Zookeeper学习笔记
Zookeeper学习笔记
一、概述
1.1 Zookeeper伪集群的搭建
这里以个人电脑windwos平台为例
首先下载zookeeper的安装包我这里是3.6.3版本,下载地址
解压后,创建data和log目录,如下图:
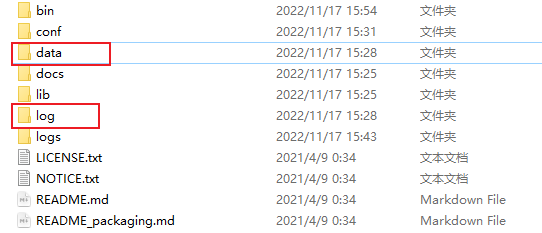
然后在data和log目录中建三个文件夹:

在data目录的每一个文件夹中创建一个myid的文件,然后文件内容为id:
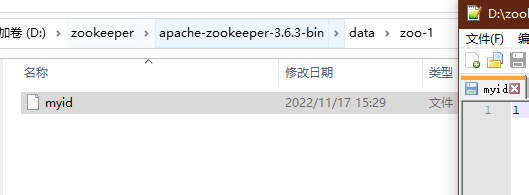
然后复制zoo_sample.cfg文件,复制三份,并修改配置文件内容,:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=D:\zookeeper\apache-zookeeper-3.6.3-bin\data\zoo-1
dataLogDir=D:\zookeeper\apache-zookeeper-3.6.3-bin\log\zoo-1
# the port at which the clients will connect
clientPort=2181
#在3.6.x以上版本zookeeper有一个管理后台,默认占用8080端口,所以需要手动修改
admin.serverPort=2666
server.1=127.0.0.1:2888:3888
进入bin目录,复制zkServer.cmd,复制三分,并进行修改:
@echo off
setlocal
call "%~dp0zkEnv.cmd"
set ZOOCFG=D:\zookeeper\apache-zookeeper-3.6.3-bin\conf\zoo-1.cfg
set ZOOMAIN=org.apache.zookeeper.server.quorum.QuorumPeerMain
set ZOO_LOG_FILE=zookeeper-%USERNAME%-server-%COMPUTERNAME%.log
echo on
call %JAVA% "-Dzookeeper.admin.enableServer=false -Dzookeeper.log.dir=%ZOO_LOG_DIR%" "-Dzookeeper.root.logger=%ZOO_LOG4J_PROP%" "-Dzookeeper.log.file=%ZOO_LOG_FILE%" "-XX:+HeapDumpOnOutOfMemoryError" "-XX:OnOutOfMemoryError=cmd /c taskkill /pid %%%%p /t /f" -cp "%CLASSPATH%" %ZOOMAIN% "%ZOOCFG%" %*
endlocal
然后分别启动三个cmd即可。到此zookeeper的伪集群搭建完成。
1.2 Zookeeper存储模型
zookeeper的存储模式很简单,与Linux的文件系统类似。zookeeper是一颗以/为根节点的树,而其中的每一个节点叫ZNode,所有的节点通过树结构按层次组织在一起,构成一个ZNode树。每个节点都用一个完整的路径唯一标识,比如/test/node1。
通过ZNode树,ZooKeeper提供一个多层级的树状命名空间。该树状命名空间与文件的目录系统中的目录树有所不同的是:这些ZNode节点可以保存二进制负载数据(Payload)。而文件系统目录树中的目录,只能存放路径信息,二不能存放负载数据。
一个节点的负载数据能放多少二进制数据呢?ZooKeeper为了保证高吞吐和低延迟,整个树状的目录结构全部都放在内存中。与硬盘和其他的外存设备相比,机器的内存比较有限,使得ZooKeeper的目录结构,不能用于存放大量的数据。ZooKeeper官方的要求是,每个节点存放的Payload负载数据的上限,仅仅为1M。
二、客户端的使用
zookeeper的应用开发主要通过Java客户端去连接和操作zookeeper集群,目前的Java客户端有:
- zookeeper官方的Java客户端
- 第三方的客户端API
ZooKeeper官方的客户端API提供了基本的操作。比如,创建会话、创建节点、读取节点、更新数据、删除节点和检查节点是否存在等。但对于实际开发来说,ZooKeeper官方API有一些不足之处:
- ZooKeeper的Watcher监测是一次性的,每次触发之后都需要重新进行注册;
- Session超时之后没有实现重连机制;
- 异常处理繁琐,ZooKeeper提供了很多异常,对于开发人员来说可能根本不知道该如何处理这些异常信息;
- 只提供了简单的byte[] 数组类型的接口,没有提供Java POJO级别的序列化数据处理接口;
- 创建节点时如果节点存在抛出异常,需要自行检查节点是否存在;
- 无法实现级联删除
因此我这里采用第三方客户端进行学习,第三方开源客户端API主要有zkClient和Curator。我这里使用Curator进行学习。
Curator是Netflix公司开源的一套ZooKeeper客户端框架,和ZkClient一样,Curator提供了非常底层的细节开发工作,包括Session会话超时重连、掉线重连、反复注册Watcher和NodeExistsException异常等。它是Apache基金会的顶级项目之一,Curator具有更加完善的文档,另外还提供了一套易用性和可读性更强的Fluent风格的客户端API框架。Curator还提供了ZooKeeper一些比较普遍的分布式开发的开箱即用的解决方案,比如Recipes、共享锁服务、Master选举机制和分布式计算器等,Java应用开发时在这些小的组件上可以不用重复造轮子。
2.1 创建Client
使用Curator首先需要引入依赖,我的zookeeper的版本是3.6.3,这里引入以下版本Curator:
<!--curator版本需要与zookeeper版本匹配,这里-->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>5.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-client</artifactId>
<version>5.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>5.2.0</version>
</dependency>
然后我们就可以创建Curator客户端了,Curator客户端有两种方式可以进行创建,一种是使用newClient方式,另一种是builder构造者方法。
这里将两种创建方式封装成一个工厂类,代码如下:
public class ClientFactory {
/**
* 创建简单的CuratorFramework实例
*
* @param connectionStr 连接地址
* @author Yuhaoran
* @date 2022/11/18 10:38
*/
public static CuratorFramework createSimple(String connectionStr) {
//重试策略,第一次重试等待1s,第二次重试等待2s,第三次4s。。。
//baseSleepTimeMs:等待时间的基础单位,下面设定了1000ms
//maxRetries:重试次数
ExponentialBackoffRetry retry = new ExponentialBackoffRetry(1000, 3);
//使用工厂类的静态方法
//参数1:zk的连接地址;参数2:重试策略
return CuratorFrameworkFactory.newClient(connectionStr, retry);
}
/**
* 创建带参数的CuratorFramework实例
*
* @param connStr 连接地址
* @param retryPolicy 重试策略
* @param connTimeoutMs 连接超时时长
* @param sessionTimeoutMs 会话超时时长
* @author Yuhaoran
* @date 2022/11/18 10:39
*/
public static CuratorFramework createWithOptions(String connStr, RetryPolicy retryPolicy, int connTimeoutMs, int sessionTimeoutMs) {
//通过builder构造者方法构造
return CuratorFrameworkFactory.builder()
.connectString(connStr)
.retryPolicy(retryPolicy)
.connectionTimeoutMs(connTimeoutMs)
.sessionTimeoutMs(sessionTimeoutMs)
.build();
}
}
2.2 节点的增删改查
关于Znode节点的增删改查,示例代码和注释如下:
@Slf4j
public class TestCurator {
private static final String ZK_ADDRESS="127.0.0.1:2881";
@Test
public void createNode(){
CuratorFramework client = ClientFactory.createSimple(ZK_ADDRESS);
try {
//启动客户端,连接服务器
client.start();
//创建一个节点,节点数据为 payload
String data = "Hello,ZK!";
byte[] bytes = data.getBytes(StandardCharsets.UTF_8);
String zkPath = "/test/CURD/node-1";
//create方法可以创建Znode节点,但该方法不会立即创建节点,而是返回一个CreateBuilder构造者实例,并设置一些参数
//最终通过forPath方法完成真正的节点创建工作
client.create()
.creatingParentsIfNeeded()
//节点类型主要有四种
//PERSISTENT 持久化节点:持久节点,是指在节点创建后,就一直存在,直到有删除操作来主动清除这个节点。持久节点的生命周期是永久有效,不会因为创建该节点的客户端会话失效而消失
//PERSISTENT_SEQUENTIAL 持久化顺序节点:持久化顺序节点的每个父节点会为他的第一级子节点维护一份次序,会记录每个子节点创建的先后顺序
//EPHEMERAL临时节点:临时节点的生命周期和客户端会话绑定
//EPHEMERAL_SEQUENTIAL临时顺序节点:带有顺序编号的临时节点
.withMode(CreateMode.PERSISTENT)
.forPath(zkPath,bytes);
}catch (Exception e){
log.error(e.getMessage());
}finally {
client.close();
}
}
@Test
public void readNode(){
CuratorFramework client = ClientFactory.createSimple(ZK_ADDRESS);
try {
client.start();
String zkPath = "/test/CURD/node-1";
//无论是checkExists、getData、getChildren方法,都有一个共同的特点,就是方法法返回的是构造者实例,不会立即执行,最终需要调用forPath进行调用
Stat stat = client.checkExists().forPath(zkPath);
if (stat!=null){
byte[] bytes = client.getData().forPath(zkPath);
String data = new String(bytes);
log.info("data={}",data);
String parentPath = "/test";
List<String> list = client.getChildren().forPath(parentPath);
for (String child : list) {
log.info("child={}",child);
}
}
}catch (Exception e){
log.error(e.getMessage());
}finally {
client.close();
}
}
//节点的更新操作,可以分为同步更新与异步更新,以下是同步更新
@Test
public void updateNode(){
CuratorFramework client = ClientFactory.createSimple(ZK_ADDRESS);
try {
client.start();
String zkPath = "/test/CURD/node-1";
String data = "Hello,Update_ZK";
byte[] bytes = data.getBytes(StandardCharsets.UTF_8);
//使用setData()方法可以进行同步更新
client.setData().forPath(zkPath,bytes);
}catch (Exception e){
log.error(e.getMessage());
}finally {
client.close();
}
}
//节点的更新操作,可以分为同步更新与异步更新,以下是异步更新
@Test
public void updateNodeAsync(){
CuratorFramework client = ClientFactory.createSimple(ZK_ADDRESS);
try {
AsyncCallback callback = new AsyncCallback.StringCallback() {
@Override
public void processResult(int i, String s, Object o, String s1) {
log.info("i={};\ns={};\no={};\ns1={}",i,s,o,s1);
}
};
client.start();
String zkPath = "/test/CURD/node-1";
String data = "Hello,Update_Async_ZK";
byte[] bytes = data.getBytes(StandardCharsets.UTF_8);
//使用setData()方法可以进行同步更新
client.setData()
.inBackground(callback)//设置回调实例
.forPath(zkPath,bytes);
}catch (Exception e){
log.error(e.getMessage());
}finally {
client.close();
}
}
@Test
public void deleteNode(){
CuratorFramework client = ClientFactory.createSimple(ZK_ADDRESS);
try {
client.start();
String zkPath = "/test/CURD/node-1";
//删除也可以异步,用法与更新类似
client.delete().forPath(zkPath);
String parentPath = "/test";
List<String> list = client.getChildren().forPath(parentPath);
for (String child : list) {
log.info("child={}",child);
}
}catch (Exception e){
log.error(e.getMessage());
}finally {
client.close();
}
}
}
2.3 客户端CURD示例
分布式节点ID生成示例,此示例的原理是zookeeper的顺序节点可以进行自动编号,因此通过临时顺序节点即可实现ID生成,代码如下:
public class IDMaker {
private static final String ZK_ADDRESS = "127.0.0.1:2181";
private String createID(String prefix) {
CuratorFramework client = ClientFactory.createSimple(ZK_ADDRESS);
try {
client.start();
String forPath = client
.create()
.creatingParentsIfNeeded()
.withMode(CreateMode.EPHEMERAL_SEQUENTIAL)
.forPath(prefix);
return forPath;
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
public String getID(String nodeName) {
//返回创建的节点的路径名称
String result = createID(nodeName);
if (result == null) {
return null;
}
int index = result.lastIndexOf(nodeName);
if (index >= 0) {
index += nodeName.length();
return index < result.length() ? result.substring(index) : "";
}
return result;
}
}
@Test
public void testIDMaker(){
IDMaker idMaker = new IDMaker();
for (int i = 0; i < 10; i++) {
System.out.println("####"+idMaker.getID("/test/IDMake-"));
}
}
三、分布式事件监听
针对ZooKeeper服务端的节点操作事件监听,是客户端操作服务器的一项重点工作。在Curator的API中,事件监听有两种方式:一是标准的观察者模式,二是缓存监听模式。标准的观察者模式,是通过Watcher监听器实现,缓存监听模式则是引入了本地缓存Cache机制实现。简单地理解,Cache在客户端缓存了Znode的各种状态,当感知到Zookeeper集群的Znode变化,会触发event事件,注册到这些事件上的监听器会处理这些事件。虽然Cache是缓存机制,但是可以借助Cache实现事件的监听,并且Watcher只能监听一次,Cache可以多次监听。
3.1 Watcher
下面是Watcher的用法:
@Slf4j
public class TestZkWatcher {
private static final String ZK_ADDRESS="127.0.0.1:2181";
private final String workerPath = "/test/listener/remoteNode";
private final String subWorkerPath = "/test/listener/remoteNode/id-";
@Test
public void testWatcher(){
CuratorFramework client = ClientFactory.createSimple(ZK_ADDRESS);
client.start();
try {
Stat stat = client.checkExists().forPath(workerPath);
if (stat==null){
client.create().creatingParentsIfNeeded().forPath(workerPath);
}
//构建Watcher实例
Watcher watcher = new Watcher() {
//process是回调方法;Watcher只能监听一次
@Override
public void process(WatchedEvent watchedEvent) {
//输出结果为:
//####监听的变化 watchEvent=WatchedEvent state:SyncConnected type:NodeDataChanged path:/test/listener/remoteNode
//具体含义可以查下表
System.out.println("####监听的变化 watchEvent="+watchedEvent);
}
};
//一般来说可以通过GetDataBuilder、GetChildrenBuilder、ExistsBuidler等实现了Watchable接口的构造者实例,通过其usingWatcher方法使用Watcher监听器
//比如下面getData()返回的就是一个GetDataBuilder实例
byte[] bytes = client.getData().usingWatcher(watcher).forPath(workerPath);
log.info("监听节点内容={}",new String(bytes));
client.setData().forPath(workerPath,"第一次变动".getBytes(StandardCharsets.UTF_8));
client.setData().forPath(workerPath,"第二次变动".getBytes(StandardCharsets.UTF_8));
Thread.sleep(Integer.MAX_VALUE);
}catch (Exception e){
e.printStackTrace();
}
}
}
在WatchedEvent中一共有三个属性:keeperState通知状态、eventType事件类型、path节点路径,三个属性。关于通知状态和事件类型如下图:(图片来自高并发核心编程卷一)
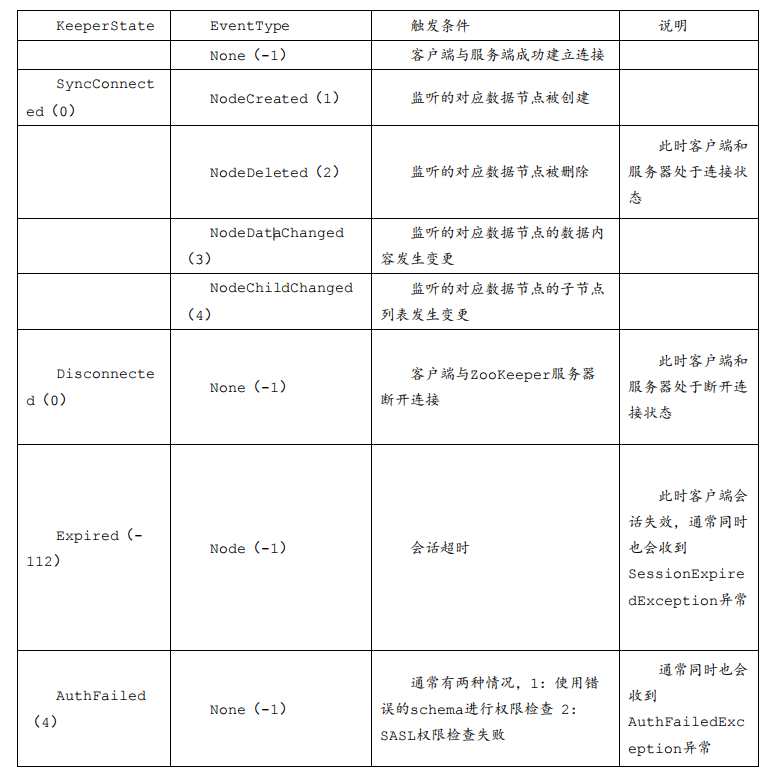
3.2 Cache
Curator引入的Cache缓存实现,Cache缓存拥有一个系列的类型,包括了Node Cache 、Path Cache、Tree Cache三组类:
- Node Cache节点缓存可以用于ZNode节点的监听;
- Path Cache子节点缓存用于ZNode的子节点的监听;
- Tree Cache树缓存是Path Cache的增强,不仅仅能监听子节点,也能监听ZNode节点自身。
下面是Node Cache的例子:
@Test
public void testNodeCache(){
CuratorFramework client = ClientFactory.createSimple(ZK_ADDRESS);
client.start();
try {
NodeCache nodeCache = new NodeCache(client,workerPath,false);
NodeCacheListener listener = new NodeCacheListener() {
@Override
public void nodeChanged() throws Exception {
ChildData currentData = nodeCache.getCurrentData();
log.info("####节点变化,path={}",currentData.getPath());
log.info("####节点变化,data={}",new String(currentData.getData(),StandardCharsets.UTF_8));
log.info("####节点变化,stat={}",currentData.getStat());
}
};
nodeCache.getListenable().addListener(listener);
nodeCache.start();
client.setData().forPath(workerPath,"第111111次变动".getBytes(StandardCharsets.UTF_8));
Thread.sleep(1000);
client.setData().forPath(workerPath,"第222222次变动".getBytes(StandardCharsets.UTF_8));
Thread.sleep(1000);
client.setData().forPath(workerPath,"第333333次变动".getBytes(StandardCharsets.UTF_8));
Thread.sleep(Integer.MAX_VALUE);
}catch (Exception e){
e.printStackTrace();
}
}
下面是Path Cache的例子:
@Test
public void testPathCache() {
CuratorFramework client = ClientFactory.createSimple(ZK_ADDRESS);
client.start();
try {
PathChildrenCache cache =
new PathChildrenCache(client, workerPath, true);
PathChildrenCacheListener l =
new PathChildrenCacheListener() {
@Override
public void childEvent(CuratorFramework client,
PathChildrenCacheEvent event) {
try {
ChildData data = event.getData();
switch (event.getType()) {
case CHILD_ADDED:
log.info("####子节点增加, path={}, data={}",
data.getPath(), new String(data.getData(), "UTF-8"));
break;
case CHILD_UPDATED:
log.info("####子节点更新, path={}, data={}",
data.getPath(), new String(data.getData(), "UTF-8"));
break;
case CHILD_REMOVED:
log.info("####子节点删除, path={}, data={}",
data.getPath(), new String(data.getData(), "UTF-8"));
break;
default:
break;
}
} catch (
UnsupportedEncodingException e) {
e.printStackTrace();
}
}
};
cache.getListenable().addListener(l);
cache.start(PathChildrenCache.StartMode.BUILD_INITIAL_CACHE);
for (int i = 0; i < 3; i++) {
client.create()
.creatingParentsIfNeeded()
.withMode(CreateMode.PERSISTENT)
.forPath(subWorkerPath+i, ("第"+i+"次新增").getBytes(StandardCharsets.UTF_8));
}
Thread.sleep(1000);
for (int i = 0; i < 3; i++) {
Stat stat = client.checkExists().forPath(subWorkerPath + i);
if (stat != null){
client.delete().forPath(subWorkerPath+i);
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
下面是Tree Cache的例子:
@Test
public void testTreeCache() {
CuratorFramework client = ClientFactory.createSimple(ZK_ADDRESS);
client.start();
try {
Stat statP = client.checkExists().forPath(workerPath);
if (statP == null){
client.create().creatingParentsIfNeeded().forPath(workerPath);
}
TreeCache treeCache =
new TreeCache(client, workerPath);
TreeCacheListener l =
new TreeCacheListener() {
@Override
public void childEvent(CuratorFramework client,
TreeCacheEvent event) {
try {
ChildData data = event.getData();
if (data == null) {
log.info("数据为空");
return;
}
switch (event.getType()) {
case NODE_ADDED:
log.info("####节点增加, path={}, data={}",
data.getPath(), new String(data.getData(), "UTF-8"));
break;
case NODE_UPDATED:
log.info("####节点更新, path={}, data={}",
data.getPath(), new String(data.getData(), "UTF-8"));
break;
case NODE_REMOVED:
log.info("####节点删除, path={}, data={}",
data.getPath(), new String(data.getData(), "UTF-8"));
break;
default:
break;
}
} catch (
UnsupportedEncodingException e) {
e.printStackTrace();
}
}
};
treeCache.getListenable().addListener(l);
treeCache.start();
Thread.sleep(1000);
for (int i = 0; i < 3; i++) {
client.create()
.creatingParentsIfNeeded()
.withMode(CreateMode.PERSISTENT)
.forPath(subWorkerPath+i, ("第"+i+"次新增").getBytes(StandardCharsets.UTF_8));
}
Thread.sleep(1000);
for (int i = 0; i < 3; i++) {
Stat stat = client.checkExists().forPath(subWorkerPath + i);
if (stat != null){
client.delete().forPath(subWorkerPath+i);
}
}
Thread.sleep(1000);
client.delete().forPath(workerPath);
Thread.sleep(Integer.MAX_VALUE);
} catch (Exception e) {
e.printStackTrace();
}
}
对于Zookeeper3.6.x之前版本,Curator提供的Cache分为Path Cache、NodeCache、Tree Cache,三者隶属于三个独立的类。对于之后的版本,统一使用一个工具类CuratorCache实现。就是说,Zookeeper3.6.x之后版本,Path Cache、Node Cache、Tree Cache均标记为废弃,建议使用Curator Cache。例子如下:
@Test
public void testCuratorCache() {
CuratorFramework client = ClientFactory.createSimple(ZK_ADDRESS);
client.start();
try {
/*默认已指定节点为根的整个子树都被缓存;如果使用SINGLE_NODE_CACHE则只会缓存指定的节点
* CuratorCache.Options除了单节点还有两个选项:
* COMPRESSED_DATA: 通过org.apache.curator.framework.api.GetDataBuilder.decompressed()解压数据
* DO_NOT_CLEAR_ON_CLOSE:当通过close()关闭缓存时,会通过CuratorCacheStorage.clear()清除storage,此选项可以防止storage被清除
* */
CuratorCache curatorCache = CuratorCache.build(client, workerPath, CuratorCache.Options.SINGLE_NODE_CACHE);
//通过lambda构建listener
CuratorCacheListener listener = CuratorCacheListener.builder()
//添加缓存中的数据时调用
.forCreates(node -> System.out.println(String.format("####Node created: [%s]", node)))
//修改缓存中的数据时调用
.forChanges((oldNode, node) -> System.out.println(String.format("####Node changed. Old: [%s] New: [%s]", oldNode, node)))
//删除缓存中的数据时调用
.forDeletes(oldNode -> System.out.println(String.format("####Node deleted. Old value: [%s]", oldNode)))
//初始化完成时调用
.forInitialized(() -> System.out.println("####Cache initialized"))
.build();
curatorCache.listenable().addListener(listener);
//或者匿名创建listener
// curatorCache.listenable().addListener(new CuratorCacheListener() {
// @Override
// public void event(Type type, ChildData oldData, ChildData data) {
// switch (type.name()) {
// case "NODE_CREATED":
// System.out.println("####NODE_CREATED: " + oldData + " : " + data);
// break;
// case "NODE_CHANGED":
// System.out.println("####NODE_CHANGED: " + oldData + " : " + data);
// break;
// case "NODE_DELETED":
// System.out.println("####NODE_DELETED: " + oldData + " : " + data);
// break;
// default:
// break;
// }
// }
// });
curatorCache.start();
client.setData().forPath(workerPath, "第111111次变动".getBytes(StandardCharsets.UTF_8));
Thread.sleep(1000);
client.setData().forPath(workerPath, "第222222次变动".getBytes(StandardCharsets.UTF_8));
Thread.sleep(1000);
client.setData().forPath(workerPath, "第333333次变动".getBytes(StandardCharsets.UTF_8));
Thread.sleep(Integer.MAX_VALUE);
} catch (Exception e) {
e.printStackTrace();
}
}
四、分布式锁
4.1 自定义Zookeeper分布式锁
我们先来了解什么是公平锁、非公平锁,可重入锁、不可重入锁。以下内容来自我的博客Java多线程:
公平锁和非公平锁
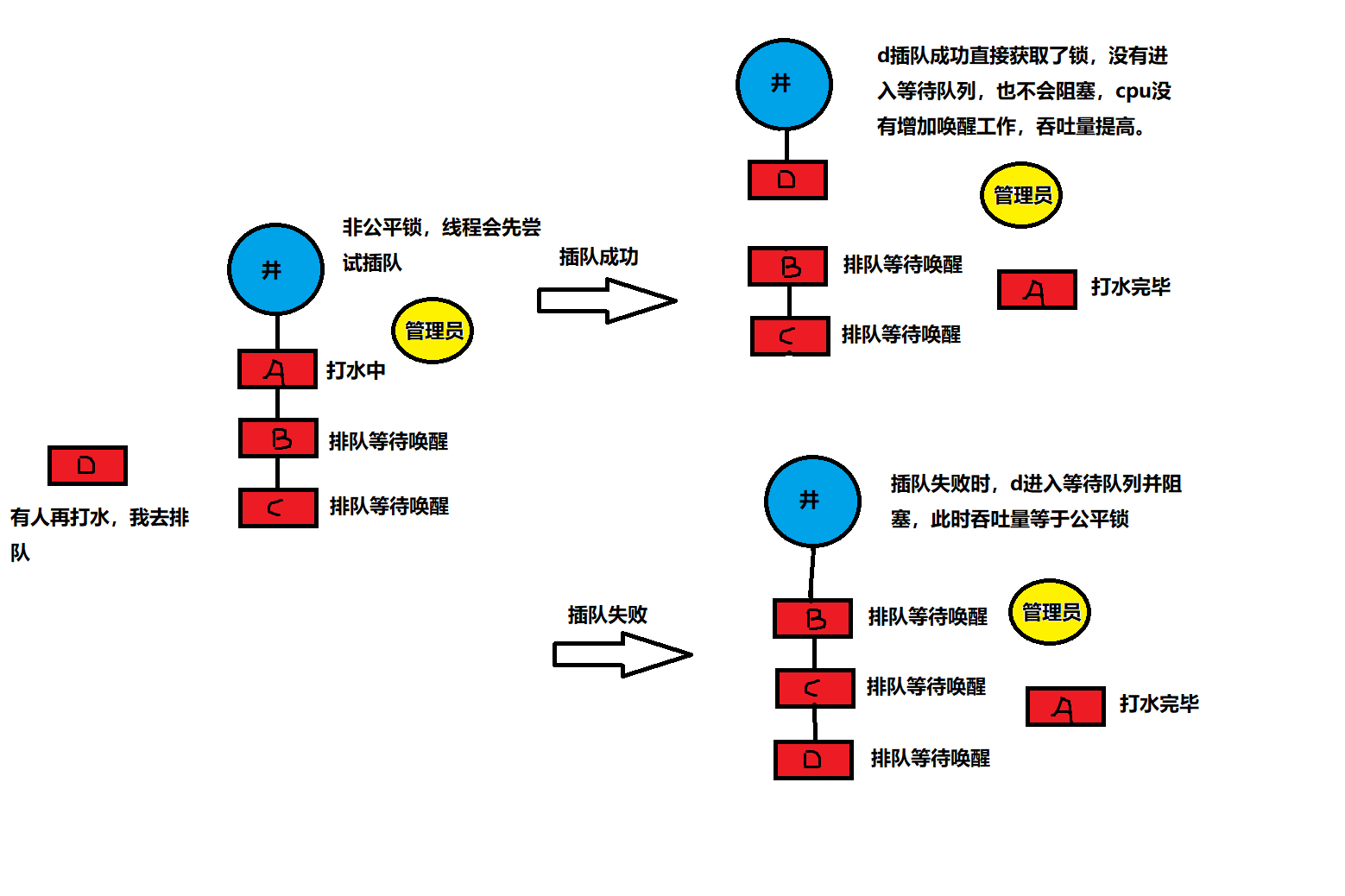
公平锁是指多个线程按照申请锁的顺序来获取锁,线程直接进入队列中排队,队列中的第一个线程才能获得锁。公平锁的优点是等待锁的线程不会饿死。缺点是整体吞吐效率相对非公平锁要低,等待队列中除第一个线程以外的所有线程都会阻塞,CPU唤醒阻塞线程的开销比非公平锁大。
非公平锁是多个线程加锁时直接尝试获取锁,获取不到才会到等待队列的队尾等待。但如果此时锁刚好可用,那么这个线程可以无需阻塞直接获取到锁,所以非公平锁有可能出现后申请锁的线程先获取锁的场景。非公平锁的优点是可以减少唤起线程的开销,整体的吞吐效率高,因为线程有几率不阻塞直接获得锁,CPU不必唤醒所有线程。缺点是处于等待队列中的线程可能会饿死,或者等很久才会获得锁。
以水井为例,由管理员看守且管理员只有一把锁,如果前面有人打水,那么这个d想打水就必须排队,且必须去队尾排队,管理员只会给队伍中最前面的人锁并让你去打水。
如果是非公平锁,即便队伍中有等待的人,但如果刚好上一个人刚打完水交还锁且管理员还没有允许下一个人去打水时,这时来了一个插队的人,这个插队的人可以直接去拿锁不需要排队。
可重入和不可重入锁
以水井为例,有多个人在排队打水,此时管理员允许锁和同一个人的多个水桶绑定。这个人用多个水桶打水时,第一个水桶和锁绑定并打完水之后,第二个水桶也可以直接和锁绑定并开始打水,所有的水桶都打完水之后打水人才会将锁还给管理员。这个人的所有打水流程都能够成功执行,后续等待的人也能够打到水。这就是可重入锁。
如果是非可重入锁的话,此时管理员只允许锁和同一个人的一个水桶绑定。第一个水桶和锁绑定打完水之后并不会释放锁,导致第二个水桶不能和锁绑定也无法打水。当前线程出现死锁,整个等待队列中的所有线程都无法被唤醒。

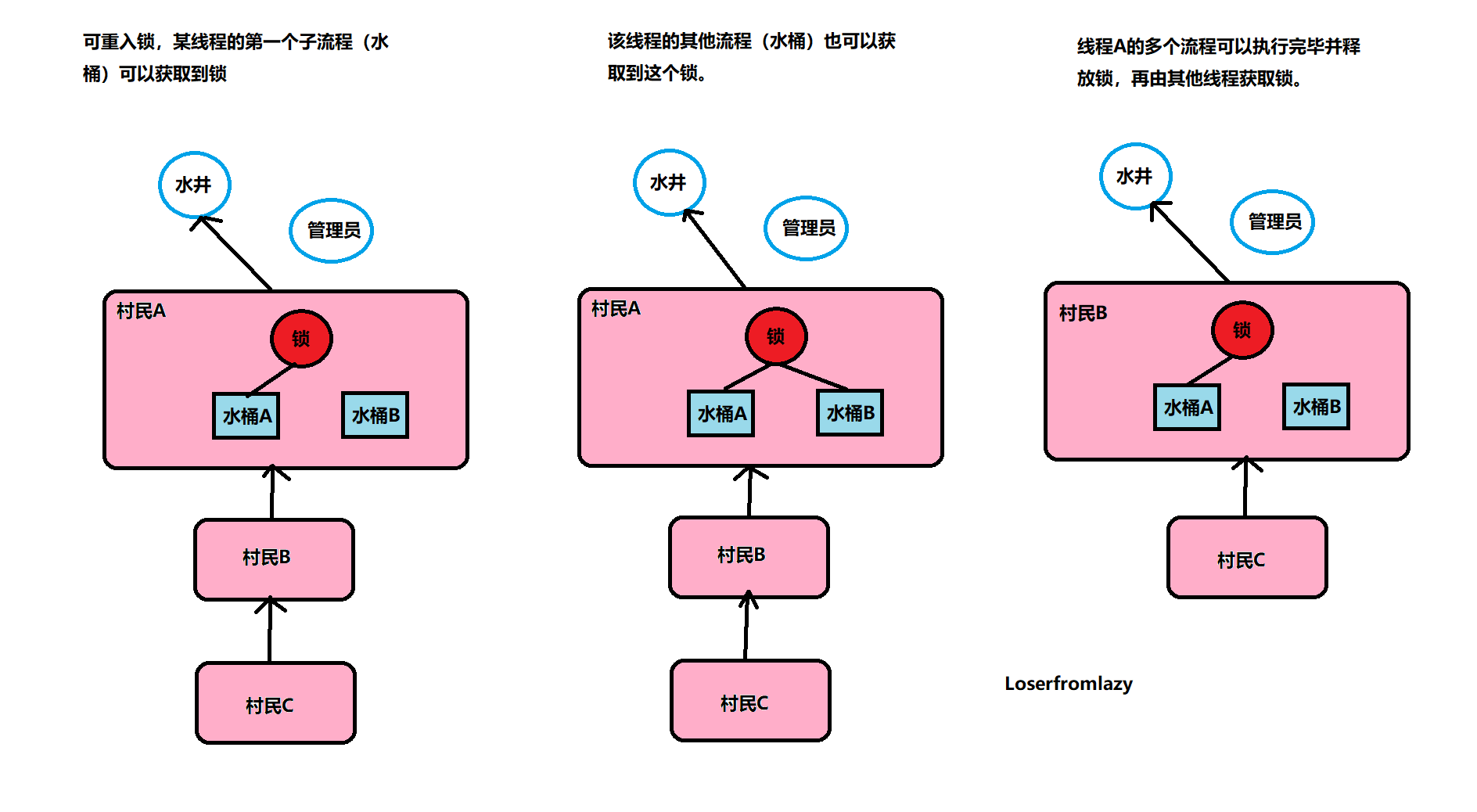

下面我们来根据zookeeper实现公平可重入锁,其原理主要是这样的:
- Zookeeper的临时顺序节点,会按顺序不断递增是一个天然的顺序发号器
- Zookeeper的节点是递增且有序的,可以保证锁的公平。我们只需要加锁前判断当前的节点是否是节点中最小的即可,这样就能保证锁的公平。
- Zookeeper的节点监听机制,可以保证锁的传递有序和高效,不像CLH锁,需要不断轮询前一个节点的状态,耗费资源。(CLH锁可以见我的显示锁学习笔记5.3节)同时还可以避免惊群效应,即一个节点释放锁,所有的节点都去抢锁。
也就是说我们将zookeeper当作锁的队列,队列中最小的就是持有锁的,其余节点等待并监听前一个节点的删除事件,如果前一个节点被删除,说明前一个线程释放了锁,当前线程就可以去抢锁了。
我们下面基于zookeeper实现一个简单的公平可重入锁。首先定义一个接口:
public interface Lock {
boolean lock();
boolean unlock();
}
然后编写一个单例的zookeeper的客户端:
public class ZkClient {
private static ZkClient zkClient = null;
private CuratorFramework client = null;
public CuratorFramework getClient() {
return client;
}
public void setClient(CuratorFramework client) {
this.client = client;
}
private static final String ZK_ADDRESS = "127.0.0.1:2181";
//饿汉式单例模式,通过synchronized保证线程安全
private ZkClient(){}
public static synchronized ZkClient getInstance(){
if (zkClient == null){
zkClient = new ZkClient();
zkClient.init();
}
return zkClient;
}
public void init() {
if (client == null){
//创建客户端
client = ClientFactory.createSimple(ZK_ADDRESS);
//启动客户端实例,连接服务器
client.start();
}
}
}
然后我们编写分布式锁,代码如下:
public class ZkLock implements Lock {
//我们分布式锁使用的节点的路径
private static final String LOCK_PATH = "/lock/mylock";
//分布式锁每一个节点的前缀
private static final String LOCK_PREFIX = LOCK_PATH + "/";
//当前锁的序号,这个属性是对象私有的,因为锁队列上每一个节点的状态是不一样的
private String lockNumber;
//前一个锁的序号,这个属性是对象私有的,因为锁队列上每一个节点的状态是不一样的
private String lastNumber;
CuratorFramework client = null;
//可重入锁计数
final AtomicInteger lockCount = new AtomicInteger(0);
Thread thread;
public ZkLock() {
//获取单例客户端
ZkClient.getInstance().init();
client = ZkClient.getInstance().getClient();
try {
Stat stat = client.checkExists().forPath(LOCK_PATH);
if (stat == null) {
client.create().creatingParentsIfNeeded().forPath(LOCK_PATH);
}
} catch (Exception e) {
e.printStackTrace();
}
}
//加锁方法
@Override
public boolean lock() {
//锁自己,防止出现重入的并发
synchronized (this) {
System.out.println("####当前数量"+lockCount.get());
if (lockCount.get() == 0) {
//第一次抢锁,设置当前线程
thread = Thread.currentThread();
lockCount.incrementAndGet();
} else {
//不是当前线程不能重入
if (!thread.equals(Thread.currentThread())) {
return false;
}
//是当前线程可以进行重入,直接返回true
lockCount.incrementAndGet();
return true;
}
}
try {
//通过zookeeper进行加锁
boolean locked = tryLock();
if (locked) {
return true;
}
//如果获取锁失败,则在队列中等待
while (!locked) {
//调用等待方法
await();
//如果结束等待,说明前一个节点被删除,当前节点被唤醒
//这时在判断一次自己是否是队列最小节点,是则加锁成功
List<String> waiters = getWaiters();
if (checkLocked(waiters)) {
locked = true;
}
}
return true;
} catch (Exception e) {
lockCount.decrementAndGet();
e.printStackTrace();
}
return false;
}
//解锁方法
@Override
public boolean unlock() {
//不是当前线程不能进行解锁
if (!thread.equals(Thread.currentThread())) {
return false;
}
lockCount.decrementAndGet();
if (lockCount.get() < 0) {
throw new RuntimeException("当前并未上锁,无法释放锁");
}
if (lockCount.get() != 0) {
return true;
}
try {
Stat stat = client.checkExists().forPath(LOCK_PREFIX + lockNumber);
if (stat != null) {
//删除自己的节点,表示当前持有的锁已释放
client.delete().forPath(LOCK_PREFIX + lockNumber);
}
} catch (Exception e) {
e.printStackTrace();
return false;
}
return true;
}
//尝试加锁
private boolean tryLock() throws Exception {
//创建一个临时顺序节点
String forPath = client.create().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath(LOCK_PREFIX);
//获取此节点的zookeeper生成的序号
lockNumber = forPath.substring(LOCK_PREFIX.length());
//获取队列中所有节点,判断自己是否是最小的,是则加锁成功。
List<String> waiters = getWaiters();
if (checkLocked(waiters)) {
return true;
}
//搜索自己在队列中的位置
int index = Collections.binarySearch(waiters, lockNumber);
if (index < 0) {
throw new RuntimeException("发生异常,找不到当前节点");
}
//保存自己的前一个节点的序号
lastNumber = LOCK_PREFIX + waiters.get(index - 1);
return false;
}
//检查自己是不是最小的节点
private boolean checkLocked(List<String> waiters) {
Collections.sort(waiters);
return lockNumber.equals(waiters.get(0));
}
//获取等待队列
private List<String> getWaiters() throws Exception {
return client.getChildren().forPath(LOCK_PATH);
}
//等待方法
private void await() throws Exception {
if (lastNumber == null) {
throw new RuntimeException("前一节点为空");
}
//利用CountDownLatch进行等待
CountDownLatch latch = new CountDownLatch(1);
//当前节点监听前一个节点的事件,如果前一个结点被删除,则结束等待
client.getData().usingWatcher((Watcher) event -> {
System.out.println("####监听到变化,event=" + event);
latch.countDown();
}).forPath(lastNumber);
System.out.println("####" + Thread.currentThread().getName() + "===>" + "进入了await" + "当前是" + lockNumber + "监听了" + lastNumber);
latch.await();
System.out.println("####" + Thread.currentThread().getName() + "===>" + "解除了await");
}
}
然后我们编写一个测试用例:
public class TestZkLock {
int count=0;
@Test
public void testZkLock() throws InterruptedException {
ExecutorService service = Executors.newFixedThreadPool(10);
for (int i = 0; i < 10; i++) {
service.execute(() -> {
ZkLock zkLock = new ZkLock();
zkLock.lock();
for (int j = 0; j < 10; j++) {
count++;
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
zkLock.unlock();
System.out.println("####"+count);
});
}
Thread.sleep(Integer.MAX_VALUE);
}
}
4.2 Curator的分布式锁
当然实际开发中不建议自己造轮子,而是使用现成的组件。Curator客户端中提供了各种分布式锁的实现,这里以InterProcessMutex可重入锁为例学习其使用方法:
@Test
public void testCuratorLock() throws InterruptedException {
CuratorFramework client = ZkClient.getInstance().getClient();
InterProcessMutex interProcessMutex = new InterProcessMutex(client, "/mutex");
ExecutorService service = Executors.newFixedThreadPool(10);
for (int i = 0; i < 10; i++) {
service.execute(() -> {
//获取互斥锁
try {
interProcessMutex.acquire();
for (int j = 0; j < 10; j++) {
count++;
}
Thread.sleep(1000);
//释放互斥锁
interProcessMutex.release();
System.out.println("####"+count);
} catch (Exception e) {
e.printStackTrace();
}
});
}
Thread.sleep(Integer.MAX_VALUE);
}
4.3 分布式锁的优缺点
Zookeeper的分布式锁的优点是有效的解决分布式问题和不可重入问题,使用简单。缺点是性能不高。因为每次创建和释放锁都要动态创建销毁瞬时节点,这样频繁的的网络通信性能是很低的。
目前的分布式锁的方案中主要有两种:
- 基于Redis的分布式锁:适用于并发高,性能要求高,可靠性可以通过其他方式弥补。
- 基于Zookeeper的分布式锁:适用于高可靠且并发不是很高的场景。
参考资料
参考资料:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号