面向对象程序设计——基于JML的地铁系统
本次实验的主要内容是根据JML的需求描述,完成一个支持增删检查以及多种最短路查询的地铁系统设计。主要运用到了JML的相关语法,以及基本的图论知识。
1. JML理论基础
JML是Java Modeling language的简称,是一种对Java程序开发的一种接口规格语言,它使用了前置后置条件、不变式等方法来实现标准化的契约式设计,来正式地描述Java模块的行为,防止了模块设计者的自然语言的语义模糊。
基本JML语法提供以下关键字和表达式
-
方法规格
-
requires 定义了一个方法运行前需要满足的先决条件。
-
ensures 定义了方法运行结束后需要满足的后置条件。
-
assignable
定义了方法的副作用范围,即方法可以修改的类成员。
-
signals 定义了方法抛出给定Exception时的后置条件。
-
signals_only 定义在给定前置条件成立时可能抛出的异常。
-
pure 声明一个方法是没有副作用的。此外,纯方法应始终正常终止或抛出异常。
-
also 用于多个规则,或是子类继承父类时增加新的规则。
-
-
类型规格
-
invariant 定义类的不变属性,在任何时刻对象的实例数据都必须满足。
-
constraint
定义任何时刻修改对象实例数据所必须满足的要求
-
-
其他规格
-
loop_invariant 为循环定义循环不变量。
-
assert 定义JML 断言。
-
spec_public 为规范目的声明受保护或私有变量public。
-
-
原子表达式
-
\not_modify(<expression>)
表示<expression>在方法执行期间取值是否发生变化
-
\not_assigned(<expression>)
表示<expression>在方法执行期间是否被赋值
-
\result 表示后面的方法的返回值的标识符。
-
\nonnullelements(<container>)
表示<container>储存的对象中不会出现null
-
\type(type)
返回类型type对应的Class
-
\typeof(<expression>)
返回<experssion>对应的类型
-
\old(<expression>) 表示进入方法之前表达式的值的修饰符<expression>。
-
-
量化表达式
-
(\forall <decl>; <range-exp>; <body-exp>) 全称量词。
-
(\exists <decl>; <range-exp>; <body-exp>) 存在量词。
-
(\sum \product \max \min \num_of<decl>; <range-exp>; <body-exp>)
分别为对应范围内表达式的连加、连乘、最大值、最小值以及满足条件的个数
-
-
操作符
-
a ==> b b<==a a 可推出 b
-
a <==> b a 当且仅当 b
-
a<:b
a是b的子类型
-
\noting \everthing
表示空集和全集
-
二. 部署JMLUnit
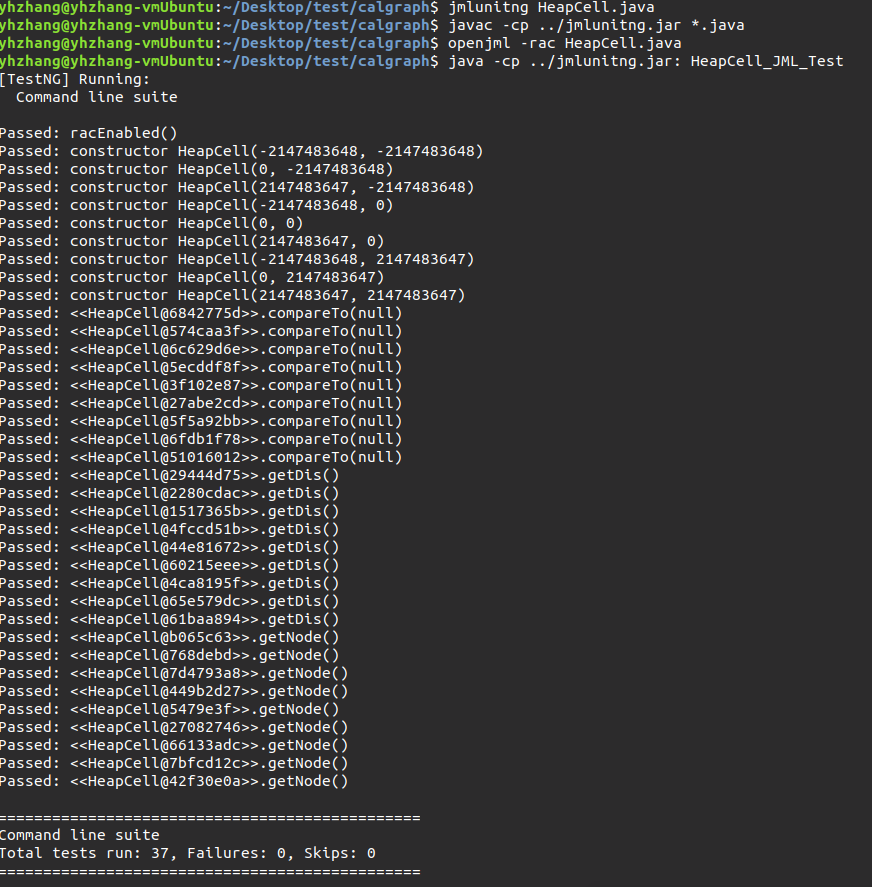
我抽取了我代码中的一个为Dijkstra进行堆优化而创建的类HeapCell.java,为它加入了其代码对应的JML,并使用JMLUnitNg进行了测试。
1 //HeapCell.java 2 public class HeapCell implements Comparable<HeapCell> { 3 public Integer node; 4 public Integer dis; 5 6 //@ requires dis>=0; 7 public HeapCell(int node, int dis) { 8 this.dis = dis; 9 this.node = node; 10 } 11 12 //@ ensures \result == dis; 13 public/*@pure@*/ int getDis() { 14 return dis; 15 } 16 17 //@ ensures \result == node; 18 public/*@pure@*/ int getNode() { 19 return node; 20 } 21 22 //@ also 23 //@ requires o != null; 24 //@ ensures \result == dis - o.getDis(); 25 @Override 26 public/*@pure*/ int compareTo(HeapCell o) { 27 if(o == null){ 28 return 0; 29 } 30 return this.dis - o.dis; 31 } 32 }
运行的代码与最后结果如图:
三. 代码架构设计
本次实验是根据规格来完成设计,所以很大程度上的架构是已经被设计好的,我们更多的是做一些数据结构上的架构设计,另外在第二次及第三次实验中涉及到的图论计算部分是需要自己独立架构设计的。
在第一次作业中,主要是需要对MyPath和MyPathContainer中的数据存储方式进行设计。对于MyPath,其既有对结点顺序访问的需求,同时也有无视顺序和重复查找结点的需求,那么就使用ArrayList和HashSet两个数据结构进行存储,ArrayList负责顺序访问,HashSet则负责与顺序以及是否重复无关的访问请求。在MyPathContainer中,对于Path与id相互转换的需求,使用两个HashMap分别从Path映射到id和从id映射到map;对于无视顺序和重复性查询容器内结点个数的请求,为了降低查询的复杂度,使用HashMap记录各种节点的出现次数,并在每次增加和除去Path时进行统计处理,则查询时直接返回该结构的大小即可。以上的主要思想是以空间换时间,即就是为了加快程序的速度,根据不同的需求设计不同的数据结构,在程序内冗余地存在,这样加大了内存存储的需求,但降低了运行时间的需求。
在第二次作业中,增加的需求主要是在图内进行最短路的查询,我决定使用堆优化的Dijkstra进行解决,那么就需要建立一个邻接表来进行处理。我将这一套图论相关的内容封装为了一个CalGraph类,类中使用addPath和removePath对图进行更改,每次更改后,对新图跑一遍完整的Dijkstra,之后的查询操作就直接从储存好的数据结构中查询即可。其中为了方便,我使用了大量的HashMap对数据进行存储,在避免了下标转换的同时,也引入了大量的索引复杂度,虽然最后达到了作业需要的速度,但远远慢于堆优化的Dijkstra应该有的速度。
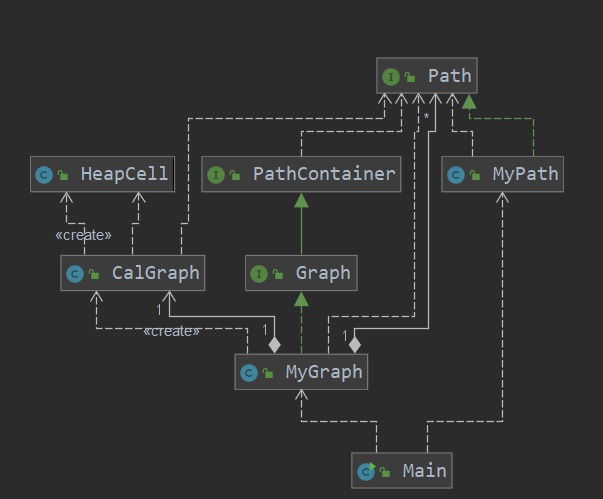
在第三次作业中,增加的需求主要是不同类型最短路的查询,其中包括最少票价、最小不满意度、最少换乘等,这些需求实际上都可以转化为最短路径来解决,只需要针对不同的情况给边赋予不同的权值即可。真正导致难度加大的是加入了不同Path之间换乘的概念,说到换乘的处理,第一个想到的应该就是拆点,简单来说就是将不同path经过的同一个结点拆成分属于不同path的不同节点,那么这些结点之间的边就体现了换乘这一概念,给其加上不同的权值就可以达到不同的需求。这一想法是自然和直接的,但由于我在之前的设计中没有对点进程重新的编码映射,所以在拆点时会一些难办。这时我看到了wjy等大佬提出的算法,即不用拆点,而是对于每个path在其内部将每个点直接连起来,权值设为原权值+换乘权值,这样构成的图跑最短路后,再减去一个换乘权值,就满足了需要考虑换乘的需求。另外对于连通块的查询,就使用路径优化的并查集来维护就可以。
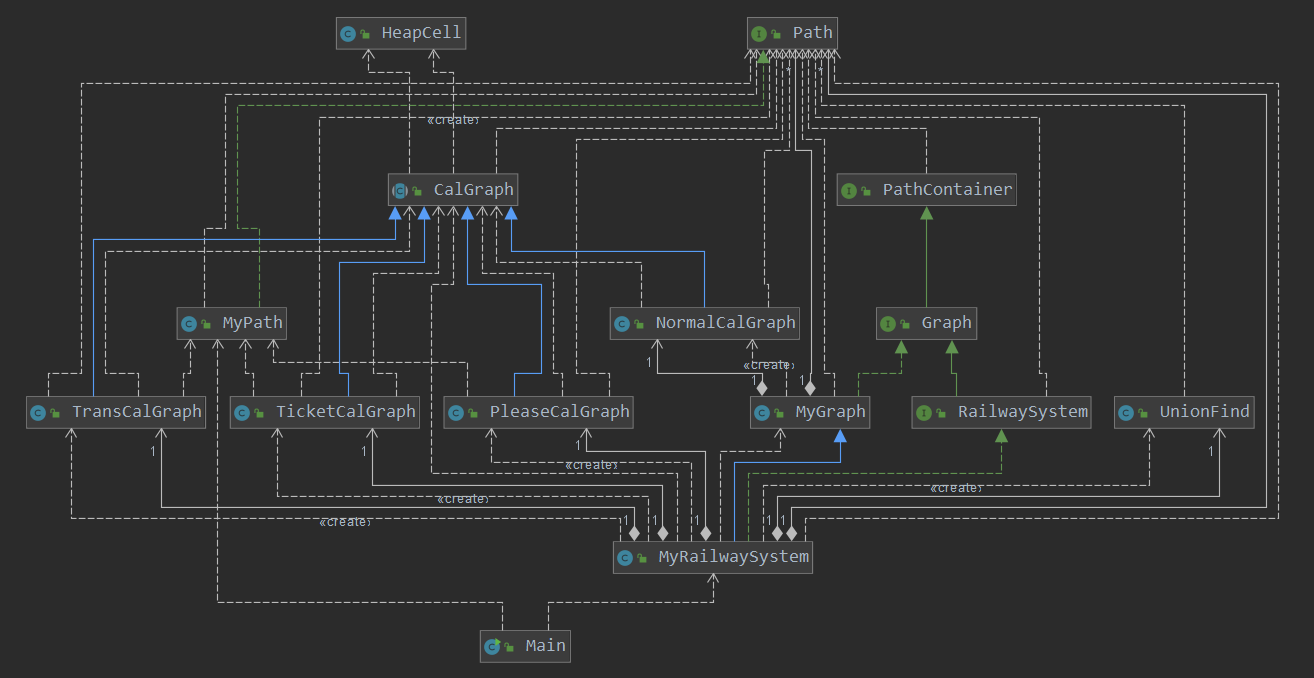
具体地,再设计上我延续了上一次地想法,使用CalGraph对图的功能进行封装,针对不同的需求,建立NormalCalGraph, PleaseCalGraph, TicketCalGraph, TransCalGraph四个类,他们分别都继承了CalGraph类,针对不同的需求他们只需要重载父类的addPath和removePath两个类即可,非常的方便快捷并且清晰。另外针对联通块,就单独建立一个UnionFind类来完成一个简单的并查集即可。最后,MyRailwayStation继承了MyGraph,重载MyGraph的addPath和两个removePath方法,MyGraph完全不用改动,在MyRailwayStation内实例化上面提到的五个类,之后通过其接口进行增删查操作即可。
所以本次实验是这么多次实验以来重构率最小的一次,第二次可以完全使用第一次的代码这不用多说,第三次也基本上90%重用了第二次的代码,其中所作的改动主要在在第三次作业中我为了提高Dijkstra的效率,没有选择像上次一样每次更改图就完全跑一遍最短路,而是利用Dijkstra可以缓存的特性,在每次查询时再进行最短路,并且把计算出的值缓存起来,以减少下次的计算,最后发现效果很好。另外,由于我Dijstra最短路方法并不是一个静态方法,不适用于对Path内部进行最短路的求解,我再CalGraph里单独写了一个Floyd的静态最短路方法供MyRailwayStation调用。除了以上两个功能上的改进和需求外,其他代码和架构都基本可以完全复用。
四. BUG及修复
第一次作业由于较为简单,线下的编码及调试和线上的测试和互测中均没有发现什么非常有特点的bug。第二次的作业中情况也相似,在自己的编码中出现的一些小问题也被很快的解决了。
第三次作业较为复杂,问题就有很多了,以下均是在线下测试中发现的问题。
-
我的图在removePath时需要将map对象初始化,之后再重新建图,但由于我子类中的map获取的是父类map的引用,而我再初始化时直接将子类的map置为一个new HashMap<>(),这样其实只是将子类的map对象指向了一个新的HashMap对象,而并没有对父类原本的map产生任何影响。发现之后,我使用map.clear(),即就解决了这个问题。
-
这个bug比较弱智,我在addPath的一个双重循环里循环里循环变量把i和j反了,调了我好一阵,改起来倒是很容易。所以,写代码的时候一定要认真啊!并且,少用i/j这种没有特点的C语言风格变量名。
-
这个bug是命名的锅,我在对dijkstra进行缓存优化时,把我的两个HashMap:distant和dis用混了,导致了这个同样非常难de的bug,这也提醒我变量命名要清晰明了有特点!!!
五. 关于规格的心得体会
