【WEB UI自动化】Selenium爬取b站的浏览历史记录(打印到控制台以及保存到sqlite)
代码
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
import time
import requests
import sqlite3
import os
from datetime import datetime
#步骤:
# 切换到chrome.exe所在路径下
# cmd执行 chrome.exe --remote-debugging-port=9222 --user-data-dir="E:\selenium_data"
# 访问b站,登录你的账号
# 之后运行该脚本进行接管
minimum_record_number=int(input("请输入要爬取的最少记录数目"))
db_file='history'+datetime.today().strftime("%Y-%m-%d-%H-%M-%S")+'.db'
if not os.path.exists(db_file):
open(db_file, 'w')
else:
pass
conn=sqlite3.connect(db_file)
cur=conn.cursor()
sql="CREATE TABLE 'watch_history' ( \
'wh_id' INTEGER NOT NULL, \
'url_item' TEXT, \
'title_item' TEXT, \
PRIMARY KEY('wh_id' AUTOINCREMENT) \
)"
cur.execute(sql)
history_list=[]
url=f'https://www.bilibili.com/account/history'
chrome_options = Options()
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222") # 前面设置的端口号
driver = webdriver.Chrome(options=chrome_options)
driver.get(url)
driver.implicitly_wait(1) # 设置超时时间为1秒
# selenium测瀑布流UI页面的Python代码
count=0
while True:
driver.execute_script("window.scrollTo(0,document.body.scrollHeight)")
try:
i = 1
while True:
js = "var q=document.documentElement.scrollTop=" + str(1400 * i) # 谷歌 和 火狐
i = i + 1
driver.execute_script(js)
time.sleep(1)
videos=driver.find_elements_by_xpath("//div[@class='r-txt']")
videos_len=len(videos)
for j in range(count,videos_len):
url_item=videos[j].find_element_by_xpath(".//a[@class='title']").get_attribute("href") #相当于 .//a[@class='title']/@href
title_item=videos[j].find_element_by_xpath("./a").text
history_list.append((url_item,title_item))
print(url_item, title_item, sep=' ')
print(count)
count=count+1
if count>=minimum_record_number:
break
sql = "insert into watch_history(url_item,title_item) values(?,?)"
cur.execute(sql, history_list[-1])
if count >= minimum_record_number:
break
if count >= minimum_record_number:
break
except NoSuchElementException as e:
# 抛出异常说明没找到底部标志,继续向下滑动
print('erro %s' % e)
finally:
conn.commit()
"""
sql='select * from history'
cur.execute(sql)
print(cur.fetchall())
"""
conn.commit()
cur.close()
conn.close()
效果演示
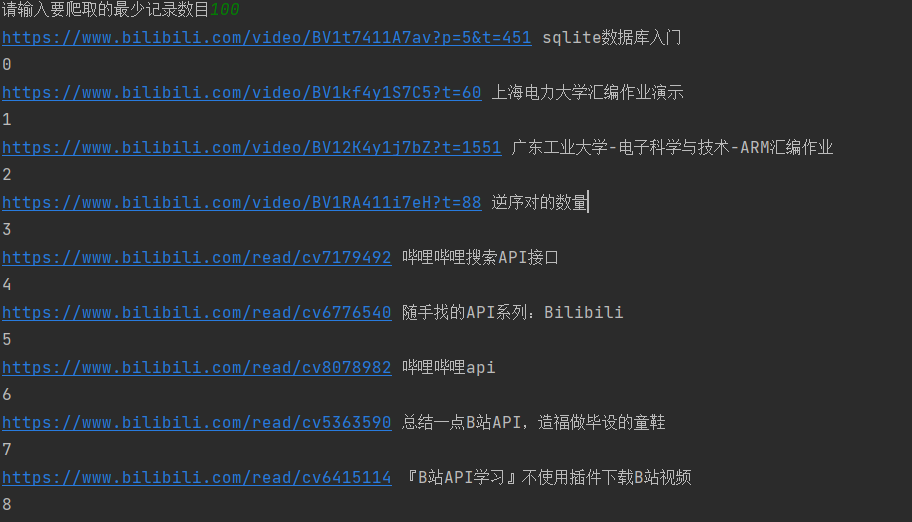
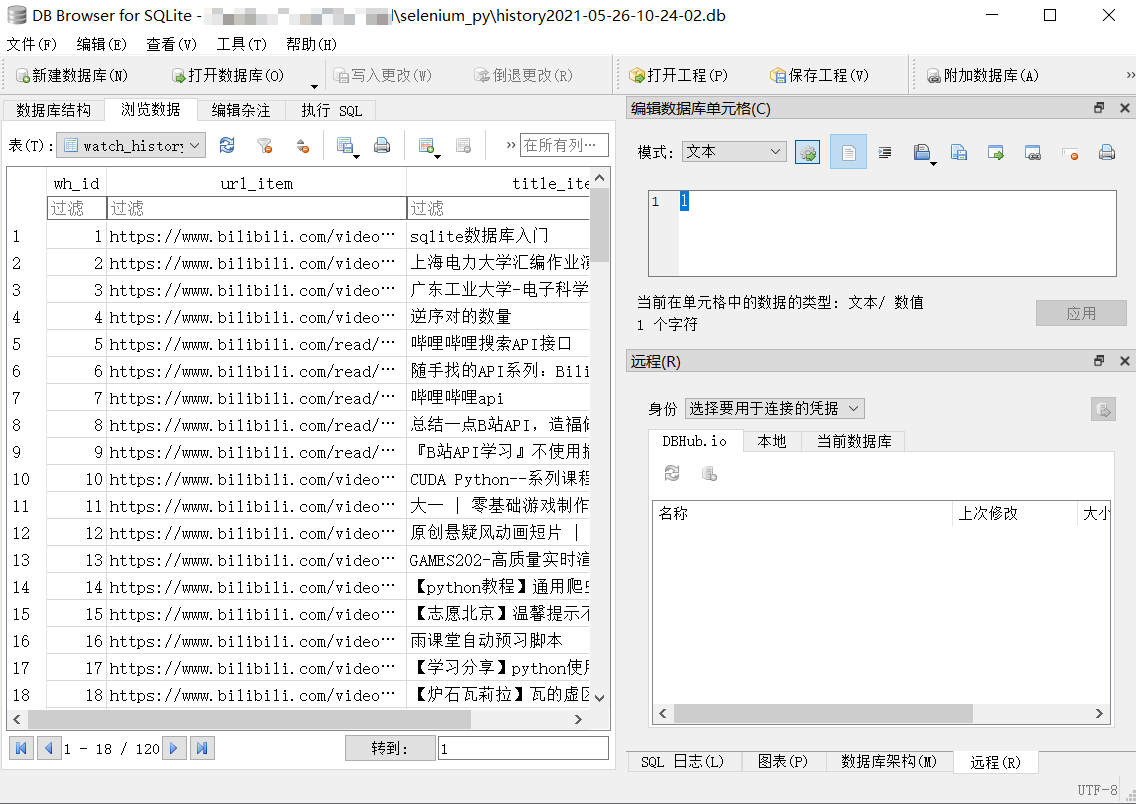
TODO
瀑布流额外加载一次后,之前的数据没必要再find一遍
暂时没想到怎么优化
打算加一个生产者-消费者模式,这边爬取后把数据扔进队列,那边从队列中捡起数据开始处理数据
https://blog.csdn.net/weixin_43533825/article/details/89155648
打算玩转bilibili的API
https://github.com/SocialSisterYi/bilibili-API-collect

 浙公网安备 33010602011771号
浙公网安备 33010602011771号