Flink SQL学习笔记
Flink非常灵活
对于同一个需求
你可以拿Table API写
也能拿SQL 写
甚至可以混搭
参考
https://www.bilibili.com/video/BV12k4y1z7LM?p=2
什么是TableEnvironment
TableEnvironment是Flink中集成Table API和SQL的一个概念,所有对表的操作都是基于它:
注册Catalog
之后在Catalog中注册表
执行SQL查询
注册用户自定义函数 UDF
Table 由 Catalog名,数据库名,对象名 联合起来作为唯一标识
Fink的 表查询 基本的程序结构
val tableEnv = ... //创建表的执行环境
//创建一张表,用于读取数据
tableEnv.connect(...).createTemporaryTable("inputTAble")
//注册一张表,用于把计算结果输出
tableEnv.connect(...)
.withFormat(...) //定义数据格式化方法
.withSchema(...) //定义表结构
.createTemporaryTable("outputTable")
//通过Table API 查询算子,得到一张结果表
val result = tableEnv.from("inputTable").select(...)
//通过SQL查询语句,得到一张结果表
val sqlResult = tableEnv.sqlQuery("SELECT ... FROM inputTable ...")
//将结果表写入输出表中
result.insertInto("outputTable")
创建表
// 读取文件数据
val filePath = "D://to/path"
tableEnv.connect(new FileSystem.path(filePath))
.withFormat( new OldCsv()) //反序列化
.withSchema (new Schema()
.field("id",DataTypes.STRING())
.field("timestamp",DataTypes.DOUBLE())
.field("temperature",DataTypes.DOUBLE())
)
.createTemporaryTable("inputTable")
// 测试输出
val inputTable: Table = tableEnv.from("inputTable")
inputTable.toAppendStream[(String,Long,Double)].print()
env.execute("table api test job")
// 消费kafka数据
tableEnv.connect(new Kafka()
.version("0.11")
.topic("sensor")
.property("zookeeper.connect","localhost:2181")
.property("bootstrap.servers","localhost:9092")
)
.withFormat(...)
.withSchema(...)
.createTemporaryTable("kafkaInputTable")
表的查询转换
//表的查询转换
val sensorTable: Table = tableEnv.from("inputTable")
val resultTable: Table = sensorTable
.select('id,'temperature) //一个单引号是scala特性
.filter('id === "sensor_1" )
var aggResultTable :Table = sensorTable
.groupBy('id)
.select('id,'id.count as 'count)
//测试输出
aggResultTable.toRetractStream(String,Long).print("agg result")
表和流的相互转换
//流转换成表 前面已经有叙述
val dataStream: DataStream[SensorReading] = ...
//表转换成流: (几乎不要指定Schema和Format,也可以一一指定)
val sensorTable: Table = tableEnv.fromDataStream(dataStream)
表的输出——将数据写入TableSink来实现表的输出
更新模式
对于流式查询,需要声明如何在表和外部连接器之间执行转换
与外部系统交换消息类型,由 更新模式 来指定
更新模式有下面3种:
Append 追加模式
Retract 撤回模式
Upsert 更新输入模式

Flink中的窗口
时间语义,要配合窗口操作才能发挥作用
在Table API 和SQL中,主要有2种窗口:
Group Windows 根据时间或计数间隔,将行聚合到有限的Group中,并对每个组的数据执行一次聚合函数
Over Windows 针对每个输入行,计算相邻行范围内的聚合
GroupWindow
形如
// 原理见这张照片 https://img2020.cnblogs.com/blog/1943228/202109/1943228-20210904203721272-1657808652.png
val table = input
.window([w: GroupWindow] as 'w) //定义窗口,别名为w
.groupBy('w,'a) //按照字段a和窗口w分组
.select('a,'b.sum) //聚合
OverWindow
形如
val table = input
.window([w: OverWindow] as 'w)
.select('a ,'b.sum over 'w, 'c.min over 'w) //OverWindow聚合在标准SQL中已经集成
也可以在SQL语句中用Window
比如
SELECT COUNT(amount) OVER(
PARTITION BY user
ORDER BY proctime
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW)
FROM Orders
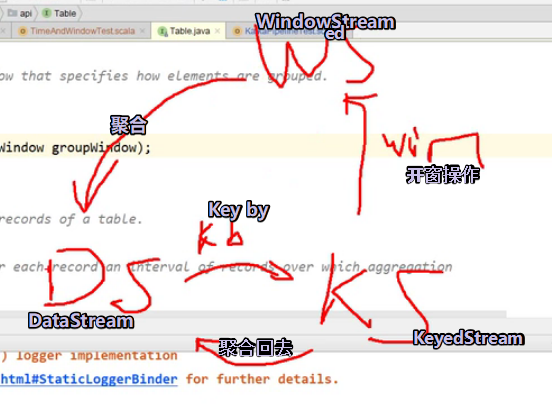
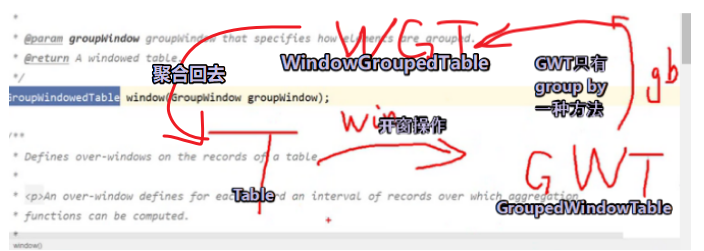
表和流和其他相互转换 灵魂画手!
UDF 用户自定义函数之标量函数
用户自定义的标量函数,可以将0,1或多个标量值,映射到新的标量值
为了定义标量函数,必须在org.apache.flink.table.functions中扩展基类
比如
class HashCode(factor: Int) extends ScalarFunction{
def eval(s:String): Int ={
s.hashCode *factor
}
}
UDF 用户自定义函数之表函数
例如
class Split(separator: String) extends TableFunction[(String,Int)]{
def eval(str: String): Unit = {
word => collect((word,word.length)) //元组
)
}
}
UDF 用户自定义函数之 聚合函数 UDAGGS
可以把一个表的数据,聚合成一个标量值
是通过继承AggregationFunction抽象类实现的
必须要实现的方法有
createAccumator()
accumulate()
getValue()
工作原理如下:
首先,它需要一个累加器Accumulator,用来保存聚合中间结果的数据结构;可以通过createAccumulator()方法创建空累加器。
随后,对每个输入行调用函数的accumulate()方法来更新累加器
处理后所有行后,将调用函数的getValue()方法并计算返回最终结果。
例如
UDF 用户自定义函数之 表聚合函数 UDTAGGs
可以把一个表中数据,聚合为具有多行和多列的结果表
UDTAGGs是通过继承TableAggregateFunction抽象类来实现的
比如
累加器中保存top1高和top2高数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号