
4.18团队和个人第六次冲刺
团队博客
整个项目预期的任务量:30h 已用15h
任务看板照片

团队照片

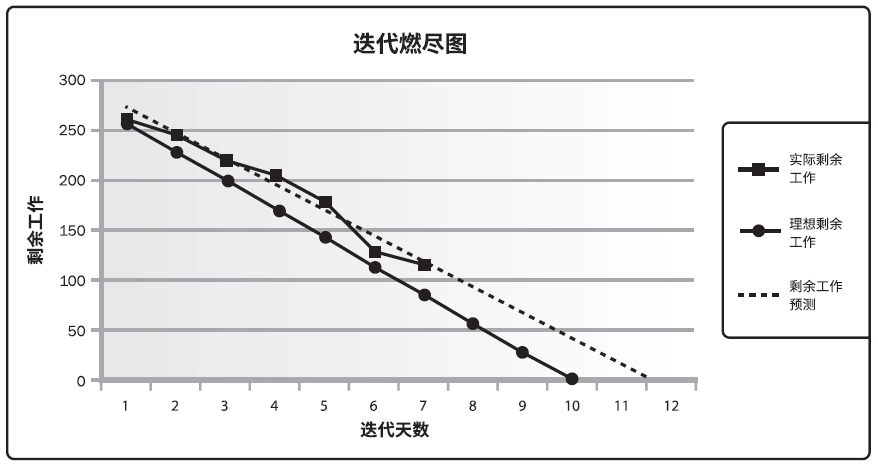
燃尽图
4.产品状态
完成了pdf文档的识别

个人博客
昨天完成了pdf文件通过服务器最后存储到磁盘中,
今天完成pdf文件的识别与录入,
首先在网上寻找了相关实例,导入相关代码

<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>jempbox</artifactId>
<version>1.8.11</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>xmpbox</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>preflight</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox-tools</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
</dependencies>
然后进行文字的识别,测试代码成功
package com.itheima.pojo; import java.awt.Rectangle; import java.awt.geom.Rectangle2D; import java.io.File; import java.util.Iterator; import org.apache.pdfbox.text.PDFTextStripper; import org.apache.pdfbox.text.PDFTextStripperByArea; import org.apache.pdfbox.cos.COSName; import org.apache.pdfbox.io.RandomAccessFile; import org.apache.pdfbox.pdfparser.PDFParser; import org.apache.pdfbox.pdmodel.PDDocument; import org.apache.pdfbox.pdmodel.PDPage; import org.apache.pdfbox.pdmodel.PDResources; import org.apache.pdfbox.pdmodel.graphics.image.PDImageXObject; import javax.imageio.ImageIO; public class PDFReader { static String fileName = "F:/qiao.pdf"; public static void main(String[] args) throws Exception { String s = readFile(); System.out.println(s); } /** * 一次获取整个文件的内容 * * @throws Exception */ public static String readFile() throws Exception { File file = new File(fileName); RandomAccessFile is = new RandomAccessFile(file, "r"); PDFParser parser = new PDFParser(is); parser.parse(); PDDocument doc = parser.getPDDocument(); String s=""; PDFTextStripper textStripper = new PDFTextStripper(); try { s = textStripper.getText(doc); // System.out.println("总页数:" + doc.getNumberOfPages()); // System.out.println("输出内容:"); // System.out.println(s); }catch (Exception e){ e.printStackTrace(); } doc.close(); return s; } /** * 分页获取文字的内容 * * @throws Exception */ public static void readPage() throws Exception { File file = new File(fileName); RandomAccessFile is = new RandomAccessFile(file, "r"); PDFParser parser = new PDFParser(is); parser.parse(); PDDocument doc = parser.getPDDocument(); PDFTextStripper textStripper = new PDFTextStripper(); for (int i = 1; i <= doc.getNumberOfPages(); i++) { textStripper.setStartPage(i); textStripper.setEndPage(i); // 一次输出多个页时,按顺序输出 textStripper.setSortByPosition(true); String s = textStripper.getText(doc); System.out.println("当前页:" + i); System.out.println("输出内容:"); System.out.println(s); } doc.close(); } /** * 读取文本内容和图片 * * @throws Exception */ public static void readTextImage() throws Exception { File file = new File(fileName); PDDocument doc = PDDocument.load(file); PDFTextStripper textStripper = new PDFTextStripper(); for (int i = 1; i <= doc.getNumberOfPages(); i++) { textStripper.setStartPage(i); textStripper.setEndPage(i); String s = textStripper.getText(doc); System.out.println("第 " + i + " 页 :" + s); // 读取图片 PDPage page = doc.getPage(i - 1); PDResources resources = page.getResources(); // 获取页中的对象 Iterable<COSName> xobjects = resources.getXObjectNames(); if (xobjects != null) { Iterator<COSName> imageIter = xobjects.iterator(); while (imageIter.hasNext()) { COSName cosName = imageIter.next(); boolean isImageXObject = resources.isImageXObject(cosName); if (isImageXObject) { // 获取每页资源的图片 PDImageXObject ixt = (PDImageXObject) resources.getXObject(cosName); File outputfile = new File("第 " + (i) + " 页" + cosName.getName() + ".jpg"); System.out.println(cosName.getName()); ImageIO.write(ixt.getImage(), "jpg", outputfile); } } } } doc.close(); } /** * 区域解析 * * @throws Exception */ public static void readRectangle() throws Exception { String filePath = fileName; File file = new File(filePath); PDDocument doc = PDDocument.load(file); // 这个四边形所在区域在 y轴向下为正,x轴向右为正。 int x = 35; int y = 300; int width = 50; int height = 50; PDFTextStripperByArea stripper = new PDFTextStripperByArea(); stripper.setSortByPosition(true); // 划定区域 Rectangle2D rect = new Rectangle(x, y, width, height); stripper.addRegion("area", rect); PDPage page = doc.getPage(0); stripper.extractRegions(page); // 获取区域的text String data = stripper.getTextForRegion("area"); data = data.trim(); System.out.println(data); doc.close(); } }
遇到了提取有效的信息困难。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律