
【论文集合】curriculum learning总结/课程学习论文
Curriculum Learning主要有两个关键:①训练样本的难度定义;②训练的策略
本文总结一下看过的不同论文中出现的训练策略或者样本难度,主要与NMT相关。
持续更新。。。
2020之前的论文
Curriculum Learning
在shape recognition任务上是达到switch epoch或者直到触发early stopping换难的数据
Curriculum Learning and Minibatch Bucketing in Neural Machine Translation
分为多个bin,当第一个bin的数据被取得剩下第二个bin的一半,添加第二个bin的数据,从两个bin剩下的样例中取,直到剩下的和第三个bin样例数一样。以此类推
Teacher-Student Curriculum Learning 2017
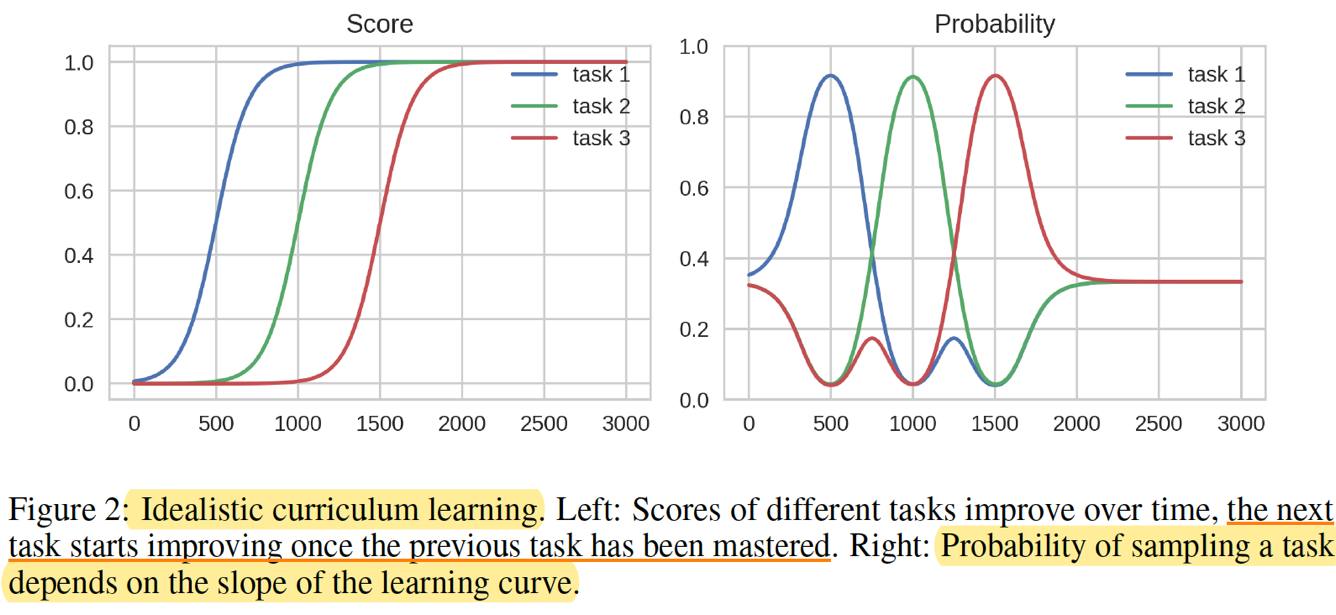
1.At first, the Teacher has no knowledge so it samples from all tasks uniformly.
2. When the Student starts making progress on task 1, the Teacher allocates more probability mass to this task.
3. When the Student masters task 1, its learning curve flattens and the Teacher samples the task less often. At this point Student also starts making progress on task 2, so the Teacher samples more from task 2.
4. This continues until the Student masters all tasks. As all task learning curves flatten in the end, the Teacher returns to uniform sampling of the tasks.
An Empirical Exploration of Curriculum Learning for Neural Machine Translation 2018
将数据排序,然后分为多个shard,训练的每个phase增加一个shard的数据。
- one-best score(训练一个更简单的辅助翻译模型)
给定源句,计算最佳翻译中单个词的预测概率乘积
- 句长、词频
句长:源句、目标句、前两者之和
词频:平均词频排名、最大词频排名 可以设置阈值分类。
论文中样本按难度排序后按照Jenks Natural Breaks分类方法把样本分为shards,让shard间差距大,shard内差距小
下图的时间轴竖着,颜色越浅代表样本越简单。
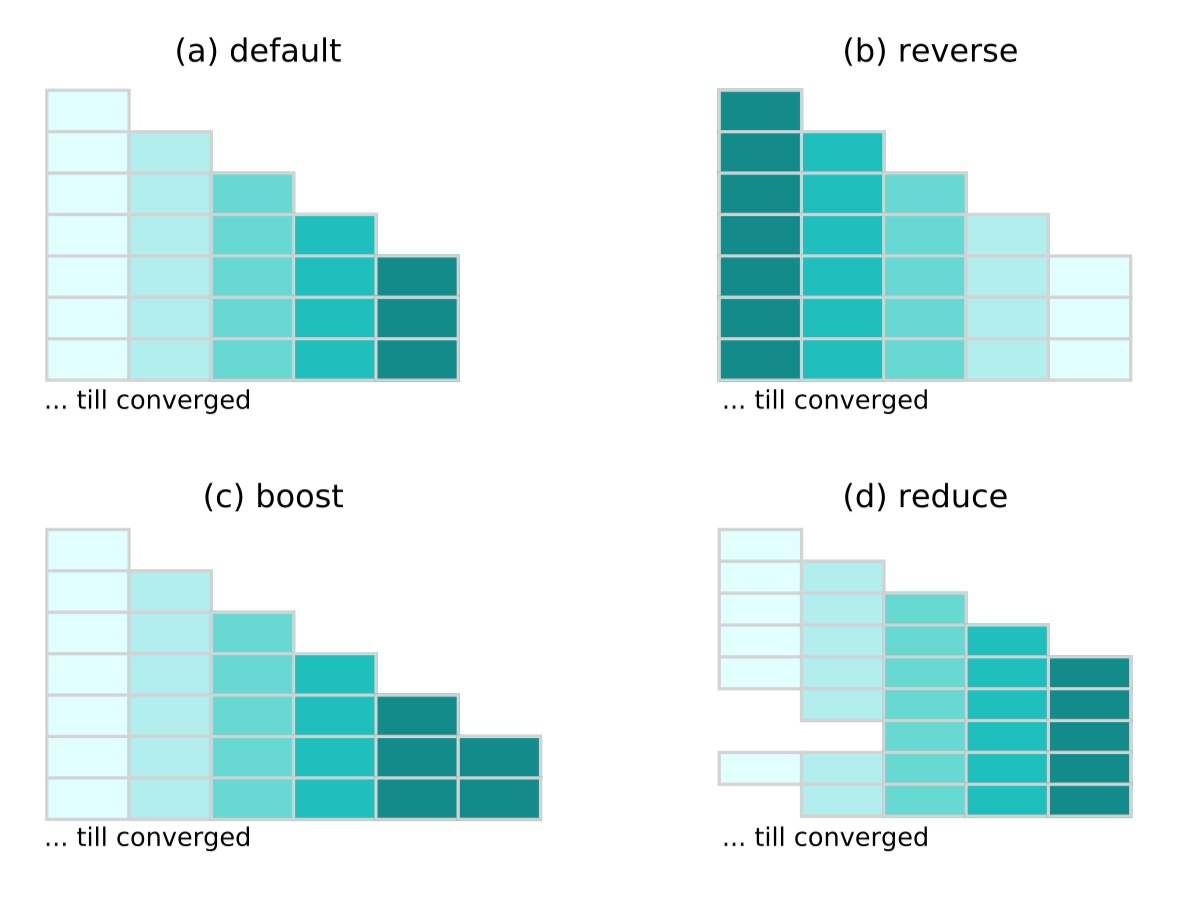
到达curriculum update frequency(文中是1000个mini batch = checkpoint frequency,更新一次课程学习阶段) default、reverse、boost、reduce、
Dynamic Curriculum Learning for Imbalanced Data Classification 2018
将数据分为几个shard,按概率采样,有schedule调整概率
样本按类别分类,按各类别包含的样本数目升序排列已分类的样本,得到真实数据集的类别比例Dtrain。
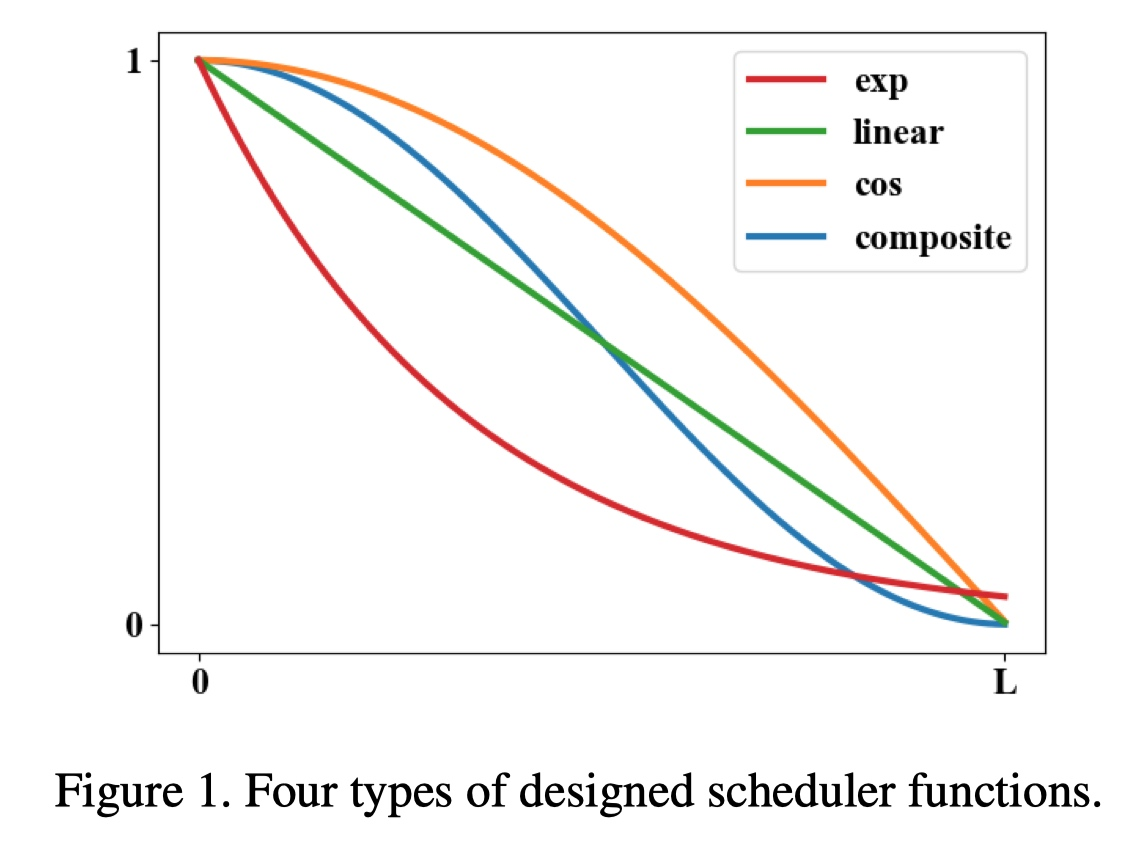
L是总epoch数。输入表示当前训练epoch的进度变量l,输出在[1-0]之间单调递减的schedule function(SF)值g(l);下图SF曲线的凹凸和斜率表明的学习速度,先快后慢、先慢后快、恒定、组合速度。
当l=0时,g(l)=1,各类别样本数目不均衡;l=L时,g(l)=0,各类别样本数目相等,均衡分布。实验中cos函数(convex)效果最好:即从开始慢慢的学习分布不均衡的数据,再到后面快速学习均衡分布的数据。![]()
目标样本分布Dtarget:![]()
当epoch=l,由g(l)的值会得到当前epoch对应的目标样本分布(按照xx比例),当l=0时,g(l)=1,当前epoch目标样本分布=原始数据集样本分布,各类别样本数目不均衡;l=L时,g(l)=0,当前epoch目标样本各类别分布=1:1:1...即各类别样本数目相等,均衡分布。假设SF是linear曲线,当l=0.5L,g(l)=0.5, 当前epoch目标样本分布=原始数据集分布0.5,各类别样本数稍微均衡了一点。
再由目标样本分布和当前样本分布(前一次的目标样本分布?)得到损失函数

Simple and Effective Curriculum Pointer-Generator Networks for Reading Comprehension over Long Narratives
当没有提升时,换部分数据到简单的数据set内,直到所有数据都被换,再将整个数据集换成另一个。

On The Power of Curriculum Learning in Training Deep Networks 2019
图片分类任务
scoring function + pacing function
两种score函数:
- transfer score function:在Imagenet上预训练感知机,用它跑每张图片,再用倒数第二层的激活层作为特征向量;用特征向量训练一个classifier(RBF SVM),自信得分作为困难度分数。用其他网络在Imagenet上训练的老师和可以得到类似的结果
- self-taught score function:【与自步学习区分】自步学习是基于对应当前假设(or网络)的loss设计scoring函数,根据当前假设给更低cost的样本更大的权重;self-taught学习是基于对应(无CL)目标假设的loss设计打分函数:无cl训练网络,得到的分类器再从头训练相同的网络,过程可以repeat。但一旦分错样本,错误困难会累积。
pacing function:
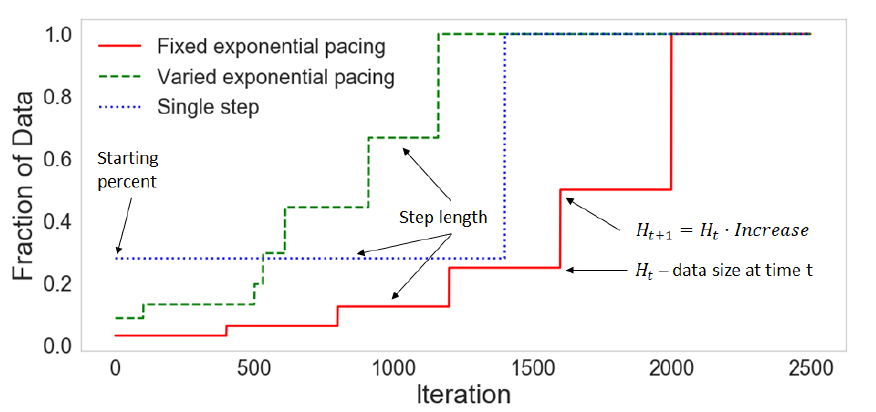
单调递增,简单样本随之减少。有三种,图也见下:
- Fixed exponential pacing:固定学习轮数,指数型的增加训练数据。

- Varied exponential pacing:每个step,学习轮数vary。
- Single-step pacing:mini-batche最初以固定比例从简单样本中采样,然后像往常一样从整个数据集采样。

Dynamically Composing Domain-Data Selection with Clean-Data Selection by “Co-Curricular Learning” for Neural Machine Translation 2019
领域+噪音两个方面
让提出的co-CL逼近真实课程(领域内受信的平行数据),在领域内和领域外干净样本上逐步训练模型(假设无领域内的受信平行语料)
每次选择的数据比率topλ ![]() 。单调递减的光滑曲线控制当前可用于训练数据的大小。
。单调递减的光滑曲线控制当前可用于训练数据的大小。

EM -style 优化
目的是:在迭代的提升去噪选择的同时不损害领域选择的质量
- 第 i 轮,首先生成一个具体课程,使用动态重分配;

- 在原始的噪音NMT上微调,生成参数θ*来替代Φ中干净的θ组件;
- 新的θ与原始的θ比较,有一个得分;
- 更新后的Φ和受限φ一起作用生成下一轮新课程 过程中只更新了Φ
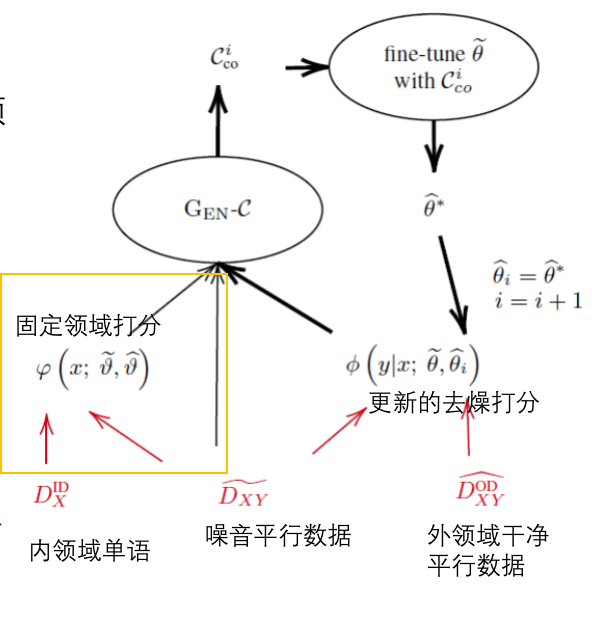
Curriculum Learning for Domain Adaptation in Neural Machine Translation 2019
延续18年的论文 An Empirical Exploration of Curriculum Learning for Neural Machine Translation,只不过用在机器翻译领域适应中。
样本按难度(领域相关度)排序,再分成shard,每个训练的phase在前一次的基础上增加一个shard。
每个课程学习阶段设为1000个batch,内外领域共40个shards,in domain算一个shards
实验结果对超参的设置非常敏感。
Competence-based Curriculum Learning for Neural Machine Translation 2019
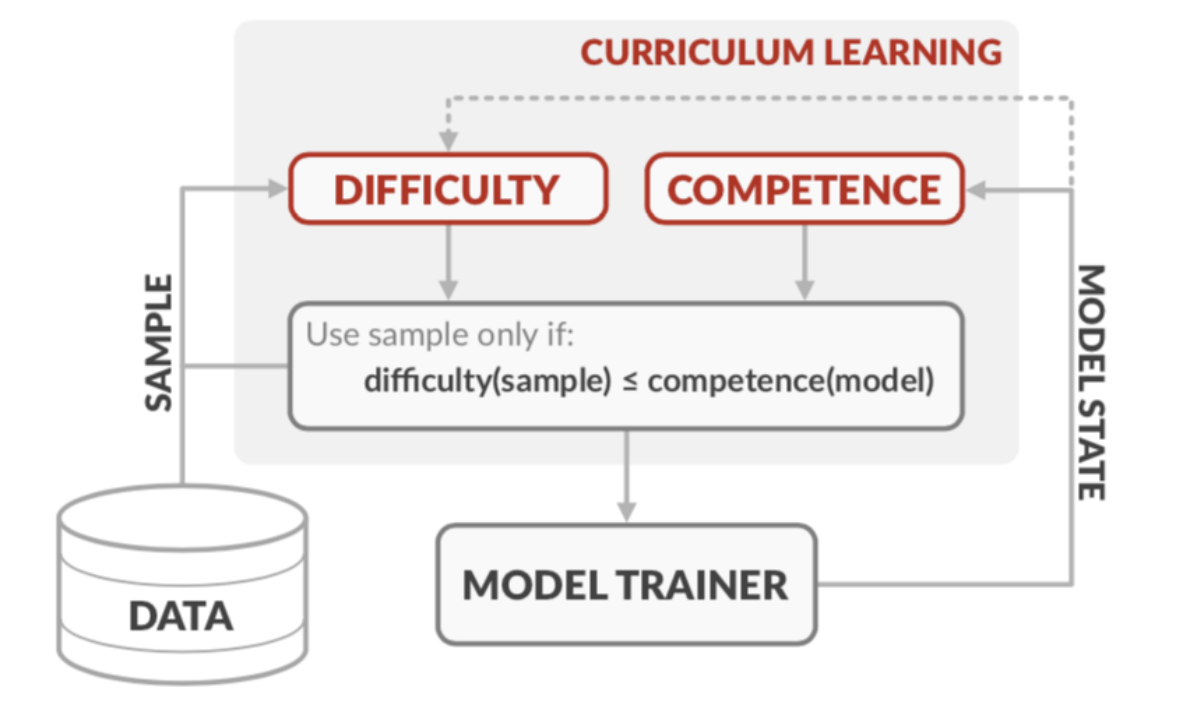
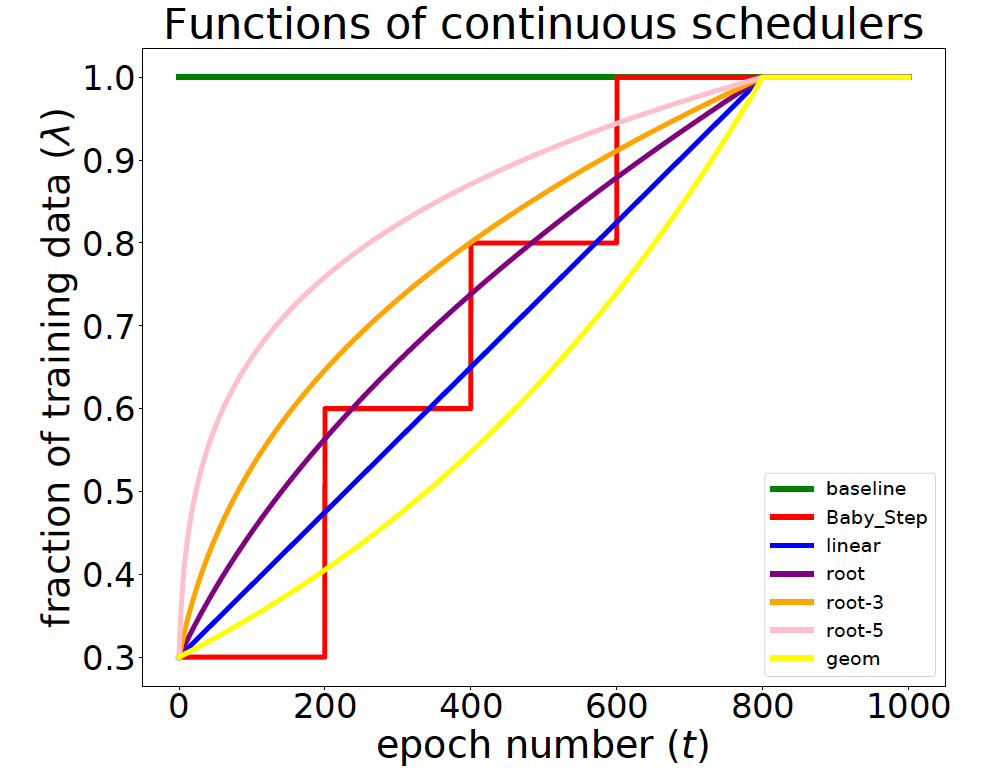
给定一个单调递增的曲线控制当前可用于训练的数据的比例。训练:对 困难分数CDF <= 模型能力c(t) 的数据均匀采样。唯一需要调的参数是课程学习阶段的长度
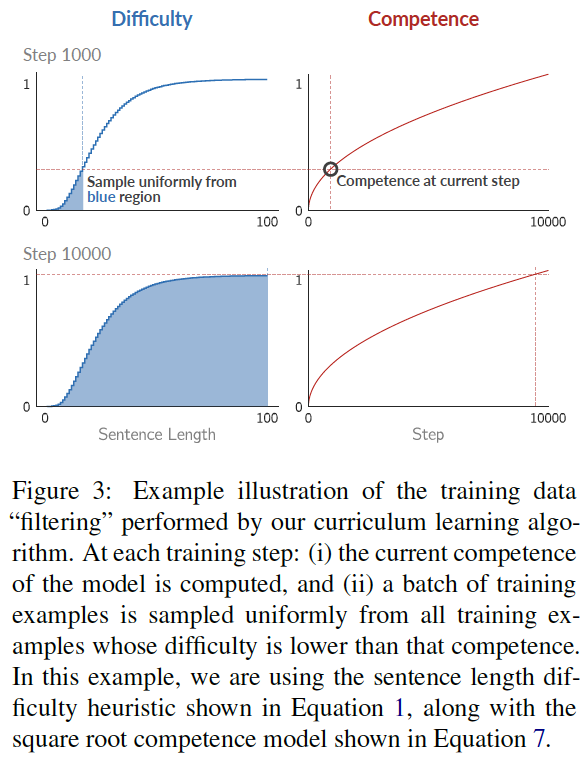
句子难度d:
句长;word rarity

句子难度d=CDF是累计概率分布(在0-1之间)==概率密度函数的积分,所以上图中图2曲线下的蓝色阴影面积即是概率密度的积分==图3的对应的函数值
模型能力c(t)
在0-1之间的c(t)表示时间步t时允许学习器使用的训练数据的比例。
linear:任意时刻,更难更新的样本都是匀速加入训练的,每次加入训练集的样本数目相同。
root:而当t增加,训练数据增加,每个样本在训练batch中被采样到的概率变小。所以用root是为了随时间增加,让更难更新的数据加入训练集的数目会逐步变少(加入速度变缓慢)、被采样到的概率变小,因此给困难样本的训练时间长、给简单样本的训练时间短。
--注意与上述Dynamic Curriculum Learning for Imbalanced Data Classification 论文中的convex对比
实验中sqrt效果最好。曲线越凸,说明与无课程学习即c(t)=1的场景越类似(从开始就使用全部训练集),效果越不好。

2020年
Norm-Based Curriculum Learning for Neural Machine Translation
词向量可分解为:norm+direction
论文动机: 让模型根据它的能力自动安排课程、 norm-based句子困难度是语言学和模型的结合
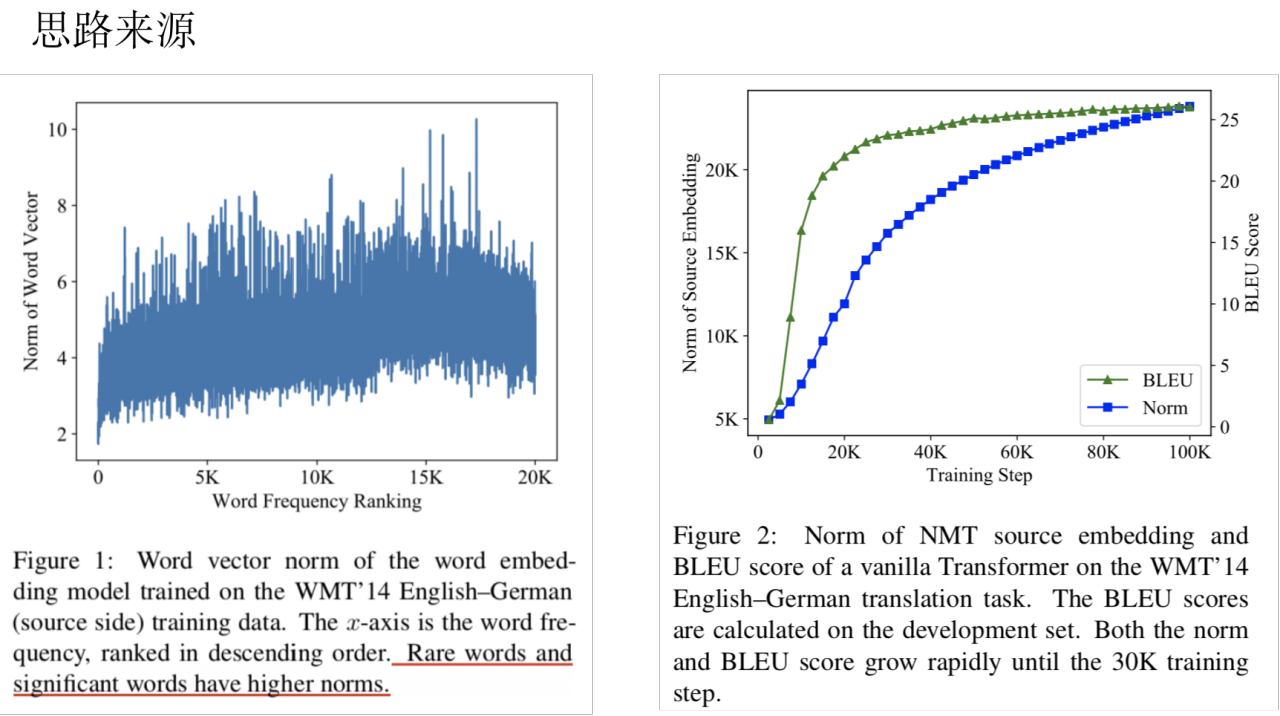


上面Competence-based cl的改进,沿用的是上篇的sqrt,让模型可以根据模型能力自动设计策略:

Uncertainty-Aware Curriculum Learning for Neural Machine Translation
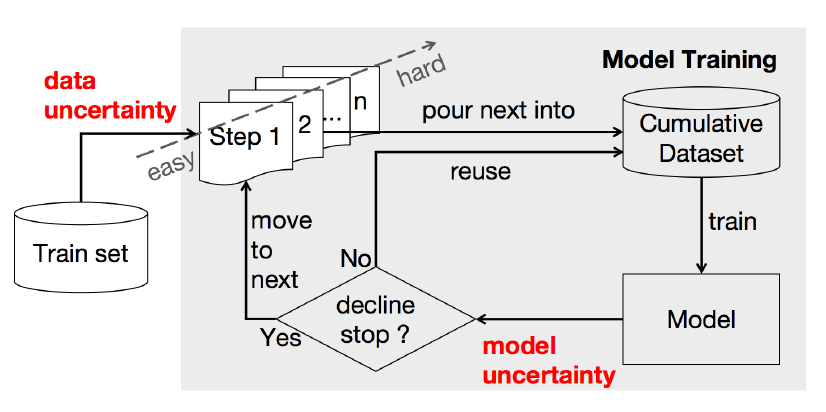
仍旧与前面zhang18,19的论文类似,把整体数据集分为几个shards,按难度排序,课程学习到下一阶段则在训练集中新加入一个shard。
数据和模型都分别有困难度的定义
数据的困难度:在训练集上预训练好的语言模型打分,即交叉熵/困惑度ppl
模型的困难度:沿袭Improving Back-Translation with Uncertainty-based Confidence Estimation的工作,定义模型的不确定性——贝叶斯网络——蒙特卡洛dropout来估计(K次前向传播,每次随机让部分神经元失活,这样模型参数也有K种; 给定M对平行句来估计模型不确定性。)
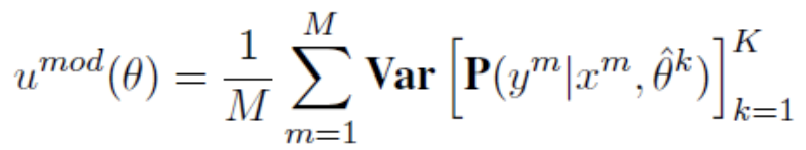
(MC dropout: 不需要修改现有的神经网络模型,只需要神经网络模型中带 dropout 层 在训练的时候,MC dropout 表现形式和 dropout 没有什么区别,按照正常模型训练方式训练即可。 在测试的时候,在前向传播过程,神经网络的 dropout 是不能关闭的。这就是和平常使用的唯一的区别。)
CL训练:
-
训练集根据数据不确定性升序排列。再分为buckets,不确定性相似的在一块
-
课程:最初由不确定性小的来训练,当模型不确定性停止下降时加入下一bucket
-
模型的不确定性是从当前数据集中采样部分数据来计算的
该论文中的cl到下一训练阶段的转换完全看模型的困难度,模型和数据困难度之间没有直接联系
Curriculum Learning for Natural Language Understanding
Cross review method 评估困难度
直接的想法:样本困难度应该由模型自身决定,困难度指标是目标任务的golden metric——the best metric should be the golden metric of the target task, which can be accuracy, F1 score,
(这种cross view的方法可以缓解困难度衡量的波动性。
用于推理与训练的数据应该孤立。因为是考虑的NLU任务,使用BERT base/large模型(进行微调)。
metric离散,分布自然是由难度分数层次构成的。对其他指标(MSE),可以手动均分。
因为每阶段样本是不重叠的,所以要/N。整体上看和Baby Step类似。N=10,训练集小于10k时N设置为3,N的寻找也是个值得探索的问题。)
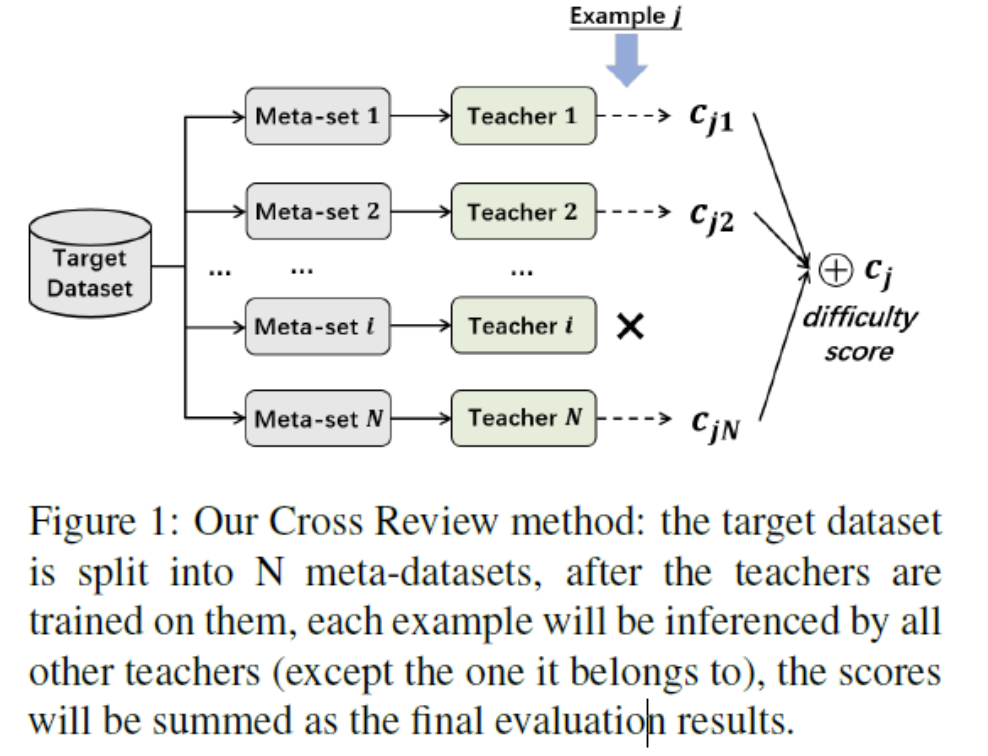
- 困难度衡量——Cross view(缓解困难度衡量的波动性)
- 把数据集平均分为N(10)份,N个子集分别训练teacher模型,teacher模型与学生的结构相同;
- 样本j在包含在第i个子集中
- 除了第i个子集,用N-1个teacher模型推理样本j,得到N-1个分值(目标任务的golden metric),分值之和是样本j最后的困难度得分
Curriculum Arrangement—anneal method (baby step)
- 样本按难度排序,(看metric的类型)把样本分为N个bucket,C1-CN是由易到难的bucket
- 对每个学习阶段Si,从所有包括i之前的buckets 里采样
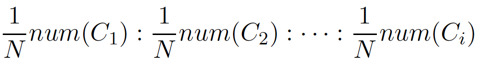
- 每个阶段样本不重叠,每阶段模型只训练1轮
- 最后到达SN之后,模型接触到的样本和原样本分布是一致的;
- 额外再加一个训练阶段用全部的训练集训练直到模型收敛
Learning a Multi-Domain Curriculum for Neural Machine Translation
分类(A Comprehensive Survey on Curriculum Learning)
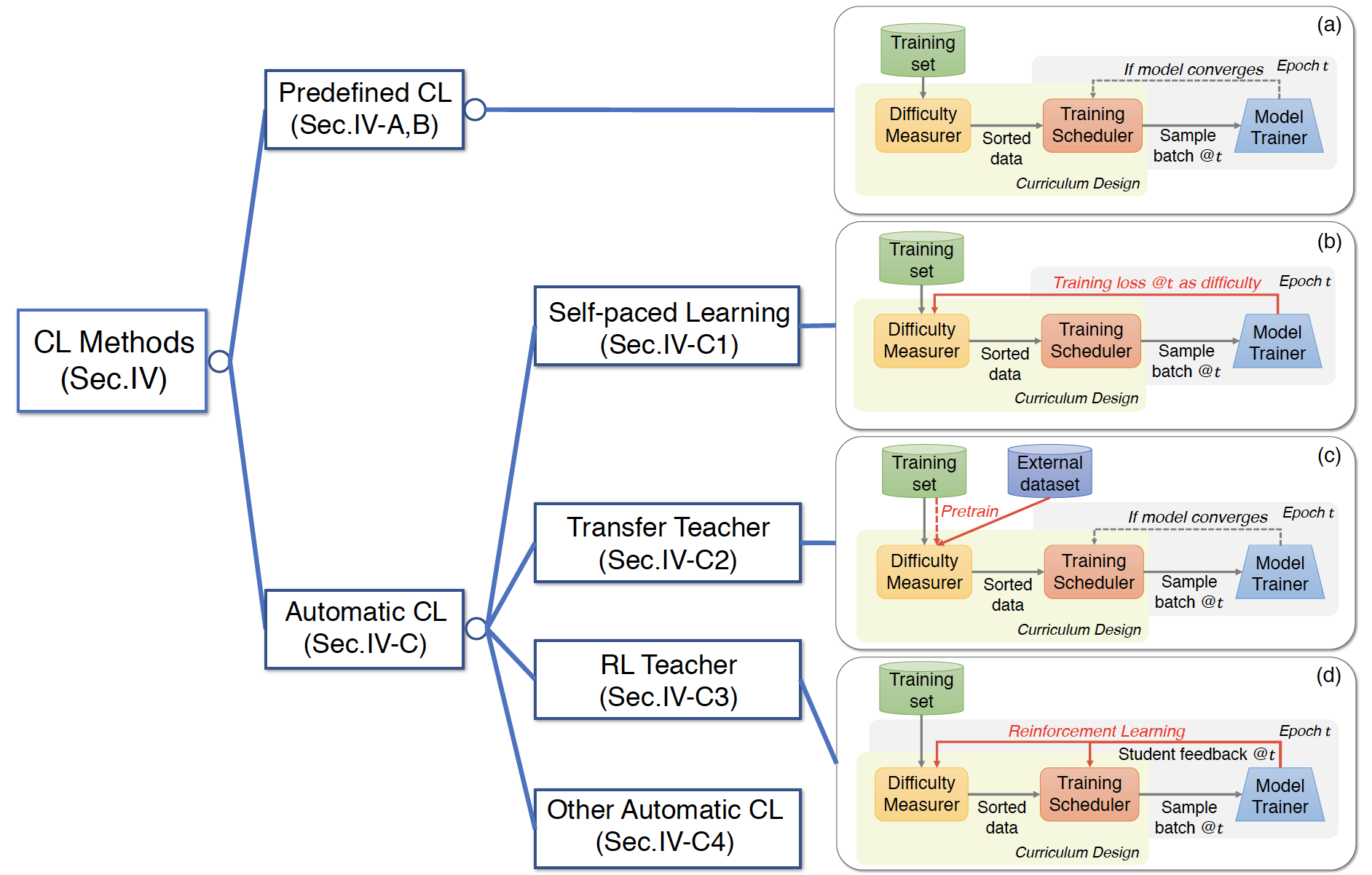
Predefined CL
预定义的困难度衡量常用类型
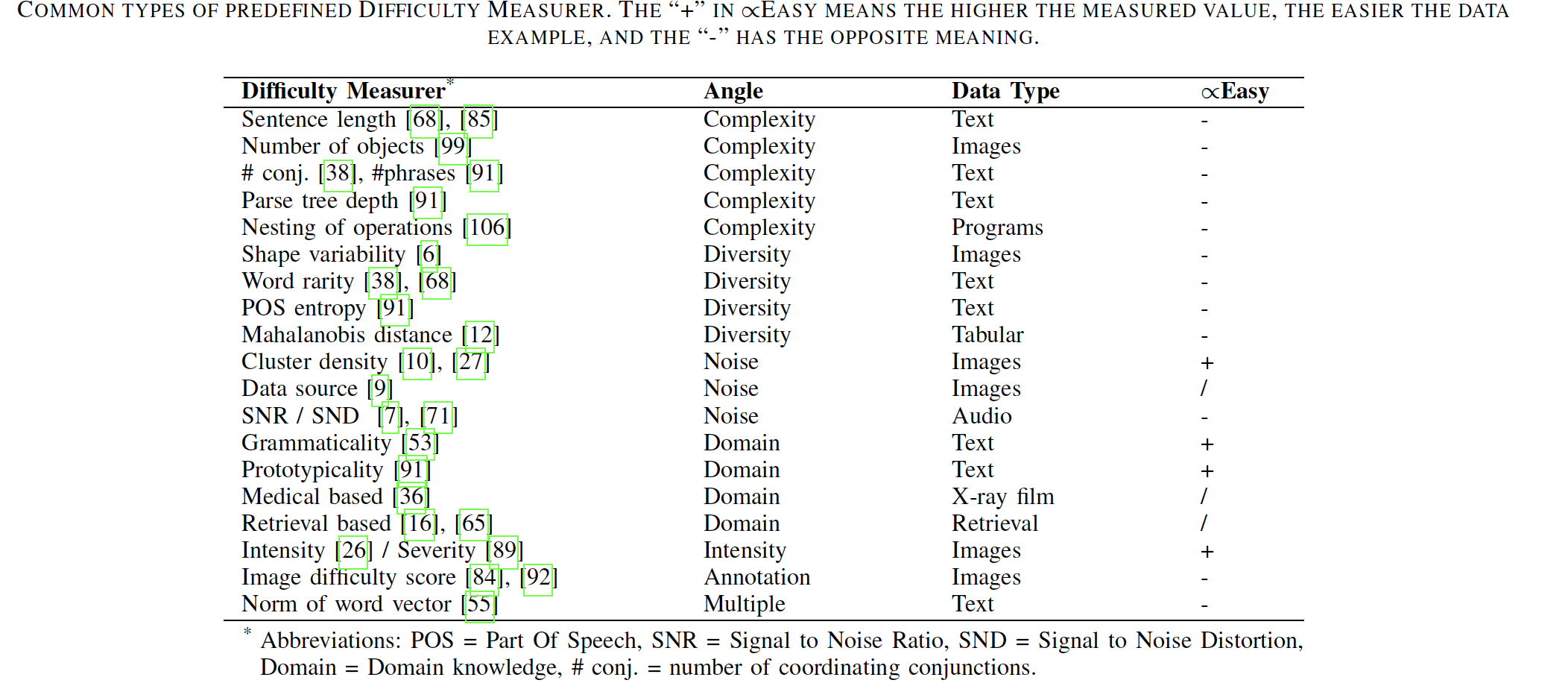
预定义的训练策略常用类型
离散策略
Baby Step
One Pass
连续策略
competence function:某时刻的训练数据占整个数据集的比例与模型能力函数有关,该能力函数一般是root形式
distribution shift:表现为一系列数据选择,训练时从初始的分布逐步转移到目标分布(样本权重)。样本可分两类,一类是common(简单、低质量)、另一类是target(更复杂、高质量)。
预先定义CL的限制
Automatic CL
SPL和TT是半自动课程学习-训练策略已经预定义、困难度衡量全自动;RL是全自动课程学习。对比如下;

Self-paced Learning
学生自身作为老师,根据样本的loss衡量样本的困难度
Transfer Teacher
引入强壮的老师模型,根据老师模型的表现衡量样本困难度。老师模型pretrained,老师结构可以与学生一致,可以不一致

RL Teacher
老师模型和学生模型共同提升。采用强化学习框架作为老师模型,根据学生的反馈动态选择数据

Other Automatic CL

参考:https://www.dazhuanlan.com/2019/12/12/5df15a966a146/
Imagenet.

