ElasticSearch学习文档
ElasticSearch学习笔记
一.简介
Elaticsearch,简称为es, es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。es也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
使用案例
- 2013年初,GitHub抛弃了Solr,采取ElasticSearch 来做PB级的搜索。 “GitHub使用ElasticSearch搜索20TB的数据,包括13亿文件和1300亿行代码”
- 维基百科:启动以elasticsearch为基础的核心搜索架构
- SoundCloud:“SoundCloud使用ElasticSearch为1.8亿用户提供即时而精准的音乐搜索服务”
- 百度:百度目前广泛使用ElasticSearch作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部20多个业务线(包括casio、云分析、网盟、预测、文库、直达号、钱包、风控等),单集群最大100台机器,200个ES节点,每天导入30TB+数据
- 新浪使用ES 分析处理32亿条实时日志
- 阿里使用ES 构建挖财自己的日志采集和分析体系
对比solr
- 2013年初,GitHub抛弃了Solr,采取ElasticSearch 来做PB级的搜索。 “GitHub使用ElasticSearch搜索20TB的数据,包括13亿文件和1300亿行代码”
- 维基百科:启动以elasticsearch为基础的核心搜索架构
- SoundCloud:“SoundCloud使用ElasticSearch为1.8亿用户提供即时而精准的音乐搜索服务”
- 百度:百度目前广泛使用ElasticSearch作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部20多个业务线(包括casio、云分析、网盟、预测、文库、直达号、钱包、风控等),单集群最大100台机器,200个ES节点,每天导入30TB+数据
- 新浪使用ES 分析处理32亿条实时日志
- 阿里使用ES 构建挖财自己的日志采集和分析体系
二.安装与启动
下载es包
安装es包:es的安装类似于tomcat,解压即可,解压后目录结构如下:
bin:可执行二进制文件
config:配置信息目录 elasticsearch配置文件:config/elasticsearch.yml:
增加以下两句命令:注意冒号后面必须有一个空格
http.cors.enabled: true
http.cors.allow-origin: "*"
此步为允许elasticsearch跨越访问,如果不安装后面的elasticsearch-head是可以不修改,直接启动。
lib:jar包存放位置
logs:日志存放目录
modules:模块存在目录
plugins:插件安装目录
启动服务:
点击bin下的elasticSearch.bat启动,
注意:9300是tcp通讯端口,集群间和TCPclient都执行该端口,9200是http协议的RESTful接口。
通过浏览器访问ElasticSearch服务器看到返回的json信息,代表服务启动成功

安装ES的图形化界面插件
ElasticSearch不同于Solr自带图形化界面,我们可以通过安装ElasticSearch的head插件,完成图形化界面的效
果,完成索引数据的查看。安装插件的方式有两种,在线安装和本地安装。本文档采用本地安装方式进行head插
件的安装。elasticsearch-5-*以上版本安装head需要安装node和grunt
1.elasticsearch-head-master插件压缩包;将elasticsearch-head-master压缩包解压到任意目录,但是要和elasticsearch的安装目录区别开
2.下载nodejs:https://nodejs.org/en/download/ 并安装。安装完毕后,可以通过cmd输入node-v查看版本号
3.将grunt 安装为全局命令,Grunt是基于Node.js的项目构建工具
在cmd中输入
npm install -g grunt-cli
PS:国内连接npm可能会导致网络不畅通建议使用npm代理
npm config set registry https://registry.npm.taobao.org
使用完此代码后在进行npm命令
进入elasticsearch-head-master目录启动head,在命令提示符下输入命令:
npm install
grunt server
打开浏览器,输入http://localhost:9100,看到如下页面及成功
如不能连接 按上面的修改 yml配置文件 重启es服务即可
三 .ElasticSearch相关概念
Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅
仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在Elasticsearch中,你可以对文档(而非成行成列的
数据)进行索引、搜索、排序、过滤。Elasticsearch比传统关系型数据库如下:
Relational DB -> DataBases -> Tables -> Rows -> Columns
Elasticsearch -> Indices -> Types -> Documents -> Fields
核心概念
3.1 索引 index
一个索引就是一个拥有几分相似特征的文档的集合。elastic数据管理的顶层单位就是索引。它相当于关系型数据库中的一个数据库。
3.2 类型 type
在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分区/分类,其语义完全由你来定。通常,回味具有一组共同字段的文档定义为一个类型。我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。
Elastic 6.x 版只允许每个 Index 包含一个 Type,7.x 版将会彻底移除 Type。
3.3 字段 Field
相当于数据表的字段,对文档数据根据不同属性进行的分类标识。
3.4 映射 Mapping
mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等。
映射主要分为动态映射和静态映射:
动态映射:在elasticsearch中不需要事先定义映射,文档写入elasticsearch时,会根据文档的字段自动识别类型,这种机制成为动态映射。
静态映射:在elasticsearch中可以事先定义好映射,包含文档中的各个字段及其类型,这种方式成为静态映射。
常用数据类型:
3.4.1字符串类型
| 类型 | 描述 |
|---|---|
| text | 当一个字段需要被全文搜索,比如Email内容、产品描述,应该使用text类型。设置text类型之后,字段内容会被分析,在生成倒排索引以前,字符串会被分析器分成一个词项。text字段不用于排序,很少用于聚合。 |
| keyword | keyword类型适用于索引结构化的字段,比如Email地址、主机名、状态码和标签。如果字段需要进行过滤(比如查找已发布博客中status属性为public的文章)、排序、聚合。ketword类型的字段只能通过精确值搜索到。 |
3.4.2整数类型
| 类型 | 范围 |
|---|---|
| byte | -128~127 |
| short | -32768~32768 |
| integer | -231~231-1 |
| long | -263~263-1 |
3.4.3浮点类型
| 类型 | 范围 |
|---|---|
| double | 64位双精度浮点 |
| float | 32位单精度浮点 |
| half_float | 16位版精度浮点类型 |
| scaled_float | 缩放类型的浮点数 |
3.4.4date类型
日期类型可以以下几种:
- 日期类型字符串,比如"2018-12-12"或"2018-12-12 12:12:12"
- long类型的毫秒数(从1970年1月1日0时0分0秒开始)
- integer的秒数
3.4.5 boolean类型
true或false
3.4.6 binary类型
进制字段是指用base64来表示索引中存储的二进制数据,可用来存储二进制形式的数据,例如图像。默认情况下,该类型的字段只存储不索引。二进制类型只支持index_name属性
3.4.7 array类型
字符数组: ["one","two"]
整数数组: productid:[1,2]
对象\文档数组:"user":[{"name":"Mary","age":"18"},{"name":"Mike","age":"19"}]
3.4.8 object类型
json对象
3.4.9 ip类型
ip类型的字段用于存储ipv4或ipv6的地址
3.5 文档 document
index中单条记录成为文档。许多条文档构成一个index。文档相当于关系型数据库中的一行记录。document使用json格式表示:
{
"user":"zhangsan",
"title":"工程师",
"desc":"manager"
}
同一个index中的document可以有不同的结构,但最好保持相同,有利于搜索效率。
3.6 接近实时 NRT
ElsaticSearch是一个接近实时的搜索平台。这意味着,从索引一个文档直到这个文档能被搜索到有一个轻微的延迟(通常为一秒以内)
3.7 集群 cluster
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能。一个集群由一个唯一的名字标识,这个名字默认就是“elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群
3.8 节点 node
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。和集群类似,一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对应于Elasticsearch集群中的哪些节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫
做“elasticsearch”的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中。
在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何Elasticsearch节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
3.9 分片和复制 shard&replicas
一个索引可以存储超出单个节点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任意节点都没有这样庞大的磁盘空间;或者单个节点处理搜索请求,相应太慢。为了解决这个问题,Elasticsearch提供了将索引划分为多份的能力,这些份就叫做分片。当你创建一个索引的时候你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。分片很重要,主要有两方面的原因:1)允许你水平分割/扩展你的内容容量。2)允许你在分片(潜在地,位于多个节点上)之上
进行分布式的、并行的操作,进而提高性能/吞吐量。
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户的你来说,
这些都是透明的。
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因
消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分
片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。
复制之所以重要,有两个主要原因:在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分
片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。扩展你的搜索量/吞吐量,因为搜索可以
在所有的复制上并行运行。总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)
或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分
片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你
事后不能改变分片的数量。
默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节
点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。
四 .ElasticSearch的客户端操作
实际开发中,主要有三个方式可以作为elasticsearch服务的客户端
- 第一种,elasticsearch-head插件
- 第二种,使用elasticsearch提供的Resultful接口直接访问
- 第三种,使用elasticsearch提供的API进行访问
4.1Postman工具的下载安装
Postman中文版是postman这款强大网页调试工具的windows客户端,提供功能强大的Web API & HTTP 请求调
试。软件功能非常强大,界面简洁明晰、操作方便快捷,设计得很人性化。Postman中文版能够发送任何类型的
HTTP 请求(GET, HEAD, POST, PUT..),且可以附带任何数量的参数。
Postman官网:https://www.getpostman.com
此软件需要注册后使用
4.2 使用Postman工具进行Restful接口访问
4.2.1ElasticSearch的接口语法
curl -X< VERB> '< PROTOCOL>://< HOST>:< PORT>/< PATH>?< QUERY_STRING>' -d ''
| 参数 | 解释 |
|---|---|
| VBER | 适当的HTTP方法 或 谓词 :GET、POST、PUT、HEAD、DELETE |
| PROTOCOL | http或者https (如果你在Elasticsearch前面有一个https代理) |
| HOST | ElasticSearch集群中任意节点的主机名,或者用localhost代表本地机器上的节点 |
| PORT | 运行Elasticsearch HTTP服务的端口号 ,默认是9200 |
| PATH | API的终端路径(例如_count 将返回集群中文档数量)。path可能包含多个组件,例如:_cluster/stats和 _nodes/stats/jvm |
| QUERY_STRING | 任意可选的查询字符串参数(例如?pretty 将格式化的输出JSON返回值,使其更容易阅读) |
| BODY | 一个JSON格式的请求体(如果请求需要的话) |
4.2.2 创建索引index和映射mapping
请求URL:
PUT localhist:9200/索引名
请求体
{
"mappings":
{
"article"://类型名称
{
"properties"://定义属性
{
"id": //字段名
{ //属性
"type": "long",
"store": true,
"index": false
},
"title":
{
"type": "text",
"store": true,
"index": true,
"analyzer":"standard"
},
"content": {
"type": "text",
"store": true,
"index": true,
"analyzer":"standard"
}
}
}
}
}
类型名称:type的概念,类似于数据库中的不同表
字段名:任意,可以指定许多属性,例如:
- type:可以是text、long等
- index:是否索引,默认ture
- store:是否单独存储,默认false,一般内容比较多的字段设置为true,可提升查询性能
- analyzer:分词器
4.2.3 创建索引后设置Mapping
在上一个方法中不设置mapping,直接使用put创建一个索引,然后再此方法设置mapping
{
"hello": {
"properties": {
"id": {
"type": "long",
"store": true
},
"title": {
"type": "text",
"store":true,
"index":true,
"analyzer":"standard"
},
"content": {
"type": "text",
"store": true,
"index": true,
"analyzer": "standard"
}
}
}
}
4.2.4 删除索引index
DELETE localhost:9200/blog1
4.2.5 创建文档
POST localhost:9200/索引名/类型名/id值
{
"id": 1,
"title": "ElasticSearch是一个基于Lucene的全文检索服务器",
"content": "它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。",
"key":"value"
}
如果没有指定id值,则自动生成id
4.2.6 修改文档document
POST localhost:9200/blog/artical/1
{
"id": 1,
"title": "【修改】ElasticSearch是一个基于Lucene的全文检索服务器",
"content": "【修改】它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。"
}
4.2.7 删除文档
DELETE localhost:9200/blog/article/1
4.2.8 查询文档根据id查询
GET localhost:9200/blog/article/1
索引查询基本语法:
GET /索引名/_search
{
"query":{
"查询类型":{
"查询条件":"查询条件值"
}
}
}
这里query代表一个查询对象,里面可以有不同的查询属性
- 查询类型
- match_all,term等等
- 查询条件,查询条件会根据类型的不同有些许差异
4.2.9 查询所有数据
GET localhost:9200/sku/_search
{
"query":{
"match_all":{}
}
}
查询索引库中所有记录
4.2.10 匹配查询
GET localhost:9200/sku/_search
kibana中 GET /sku/_search
{
"query":{
"match":{
"name":"小米手机"//查询时会分词,可能查询时会包含小米或手机或小米手机
}
}
}
返回值会有“score”属性显示匹配度分值.
下面将展示另一种写法:
{
"query":{
"match":{
"name":{
"query":"小米手机",
"operator":"and"
}
}
}
}
这种写法是精准查询,将操作改为and,这时必须包含小米和手机两个词才能被搜索出来。
4.2.11 多字段查询
GET localhost:9200/sku/_search
与match类似,但是可以在多个字段中查询
{
"query":{
"multi_match":{
"query":"小米",
"fields":["name","brandName","categoryName"]
}
}
}
这时就会在这三个字段中进行查询了
4.2.12 词条匹配term
term用于精确值匹配,这些精确值可能是数字、时间】布尔或为分词的字符串
GET localhost:9200/sku/_search
{
"query": {
"term": {
"price": 1000
#"price":{
# "value":1000
#}
#也可以这种写法
}
}
}
多词条匹配terms
与term一样,但允许多个值匹配
{
"query": {
"term": {
"price": [300000,200000]
}
}
}
4.2.13 布尔组合查询
把各种查询通过must (与)must_not (非)should(或)的方式进行组合
GET /sku/_search
示例:查询名称包含手机且品牌为小米
{
"query":{
"bool":{
"must":[
{"match":{"name":"手机"}},
{"term":{"brandName":"小米"}}
]
}
}
}
示例:查询名称包含手机或品牌为小米的
{
"query":{
"bool":{
"should":[
{"match":{"name":"手机"}},
{"term":{"brandName":"小米"}}
]
}
}
}
4.2.14 过滤查询
过滤查询是针对搜索的结果进行过滤,过滤器主要判断文档是否匹配,不去计算和判断文档的匹配度得分,所以过滤器比查询性能高,且方便缓存
{
"query":{
"bool":{
"filter":[
{"match":{"brandName":"小米"}}
]
}
}
}
4.2.15 分组/聚合查询
{
"aggs":{//聚合
"sku_categoey":{//分组结果集名称
"terms":{//分组查询类型
"field":"categoryName"//按分类来统计结果
}
},
"sku_brand":{//分组结果集名称
"terms":{//分组查询类型
"field":"brandName"//按品牌来统计结果
}
}
}
}
如果不想查询记录指向查看分组统计结果,秩只需添加"size":0,因为size为0不会显示出来,即:
{
"size":0,
"aggs":{//聚合
"sku_categoey":{//分组结果集名称
"terms":{//分组查询类型
"field":"categoryName"//按分类来统计结果
}
},
"sku_brand":{//分组结果集名称
"terms":{//分组查询类型
"field":"brandName"//按品牌来统计结果
}
}
}
}
4.3 Kibana可视化工具的安装与使用
Kibana是一个开源的分析和可视化平台。旨在与elasticsearch合作。kibana提供搜索、查看和与存储在elasticsearch索引中的数据进行交互的功能。
安装
- 解压kibana-x.x.x-windows-x86_64.zip
- 如果kibana远程连接elasticsearch,可以修改config\kibana.yml
- 执行bin\kibana.bat
- 打开浏览器输入localhost:5601访问
Kibana的操作均在开发工具(dev_tools)选单中操作,具体操作与postman基本一致,例如
在postman中删除:
DELETE localhost:9200/blog
在kibana中删除:在devtools中写:
DELETE blog
所以在kibana中不需要地址和端口号
五. IK分词器和ElasticSearch继承使用
5.1 标准分词器分词效果
GET http://127.0.0.1:9200/_analyze?analyzer=standard&pretty=true&text=我是程序员
5.2 IK分词器简介
IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始,IKAnalyzer已经推出了3个大版本。最初,它是以开源项目Lucene为应用主体的,结合词典分词和文法分析算法的
中文分词组件。新版本的IKAnalyzer3.0则发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对
Lucene的默认优化实现。
IK分词器3.0的特性如下:
1)采用了特有的“正向迭代最细粒度切分算法“,具有60万字/秒的高速处理能力。2)采用了多子处理器分析模
式,支持:英文字母(IP地址、Email、URL)、数字(日期,常用中文数量词,罗马数字,科学计数法),中文
词汇(姓名、地名处理)等分词处理。3)对中英联合支持不是很好,在这方面的处理比较麻烦.需再做一次查询,同
时是支持个人词条的优化的词典存储,更小的内存占用。4)支持用户词典扩展定义。5)针对Lucene全文检索优
化的查询分析器IKQueryParser;采用歧义分析算法优化查询关键字的搜索排列组合,能极大的提高Lucene检索的命中率。
5.3 ES集成IK分词器
5.3.1下载安装解压
解压后,将解压好的文件夹拷贝到elasticsearch-5.6.8\plugins下,并重命名analysis-ik
重启ES服务,即可加载IK分词器
5.3.2 测试IK分词器
IK提供了两个分词算法ik_smart 和ik_max_word
其中ik_smart 为最少切分,ik_max_word为最细粒度划分
a)最小切分
localhost:9200/_analyze?analyzer=ik_smart&pretty=true&text=我是程序员
输出结果为
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "程序员",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
}
]
}
b)最细切分
localhost:9200/_analyze?analyzer=ik_max_word&pretty=true&text=我是程序员
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "程序员",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
},
{
"token": "程序",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 3
},
{
"token": "员",
"start_offset": 4,
"end_offset": 5,
"type": "CN_CHAR",
"position": 4
}
]
}
5.3.3自定义词库
在elasticsearch的plugins文件夹下的ik文件夹下的config文件夹中创建xxx.dic文件输入单词并以utf-8格式编码
在IKAnalyzer.cfg.xml文件中配置:
<entry key="ext_dict">xxx.dic</entry>
5.4 修改索引映射mapping
PUT localhost:9200/blog1
{
"mappings":
{
"article":
{
"properties":
{
"id":
{
"type": "long",
"store": true,
"index": false
},
"title":
{
"type": "text",
"store": true,
"index": true,
"analyzer":"ik_max_word"
},
"content": {
"type": "text",
"store": true,
"index": true,
"analyzer":"ik_max_word"
}
}
}
}
}
POST localhost:9200/blog1/article/1
{
"id":1,
"title":"ElasticSearch是一个基于Lucene的搜索服务器",
"content":"它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java
开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时
搜索,稳定,可靠,快速,安装使用方便。"
}
POST localhost:9200/blog1/article/_search
{
"query": {
"query_string": {
"default_field": "title",
"query": "搜索服务器"
}
}
}
六. ElasticSearch集群
ES集群是一个P2P类型(使用gossip协议)的分布式系统,除了集群状态管理之外,其他所有的请求都可以发送到
集群内任意一台节点上,这个节点可以自己找到需要转发给哪些节点,并且直接跟这些节点通信。所以,从网络架
构及服务配置上来说,构建集群所需要的配置极其简单。在Elasticsearch 2.0 之前,无阻碍的网络下,所有配置了
相同cluster.name 的节点都自动归属到一个集群中。2.0 版本之后,基于安全的考虑避免开发环境过于随便造成的
麻烦,从2.0 版本开始,默认的自动发现方式改为了单播(unicast)方式。配置里提供几台节点的地址,ES 将其视作
gossip router 角色,借以完成集群的发现。由于这只是ES 内一个很小的功能,所以gossip router 角色并不需要
单独配置,每个ES 节点都可以担任。所以,采用单播方式的集群,各节点都配置相同的几个节点列表作为router
即可。
集群中节点数量没有限制,一般大于等于2个节点就可以看做是集群了。一般处于高性能及高可用方面来考虑一般
集群中的节点数量都是3个及3个以上。
6.1 集群的相关概念
集群 cluster
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能。一个集群由
一个唯一的名字标识,这个名字默认就是“elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集
群的名字,来加入这个集群
节点 node
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。和集群类似,一
个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的
时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对
应于Elasticsearch集群中的哪些节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫
做“elasticsearch”的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,
它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中。
在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何Elasticsearch节点,
这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
分片和复制 shard&replicas
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任
一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。为了解决这个问题,Elasticsearch提供
了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每
个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。分片很重要,主
要有两方面的原因:1)允许你水平分割/扩展你的内容容量。2)允许你在分片(潜在地,位于多个节点上)之上
进行分布式的、并行的操作,进而提高性能/吞吐量。
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户的你来说,
这些都是透明的。
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因
消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分
片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。
复制之所以重要,有两个主要原因:在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分
片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。扩展你的搜索量/吞吐量,因为搜索可以
在所有的复制上并行运行。总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)
或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分
片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你
事后不能改变分片的数量。
默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节
点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。
6.2集群的搭建
6.2.1准备并修改三台服务器配置
创建elasticsearch-cluster文件夹,在内部复制三个elasticsearch服务
修改elasticsearch-cluster\node*\config\elasticsearch.yml配置文件
node1:
#节点1的配置信息:
#集群名称,保证唯一
cluster.name: my-elasticsearch
#节点名称,必须不一样
node.name: node-1
#必须为本机的ip地址
network.host: 127.0.0.1
#服务端口号,在同一机器下必须不一样
http.port: 9201
#集群间通信端口号,在同一机器下必须不一样
transport.tcp.port: 9301
#设置集群自动发现机器ip集合
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
node2:
#节点2的配置信息:
#集群名称,保证唯一
cluster.name: my-elasticsearch
#节点名称,必须不一样
node.name: node-2
#必须为本机的ip地址
network.host: 127.0.0.1
#服务端口号,在同一机器下必须不一样
http.port: 9202
#集群间通信端口号,在同一机器下必须不一样
transport.tcp.port: 9302
#设置集群自动发现机器ip集合
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
node3:
#节点3的配置信息:
#集群名称,保证唯一
cluster.name: my-elasticsearch
#节点名称,必须不一样
node.name: node-3
#必须为本机的ip地址
network.host: 127.0.0.1
#服务端口号,在同一机器下必须不一样
http.port: 9203
#集群间通信端口号,在同一机器下必须不一样
transport.tcp.port: 9303
#设置集群自动发现机器ip集合
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
6.2.3启动各个节点的服务器
双击elasticsearch-cluster\node*\bin\elasticsearch.bat
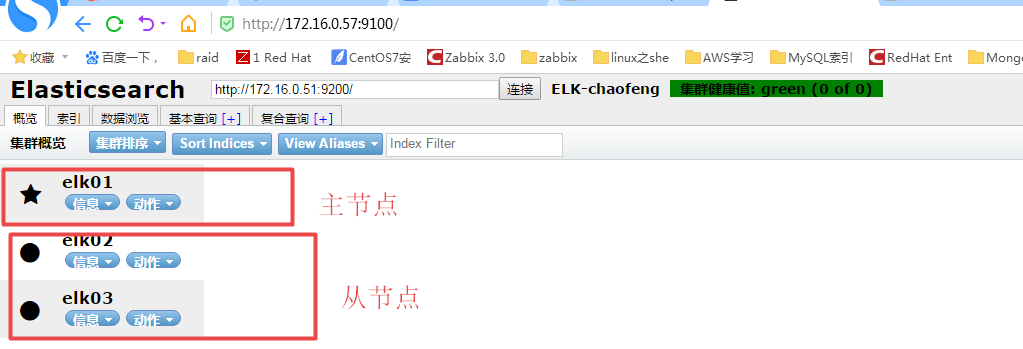
在localhost:9100中:带星号的为主节点 带圆圈的为父节点
连接时连接任意一个即可
6.2.4 集群测试
添加索引和映射
与上面相同
添加文档
与上面相同
使用elasticsearch-head查看集群情况
创建索引后,外框较粗的为主节点
七. ES---java客户端编程操作
es存在三种java客户端
1.Transport Client
2.java low level rest client (低级rest客户端)
3.java high level rest client(高级rest客户端)
区别:
TransportClient没有使用RestFul风格的接口,而是二进制的方式传输数据。
ES官方推出了Java Low Level REST Client,支持Restful。缺点是因为把Transport Client迁移到java low level rest client的工作量过大。
ES官方推出了.java high level rest client,它是基于Java Low Level REST Client的封装,并且API接收参数和返回值和TransportClient是一样的,兼容这两种客户端的优点。建议ES5及以后的版本使用这个。
Transport Client
1 创建工程
导入POM坐标
<dependencies>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>5.6.8</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>5.6.8</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.9.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.24</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.21</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.12</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
2 创建索引Index
- 创建JAVA工程
- 添加jar包,添加maven坐标
- 编写测试方法创建索引库
- 创建Setting对象,相当于一个配置信息,主要配置集群的名称
- 创建一个客户端Client对象
- 使用client对象创建一个索引库
- 关闭client对象
@Test
public void creatIndex() throws Exception{
//创建一个Settings对象
Settings settings=Settings.builder().put("cluster.name","my-elasticsearch").build();
//创建一个客户端Client对象
TransportClient client = new PreBuiltTransportClient(settings);
client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9301));
client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9302));
client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9303));
//使用client对象创建一个索引库
client.admin().indices().prepareCreate("index_hello")
//执行操作
.get();
//关闭client对象
client.close();
}
3 创建映射mapping
- 创建Setting对象,相当于一个配置信息,主要配置集群的名称
- 创建一个客户端Client对象
- 创建一个mapping信息 ,是json数据,可以是字符串,也可以是XContextBuilder对象
- 使用clint向es发送mapping信息
- 关闭client对象
public void creatMapping() throws Exception{
//创建一个Settings对象
Settings settings=Settings.builder().put("cluster.name","my-elasticsearch").build();
//创建一个客户端Client对象
TransportClient client = new PreBuiltTransportClient(settings);
client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9301));
client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9302));
client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9303));
//创建一个mapping信息
XContentBuilder xContentBuilder = XContentFactory.jsonBuilder()
//相当于{
.startObject()
.startObject("article")
.startObject("properties")
.startObject("id")
.field("type","long")
.field("store",true)
.endObject()
.startObject("title")
.field("type","text")
.field("store",true)
.field("analyzer","ik_smart")
.endObject()
.startObject("content")
.field("type","text")
.field("store",true)
.field("analyzer","ik_smart")
.endObject()
.endObject()
.endObject()
.endObject();
//使用client将mapping信息设置到索引库
client.admin().indices()
//设置要做映射的索引
.preparePutMapping("index_hello")
//设置TYPE
.setType("article")
//mapping信息
.setSource(xContentBuilder)
.get();
client.close();
}
4 向索引库添加文档
通过XContentBuilder
- 创建Setting对象,相当于一个配置信息,主要配置集群的名称
- 创建一个客户端Client对象
- 创建一个文档对象 ,是json数据,可以是字符串,也可以是XContextBuilder对象
- 使用clint把文档添加到索引库中
- 关闭client对象
@Test
public void testAddDocument()throws Exception{
//创建文档对象
XContentBuilder xContentBuilder= XContentFactory.jsonBuilder()
.startObject()
.field("id",1l)
.field("title","")
.field("content","")
.endObject();
//添加文档对象
//client.prepareIndex("index_hello","article","1").get();
client.prepareIndex()
.setIndex("index_hello")
.setType("article")
//不设置id会自动生成
.setId("1")
.setSource(xContentBuilder)
.get();
client.close();
}
通过Jackson转换实体
@Test
public void testAddDocument2()throws Exception{
//创建Article对象
Article article=new Article();
article.setId(2l);
article.setTitle("奥特曼");
article.setContent("奥特曼系列(日语:ウルトラマンシリーズ),是日本“特摄之神”的圆谷英二导演一手创办的“圆谷制作公司”(円谷プロダクション,原名:圆谷株式会社)所拍摄的作品,自二十世纪六十年代起推出的空想特摄系列电视剧。");
//把article转换为json对象
ObjectMapper objectMapper=new ObjectMapper();
String jsonstr = objectMapper.writeValueAsString(article);
System.out.println(jsonstr);
//添加文档对象;
client.prepareIndex("index_hello","article","2")
.setSource(jsonstr, XContentType.JSON)
.get();
client.close();
}
5 实现搜索
查询步骤
- 创建client对象
- 创建查询对象,QueryBuilders工具类创建QueryBuilder对象
- 使用client执行查询
- 得到查询的结果
- 取得查询结果的总记录数
- 取查询结果列表
- 关闭client对象
根据id查询
@Test
public void testQueryByid()throws Exception{
//创建查询对象
QueryBuilder queryBuilder = QueryBuilders.idsQuery().addIds("1","2");
//执行查询
SearchResponse searchResponse = client.prepareSearch("index_hello")
.setTypes("article")
.setQuery(queryBuilder)
.get();
//取查询结果
SearchHits searchHits = searchResponse.getHits();
//取总记录数
System.out.println(searchHits.getTotalHits());
//取结果列表
Iterator<SearchHit> iterator = searchHits.iterator();
while (iterator.hasNext()){
SearchHit searchHit = iterator.next();
//打印整个文档
System.out.println(searchHit.getSourceAsString());
//取文档的属性
Map<String, Object> document = searchHit.getSource();
System.out.println(document.get("id"));
System.out.println(document.get("title"));
System.out.println(document.get("content"));
}
//关闭client
client.close();
}
根据Term查询
@Test
public void testQueryByTerm()throws Exception{
//创建查询对象
//参数一要搜索的字段
// 参数二要搜索的关键词
QueryBuilder queryBuilder = QueryBuilders.termQuery("title","奥特曼");
//执行查询
search(queryBuilder);
//关闭client
client.close();
}
根据QueryString查询(带分析的查询)
@Test
public void testQueryByQueryString()throws Exception{
//创建查询对象
//参数一要搜索的字段
// 参数二要搜索的关键词
QueryBuilder queryBuilder = QueryBuilders.queryStringQuery("奥特曼").defaultField("title");
//执行查询
search(queryBuilder);
//关闭client
client.close();
}
6 查询文档分页
SearchResponse searchResponse = client.prepareSearch("index_hello")
.setTypes("article")
.setQuery(queryBuilder)
//设置起始行号,从0开始
.setFrom(0)
//每页显示的行数
.setSize(5)
.get();
7 查询结果高亮显示
- 设置高亮显示的字段
- 设置高亮显示的前缀
- 设置高亮显示的后缀
- 在client执行查询前,设置高亮显示信息
- 遍历结果列表时可以从结果中取高亮结果
HighlightBuilder highlightBuilder=new HighlightBuilder();
highlightBuilder.field("title");
highlightBuilder.preTags("<em>");
highlightBuilder.postTags("</em>");
SearchResponse searchResponse = client.prepareSearch("index_hello")
.setTypes("article")
.setQuery(queryBuilder)
//设置起始行号
.setFrom(0)
//每页显示的行数
.setSize(5)
.highlighter(highlightBuilder)
.get();
java Rest 客户端(高级客户端)
1.入门
Java高级REST客户端需要Java 1.8,并依赖于Elasticsearch核心项目。客户端版本与为其开发客户端的Elasticsearch版本相同。
RestHighLevelClient构建
一个RestHighLevelClient 实例需要REST low-level client builder 去构建
RestHighLevelClient client = new RestHighLevelClient(RestClient.Builder(
new HttpHost("localhost", 9200, "http"),
new HttpHost("localhost", 9201, "http")));
高级客户端将基于提供的构建器在内部创建用于执行请求的低级客户端。该低级客户端维护着一个连接池并启动了一些线程,因此您应该在完全正确地使用高级客户端后关闭它,这反过来又将关闭内部低级客户端以释放这些资源。
1 新增和修改数据
插入单条数据:
HttpHost:url地址封装
RestClientBuilder:rest客户端构建器
RestHighLevelClient:rest高级客户端
IndexRequest:新增或修改请求
IndexResponse:新增或修改的响应结果
public static void main(String[] args) throws IOException {
// 连接rest接口
//参数 :地址,端口,协议
HttpHost httpHost = new HttpHost("127.0.0.1",9200,"http");
RestClientBuilder restClientBuilder =RestClient.builder(httpHost);//rest构建器
RestHighLevelClient restHighLevelClient =new RestHighLevelClient(restClientBuilder);//高级客户端对象
//封装请求对象
IndexRequest indexRequest=new IndexRequest("sku","doc","3");//索引名称 类型 id
Map skuMap =new HashMap();
skuMap.put("name","华为");
skuMap.put("price",10101);
skuMap.put("尺寸","5");
indexRequest.source(skuMap);
//获取执行结果
IndexResponse response = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
int status = response.status().getStatus();
System.out.println(status);
restHighLevelClient.close();
}
批处理:在上面代码上稍作修改
BulkRequest:批量请求
BulkResponse:批量请求
public static void main(String[] args) throws IOException {
// 连接rest接口
//参数 :地址,端口,协议
HttpHost httpHost = new HttpHost("127.0.0.1",9200,"http");
RestClientBuilder restClientBuilder =RestClient.builder(httpHost);//rest构建器
RestHighLevelClient restHighLevelClient =new RestHighLevelClient(restClientBuilder);//高级客户端对象
//封装请求对象
BulkRequest bulkRequest =new BulkRequest();//批量
//可循环
IndexRequest indexRequest=new IndexRequest("sku","doc","5");//索引名称 类型 id
Map skuMap =new HashMap();
skuMap.put("name","华为mate 20 pro");
skuMap.put("price",10101);
skuMap.put("尺寸","5");
indexRequest.source(skuMap);
//循环结束
bulkRequest.add(indexRequest);
//获取执行结果
//IndexResponse response = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
BulkResponse bulkResponse = restHighLevelClient.bulk(bulkRequest,RequestOptions.DEFAULT);
int status = bulkResponse.status().getStatus();
System.out.println(status);
restHighLevelClient.close();
}
2 匹配查询
SearchRequest:查询请求对象
SearchResponse:查询响应对象
SearchSourceBuilder:查询源构建器
MatchQueryBuilder:匹配查询构建器
public static void main(String[] args) throws IOException {
// 连接rest接口
//参数 :地址,端口,协议
HttpHost httpHost = new HttpHost("127.0.0.1",9200,"http");
RestClientBuilder restClientBuilder = RestClient.builder(httpHost);//rest构建器
RestHighLevelClient restHighLevelClient =new RestHighLevelClient(restClientBuilder);//高级客户端对象
//封装查询请求
SearchRequest searchRequest =new SearchRequest("sku");
searchRequest.types("doc");//设置查询类型,可以不设置查询全部
SearchSourceBuilder searchSourceBuilder =new SearchSourceBuilder();//相当于query
MatchQueryBuilder queryBuilder = QueryBuilders.matchQuery("name","手机");
searchSourceBuilder.query(queryBuilder);
searchRequest.source(searchSourceBuilder);
//获取查询结果
SearchResponse searchResponse =restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits =searchResponse.getHits();
long totalHits = searchHits.getTotalHits();
System.out.println("记录数"+totalHits);
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit:hits) {
String source = hit.getSourceAsString();
System.out.println(source);
}
restHighLevelClient.close();
}
3 布尔和词条查询
BoolQueryBuilder:布尔查询构建器
TermQueryBuilder:词条查询构建器
QueryBuilders:查询构建器工厂
//封装查询请求
SearchRequest searchRequest = new SearchRequest("sku");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();//布尔查询构建器
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("name","手机");//第一个条件
boolQueryBuilder.must(matchQueryBuilder);
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("price",8000);//第二个条件
boolQueryBuilder.must(termQueryBuilder);
searchSourceBuilder.query(boolQueryBuilder);
searchRequest.source(searchSourceBuilder);
4 过滤查询
与bool查询类似,只是must连接改为filter连接
//封装查询请求
SearchRequest searchRequest = new SearchRequest("sku");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();//布尔查询构建器
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("price",8000);//第二个条件
boolQueryBuilder.filter(termQueryBuilder);
searchSourceBuilder.query(boolQueryBuilder);
searchRequest.source(searchSourceBuilder);
5 分组(聚合)查询
AggregationBuilders:集合构建器工厂
TermAggregationBuilder:词条聚合构建器
Aggregations:分组结果封装
Terms.Bucket:桶
//连接rest接口
HttpHost httpHost = new HttpHost("127.0.0.1",9200,"http");
RestClientBuilder restClientBuilder = RestClient.builder(httpHost);//rest构建器
RestHighLevelClient restHighLevelClient =new RestHighLevelClient(restClientBuilder);
//封装查询请求
SearchRequest searchRequest = new SearchRequest("sku");
searchRequest.types("doc");
SearchSourceBuilder builder = new SearchSourceBuilder();
TermsAggregationBuilder termBuilder= AggregationBuilders.terms("sku_category").field("categoryName");
builder.aggregation(termBuilder);
builder.size(0);
searchRequest.source(builder);
//获取查询结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest,
RequestOptions.DEFAULT);
Aggregations aggregations = searchResponse.getAggregations();
Map<String, Aggregation> asMap = aggregations.getAsMap();
Terms terms = (Terms) asMap.get("sku_category");
List<? extends Terms.Bucket> buckets = terms.getBuckets();
for(Terms.Bucket bucket:buckets){
System.out.println(bucket.getKeyAsString()+":"+ bucket.getDocCount()
);
restHighLevelClient.close();

 浙公网安备 33010602011771号
浙公网安备 33010602011771号