

ShardingSphere实战
前言
本文主要从sharding最新版本5.1.2版本入手搭建,按主键ID和时间进行分表。
本文主要介绍搭建过程,有兴趣了解shardingsphere的同学可以先自行查阅相关资料。
shardsphere官网:https://shardingsphere.apache.org/index_zh.html(建议下载master文档进行学习)
github地址:https://github.com/apache/shardingsphere.git
gitee地址:https://gitee.com/Sharding-Sphere/sharding-sphere.git
正文
这里搭建的框架采用 springboot2 + shardingsphere5 + mybatisplus(不用写sql) + mysql(druid连接池)
1、初始化SQL脚本(需要的自行前往文末项目地址获取)
● 示例中有user表和order表,user表按id分片,order表按时间进行年月分片。
● 注意:分表需要自行预创建,这里建议写个执行器创建
2、项目引入pom依赖(这里选的版本未发现冲突)



<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.1.2</version>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.2.2</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.2</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.11</version>
</dependency>
3、进行yml配置
● 需要加上spring.shardingsphere.props.sql-show = true , 打印sharding执行的sql,便于观察理解分表的原理,生产环境可选择关闭。
● 这里主要是用order表根据年月进行分表,因考虑到需要兼容历史表,所以这里逻辑分表需包含历史表名,具体看配置项actual-data-nodes。
● 一般建议跨两个表进行查询,比如这里是按照月份分表,则建议限制查询时间跨度最大为一个月,这样最多跨两个逻辑分表进行查询,性能会提高很多。
spring: application: name: demo-shardingsphere shardingsphere: # 打印执行sql props: sql-show: true # 数据源配置 datasource: names: test test: type: com.alibaba.druid.pool.DruidDataSource driverClassName: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/ss_test?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8 username: root password: root # 分片规则 rules: sharding: # 分片策略 sharding-algorithms: # 自定义分片策略 order_inline: type: class_based props: strategy: standard algorithmClassName: com.demo.config.sharding.algorithm.OrderTableAlgorithm tables: # 需要进行分片的逻辑表名前缀 t_order: # 逻辑分表 actual-data-nodes: test.t_order,test.t_order_$->{2022..2025}0$->{1..9},test.t_order_$->{2022..2025}1$->{0..2} table-strategy: standard: # 分表的字段 sharding-column: create_date # 自定义的分片策略名 sharding-algorithm-name: order_inline # 下面是按主键进行分表,规则比较简单,自定义表达式即可 # sharding-algorithms: # user_inline: # type: inline # props: # algorithm-expression: user_$->{id % 2} # tables: # user: # actual-data-nodes: test.user_$->{0..1} # table-strategy: # standard: # sharding-column: id # sharding-algorithm-name: user_inline # key-generate-strategy: # column: id # key-generator-name: snowflake # key-generators: # snowflake: # type: SNOWFLAKE server: port: 8889 # 定义跨表时间查询范围,小于min时间,则联查历史表,不允许大于max时间,具体可看自定义的分片策略实现 sharding: table: user: base: date: min: 2022-08-01 00:00:00 max: 2023-01-31 23:59:59 #logging: # level: # com.demo.mapper: debug
4、自定分片策略
● 这里采用jdk8的新时间特性LocalDateTime,需要与定义的分表字段类型对应上。
● sharding5使用了新的分片对象(5之前使用PreciseShargingAlgorithm),查询和插入都可以在一个对象里配置。
● 考虑到有些项目已经是在线上运行的项目,需要兼容历史表,这里配置中做了判断,需自行配置分表投产的时间作为区分,历史表数据不动,新数据采用分表插入和查询。
private static final DateTimeFormatter dateFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"); private static final DateTimeFormatter monthFormatter = DateTimeFormatter.ofPattern("yyyyMM"); /** * 获取查询对应分表名 * @param collection * @param preciseShardingValue * @return */ @Override public String doSharding(Collection<String> collection, PreciseShardingValue<LocalDateTime> preciseShardingValue) { LocalDateTime date = preciseShardingValue.getValue(); if (date == null) { return collection.stream().findFirst().get(); } String tableName = preciseShardingValue.getLogicTableName(); // 如果查询范围包括基础表,则需要联合基础表进行查询 LocalDateTime minBaseDate = LocalDateTime.parse(StaticValue.userBaseTableMinDate, dateFormatter); if (date.isAfter(minBaseDate)) { String tableSuffix = date.format(monthFormatter); tableName = tableName.concat("_").concat(tableSuffix); } String t = tableName; return collection.stream().filter(str -> str.equals(t)).findFirst().orElseThrow(() -> new RuntimeException(t + "分表不存在")); } /** * 范围查询获取所有分表 * * @param collection * @param rangeShardingValue * @return 分表集合 */ @Override public Collection<String> doSharding(Collection collection, RangeShardingValue rangeShardingValue) { String logicTableName = rangeShardingValue.getLogicTableName(); Range<LocalDateTime> valueRange = rangeShardingValue.getValueRange(); Set<String> tableRange = extracted(logicTableName, valueRange.lowerEndpoint(), valueRange.upperEndpoint()); return tableRange; } /** * 根据时间范围获取分表集合 * * @param logicTableName * @param lowerEndpoint * @param upperEndpoint * @return */ private Set<String> extracted(String logicTableName, LocalDateTime lowerEndpoint, LocalDateTime upperEndpoint) { Set<String> rangeTable = new HashSet<>(); // 如果查询范围包括基础表,则需要联合基础表进行查询 LocalDateTime minBaseDate = LocalDateTime.parse(StaticValue.userBaseTableMinDate, dateFormatter); LocalDateTime maxBaseDate = LocalDateTime.parse(StaticValue.userBaseTableMaxDate, dateFormatter); if (lowerEndpoint.isBefore(minBaseDate)) { lowerEndpoint = minBaseDate; rangeTable.add(logicTableName); } if (upperEndpoint.isAfter(maxBaseDate)) { throw new RuntimeException("结束时间不在当前时间内"); } // 便利所有分表 while (lowerEndpoint.isBefore(upperEndpoint)) { String tableName = logicTableName.concat("_").concat(lowerEndpoint.format(monthFormatter)); rangeTable.add(tableName); lowerEndpoint = lowerEndpoint.plusMonths(1); } // 可能开始时间累加后与结束时间一致 String tableName = logicTableName.concat("_").concat(upperEndpoint.format(monthFormatter)); rangeTable.add(tableName); return rangeTable; }
5、自定义接口测试
● 接口定义请自行参考文末项目源码,这里直接上测试结果图
测试场景一:插入一条2022年10月份数据
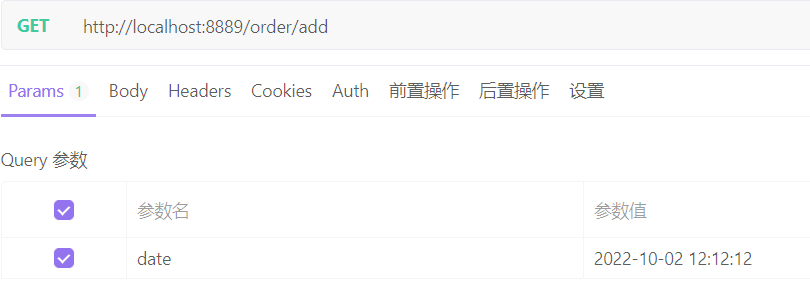
sharding运行过程

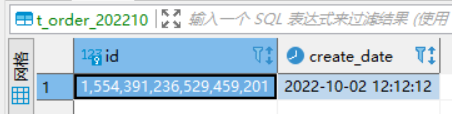
执行结果,插入到表t_order_202210
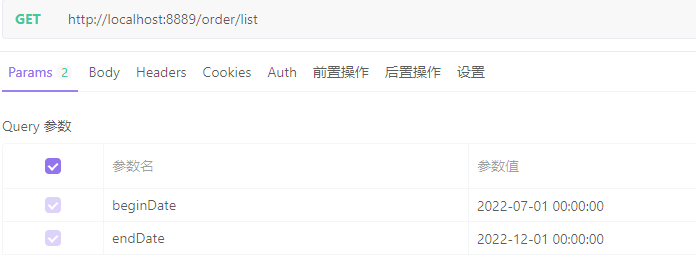
测试场景二:范围查找2022-07-01至2022-12-01
sharding执行过程
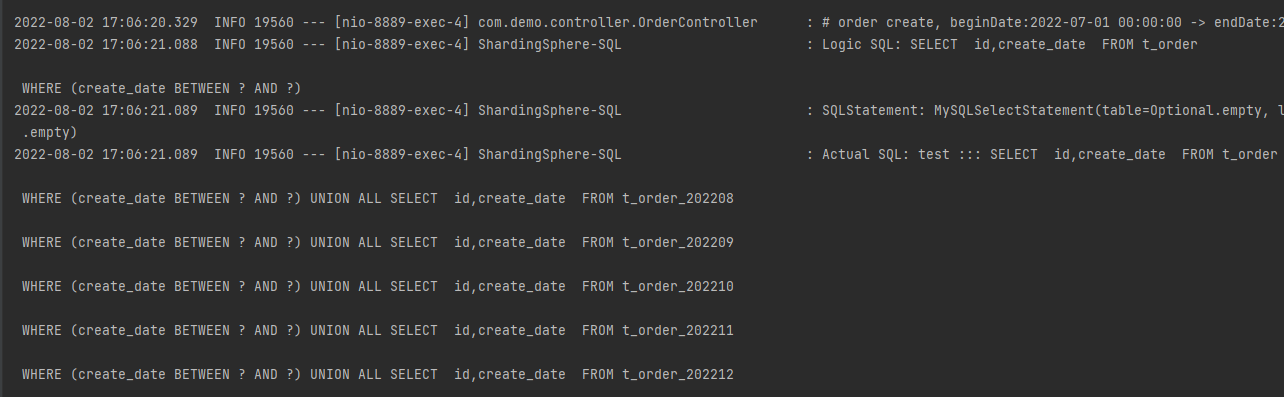
执行结果,可以观察到我们刚插入的数据,另外一条是之前测试插入的
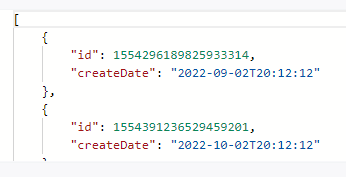
至此,本片文章结束,有兴趣的同学可以一起讨论,谢谢。
有兴趣可参考完整项目地址:https://gitee.com/yhc910/demo-shardingsphere
实战注意点(实时更新):
1、druid连接池属性,jdbc-url改为url
2、sharding-algorithm-name,注意algorithm后面不要加s,后面debug源码才找到问题
3、数据源配置url后面的属性,不要连着两个&&,不然会报错无效数组


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通