

Oracle常见的表连接的方法
1 排序合并连接SMJ
Sort merge join
排序合并总结:
1 通常情况下,排序合并连接的效率远不如hash join,前者适用范围更广,hj只使用于等值连接,smj范围更广(<,>,>=,<=)
2 通常情况下,smj并不适合OLTP系统,排序操作是非常昂贵的操作,
2 嵌套循环连接NL
优化器会根据一定的规则来确定表T1,T2谁是驱动表,谁是被驱动表,驱动表用于外层循环,被驱动表用于内存循环,这里假设驱动表时T1,被驱动表时T2
目标sql中指定的谓词条件去访问T1,得到的结果集为1
然后遍历驱动结果集1同时遍历被驱动表T2,即先取出1中的第一条记录,接着遍历T2并按照条件去判断T2中是否存在配匹的记录,然后在取出1中的第二条记录。。。。
嵌套循环总结:
1 如果t1对应的驱动结果集较少,同时t2的连接列上又有唯一性索引,则效率会很高
2 只要驱动结果集很少就具备嵌套循环的前提条件
3 嵌套循环可以实现快速响应,即可以第一时间返回经过连接且满足条件的记录,而不必等待所有的连接操作全部做完才返回连接结果
如果使用了nl连接,并且t2的连接列上index,那么oracle访问该index是通常会使用单块读,则t1的返回n条结果,就会是t2访问该index n次,如果要回表,
则会回表n次,这就使得不在index 或者data buffer cache中的数据,发生物理I/O,
Oracle 11g使用了向量I/O,提高nl的连接效率
nested loop
outer table --驱动表
inner table
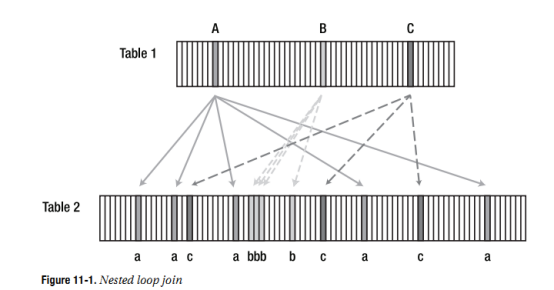
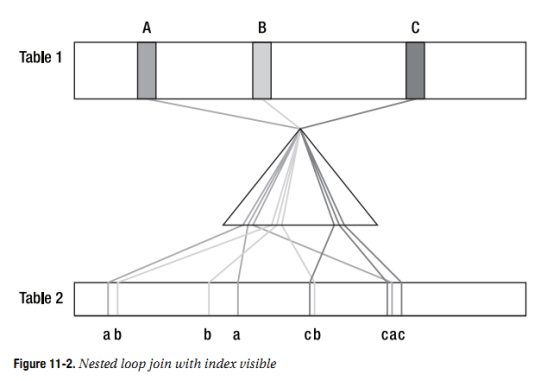
The second picture, shown in Figure 11-2, includes a representation of working through
an index on the second table, because an index is usually involved in this way when there is a
nested loop around.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 | 例create table t1 (col1 number, col2 varchar2(1));create table t2 (col2 varchar2(1), col3 varchar2(2));insert into t1 values(1,'A');insert into t1 values(2,'B');insert into t1 values(3,'C');insert into t2 values('A','A1');insert into t2 values('B','B1');insert into t2 values('D','D1');Connected to:Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - 64bit ProductionWith the Partitioning, OLAP and Data Mining optionsSQL> set linesize 1000SQL> set pagesize 1000SQL> set timing onSQL> set autot trace onlySP2-0158: unknown SET option "only"SQL> set autotrace traceonly;SQL> select t1.col1,t1.col2,t2.col3 2 from t1,t2 3 where t1.col2=t2.col2;Elapsed: 00:00:00.04Execution Plan----------------------------------------------------------Plan hash value: 2253255382--------------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |--------------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 3 | 60 | 4 (0)| 00:00:01 || 1 | TABLE ACCESS BY INDEX ROWID| T2 | 1 | 5 | 1 (0)| 00:00:01 || 2 | NESTED LOOPS | | 3 | 60 | 4 (0)| 00:00:01 || 3 | TABLE ACCESS FULL | T1 | 3 | 45 | 3 (0)| 00:00:01 ||* 4 | INDEX RANGE SCAN | IDX_T2 | 1 | | 0 (0)| 00:00:01 |--------------------------------------------------------------------------------------Predicate Information (identified by operation id):--------------------------------------------------- 4 - access("T1"."COL2"="T2"."COL2")Note----- - dynamic sampling used for this statementStatistics---------------------------------------------------------- 0 recursive calls 0 db block gets 13 consistent gets 0 physical reads 0 redo size 469 bytes sent via SQL*Net to client 337 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 2 rows processed |
3 哈希连接HJ
哈希连接是两个表在做连接时只要依靠哈希运算来得到结果集(仅适合CBO),在解析目标sql 时是否考虑哈希连接受限制与隐含参数(_HASH_JOIN_ENABLED),
默认值TRUE,如果值为false,强制使用hint,也是会走hj的
1 oracle会根据参数HASH_AREA_SIZE,DB_BLOCK_SIZE,_HASH_MULTIBLOCK_IO_COUNT来决定hash partition的数量,所有hash partition的集合称为Hash table,
2 表t1,t2在目标sql中的谓词条件后,得到结果集中的数据量较少的那个结果集会被oracle选为哈希连接的驱动结果集,假设t1的结果集1较少(驱动结果集),t2的结果2(被驱动结果集)
3 oracle会遍历结果集1,读取1中的每一条记录,并对每一条记录按照该记录t1中的连接列做哈希运算,
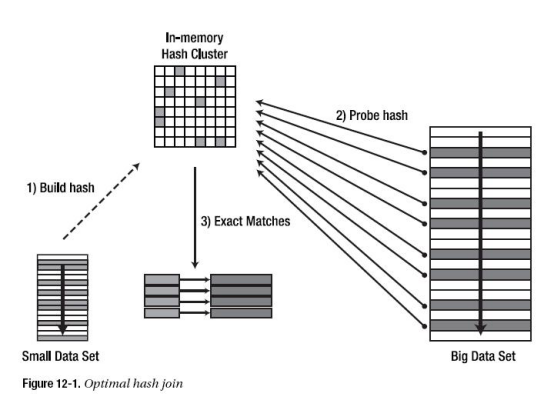
--小表在数据在指定谓词后做哈希运算放入pga中(超过放入temp),大表数据按照连接列做哈希运算,然后大表去配匹pga中的值,遍历完为止
哈希连接的优缺点:
1 哈希连接不一定会排序,大多数情况下不需要排序
2 哈希连接的驱动表所对应的连接列的可选择性尽可能的好,会影响hash bucket中的记录数,哈希连接中,遍历hash bucket的动作发生在pga工作区中,不消耗逻辑读,
3 哈希连接适用于CBO,等值连接
4 哈希连接适合大表跟小表的连接,2个表做哈希连接,在指定了谓词后的sql中得到的数量较少的结果集所对应的hash table能完全容纳在pga中,则效率会很高。

SQL> select /*+ leading (t1) use_hash(t2) */ 2 t1.col1,t1.col2,t2.col3 3 from t1,t2 4 where t1.col2=t2.col2; Elapsed: 00:00:00.25 Execution Plan ---------------------------------------------------------- Plan hash value: 1838229974 --------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 3 | 60 | 7 (15)| 00:00:01 | |* 1 | HASH JOIN | | 3 | 60 | 7 (15)| 00:00:01 | | 2 | TABLE ACCESS FULL| T1 | 3 | 45 | 3 (0)| 00:00:01 | | 3 | TABLE ACCESS FULL| T2 | 3 | 15 | 3 (0)| 00:00:01 | --------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - access("T1"."COL2"="T2"."COL2") Note ----- - dynamic sampling used for this statement Statistics ---------------------------------------------------------- 7 recursive calls 0 db block gets 32 consistent gets 0 physical reads 0 redo size 469 bytes sent via SQL*Net to client 337 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 2 sorts (memory) 0 sorts (disk) 2 rows processed
4笛卡尔连接cross join
2个表在做连接是,没有指定任何连接条件的连接
SQL> select 2 t1.col1,t1.col2,t2.col3 3 from t1,t2; 9 rows selected. Elapsed: 00:00:00.03 Execution Plan ---------------------------------------------------------- Plan hash value: 787647388 ----------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ----------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 9 | 162 | 8 (0)| 00:00:01 | | 1 | MERGE JOIN CARTESIAN| | 9 | 162 | 8 (0)| 00:00:01 | | 2 | TABLE ACCESS FULL | T1 | 3 | 45 | 3 (0)| 00:00:01 | | 3 | BUFFER SORT | | 3 | 9 | 5 (0)| 00:00:01 | | 4 | TABLE ACCESS FULL | T2 | 3 | 9 | 2 (0)| 00:00:01 | -----------------------------------------------------------------------------
5 反连接Anti join
做子查询展开时,oracle会经常把那些外部where条件为 no exists,not in ,<>all的子查询转换成对应的反连接
SQL> select * from t1 2 where t1.col2 not in (select col2 from t2); Elapsed: 00:00:00.01 Execution Plan ---------------------------------------------------------- Plan hash value: 895956251 --------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 15 | 5 (0)| 00:00:01 | |* 1 | FILTER | | | | | | | 2 | TABLE ACCESS FULL| T1 | 3 | 45 | 3 (0)| 00:00:01 | |* 3 | TABLE ACCESS FULL| T2 | 3 | 6 | 2 (0)| 00:00:01 | --------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter( NOT EXISTS (SELECT /*+ */ 0 FROM "T2" "T2" WHERE LNNVL("COL2"<>:B1))) 3 - filter(LNNVL("COL2"<>:B1)) SQL> select * from t1 2 where not exists (select 1 from t2 where t1.col2=t2.col2); Elapsed: 00:00:00.01 Execution Plan ---------------------------------------------------------- Plan hash value: 1534930707 ----------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ----------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 17 | 3 (0)| 00:00:01 | | 1 | NESTED LOOPS ANTI | | 1 | 17 | 3 (0)| 00:00:01 | | 2 | TABLE ACCESS FULL| T1 | 3 | 45 | 3 (0)| 00:00:01 | |* 3 | INDEX RANGE SCAN | IDX_T2 | 3 | 6 | 0 (0)| 00:00:01 | ----------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 3 - access("T1"."COL2"="T2"."COL2") alter session set "_optimizer_null_aware_antijoin"=false
6 半连接semi join
半连接跟普通的连接不同,半连接会去重?
对子查询展开,exists,in等
SQL> select * from t1 2 where t1.col2 in (select col2 from t2); Elapsed: 00:00:00.01 Execution Plan ---------------------------------------------------------- Plan hash value: 3783859632 ----------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ----------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 3 | 51 | 3 (0)| 00:00:01 | | 1 | NESTED LOOPS SEMI | | 3 | 51 | 3 (0)| 00:00:01 | | 2 | TABLE ACCESS FULL| T1 | 3 | 45 | 3 (0)| 00:00:01 | |* 3 | INDEX RANGE SCAN | IDX_T2 | 3 | 6 | 0 (0)| 00:00:01 | ----------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 3 - access("T1"."COL2"="COL2") SQL> select * from t1 2 where exists (select 1 from t2 where t1.col2=t2.col2); Elapsed: 00:00:00.01 Execution Plan ---------------------------------------------------------- Plan hash value: 3783859632 ----------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ----------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 3 | 51 | 3 (0)| 00:00:01 | | 1 | NESTED LOOPS SEMI | | 3 | 51 | 3 (0)| 00:00:01 | | 2 | TABLE ACCESS FULL| T1 | 3 | 45 | 3 (0)| 00:00:01 | |* 3 | INDEX RANGE SCAN | IDX_T2 | 3 | 6 | 0 (0)| 00:00:01 | ----------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 3 - access("T1"."COL2"="T2"."COL2")
总结一下
- 在哪种情况下用哪种连接方法比较好:
A)排序合并连接(Sort Merge Join, SMJ):
a) 对于非等值连接,这种连接方式的效率是比较高的。
b) 如果在关联的列上都有索引,效果更好。
c) 对于将2个较大的表源做连接,该连接方法比NL连接要好一些。
B)嵌套循环(Nested Loops, NL):
a) 如果驱动表(外部表)比较小,并且在被驱动表(内部表)上有唯一索引,或有高选择性非唯一索引时,使用这种方法可以得到较好的效率。
b)嵌套循环连接有其它连接方法没有的的一个优点是:可以先返回已经连接的行,而不必等待所有的连接操作处理完才返回数据,这可以实现快速的响应时间。
C)哈希连接(Hash Join, HJ):
a) 这种方法是在oracle7后来引入的,使用了比较先进的连接理论,一般来说,其效率应该好于其它2种连接,但是这种连接只能用在CBO优化器中,
而且需要设置合适的hash_area_size参数,才能取得较好的性能。
b) 在2个较大的表源之间连接时会取得相对较好的效率,在一个表源较小时则能取得更好的效率。
c) 只能用于等值连接中


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构