

城堡(一)
易得,只有偶数个奇数时可行。
点击查看代码
#include <cstdio> #include <iostream> #include <algorithm> using namespace std; // #define Debug // #define LOCAL // #define TestCases void solve() { int n, cnt = 0; cin >> n; for (int i = 1, a; i <= n; i++) cin >> a, cnt += (a & 1); puts(cnt & 1 ? "NO" : "YES"); return ; } int main() { #ifdef LOCAL freopen("data.in", "r", stdin); freopen("mycode.out", "w", stdout); #endif ios :: sync_with_stdio(false); cin.tie(nullptr), cout.tie(nullptr); int T = 1; #ifdef TestCases cin >> T; #endif while (T--) solve(); return 0; }
先整体考虑,必要
加等差数列,考虑差分。一次操作后,
点击查看代码
#include <cstdio> #include <iostream> #include <algorithm> using namespace std; // #define Debug // #define LOCAL // #define TestCases const int N = 1e5; int n; long long a[N + 5]; void solve() { cin >> n; long long sum = 0, base = 1ll * n * (n + 1) / 2; for (int i = 1; i <= n; i++) cin >> a[i], sum += a[i]; if (sum % base != 0) return puts("NO"), void(); long long t = sum / base; a[0] = a[n]; for (int i = n; i > 0; i--) a[i] -= a[i - 1]; for (int i = 1; i <= n; i++) { if (t - a[i] < 0 || (t - a[i]) % n != 0) return puts("NO"), void(); } return puts("YES"), void(); } int main() { #ifdef LOCAL freopen("data.in", "r", stdin); freopen("mycode.out", "w", stdout); #endif ios :: sync_with_stdio(false); cin.tie(nullptr), cout.tie(nullptr); int T = 1; #ifdef TestCases cin >> T; #endif while (T--) solve(); return 0; }
点权放边权。考虑每条边被覆盖的次数
只需考虑每个点处能否满足。有
一个经典结论的证明
堆,个数满足 ,保证总数是 的倍数。不同堆两两配对,则能做到的充要条件是 。
必要性:反证。若
,即 大于其余所有数之和,必不满足 充分性:每次取最大的两个配对,考虑新的
,有
,即原始 ,则 。若不合法,即有 ,得 。此时数列全为 ,又总和为偶数, 满足限制。 故操作后仍合法。
点击查看代码
#include <cstdio> #include <iostream> #include <algorithm> #include <vector> using namespace std; // #define Debug // #define LOCAL // #define TestCases const int N = 1e5; int n; long long a[N + 5]; int root; vector<int> e[N + 5]; long long b[N + 5]; #define Failed (puts("NO"), exit(0)) void dfs(int u, int fa) { if (e[u].size() == 1) { b[u] = a[u]; return ; } b[u] = a[u] << 1; long long mx = 0; for (auto v : e[u]) { if (v == fa) continue; dfs(v, u); b[u] -= b[v]; mx = max(mx, b[v]); } if (b[u] < 0) Failed; mx = max(mx, b[u]); if (mx > a[u]) Failed; if (u == root && b[u] != 0) Failed; return ; } void solve() { cin >> n; for (int i = 1; i <= n; i++) cin >> a[i]; for (int i = 1, u, v; i < n; i++) { cin >> u >> v; e[u].push_back(v), e[v].push_back(u); } for (int i = 1; i <= n; i++) { if (e[i].size() == 1) continue; root = i; break; } if (!root)//all nodes are leaf, which is a chain with length 2 return puts(a[1] == a[2] ? "YES" : "NO"), void(); dfs(root, 0);//root is not leaf return puts("YES"), void(); } int main() { #ifdef LOCAL freopen("data.in", "r", stdin); freopen("mycode.out", "w", stdout); #endif ios :: sync_with_stdio(false); cin.tie(nullptr), cout.tie(nullptr); int T = 1; #ifdef TestCases cin >> T; #endif while (T--) solve(); return 0; }
考虑奇偶性。当最终不能再除
只关心奇数、偶数个数的奇偶性,
分讨
把任意
同上一情况中后手面对的局势。
显然不能对偶数操作,否则变为第二种情况。只能令唯一的
每次至少除
总
点击查看代码
#include <cstdio> #include <iostream> #include <algorithm> using namespace std; // #define Debug // #define LOCAL // #define TestCases const int N = 1e5; int n; int a[N + 5]; void solve() { cin >> n; for (int i = 1; i <= n; i++) cin >> a[i]; if (n == 1) return puts(a[1] & 1 ? "Second" : "First"), void(); int p = 1; while (1) { int odd = 0, even = 0; for (int i = 1; i <= n; i++) { odd += a[i] & 1; even += !(a[i] & 1); } if (even & 1) break; if (odd > 1) { p = 3 - p; break; } int index = 0; for (int i = 1; i <= n; i++) { if (a[i] & 1) { index = i; break; } } if (a[index] == 1) { p = 3 - p; break; } a[index]--; int d = a[1]; for (int i = 2; i <= n; i++) d = __gcd(d, a[i]); for (int i = 1; i <= n; i++) a[i] /= d; p = 3 - p; } puts(p == 1 ? "First" : "Second"); return ; } int main() { #ifdef LOCAL freopen("data.in", "r", stdin); freopen("mycode.out", "w", stdout); #endif ios :: sync_with_stdio(false); cin.tie(nullptr), cout.tie(nullptr); int T = 1; #ifdef TestCases cin >> T; #endif while (T--) solve(); return 0; }
- 原始做法,未实现,正确性未知
注:开始把二人的目的看反了,下文全是反的
考虑逐位确定。比如第一位。如果
被移到第一位,意味着 与前面所有数互质。反之如果有一个不互质的数挡在 之前, 就不会成为开头。 可以二分!希望挡住
的数怎么办?显然先把 的放开头,在此基础上拓展,往后接不互质的数。如果所有数都被遍历到了,即合法!这是一个 的过程。 第二位怎么办?还是二分,但是最先放的应该
且与第一个不互质。而其他数要么对第一个有威胁,要么对 有威胁,都应被拓展而得。 已固定前
位,也是类似的。而新加确定一个数,其他数对前面是否有威胁可以 更新,一些的限制被取 ,另一些的限制解除(与新数不互质的那些)。 然而,单次遍历是
的,总 。
-
题解做法
第一步,用不互质的阻挡是对的。但这里已经可以从图论考虑了。不互质的两个数的前后关系,相当于在“不互质图”上给一条边定向。甲操作后,这张图变为一张乙的解法是经典的,用优先队列做拓扑排序。
考虑甲。对于图上两个不同的连通块,相互独立,甲只能限制块内数的先后顺序。以最小的数为根,按
总
点击查看代码
#include <cstdio> #include <iostream> #include <algorithm> #include <vector> #include <queue> using namespace std; // #define Debug // #define LOCAL // #define TestCases const int N = 2000; int n; int a[N + 5]; vector<int> e[N + 5];//undirected vector<int> g[N + 5];//directed int in[N + 5]; int vis[N + 5]; void dfs(int u) { vis[u] = 1; for (auto v : e[u]) { if (vis[v]) continue; g[u].push_back(v), in[v]++; dfs(v); } return ; } void toposort() { priority_queue<int> q; for (int i = 1; i <= n; i++) { if (!in[i]) q.push(i); } while (!q.empty()) { int u = q.top(); q.pop(); cout << a[u] << " "; for (auto v : g[u]) { in[v]--; if (!in[v]) q.push(v); } } cout << endl; return ; } void solve() { cin >> n; for (int i = 1; i <= n; i++) cin >> a[i]; sort(a + 1, a + n + 1); for (int u = 1; u <= n; u++) { for (int v = 1; v <= n; v++) { if (__gcd(a[u], a[v]) == 1) continue; e[u].push_back(v); e[v].push_back(u); } } for (int i = 1; i <= n; i++) { if (!vis[i]) dfs(i); } toposort(); return ; } int main() { #ifdef LOCAL freopen("data.in", "r", stdin); freopen("mycode.out", "w", stdout); #endif ios :: sync_with_stdio(false); cin.tie(nullptr), cout.tie(nullptr); int T = 1; #ifdef TestCases cin >> T; #endif while (T--) solve(); return 0; }
从简单情况入手,其实并没有很复杂。
- 两个点
- 菊花图花心
先手只能去叶子,后手只能从叶子回来。先手要最快制造一个为
一般地,记
局势变为后手必胜,后手一定会把棋子向
后手必败,只能返回
因此每个点处都类似菊花图花心处理。枚举根,总
点击查看代码
#include <cstdio> #include <iostream> #include <algorithm> #include <vector> using namespace std; // #define Debug // #define LOCAL // #define TestCases const int N = 3000, Inf = 0x3f3f3f3f; int n; int a[N + 5]; vector<int> e[N + 5]; int sg[N + 5];//whether 1st player will win, only consider subtree(u) void dfs(int u, int fa) { if (fa && e[u].size() == 1)//leaf & not root return sg[u] = 0, void(); int mn = Inf; for (auto v : e[u]) { if (v == fa) continue; dfs(v, u); if (sg[v] == 0) mn = min(mn, a[v]); } sg[u] = (a[u] > mn); return ; } bool check(int rt) { dfs(rt, 0); return sg[rt]; } void solve() { cin >> n; for (int i = 1; i <= n; i++) cin >> a[i]; for (int i = 1, u, v; i < n; i++) { cin >> u >> v; e[u].push_back(v); e[v].push_back(u); } for (int i = 1; i <= n; i++) { if (check(i)) cout << i << " "; } cout << endl; return ; } int main() { #ifdef LOCAL freopen("data.in", "r", stdin); freopen("mycode.out", "w", stdout); #endif ios :: sync_with_stdio(false); cin.tie(nullptr), cout.tie(nullptr); int T = 1; #ifdef TestCases cin >> T; #endif while (T--) solve(); return 0; }
贪心。
要超时了,用最少的车接走最早的人,富裕的位置用没走的人补。
点击查看代码
#include <cstdio> #include <iostream> #include <algorithm> #include <set> using namespace std; // #define Debug // #define LOCAL // #define TestCases const int N = 1e5; int n, c, k; multiset<int> s; void solve() { cin >> n >> c >> k; for (int i = 1, t; i <= n; i++) { cin >> t; s.insert(t); } int ans = 0; while (!s.empty()) { auto t = *s.begin(); int lim = t + k, cnt = 0; while (!s.empty() && *s.begin() == t) { cnt++; s.erase(s.begin()); } int need = (cnt + c - 1) / c; ans += need; int rem = need * c - cnt; while (!s.empty() && rem > 0 && *s.begin() <= lim) { rem--; s.erase(s.begin()); } } cout << ans << endl; return ; } int main() { #ifdef LOCAL freopen("data.in", "r", stdin); freopen("mycode.out", "w", stdout); #endif ios :: sync_with_stdio(false); cin.tie(nullptr), cout.tie(nullptr); int T = 1; #ifdef TestCases cin >> T; #endif while (T--) solve(); return 0; }
贪心。
一定是从小到大吃,先吃了小的。倒序维护需要的最小体积
即
点击查看代码
#include <cstdio> #include <iostream> #include <algorithm> #include <map> using namespace std; // #define Debug // #define LOCAL // #define TestCases const int N = 1e5; int n; long long sz[N + 5]; long long sum[N + 5];//prefix sum void solve() { cin >> n; for (int i = 1; i <= n; i++) cin >> sz[i]; sort(sz + 1, sz + n + 1); for (int i = 1; i <= n; i++) sum[i] = sum[i - 1] + sz[i]; int ans = 0; long long need = 0; for (int i = n; i > 0; i--) { ans += (sum[i] >= need); need = max(need - sz[i], (sz[i] + 1) >> 1); } cout << ans << endl; return ; } int main() { #ifdef LOCAL freopen("data.in", "r", stdin); freopen("mycode.out", "w", stdout); #endif ios :: sync_with_stdio(false); cin.tie(nullptr), cout.tie(nullptr); int T = 1; #ifdef TestCases cin >> T; #endif while (T--) solve(); return 0; }
打表。
不妨先对每个连通块考虑。
考虑一条边
- 对于二分图,一定是两个块
- 对于非二分图,一定是一个块。首先这对奇环成立,然后考虑从环上伸出的边,十字结构都与环连通,进而推出整个块连通
注:下图省略了一些边
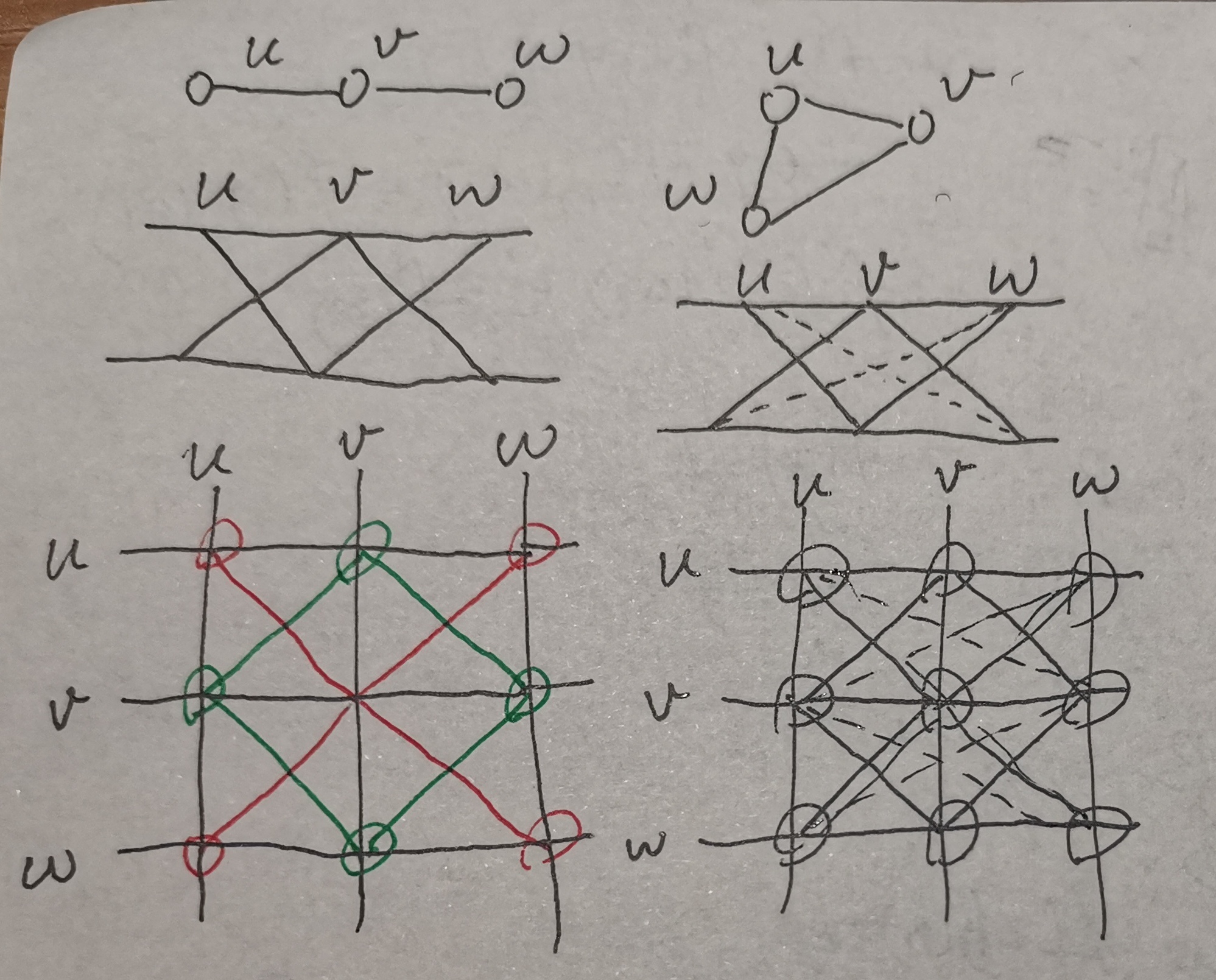
现在单个连通块的情况研究清楚了,接下来考虑不同块间的影响。
如下面第一张图,从左到右,前两张图为二分图与非二分图,第三张为两个二分图;第二张图为对应的新图
从坐标考虑,新图关于主对角线对称,任意两个原图连通块可以组成若干个新图连通块,新连通块大小为原连通块大小之乘积。容易发现:
- 二分图
- 二分图
- 非二分图

注意一下,当原连通块为孤立点时,结论可能有偏差,此时特判就好了。孤立点不会产生任何新连通块。
最后,答案怎么计算呢?反向思考,考虑比
点击查看代码
#include <cstdio> #include <iostream> #include <algorithm> #include <vector> using namespace std; // #define Debug // #define LOCAL // #define TestCases const int N = 1e5; int n, m; vector<int> e[N + 5]; int sz[N + 5], col[N + 5]; bool dfs(int u) { sz[u] = 1; bool res = 1; for (auto v : e[u]) { if (!col[v]) { col[v] = 3 - col[u]; res &= dfs(v); sz[u] += sz[v]; } else res &= (col[u] != col[v]); } return res; } void solve() { cin >> n >> m; for (int i = 1, u, v; i <= m; i++) { cin >> u >> v; e[u].push_back(v); e[v].push_back(u); } long long ans = 1ll * n * n; int cnt_bi = 0, cnt_none = 0; int sz_bi = 0, sz_none = 0; for (int u = 1; u <= n; u++) { if (col[u]) continue; col[u] = 1; bool res = dfs(u); if (sz[u] == 1) continue; ans -= 1ll * sz[u] * sz[u] - 1 - res; ans -= 2ll * sz[u] * sz_bi - 2 * (1 + res) * cnt_bi; ans -= 2ll * sz[u] * sz_none - 2 * cnt_none; if (res) cnt_bi++, sz_bi += sz[u]; else cnt_none++, sz_none += sz[u]; } cout << ans << endl; return ; } int main() { #ifdef LOCAL freopen("data.in", "r", stdin); freopen("mycode.out", "w", stdout); #endif ios :: sync_with_stdio(false); cin.tie(nullptr), cout.tie(nullptr); int T = 1; #ifdef TestCases cin >> T; #endif while (T--) solve(); return 0; }
还是打表!
放一个简易可视化打表机,具体的表就不放了
点击查看代码
#include <cstdio> #include <iostream> #include <algorithm> using namespace std; // #define Debug #define LOCAL // #define TestCases const int N = 100; int n, k; int s[N + 5]; void print(int pos, int v) { if (pos == 0 && v == -1) printf(" <- "); else if (pos == 1 && v == 1) printf(" -> "); else printf(" "); for (int i = 1; i <= n; i++) { printf("%d", s[i]); if (pos == i && v == -1) printf(" <- "); else if (pos == i + 1 && v == 1) printf(" -> "); else printf(" "); } printf("\n"); return ; } void stimulate() { int pos = 1, v = 1; print(pos, v); while (0 < pos && pos <= n) { if (s[pos]) { s[pos] ^= 1; } else { s[pos] ^= 1; v *= -1; } pos += v; print(pos, v); } return ; } void solve() { cin >> n >> k; for (int i = 1; i <= n; i++) { char c; cin >> c; s[i] = c - 'A'; } k = 100; for (int r = 1; r <= k; r++) { printf("Round: %d\n", r); stimulate(); printf("\n"); } return ; } int main() { #ifdef LOCAL freopen("data.in", "r", stdin); freopen("mycode.out", "w", stdout); #endif ios :: sync_with_stdio(false); cin.tie(nullptr), cout.tie(nullptr); int T = 1; #ifdef TestCases cin >> T; #endif while (T--) solve(); return 0; }
从一些极端情况入手,比如看看
具体来讲:
- 球要么被第一个字母弹回,要么从最右端飞出
- 对任意
再详细分析具体过程,以
过程
Begin: 0 0 0 0 0 1 1 1 1 1 0 0 0 0 0 1 1 1 1 1 Round: 1 1 0 0 0 0 1 1 1 1 1 0 0 0 0 0 1 1 1 1 1 Round: 2 1 1 1 1 0 0 0 0 0 1 1 1 1 1 0 0 0 0 0 0 Round: 3 0 0 0 1 1 1 1 1 0 0 0 0 0 1 1 1 1 1 1 0 Round: 4 1 0 0 1 1 1 1 1 0 0 0 0 0 1 1 1 1 1 1 0 Round: 5 1 1 0 0 0 0 0 1 1 1 1 1 0 0 0 0 0 0 1 0 Round: 6 0 1 1 1 1 1 0 0 0 0 0 1 1 1 1 1 1 0 1 0 Round: 7 1 1 1 1 1 1 0 0 0 0 0 1 1 1 1 1 1 0 1 0 Round: 8 0 0 0 0 0 1 1 1 1 1 0 0 0 0 0 0 1 0 1 0 Round: 9 1 0 0 0 0 1 1 1 1 1 0 0 0 0 0 0 1 0 1 0 Round: 10 1 1 1 1 0 0 0 0 0 1 1 1 1 1 1 0 1 0 1 0 Round: 11 0 0 0 1 1 1 1 1 0 0 0 0 0 0 1 0 1 0 1 0 Round: 12 1 0 0 1 1 1 1 1 0 0 0 0 0 0 1 0 1 0 1 0 Round: 13 1 1 0 0 0 0 0 1 1 1 1 1 1 0 1 0 1 0 1 0 Round: 14 0 1 1 1 1 1 0 0 0 0 0 0 1 0 1 0 1 0 1 0 Round: 15 1 1 1 1 1 1 0 0 0 0 0 0 1 0 1 0 1 0 1 0 Round: 16 0 0 0 0 0 1 1 1 1 1 1 0 1 0 1 0 1 0 1 0 Round: 17 1 0 0 0 0 1 1 1 1 1 1 0 1 0 1 0 1 0 1 0 Round: 18 1 1 1 1 0 0 0 0 0 0 1 0 1 0 1 0 1 0 1 0 Round: 19 0 0 0 1 1 1 1 1 1 0 1 0 1 0 1 0 1 0 1 0 Round: 20 1 0 0 1 1 1 1 1 1 0 1 0 1 0 1 0 1 0 1 0 Round: 21 1 1 0 0 0 0 0 0 1 0 1 0 1 0 1 0 1 0 1 0 Round: 22 0 1 1 1 1 1 1 0 1 0 1 0 1 0 1 0 1 0 1 0 Round: 23 1 1 1 1 1 1 1 0 1 0 1 0 1 0 1 0 1 0 1 0 Round: 24 0 0 0 0 0 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 Round: 25 1 0 0 0 0 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 Round: 26 1 1 1 1 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 Round: 27 0 0 0 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 Round: 28 1 0 0 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 Round: 29 1 1 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 Round: 30 0 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 Round: 31 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0
发现一次横穿操作后,每个连续段向前移动一位且字母翻转,对于后端空出来的部分,交替填入两种字母且不再改变(也可以看作连续段,和前面规律类似)。
显然可以用双端队列模拟!记录当前相对初始有没有翻转,每次模拟是
点击查看代码
#include <cstdio> #include <iostream> #include <algorithm> #include <queue> #include <string> #include <map> #include <vector> using namespace std; // #define Debug // #define LOCAL // #define TestCases const int N = 2e5; int n, k; string s; typedef pair<int, int> node; #define col first//0: A, 1: B #define len second deque<node> q; vector<int> v; /* stable: even: BA...BA odd ABA...BA <-> BBA...BA */ void solve() { cin >> n >> k >> s; for (int l = 0, r = 0; l < n; l = r + 1) { r = l; while (r + 1 < n && s[r + 1] == s[r]) r++; q.emplace_back(s[l] - 'A', r - l + 1); } int flip = 0; for (int r = 1; r <= n + n && !q.empty() && k; r++, k--) { auto info = q.front(); q.pop_front(); if ((info.col ^ flip) == 0)//A -> B { if (info.len == 1)//A BBB -> BBBB { if (q.empty()) { v.push_back(1); continue; } info = q.front(); q.pop_front(); info.len++; q.push_front(info); } else//AAA -> B AA { info.len--; q.push_front(info); q.emplace_front(1 ^ flip, 1); } continue; } info.len--;//BBB (BAAA) -> AAA (BBB A) if (info.len > 0) q.push_front(info); if (!v.empty()) v.push_back(v.back() ^ 1); else//q can't be empty { info = q.back(); if ((info.col ^ flip) == 0)//only if end with A v.push_back(0); else { if (info.len != n)//not all B -> #(A) + 1 { info.len++; q.pop_back(); q.push_back(info); } } } flip ^= 1; } reverse(v.begin(), v.end()); if (!k) { while (!q.empty()) { auto info = q.front(); q.pop_front(); while (info.len--) cout << char((info.col ^ flip) + 'A'); } for (auto c : v) cout << char(c + 'A'); cout << endl; return ; } k %= 2; if ((n & 1) && (k & 1)) v[0] ^= 1; for (auto c : v) cout << char(c + 'A'); cout << endl; return ; } int main() { #ifdef LOCAL freopen("data.in", "r", stdin); freopen("mycode.out", "w", stdout); #endif ios :: sync_with_stdio(false); cin.tie(nullptr), cout.tie(nullptr); int T = 1; #ifdef TestCases cin >> T; #endif while (T--) solve(); return 0; }
猜了神秘结论,过了
我的做法:猜测可以贪心,每次减去最大的“不降数”
本来只是拿样例
20170312手玩一下,发现这个是对的。写了验证,样例全过了。
讨论区有人认为,该结论和从官方解法构造答案本质相同,但这对我并不显然。
大胆猜想,对任意进制结论均成立,然而我哪个都不会证明。实现上,先找到
的最长不降前缀,再在该前缀末尾连续段的首位减一,首位后用 填满。相当于先抹去一段前缀,再 +1。
写了一棵线段树维护。但其实暴力就是对的,
+1操作均摊常数,找前缀可能需要一点优化,但线段树大抵是不用的了。
另外,由此可知答案不超过位数,因为每次一定抹去最高位。若+1导致进位到最高位,则后面必须全为,又与最大矛盾了。
n = int(input()) tot = len(str(n)) cnt = 0 while n > 0: cnt = cnt + 1 delta = str("") s = "0" + str(n) l = len(s) - 1 pos = 1 while pos + 1 <= l and s[pos + 1] >= s[pos]: pos = pos + 1 lis = pos + tot - l if pos == l: break lenlen = 1 while pos > 0 and s[pos - 1] == s[pos]: pos = pos - 1 lenlen = lenlen + 1 if pos == 0: delta = delta + str(int(s[1]) - 1) for i in range(2, l + 1): delta = delta + str(9) else: for i in range(1, pos): delta = delta + str(s[i]) delta = delta + str(int(s[pos]) - 1) for i in range(pos + 1, l + 1): delta = delta + str(9) delta = int(delta) n = n - delta zero = tot - len(str(n)) delta = "" for i in range(1, zero + 1): delta = delta + "0" delta = delta + str(n) print(delta) print(cnt)
官方做法是合理的。
首先,任何一个“不降数”都可以拆成至多
右式共
点击查看代码
#include <cstdio> #include <iostream> #include <algorithm> #include <string> using namespace std; // #define Debug // #define LOCAL // #define TestCases const int N = 5e5, SZ = N << 2; int n; string str; struct Node { int keyl, keyr; int lis, len;//left, right int full;//r - l + 1 int tag; Node(): tag(-1) {} }; Node node[SZ + 5]; #define ls(p) (p << 1) #define rs(p) (p << 1 | 1) #define keyl(p) node[p].keyl #define keyr(p) node[p].keyr #define lis(p) node[p].lis #define len(p) node[p].len #define full(p) node[p].full #define tag(p) node[p].tag void pushup(int p) { keyl(p) = keyl(ls(p)), keyr(p) = keyr(rs(p)); if (lis(ls(p)) == full(ls(p))) lis(p) = full(ls(p)) + (keyr(ls(p)) <= keyl(rs(p))) * lis(rs(p)); else lis(p) = lis(ls(p)); if (len(rs(p)) == full(rs(p))) len(p) = full(rs(p)) + (keyr(ls(p)) == keyl(rs(p))) * len(ls(p)); else len(p) = len(rs(p)); return ; } void cover(int p, int x) { tag(p) = x; keyl(p) = keyr(p) = x; lis(p) = len(p) = full(p); return ; } void pushdown(int p) { if (tag(p) > -1) { cover(ls(p), tag(p)); cover(rs(p), tag(p)); tag(p) = -1; } return ; } void build(int p, int l, int r) { full(p) = r - l + 1; if (l == r) { keyl(p) = keyr(p) = str[l - 1] - '0'; lis(p) = len(p) = 1; return ; } int mid = (l + r) >> 1; build(ls(p), l, mid); build(rs(p), mid + 1, r); pushup(p); return ; } Node operator + (Node x, Node y) { Node z; z.keyl = x.keyl, z.keyr = y.keyr; z.full = x.full + y.full; z.len = y.len; if (y.len == y.full && x.keyr == y.keyl) z.len += x.len; return z; } Node query(int p, int l, int r, int L, int R) { if (L <= l && r <= R) return node[p]; int mid = (l + r) >> 1; pushdown(p); if (R <= mid) return query(ls(p), l, mid, L, R); if (L > mid) return query(rs(p), mid + 1, r, L, R); return query(ls(p), l, mid, L, R) + query(rs(p), mid + 1, r, L, R); } int get(int p, int l, int r, int pos) { if (l == r) return keyl(p); int mid = (l + r) >> 1; pushdown(p); if (pos <= mid) return get(ls(p), l, mid, pos); return get(rs(p), mid + 1, r, pos); } void modify(int p, int l, int r, int L, int R, int x) { if (L <= l && r <= R) return cover(p, x), void(); int mid = (l + r) >> 1; pushdown(p); if (L <= mid) modify(ls(p), l, mid, L, R, x); if (R > mid) modify(rs(p), mid + 1, r, L, R, x); pushup(p); return ; } void solve() { cin >> str; n = str.size(); build(1, 1, n); int ans = 1; while (lis(1) < n) { int split = lis(1); auto res = query(1, 1, n, 1, split); int len = res.len; modify(1, 1, n, 1, split - len + 1, 0); if (keyr(1) < 9) modify(1, 1, n, n, n, keyr(1) + 1); else { int pos = n - len(1); int x = get(1, 1, n, pos); modify(1, 1, n, pos, pos, x + 1); modify(1, 1, n, pos + 1, n, 0); } ans++; } cout << ans << endl; return ; } int main() { #ifdef LOCAL freopen("data.in", "r", stdin); freopen("mycode.out", "w", stdout); #endif ios :: sync_with_stdio(false); cin.tie(nullptr), cout.tie(nullptr); int T = 1; #ifdef TestCases cin >> T; #endif while (T--) solve(); return 0; }
本场唯一没有独立想出的题。
容易发现,对任意车站、任意方向,都是每
先考虑判断无解。对于单行线,
设
记
恒无交,即要求:
化简得
这也侧面说明了无解条件的合理性。如果区间长度超过
记
显然存在一种最优解,
记
点击查看代码
#include <cstdio> #include <iostream> #include <algorithm> using namespace std; // #define Debug // #define LOCAL // #define TestCases const int N = 1e5; const int L = N * 2 + 2; int n; long long k; long long t[N + 5]; int b[N + 5]; long long tmp[L + 5]; int cnt; const int SZ = L << 2; const long long Inf = 1e16; struct Node { long long key; int tag; }; Node node[SZ + 5]; #define ls(p) (p << 1) #define rs(p) (p << 1 | 1) #define key(p) node[p].key #define tag(p) node[p].tag void pushup(int p) { key(p) = min(key(ls(p)), key(rs(p))); return ; } void cover(int p) { tag(p) = 1; key(p) = Inf; return ; } void pushdown(int p) { if (tag(p)) { cover(ls(p)); cover(rs(p)); tag(p) = 0; } return ; } void build(int p, int l, int r) { if (l == r) return key(p) = -tmp[l], void(); int mid = (l + r) >> 1; build(ls(p), l, mid); build(rs(p), mid + 1, r); pushup(p); return ; } void modify(int p, int l, int r, int pos, long long val) { if (l == r) return key(p) = min(key(p), val), void(); int mid = (l + r) >> 1; pushdown(p); if (pos <= mid) modify(ls(p), l, mid, pos, val); else modify(rs(p), mid + 1, r, pos, val); pushup(p); return ; } void clr(int p, int l, int r, int L, int R) { if (L <= l && r <= R) return cover(p), void(); int mid = (l + r) >> 1; pushdown(p); if (L <= mid) clr(ls(p), l, mid, L, R); if (R > mid) clr(rs(p), mid + 1, r, L, R); pushup(p); return ; } long long query(int p, int l, int r, int L, int R) { if (L <= l && r <= R) return key(p); int mid = (l + r) >> 1; pushdown(p); long long res = Inf; if (L <= mid) res = min(res, query(ls(p), l, mid, L, R)); if (R > mid) res = min(res, query(rs(p), mid + 1, r, L, R)); return res; } long long dfs(int p, int l, int r) { if (l == r) return key(p) + tmp[l]; int mid = (l + r) >> 1; pushdown(p); long long res = Inf; res = min(res, dfs(ls(p), l, mid)); res = min(res, dfs(rs(p), mid + 1, r)); return res; } void solve() { cin >> n >> k; auto mod = [&](long long val) { return (val % k + k) % k; }; for (int i = 1; i <= n; i++) { cin >> t[i] >> b[i]; if (b[i] == 1 && t[i] + t[i] > k) return puts("-1"), void(); t[i] += t[i - 1]; tmp[++cnt] = mod(-2 * t[i]);//l tmp[++cnt] = mod(-2 * t[i - 1]);//r } tmp[++cnt] = 0; tmp[++cnt] = k - 1; sort(tmp + 1, tmp + cnt + 1); cnt = unique(tmp + 1, tmp + cnt + 1) - tmp - 1; build(1, 1, cnt); for (int i = 1; i <= n; i++) { if (b[i] == 2) continue; int l = lower_bound(tmp + 1, tmp + cnt + 1, mod(-2 * t[i])) - tmp; int r = lower_bound(tmp + 1, tmp + cnt + 1, mod(-2 * t[i - 1])) - tmp; if (l < r)//l = r -> [r + 1, cnt] + [1, l - 1] is illegal { long long res = query(1, 1, cnt, l + 1, r - 1); modify(1, 1, cnt, r, res); clr(1, 1, cnt, l + 1, r - 1); } else { long long res = Inf; if (l + 1 <= cnt) { res = query(1, 1, cnt, l + 1, cnt) + k; clr(1, 1, cnt, l + 1, cnt); } if (r - 1 > 0) { res = min(res, query(1, 1, cnt, 1, r - 1)); clr(1, 1, cnt, 1, r - 1); } modify(1, 1, cnt, r, res); } } long long ans = 2 * t[n] + dfs(1, 1, cnt); cout << ans << endl; return ; } int main() { #ifdef LOCAL freopen("data.in", "r", stdin); freopen("mycode.out", "w", stdout); #endif ios :: sync_with_stdio(false); cin.tie(nullptr), cout.tie(nullptr); int T = 1; #ifdef TestCases cin >> T; #endif while (T--) solve(); return 0; }
先升序排序,考虑贪心。最大的
归纳可得,答案即为
点击查看代码
#include <cstdio> #include <iostream> #include <algorithm> using namespace std; // #define Debug // #define LOCAL // #define TestCases const int N = 1e5, M = N * 3; int n, m; int a[M + 5]; void solve() { cin >> n; m = n * 3; for (int i = 1; i <= m; i++) cin >> a[i]; sort(a + 1, a + m + 1); long long ans = 0; for (int i = 1, j = m - 1; i <= n; i++, j -= 2) ans += a[j]; cout << ans << endl; return ; } int main() { #ifdef LOCAL freopen("data.in", "r", stdin); freopen("mycode.out", "w", stdout); #endif ios :: sync_with_stdio(false); cin.tie(nullptr), cout.tie(nullptr); int T = 1; #ifdef TestCases cin >> T; #endif while (T--) solve(); return 0; }
一个直接的想法是,应该从后往前执行操作,希望每个点只被染一次。
图上一个点的领域没有什么好的维护方法,大概只能暴力扩展,那么应以减少无效操作入手。对于
维护每个点的最大半径,双端队列
点击查看代码
#include <cstdio> #include <iostream> #include <algorithm> #include <vector> #include <cstring> #include <queue> #include <tuple> using namespace std; // #define Debug // #define LOCAL // #define TestCases constexpr int N = 1e5; int n, m, q; vector<int> e[N + 5]; int dfn[N + 5], col[N + 5]; typedef tuple<int, int, int> Info; deque<Info> dq; void solve() { cin >> n >> m; for (int i = 1, u, v; i <= m; i++) { cin >> u >> v; e[u].push_back(v), e[v].push_back(u); } cin >> q; for (int i = 1, u, d, c; i <= q; i++) { cin >> u >> d >> c; dq.emplace_front(u, d, c); } memset(dfn, -1, sizeof(dfn)); while (!dq.empty()) { int u, d, c; tie(u, d, c) = dq.front(); dq.pop_front(); if (!col[u]) col[u] = c; dfn[u] = d; d--; if (d < 0) continue; for (auto v: e[u]) { if (dfn[v] < d) dq.emplace_front(v, d, c); } } for (int i = 1; i <= n; i++) cout << col[i] << endl; return ; } int main() { #ifdef LOCAL freopen("data.in", "r", stdin); freopen("mycode.out", "w", stdout); #endif ios :: sync_with_stdio(false); cin.tie(nullptr), cout.tie(nullptr); int T = 1; #ifdef TestCases cin >> T; #endif while (T--) solve(); return 0; }
非常正确的随机化,拜谢
两个字符集无交的字符串拼起来,好串数也是相加。考虑随机一些短字符串凑出
。
首先应该手搓一个。 枚举第二个子序列的开头
,设 表示两个子序列依次以 结尾的合法串数量。 观察转移,
其实相当于一个以 为顶点的矩形内所有 之和( 因为上面是严格小于),可以边 边维护矩形前缀和,单次是 的
总。合法串数即 ,如果过程中串数已经大于 可以直接返回避免爆长整型
很大,串长限制较紧,肯定希望单串的”性价比“尽量高。这意味着,串长要短,字符集 要小。
好不好呢?简单计算知,长为 的有 个合法串。而用二进制拆分来凑,总长度会爆 ,原因是增长过快而不实用。
尝试,每一位等概率在 随机,发现当 时平均合法个数已达到 量级,够用了。
当然合法个数较少的串同样重要,用来补缺。
因此,考虑,每个长度随机 个并计算。求解用贪心,每次选一个最大的减掉。该做法在极限情况下需要 位,擦边球但确实能稳定通过。
还是执着于确定性做法?很简单,用固定的随机种子就好了!比如某八位质数。
点击查看代码
#include <cstdio> #include <iostream> #include <algorithm> #include <vector> #include <random> using namespace std; // #define Debug // #define LOCAL // #define TestCases constexpr int S = 200; constexpr long long Lim = 1e12; constexpr int Size = 2e4; typedef vector<int> arr; namespace Calc { long long f[S + 5][S + 5]; long long pre[S + 5][S + 5]; long long calc(arr a) { long long sum = 0; int len = a.size(); for (int s = 2; s <= len; s++)//start { for (int e1 = 1; e1 < s; e1++) f[e1][s] = (a[e1 - 1] == a[s - 1]); for (int e1 = 1; e1 < s; e1++) for (int e2 = s; e2 <= len; e2++) { if (a[e1 - 1] == a[e2 - 1]) f[e1][e2] += pre[e1 - 1][e2 - 1]; pre[e1][e2] = f[e1][e2] + pre[e1 - 1][e2] + pre[e1][e2 - 1] - pre[e1 - 1][e2 - 1]; sum += f[e1][e2]; if (sum > Lim) return Lim + 1; } for (int e1 = 1; e1 < s; e1++) for (int e2 = s; e2 <= len; e2++) f[e1][e2] = pre[e1][e2] = 0; } return sum; } } using Calc :: calc; namespace Gen { mt19937 rnd(19260817); arr generate(int len) { arr v(len); for (int i = 0; i < len; i++) v[i] = rnd() & 1; return v; } } using Gen :: generate; arr pool[Size + 5]; long long sum[Size + 5]; int index[Size + 5]; int sz; void init(int len, int tot = 400) { for (int t = 1; t <= tot; t++) { auto a = generate(len); auto res = calc(a); if (res > Lim) continue; sz++; pool[sz] = a; sum[sz] = res; index[sz] = sz; } return ; } int ans[S + 5], cnt; void add(arr a, int base) { for (auto v: a) ans[++cnt] = v + base; return ; } void solve() { for (int len = 2; len <= 50; len++) init(len); sort(index + 1, index + sz + 1, [&](int x, int y){ return sum[x] < sum[y]; }); long long n; cin >> n; int base = 1, it = sz; while (n) { while (sum[ index[it] ] > n) it--; int p = index[it]; n -= sum[p]; add(pool[p], base); base += 2; } cout << cnt << endl; for (int i = 1; i <= cnt; i++) cout << ans[i] << " "; cout << endl; return ; } int main() { #ifdef LOCAL freopen("data.in", "r", stdin); freopen("mycode.out", "w", stdout); #endif ios :: sync_with_stdio(false); cin.tie(nullptr), cout.tie(nullptr); int T = 1; #ifdef TestCases cin >> T; #endif while (T--) solve(); return 0; }
毫无道理的正解
固定一种构造,在此基础上调整。
构造,即一个排列 接着 。合法串的两部分一定分属前后,因此只需 的递增子序列数为 。
归纳构造,假设已经构造了,当前共 个合法。考虑 的两种放法: 二进制拆分,最多需要
位
代码略。
初始序列什么样子显然没用。将可交换的关系看作边,则这张
一个有
现在只需求出连通块。
- 同种颜色
判断与该颜色重量最轻的能否交换,同块的点一定可以通过它间接连通 - 异种颜色
类似的,判断与不同色的球中,重量最轻的能否交换
并查集维护。
点击查看代码
#include <cstdio> #include <iostream> #include <algorithm> using namespace std; // #define Debug // #define LOCAL // #define TestCases constexpr int N = 2e5, P = 1e9 + 7; constexpr int Inf = 0x3f3f3f3f; int n, x, y; int c[N + 5], w[N + 5]; int index[N + 5]; int fa[N + 5]; int find(int u) { if (fa[u] == u) return u; return fa[u] = find(fa[u]); } void init_dsu() { for (int i = 1; i <= n; i++) fa[i] = i; return ; } void link(int u, int v) { fa[find(u)] = find(v); return ; } int fac[N + 5], inv[N + 5]; int ksm(int d, int u) { int res = 1; while (u) { if (u & 1) res = 1ll * res * d % P; u >>= 1; d = 1ll * d * d % P; } return res; } void init_fac() { fac[0] = 1; for (int i = 1; i <= n; i++) fac[i] = 1ll * fac[i - 1] * i % P; inv[n] = ksm(fac[n], P - 2); for (int i = n - 1; i >= 0; i--) inv[i] = 1ll * inv[i + 1] * (i + 1) % P; return ; } int cnt[N + 5]; void solve() { cin >> n >> x >> y; w[0] = Inf; for (int i = 1; i <= n; i++) { cin >> c[i] >> w[i]; if (w[ index[c[i]] ] > w[i]) index[c[i]] = i; } init_dsu(); for (int i = 1; i <= n; i++) { if (w[i] + w[ index[c[i]] ] <= x) link(i, index[c[i]]); } sort(index + 1, index + n + 1, [&](int u, int v){ return w[u] < w[v]; }); for (int i = 1; i <= n; i++) { if (c[i] == c[ index[1] ]) { if (w[i] + w[ index[2] ] <= y) link(i, index[2]); } else { if (w[i] + w[ index[1] ] <= y) link(i, index[1]); } } init_fac(); for (int i = 1; i <= n; i++) index[i] = i; sort(index + 1, index + n + 1, [&](int u, int v){ return find(u) < find(v); }); int ans = 1; for (int l = 1, r = 1; l <= n; l = r + 1) { r = l; while (r + 1 <= n && find(index[r + 1]) == find(index[l])) r++; for (int i = l; i <= r; i++) cnt[ c[index[i]] ]++; ans = 1ll * ans * fac[r - l + 1] % P; for (int i = l; i <= r; i++) { ans = 1ll * ans * inv[ cnt[ c[index[i]] ] ] % P; cnt[ c[index[i]] ] = 0; } } cout << ans << endl; return ; } int main() { #ifdef LOCAL freopen("data.in", "r", stdin); freopen("mycode.out", "w", stdout); #endif ios :: sync_with_stdio(false); cin.tie(nullptr), cout.tie(nullptr); int T = 1; #ifdef TestCases cin >> T; #endif while (T--) solve(); return 0; }
前后缀的问题宜从序列考虑?
对于
考虑
中所有数对应的序列切分情况,组成树型结构,因为祖先的断点一定也是后代的断点。这片森林中,每棵树的高度不超过 。
问题转化为,在森林的每一层选择一个点,使得每个叶子都被覆盖。对所有的树根判断,如果第一层选它,能否实现。
可惜这个转化没法做。在树上合并信息(如果有某种做法)难以避免形如之类的转移复杂度,其中 为子树的深度(叶向)
突破口在于从序列考虑。
计算
枚举第一层选哪个,进而枚举全集的划分,判断
如果第一层有多于
总
点击查看代码
#include <cstdio> #include <iostream> #include <algorithm> using namespace std; // #define Debug // #define LOCAL // #define TestCases constexpr int N = 2e5, Lg = 18;//at most (/= 2) 18 times constexpr int S = 1 << Lg; int n, m, v[Lg + 5]; int x[N + 5]; int L[Lg + 5][N + 5], R[Lg + 5][N + 5]; int f[S + 5], g[S + 5]; #define P cout << "Possible" << endl #define NP cout << "Impossible" << endl void solve() { cin >> n >> v[0]; for (int i = 1; i <= n; i++) cin >> x[i]; m = __lg(v[0]) + 1; for (int i = 1; i <= m; i++) v[i] = v[i - 1] >> 1; for (int d = 0; d <= m; d++) { for (int l = 1, r = 1; l <= n; l = r + 1) { r = l; while (r + 1 <= n && x[r + 1] - x[r] <= v[d]) r++; for (int t = l; t <= r; t++) L[d][t] = l, R[d][t] = r; } } int cnt = 0; for (int i = 1; i <= n; i++) cnt += (L[0][i] == i); if (cnt > Lg) { for (int i = 1; i <= n; i++) NP; return ; } int s = (1 << m) - 1; f[0] = 0, g[0] = n + 1; for (int t = 1; t <= s; t++) { g[t] = n; for (int lst = 1; lst <= m; lst++) { if (!((t >> (lst - 1)) & 1)) continue; int prv = t ^ (1 << (lst - 1)); if (f[prv] == n) f[t] = n; else f[t] = max(f[t], R[lst][f[prv] + 1]); if (g[prv] == 1) g[t] = 1; else g[t] = min(g[t], L[lst][g[prv] - 1]); } } for (int l = 1, r = R[0][l]; l <= n; l = r + 1) { r = R[0][l]; int res = 0; for (int t = 0; t <= s && !res; t++) { if (f[t] >= l - 1 && g[s ^ t] <= r + 1) res = 1; } for (int i = l; i <= r; i++) { if (res) P; else NP; } } return ; } int main() { #ifdef LOCAL freopen("data.in", "r", stdin); freopen("mycode.out", "w", stdout); #endif ios :: sync_with_stdio(false); cin.tie(nullptr), cout.tie(nullptr); int T = 1; #ifdef TestCases cin >> T; #endif while (T--) solve(); return 0; }
方向是套路的。先思考判定合法,再考虑计数。
先排序。
判合法
题解区有一句话很好,当必要条件堆得足够多时,它(们)就是充要条件。
考虑取值范围。
是 个数的中位数,即各有 个数不大于、不小于它。因此 在 中的排名必须在 中。 再从过程入手。每次加两个不好思考,反过来,考虑每次删去两个。如果原来的中位数是
,此时序列是 ,则删除后 要么不变,要么是 在 中的前驱或后继,即至多变化一位。
形式化地说,使得 介于 之间(开区间)。 这两条已经足够了。归纳证明合法性:删两个,说明条件不变。
设当前中位数为,左右各有 个数。则目前一共出现的中位数有 个。
:除了 ,还有 个中位数。而初始左右各有 个,因此两侧总能各找出一个未出现的数删去。
:不妨设 ,则要删去两个不超过 的数。显然其中一个可以是 本身,而且这样是优的。在 个中位数中, 各占去一个,又有 ,则 左侧至多有 个,也一定能找出一个未出现的数删去。 或许会问,上述证明过程中哪里用到两个必要条件。左右各有
个数需要第一个来保证,而第二条确保删完之后第一条依然成立,这样归纳就能继续下去。
计数
还是删数好想。
设
表示从后往前填数,考虑到正数第 个,这时在排名为 的这些数中,有 种数小于 、 种数大于 ,并且这些数还没有被第二个必要条件排除掉。
为什么是数的种类?原序列中有相同的数,对于一串相同的,不妨钦定它们对应的是同一个数,以避免重复计入。 从
到 ,第一个条件说明取值范围扩大,有两个数会分别加入 ,但只有该数值第一次出现才能计入。这通过区间内与它们相邻的数与二者是否相同来判断。如果二端均相同呢?那说明取值范围内所有数均相同,在初始化时已计入,也没有问题。
然后是的移动。要么不变,要么移动。对于后一种情况,比如右移,左侧合法取值会增加一(即 本身),右侧至少要减少一(因为 不算在内)。此时不需考虑具体如何删除,只有这两个必要条件是要考虑的。
总
点击查看代码
#include <cstdio> #include <iostream> #include <algorithm> using namespace std; // #define Debug // #define LOCAL // #define TestCases constexpr int N = 50, M = N << 1; constexpr int P = 1e9 + 7; int n, m; int a[M + 5]; int f[N + 5][M + 5][M + 5]; void addto(int &x, int y) { x += y; if (x > P) x -= P; return ; } void solve() { cin >> n; m = n + n - 1; for (int i = 1; i <= m; i++) cin >> a[i]; sort(a + 1, a + m + 1); f[n][0][0] = 1; for (int t = n; t > 1; t--) { int dl = (a[t] != a[t - 1]); int dr = (a[n + n - t] != a[n + n - t + 1]); for (int l = 0; l <= m; l++)//actually, is 2(n - t + 1) - 1, which is the length of the interval for (int r = 0; r <= m; r++) { int L = l + dl, R = r + dr; addto(f[t - 1][L][R], f[t][l][r]); for (int k = 1; k <= L; k++)//at least 1, because the new median is no longer belongs to the left addto(f[t - 1][L - k][R + 1], f[t][l][r]);//cur median is still useful, so + 1 for (int k = 1; k <= R; k++) addto(f[t - 1][L + 1][R - k], f[t][l][r]); } /* O(n^3) version for (int R = m; R >= dr + 1; R--) for (int L = m, sum = 0; L >= max(0, dl - 1); L--) { addto(sum, f[t][L - dl + 1][R - dr - 1]); addto(f[t - 1][L][R], sum); } for (int L = m; L >= dl + 1; L--) for (int R = m, sum = 0; R >= max(0, dr - 1); R--) { addto(sum, f[t][L - dl - 1][R - dr + 1]); addto(f[t - 1][L][R], sum); } */ } int ans = 0; for (int l = 0; l <= m; l++) for (int r = 0; r <= m; r++) addto(ans, f[1][l][r]); cout << ans << endl; return ; } int main() { #ifdef LOCAL freopen("data.in", "r", stdin); freopen("mycode.out", "w", stdout); #endif ios :: sync_with_stdio(false); cin.tie(nullptr), cout.tie(nullptr); int T = 1; #ifdef TestCases cin >> T; #endif while (T--) solve(); return 0; }
是子段不是子序列,贪心即可。
点击查看代码
#include <cstdio> #include <iostream> #include <algorithm> using namespace std; // #define Debug // #define LOCAL // #define TestCases const int N = 1e5; int n; int a[N + 5]; void solve() { cin >> n; for (int i = 1; i <= n; i++) cin >> a[i]; int ans = 0; for (int l = 1, r = 1; l <= n; l = r + 1) { ans++; r = l; while (r + 1 <= n && a[r + 1] == a[l]) r++; l = r; while (r + 1 <= n && (a[r + 1] == a[r] || (a[l] < a[l + 1]) == (a[r] < a[r + 1]))) r++; } cout << ans << endl; return ; } int main() { #ifdef LOCAL freopen("data.in", "r", stdin); freopen("mycode.out", "w", stdout); #endif ios :: sync_with_stdio(false); cin.tie(nullptr), cout.tie(nullptr); int T = 1; #ifdef TestCases cin >> T; #endif while (T--) solve(); return 0; }


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!