errorDemo()
if err!=nil{
fmt.Println(err)
return
}
4.2 自定义异常
比如程序有一个功能为除法的函数,除数不能为 0 ,否则程序为出现异常,我们就要提前判断除数,如果为 0 返回一个异常。那他应该这么写。
func divisionInt(a, b int) (int, error) {
if b == 0 {
return -1, errors.New("除数不能为0")
}
return a / b, nil
}
这个函数应该被这么调用
a, b := 4, 0
res, err := divisionInt(a, b)
if err != nil {
fmt.Println(err.Error())
return
}
fmt.Println(a, "除以", b, "的结果是 ", res)
可以注意到上面的两个知识点
- 创建一个异常
errors.New("字符串") - 打印异常信息
err.Error()
只要记得这些,就掌握了自定义异常的基本方法。
errors.New("字符串")的形式不支持字符串格式化功能,一般使用fmt.Errorf来做这样的事情。err = fmt.Errorf("产生了一个 %v 异常", "喝太多")
5.4 详细的异常信息
上面的异常信息只是简单的返回了一个字符串而已,想在报错的时候得到更多的异常内容怎么办呢?这就要看看 errors 的内部实现了。其实相当简单。
errors 实现了一个叫 error 的接口,这个接口里就一个 Error 方法且返回一个 string ,如下
type error interface {
Error() string
}
只要结构体实现了这个方法就行,源码的实现方式如下
type errorString struct {
s string
}
func (e *errorString) Error() string {
return e.s
}
// 多一个函数当作构造函数
func New(text string) error {
return &errorString{text}
}
所以我们只要扩充下自定义 error 的结构体字段就行了。
这个自定义异常可以在报错的时候存储一些信息,供外部程序使用
type FileError struct {
Op string
Name string
Path string
}
// 初始化函数
func NewFileError(op string, name string, path string) *FileError {
return &FileError{Op: op, Name: name, Path: path}
}
// 实现接口
func (f *FileError) Error() string {
return fmt.Sprintf("路径为 %v 的文件 %v,在 %v 操作时出错", f.Path, f.Name, f.Op)
}
调用
f := NewFileError("读", "README", "/home/how_to_code/README")
fmt.Println(f.Error())
输出
路径为 /home/how_to_code/README 的文件 README,在 读 操作时出错
五、接口
在Go语言中还存在着另外一种类型:接口类型。接口类型是一种抽象的类型。它不会暴露出它所代表的对象的内部值的结构和这个对象支持的基础操作的集合;它们只会表现出它们自己的方法。也就是说当你有看到一个接口类型的值时,你不知道它是什么,唯一知道的就是可以通过它的方法来做什么。
5.1 接口定义
接口同 java 一样,可以把一堆有共性的方法定义在里面,但是比 java 灵活的是,不需要显式实现接口,你可以自己控制实现哪些方法。不需要显式实现的意思是,不需要像 java 那样 implements interface 写出来,如下面的例子:
定义一个接口。
type humanInterface interface {
eat() string
play() string
}
定义一个结构体(类)
type man struct {
name string
}
实现接口,语法和 给结构体添加方法 一样,完全看不出来 接口 的身影。
func (p man) eat() string {
return "eat banana"
}
func (p man) play() string {
return "play game"
}
上面的代码给结构体添加了和接口一样的方法,只要完全实现接口中的方式,默认这就实现接口(隐式)。
5.2 接口使用
用下面这样的格式,把结构体赋值给接口来实现他 接口实例 = new(类型)
var human humanInterface
human = new(man)
fmt.Println(human.eat())
fmt.Println(human.play())
//输出
//eat banana
//play game
PS:
new关键字和c++中的不同,释放内存由go的垃圾处理机来做,不需要自己释放内存。
要注意的是,必须实现了所有接口的方法才算是实现了这个接口。假如只实现了接口中的一个方法,就会报错
type dogInterface interface {
eat() string
play() string
}
type dog1 struct {
name string
}
func (d dog1) eat() string {
return "Eat dog food"
}
var dog dogInterface
dog = new(dog1)
报错
报错:Cannot use 'new(dog1)' (type *dog1) as type dogInterface in assignment
Type does not implement 'dogInterface' as some methods are missing: play() string more...
5.3 多态
多态是面向对象的灵魂, go 也有多态。下面一个以接口为参数的函数,方法内调用了接口中方法。
func humanDoWhat(p humanInterface) {
fmt.Println(p.eat())
fmt.Println(p.play())
}
传入不同的类(结构体)
w := woman{"lisa"}
m := man{"tom"}
// 多态的含义就是不需要修改函数,只需要修改外部实现
// 同一个接口有不同的表现
humanDoWhat(w)
humanDoWhat(m)
不同输出
lisaeat rice
lisawatch TV
tomeat banana
tomplay game
六、go的并发
本章节是go的重点
6.1 goroutine创建与使用
go 在并发方面为我们提供了一个语言级别的支持, goroutine 和 channel 相互配合,这决定了他的先天优势。goroutine 也就是go协程,概念类似于线程, Go 程序运行时会自动调度和管理,系统能智能地将 goroutine 中的任务合理地分配给 CPU , 让这些任务尽量并发运作。
从使用上讲
- 比线程更轻量级,可以创建十万、百万不用担心资源问题。
- 和
channel搭配使用,实现高并发,goroutine之间传输数据更方便。 - 如果访问同一个数据块,要小心数据竞态问题、共享锁还是互斥锁的选择问题、并发操作的数据同步问题(后面会说)
从其实现上讲
- 从资源上讲,线程的栈内存大小一般是固定的一般为
2MB,虽然这个数值可以设置,但是 太大了浪费,太小了容易不够用, 而goroutine栈内存是可变的,初始一般为2KB,随着需求可以扩大达到 1GB。 所以goroutine十分的轻量级,且能满足不同的需求。 - 从调度上讲,线程的调度由
OS的内核完成;线程的切换需要 CPU 寄存器 和 内存的数据交换 ,从而切换不同的线程上下文。 其触发方式为CPU时钟, 而goroutine的调度则比较轻量级,由自身的调度器完成。 - 协程同线程的关系,有些类似于 线程同进程的关系。
举个入门案例,创建一个 goroutine ,只需要在函数前加一个 go 关键字就可以:
func main() {
go testGorutine()
for i := 1; i <= 10; i++ {
fmt.Println("main hello go" + strconv.Itoa(i))
time.Sleep(time.Second)
}
}
func testGorutine() {
for i := 1; i <= 10; i++ {
fmt.Println("test hello go" + strconv.Itoa(i))
time.Sleep(time.Second)
}
}
注意点如下:
- goroutine 和 main 主线程同时运行
- main 运行结束会暴力终止所有协程,所以上面的程序多等待了 1 秒
- Go 程序从 main 包的
main()函数开始,在程序启动时, Go 程序就会为main()函数创建一个默认的 goroutine 。
也可以用匿名函数来创建 goroutine:
func main(){
go func() {
fmt.Println("hello ")
}()
time.Sleep(time.Second) //main运行结束会暴力终止所有协程,所以这里先等待1秒
}
和线程不同,
goroutine没有唯一的id,所以我们没办法专门针对某个协程进行操作。
6.2 并发等待
由于主线程并不会等待协程结束,所以我们需要一些方式去等待写成的完成,主要有以下方式:
第一种最简单的方式就是阻塞主线程:
func main() {
go say("hello world")
time.Sleep(time.Second*1)
fmt.Println("over!")
}
第二种方式就是通过channel(这是一种协程通信的工具,用法见下一节),但这种方式不能处理多个协程,用法如下:
func main() {
done := make(chan bool)
go func() {
for i := 0; i < 3; i++ {
time.Sleep(100 * time.Millisecond)
fmt.Println("hello world")
}
done <- true
}()
<-done
fmt.Println("over!")
}
最好的方式就是通过WaitGroup 解决并发的等待问题,Golang 官方在 sync 包中提供了 WaitGroup 类型可以解决这个问题。其文档描述如下:
使用方法可以总结为下面几点:
- 在父协程中创建一个
WaitGroup实例,比如名称为:wg - 调用
wg.Add(n),其中 n 是等待的goroutine的数量 - 在每个
goroutine运行的函数中执行defer wg.Done() - 调用
wg.Wait()阻塞主逻辑 - 直到所有
goroutine执行完成。
PS:其实用法与Java的CountDownLatch类似
例子如下:
func main() {
var wg sync.WaitGroup
wg.Add(2)
go say2("hello", &wg)
go say2("world", &wg)
fmt.Println("over!")
wg.Wait()
}
func say2(s string, waitGroup *sync.WaitGroup) {
defer waitGroup.Done()
for i := 0; i < 3; i++ {
fmt.Println(s)
}
}
在使用协程时要注意循环传入的变量用中间变量替代,防止闭包 bug例子如下:
func errFunc() {
var wg sync.WaitGroup
sList := []string{"a", "b"}
wg.Add(len(sList))
for _, d := range sList {
go func() {
defer wg.Done()
fmt.Println(d)
}()
}
wg.Wait()
}
输出,可以发现全部变成了最后一个
b
b
这是因为父协程与子协程是并发的。父协程上的for循环瞬间执行完了,内部的协程使用的是d最后的值,这就是闭包问题。
6.3 channel
Go 是一门从语言级别就支持并发的编程语言, 它有一个设计哲学很特别 不要通过共享内存来通信,而应通过通信来共享内存 。在传统语言中并发使用全局变量来进行不同线程之间的数据共享,这种方式就是使用共享内存的方式进行通信。而 Go 会在协程和协程之间打一个隧道,通过这个隧道来传输数据(发送和接收)。channel 是 goroutine 之间互相通讯的东西,goroutine 之间用来发消息和接收消息。channel本质上可以理解为一个FIFO的队列。
6.3.1 channel的声明
channel是类型相关的,也就是说一个 channel 只能传递一种类型的值,这个类型需要在 channel 声明时指定。channel 的一般声明形式:
var chanName chan 类型
与普通变量的声明不同的是在类型前面加了 channel 关键字,类型 则指定了这个 channel 所能传递的元素类型。示例:
var a chan int //声明一个传递元素类型为int的channel
var b chan float64
var c chan string
通道是一个引用类型,初始值为nil,对于值为nil的通道,不论具体是什么类型,它们所属的接收和发送操作都会永久处于阻塞状态,所以必须手动make初始化,示例:
a := make(chan int) //初始化一个int型的名为a的channel
b := make(chan float64)
c := make(chan string)
既然是队列,那就有大小,上面没声明具体的大小,被认为是无缓冲的(注意大小是 0,不是 1)也就是说必须有其他goroutine接收,不然就会阻塞在那。声明有缓冲的channel,指定大小就可以了。
a := make(chan int,100)
6.3.2 channel的使用
我们先试试无缓冲 channel 并熟悉下用法,示例如下:
func testChan() {
a := make(chan int)
a <- 1 //将数据写入channel
z := <-a //从channel中读取数据
fmt.Println(z)
}
由于channel 是用来给不同 goroutine 通信的,所以上面的代码会死锁,输出如下:
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan send]:
main.testGorutine()
D:/goProject/first/main.go:15 +0x37
main.main()
D:/goProject/first/main.go:10 +0x17
exit status 2
死锁的原因是没有其他协程来接收数据,隧道因为是无缓冲的,所以直接永远的阻塞在发送方。要解决这个问题也好办,只要放到不同 goroutine 里就可以,如下:
func testNotDeadLock() {
chanInt := make(chan int)
go func() {
chanInt <- 1
}()
res := <-chanInt
//此方法输出1
fmt.Println(res)
}
上面的方法会输出1,因为无缓冲通道在无数据发送时,接收端会阻塞,直到有新数据发送过来为止。
而实际使用中数据往往是连续不断发送的。来看一段代码:
func standard() {
chanInt := make(chan int)
go func() {
defer close(chanInt)
var produceData = []int{1, 2, 3}
for _, v := range produceData {
chanInt <- v
}
}()
for v := range chanInt {
fmt.Println(v)
}
}
输出
1
2
3
在上面的代码中新建一个协程循环传递数据,同时父协程循环接收。同时需要注意:
range chan的方式可以不断的接收数据,直到通道关闭,假如通道不关闭会永远阻塞,无法通过编译,直接报死锁。- 必须在发送端关闭通道,因为接收端无法预料是否还有数据没有接收完;向已关闭的
channel发送数据会panic。
以上就是channel的使用。
6.3.3 channel的关闭
使用 Go 语言内置的 close() 函数即可关闭 channel,建议使用defer关闭,示例:
defer close(ch)
Channel还支持close操作,用于关闭channel,随后对基于该channel的任何发送操作都将导致panic异常。对一个已经被close过的channel进行接收操作依然可以接受到之前已经成功发送的数据;如果channel中已经没有数据的话将产生一个零值的数据。
6.4 死锁
我们来了解一下go中使用channel可能会造成的死锁:
6.4.1 当发送单个值时死锁
例子如下:
a := make(chan int)
a <- 1 //将数据写入channel
z := <-a //从channel中读取数据
- 当只有一个协程时,无缓冲的通道会死锁
- 先发送会阻塞在发送处,发送操作在接收者准备好之前是阻塞的,先接收会阻塞在接收处,接收操作在发送之前是阻塞的。
如何解决这种死锁呢?首先就是使用缓冲通道,如下:
func testGorutine() {
chanInt := make(chan int, 1)
chanInt <- 2
fmt.Println(len(chanInt))
z := <-chanInt
fmt.Println(z)
fmt.Println(len(chanInt))
fmt.Println(cap(chanInt))
//输出:
//1
//2
//0
//1
}
- 缓冲通道内部的消息数量用
len()函数可以测试出来 - 缓冲通道的容量可以用
cap()测试出来 - 在满足
cap>len时候,因为没有满,发送不会阻塞 - 在
len>0时,因为不为空,所以接收不会阻塞
使用缓冲通道可以让生产者和消费者减少阻塞的可能性,对异步操作更友好,不用等待对方准备,但是容量不应设置过大,不然会占用较多内存。
第二种方式就是配对协程,不让无缓冲chanel只有一个协程:
chanInt := make(chan int)
go func() {
chanInt <- 1
}()
res := <-chanInt
6.4.2 多个值发送的死锁
配对可以让死锁消失,但发送多个值的时候又无法配对了,又会死锁,例子如下:
func multipleDeathLock() {
chanInt := make(chan int)
defer close(chanInt)
go func() {
res := <-chanInt
fmt.Println(res)
}()
chanInt <- 1
chanInt <- 1
}
一般来说通知和信号是一对一的情况,通知一次后就不会再使用了。如何解决这种死锁呢?
一般来说都是通过循环来不断接收值,接受一个处理一个,如下:
func multipleLoop() {
chanInt := make(chan int)
defer close(chanInt)
go func() {
for {
//不使用ok会goroutine泄漏
//res := <-chanInt
res,ok := <-chanInt
if !ok {
break
}
fmt.Println(res)
}
}()
chanInt <- 1
chanInt <- 1
}
//输出
//1
//1
没有办法直接测试一个channel是否被关闭,但是接收操作有一个变体形式:它多接收一个结果,多接收的第二个结果是一个布尔值ok,ture表示成功从channels接收到值,false表示channels已经被关闭并且里面没有值可接收。
6.4.3 gorutine总是先接收
如果我们改变上面的函数的顺序:
func mutipleLoop(){
chanInt := make(chan int)
defer close(chanInt)
go func(){
chanInt <- 1
chanInt <- 2
}()
res,ok := <-chanInt
if !ok {
break
}
fmt.Println(res)
}
输出结果:
1
2
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan receive]:
main.multipleDeathLock2()
D:/goProject/first/main.go:39 +0xfa
main.main()
D:/goProject/first/main.go:10 +0x17
exit status 2
这是因为for循环一直在获取通道中的值,但是读取完1和2后,通道中一直没有新的值,这样接收者就阻塞了。这是因为发送提前结束后会触发函数的defer自动关闭通道,所以我们应该总是先接收后发送,并由发送端来关闭
6.4.4 gorutine泄露
goroutine 终止的场景有三个:
- 当一个
goroutine完成了它的工作 - 由于发生了没有处理的错误
- 有其他的协程告诉它终止
当三个条件都没有满足,goroutine 就会一直运行下去,举个例子:
func goroutineLeak() {
chanInt := make(chan int)
defer close(chanInt)
go func() {
for {
res := <-chanInt
//这回不用ok接收channel
//res,ok := <-chanInt
//if !ok {
// break
//}
fmt.Println(res)
}
}()
chanInt <- 1
chanInt <- 1
}
上面的goroutineLeak()函数结束后触发defer close(chanInt)关闭了通道。但是匿名函数中的goroutine并没有关闭,而是一直在循环取值,并且取到是的关闭后的通道值(这里是int的默认值 0)。这样的话goroutine会永远运行下去,如果以后再次使用又会出现新的泄漏!导致内存、cpu占用越来越多
输出,如果程序不停止就会一直输出0
1
1
0
0
0
...
假如不关闭且外部没有写入值,那接收处就会永远阻塞在那里,连输出都不会有,如下面代码:
func goroutineLeakNoClosed() {
chanInt := make(chan int)
go func() {
for {
res := <-chanInt
fmt.Println(res)
}
}()
}
上面的代码无任何输出的阻塞。同理换成写入也是一样的。如果是有缓冲的通道,换成已满的通道写没有读;或者换成向空的通道读没有写也是同样的情况。除了阻塞,goroutine进入死循环也是泄露的原因
6.5 select
6.5.1 select语句用法
在switch语句中,会逐个匹配case语句(可以是值也可以是表达式),一个一个的判断过去,直到有符合的语句存在,执行匹配的语句内容后跳出switch。
而 select 用于处理通道,它的语法与 switch 非常类似。每个 case 语句里必须是一个 channel 操作。它既可以用于 channel 的数据接收,也可以用于 channel 的数据发送,例子如下:
func foo() {
chanInt := make(chan int)
defer close(chanInt)
go func() {
//如果 select 的多个分支都满足条件,则会随机的选取其中一个满足条件的分支。
select {
case data, ok := <-chanInt:
if ok {
fmt.Println(data)
}
default:
//在case都处于阻塞状态时,会直接执行default的内容。导致子协程提前退出,主协程中的写入操作会一直阻塞(等待接收者,接收者已经退出了) 触发死锁
fmt.Println("全部阻塞")
}
}()
time.Sleep(time.Second)
chanInt <- 1
}
上面的代码会死锁,因为select执行完了之后会退出goroutine,而发送才刚执行到(因为阻塞了一秒),所以会死锁。
正确的做法是把接收套在循环里面。
func bar() {
chanInt := make(chan int)
defer close(chanInt)
go func() {
for {
select {
...
}
}
}()
chanInt <- 1
}
这样就不会死锁了,但是我们上一节学到了goroutine泄露,这时会一直在goroutine中无法退出循环,这时就可以用通知机制解决了。
6.5.2 通知机制
Go 语言总是简单和灵活的,虽然没有针对提供专门的机制来处理退出,但我们可以自己操作
func main() {
chanInt, done := make(chan int), make(chan struct{})
defer close(chanInt)
defer close(done)
go func() {
for {
select {
case <-chanInt:
case <-done:
return
}
}
}()
done <- struct{}{}
}
这段代码里没有给chanInt发送任何东西,按理说会阻塞,导致goroutine泄露,但是这里使用了额外的通道完成协程的退出控制。
6.5.3 case执行原理
如果case后左边和右边跟了函数,会执行函数,如下:
func testCase() {
ch, done := make(chan int), make(chan struct{})
defer close(ch)
go func() {
select {
case ch <- fa():
case ch <- fb():
case <-done:
}
}()
done <- struct{}{}
}
func fa() int {
fmt.Println("startA")
fmt.Println("endA")
return 1
}
func fb() int {
fmt.Println("startB")
fmt.Println("endB")
return 2
}
在select中是从左到右,从上到下的顺序扫描的,select会按照这个顺序先求值,如果是函数就会先执行函数,然后会判断函数是否可以立即执行(或者说是是否会因为执行而阻塞)。
所以在上面的代码中,两个函数会都进入,也就是先进入A在进入B。因为select需要获取case的值来判断是否满足条件。
6.6 并发安全
go也提供了临界区的保护,在go中提供了互斥锁和读写锁。
Go 语言中互斥锁的用法如下:
var lock sync.Mutex //互斥锁
lock.Lock() //加锁
//doSomething
lock.Unlock() //解锁
在访问临界区的前后加上互斥锁,就可以保证不会出现并发问题。
go也支持读写锁,用法如下:
rwlock sync.RWMutex
//读锁
rwlock.RLock()
rwlock.RUnlock()
//写锁
rwlock.Lock()
rwlock.Unlock()
6.7 定时器
很多时候需要周期性的执行某些操作,就需要用到定时器。定时器有三种思路。
6.7.1 Sleep
使用休眠,让当前Goroutine休眠一定的时间来实现定时的效果,缺点是程序执行速度不均匀(休眠需要调度),导致定时周期不均匀。
for{
fmt.Println(time.Now())
time.Sleep(time.Second*1)
}
6.7.2 Timer
第二种思路就是Go 的内置包,指定一个时间开始计时,时间到之后会向外发送通知,发送通知的方式就是使用<-chan Time 返回内容。
第一种方式,直接在需要等待处使用,效果和Sleep一样,一使用就卡在那了内部就是使用了Timer。
fmt.Println(time.Now())
<-time.After(1*time.Second)
fmt.Println(time.Now())
也可以把他拆分开,在任意地方进行等待
timer := time.NewTimer(1 * time.Second)
<-timer.C
fmt.Println(time.Now())
6.7.3 Ticker
上面只是延迟一次,虽然也可以自己实现,但是go有内置的定时器,Ticker 本身就是一个定时器(内部封装了Timer),用法如下:
func testTicker() {
ticker := time.NewTicker(1 * time.Second)
go func() {
for {
<-ticker.C
fmt.Println(time.Now())
}
}()
<-time.After(5*time.Second + time.Millisecond*100)
ticker.Stop()
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix