Nginx高并发(三万字长文)
Nginx高并发编程
转载请声明!!!切勿剽窃他人成果。本文如有错误欢迎指正,感激不尽。
参考资料:Spring Cloud、Nginx高并发核心编程尼恩编著、以及菜鸟教程等互联网资源
所有例子均是本人亲自上机后,将代码或结果复制回来的。
一、Nginx/OpenResty详解
1.1 Nginx简介
Nginx有以下3个主要社区分支:
- Nginx官方版本:更新迭代比较快,并且提供免费版本和商业版本。
- Tengine:Tengine是由淘宝网发起的Web服务器项目。它在Nginx的基础上针对大访问量网站的需求添加了很多高级功能和特性。Tengine的性能和稳定性已经在大型的网站(如淘宝网、天猫商城等)得到了很好的检验。它的最终目标是打造一个高效、稳定、安全和易用的Web平台。
- OpenResty:2011年,中国人章亦春老师把LuaJIT VM嵌入Nginx中,实现了OpenResty这个高性能服务端解决方案。OpenResty是一个基于Nginx与Lua的高性能Web平台,其内部集成了大量精良的Lua库、第三方模块以及大多数的依赖项,用于方便地搭建能够处理超高并发、扩展性极高的动态Web应用、Web服务和动态网关。
OpenResty的目标是让Web服务直接跑在Nginx服务内部,充分利用Nginx的非阻塞I/O模型,不仅对HTTP客户端请求,甚至对远程后端(诸如MySQL、PostgreSQL、Memcached以及Redis等)都进行一致的高性能响应。OpenResty通过汇聚各种设计精良的Nginx模块(主要由OpenResty团队自主开发)从而将Nginx有效地变成一个强大的通用Web应用平台,使得Web开发人员和系统工程师可以使用Lua脚本语言调动Nginx支持的各种C以及Lua模块,快速构造出足以胜任10KB乃至1000KB以上单机并发连接的高性能Web应用系统。
1.1.1 正向代理和反向代理
正向代理和反向代理的使用场景说明:
- 正向代理的主要场景是客户端。由于网络不通等物理原因,需要通过正向代理服务器这种中间转发环节顺利访问目标服务器。当然,也可以通过正向代理服务器对客户端某些详细信息进行一些伪装和改变。
- 反向代理的主要场景是服务端。服务提供方可以通过反向代理服务器轻松实现目标服务器的动态切换,实现多目标服务器的负载均衡等。
通俗点来说,正向代理(如Squid、Proxy)是对客户端的伪装,隐藏了客户端的IP、头部或者其他信息,服务器得到的是伪装过的客户端信息;反向代理(如Nginx)是对目标服务器的伪装,隐藏了目标服务器的IP、头部或者其他信息,客户端得到的是伪装过的目标服务器信息。
1.1.2 Nginx启动与停止
这里用windows平台和OpenResty举例:
首先下载OpenResty的压缩包,然后解压,最后双击nginx.exe即可启动,启动后浏览器输入localhost,如果出现以下页面则启动成功。(Nginx同理)
关于Nginx的在windows/linux平台更详细的安装过程和编写更方便的nginx/OpenResty脚本的过程,这里推荐尼恩的博客,写的很详细,这里就不再赘述:
| 命令 | windows | linux | 备注 |
|---|---|---|---|
| 启动 | start .\nginx.exe |
./nginx |
启动服务 |
| 停止 | .\nginx.exe -s quit |
./nginx -s qiut |
quit安全停止,stop快速停止 |
| 重载 | .\nginx.exe -s reload |
./nginx -s reload |
修改配置文件后重新加载 |
| 重新打开日志 | .\nginx.exe -s reopen |
./nginx -s reopen |
重新打开日志,剪切日志,日志备份转移,不更改日志文件名**;而 **reload 更改配置会新按照最新的日志名创建文件 |
学习前有一点需要注意:如果你的echo在浏览器上只能下载文件后才能看到内容,那么你就可以通过加请求头来解决此问题(我的是因为使用了windows版本的openresty有此问题,我在linux上安装的没有此问题),请求头如下:
add_header Content-Type text/plain;
下面我们对nginx的启动命令参数进行详细的了解:
nginx的原始启动命令就是nginx,但是可以传参数,就像上面停止重载时的-s参数,下面我们来详细的了解一下各个参数的含义:
-
-v查看nginx的版本:
D:\IDEA\LuaDemo>nginx -v nginx version: openresty/1.21.4.1 -
-c此参数用于指定一个Nginx配置文件来替换默认的Nginx配置文件,例如我们下面要学习的lua编程中就是这么替换nginx的配置文件的:
D:\IDEA\LuaDemo\src>nginx -p ./ -c nginx-demo.conf
-
-t用于测试Nginx的配置文件,如果不能确定Nginx配置文件的语法是否正确,就可以通过Nginx的-t命令进行测试。
-
-p此参数用于设置前缀路径,nginx配置文件中用到的相对路径都会加上这个前缀
-
-s表示给nginx发送进程信号包括stop(停止)或reload(重载)
1.2 Nginx原理
1.2.1 Reactor模式
关于Reactor模式,我们在上一篇学习NIO和Netty中,有学到过。这是一种高性能的事件驱动模式,具体可以在NIO和Netty的学习笔记中进行查看。
正是由于 Nginx 使用了高性能的 Reactor 模式,因此是目前并发能力很高的 Web 服务器之一,成为迄今为止使用广泛的工业级 Web 服务器。当然,Nginx 也解决了著名的网络读写的 C10K问题。什么是 C10K 问题呢?网络服务在处理数以万计的客户端连接时,往往出现效率低下甚至完全瘫痪,这类问题就被称为 C10K 问题。
1.2.2 Nginx的两类进程
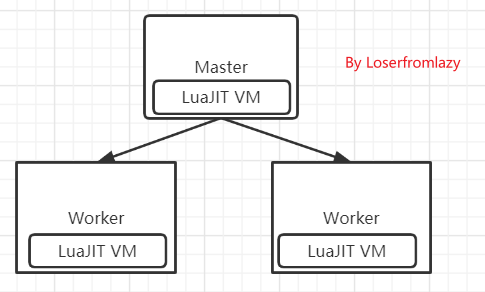
nginx有两种启动方式:一种是单进程启动,还有一种是多进程启动。在单进程启动时,系统中只有一个进程,该进程即当Master角色,又当Worker角色。在多进程启动时,系统中有且只有一个master进程,至少有一个worker进程。如下图:

nginx启动后会以守护进程的方式在后台运行,其后台进程有两类,一类是Master进程,一类是Worker进程。
Master管理进程的工作主要有以下两点:
- 负责调度Worker工作进程,比如加载配置、启动工作进程、接收外界信号、向Worker发送信号、监控Worker进程的运行状态等。
- 负责创建监听套接字,交由Worker进程进行连接监听。
而Worker工作进程主要用来处理网络事件当一个 Worker 进程在接收一条连接通道之后,就开始读取请求、解析请求、处理请求,处理完成产生数据后,再返回给客户端,最后断开连接通道。
各个Worker进程之间是对等且相互独立的,它们同等竞争来自客户端的请求,一个请求只可能在一个 Worker 进程中处理。这都是典型的 Reactor 模型中 Worker 进程(或者线程)的职能。
如果启动了多个 Worker 进程,那么每个 Worker 子进程独自尝试接收已连接的 Socket 监听通道,accept 操作默认会上锁,优先使用操作系统的共享内存原子锁,如果操作系统不支持,就使用文件上锁。
Worker 进程的接收操作也可以不使用锁,在多个进程同时接收时,当一个连接进来的时候多个工作进程同时被唤起,则会导致惊群问题。而在上锁的场景下,只会有一个 Worker阻塞在 accept 上,其他的进程会因为不能获取锁而阻塞,所以上锁的场景不存在惊群问题。
1.2.3 Nginx的模块化设计
Nginx服务器被分解为多个模块,各个模块遵循高内聚、低耦合的原则,每个模块聚焦一个功能,高度模块化是Nginx的架构基础。
在Nginx中,一个模块包括一系列命令,和这些命令的处理函数。Nginx的Worker进程在执行过程中会通过配置文件的配置定位到对应模块的某个命令,然后调用命令对应的处理函数完成处理。Nginx的Worker进程会首先调用Core核心模块,这个模块内部会维护一个循环,主要包括事件的收集、分发、处理。Core模块负责执行网络请求处理的基础操作,比如网络读写、存储读写、内容传输、外出过滤以及请求发往上游服务器等。
Nginx的Core模块是启动时一定会加载的,其余模块只有在解析配置时遇到了才会加载对应的模块。Core模块为其他模块构建了基本的运行时环境。当然除了Core,Nginx还有其他比如Event、Conf、HTTP等一系列模块,Nginx的模块结构如下图(图片来自于Spring Cloud、Nginx高并发核心编程一书):
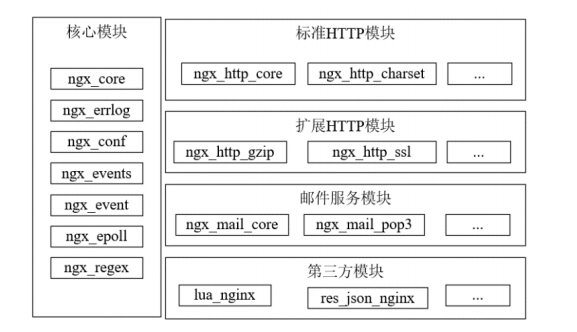
主要模块:
- Core核心模块:必不可少,提供了错误日志记录、配置文件解析、Reactor事件驱动、进程管理等核心功能。
- 标准HTTP模块:提供解析HTTP协议的相关功能,比如端口配置、网页编码配置、HTTP响应头设置等
- 可选HTTP模块:主要用于扩展标准的HTTP功能,让Nginx能处理一些特殊的服务,比如Flash多媒体、网络传输压缩、SSL等
- 邮件服务模块:主要用于支持Nginx的邮件服务,包括PoP3、IMAP、SMTP的支持。
- 第三方模块:用于拓展Nginx服务器的功能,定制自定义功能,比如支持JSON、Lua等。
1.2.4 Nginx配置文件的结构
一个Nginx功能模块包含一系列命令以及对应的处理函数。而Nginx会根据配置文件中的指令就知道对应到哪个模块的哪个命令,然后调用对应的处理函数来处理。
一个Nginx配置文件包含若干配置项,每个配置项由配置指令和指令参数两部分组成,可以简单认为配置项就是一个键值对:
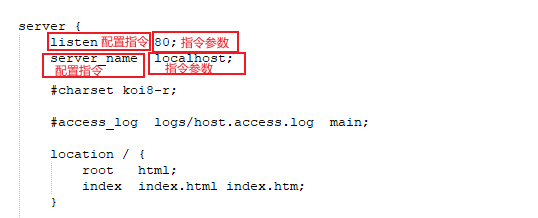
Nginx配置文件中的配置指令如果包含空格,就需要用单引号和双引号引起来。指令参数如果是简单的字符串就以分号结束,如果是复杂的多行字符串,配置项就用花括号{}括起来。
Nginx配置文件的配置块大致有5种,其结构如下:
... #全局块
events { #events块
...
}
http #http块
{
... #http全局块
server #server块
{
... #server全局块
location [PATTERN] #location块
{
...
}
location [PATTERN]
{
...
}
}
server
{
...
}
... #http全局块
}
mail #mail服务配置块
{
...#email相关协议配置
}
- 全局块:配置影响nginx全局的指令。一般有运行nginx服务器的用户组,nginx进程pid存放路径,日志存放路径,配置文件引入,允许生成worker process数等。
- events块:配置影响nginx服务器或与用户的网络连接。有每个进程的最大连接数,选取哪种事件驱动模型处理连接请求,是否允许同时接受多个网路连接,开启多个网络连接序列化等。
- http块:可以嵌套多个server,http块是配置最频繁的部分,常见有:虚拟主机的配置,监听端口的配置,请求转发,反向代理,负载均衡配置等。
- server块:配置虚拟主机的相关参数,一个http中可以有多个server。
- location块:配置请求的路由,以及各种页面的处理情况。
- mail块:Nginx 为 email 相关协议(如 SMTP/IMAP/POP3)提供反向代理时,mail 服务配置块负责配置一些相关的配置项
1.2.5 Nginx请求处理流程
Nginx中HTTP请求的处理流程可以分为4步:
- 读取解析请求行
- 读取解析请求头
- 多阶段处理,执行handler处理器列表
- 将结果返回给客户端
多阶段处理时Nginx处理HTTP请求流程中重要的一步,Nginx将请求划分为11个阶段,在完成第一步和第二步后,Nginx将请求封装到请求结构体中ngx_http_request中,然后进入到第三步。
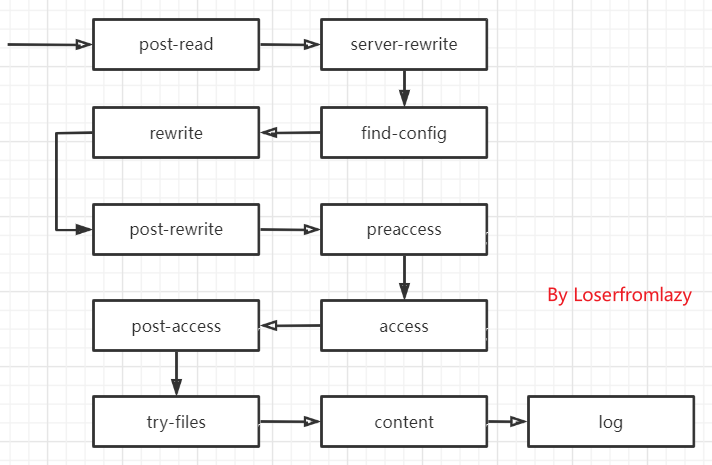
-
post-read阶段:完成读取解析请求头和请求行后,首先就是这个阶段,注册在这个阶段的处理器不多,标准模块的ngx_realip处理器就在这个模块,而ngx_realip的作用是改写请求的来源地址。
ngx_realip:当Nginx处理的请求经过了某个正向代理服务器的转发后,ip地址可能就不是真实IP地址了,而是变成下游服务器的IP,解决办法之一就是将原来的IP地址放到HTTP请求头中,Nginx获取后传给Nginx的上游服务器,ngx_realip就是这个作用。
比如以下配置:将正向代理服务器192.168.0.100的所有请求的IP地址修改为请求头X-MY-IP所指定的值,然后放在$remote_addr内置标准变量中。
server{ listen 8080; set_real_ip_from 192.168.0.100; real_ip_header X-MY-IP; location /test { echo "from: $remote_addr" } } -
server-rewrite
这个阶段是server块中的请求地址重写阶段,在进行UIR与location路由规则匹配之前可以修改请求的URI地址。大部分在server块中的配置项都在这个阶段运行,比如:
server{ listen 8080; set $a hello;#在server-rewrite阶段运行 location /test { set $b "$a world"; echo $b; } set $b hello;#在server-rewrite阶段运行 }两个变量赋值直接写在server配置块中,因此他们就运行在server-rewrite阶段。
-
find-config
这个阶段叫配置查找阶段,主要功能是根据URL地址去匹配location路由表达式。此阶段由Nginx HTTP Core模块全部负责,并完成当前请求URL和location配置块之间的配对工作,这个阶段不支持 Nginx 模块注册处理程序。
在
find-config阶段之前,客户端请求并没有与任何location配置块相关联,在此之前的 post-read 和 server-rewrite 阶段来说,只有 server 配置块以及更外层作用域中的配置项才会起作用,location 配置块中的配置项不起作用。 -
rewrite
由于Nginx在find-config阶段完成了当前请求和location的匹配,因此从rewrite阶段开始,location配置块中的指令就起作用了。
这个阶段也叫请求地址重写阶段,rewrite 阶段也叫请求地址重写阶段,注册在 rewrite 阶段的指令首先是 ngx_rewrite 模块的指令,比如 break、if、return、rewrite、set 等。其次,第三方ngx_lua 模块中的 set_by_lua 指令和rewrite_by_lua 指令也能在此阶段注册。
-
post-rewrite
请求地址URI重写提交阶段,防止修改递归修改URI造成死循环(一个请求执行 10 次就会被 Nginx 认定为死循环)该阶段只能由 Nginx HTTP Core(ngx_http_core_module)模块实现。
-
preaccess
访问权限检查准备阶段,控制访问频率的 ngx_limit_req 模块和限制并发度的 ngx_limit_zone模块的相关指令就注册在此阶段。
-
access
在访问权限检查阶段,配置指令大多是执行访问控制类型的任务,比如检查用户的访问权限、检查用户的来源IP地址是否合法等。在此阶段注册的指令有:HTTP标准模块ngx_http_access_module 的指令、第三方 ngx_auth_request 模块的指令、第三方 ngx_lua 模块的access_by_lua 指令等。
比如,deny和allow指令属于ngx_http_access_module模块,使用示例如下:
server{ #... #拒绝全部 location = /denyall { dent all; } #允许来源ip属于192.168.0.0/24网段或127.0.0.1的请求,其他来源的ip全部拒绝 location = /allowsome { allow 192.168.0.0/24; allow 127.0.0.1; deny all; echo "this is ok"; } #... }如果同一个location配置了多个allow/deny配置项,access阶段的配置项之间是按照配置的先后顺序匹配的,匹配成功一个跳出。在上面的例子中,如果客户端的ip是127.0.0.1,则匹配到
allow 127.0.0.1;配置项后就不在匹配后面的deny all;,也就是说不会被拒绝。如果这些配置项的指令来自不同的模块,则每个模块会执行一个访问控制类型的指令。echo 指令用于返回内容,在 location 上下文中,该指令注册在 content 生产阶段。由于 echo 指令不是注册在 access 阶段,因此在 access 阶段不执行该指令的配置项。
-
post-access
访问权限检查提交阶段。如果请求不被允许访问Nginx服务器,该阶段负责向用户返回错误响应。在access阶段可能存在多个访问控制模块的指令注册,post-access阶段的satisfy配置指令可以用于控制它们之间的协作方式。比如:
location = /satisfy-demo { satisfy any; access_by_lua "ngx.exit(ngx.OK)"; deny all; echo "this is ok"; }在这个例子中,deny指令属于HTTP标准模块的ngx_http_access_module访问控制模块,而access_by_lua指令属于第三方ngx_lua模块,两个模块都有自己的计算结果,需要最终进行结果统一。
而这个统一工作由satisfy指令负责:
-
逻辑或操作
具体的配置项为
satisfy any;,表示访问控制模块A、B、C或更多只要其中任意一个通过验证就算通过 -
逻辑与操作
具体的配置项为
satisfy all;,表示访问控制模块A、B、C或更多全部模块都通过验证才算通过
-
-
try-files
如果HTTP请求访问静态资源文件,那么try-files配置项可以使这个请求按顺序访问多个静态资源文件,直到某个静态文件符合选取条件。这个阶段不支持Nginx模块注册处理程序,只有一个标准配置指令
try-files。try-files 指令接收两个以上任意数量的参数,每个参数都指定了一个 URI,Nginx 会在 try-files阶段依次把前 N-1 个参数映射为文件系统上的对象(文件或者目录),然后检查这些对象是否存在。若 Nginx 发现某个文件系统对象存在,则查找成功,进而在 try-files 阶段把当前请求的 URI改写为该对象所对应的参数 URI(但不会包含末尾的斜杠字符,也不会发生“内部跳转”)。如果前 N-1 个参数所对应的文件系统对象都不存在,try-files 阶段就会立即发起“内部跳转”,跳转到最后一个参数(第 N 个参数)所指定的 URI。
这里举个例子:
root /var/www; #root指令把查找文件的根目录配置为/var/www/ location = /try_files-demo { try_files /foo /bar /last; } # 对应到前面 try_files的最后一个URI location /last{ echo "uri: $uri"; }这里 try-files 会在文件系统查找前两个参数对应的文件 /var/www/foo 和 /var/www/bar 所对应的文件是否存在。如果不存在,此时 Nginx 就会在 try-files 阶段发起到最后一个参数所指定的URI(/last)的内部跳转。
-
content
大部分 HTTP 模块会介入内容产生阶段,是所有请求处理阶段中重要的阶段。Nginx 的 echo指令、第三方 ngx_lua 模块的 content_by_lua 指令都注册在此阶段。
这里要注意的是,每一个 location 只能有一个“内容处理程序”,因此,当在 location 中同时使用多个模块的 content 阶段指令时,只有一个模块能成功注册成为“内容处理器”。例如 echo和 content_by_lua 同时注册,最终只会有一个生效,但具体是哪一个生效,结果是不稳定的。
-
log
日志模块处理阶段,记录日志。
Nginx 将一个HTTP请求分为11个处理阶段,这样做让每个HTTP模块可以只专注于完成一个独立、简单的功能。而一个请求的完整处理过程由多个 HTTP 模块共同合作完成,可以极大地提高多个模块合作的协同性、可测试性和可扩展性。
Nginx 请求处理的 11 个阶段中,有些阶段是必备的,有些阶段是可选的,各个阶段可以允许多个模块的指令同时注册。但是,find-config、post-rewrite、post-access、try-files 四个阶段是不允许其他模块的处理指令注册的,它们仅注册了 HTTP 框架自身实现的几个固定的方法。同一个阶段内的指令,Nginx 会按照各个指令的上下文顺序执行对应的 handler 处理器方法。
1.3 Nginx的基础配置
1.3.1 events事件驱动配置
一个典型的events事件模型配置块的示例:
events {
use epoll; #使用epoll类型的IO多路复用
worker_connections 204800; #最大连接数限制为20万
accept_mutex on;#各个worker通过锁来获取新连接
}
-
worker_connections 用于配置每个Worker进程能打开的最大并发连接数量,指令参数为连接数的上限。
-
use use 指令用于配置 IO 多路复用模型,有多种模型可配置,常用的有 select、epoll 两种。在windows的默认为select。可以通过将nginx的日志级别调整为debug,在errors_log中就可以看到了,以下是我的日志:
2022/06/20 14:05:08 [notice] 10024#11096: using the "select" event method 2022/06/20 14:05:08 [notice] 10024#11096: openresty/1.21.4.1 -
accept_mutex
这个指令用于配置各个Worker进程是否通过互斥锁有序接收新的连接请求。on参数表示各个Worker通过互斥锁有序接受新请求;off参数指每个新请求到达时会通知(唤醒)所有的Worker进程参与争抢,但只有一个进程可获得连接。配置off参数会造成惊群问题影响性能。accept_mutex指令的参数默认为on。
1.3.2 虚拟主机配置
配置虚拟主机可使用 server 指令。虚拟主机的基础配置包含套接字配置、虚拟主机名称配置等。
虚拟主机的监听套接字配置:
-
使用listen指令直接配置监听端口
server{ listen 80; } -
使用listen指令配置监听的IP和端口
server{ listen 127.0.0.1:80; }
虚拟主机名称配置:
虚拟主机名称配置可使用 server_name 指令。基于微服务架构的分布式平台有很多类型的服务,比如文件服务、后台服务、基础服务等。很多情况下,可以通过域名前缀的方式进行 URL 路径区分,示例如下:
#后台管理服务的虚拟主机
server {
listen 80;
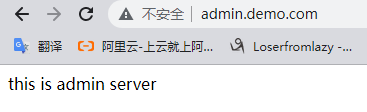
server_name admin.demo.com;
location /{
default_type 'text/html';
charset utf-8;
echo "this is admin server";
}
}
#文件服务的虚拟主机
server {
listen 80;
server_name file.demo.com;
location /{
default_type 'text/html';
charset utf-8;
echo "this is file server";
}
}
#默认服务的虚拟主机
server {
listen 80 default;
server_name demo.com *.demo.com;#如果没有前缀,这就是默认访问的虚拟主机
location /{
default_type 'text/html';
charset utf-8;
echo "this is default server";
}
}
当然如果想访问上面的3个虚拟主机,那么就需要域名服务器或本地hosts文件解析出域名对应的IP地址,所以可以修改本地hosts文件:
127.0.0.1 demo.com
127.0.0.1 file.demo.com
127.0.0.1 admin.demo.com
127.0.0.1 xxx.demo.com
重启Nginx后,在浏览器中访问,结果如下:
多个虚拟主机的优先级如下:
- 字符串精确匹配:如果请求域名为
admin.demo.com,那么就会匹配到名称为admin.demo.com的虚拟主机 - 左侧
*通配符匹配:若浏览器请求的域名为xxx.crazydemo.com,则会匹配到*.crazydemo.com虚拟主机。因为配置文件中并没有server_name为xxx.crazydemo.com的主机,所以退而求其次,名称为*.crazydemo.com的虚拟主机按照通配符规则匹配成功 - 右侧
*通配符匹配:右侧通配符和左侧通配符匹配类似,只不过优先级低于左侧通配符匹配 - 正则表达式匹配:与通配符匹配类似,不过优先级更低。
- default_server:在listen指令后面如果带有default的指令参数,就代表这是默认的、最后兜底的虚拟主机,如果前面的匹配规则都没有命中,就只能命中 default_server 指定的默认主机。
1.3.3 错误页面配置
错误页面的配置指令为error_page,格式如下:
error_page code ... [=[response]] uri;
code表示响应码,可以同时配置多个:uri表示错误页面,一般为服务器上的静态资源页面。例如:
server{
listen 80;
server_name admin.demo.com;
location /{
default_type 'text/html';
charset utf-8;
echo "this is admin server";
}
error_page 404 /404.html;
error_page 500 502 503 504 /50x.html
}
error_page 指令除了可用于 server 上下文外,还可用于 http、server、location、if in location 等上下文。
1.3.4 长连接相关配置
配置长连接的有效时长可以使用keppalive_timeout指令,格式如下:
keepalive_timeout timeout [header_timeout];
其中timeout参数用于设置保持连接超时时长,0表示禁止长连接,默认为75s。如果要配置长连接的一条连接允许的最大请求数,可以使用,以下指令:
keepalive_request number;
其中number参数用于设置在一条长连接上被允许请求的资源的最大数量,默认为100。如果要配置向客户端发送响应报文的超时限制,可以使用下面的指令:
send_timeout time;
其中time参数用于设置Nginx向客户端发送响应报文的超时限制,此处时长是指两次向客户但写操作之间的间隔时长,并非整个响应过程的传输时长。
1.3.5 访问日志配置
Nginx 将客户端的访问日志信息记录到指定的日志文件中,用于后期分析用户的浏览行为等,此功能由 ngx_http_log_module 模块负责,其指令在 HTTP 处理流程的 log 阶段执行。格式如下:
access_log path [format [buffer=size] [gzip[=level]] [flush=time] [if=condition]];
其中,path表示日志文件的本地路径;format表示日志输出的格式名称。定义日志输出的格式的指令是log_format:log_format name string ...;其中name参数用于指定格式名称;string参数用于设置格式字符串,可以有多个。字符串中可以使用Nginx核心模块及其他模块的内置变量。
举例:
http{
#定义日志格式
log_format format_main '$remote_addr - $remote_user [$time_local] $request -' '$status - $body_bytes_sent [$http_referer]' '[$http_user_agent] [$http_x_forwarded_for]';
#配置:日志文件、访问日志格式
access_log logs/access_main.log format_main;
}
修改配置后,重启Nginx,然后发一条请求(用上面配置的hosts域名访问),就可以在access_main.log中看到新增的日志记录。
下面介绍一下各个Nginx内置变量:
- $request:记录用户的HTTP请求起始行
- $status:记录HTTP状态码
- $remote_addr:记录访问网站的客户端地址
- $remote_user:记录访问网站的客户端用户名你
- $time_local:记录访问时间与时区
- $body_bytes_sent:记录服务器发送给客户端的响应body字节数
- $http_referer:记录此次请求是从哪个链接访问过来的,可以根据其进行防盗链的监测
- $http_user_agent:记录客户端访问信息,如浏览器手机客户端等
- $http_x_forwarded_for:当前有正向代理服务器时,此参数用于保持客户端真实的IP地址。该参数生效的前提是;前端的代理服务器上进行了相关的x_forwarded_for设置。
1.3.6 Nginx核心模块内置变量
Nginx 核心模块 ngx_http_core_module 中定义了一系列存储 HTTP 请求信息的变量,例如$http_user_agent、$http_cookie 等。这些内置变量在 Nginx 配置过程中使用较多,下面介绍常用内置变量:
- $arg_PARAMETER:请求URL中以PARAMETER为名称的参数值。请求参数即URL的的值,如
/index.php?site=www.ttlsa.com,可以用$arg_site 取得www.ttlsa.com这个值. - $args:请求URL中的整个参数串,其作用与$query_string相同
- $binary_remote_addr:二进制形式的客户端地址
- $body_bytes_sent:传输给客户端的字节数,响应头不计算在内
- $bytes_sent:传输给客户端的字节数,包含响应头和响应体
- $content_length:等同于$http_content_length,用于获取请求体body的大小,指的是Nginx从客户端收到的请求头中Content-Length字段的值,不是发送给客户端响应中的Content-Length,如果想获取响应中的Content-Length,应该用$sent_http_content_length
- $request_length:请求的字节数(包括请求行、请求头和请求体)。由于$request_length是请求解析过程中不断累加的,如果解析请求时出现异常,那么$request_length是已经累加部分的长度,不是完整长度。
- $connection:TCP 连接的序列号
- $connection_requests:TCP 连接当前的请求数量
- $content_type:请求中的 Content-Type 请求头字段值
- $cookie_name:请求中名称 name 的 cookie 值
- $document_root:当前请求的文档根目录或别名
- $uri:当前请求中的 URI(不带请求参数,参数位于$args 变量)$uri 变量值不包含主机名,举个例子像
/foo/bar.html这样 - $request_uri:包含客户端请求参数的原始 URI,不包含主机名,此参数不可以修改,举个例子像
/foo/bar.html? name=value这样 - $host:请求的主机名。优先级为:HTTP 请求行的主机名 > HOST 请求头字段 > 符合请求的服务器名
- $http_NAME:名称为NAME的请求头的值。如果实际请求头NAME中包含中画线
-,那么需要将中画线-替换为下画线_;如果实际请求头 name 中包含大写字母,那么可以替换为小写字母。例如获取 Accept-Language 请求头的值,变量名称为$http_accept_language - $msec:当前的 UNIX 时间戳。UNIX 时间戳是从 1970 年 1 月 1 日(UTC/GMT 的午夜)开始所经过的秒数,不考虑闰秒
- $nginx_version:获取 Nginx 版本
- $pid:获取 Worker 工作进程的 PID
- $proxy_protocol_addr:代理访问服务器的客户端地址,如果是直接访问,那么该值为空字符串
- $realpath_root:当前请求的文档根目录或别名的真实路径,会将所有符号连接转换为真实路径
- $remote_addr:客户端请求地址
- $remote_port:客户端请求端口
- $request_body:客户端请求主体。此变量可在 location 中使用,将请求主体通过proxy_pass、fastcgi_pass、uwsgi_pass 和 scgi_pass 传递给下一级的代理服务器
- $request_completion:如果请求成功,那么值为 OK;如果请求未完成或者请求不是一个范围请求的最后一部分,那么值为空
- $request_filename:当前请求的文件路径,由 root 或 alias 指令与 URI 请求结合生成
- $request_length:请求的长度,包括请求的地址、HTTP 请求头和请求主体
- $request_method:HTTP 请求方法,比如 GET 或 POST 等
- $request_time:处理客户端请求使用的时间,从读取客户端的第一个字节开始计时
- $scheme:请求使用的 Web 协议,如 HTTP 或 HTTPS
- $sent_http_NAME:设置任意名称为NAME的 HTTP 响应头字段。例如,如果需要设置响应头 Content-Length,那么将“-”替换为下画线,大写字母替换为小写字母,变量为
$sent_http_content_length - $server_addr:服务器端地址为了避免访问操作系统内核,应将 IP 地址提前设置在配置文件中
- $server_name:虚拟主机的服务器名,如 demo.com
- $server_port:虚拟主机的服务器端口
- $server_protocol:服务器的 HTTP 版本,通常为 HTTP/1.0 或 HTTP/1.1
- $status:HTTP 响应代码
1.4 location路由规则匹配
location 路由匹配发生在 HTTP 请求处理的 find-config 配置查找阶段,主要功能是:根据请求的 URI 地址匹配 location 路由表达式,如果匹配成功,就执行 location 后面的上下文配置块。
1.4.1 location语法
Nginx配置文件中,location配置项的语法格式如下:
location [=|~|~*|^*] 模式字符串{
...
}
按照匹配符号不同,可以分为精准匹配、普通匹配、正则匹配、默认根路径匹配。
-
精准匹配
精准匹配的符号标记为
=,下面是一个location的例子:location = /test { echo "location = /test"; }如果请求的URI和精准匹配的模式字符串
/test完全相同,那么精准匹配通过。精准匹配的优先级最高。 -
普通匹配
普通匹配的符号标记为
^~下面是一个普通匹配的例子location ^~ /test { echo "location= ^~/test" }普通匹配属于字符串前缀匹配,如果请求路径URI头部匹配到location的模式字符串,那么就匹配成功,如果匹配到多个前缀那么最长模式匹配优先。
location ^~ /test { echo "location= ^~/test" } location ^~ /test/long { echo "location= ^~/test" }普通匹配是前缀匹配,也是 Nginx 默认的匹配类型。也就是说,类型符号“^~”可以省略,如果 location 没有任何匹配类型,就为普通的前缀匹配。如果一个 URI 命中多个 location 普通匹配,则最长的 location 普通匹配当选。
-
正则匹配
正则匹配按照符号类型不同可以分为以下4种:
~:标准正则匹配,区分大小写,进行正则测试,测试成功则匹配成功。~*:标准正则匹配,不区分大小写字母,进行正则表达式测试,测试成功则匹配成功。!~:反向正则匹配,区分大小写,进行正则测试,测试成功则匹配成功。!~*:反向正则匹配,不区分大小写字母,进行正则表达式测试,测试成功则匹配成功。
-
默认根路径匹配
随便访问一个地址,如果不能匹配其他location则匹配到根路径地址
location / { echo "默认根路径匹配= /"; }表面看上去,location 根路径匹配非常类似普通匹配,但实际上该规则自成一类,虽然只有唯一的一个路径,但是此类规则优先级是最低的。
-
匹配优先级
- 类型之间的优先级:精准匹配>普通匹配>正则匹配>根路径匹配
- 普通类型匹配之间的优先级位最长前缀优先,普通匹配的优先级与location在配置文件中的先后顺序无关。
- 正则匹配同类型location之间的优先级为顺序优先,只要匹配到第一个正则规则的location就停止后面的正则规则的测试。正则匹配与location规则定义在配置文件中的先后顺序强相关。
1.4.2 常用配置
-
根路由配置:
-
首先,根路径可以路由到一个静态首页,比如:
location / { root html; index index.html index.htm; }表示在请求匹配到
/跟路由规则时,首先Nginx会在html目录下查找index.html文件,如果没有找到,就查找index.htm文件,将找到的文件返回给客户端。 -
或者根路由规则也可以匹配到一个访问很频繁的上游服务,比如Spring Cloud 的微服务网关。
location / { proxy_pass http://127.0.0.1:8999/; }这里127.0.0.1:8999假定是微服务网关的IP和端口,当请求匹配到跟路由规则时,将直接转发给上游微服务网关。
-
-
静态文件路由规则
对静态文件进行访问时Nginx作为HTTP服务器的强项。静态文件匹配规则有两种配置方式:目录匹配(前缀匹配)和后缀匹配(正则匹配)。例如:
root /www/resources/static/; location ^~ /static/{ root /www/resources/; }所有
/static/...规则的静态资源请求都将路由到root指令所配置的文件目录/www/resources/static/下对应的某个文件,比如(/www/resources/static/img/001.jpg)后缀匹配例子如下:
location ~*\.(gif|jpg|jepg|png|css|js|ico){ root /www/resources/; }所有匹配到正则规则的静态资源请求都将路由到root指令所配置的文件目录。
1.5 Nginx的rewrite模块
Nginx的rewrite模块是ngx_http_rewrite_module标准模块,主要功能是重写请求URI,也是nginx默认安装的模块,rewrite模块会根据PCRE正则重写URI,然后根据指令参数或者发起内部跳转再进行一次location匹配,或者直接进行30x重定向返回客户端。
rewrite模块的指令是一门微型编程语言,包含set、rewrite、break、if、return等一系列指令
1.5.1 set指令
set指令主要用于存放变量值,在Nginx的配置文件中,变量只有一种,就是字符串。set指令格式:
set $var value;
在nginx中,变量的定义和使用都要以$开头。另外变量名不能和Nginx服务器预设的变量名同名。
下面举个例子:
set $a "hello world";#对变量a进行赋值
set $b "$a,hello nginx";#通过变量a构造变量b
像上面,在字符串中使用变量a,在linux shell脚本中常用到,叫做变量插值。set指令不仅有赋值的功能,还有创建nginx变量的作用,即当变量不存在时会自动创建,比如上面例子的变量a。
Nginx 变量一旦创建,其变量名的可见范围就是整个 Nginx 配置,甚至可以跨越不同虚拟主机的 server 配置块。但是,对于每个请求,所有变量都有一份独立的副本,或者说都有各变量用来存放值的容器的独立副本,彼此互不干扰。Nginx 变量的生命周期是不可跨越请求边界的。
1.5.2 rewrite指令
rewrite指令主要功能是改写请求的URI,可以使用在server、location、if in location。格式如下:
rewrite regrex replacement [flga];
如果regrex匹配URI,URI就会被替换成replacement的计算结果,replacement一般是一个变量插值表达式,其计算结果的字符串就是新的URI。比如:
location /download/ {
rewrite ^/download/(.*)/video/(.*)$ /view/$1/mp3/$2.mp3 last;
rewrite ^/download/(.*)/audio/(.*)$ /view/$1/mp3/$2.rmvb last;
return 404;
}
location /view {
#add_header Content-Type text/plain;
echo "uri: $uri";
}
在浏览器中请求匹配上面例子的地址,如http://crazydemo.com/download/1/video/10,访问之后地址发生了重写,并且发生了location 的跳转。
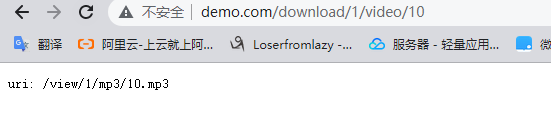
在上面的例子中,replacement中的$1和$2是从regrex正则表达式从原始URI中匹配出来的子字符串,也叫正则捕获组。
如果同一个上下文中有多个rewrite指令,那么就会按照rewrite指令出现的顺序进行匹配,匹配成功后可以用第三个指令[flag]进行设置:
-
如果 flag 参数使用 last 值,并且匹配成功,那么停止处理任何 rewrite 相关的指令,立即用计算后的新 URI 开始下一轮的 location 匹配和跳转。前面的例子使用的就是 last 参数值。
-
如果 flag 参数使用 break 值,就如同 break 指令的字面意思一样,停止处理任何 rewrite 的相关指令,但是不进行 location 跳转
如果我们将上面的last改成break,我们就能看到效果:
location /view { #add_header Content-Type text/plain; echo "uri: $uri"; } location /download/ { rewrite ^/download/(.*)/video/(.*)$ /view/$1/mp3/$2.mp3 break; rewrite ^/download/(.*)/audio/(.*)$ /view/$1/mp3/$2.rmvb break; #add_header Content-Type text/plain; echo "break: $uri"; return 404; }我们访问地址后,效果如下:
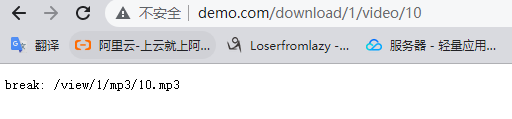
可以看到地址发生了重写,但是location 并没有跳转,而是直接结束了。
在 location 上下文中,last 和 break 是有区别的:last 其实就相当于一个新的 URL,Nginx 进行了一次新的 location 匹配,通过 last 获得一个可以转到其他 location 配置中处理的机会(内部的重定向);而 break 在一个 location 中将原来的 URL(包括 URI 和 args)改写之后,再继续进行后面的处理,这个重写之后的请求始终都是在同一个 location 上下文中,并没有发生内部跳转。
这里要注意:last 和 break 的区别仅仅发生在 location 上下文中;如果发生在 server 上下文,那么 last 和 break 的作用是一样的。
还要注意:在 location 上下文中的 rewrite 指令使用 last 指令参数会再次以新的 URI 重新发起内部重定向,再次进行 location 匹配,而新的 URI 极有可能和旧的 URI 一样再次匹配到相同的目标 location 中,这样死循环就发生了。当循环到第 10 次时,Nginx 会终止这样无意义的循环并返回 500 错误。
-
如果 rewrite 指令使用的 flag 参数的值是 permanent,就表示进行外部重定向,也就是在客户端进行重定向。此时,服务器将新 URI 地址返回给客户端浏览器,并且返回 301(永久重定向的响应码)给客户端。客户端将使用新的重定向地址再发起一次远程请求。
外部重定向与内部重定向是有本质区别的。从数量上说,外部重定向有两次请求,内部重定向只有一次请求。
-
如果 rewrite 指令使用的 flag 参数的值是 redirect,就表示进行外部重定向,表现的行为与permanent 参数值完全一样,不同的是返回 302(临时重定向的响应码)给客户端。
1.5.3 if条件指令
if指令的格式如下:
if(condition){...}
当if条件满足时,执行配置块中的指令,if指令的配置块相当于一个新的上下文作用域。if指令适用于server和location。
if的congdition有如下几种:
==:相等!=:不相等~:区分字母大小写的模式匹配~*:不区分大小写的模式匹配- 还有其它的专用比较符号,比如判断文件或目录是否存在的符号等。
举个例子:
location /test {
if ($http_user_agent ~* "Firefox"){#注意空格
return 403;
}
if ($http_user_agent ~* "Chrome"){
return 301;
}
return 404;
}
我们用不同的浏览器访问会有不同的返回码显示。
上面我们用到了return 指令。return 指令用于返回 HTTP 的状态码。return 指令会停止同一个作用域的剩余指令处理,并返回给客户端指定的响应码。return 指令可以用于 server、location、if 上下文中,执行阶段是rewrite 阶段。其指令的格式如下:
#格式一:返回响应的状态码和提示文字,提示文字可选
return code [text];
#格式二:返回响应的重定向状态码(如 301)和重定向 URL
return code URL;
#格式三:返回响应的重定向 URL,默认的返回状态码是临时重定向 302
return URL;
1.5.4 add_header指令
response header 一般是以 key:value 的形式,我们用add_header指令就可以增加响应头。格式如下:
add_header key value
#例如
add_header Content-Type text/plain;
我们以非常常用的 response header,Content-Type举例:
add_header Content-Type 'text/html; charset=utf-8'
使用ajax跨域请求时,会发送一条预检请求OPTIONS,用于判断是否安全或服务端是否支持跨域。预检请求一般是由浏览器发出的,用户一般不知情,而对于客户端来说只有预检请求返回成功才会正式请求,这样就会损失一定性能,因此一般会在Nginx代理服务端对预检请求提前进行拦截,并设置较长有效期:
upstream zuul{
server "192.168.22.123:8999";
keepalive 1000;
}
server{
listen 80;
server_name nginx.server *.nginx.server;
default_type 'text/html';
charset utf-8;
#将请求转发到上游服务器,但是OPTIONS请求直接返回
location{
if($request_method = 'OPTIONS'){
add_header Access-Control-Max-Age 1728000;#用来指定本次预检请求的有效期,目前设置为1728000秒
add_header Access-Control-Allow-Origin *;
add_header Access-Control-Allow-Credentials true;
add_header Access-Control-Allow-Methods 'GET,POST,OPTIONS';
add_header Access-Control-Allow-Header 'Keep-Alive,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,token';
return 204;
}
proxy_pass http://zuul/;
}
}
1.5.5 指令的执行顺序
Nginx 的请求处理阶段共有11个,分别是 post-read、server-rewrite、find-config、rewrite、post-rewrite、preaccess、access、post-access、try-files、content 以及 log。其中3 个比较常见的按照执行时的先后顺序依次是 rewrite 阶段、access 阶段以及 content 阶段。
Nginx 的配置指令一般只会注册并运行在其中的某一个处理阶段,比如set指令就是在 rewrite阶段运行的,而echo指令只会在content阶段运行。在一次请求处理流程中,rewrite阶段总是在content 阶段之前执行。因此,属于rewrite阶段的配置指令(示例中的 set)总是会无条件地在content 阶段的配置指令(示例中的 echo)之前执行,即便是 echo 配置项出现在 set 配置项的前面。
举个例子:
location {
set $a 'hello';
echo $a;
set $a 'world';
echo $a;
}
这个指令输出结果如下:
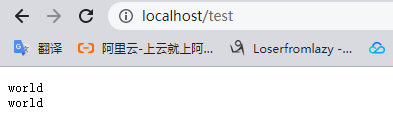
这就是因为set指令就在rewrite阶段运行,而echo在content阶段运行,而rewrite阶段总是在content阶段之前执行,因此结果会变成这样。
1.6 反向代理和负载均衡
单体 Nginx 的性能虽然不错,但也是有瓶颈的。打个比方:用户请求发起一个请求,网站显示的图片量比较大,如果这个时候有大量用户同时访问,全部的工作量都集中到了一台服务器上,服务器不负重压,可能就崩溃了。高并发场景下,自然需要多台服务器进行集群,既能防止单个节点崩溃导致平台无法使用,又能提高一些效率。一般来说,Nginx 完成 10 万多用户同时访问,程序就相对容易崩溃。
下面我们来配置Nginx的反向代理和负载均衡。
1.6.1 demo环境
因为要模拟代理,因此我准备了一台linux的云服务器(如果没有云服务器也可以准备一台虚拟机进行测试),然后在上面安装了nginx/openresty,然后我让这个云服务器上的监听80和8081端口,我们的80端口用作nginx的监听端口,然后8081端口模拟代理服务器,也就是说整体流程是这样的,我在本地向云服务器nginx发送请求,nginx通过反向代理将请求转发到127.0.0.1:8081(也就是说8081模拟被代理的tomcat或其他服务器)。通过这种方式进行模拟反向代理。
云服务器上的nginx配置:
server {
listen 8081;
server_name locahost;
default_type 'text/html';
charset utf-8;
location / {
echo "uri: $uri,host: $host,remote_addr:$remote_addr,proxy_add_x_forwarded_for:$proxy_add_x_forwarded_for,http_x_forwarded_for:$http_x_forwarded_for";
}
}
server {
listen 80;
server_name localhost;
default_type 'text/html';
charset utf-8;
location / {
echo "默认根路径匹配";
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
1.6.2 proxy_pass反向代理指令
proxy_pass 反向代理指令处于 ngx_http_proxy_module 模块,并且注册在 HTTP请求 11 个阶段的 content 阶段。格式如下:
proxy_pass 目标URL前缀;
当proxy_pass后面的目标URL格式为协议+IP[:port]+/的格式(最后有/根路径)时,表示最终的结果路径会把location指令的URI前缀也给加上,这里称为不带前缀代理。
反之如果目标URL格式为协议+IP[:port]的格式(没有/根路径)时,表示最终Nginx不会把location指令的URI前缀也给加上,这里称为带前缀代理。
-
不带location前缀代理
这种是proxy_pass的目标URL前缀加上根路径的形式:
location /test_no_pre { proxy_pass http://127.0.0.1:8081/; }我们将上面的配置加到服务器的nginx的配置文件中,然后刷新配置,然后我们访问服务器上的此地址:

我们可以看到,$uri 变量输出的代理 URI 为
/test.html,并没有在结果 URL 中看到 location 配置指令的前缀/test_no_pre -
带前缀代理
这种是proxy_pass的目标URL前缀不加上根路径的形式:
location /test_pre { proxy_pass http://127.0.0.1:8081; }我们将上面的配置加到服务器的nginx的配置文件中,然后刷新配置,然后我们访问服务器上的此地址:

我们可以看到,$uri 变量输出的代理 URI 为
/test_pre/test.html -
带部分前缀代理
除了上面两种代理,还有一种带部分前缀的代理。如果proxy_pass的路径参数不只有ip和端口,还有部分目标URI的路径,那么最终的代理URI就由两部分组成:一部分是配置项中的目标URI前缀,还有一部分是请求URI中去掉location前缀剩余的部分。举个例子:
location /test_uri_1 { proxy_pass http://127.0.0.1:8081/contextA/; } location /test_uri_2 { proxy_pass http://127.0.0.1:8081/contextB; }我们将上面的配置加到服务器的nginx的配置文件中,然后刷新配置,然后我们访问服务器上的此地址:


可以看到无论我们加不加根路径,nginx都会将端口号后面的路径给加上,只是在代理路径中去掉了 location 指令的匹配前缀。
仅仅使用 proxy_pass 指令进行请求转发,发现很多原始请求信息都丢了。明显的是客户端 IP 地址,前面的例子中请求都是从我们的电脑发出去的,经过代理服务器之后,服务端返回的 remote_addr 客户端 IP 地址并不是我们自己的ip地址,而是变成了代理服务器的 IP 127.0.0.1。
这时我们就需要使用proxy_set_head解决原始信息丢失的问题。
1.6.3 proxy_set_head请求头设置指令
在反向代理之前,proxy_set_head指令能够重新添加/定义字段并传递给代理服务器的请求头,格式如下:
#head_field请求头 field_value值
proxy_pass_header head_field field_value;
举个例子,比如经过反向代理后,对于目标服务器来说,客户端已经变成了nginx,目标服务器无法获取真实IP,比如我们的服务器是Tomcat的那么获取的ip(比如用Java的request.getRemoteAddr())其实拿到的是nginx的IP,所以我们通过这个指令将真实客户端地址保持在请求头中,这样目标服务器通过获取请求头中的内容就可以获取真实客户端ip地址了。
location /test_pre_head/ {
proxy_pass http://127.0.0.1:8081/;
proxy_set_header X-real-ip $remote_addr;
}
在Java中使用request.getHeader("X-real-ip")就能获取到真正的客户端IP。
当然,在整个请求链路上可能不止一次反向代理,因此如果想获取整个转发记录也可以通过设置请求头的方式,如下:
location /test_prefix {
proxy_pass http://127.0.0.1:8081;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
这里使用了系统变量$proxy_add_x_forwarded_for,它的第一个地址就是客户端真实地址,然后每转发一次就在后面累加一次代理地址。
一般为了不丢失信息会将信息都保存在头部:
location /test {
proxy_pass http://127.0.0.1:8081;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;#转发记录
proxy_set_header X-real-ip $remote_addr;#客户端ip
proxy_set_header Host $host;#当前的目标主机
proxy_redirect off;
}
proxy_redirect 指令的作用是修改从上游被代理服务器传来的应答头中的 Location 和 Refresh字段,尤其是当上游服务器返回的响应码是重定向或刷新请求,如HTTP响应码是301或者302时proxy_redirect 可以重设 HTTP 头部的 location 或 refresh 字段值。off 参数表示禁止所有的proxy_redirect 指令
1.6.4 upstream上游服务器组
假设 Nginx 只有反向代理没有负载均衡,它的价值会大打折扣。Nginx 在配置反向代理时可以通过负载均衡机制配置一个上游服务器组(多台上游服务器)。当组内的某台服务器宕机时仍能保持系统可用,从而实现高可用。
Nginx的负载均衡主要使用upstream上游服务器组指令,格式如下:
upstream name {
#......配置块
}
upstream指令的那么是指定上游服务器组的名称,内部使用server指令定义组内的上游候选服务器。这个指令与server有点类似,其功能是加入一个特殊的虚拟主机server几点,特殊之处在于此指令是服务器组,可以包含一个或多个上游server。比如:
upstream testNode {
server "192.168.22.1:8080";#上游候选服务器1
server "192.168.22.2:8080";#上游候选服务器2
server "192.168.22.3:8080";#上游候选服务器3
server "192.168.22.4:8080";#上游候选服务器4
}
当请求过来时,testNode主机节点的作用是按照默认负载均衡算法(带权重的轮询算法)在 4 个上游候选服务中选取一个进行请求转发。
我们下面测试一下负载均衡,首先配置一下upstream,然后配置两个用于负载的两个虚拟主机,然后最后配置代理主机
upstream testNode {
server "127.0.0.1:9090";#上游候选服务器1
server "127.0.0.1:9091";#上游候选服务器2
}
#用于负载的虚拟主机
server {
listen 9090;
server_name locahost;
default_type 'text/html';
charset utf-8;
location / {
echo "9090";
}
}
#用于负载的虚拟主机
server {
listen 9091;
server_name localhost;
default_type 'text/html';
charset utf-8;
location / {
echo '9091';
}
}
server {
listen 80;
server_name localhost;
default_type 'text/html';
charset utf-8;
location / {
echo "默认根路径匹配";
}
location /balance {
proxy_pass http://testNode;
}
}
然后我们访问http://服务器ip地址/balance然后就能观察到在两个虚拟主机之间进行了负载均衡。
1.6.5 upstream的上游服务器配置
upstream 块中将使用 server 指令定义组内的上游候选服务器。内部 server 指令的语法如下:
server address [parameters];
这个内嵌的server指令可以用于定义上游服务器的地址和其它可选参数,它的地址可以指定为域名或者IP地址带端口,如果未指定端口则默认使用80.
其中server指令的可选参数如下:
-
weight=numbwer,设置上游服务器权重,默认情况下upstream使用加权轮询负载均衡,weight默认为1,如果某个上游服务器宕机就自动剔除。配置权重如下:
upstream testNode { server "127.0.0.1:9090" weight=2; server "127.0.0.1:9091" weight=2; }权重越大,将被分发到更多请求。
-
max_conns=number,设置上游服务器最大连接数。默认为0表示没有限制。如果 upstream 服务器组没有通过 zone 指令设置共享内存,那么在单个Worker工作进程范围内对上游服务的最大连接数进行限制;如果upstream服务器组通过zone指令设置了共享内存,那么在全体的 Worker 工作进程范围内对上游服务进行统一的最大连接数限制。
-
backup,此参数用于标识该server是备份的上游节点,当普通的上游服务(非backup)不可用时,请求将被转发到备份的节点上,当普通的上游服务(非backup)可用时,请求将不会被转发到备份的节点上
-
down,此参数用于标识该server节点不可用或者永久下线。
-
max_fils=number,最大错误次数。此参数是用于判断上游服务不可访问的参数之一。该参数表示请求转发最多失败number次就判定该server为不可用。max_fails参数的默认次数为 1,表示转发失败 1 次,该 server 即不可用。如果此参数设置为 0,就会禁用不可用的判断,一直不断地尝试连接后端 server。
-
fail_timeout=time,失败测试的时间长度。一般与上面的max_fils参数一起使用。指的是在fail_timeout时间范围内最多尝试max_fails次,就判定该server为不可用。fail_timeout参数的默认值为10秒。
server 指令在进行 max_conns 连接数配置时,Nginx 内部会涉及共享内存区域的使用,配置共享内存区域的指令为 zone,其具体语法如下:
zone name [size];如果配置了 upstream 的共享内存区域,那么其运行时状态(包括最大连接数)在所有的Worker工作进程之间是共享的。在name相同的情况下,不同的 upstream 组将共享同一个区,这种情况下,size 参数的大小值只需设置一次。
举个例子:
upstream gateway { zone upstream_gateway 64k;#名称为upstream_gateway,大小为64K的共享内存区域 server "127.0.0.1:9090" weight=3 max_conns=500; server "127.0.0.1:9091" fail_timeout=20s max_fails=2; server "127.0.0.1:9092" backup; }
1.6.6 upstream的负载分配方式
upstream 大致有 3 种负载分配方式:
-
加权轮询
默认情况下使用加权轮询,默认权重为1,并且各个上游服务器weight相同,表示每个请求按照到达顺序逐一分配到不同的服务器上。例子略,上面已经演示过了。
-
hash指令
基于hash函数值进行负载均衡,hash函数的key可以包含文本、变量或两者组合。hash函数负载均衡是一个独立的指令,格式如下:
hash key [consistent];如果 upstream 组中摘除掉一个 server,就会导致 hash 值重新计算,即原来的大多数key 可能会寻址到不同的 server 上。若配置有 consistent 参数,则 hash 一致性将选择 Ketama 算法。这个算法的优势是,如果有 server 从 upstream 组里摘除掉,那么只有少数的 key 会重新映射到其他的 server 上,即大多数 key 不受 server 摘除的影响,还走到原来的 server。这对提高缓存server 命中率有很大帮助。
举个例子:
upstream testHash { hash $euquest_uri consistent; server "192.168.0.1:9090"; server "192.168.0.2:9091"; server "192.168.0.3:9092"; } -
ip_hash指令
基于客户端的ip的hash值进行负载均衡,这样每个客户端固定访问一个后端服务器,可以解决类似session不能跨服务器的问题,如果上游服务不可用,那么就需要手动删除或配置down参数。例子:
upstream testHash { ip_hash; server "192.168.0.1:9090"; server "192.168.0.2:9091"; server "192.168.0.3:9092"; }
二、Nginx的lua编程
Nginx 毫无疑问是高性能 Web 服务器很好的选择。除此之外,Nginx 还具备可编程能力,理论上可以使用 Nginx 的扩展组件 ngx_lua 开发各种复杂的动态应用。不过,由于Lua 是一种脚本动态语言,因此不太适合做复杂业务逻辑的程序开发。但是,在高并发场景下,Nginx Lua 编程是解决性能问题的利器。
2.1 应用场景
-
API网关:实现数据校验前置、请求过滤、API请求聚合、AB测试、灰度发布、降级、监控等功能。开源网关Kong就是基于Nginx Lua开发的
-
高速缓存:可以对响应内容进行缓存,减少到后端的请求提升性能。比如Nginx Lua可以和Java容器(Tomcat)或Redis整合,由Java容器进行业务处理和数据缓存,而Nginx负责都缓存并进行响应,从而解决Java容器的性能瓶颈。
-
简单的动态Web应用
可以完成一些业务逻辑处理少但是耗费CPU的简单应用,比如模板页面的渲染。一般Nginx Lua页面渲染处理流程为:从Redis获取业务处理结果数据,从本地加载XML/HTML页面模板,然后进行页面渲染。
-
网关限流:缓存、降级、限流是解决高并发的三大利器,Nginx内置了令牌限流的的算法,但是对于分布式的限流场景,可以通过Nginx Lua编程定制自己的限流机制。
2.2 入门
我们这里使用的是windows上的openresty/1.21.4.1,而且需要将其配置到环境变量中,方法如下:
新建变量,然后选择openresty的根目录

然后配置到path中即可:
2.2.1 ngx_lua
lua是一种轻量级、可嵌入式的脚本语言,因为其小巧轻量,所以可以在Nginx中嵌入Lua VM,请求时创建一个VM,请求结束时回收VM。
ngx_lua是Nginx的一个拓展模块,将Lua VM嵌入Nginx中,从而可以在内部运行Lua脚本,使Nginx变成一个web容器。ngx_lua提供了与Nginx交互的很多API,对于开发人员来说只要学习API就能开发,对于开发Web应用来说,如果接触过Servlet,可以发现ngx_lua与Servlet类似,无外乎是接收请求、参数解析、功能处理、返回响应。
使用 ngx_lua 开发 Web 应用时,有很多源码的Lua基础性模块可供使用,比如 OpenResty 就提供了一些常用的 ngx_lua 开发模块:
- lua-resty-memcached:通过Lua操作Memcached缓存
- lua-resty-mysql:通过Lua操作MySQL数据库
- lua-resty-redis:通过Lua操作Redis缓存
- lua-resty-dns:通过Lua操作DNS域名服务器
- lua-resty-limit-traffic:通过Lua进行限流
- lua-resty-template:通过Lua进行模板渲染
除了上述常用组件外,还有很多第三方的ngx_lua组件(lua-resty-jwt、lua-resty-kafka),对于大部分应用场景来说,现在ngx_lua生态环境组件已经足够,如果不能满足需求,也可以开发自己的Lua模块。
2.2.2 创建和启动Nginx Lua项目
通过IDEA->New Project新建一个Lua项目:
当然创建前需要先安装Lua的插件,如果你的IDEA里没有Lua的插件,那么就没有这个Lua项目的选项,插件安装下面这个即可。

新建完的工程只有一个src目录,因此需要我们自己创建文件夹,我们可以创建nginx的配置文件和存放lua脚本的文件夹,具体怎么存放文件夹都可以自己定,下图是我的目录:
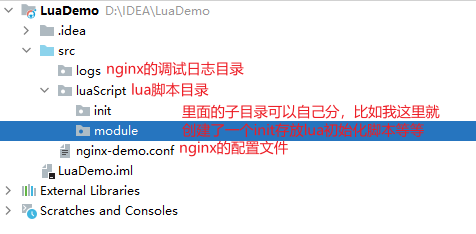
但是nginx的配置文件一定要放在src目录下,与存放lua脚本的文件夹平级,因为在 nginx-debug.conf 中会应用到 Lua 脚本,使用的是相对路径,如果目录的相对位置不对,就会找不到 Lua 脚本。
以下是nginx-debug.conf的内容:
worker_processes 1;
#开发环境
error_log logs/error.log debug;
#生产环境
#error_log logs/error.log;
#pid logs/nginx.pid;
events {
worker_connections 1024;
}
http {
default_type 'text/html';
charset utf-8;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log logs/access_main.log main;
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
#gzip on;
#指定缓存信息
lua_shared_dict ngx_cache 128m;
#保证只有一个线程去访问redis或是mysql-lock for cache
lua_shared_dict cache_lock 100k;
#lua扩展加载
# for linux
#lua_package_path "./?.lua;/vagrant/LuaDemoProject/src/?/?.lua;/vagrant/LuaDemoProject/src/?.lua;/usr/local/openresty/lualib/?/?.lua;/usr/local/openresty/lualib/?.lua;;";
#lua_package_cpath "/usr/local/openresty/lualib/?/?.so;/usr/local/openresty/lualib/?.so;;";
# for windows
lua_package_path "./?.lua;C:/dev/refer/LuaDemoProject/src/?.lua;D:/openresty/openresty-1.21.4.1-win64/lualib/?.lua;;";
lua_package_cpath "D:/openresty/openresty-1.21.4.1-win64/lualib/?.dll;;";
# 初始化项目
init_by_lua_file luaScript/init/loading_config.lua;
#调试模式(即关闭lua脚本缓存)
lua_code_cache off;
server {
listen 80 default;
server_name localhost;
default_type 'text/html';
charset utf-8;
location / {
echo "默认根路径匹配: /";
}
#测试lua是否可以执行
location /lua {
content_by_lua 'ngx.say("Hello, Lua!")';
}
}
}
上面配置文件中用到的lua脚本如下:
-- 加载cjson
cjson = require("cjson");
-- 加载string
string = require("string");
--table = require("table");
--[[
项目内公共包配置
]]
-- 加载resty.core
require("resty.core");
创建完项目后,我们就可以启动项目,启动项目是通过启动Nginx来执行Lua项目(这里能直接用nginx命令是因为配置了环境变量),启动等相关命令如下:
启动Lua项目:
D:\IDEA\LuaDemo\src>nginx -p ./ -c nginx-demo.conf
重启
D:\IDEA\LuaDemo\src>nginx -p ./ -c nginx-demo.conf -s reload
停止
D:\IDEA\LuaDemo\src>nginx -p ./ -c nginx-demo.conf -s stop
2.3 Lua基础和入门
Lua 是一种轻量小巧的脚本语言,用标准C语言编写并以源代码形式开放, 其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。
Lua脚本需要通过Lua解释器来解释执行,除了Lua官方的默认解释器外,目前使用广泛的Lua解释器叫作LuaJIT。LuaJIT 是采用 C 语言编写的Lua脚本解释器。LuaJIT被设计成全兼容标准Lua 5.1,因此LuaJIT 代码的语法和标准 Lua 的语法没多大区别。LuaJIT 和 Lua 的一个区别是,LuaJIT 的运行速度比标准 Lua 快数十倍,可以说是一个 Lua 的高效率版本。
2.3.1 Lua中模块
与Java类似,实际开发的 Lua 代码需要进行分模块开发。Lua 中的一个模块对应一个 Lua 脚本文件。使用 require 指令导入 Lua 模块,第一次导入模块后,所有 Nginx 进程全局共享模块的数据和代码,每个 Worker 进程需要时会得到此模块的一个副本,不需要重复导入,从而提高 Lua 应用的性能。
下面给出一个例子:
--定义一个应用程序公有的Lua对象
local app_info = {version = "1.0"}
--增加一个path属性,保存Nginx进程所保存的Lua模块路径,包括conf配置文件的部分路径
app_info.path = package.path;
--局部函数,取得最大值
local function max(num1,num2)
if num1>num2 then
result = num1;
else
result = num2
end
return result;
end
--统一的模块对象
local _Module = {
app_info = app_info;
max = max;
}
return _Module
模块内的所有对象、数据、函数都定义成局部变量或者局部函数。然后,对于需要暴露给外部的对象或者函数,作为成员属性保存到一个统一的 Lua 局部对象(如_Module)中,通过返回这个统一的局部对象将内部的成员对象或者方法暴露出去,从而实现 Lua 的模块化封装。
接下来我们使用上面的封装好的lua模块:
我们在ngixn的配置文件中添加:
#第一个lua脚本 hellword
location /helloworld {
default_type 'text/html';
charset utf-8;
content_by_lua_file luaScript/module/helloworld.lua;
}
然后编写helloworld.lua脚本
--导入自定义模块
local basic = require("luaScript.module.base");
ngx.say("hello world." );
ngx.say("<hr>" );
--使用模块的成员属性
ngx.say("Lua path is: " .. basic.app_info.path);
ngx.say("<hr>" );
--使用模块的成员方法
ngx.say("max 1 and 11 is: ".. basic.max(1,11) );
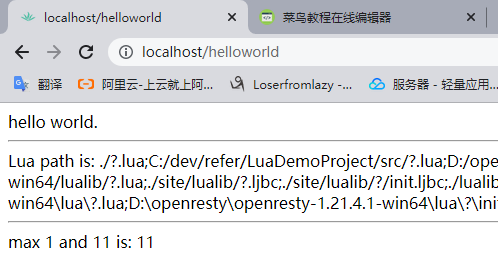
然后使用nginx -p ./ -c nginx-demo.conf -s reload命令,重载ngixn,然后我们访问localhost/helloworld就可以看到对应的内容了,如下图:
lua中导入模块时使用require(目录1.目录2.模块名)源目录之间的/斜杠分隔符改成.点号分隔符。这一点和 Java的包名的分隔符类似。
Lua 文件查找时,首先会在 Nginx 的当前工作目录查找,如果没有找到,就会在 Nginx 的 Lua包路径 lua_package_path 和 lua_package_cpath 声明的位置查找。整个 Lua 文件的查找过程和 Java的.class 文件查找的过程很类似。需要注意的是,Lua 包路径需要在 nginx.conf 配置文件中进行配置,如下面代码(完整配置文件上面已给出):
# for windows
http{
#...略
lua_package_path "./?.lua;C:/dev/refer/LuaDemoProject/src/?.lua;D:/openresty/openresty-1.21.4.1-win64/lualib/?.lua;;";
lua_package_cpath "D:/openresty/openresty-1.21.4.1-win64/lualib/?.dll;;";
#...略
}
这里有两个包路径配置项:lua_package_path用于配置 Lua 文件的包路径;lua_package_cpath用于配置C语言模块文件的包路径。在Linux 系统上,C语言模块文件的类型是.so在 Windows平台上,C语言模块文件的类型是.dll。Lua 包路径如果需要配置多个路径,那么路径之间使用分号;分隔。末尾的两个分号;;表示加上 Nginx 默认的 Lua 包搜索路径,其中包含Nginx的安装目录下的lua目录。
在OpenResty的lualib下已经提供了大量的第三方开发库,如CJSON、Redis客户端、Mysql客户端等,并且这些模块已经包含到默认的搜索路径中。在在OpenResty的lualib下的模块可以直接在lua文件中通过require导入,比如:
local redis = require("resty.redis")
2.3.2 Lua数据类型
lua 是动态类型语言,和 JavaScript 等脚本语言类似,变量没有固定的数据类型,每个变量可以包含任意类型的值。且变量不要类型定义,只需要为变量赋值。值可以存储在变量中,作为参数传递或结果返回。
Lua 中有 8 个基本类型分别为:nil、boolean、number、string、userdata、function、thread 和 table。使用内置的 type(…)方法可以获取该变量的数据类型。
| 数据类型 | 描述 |
|---|---|
| nil | 这个最简单,只有值nil属于该类,表示一个无效值(在条件表达式中相当于false)。 |
| boolean | 包含两个值:false和true。 |
| number | 表示双精度类型的实浮点数 |
| string | 字符串由一对双引号或单引号来表示 |
| function | 由 C 或 Lua 编写的函数 |
| userdata | 表示任意存储在变量中的C数据结构 |
| thread | 表示执行的独立线路,用于执行协同程序 |
| table | Lua 中的表(table)其实是一个"关联数组"(associative arrays),数组的索引可以是数字、字符串或表类型。在 Lua 里,table 的创建是通过"构造表达式"来完成,最简单构造表达式是{},用来创建一个空表。 |
下面给出例子,首先编写方法:
local function showDataType()
local i;
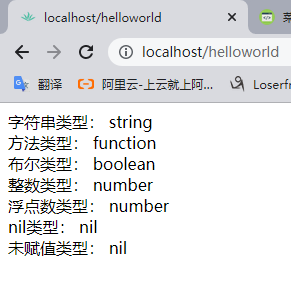
ngx.say("字符串类型:");ngx.say(type("hello,world"));ngx.say("<br>");
ngx.say("方法类型:");ngx.say(type(showDataType));ngx.say("<br>");
ngx.say("布尔类型:");ngx.say(type(true));ngx.say("<br>");
ngx.say("整数类型:");ngx.say(type(11));ngx.say("<br>");
ngx.say("浮点数类型:");ngx.say(type(11.1));ngx.say("<br>");
ngx.say("nil类型:");ngx.say(type(nil));ngx.say("<br>");
ngx.say("未赋值类型:");ngx.say(type(i));ngx.say("<br>");
end
然后在helloworld模块调用此方法:
local basic = require("luaScript.module.base");
ngx.say(basic.showDataType())
lua的数据结构有以下需要注意的几点:
-
nil 是一种类型,在 Lua 中表示“无效值”。nil 也是一个值,表示变量是否被赋值,如果变量没有被赋值,那么值为 nil,类型也为 nil。 与 Nginx 略微有一点不同,OpenResty 还提供了一种特殊的空值,即 ngx.null,用来表示空值,但是不同于 nil。
-
boolean(布尔类型)的可选值为 true 和 false。在 Lua 中,只有 nil 与 false 为“假”,其他所有值均为“真”,比如数字 0 和空字符串都是“真”。这一点和 Java 语言的 boolean 类型还是有一点区别的。
-
number 类型用于表示实数,与 Java 中的 double 类型类似。但是又有区别,Lua 的整数类型也是 number。一般来说,Lua 中的 number 类型是用双精度浮点数来实现的。可以使用数学函数math.lua来操作 number 类型的变量。在 math.lua 模块中定义了大量数字操作方法,比如定义了 floor(向下取整)和 ceil(向上取整)等操作。
-
table 类型实现了一种抽象的“关联数组”,相当于 Java 中的 Map。“关联数组”是一种具有特殊索引方式的数组,索引(也就是 Map 中的 key)通常是 number 类型或者 string 类型,也可以是除 nil 以外的任意类型的值。默认情况下,table 中的 key 是 number 类型的,并且 key 的值为递增的数字。
-
运行时,Lua会自动在string和numbers之间自动进行类型转换,当一个字符串使用算术操作符时, string 就会被转成数字。
print("10"+ 1) --> 11 print("10 + 1") --> 10 + 1 print("hello"+ 1) -- 报错 (无法转换 "hello")反过来,当 Lua 期望一个 string 而碰到数字时,会将数字转成 string。
print(10 .. 20) --> 1020..在Lua中是字符串连接符,当在一个数字后面写..时,必须加上空格以防止被解释错。 -
和 JavaScript 脚本语言类似,在 Lua 中的函数也是一种数据类型,类型为 function。函数可以存储在变量中,可以作为参数传递给其他函数,还可以作为其他函数的返回值。定义一个有名字的函数本质上是定义一个函数对象,然后赋值给变量名称(函数名)
2.3.3 Lua字符串
lua中有三种方式表示字符串:
- 使用一对半角英文单引号例如:'hello'
- 使用一对半角英文双引号例如:"hello"
- 使用双方括号的方式定义,例如[["add\name","hello"]],双方括号中的任何转义字符不会被处理
Lua的字符串的值是不可改变的,类似Java,如果需要改变就要根据要求创建一个新的字符串并返回。且Lua不支持下标访问字符串的某个字符。
Lua中的主要字符串操作如下:
-
..字符串拼接local function stringOperator() local str = "hello" .. "world" .. "!"; print(str); ngx.say(str); end -
string.len(s)获取字符串长度local function stringLen() local str = "hello" .. "world" .. "!"; ngx.say(string.len(str)); ngx.say("<br>"); ngx.say(#str); end此功能与
#运算符类似,这个运算符也是取字符串长度,开发建议使用#来获取Lua字符串长度 -
string.format(formatString,...)格式化字符串第一个参数表示需要进行格式化的字符串规则,例如:
--简单的圆周率格式化规则 string.format(" 保留两位小数的圆周率 %.4f", 3.1415926); --格式化日期 string.format("%s %02d-%02d-%02d", "今天 is:", 2020, 1, 1));格式指令由%加上一个类型字母组成,比如%s(字符串格式化)、%d(整数格式化)、%f(浮点数格式化)等,在%和类型符号的中间可以选择性地加上一些格式控制数据,比如%02d,表示进行两位的整数格式输出。总体来说,formatString 参数中的格式化指令规则与标准 C 语言中 printf 函数的格式化规则基本相同。
-
string.find(str,substr[,init[,plain]])字符串匹配在一个指定的目标字符串 str 中搜索指定的内容 substr,如果找到了一个匹配的子串,就会返回这个子串的起始索引和结束索引,不存在则返回 nil。init 指定了搜索的起始位置,默认为 1,可以一个负数,表示从后往前数的字符个数。plain 表示是否以正则表达式匹配。以下实例查找字符串 "Lua" 的起始索引和结束索引位置:
> string.find("Hello Lua user", "Lua", 1) 7 9 -
string.upper(s)字符串转大写接收一个字符串s,返回一个把所有小写字母变成大写字母的字符串。与 string.upper(s)方法类似,string.lower(s)方法的作用是接收一个字符串s,返回一个全部字母变成小写的字符串。
2.3.4 Lua变量
变量在使用前,需要在代码中进行声明,即创建该变量。编译程序执行代码之前编译器需要知道如何给语句变量开辟存储区,用于存储变量的值。
Lua 变量有三种类型:全局变量、局部变量、表中的域。Lua 中的变量全是全局变量,哪怕是语句块或是函数里,除非用 local 显式声明为局部变量。局部变量的作用域为从声明位置开始到所在语句块结束。变量的默认值均为 nil。例子(来源于菜鸟教程):
-- test.lua 文件脚本
a = 5 -- 全局变量
local b = 5 -- 局部变量
function joke()
c = 5 -- 全局变量
local d = 6 -- 局部变量
end
joke()
print(c,d) --> 5 nil
do
local a = 6 -- 局部变量
b = 6 -- 对局部变量重新赋值
print(a,b); --> 6 6
end
print(a,b) --> 5 6
2.3.4 Lua数组
Lua数组内部采用哈希表保存键值对,类似Java中的HashMap,不同的是Lua在初始化普通数组时如果不显示指定元素的key,默认用数字索引作为key。
定义一个数组使用花括号即可,中间加上初始化的元素序列,元素之间逗号隔开:
--普通数组
local array = {"111","hello","world"}
--键值对数组
local array1 = {k1="111",k2="hello",k3="world"}
取得数组元素值使用[]形式为array[key],对于键值对形式的数组key就是键。这里要注意的是,普通数组的数字下标从1开始,且普通数组的长度是从第一个元素开始计算到最后一个非nil为止。举例:
--遍历上面的数组
for i =1 , 3 do
ngx.say(i .. "=" .. array[i] .. " ");
end
for k,v in pairs(array1) do
ngx.say(k .. "=" .. array[k] .. " ");
end
Lua 定义了一个负责数组和容器操作的 table 模块,主要的操作如下:
| 序号 | 方法 & 用途 |
|---|---|
| 1 | table.concat (table [, sep [, start [, end]]]):concat是concatenate(连锁, 连接)的缩写. table.concat()函数列出参数中指定table的数组部分从start位置到end位置的所有元素, 元素间以指定的分隔符(sep)隔开。 |
| 2 | table.insert (table, [pos,] value):在table的数组部分指定位置(pos)插入值为value的一个元素. pos参数可选, 默认为数组部分末尾. |
| 3 | table.maxn (table)指定table中所有正数key值中最大的key值. 如果不存在key值为正数的元素, 则返回0。(Lua5.2之后该方法已经不存在了,本文使用了自定义函数实现) |
| 4 | table.remove (table [, pos])返回table数组部分位于pos位置的元素. 其后的元素会被前移. pos参数可选, 默认为table长度, 即从最后一个元素删起。 |
| 5 | table.sort (table [, comp])对给定的table进行升序排序。 |
| 6 | table.getn (t)获取长度 |
2.3.5 Lua流程控制
-
if
以关键词 if 开头,以关键词 end 结束。这一点和 Java 不同,Java 中使用右花括号作为分支结构体的结束符号。例子(来源于菜鸟教程)
--[ 定义变量 --] a = 10; --[ 使用 if 语句 --] if( a < 20 ) then --[ if 条件为 true 时打印以下信息 --] print("a 小于 20" ); end print("a 的值为:", a); -
if-else
例子(来源于菜鸟教程)
--[ 定义变量 --] a = 100; --[ 检查条件 --] if( a < 20 ) then --[ if 条件为 true 时执行该语句块 --] print("a 小于 20" ) else --[ if 条件为 false 时执行该语句块 --] print("a 大于 20" ) end print("a 的值为 :", a) -
if-elseif-else
例子(来源于菜鸟教程)
--[ 定义变量 --] a = 100 --[ 检查布尔条件 --] if( a == 10 ) then --[ 如果条件为 true 打印以下信息 --] print("a 的值为 10" ) elseif( a == 20 ) then --[ if else if 条件为 true 时打印以下信息 --] print("a 的值为 20" ) elseif( a == 30 ) then --[ if else if condition 条件为 true 时打印以下信息 --] print("a 的值为 30" ) else --[ 以上条件语句没有一个为 true 时打印以下信息 --] print("没有匹配 a 的值" ) end print("a 的真实值为: ", a ) -
for循环
Lua 编程语言中数值 for 循环语法格式:
for var=exp1,exp2,exp3 do <执行体> endvar 从 exp1 变化到 exp2,每次变化以 exp3 为步长递增 var,并执行一次 "执行体"。exp3 是可选的,如果不指定,默认为1。
例子(来源于菜鸟教程)
for i=1,f(x) do print(i) end for i=10,1,-1 do print(i) end -
foreach
泛型 for 循环通过一个迭代器函数来遍历所有值,类似 java 中的 foreach 语句。
Lua 编程语言中泛型 for 循环语法格式:
--打印数组a的所有值 a = {"one", "two", "three"} for i, v in ipairs(a) do print(i, v) endi是数组索引值,v是对应索引的数组元素值。ipairs是Lua提供的一个迭代器函数,用来迭代数组。
例子(来源于菜鸟教程)
days = {"Sunday","Monday","Tuesday","Wednesday","Thursday","Friday","Saturday"} for i,v in ipairs(days) do print(v) end
2.3.6 Lua函数
Lua 编程语言函数定义格式如下:
optional_function_scope function function_name( argument1, argument2, argument3..., argumentn)
function_body
return result_params_comma_separated
end
解析:
- optional_function_scope: 该参数是可选的制定函数是全局函数还是局部函数,未设置该参数默认为全局函数,如果你需要设置函数为局部函数需要使用关键字 local。
- function_name: 指定函数名称。
- argument1, argument2, argument3..., argumentn: 函数参数,多个参数以逗号隔开,函数也可以不带参数。
- function_body: 函数体,函数中需要执行的代码语句块。
- result_params_comma_separated: 函数返回值,Lua语言函数可以返回多个值,每个值以逗号隔开。
例子(来自菜鸟教程)
--[[ 函数返回两个值的最大值 --]]
function max(num1, num2)
if (num1 > num2) then
result = num1;
else
result = num2;
end
return result;
end
-- 调用函数
print("两值比较最大值为 ",max(10,4))
print("两值比较最大值为 ",max(5,6))
--在lua中也是可以将函数作为参数传递的
myprint = function(param)
print("这是打印函数 - ##",param,"##")
end
function add(num1,num2,functionPrint)
result = num1 + num2
-- 调用传递的函数参数
functionPrint(result)
end
myprint(10)
-- myprint 函数作为参数传递
add(2,5,myprint)
当然,Lua函数可以返回多个结果值,比如string.find,其返回匹配串"开始和结束的下标"(如果不存在匹配串返回nil)。
> s, e = string.find("www.runoob.com", "runoob")
> print(s, e)
5 10
除此之外,lua函数还可以使用可变参数:
lua 函数可以接受可变数目的参数,和 C 语言类似,在函数参数列表中使用三点 ... 表示函数有可变的参数。例子(来源于菜鸟教程):
function average(...)
result = 0
local arg={...} --> arg 为一个表,局部变量
for i,v in ipairs(arg) do
result = result + v
end
print("总共传入 " .. #arg .. " 个数")
return result/#arg
end
print("平均值为",average(10,5,3,4,5,6))
--当然我们也可以通过select()来选择可变参
function average(...)
result = 0
local arg={...}
for i,v in ipairs(arg) do
result = result + v
end
print("总共传入 " .. select("#",...) .. " 个数")
return result/select("#",...)
end
- select('#', …) 返回可变参数的长度。
- select(n, …) 用于返回从起点 n 开始到结束位置的所有参数列表。
2.4 Nginx Lua基础
2.4.1 Nginx Lua的执行原理
在OpenResty中,每个Worker进程都使用一个Lua VM(Lua虚拟机),当请求被分配到Worker时,将在这个VM中创建一个协程,协程之间数据隔离,每个协程都具有独立的全局变量。
ngx_lua时将lua嵌入nginx,让nginx执行lua脚本,并且高并发、非阻塞地处理各种请求。Lua内置协程可以很好的将异步回调转换成顺序调用的形式。开发者可以采用串行的方式编程,ngx_lua会在执行阻塞IO时自动终端,保存上下文,然后将IO操作委托给nginx事件处理机制,在IO操作完成后,ngx_lua会恢复上下文,程序继续执行,这些操作对用户程序都是透明的。
每个Nginx的Worker进程都持有一个Lua解释器或LuaJIT实例,被这个Worker处理的所有请求共享这个实例。每个请求的context上下文会被Lua轻量级的协程分隔,从而保证各个请求是独立的。ngx_lua采用one-coroutine-per-request的处理模型,对于每个请求都有一个协程用于执行用户代码处理请求,当处理完成后这个协程会销毁。每个协程都有自己一个独立的全局环境,继承于全局共享的、只读的公共数据。所以,被用户代码注入全局空间的任何变量都不会影响其他请求的处理,并且这些变量在请求处理完成后会被释放,这样就保证所有的用户代码都运行在一个 sandbox(沙箱)中,这个沙箱与请求具有相同的生命周期。得益于 Lua 协程的支持,ngx_lua 在处理 10 000 个并发请求时只需要很少的内存。根据测试,ngx_lua处理每个请求只需要 2KB 的内存,如果使用 LuaJIT 就会更少。所以 ngx_lua 非常适合用于实现可扩展的、高并发的服务。
2.4.2 Nginx Lua的配置指令
ngx_lua 定义了一系列 Nginx 配置指令,用于配置何时运行用户 Lua 脚本以及如何返回 Lua脚本的执行结果。
| ngx_lua配置指令 | 指令说明 |
|---|---|
| lua_package_path | 用于Lua外部库的搜索路径,搜索的文件类型为.lua文件 |
| lua_package_cpath | 用于Lua外部库的搜索路径,搜索C语言编写的外部库文件。在Linux中搜索.so类型的文件;在Windows下为.dll文件。 |
| init_by_lua | Master进程启动时挂载的Lua代码块,常用于导入公共模块 |
| init_by_lua_file | Master进程启动时挂载的Lua脚本文件 |
| init_worker_by_lua | Master进程启动时挂载的Lua代码块,常用于执行一些定时任务 |
| init_worker_by_lua_file | Master进程启动时挂载的Lua脚本文件,常用于执行一些定时任务 |
| set_by_lua | 类似于rewrite模块中的set指令,将Lua代码块的返回结果设置在Nginx的变量中 |
| set_by_lua_file | 类似于rewrite模块中的set指令,将Lua脚本文件的返回结果设置在Nginx的变量中 |
| content_by_lua | 执行在content阶段的Lua代码块,执行结果作为请求响应的内容。Lua代码块是编写在Nginx字符串中的Lua脚本,可能需要进行特殊字符转义 |
| content_by_lua_file | 执行在content阶段的Lua脚本文件,执行结果作为请求响应的内容 |
| content_by_lua_block | 与content_by_lua指令类似,不同之处在于该指令在一对花括号中编写({})lua脚本源码,而不是在nginx字符串中 |
| rewrite_by_lua | 执行在rewrite阶段的Lua代码块,完成转发、重定向、缓存等功能。 |
| rewrite_by_lua_file | 执行在rewrite阶段的Lua脚本文件,完成转发、重定向、缓存等功能。 |
| access_by_lua | 执行在access阶段的Lua代码块,完成ip准入、接口权限等功能。 |
| access_by_lua_file | 执行在access阶段的Lua脚本文件,完成ip准入、接口权限等功能。 |
| header_filter_by_lua | 响应头部过滤处理的lua代码块,比如可以用于添加响应头的信息 |
| body_filter_by_lua | 响应体过滤处理的lua代码块,比如可以用于加密响应体 |
| log_by_lua | 异步完成日志记录的lua代码块,比如可以即在本地记录日志,又记录到ELT集 |
-
lua_package_path
用于设置
.lua外部库的搜索路径,此指令的上下文为http配置块,它的默认值为LUA_PATH环境变量内容或者lua编译的默认值。#设置lua扩展库的搜索路径(;;是默认路径) lua_package_path "./?.lua;C:/dev/refer/LuaDemoProject/src/?.lua;D:/openresty/openresty-1.21.4.1-win64/lualib/?.lua;;";OpenResty可以在搜索路径中使用插值变量,例如可以使用$prefix或${prefix}获取虚拟服务器server的前缀路径,server前缀路径通常在Nginx服务器启动时通过-p PATH命令行选项来指定。
-
lua_package_cpath
用于设置Lua的C语言模块外部库".so"(Linux)或".dll"(Windows)的搜索路径,此指令上下文为http配置块
lua_package_cpath "D:/openresty/openresty-1.21.4.1-win64/lualib/?.dll;;";OpenResty可以在搜索路径中使用插值变量,例如可以使用$prefix或${prefix}获取虚拟服务器server的前缀路径,server前缀路径通常在Nginx服务器启动时通过-p PATH命令行选项来指定。
-
init_by_lua
init_by_lua_file luaScript/init/loading_config.lua;此指令只能用于http上下文,运行在配置加载阶段。当Nginx的master进程在加载Nginx配置文件时,在全局LuaVM级别上运行参数指定的脚本块。当Nginx接收到HUP信号并重新加载配置文件时,LuaVM将会被重新创建,此指令将在新的Lua VM中再次运行。
如果Lua脚本的缓存是关闭的,那么没请求一次都运行一次init_by_lua程序。通过lua_code_cache指令可以关闭Lua脚本缓存,缓存请求默认是开启的。
在生产场景下都会开启 Lua 脚本缓存,在 init_by_lua 调用 require 所加载的模块文件会缓存在全局的 Lua 注册表 package.loaded 中,所以在这里定义的全局变量和函数可能会污染命名空间,当然也会影响性能
-
lua_code_cache
lua_code_cache on | off
此指令用于启动或禁用Lua脚本缓存,可以使用的上下文有http、server、location配置块。当缓存关闭时,通过ngx_lua提供的每一个请求都将在一个单独的LuaVM中运行。在缓存关闭的情况下,在set_by_lua_file、content_by_lua_file、access_by_lua_file等指令中引用的lua脚本都不会缓存,所有的Lua脚本都会重新加载。
如果设置lua_code_cache off(关闭),则每个ngx_lua处理的请求将运行在一个独立的Lua VM实例里,0.9.3版本后有效。这样set_by_lua_file, content_by_lua_file, access_by_lua_file, 等等指令引用的Lua文件将不再缓存到内存, 并且所有Lua模块每次都会从头重新加载。这样开发者就可以避免改代码然后重启nginx的操作。但是, 那些直接写在 nginx.conf 里的代码比如由 set_by_lua, content_by_lua, access_by_lua, and rewrite_by_lua 指定的代码不会在你编辑他们时实时更新。因此在开发过程中可以关闭缓存。
强烈禁止在生产环境中关闭 Lua 脚本缓存,仅仅可以在开发期间关闭 Lua 脚本缓存,在禁用 Lua 脚本缓存后,一个简单的"hello world" Lua 示例的性能可能会下降一个数量级。。
-
set_by_lua
set_by_lua $destVar lua-script-str params功能类似于nginx中的set指令,将Lua脚本的返回结果设置在nginx的变量中。set_by_lua的上下文和执行阶段与nginx的set指令类似。例子:
location /test_set_lua { set $var1 1; set $var2 2; set_by_lua $sum 'return tonumber(ngx.arg[1]) + tonumber(ngx.arg[2])' $var1 $var2; echo $sum; }例子中将lua脚本的结果设置到$sum变量中。使用 set_by_lua 配置指令时,可以在 Lua 脚本的后面带上一个调用参数列表。在 Lua 脚本中可以通过 Nginx Lua 模块内部内置的 ngx.arg 表容器读取实际参数。
-
access_by_lua
access_by_lua $destVar lua-script-str
此指令执行在access阶段,使用Lua脚本进行访问控制,access_by_lua指令运行于access阶段的末尾,虽然同属access阶段 但总是在allow和deny指令后运行。一般可以通过此指令进行复杂的验证操作。比如实时查询数据库或者其他后端服务。举个例子:
location /test_access { access_by_lua ' ngx.log(ngx.DEBUG,"remote_addr=" .. ngx.var.remote_addr); if ngx.var.remote_addr == "127.0.0.1" then return; end ngx.exit(ngx.HTTP_UNAUTHORIZED); '; echo "helloworld"; }上面代码中如果请求来源不是127.0.0.1,那么就会返回401,如果没有将请求流程中断,那么access阶段后面的content阶段就会执行输出helloworld
-
content_by_lua
content_by_lua lua-script-str
用于设置content阶段的Lua代码,执行结果将作为请求的响应内容,此指令用于location上下文,执行在content阶段,
在 Nginx 配置文件中编写字符串形式的 Lua 脚本,可能需要进行特殊字符转义,所以在 OpenResty v0.9.17 发行版之后的版本不鼓励使用此指令,改为使用 content_by_lua_block 指令代替。content_by_lua_block 指令 Lua 代码块使用花括号“{ }”定义,不再使用字符串分隔符。
2.4.3 Nginx Lua的内置常量和变量
Nginx Lua的常用内置变量:
| 内置变量 | 说明 |
|---|---|
| ngx.arg | 类型为Lua table,此变量用于获取ngx_lua配置指令后面的调用参数值,例如获取在set_by_lua指令后面的调用参数值。 |
| ngx.var | 类型为Lua table,此变量引用某个Nginx变量,如果需要对Nginx变量进行赋值,如ngx.var.b=2,那么b应该提前声明。另外也可以使用ngx.vat[捕获组序号]的格式引用location配置块中被正则表达式捕获的捕获组。 |
| ngx.ctx | 类型为Lua table,可以用来访问当前请求的Lua上下文数据,其生存周期与当前请求相同(类似Nginx变量) |
| ngx.header | 类型为Lua table,用于访问HTTP响应头,可以通过ngx.header.HEADER的形式引用某个请求头,如通过ngx.header.set_cookie访问响应头部的Cookie信息 |
| ngx.status | 用于设置当前请求的HTTP响应码 |
Nginx Lua的常用内置常量:
| 内置常量类型 | 说明 |
|---|---|
| 核心常量 | ngx.OK(0) ngx.ERROE(-1) ngx.AGAIN(-2) ngx.DONE(-4) ngx.DECLINED(-5) ngx.null |
| HTTP方法常量 | ngx.HTTP_GET ngx.HTTP_HEAD ngx.HTTP_PUT ngx.HTTP_POST ngx.HTTP_DELETE ngx.HTTP_OPTIONS ngx.HTTP_MKCOL ngx.HTTP_COPY ngx.HTTP_MOVE ngx.HTTP_PROPFIND ngx.HTTP_PROPPATCH ngx.HTTP_LOCK ngx.HTTP_UNLOCK ngx.HTTP_PATCH ngx.HTTP_TRACE |
| HTTP状态码常量 | ngx.HTTP_OK(200) ngx.HTTP_CREATED(201) ngx.HTTP_SPECIAL_RESPONSE(300) ngx.HTTP_MOVED_PERMANENTLY(301) ngx.HTTP_MOVED_TEMPPORARILY(302) ngx.HTTP_SEE_OTHER(303) ngx.HTTP_NOT_MODIFIED(304) ngx.HTTP_BAD_REQUEST(400) ngx.HTTP_UNAUTHORIZED(401) ngx.HTTP_FORBIDDEN(403) ngx.HTTP_NOT_FOUND(404) ngx.HTTP_NOT_ALLOWED(405) ngx.HTTP_GONE(410) ngx.HTTP_INTERNAL_SERVER_ERROR(500) ngx.HTTP_METHOD_NOT_IMPLEMENTED(501) ngx.HTTP_UNAVAILABLE(503) ngx.HTTP_GATEWAY_TIMEOUT(504) |
| 日志常量 | ngx.STDERR ngx.EMERG ngx.ALERT ngx.CRIT ngx.ERR ngx.WARN ngx.NOTICE ngx.INFO ngx.DEBUG |
2.4.4 Ngixn Lua的内置方法
| 内置方法 | 说明 |
|---|---|
| ngx.log(log_level,...) | 按照log_level设定的等级输出到error.log日志文件 |
| Print(...) | 输出到error.log文件,等价于ngx.log(ngx.NOTICE,...) |
| ngx.print(...) | 输出相应到客户端 |
| ngx.say(...) | 输出相应到客户端,自动添加\n换行 |
| ngx.exit(status) | 如果status>=200,此方法会结束当前请求,并且返回status状态到客户端,如果status=0,此方法就会结束请求处理的当前阶段,进入下一个请求处理阶段 |
| ngx.send_header() | 显示的发送响应头。当调用ngx.say()/ngx.print()时,ngx_lua模块会自动发送响应头,可以通过ngx.headers_send内置变量判断是否发送了响应头 |
| ngx.exec(uri,args?) | 内部跳转到uri地址 |
| ngx.redirect(uri,options?) | 外部跳转到URI地址 |
| ngx.location.capture(uri,options?) | 发起一个子请求 |
| ngx.location.capture_multi(uris) | 发起多个子请求。参数uris是一个table,格式为{{uri,options?},...} |
| ngx.is_subrequest() | 当前请求是否是子请求 |
| ngx.sleep(seconds) | 无阻塞的休眠秒数(使用定时器实现) |
| ngx.get_phase() | 获取当前Lua脚本的执行阶段名称。 |
| ngx.req.start_time() | 请求的开始时间 |
| ngx.req.http_version() | 请求的HTTP版本号 |
| ngx.req.raw_header() | 获取原始的请求头(包括请求行) |
| ngx.req.get_method() | 获取请求方法 |
| ngx.req.set_method(method) | 覆盖当前请求的方法 |
| ngx.req.get_uri_args() | 获取请求参数 |
| ngx.req.get_post_args() | 获取post请求内容体,其用法和ngx.req.get_headers()类似,调用此方法之前必须调用ngx.req.read_body()来读取body体。 |
| ngx.req.get_headers() | 获取请求头,默认只获取前100个;如果当前请求有多个header头,则返回的是table;如果想获取全部请求头,可以调用ngx.req.get_headers(0) |
| ngx.resp.get_headers() | 获取响应头,跟ngx.req.get_headers()类似 |
| ngx.req.read_body() | 读取当前请求的请求体 |
| ngx.req.set_header(name,value) | 为当前请求设置一个请求头,如果请求头已存在则覆盖 |
| ngx.req.clear_header(name) | 为当前请求删除名称为name的请求头 |
| ngx.req.set_body_data(data) | 设置当前请求的请求体为data |
| ngx.req.init_body(buffer_size?) | 为当前请求创建一个空的请求体。如果buffer_size参数不为空,那么新请求体的大小为buffer_size。如果buffer_size参数为空,那么新请求体的大小为client_body_buffer_size指令设置的请求体大小。如果未进行指定,默认的请求体大小为8KB(32位)或16KB(64位) |
| ngx.escape_uri(str) | 对uri字符串进行编码 |
| ngx.unescape_uri(str) | 对uri字符串进行解码 |
| ngx.encode_args(table) | 将Lua table 编码成一个参数字符串 |
| ngx.decode_args(str) | 将参数字符串解码成Lua table |
| ngx.encode_base64(str) | 将字符串编码成base64 |
| ngx.decode_base64(str) | 将base64解码成字符串 |
| ngx.hmac_sha1(secret,str) | 将字符串编码成二进制的hmac_sha1哈希串,并使用secret进行加密。并且可以使用ngx.encode_base64(str)将二进制格式进一步编码成字符串 |
| ngx.md5(str) | 将字符串编码成十六进制的MD5 |
| ngd.md5_bin(str) | 将字符串编码成二进制的MD5 |
| ngx.quote_sql_str(str) | SQL语句转义,按照MySql格式转义 |
| ngx.today() | 获取当前日期 |
| ngx.time() | 获取UNIX时间戳 |
| ngx.now() | 获取当前时间 |
| ngx.update_time() | 刷新时间后在返回 |
| ngx.localtime() | 获取yyyy-mm-dd hh:mm:ss格式的本地时间 |
| ngx.cookie_time() | 获取可用于cookie值的时间 |
| ngx.http_time() | 获取可用于HTTP头的时间 |
| ngx.parse_http_time() | 解析HTTP头的时间 |
| ngx.config.nginx_version() | 获取nginx版本号 |
| ngx.config.nginx_lua_version() | 获取lua模块版本号 |
| ngx.worker.pid() | 获取当前Worker进程的pid |
2.5 Nginx Lua编程示例
2.5.1 Lua脚本获取URL中的参数
我们在上面建的LuaDemo项目中修改配置文件:
location /lua_get_args{
set_by_lua $sum '
local args = ngx.req.get_uri_args();
local var1 = args["var1"];
local var2 = args["var2"];
return var1 +var2;
';
echo "$arg_var1 + $arg_var2 = $sum ";
}
#或者用nginx的内置变量
location /lua_get_args{
set_by_lua $sum '
local var1 = tonumber(ngx.arg[1]);
local var2 = tonumber(ngx.arg[2]);
return var1 +var2;
'$var1 $var2;
echo "$arg_var1 + $arg_var2 = $sum ";
}
运行结果如下:

2.5.3 通过ngx.header设置HTTP响应头
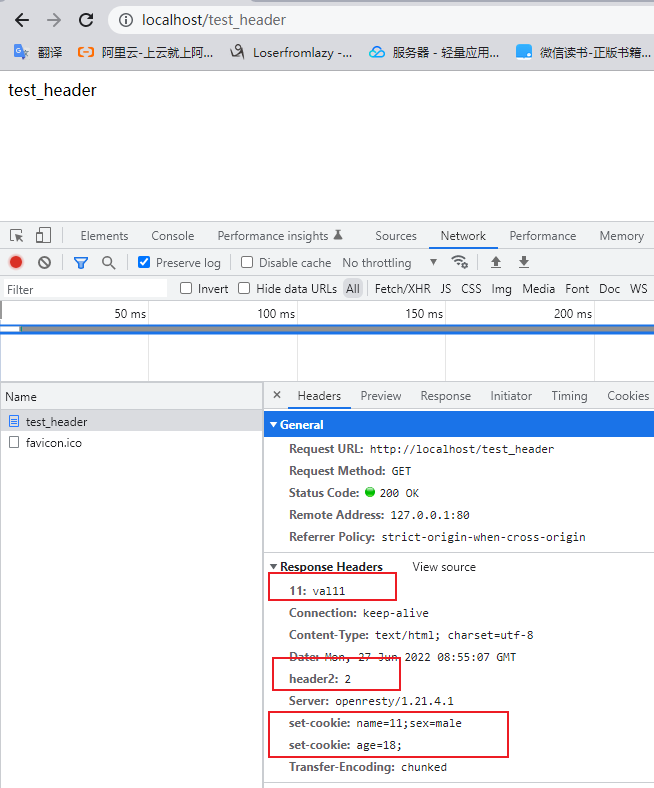
location /test_header{
content_by_lua_block {
ngx.header["11"]="val11";
ngx.header.header2=2;
ngx.header.set_cookie = {
'name=11;sex=male','age=18;'
}
ngx.say("test_header");
}
}
访问路径后结果如下:
Cookie 是通过请求的 set-cookie 响应头来保存的,HTTP 响应内容中可以包含多个 set-cookie 响应头,一个 set-cookie 响应头的值通常为一个字符串,该字符串大致包含以下内容:
| 信息 | 说明 |
|---|---|
| Cookie名称 | Cookie名称的组成字符只能使用可以用于URL中的字符,一般为字母和数字,不能包含特殊字符,若有特殊字符需要进行转码。Cookie名称为Cookie字符串中的第一组key-value中的key。 |
| Cookie值 | Cookie的值的字符组成规则与Cookie相同。Cookie值为Cookie字符串中的第一组key-value中的value。 |
| expires | 过期时间,GMT格式,过了此时间后,浏览器就会删除此cookie,不设置过期时间在关掉浏览器后就会删除 |
| path | Cookie的访问路径,此属性设置指定路径下的页面才可以访问此Cookie,一般设置为'/'表示同一站点的所有页面都可以访问此Cookie |
| domain | 访问域名,此属性设置指定域名下的页面才可以访问此Cookie。 |
| Secure | 安全属性,设置Cookie是否只能通过HTTPS协议访问,一般Cookie使用HTTP即可。一般设置此属性没有值。 |
| HttpOnly | 如果设置了此属性,那么通过程序(JS脚本、Applet等)将无法读取Cookie信息,HttpOnly和secure一样没有值只有名称。 |
- 关于HttpOnly和Secure属性:设置了HttpOnly,通过脚本就无法读取cookie的值,这样一般能防止XSS攻击。大部分场景下不需要前端脚本获取Cookie,Cookie信息只在后端Java容器中进行访问,此时就可以增加httponly属性。另外一旦设置了Secure属性,前后端就只能在通过Https协议通信时访问cookie。微信小程序就要求必须使用https协议。但是在内网内还是可以使用http协议,便于开发测试以及性能更高,然后通过Nginx外部网关完成外部HTTPS到HTTP协议的转换。
为Cookie增加HttpOnly属性可以在Java容器中完成,比如:
@WebFilter(filterName = "loginCheckFilter",urlPatterns = "/*")
public class MyFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void doFilter(ServletRequest servletRequest,
ServletResponse servletResponse,
FilterChain filterChain)
throws IOException, ServletException {
HttpServletRequest request = (HttpServletRequest) servletRequest;
HttpServletResponse response = (HttpServletResponse) servletResponse;
final Cookie[] cookies = request.getCookies();
if (cookies!=null){
for (Cookie cookie : cookies) {
final String name = cookie.getName();
final String value = cookie.getValue();
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append(name+"="+value+";");
stringBuilder.append(";httpOnly");
response.setHeader("Set-Cookie",stringBuilder.toString());
}
}
}
@Override
public void destroy() {
}
}
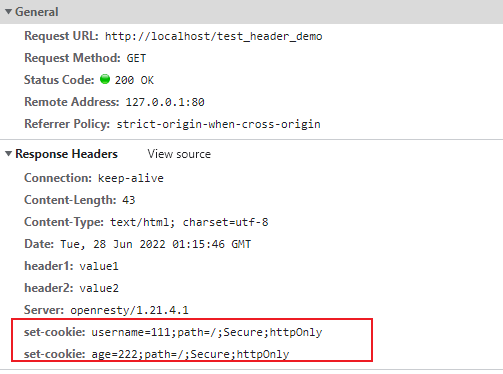
当然为Cookie增加HttpOnly属性(或者Secure)更好的方式是在Nginx中进行配置:
#模拟上游服务
location /test_upserver{
content_by_lua_block {
ngx.header["header1"]="value1";
ngx.header.header2="value2";
ngx.header.set_cookie = {
'username=111;path=/','age=222;path=/'
}
ngx.say("模拟上游服务,设置了一些cookie");
}
}
#模拟外部网关(反向代理)
location /test_header_demo {
proxy_pass http://127.0.0.1/test_upserver;
header_filter_by_lua_block {
local cookies = ngx.header.set_cookie;
if cookies then
if type(cookies) == "table" then
local cookie = {}
for k, v in pairs(cookies) do
cookie[k] = v .. ";Secure;httpOnly"; --cookie添加安全属性
end
ngx.header.set_cookie = cookie;
else
ngx.header.set_cookie = cookies .. ";Secure;httpOnly";
end
end
}
}
结果如下:
2.5.4 Lua访问Nginx变量
Nginx中提供了很多内置变量,比如$arg_PARAMETER、$args等等,除了这些内置变量还可以通过set定义一些Nginx变量,其实无论是内部变量还是自定义变量,都可以在Lua代码中通过ngx.var进行访问。举例:
location /test_lua_var {
set $hello helloworld;
content_by_lua_block {
local base = require("luaScript.module.base");
local vars = {}
vars.remote_addr = ngx.var.remote_addr;
vars.request_uri = ngx.var.request_uri;
vars.uri = ngx.var.uri;
vars.args = ngx.var.args;
ngx.say("测试:返回内置变量<br>");
local str = base.tableToStr(vars,"<br>");
ngx.say(str);
ngx.say("<br>返回普通变量<br>");
ngx.say("hello=" .. ngx.var.hello);
}
}
PS:上面base模块中的tableToStr方法代码如下:
local function toStringEx(value) if type(value)=='table' then return tableToStr(value) elseif type(value)=='string' then return "\'"..value.."\'" else return tostring(value) end end -- 此方法用于将table转换为String类型 local function tableToStr(t, split) if t == nil then return "" end if split == nil then split = ","; end local retstr = "{" local i = 1 for key, value in pairs(t) do if key == i then retstr = retstr .. toStringEx(value) .. split else if type(key) == 'number' or type(key) == 'string' then retstr = retstr .. '[' .. toStringEx(key) .. "]=" .. toStringEx(value) .. split else if type(key) == 'userdata' then retstr = retstr .. "*s" .. tableToStr(getmetatable(key)) .. "*e" .. "=" .. toStringEx(value) .. split else retstr = retstr .. key .. "=" .. toStringEx(value) .. split end end end i = i + 1 end retstr = retstr .. "}" return retstr end
2.5.5 Lua访问请求上下文变量
Nginx执行Lua脚本涉及到很多阶段,如init、init_worker、ssl_session_fetch、set、rewrite等等,每一个阶段都可以嵌入不同的lua脚本,不同阶段的lua脚本可以通过ngx.ctx进行上下文变量的共享。在 ngx_lua 模块中,每个请求(包括子请求)都有一份独立的 ngx.ctx 表。
ngx.ctx本质上是一个Lua table,其生命周期与当前请求相同。
location /test_ctx {
rewrite_by_lua_block {
ngx.ctx.var1 = 1;
}
access_by_lua_block {
ngx.ctx.var2 = 2;
}
content_by_lua_block {
ngx.ctx.var3 =3;
local result = ngx.ctx.var1 +ngx.ctx.var2 +ngx.ctx.var3;
ngx.say(result);
local base = require("luaScript.module.base");
local str = base.tableToStr(ngx.ctx);
ngx.say("<br>");
ngx.say(str);
}
}
2.6 重定向和内部子请求
Nginx 的 rewrite 指令不仅可以在 Nginx 内部的 server、location 之间进行跳转,还可以进行外部链接的重定向。通过 ngx_lua 模块的 Lua 函数除了能实现 Nginx 的 rewrite 指令的功能之外,还能顺利完成内部子请求、并发子请求等复杂功能。
2.6.1 Nginx Lua内部重定向
ngx_lua模块可以实现类似nginx的rewrite指令的效果,该模块提供了两个API:
- ngx.exec(uri,args?)内部重定向
- ngx.redirect(uri,status?)外部重定向
我们先来了解Nginx Lua的内部重定向,其实ngx.exec等价于下面的rewrite方法:
rewrite regrex replacement last;
ngx.exec的使用方式如下:
#不带参数重定向到/sum
ngx.exec('/sum');
#使用一个字符串作为追加参数的重定向.
#重定向到/sum?a=1&b=2,并且追加参数c=3
ngx.exec('/sum?a=1&b=2',"c=3");
#使用Lua table作为追加参数
ngx.exec('/sum',{a=1,b=2,c=3});
下面举个例子(结果略):
location /sum {
internal;#只允许内部调用
content_by_lua_block{
local arg_a = tonumber(ngx.var.arg_a);
local arg_b = tonumber(ngx.var.arg_b);
local arg_c = tonumber(ngx.var.arg_c);
local sum = arg_a+ arg_b+arg_c;
ngx.say(sum)
}
}
location /testsum {
content_by_lua_block{
#此方法使用时需要显式return
return ngx.exec('/sum',{a=1,b=2,c=3});
}
}
使用此方法时可以使用字符串也能使用table但要注意写法:
ngx.exec('/sum',"a=1&b=2");
ngx.exec('/sum',{a=1,b=2});
2.6.2 Nginx Lua外部重定向
外部重定向方法是ngx.redirect(uri,status?)。外部重定向与内部重定向不同,将在客户端进行二次跳转,所以会有额外的网络流量。此方法与下面的rewrite等价:
#如果你想试这个例子需要去掉/sum这个location中的internal指令,否则会报404
location /test1 {
content_by_lua_block{
return ngx.redirect("/sum?a=1&b=2&c=3");
}
}
location /test2 {
rewrite ^/test2 "/sum?a=1&b=2&c=3" redirect;
}
当然如果想实现rewrite的permanent参数的效果也是可以的,只需要使用nginx lua的内置常量即可:
#如果你想试这个例子需要去掉/sum这个location中的internal指令,否则会报404
location /test1 {
content_by_lua_block{
return ngx.redirect("/sum?a=1&b=2&c=3",ngx.HTTP_MOVED_PERMANENTLY);
}
}
location /test2 {
rewrite ^/test2 "/sum?a=1&b=2&c=3" permanent;
}
下面给出外部重定向的例子:
location ~*/testblog/(.*) {
content_by_lua_block {
ngx.redirect("https://www.cnblogs.com/" ..ngx.var[1]);
}
}
location ~*/testblog1/(.*) {
rewrite ^/testblog1/(.*) "https://www.cnblogs.com/$1" redirect;
}
location ~*/testblog2/(.*) {
rewrite ^/testblog2/(.*) $1 break;
content_by_lua_block {
ngx.redirect("https://www.cnblogs.com/" ..ngx.var[1]);
}
}
然后我们输入localhost/testblog/博客园个人博客地址就可以跳转到自己的博客园首页,这段代码本质上就是将个人博客地址拼成正确的博客地址然后进行重定向,重定向到了我们给出的博客地址。结果:

2.6.3 ngx.location.capture子请求
Nginx子请求不是HTTP的标准实现,而是Nginx的特有设计,目的是为了提高内部对单个客户端的请求处理的并发能力。如果某个客户端的请求(或主请求)访问了多个内部资源,为了提高效率,可以为每一个内部资源访问建立单个子请求,同时进行提高效率。子请求不是客户端发起的,而是Nginx根据逻辑建立的所以不会与客户端交互。通常情况下,为了保护子请求会把接口设置为internal,防止外部访问。
发起单个子请求格式如下:
ngx.location.capture (uri,options?);
其中options是一个table容器,用于设置子请求的相关选项:
- method:子请求方法,默认为ngx.HTTP_GET,只接受NGINX Lua常量
- body:传给子请求的请求体,仅限于string或nil
- args:传给子请求的参数,支持string或table
- vars:传给子请求的变量表,仅限于table,在通过 vars 向子请求中传递 Nginx 变量时,变量需要提前进行定义,否则将报出变量未定义的错误。
- ctx:父子请求共享的变量表table。父请求如果修改了 ctx 表中的成员,那么子请求可以通过 ngx.ctx 获取;反过来,子请求也可以修改ngx.ctx中的成员,父请求可以通过ctx表获取。通过ctx 属性值可以方便地让父请求和子请求进行上下文变量共享。
- copy_all_vars:复制所有变量给子请求
- share_all_vars:父子请求共享所有变量
- always_forward_body:用于设置是否转发请求体
例子:
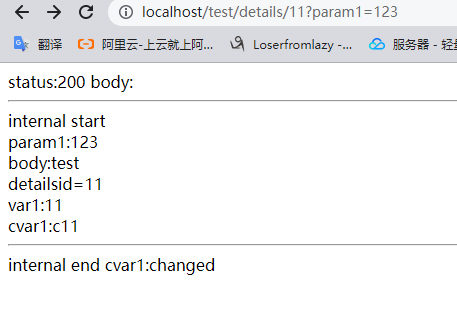
location ~ /test/details/([0-9]+) {
#获取正则捕获组数据
set $detailsid $1;
set $var1 "";
set $var2 "";
content_by_lua_block{
ngx.req.read_body();
local uri = "/internal/details/" ..ngx.var.detailsid;
--获取父请求的参数
local args = ngx.var.args;
local method = ngx.var.request_method;
local shareCtx = {cvar1= "c11",cvar2 = "c22"}
local response = ngx.location.capture(uri,{
method = ngx.HTTP_GET,
body = "test",
args = args,
vars = {var1 = "11",var2="22"},
always_forward_body = true,
ctx = shareCtx,});
ngx.say("status:" .. response.status);
ngx.say("body:" .. response.body);
ngx.say("cvar1:" .. shareCtx.cvar1);
}
}
location ~/internal/details/([0-9]+){
internal;
set $detailsid $1;
content_by_lua_block {
ngx.say("<hr> internal start");
--获取父请求的参数,两种方式均可
local args = ngx.req.get_uri_args();
ngx.say("<br>param1:" ..args.param1);
ngx.say("<br>body:" ..ngx.req.get_body_data());
ngx.say("<br>detailsid=",ngx.var.detailsid);
ngx.say("<br>var1:"..ngx.var.var1);
ngx.say("<br>cvar1:"..ngx.ctx.cvar1);
ngx.say("<hr> internal end");
--修改共享上下文
ngx.ctx.cvar1 = "changed";
}
}
结果:
2.6.4 ngx.location.capture_multi并发子请求
经过解耦后,微服务框架会提供大量的细粒度接口,一次客户端请求往往调用多个微服务接口才能获取到完整的页面内容。这种场景下可以通过网关进行上游接口合并。在OpenResty中ngx.location.capture_multi可以用于上游接口合并的场景,此方法可以进行多个子请求和并发访问,格式如下:
ngx.location.capture_multi({ {uri,options?},{uri,options?}...})
在所有子请求终止之前,ngx.location.capture_multi(...)函数不会返回。此函数的耗时是单个子请求的最长延迟,而不是所有子请求的耗时总和,因为所有子请求是并发执行的。
这个方法中的每一个子请求的参数使用方式与capture方法相同。capture_multi可以将所有的子请求加入到一个table容器表中,作为调用参数传入;capture_multi返回后可以将其结果再用花括号{}包装成一个table,方便后面迭代。
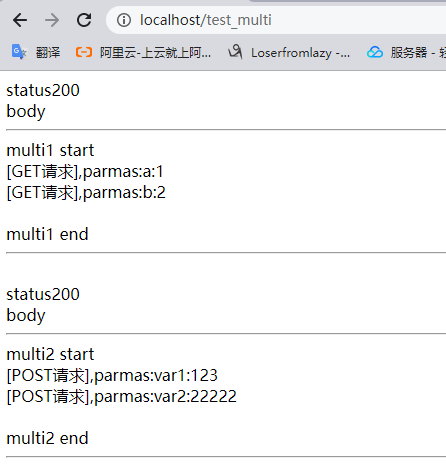
location /test_multi {
content_by_lua_block{
local postBody = ngx.encode_args({var1=123,var2="22222"});
local reqs = {};
table.insert(reqs,{"/internal/multi1",{args="a=1&b=2"}});
table.insert(reqs,{"/internal/multi2",{method = ngx.HTTP_POST,body=postBody}});
local responses = {ngx.location.capture_multi(reqs)};
for i,value in pairs(responses) do
ngx.say("status" .. value.status .."<br>" );
ngx.say("body" .. value.body .."<br>" );
end
}
}
#模拟上游接口
location /internal/multi1 {
internal;
content_by_lua_block {
ngx.say("<hr> multi1 start<br>");
local args = ngx.req.get_uri_args();
for key ,val in pairs(args) do
ngx.say("[GET请求],parmas:" .. key .. ":" .. val .. "<br>");
end
ngx.say("<br>multi1 end<hr>")
}
}
#模拟上游接口
location /internal/multi2 {
internal;
content_by_lua_block {
ngx.say("<hr> multi2 start<br>");
ngx.req.read_body();--获取请求体前必须先读
local data = ngx.req.get_post_args();
for key,val in pairs(data) do
ngx.say("[POST请求],parmas:" .. key .. ":" .. val .. "<br>");
end
ngx.say("<br>multi2 end<hr>")
}
}
2.7 Nginx Lua操作Redis
2.7.1 Redis的CRUD操作
lua操作redis的配置文件模块脚本
---
--- Generated by EmmyLua(https://github.com/EmmyLua)
--- Created by Loserfromlazy.
--- DateTime: 2022/6/28 15:53
---
-- 定义一个统一的redis 配置模块
local _Module = {
-- redis 服务器的地址
host_name = "127.0.0.1";
-- redis 服务器的端口
port = "6379";
-- redis 服务器的数据库
db = "0";
-- redis 服务器的密码
password = '123456';
--连接超时时长
timeout = 20000;
-- 线程池的连接数量
pool_size = 100;
-- 最大的空闲时间 ,单位:毫秒
pool_max_idle_time = 10000;
}
return _Module
lua操作redis的基本CURD
---
--- Generated by EmmyLua(https://github.com/EmmyLua)
--- Created by Loserfromlazy.
--- DateTime: 2022/6/28 16:40
---
local redis = require "resty.redis"
local config = require("luaScript.config.redis-config")
local red = redis:new()
--设置超时时长
red:set_timeouts(config.timeout,config.timeout,config.timeout)
--连接服务器
local ok,err = red:connect(config.host_name,config.port)
if not ok then
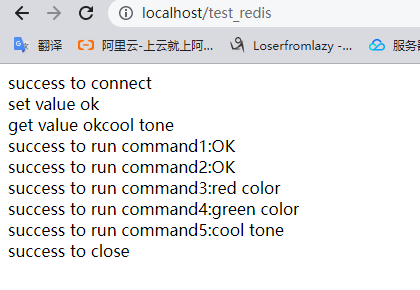
ngx.say("failed to connect:",err)
return
else
ngx.say("success to connect","<br>")
end
--认证redis密码
if config.password then
red:auth(config.password)
end
--设置值
ok,err = red:set("blue","cool tone")
if not ok then
ngx.say("failed to set value",err,"<br>")
return
else
ngx.say("set value ok","<br>")
end
--取值
local res ,error = red:get("blue")
if not res or res == ngx.null then
ngx.say("failed to get value",error,"<br>")
return
else
ngx.say("get value ok",res,"<br>")
end
--ok,err = red:set_keepalive(10000,100)
--if not ok then
-- ngx.say("failed to set keepalive",err,"<br>")
-- return
--end
--批量操作
red:init_pipeline()
red:set("red","red color")
red:set("green","green color")
red:get("red")
red:get("green")
red:get("blue")
local results,errorline = red:commit_pipeline()
if not results then
ngx.say("failed to commit the pipeline ",errorline)
return
end
for i, v in ipairs(results) do
if type(v) == "table" then
ngx.say("success to run command",i,":",v,"<br>")
else
ngx.say("success to run command",i,":",v,"<br>")
end
end
--关闭连接
ok ,err = red:close()
if not ok then
ngx.say("failed to close",err,"<br>")
else
ngx.say("success to close")
end
结果如下:
2.7.2 在Lua中使用Redis连接池
我们在上面的例子中,每一次客户端请求,lua-resty-redis服务都会创建一个新连接,这样就会造成资源浪费,且会有以下问题:
- 连接资源快速消耗
- 网络一旦抖动会有大量TIME_WAIT连接产生,需要定期重启服务程序
- 服务器工作不稳定
- 性能上不去
在高并发场景下,我们可以将短连接改成长连接,减少大量连接创建拆除的时间,同时使用连接池,将所有长连接管理起来。在OpenResty中lua-resty-redis木块管理了一个连接池。并且通过set_keepalive方法完成连接的回收和复用,语法如下:
ok,err = red:set_keepalive(max_idle_timeout,pool_size)
该方法将当前的Redis连接立即放入连接池,其中max_idle_timeout指定连接在连接池中的最大空闲超时时长,pool_size指定每个Nginx工作进程中的连接池的最大连接数。如果成功返回1,如果失败返回nil,并返回错误字符串。举个例子:
location /test_redis_poll{
content_by_lua_block {
local redis = require("resty.redis");
local config = require("luaScript.config.redis-config");
local max_size = config.pool_size;
local max_time = config.pool_max_idle_time;
local red = redis:new();
local ok,err = red:connect(config.host_name,config.port);
if not ok then
ngx.say("failed to connect redis",err);
else
ngx.say("success to connect redis");
end
--不能在此处设置red:set_keepalive,因为需要等所有数据传输完成后才能将连接放入池子
red:auth(config.password);
ok,err = red:set("test_pool","123");
if not ok then
--不能在此处设置red:set_keepalive,因为设置值失败可能连接不可用,不能将不知道是否可用的连接放入连接池
ngx.say("failed to set value",err,"<br>");
return
else
ngx.say("set value ok","<br>");
end
--使用完毕后可以回收连接
red:set_keepalive(max_time,max_size);
ngx.say("success to recycle redis connect")
}
}
set_keepalive 方法完成连接回收之后,下一次通过 red:connect(...)获取连接时,connect 方法在创建新连接前会在连接池中查找空闲连接,只有查找失败才会真正创建新连接。
2.7.3 封装操作Redis的基础类
我们在使用时如果每次都写关于redis的操作会很麻烦,所以我们可以进行封装,网上的代码有很多,这里给出一个封装的基础类:
---
--- Generated by EmmyLua(https://github.com/EmmyLua)
--- Created by Loserfromlazy.
--- DateTime: 2022/6/30 16:33
---
local redis = require "resty.redis
local config = require("luaScript.config.redis-config")
--连接池大小
local pool_size = config.pool_size;
-- 最大的空闲时间 ,单位:毫秒
local pool_max_idle_time = config.pool_max_idle_time;
--一个统一的模块对象
local _Module = {}
_Module.__index = _Module
-- 类的方法 new
function _Module.new(self)
local object = { red = nil }
setmetatable(object, self)
return object
end
--获取redis连接
function _Module.open(self)
local red = redis:new()
-- 设置超时的时间为 2 sec,connect_timeout, send_timeout, read_timeout
red:set_timeout(config.timeout, config.timeout, config.timeout);
local ok, err = red:connect( config.host_name, config.port)
if not ok then
ngx.say("连接redis服务器失败: ", err)
return false;
end
if config.password then
red:auth(config.password)
end
if config.db then
red:select(config.db)
end
ngx.say("连接redis服务器成功")
self.red = red;
return true;
end
--缓存值
function _Module.setValue(self, key, value)
local ok, err = self.red:set(key, value)
if not ok then
ngx.say("redis 缓存设置失败")
return false;
end
ngx.say("set result ok")
return true;
end
--值递增
function _Module.incrValue(self, key)
local ok, err = self.red:incr(key)
if not ok then
ngx.say("redis 缓存递增失败 ")
return false;
end
ngx.say("incr ok")
return ok;
end
--过期
function _Module.expire(self, key, seconds)
local ok, err = self.red:expire(key, seconds)
if not ok then
ngx.say("redis 设置过期失败 ")
return false;
end
return true;
end
--获取值
function _Module.getValue(self, key)
local resp, err = self.red:get(key)
if not resp then
ngx.say("redis 缓存读取失败 ")
return nil;
end
return resp;
end
--获取值
function _Module.getSmembers(self, key)
local resp, err = self.red:smembers(key)
if not resp then
ngx.say("redis 缓存读取失败 ")
return nil;
end
return resp;
end
--缓存值
function _Module.hsetValue(self, key, id, value)
local ok, err = self.red:hset(key, id, value)
if not ok then
ngx.say("redis hset 失败 ")
return false;
end
print("set result: ", ok)
return true;
end
--获取值
function _Module.hgetValue(self, key, id)
local resp, err = self.red:hget(key, id)
if not resp then
ngx.say("redis hget 失败 ")
return nil;
end
return resp;
end
--执行脚本
function _Module.evalsha(self, sha, key1, key2)
local resp, err = self.red:evalsha(sha, 2, key1, key2)
if not resp then
ngx.say("redis evalsha 执行失败 ")
return nil;
end
return resp;
end
function _Module.getConnection(self)
return self.red;
end
-- 将连接还给连接池
function _Module.close(self)
if not self.red then
return
end
local ok, err = self.red:set_keepalive(pool_max_idle_time, pool_size)
if not ok then
ngx.say("redis set_keepalive 执行失败 ")
end
ngx.say("redis 连接释放成功")
end
return _Module
使用时导入此模块即可。我们简单使用一下:
location /testUtil {
content_by_lua_block {
local redisUtil = require("luaScript.module.RedisUtil");
local red = redisUtil:new();
red.open(red);
red.setValue(red,"test11","111");
local result = red.getValue(red,"test11");
ngx.say(result);
red:close(red);
}
}
结果略。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号