爬取博客园新闻版块里的新闻
Log
2023-11-02 文章发布
2024-11-26 相同功能的脚本发布,欢迎试玩
爬取数据
import requests
from bs4 import BeautifulSoup
from multiprocessing import Pool
import sqlite3
import time
from tqdm import tqdm
import collections
your_cookie = "your_cookie"
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Cache-Control': 'max-age=0',
# 'Referer': 'https://news.cnblogs.com/n/104394/',
'Sec-Ch-Ua': '"Microsoft Edge";v="117", "Not;A=Brand";v="8", "Chromium";v="117"',
'Sec-Ch-Ua-Mobile': '?0',
'Sec-Ch-Ua-Platform': '"Windows"',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.31',
'Cookie': your_cookie
}
def get_news_info(news_id):
url = f"https://news.cnblogs.com/n/{news_id}/"
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
news_title_div = soup.find('div', {'id': 'news_title'})
news_info_div = soup.find('div', {'id': 'news_info'})
if news_title_div and news_title_div.a:
title = news_title_div.a.text
else:
title = 'Not Found'
if news_info_div:
# print(f"{str(news_info_div)=}")
time_span = news_info_div.find('span', {'class': 'time'})
view_span = news_info_div.find('span', {'class': 'view', 'id': 'News_TotalView'})
if time_span:
time_text = time_span.text.strip()
# \.split(' ')[1]
else:
time_text = 'Not Found'
if view_span:
view_text = view_span.text
else:
view_text = 'Not Found'
else:
time_text = 'Not Found'
view_text = 'Not Found'
news_body = 'Not Found'
news_body_div = soup.find('div', {'id': 'news_body'})
if news_body_div:
news_body = str(news_body_div)
else:
news_body = 'Not Found'
return {
'news_id': news_id,
'title': title,
'time': time_text,
'views': view_text,
'news_body': news_body,
'url': url,
}
def save_to_db(news_info, filename):
conn = sqlite3.connect(f'news_{filename}.db')
c = conn.cursor()
c.execute('''CREATE TABLE IF NOT EXISTS news
(news_id INT PRIMARY KEY, title TEXT, time TEXT, views TEXT, news_body TEXT, url TEXT)''')
c.execute('''INSERT INTO news VALUES (?,?,?,?,?,?)''',
(news_info['news_id'], news_info['title'], news_info['time'], news_info['views'], news_info['news_body'],
news_info['url']))
conn.commit()
conn.close()
# 定义一个 namedtuple 来存储你的列名和数据
News = collections.namedtuple('News', ['news_id', 'title', 'time', 'views', 'news_body', 'url'])
# 数据落盘,数据保存到sqlite数据库
def save_to_db_using_namedtuple(news_info, filename):
news = News(**news_info)
conn = sqlite3.connect(f'news_{filename}.db')
c = conn.cursor()
c.execute(f'''
CREATE TABLE IF NOT EXISTS news
({', '.join(f'{field} TEXT' for field in News._fields)})
''')
c.execute(f'''
INSERT INTO news ({', '.join(News._fields)})
VALUES ({', '.join('?' for _ in News._fields)})
''', news)
conn.commit()
conn.close()
if __name__ == '__main__':
with Pool(20) as p: # Number of parallel processes
new_id_start = 753006 - 2000
new_id_end = 753006
news_ids = list(range(new_id_start, new_id_end))
# new_id_start=41104
# new_id_end=0
# news_ids = list(range(new_id_start,new_id_end,-1))
start = time.time()
for news_info in tqdm(p.imap_unordered(get_news_info, news_ids), total=len(news_ids)):
save_to_db_using_namedtuple(news_info=news_info, filename=f"{new_id_start}~{new_id_end}")
end = time.time()
print(f'Time taken: {end - start} seconds')
## https://zzk.cnblogs.com/s?Keywords=facebook&datetimerange=Customer&from=2010-10-01&to=2010-11-01 也可以用博客园的找找看
数据展示
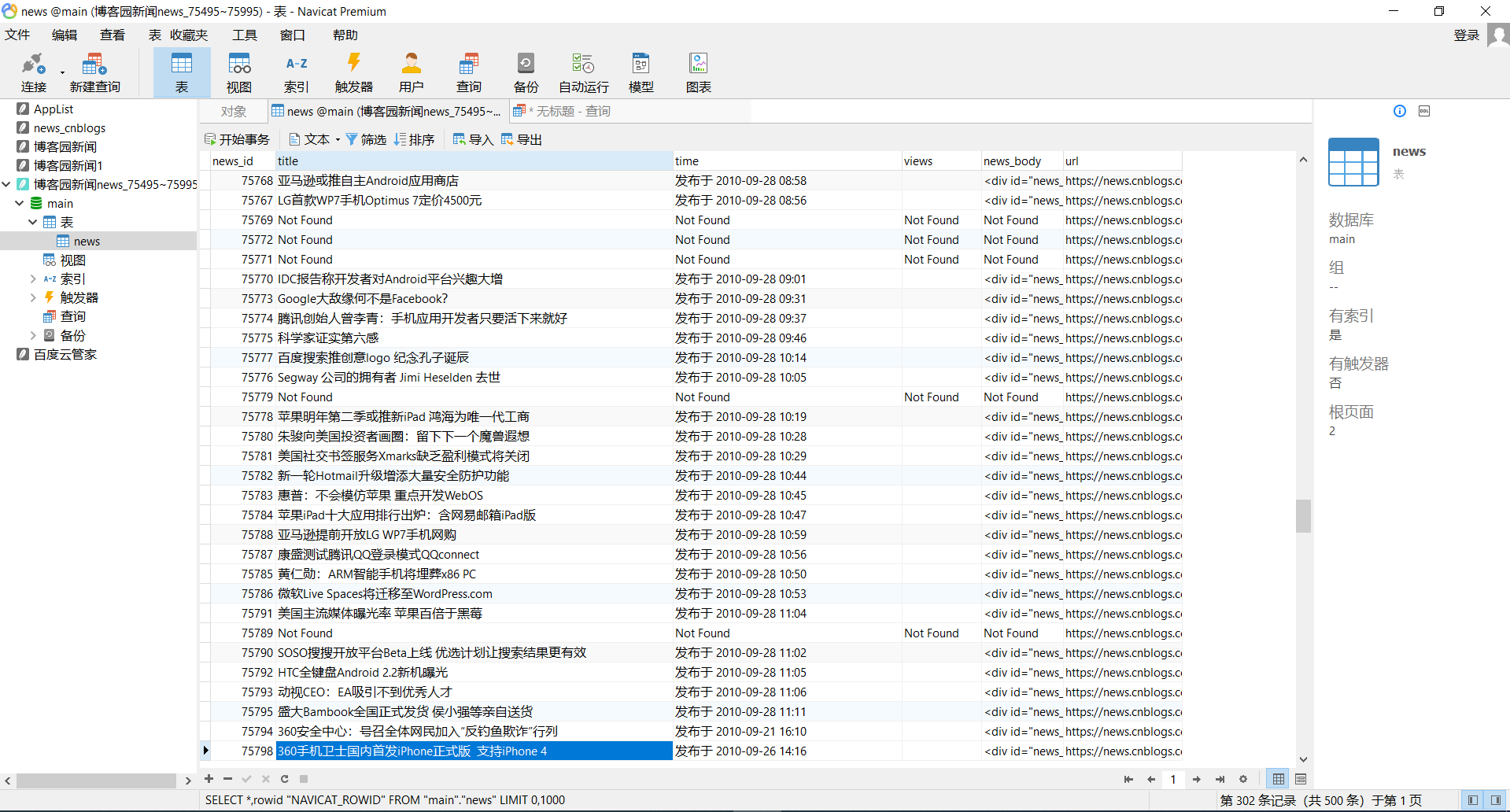

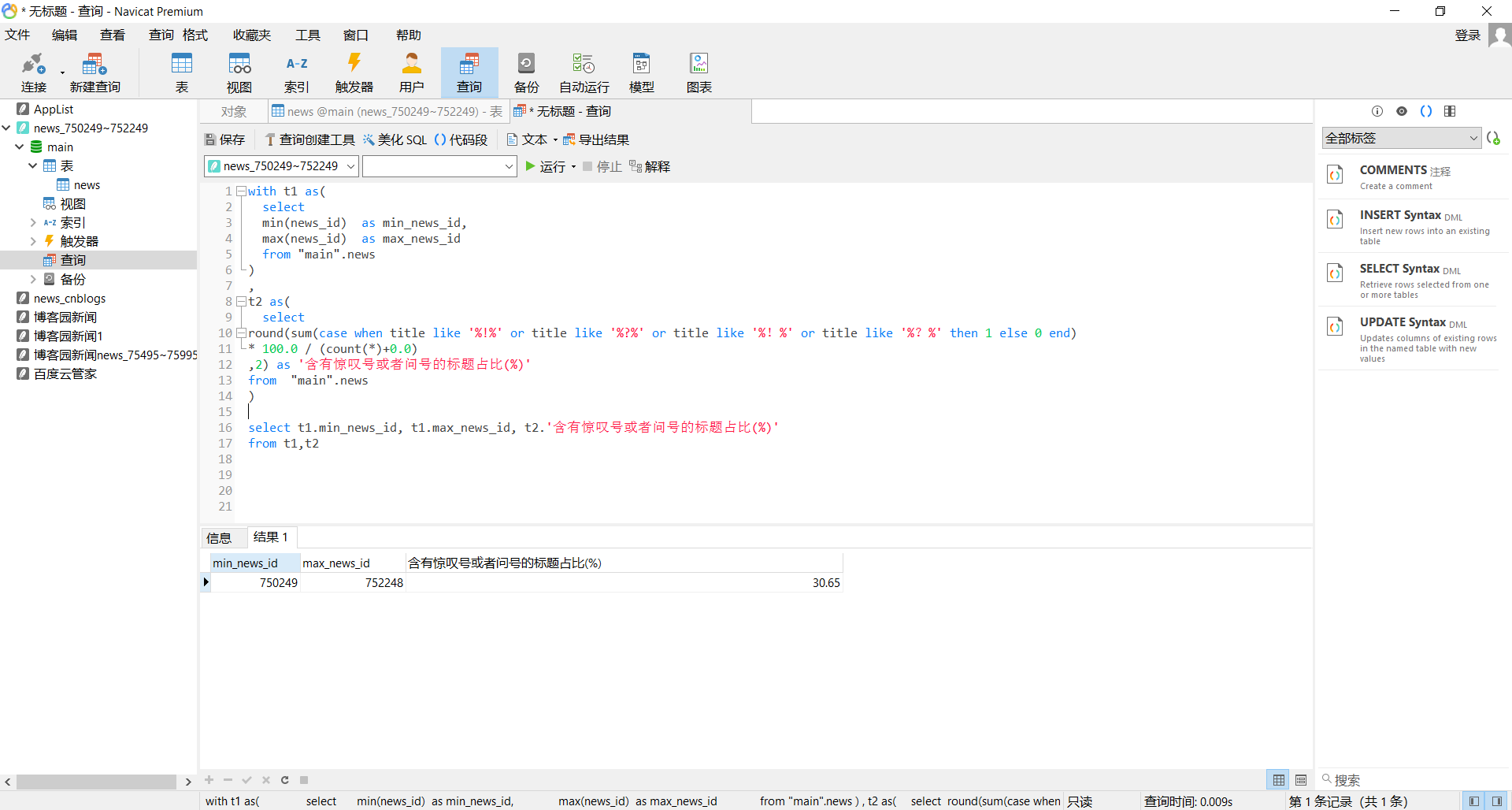
后面可以考虑:洗数据,数据挖掘之类的。
制作词云
小教训,可以直接传文本进去generate_from_text。传频次表的话,频次表里不要出现换行符'\n'
import sqlite3
import pandas as pd
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from html.parser import HTMLParser
import jieba
jieba.setLogLevel(jieba.logging.INFO)
# 连接到SQLite数据库
conn = sqlite3.connect('news_79573~0.db')
# 从news表中读取数据
df = pd.read_sql_query("SELECT * from news", conn)
# 关闭数据库连接
conn.close()
# 创建一个HTML解析器来清洗news_body字段中的HTML标签
class MyHTMLParser(HTMLParser):
def __init__(self):
super().__init__()
self.text = []
def handle_data(self, data):
self.text.append(data)
def get_text(self):
return ''.join(self.text)
# 清洗news_body字段中的HTML标签
def clean_html(html):
parser = MyHTMLParser()
parser.feed(html)
return parser.get_text()
df['news_body'] = df['news_body'].apply(clean_html)
# 将time字段转换为日期类型,并提取出年月信息
df['time'] = pd.to_datetime(df['time'], format="发布于 %Y-%m-%d %H:%M", errors='coerce')
df['year_month'] = df['time'].dt.to_period('M')
# 将title和news_body字段合并
df['text'] = df['title'] + ' ' + df['news_body']
# 对每个月的数据进行分词和词云生成
grouped = df.groupby('year_month')
for name, group in grouped:
text = ' '.join(group['text'].tolist())
wordcloud = WordCloud(font_path='msyh.ttc').generate_from_text(text)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.title(name)
plt.show()
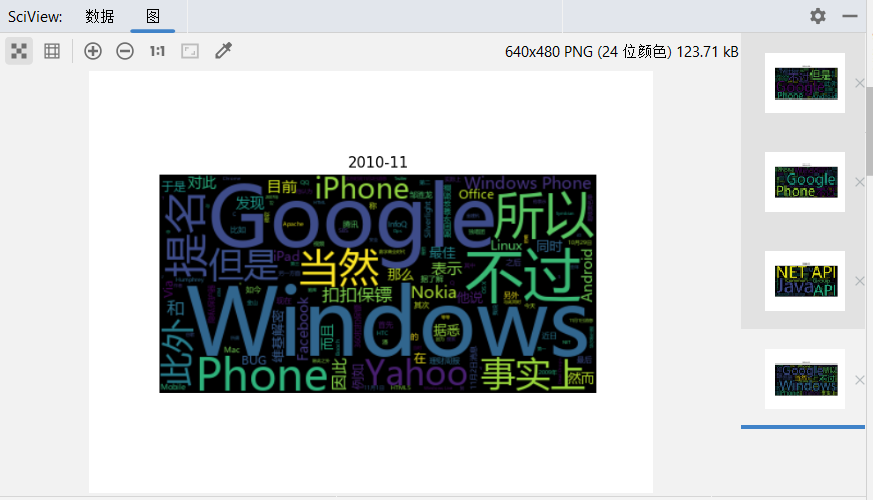
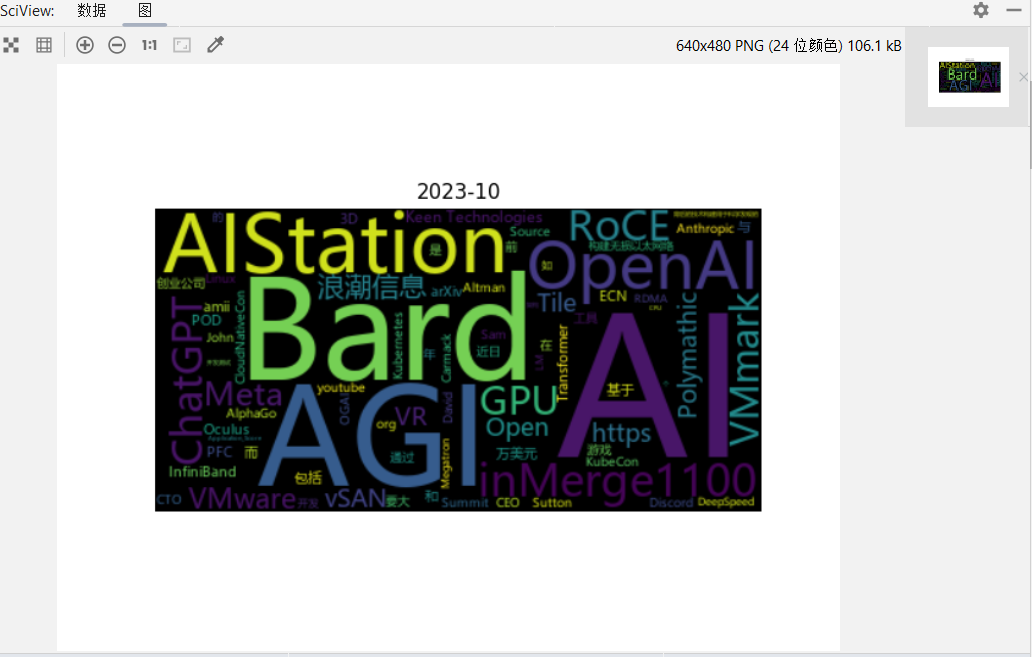
彩蛋
https://news.cnblogs.com/n/79573/ 最早的好像是2006年11月的这篇"是否能让JAVA和.NET框架共存?"的新闻

 浙公网安备 33010602011771号
浙公网安备 33010602011771号