基于Jmeter的接口测试报告
2021-12-15 09:59 _天枢 阅读(981) 评论(7) 收藏 举报【引言】
由于要使用Jmeter做接口自动化测试,Jmeter原生报告展示的内容多是基于性能参数展示;自动化测试不需要这么繁杂的报告;故决定自己开发一个简单明了的展示报告;
【思路】
利用jmeter执行结果树,生成xml报告;通过对内容进一步解析生成html报告;
需要做以下几件事:
代码目录结构:
root:
├─jmx
├─jtl
├─reports
│ ├─1640250447
|---sax_xml.py
|---report.py
|---run_jmeter.py
1.jmx用来存放jmeter jmx脚本
2.jtl用于存储jmeter生成的xml报告
3.reports用于存储生成的报告 xxxx时间戳目录\report.html
4. sax_xml.py用于解析jmeter xml并在reports目录生成报告;
5.run_jmeter.py 用于执行jmeter脚本;
备注:
1.如果你只是想解析报告,不需要第5步文件,只要按照目录将xml报告存在jtl中即可;
2.如果你想,执行和解析一体,那就需要将jmeter的jmx脚本存到jmx目录;并且对结果树进行设置;
--------------------------------------------------------------详细代码-------------------------------------------------
1.利用python的jinja2生成报告模版;
【模版html】
<!doctype html>
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- 上述3个meta标签*必须*放在最前面,任何其他内容都*必须*跟随其后! -->
<title>report</title>
<!-- Bootstrap -->
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/3.4.1/css/bootstrap.min.css" integrity="sha384-HSMxcRTRxnN+Bdg0JdbxYKrThecOKuH5zCYotlSAcp1+c8xmyTe9GYg1l9a69psu" crossorigin="anonymous">
<link rel="stylesheet" href="https://unpkg.com/bootstrap-table@1.15.3/dist/bootstrap-table.min.css">
<!-- HTML5 shim 和 Respond.js 是为了让 IE8 支持 HTML5 元素和媒体查询(media queries)功能 -->
<!-- 警告:通过 file:// 协议(就是直接将 html 页面拖拽到浏览器中)访问页面时 Respond.js 不起作用 -->
<!--[if lt IE 9]>
<script src="https://cdn.jsdelivr.net/npm/html5shiv@3.7.3/dist/html5shiv.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/respond.js@1.4.2/dest/respond.min.js"></script>
<![endif]-->
<style>
.hide {
display: none;
}
.passed {
display: "";
}
.failed {
display: "";
}
.collapsed {
display: none;
}
.log {
background-color: #e6e6e6;
border: 1px solid #e6e6e6;
color: black;
display: block;
font-family: "Courier New", Courier, monospace;
height: 230px;
overflow-y: scroll;
padding: 5px;
white-space: pre-wrap;
}
.expander::after {
content: " (用例详情)";
color: #BBB;
font-style: italic;
cursor: pointer;
}
.collapser::after {
content: " (隐藏详情)";
color: #BBB;
font-style: italic;
cursor: pointer;
}
</style>
</head>
<body>
<div class="container">
<ol class="breadcrumb">
<li class="active">接口测试报告</li>
</ol>
<div class="row">
<div class="col-sm-3 col-md-6 col-lg-8">
<p class="text-info">测试人:{{results.tester}}</p>
</div>
</div>
<div class="row">
<div class="col-sm-3 col-md-6 col-lg-8">
<p class="text-info">共【{{results.case_count}}】个用例,执行耗时【{{results.time}}】秒</p>
</div>
</div>
<div class="row">
<div class="col-sm-3 col-md-6 col-lg-8">
<button type="button" class="btn btn-info">用例总数:【{{results.case_count}}】</button>
<button type="button" class="btn btn-success">成功:【{{results.success}}】</button>
<button type="button" class="btn btn-danger">失败:【{{results.fail}}】</button>
</div>
</div>
<div class="row">
<div class="col-sm-3 col-md-6 col-lg-8" style="align-content: center; width: 100%;">
<table id="dt_deail" class="table table-hover table-bordered table-responsive">
<caption>报告详情</caption>
<thead>
<tr>
<th>结果</th>
<th>描述</th>
<th>执行时间</th>
<th>执行耗时(ms)</th>
</tr>
</thead>
<tbody id="tb">
<!--for从后端获取 tr-->
{% for row in results.table %}
<!--第一个tr是场景名称-->
{% if row.result %}
<tr id="{{ loop.index0 }}.{{ loop.index0 }}" class="res info passed">
{% else %}
<tr id="{{ loop.index0 }}.{{ loop.index0 }}" class="res danger failed">
{% endif %}
<td>
{% if row.result %}
Passed
{% else %}
Failed
{% endif %}
<span class="expander"></span>
</td>
<td>{{row.desc}}</td>
<td>{{row.case_exec_time}}</td>
<td>{{row.time}}</td>
</tr>
<!--第二个tr是第一个tr的场景详细-->
<tr id={{ loop.index0 }} class="collapsed">
<td colspan="4">
<div class="log">{{row.deail}}</div>
</td>
</tr>
{% endfor %}
</tbody>
</table>
</div>
</div>
</div>
<!-- jQuery (Bootstrap 的所有 JavaScript 插件都依赖 jQuery,所以必须放在前边) -->
<script src="https://cdn.jsdelivr.net/npm/jquery@1.12.4/dist/jquery.min.js" integrity="sha384-nvAa0+6Qg9clwYCGGPpDQLVpLNn0fRaROjHqs13t4Ggj3Ez50XnGQqc/r8MhnRDZ" crossorigin="anonymous"></script>
<!-- 加载 Bootstrap 的所有 JavaScript 插件。你也可以根据需要只加载单个插件。 -->
<script src="https://stackpath.bootstrapcdn.com/bootstrap/3.4.1/js/bootstrap.min.js" integrity="sha384-aJ21OjlMXNL5UyIl/XNwTMqvzeRMZH2w8c5cRVpzpU8Y5bApTppSuUkhZXN0VxHd" crossorigin="anonymous"></script>
<!--设置-->
<script src="https://unpkg.com/bootstrap-table@1.15.3/dist/bootstrap-table.min.js"></script>
<script>
$(function() {
$("#dt_deail").bootstrapTable({
//是否显示搜索框
search: true,
//是否分页
pagination: true,
// 每页显示多少条数据,也就是要显示多少行
pageSize: 20,
//分页,选择不同数字会改变上面的pageSize
pageList: [5, 10, 15, 20],
// //显示列选择按钮
// showColumns: false,
// //是否刷新
// showRefresh: false,
// //是否可见
// showToggle: false,
// //默认英文,如下显示中文
// locale: "zh-CN",
// //不缓存
// cache: false,
// //背景色,灰白相间
// striped: false,
// //是否显示模向滚动条
// showFooter: false,
// //是否启用排序
// sortable: false,
// //sortOrder: "asc",
// //是否启用点击选中行
// clickToSelect: false,
// //每一行的唯一标识,一般为主键列
//uniqueId: "ID",
// //是否显示父子表
// detailView: false,
// //开启单远,想要获取被选中行数据必须要有该参数
// singleSelect: true,
//单击行事件
onClickRow: function (row, $element) {
// 获取id
let id = $element[0].attributes[0].value;
id = id.substr(0, id.indexOf("."))
// 按id隐藏,显示行
$("#"+id).toggle();
$("#"+id).removeClass("hide");
},
});
$('.btn-success').click(function (){
$(".failed").addClass("hide");
$(".passed").removeClass("hide");
$(".collapsed").addClass("hide");
});
$('.btn-danger').click(function (){
$(".passed").addClass("hide");
$(".collapsed").addClass("hide");
$(".failed").removeClass("hide");
});
$('.btn-info').click(function (){
$(".passed").removeClass("hide");
$(".failed").removeClass("hide");
$(".collapsed").addClass("hide");
});
});
</script>
</body>
</html>
【生成Html代码】


import jinja2 import os import io import xml.sax from sax_xml import ReportHandler class Report: @classmethod def report(cls, root_dir: str, report_path: str, result_json: dict) ->dict: """填充报告模版""" env = jinja2.Environment( loader=jinja2.FileSystemLoader(root_dir), extensions=(), autoescape=True ) template = env.get_template("template.html", root_dir) html = template.render({"results": result_json}) output_file = os.path.join( report_path, "report.html" ) with io.open(output_file, 'w', encoding="utf-8") as fp: fp.write(html) print(output_file) return result_json @classmethod def parse_xml_generate_html(cls, xml_file: str, report_path: str) -> dict: """ 从xml解析数据,填充到html模版,并成生html报告 """ # 创建一个 XMLReader parse = xml.sax.make_parser() # turn off namespaces parse.setFeature(xml.sax.handler.feature_namespaces, 0) # 重写 ContextHandler Handler = ReportHandler() parse.setContentHandler(Handler) parse.parse(xml_file) results = Handler.content() results_json = Report.report(os.getcwd(), report_path, results) return results_json if __name__ == '__main__': # 模版解析格式 # results = { # "tester": "test", # "case_count": 123, # "time": 456, # "success": 123, # "fail": 0, # "error": 0, # "table": [{ # "result": True, # "desc": "123", # "exe_time": "123", # "time": "123", # "case_exec_time":"执行时间", # "deail": "12313" # }, # { # "result": False, # "desc": "333", # "exe_time": "44", # "time": "55", # "case_exec_time":"执行时间", # "deail": "666" # } # ] # } xml_report_file = os.path.join( os.path.join(os.getcwd(), 'jtl'), "1639479506.xml" ) html_report_path = os.path.join(os.getcwd(), 'reports') Report.parse_xml_generate_html(xml_report_file, html_report_path)
2.解析xml代码
import time import xml.sax import json class ReportHandler(xml.sax.handler.ContentHandler): def __init__(self): # 存储遍历每个节点名称; self.current_data = "" # 存储请求,响应数据; self.request_data = [] self.response_data = [] self.method = "" self.url = "" # url中带特列字符,解析时会进行分开遍历;需要放在list最后进行join拼接; self.url_list = [] self.ts = "" # 临时存储线程组结果 self.result = {} # 单接口名称,即jmeter请求命名; self.sample_name = "" # 线程组名称 self.group_name = "" # 接口响应,请求,临时存储字段; self.response = "" self.request = "" # 存储所有结果,按结果传给html模版进行渲染页面; self.all_result = [] # case总数,case成功总数,case失败总数 self.case_count = {} self.case_success_count = {} self.case_error_count = {} # 存储,成功,错误,失败结果; self.success = [] self.error = [] self.failure = [] # 临时存储每个每个case结果,{[case1,case2]} self.temp_result = {} # 总体case执行耗时s self.total_time = [] # 单个case执行耗时总时间ms self.case_total_time = {} # 存储每个请求耗时ms self.t = "" # 单个case开始请求时间; self.case_exec_time = {} self.s = "" def startElement(self, name, attrs): """ 元素开始事件处理 """ self.current_data = name if name == "httpSample": self.ts = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(int(attrs["ts"])/1000)) self.success.append(eval(str(attrs["s"]).capitalize())) self.sample_name = attrs["lb"] self.group_name = attrs["tn"] self.case_count[attrs["tn"]] = 1 self.t = attrs["t"] self.s = eval(str(attrs["s"]).capitalize()) # 记录各线程组结果list {”线程级名称1“:[True, False, True], ”线程级名称2“:[True, True, True]} if not self.result.get(attrs["tn"]): self.result[attrs["tn"]] = [] self.result[attrs["tn"]].append(eval(str(attrs["s"]).capitalize())) self.total_time.append(int(attrs["t"])) def endElement(self, name): """元素结束事件处理""" if self.current_data == "responseData": if self.response_data: try: self.response = json.dumps( json.loads( "".join(self.response_data) ), sort_keys=True, indent=2 ) except json.JSONDecodeError: self.response = self.response_data else: self.response = "" if self.current_data == "queryString": if self.request_data: try: self.request = json.dumps( json.loads( "".join(self.request_data) ), sort_keys=True, indent=2 ) except json.JSONDecodeError: self.request = self.request_data else: self.request = "" if self.current_data == "httpSample": self.case_success_count[self.group_name].append(eval(str(self.s.capitalize()))) if self.response and self.method and self.url: result_string = '''%(desc)s\n%(ts)s %(method)s 请求:%(url)s\n请求:\n%(request)s\n响应:\n%(response)s\n''' # 单条case上的详细内容 res = result_string % dict( desc=self.sample_name, ts=self.ts, method=self.method, url=self.url, request=self.request, response=self.response ) # temp_result按线程组名称为key划分,存组整个线程中请求结果; if not self.temp_result.get(self.group_name): self.temp_result[self.group_name] = [] self.case_total_time[self.group_name] = [] self.case_exec_time[self.group_name] = [] self.case_success_count[self.group_name] = [] self.temp_result[self.group_name].append(res) self.case_total_time[self.group_name].append(int(self.t)) self.case_exec_time[self.group_name].append(self.ts) self.case_success_count[self.group_name].append(self.s) # 恢复初始值 self.method = "" self.url = "" self.ts = "" self.sample_name = "" self.group_name = "" self.response = "" self.request = "" self.t = "" self.s = "" self.request_data = [] self.response_data = [] self.current_data = "" self.url = "" self.url_list = [] def characters(self, content): """内容处理事件""" if self.current_data == "responseData": self.response_data.append(content) if self.current_data == "queryString": self.request_data.append(content) if self.current_data == "method": self.method = content if self.current_data == "java.net.URL": if "http" in content or content: self.url_list.append(content) self.url = ''.join(self.url_list) if self.current_data == "error": self.error.append(eval(str(content).capitalize())) if self.current_data == "failure": self.failure.append(eval(str(content).capitalize())) def content(self): """结果进行结构组合""" # 遍历按线程组分组的结果; for key, val in self.temp_result.items(): self.all_result.append( { "result": all(self.result[key]), "desc": key, "exe_time": self.total_time, "case_exec_time": self.case_exec_time[key][0], "time": sum(self.case_total_time[key]), "deail": ''.join(val) } ) case_result_count = [all(val) for _, val in self.case_success_count.items()] # 最终所有结果; results = { "tester": "test", "case_count": len(self.case_count.keys()), "time": sum(self.total_time) / 1000, "success": case_result_count.count(True), "fail": case_result_count.count(False), "error": self.error.count(True), "table": self.all_result } return results if __name__ == "__main__": # 创建一个 XMLReader parser = xml.sax.make_parser() # turn off namespaces parser.setFeature(xml.sax.handler.feature_namespaces, 0) # 重写 ContextHandler Handler = ReportHandler() parser.setContentHandler(Handler) parser.parse("1639479506.xml") print( Handler.content() )
3. jmeter运行脚本
import os import time import requests from report import Report class WX: """企业微信""" @classmethod def send_message(cls, content: str, token: str) -> dict: """ 发送企业微信机器人文本消息 :param content: 推送内容 :param token: 机器人key :return: json {"errcode":0,"errmsg":"ok"} """ url = "https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key={}".format(token) payload = { "msgtype": "text", "text": { "content": content, } } res = requests.post(url, json=payload) return res.json() class Result: """从statistics.json读取测试结果""" @classmethod def run_jmeter(cls, timestamp: str, jmx_file_name) -> str: """执行jmeter""" cur = os.getcwd() jtl = os.path.join(cur, "jtl") reports = os.path.join(cur, "reports") # 创建report文件夹 os.makedirs(os.path.join(reports, timestamp)) cmd = "jmeter -n -t {} -Jresultsfile={}".format( os.path.join( os.path.join(cur, "jmx"), jmx_file_name ), os.path.join(jtl, "{}.xml".format(timestamp)) ) os.system(cmd) resultsfile = os.path.join(jtl, "{}.xml".format(timestamp)) return resultsfile @classmethod def get_test_result(cls, timestamp: str, desc: str, url: str, jmx_file_name: str) -> str: """ 从jmeter执行结果timeStamp.xml中读取结果; """ cur_path = os.getcwd() tmpl = """%(desc)s【已完成】:\n共%(case)s个接口, 执行耗时 %(used_time)ss, 通过 %(Pass)s, 失败 %(error)s, 通过率 %(rate)s \n测试报告地址:%(url)s""" # 执行jmeter cls.run_jmeter(timestamp, jmx_file_name) report_dir = os.path.join( os.path.join(cur_path, "reports"), timestamp ) xml_report_file = os.path.join( os.path.join("jtl", "{}.xml".format(timestamp)) ) results_json = Report.parse_xml_generate_html(xml_report_file, report_dir) # 报告成功率 total_count = results_json['case_count'] error_count = int(results_json['case_count']) - int(results_json['success'] - int(results_json['fail'])) success_count = int(results_json['success']) success_rate = success_count / total_count * 100 ret = tmpl % dict( desc=desc, case=str(total_count), used_time=results_json['time'], Pass=str(success_count), error=str(error_count), rate='{}%'.format(str(success_rate)), url=url ) return ret if __name__ == "__main__": report_dir_name = str(int(time.time())) url = "http://60.205.217.8:5004/pro_mall/reports/{}".format(report_dir_name) content = Result.get_test_result( report_dir_name, "Pro H5商城API自动化测试执行", url, "H5商城自动化Pro.jmx" ) #WX.send_message(content, "3d38fe6b-c49f-46d6-8b17-9d92b9d5a143")
4.jmeter设置
合勾上:
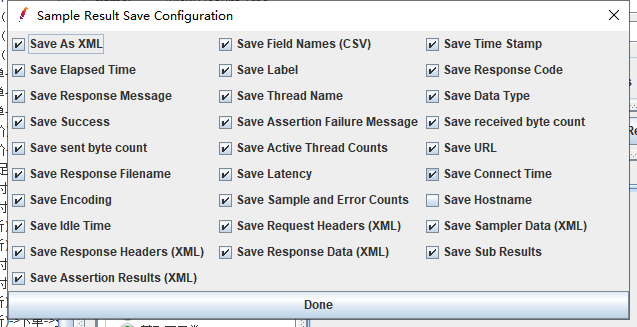
输出xml存储位置:这里是脚本运行时指的变量存储的位置resultsfile;
这个是利用了jmeter本身命令行输出参数-J:jmeter -n -t {} -Jresultsfile={}
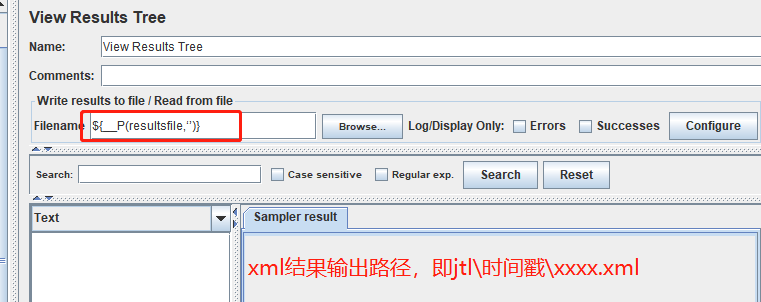
【结果样式】

作 者:
天枢
出 处:
http://www.cnblogs.com/yhleng/
关于作者:专注于软件自动化测试领域。如有问题或建议,请多多赐教!
版权声明:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。
特此声明:所有评论和私信都会在第一时间回复。也欢迎园子的大大们指正错误,共同进步。或者
直接私信我
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角
【
推荐】
一下。您的鼓励是作者坚持原创和持续写作的最大动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号