
pytorch(分布式)数据并行个人实践总结——DataParallel/DistributedDataParallel
1|0pytorch的并行分为模型并行、数据并行
源码详见我的github: TextCNN_parallel,个人总结,还有很多地方理解不到位,求轻喷。
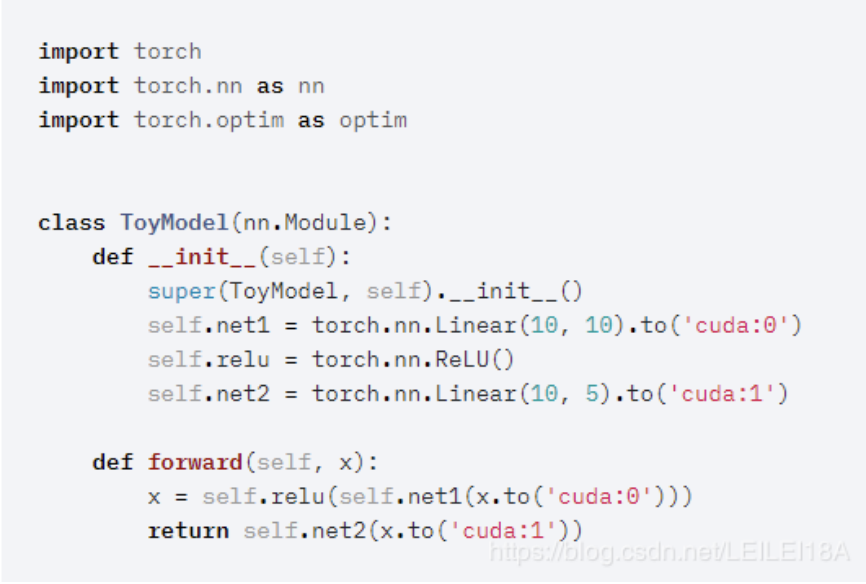
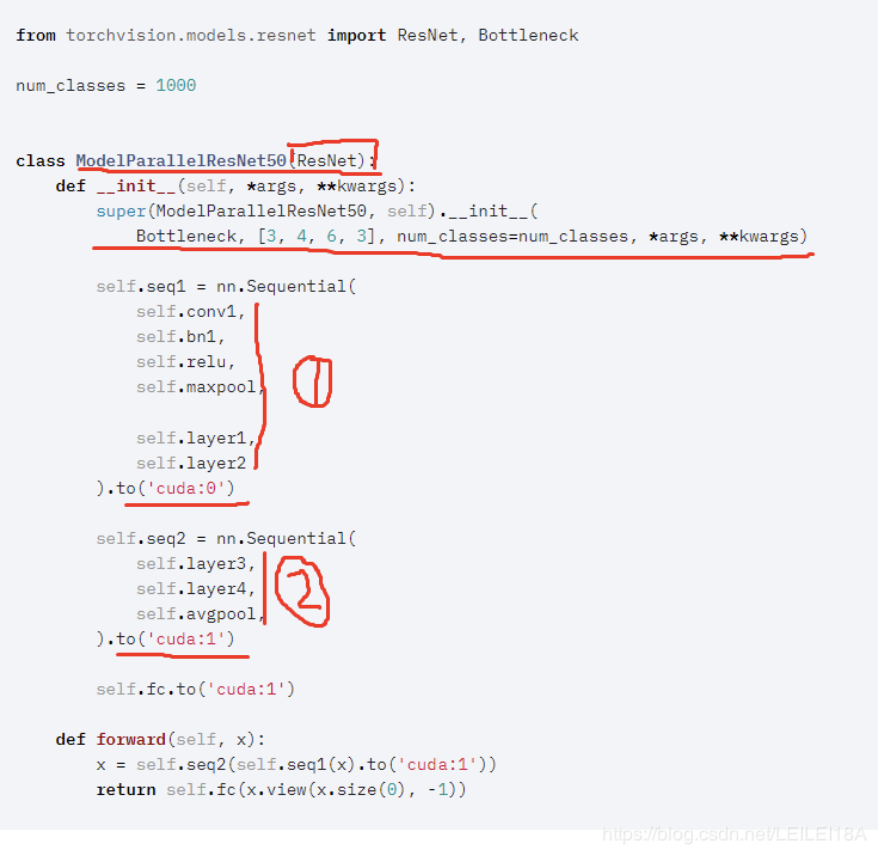
左侧模型并行:是网络太大,一张卡存不了,那么拆分,然后进行模型并行训练。
右侧数据并行:多个显卡同时采用数据训练网络的副本。
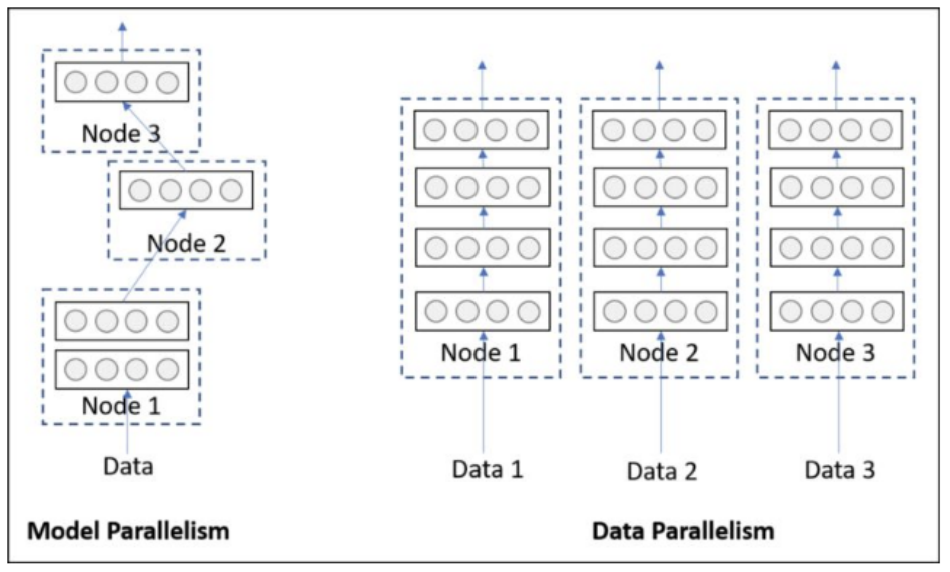
1|1模型并行
1|2数据并行
数据并行的操作要求我们将数据划分成多份,然后发送给多个 GPU 进行并行的计算。
注意:多卡训练要考虑通信开销的,是个trade off的过程,不见得四块卡一定比两块卡快多少,可能是训练到四块卡的时候通信开销已经占了大头
下面是一个简单的示例。要实现数据并行,第一个方法是采用 nn.parallel 中的几个函数,分别实现的功能如下所示:
-
复制(Replicate):将模型拷贝到多个 GPU 上;
-
分发(Scatter):将输入数据根据其第一个维度(通常就是 batch 大小)划分多份,并传送到多个 GPU 上;
-
收集(Gather):从多个 GPU 上传送回来的数据,再次连接回一起;
-
并行的应用(parallel_apply):将第三步得到的分布式的输入数据应用到第一步中拷贝的多个模型上。
- 实现代码如下
①nn.parallel.data_parallel(module, inputs, device_ids=None, output_device=None, dim=0, module_kwargs=None)
②class torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0)
可见二者的参数十分相似,通过device_ids参数可以指定在哪些GPU上进行优化,output_device指定输出到哪个GPU上。唯一的不同就在于前者直接利用多GPU并行计算得出结果,而后者则返回一个新的module,能够自动在多GPU上进行并行加速。
2|0并行数据加载
流行的深度学习框架(例如Pytorch和Tensorflow)为分布式培训提供内置支持。从广义上讲,从磁盘读取输入数据开始,加载数据涉及四个步骤:
- 将数据从磁盘加载到主机
- 将数据从可分页内存传输到主机上的固定内存。请参阅此有关分页和固定的内存更多信息。
- 将数据从固定内存传输到GPU
- 在GPU上向前和向后传递
PyTorch中的Dataloader提供使用多个进程(通过将num_workers> 0设置)从磁盘加载数据以及将多页数据从可分页内存到固定内存的能力(通过设置) pin_memory = True)。
一般的,对于大批量的数据,若仅有一个线程用于加载数据,则数据加载时间占主导地位,这意味着无论我们如何加快数据处理速度,性能都会受到数据加载时间的限制。现在,设置num_workers = 4以及pin_memory = True。这样,可以使用多个进程从磁盘读取不重叠的数据,并启动生产者-消费者线程以将这些进程读取的数据从可分页的内存转移到固定的内存。
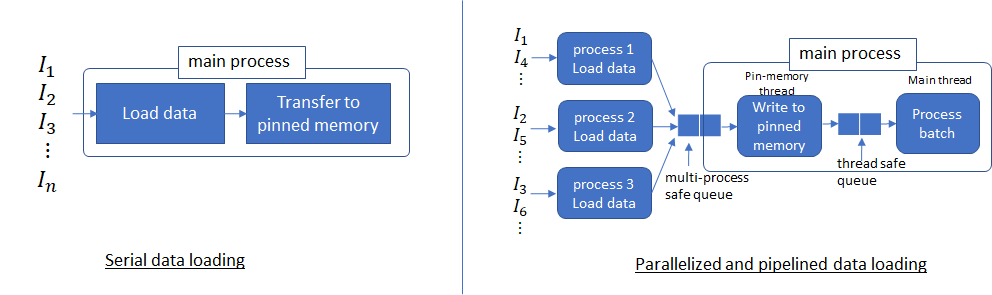
多个进程能够更快地加载数据,并且当数据处理时间足够长时,流水线数据加载几乎可以完全隐藏数据加载延迟。这是因为在处理当前批次的同时,将从磁盘读取下一个批次的数据,并将其传输到固定内存。如果处理当前批次的时间足够长,则下一个批次的数据将立即可用。这个想法还建议如何为num_workers参数设置适当的值。应该设置此参数,以使从磁盘读取批处理数据的速度比GPU处理当前批处理的速度更快(但不能更高,因为这只会浪费多个进程使用的系统资源)。
请注意,到目前为止,我们仅解决了从磁盘加载数据以及从可分页到固定内存的数据传输问题。从固定内存到GPU的数据传输(tensor.cuda())也可以使用CUDA流进行流水线处理。
现在将使用GPU网络检查数据并行处理。基本思想是,网络中的每个GPU使用模型的本地副本对一批数据进行正向和反向传播。反向传播期间计算出的梯度将发送到服务器,该服务器运行reduce归约操作以计算平均梯度。然后将平均梯度结果发送回GPU,GPU使用SGD更新模型参数。使用数据并行性和有效的网络通信软件库(例如NCCL),可以实现使训练时间几乎线性减少。
3|0数据并行DataParallel
PyTorch 中实现数据并行的操作可以通过使用 torch.nn.DataParallel。
3|1并行处理机制
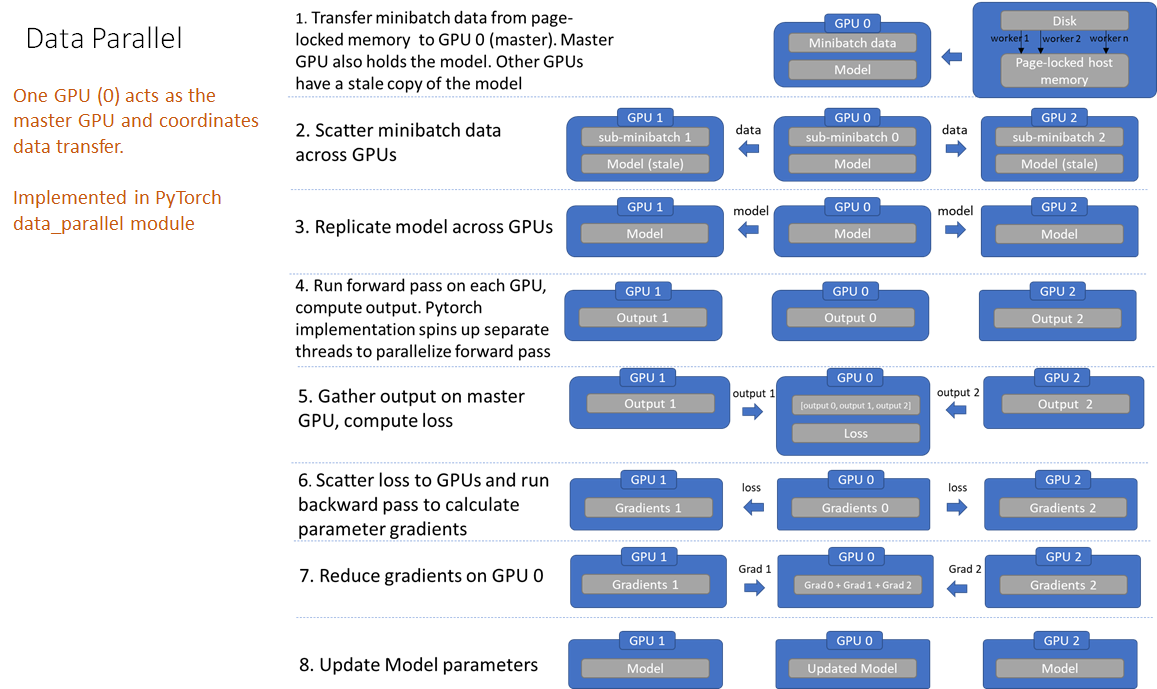
DataParallel系统通过将整个小型批处理加载到主线程上,然后将子小型批处理分散到整个GPU网络中来工作。
具体是将输入一个 batch 的数据均分成多份,分别送到对应的 GPU 进行计算。与 Module 相关的所有数据也都会以浅复制的方式复制多份。每个 GPU 在单独的线程上将针对各自的输入数据独立并行地进行 forward 计算。然后在主GPU上收集网络输出,并通过将网络输出与批次中每个元素的真实数据标签进行比较来计算损失函数值。接下来,损失值分散给各个GPU,每个GPU进行反向传播以计算梯度。最后,在主GPU上归约梯度、进行梯度下降,并更新主GPU上的模型参数。由于模型参数仅在主GPU上更新,而其他从属GPU此时并不是同步更新的,所以需要将更新后的模型参数复制到剩余的从属 GPU 中,以此来实现并行。
DataParallel会将定义的网络模型参数默认放在GPU 0上,所以dataparallel实质是可以看做把训练参数从GPU拷贝到其他的GPU同时训练,这样会导致内存和GPU使用率出现很严重的负载不均衡现象,即GPU 0的使用内存和使用率会大大超出其他显卡的使用内存,因为在这里GPU0作为master来进行梯度的汇总和模型的更新,再将计算任务下发给其他GPU,所以他的内存和使用率会比其他的高。
具体流程见下图:
3|2使用代码
注意我这里的代码时一个文本分类的,模型叫TextCNN
1.单gpu(用做对比)
2.多gpu,DataParallel使用
稍微完整一点:
3.cuda()函数解释
.cuda()函数返回一个存储在CUDA内存中的复制,其中device可以指定cuda设备。 但如果此storage对象早已在CUDA内存中存储,并且其所在的设备编号与cuda()函数传入的device参数一致,则不会发生复制操作,返回原对象。
cuda()函数的参数信息:
-
device (int) – 指定的GPU设备id. 默认为当前设备,即
torch.cuda.current_device()的返回值。 -
non_blocking (bool) – 如果此参数被设置为True, 并且此对象的资源存储在固定内存上(pinned memory),那么此cuda()函数产生的复制将与host端的原storage对象保持同步。否则此参数不起作用。
许多低效率之处:
- 冗余数据副本
- 数据从主机复制到主GPU,然后将子微型批分散在其他GPU上
- 在前向传播之前跨GPU进行模型复制
- 由于模型参数是在主GPU上更新的,因此模型必须在每次正向传递的开始时重新同步
- 每批的线程创建/销毁开销
- 并行转发是在多个线程中实现的(这可能只是PyTorch问题)
- 梯度减少流水线机会未开发
- 在Pytorch 1.0数据并行实现中,梯度下降发生在反向传播的末尾。
- 在主GPU上不必要地收集模型输出output
- GPU利用率不均
- 在主GPU上执行损失loss计算
- 梯度下降,在主GPU上更新参数
4|0分布式数据并行 DistributedDataParallel
4|1并行处理机制
DistributedDataParallel,支持 all-reduce,broadcast,send 和 receive 等等。通过 MPI 实现 CPU 通信,通过 NCCL 实现 GPU 通信。可以用于单机多卡也可用于多机多卡, 官方也曾经提到用 DistributedDataParallel 解决 DataParallel 速度慢,GPU 负载不均衡的问题。
效果比DataParallel好太多!!!torch.distributed相对于torch.nn.DataParalle 是一个底层的API,所以我们要修改我们的代码,使其能够独立的在机器(节点)中运行。
不再有主GPU,每个GPU执行相同的任务。对每个GPU的训练都是在自己的过程中进行的。每个进程都从磁盘加载其自己的数据。分布式数据采样器可确保加载的数据在各个进程之间不重叠。损失函数的前向传播和计算在每个GPU上独立执行。因此,不需要收集网络输出。在反向传播期间,梯度下降在所有GPU上均被执行,从而确保每个GPU在反向传播结束时最终得到平均梯度的相同副本。
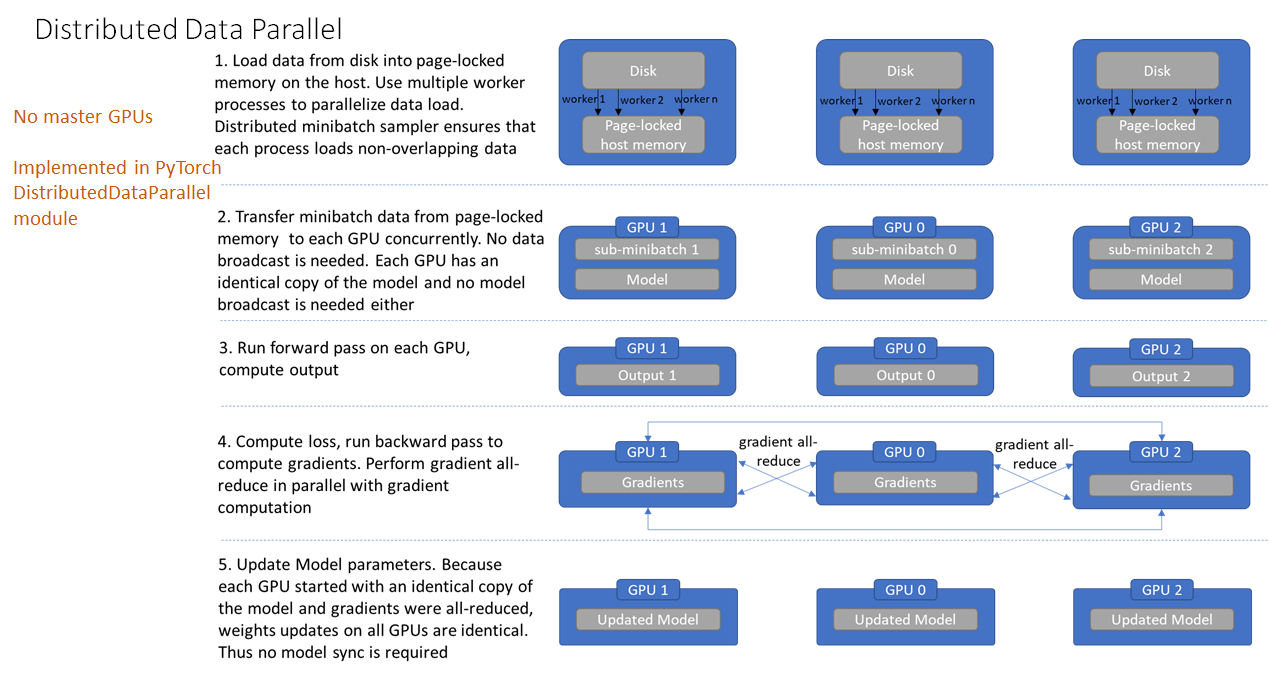
区别:DDP通过多进程实现的。也就是说操作系统会为每个GPU创建一个进程,从而避免了Python解释器GIL带来的性能开销。而DataParallel()是通过单进程控制多线程来实现的。
对比DataParallel,DistributedDataParallel的优势如下:
在每次迭代中,每个进程具有自己的 optimizer ,并独立完成所有的优化步骤,进程内与一般的训练无异。
在各进程梯度计算完成之后,各进程需要将梯度进行汇总平均,然后再由 rank=0 的进程,将其 broadcast 到所有进程。之后,各进程用该梯度来独立的更新参数。
而 DataParallel是梯度汇总到gpu0,反向传播更新参数,再广播参数给其他的gpu
由于各进程中的模型,初始参数一致 (初始时刻进行一次 broadcast),而每次用于更新参数的梯度也一致,因此,各进程的模型参数始终保持一致。
而在 DataParallel 中,全程维护一个 optimizer,对各 GPU 上梯度进行求和,而在主 GPU 进行参数更新,之后再将模型参数 broadcast 到其他 GPU。
相较于 DataParallel,torch.distributed 传输的数据量更少,因此速度更快,效率更高。
2.每个进程包含独立的解释器和 GIL。
一般使用的Python解释器CPython:是用C语言实现Pyhon,是目前应用最广泛的解释器。全局锁使Python在多线程效能上表现不佳,全局解释器锁(Global Interpreter Lock)是Python用于同步线程的工具,使得任何时刻仅有一个线程在执行。
由于每个进程拥有独立的解释器和 GIL,消除了来自单个 Python 进程中的多个执行线程,模型副本或 GPU 的额外解释器开销和 GIL-thrashing ,因此可以减少解释器和 GIL 使用冲突。这对于严重依赖 Python runtime 的 models 而言,比如说包含 RNN 层或大量小组件的 models 而言,这尤为重要。
4|2分布式几个概念:
-
即进程组。默认情况下,只有一个组,一个 job 即为一个组,也即一个 world。
当需要进行更加精细的通信时,可以通过 new_group 接口,使用 word 的子集,创建新组,用于集体通信等。
-
world size :
表示全局进程个数。
-
rank:
表示进程序号,用于进程间通讯,表征进程优先级。rank = 0 的主机为 master 节点。
-
local_rank:
进程内,GPU 编号,非显式参数,由 torch.distributed.launch 内部指定。例如, rank = 3,local_rank = 0 表示第 3 个进程内的第 1 块 GPU。
4|3使用流程
Pytorch 中分布式的基本使用流程如下:
-
在使用
distributed包的任何其他函数之前,需要使用init_process_group初始化进程组,同时初始化distributed包。 -
如果需要进行小组内集体通信,用
new_group创建子分组 -
创建分布式并行(DistributedDataParallel)模型
DDP(model, device_ids=device_ids) -
为数据集创建
Sampler -
使用启动工具
torch.distributed.launch在每个主机上执行一次脚本,开始训练 -
使用
destory_process_group()销毁进程组
4|4使用代码
4|5一些解释
启动辅助工具 Launch utility
启动实用程序torch.distributed.launch,此帮助程序可用于为每个节点启动多个进程以进行分布式训练,它在每个训练节点上产生多个分布式训练进程。
这个工具可以用作CPU或者GPU,如果被用于GPU,每个GPU产生一个进程Process。该工具既可以用来做单节点多GPU训练,也可用于多节点多GPU训练。如果是单节点多GPU,将会在单个GPU上运行一个分布式进程,据称可以非常好地改进单节点训练性能。如果用于多节点分布式训练,则通过在每个节点上产生多个进程来获得更好的多节点分布式训练性能。如果有Infiniband接口则加速比会更高。
在 单节点分布式训练 或 多节点分布式训练 的两种情况下,该工具将为每个节点启动给定数量的进程(--nproc_per_node)。如果用于GPU培训,则此数字需要小于或等于当前系统上的GPU数量(nproc_per_node),并且每个进程将在从GPU 0到GPU(nproc_per_node - 1)的单个GPU上运行。
NCCL 后端
NCCL 的全称为 Nvidia 聚合通信库(NVIDIA Collective Communications Library),是一个可以实现多个 GPU、多个结点间聚合通信的库,在 PCIe、Nvlink、InfiniBand 上可以实现较高的通信速度。
NCCL 高度优化和兼容了 MPI,并且可以感知 GPU 的拓扑,促进多 GPU 多节点的加速,最大化 GPU 内的带宽利用率,所以深度学习框架的研究员可以利用 NCCL 的这个优势,在多个结点内或者跨界点间可以充分利用所有可利用的 GPU。
NCCL 对 CPU 和 GPU 均有较好支持,且 torch.distributed 对其也提供了原生支持。
对于每台主机均使用多进程的情况,使用 NCCL 可以获得最大化的性能。每个进程内,不许对其使用的 GPUs 具有独占权。若进程之间共享 GPUs 资源,则可能导致 deadlocks。
DistributedSampler
参数
-
dataset
进行采样的数据集
-
num_replicas
分布式训练中,参与训练的进程数
-
rank
当前进程的 rank 序号(必须位于分布式训练中)
说明:
对数据集进行采样,使之划分为几个子集。
一般与 DistributedDataParallel 配合使用。此时,每个进程可以传递一个 DistributedSampler 实例作为一个 Dataloader sampler,并加载原始数据集的一个子集作为该进程的输入。每个进程都应加载数据的非重叠副本
在 Dataparallel 中,数据被直接划分到多个 GPU 上,数据传输会极大的影响效率。相比之下,在 DistributedDataParallel 使用 sampler 可以为每个进程划分一部分数据集,并避免不同进程之间数据重复。
注意:在 DataParallel 中,batch size 设置必须为单卡的 n 倍,因为一个batch的数据会被主GPU分散为minibatch给其他GPU,但是在 DistributedDataParallel 内,batch size 设置于单卡一样即可,因为各个GPU对应的进程独立从磁盘中加载数据。
5|0两种方法的使用情况,负载和训练时间
5|1DataParallel
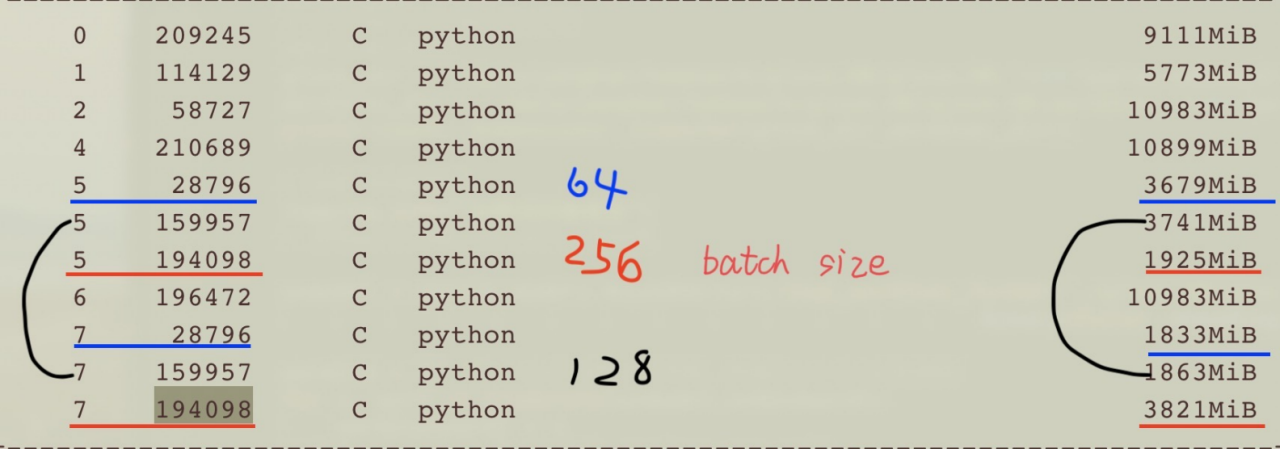
PID相同的是一个程序
在两张GPU上,本人用了3种不同batchsize跑的结果如下,
batch=64(蓝色),主卡3678MB,副卡1833MB
batch=128(黑色),主卡3741MB,副卡1863MB
batch=256(红色),主卡3821MB,副卡1925MB
总体看来,主卡,默认是指定的卡中序号排在第一个的,内存使用情况是副卡的2倍,负载不太均衡
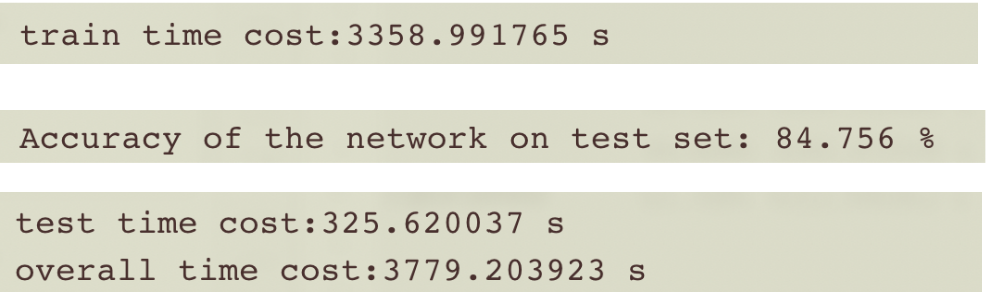
batch=512时,训练时间和准确率
5|2DistributedDataParallel
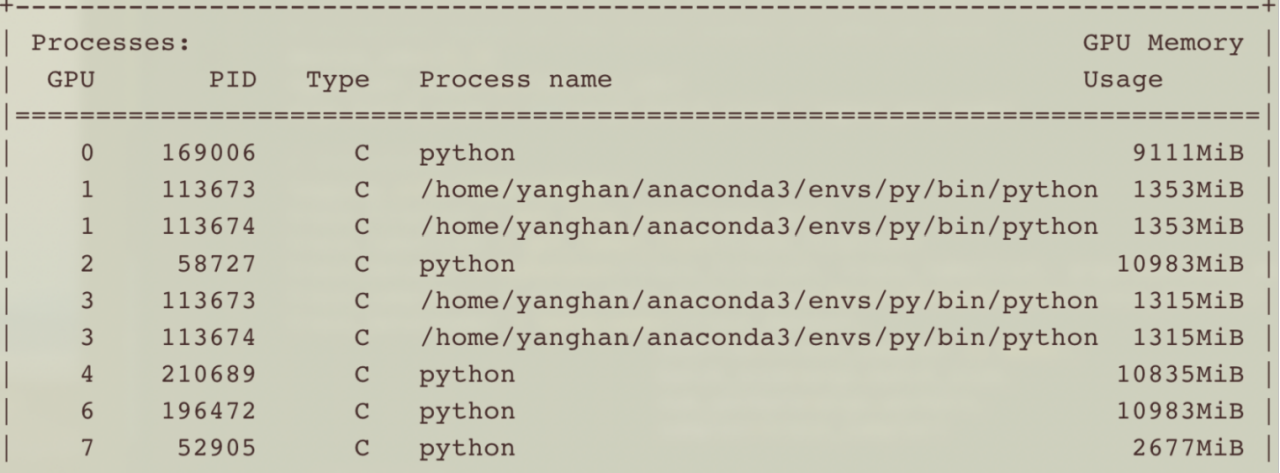
其中PID为113673、113674的是我的程序,总体有两个进程,每个进程都用了两张卡,可以看到,负载相对很均衡了。
运行脚本: CUDA_VISIBLE_DEVICES=1,3 python -m torch.distributed.launch --nproc_per_node=2 main.py
batch=500时,训练时间和准确率:
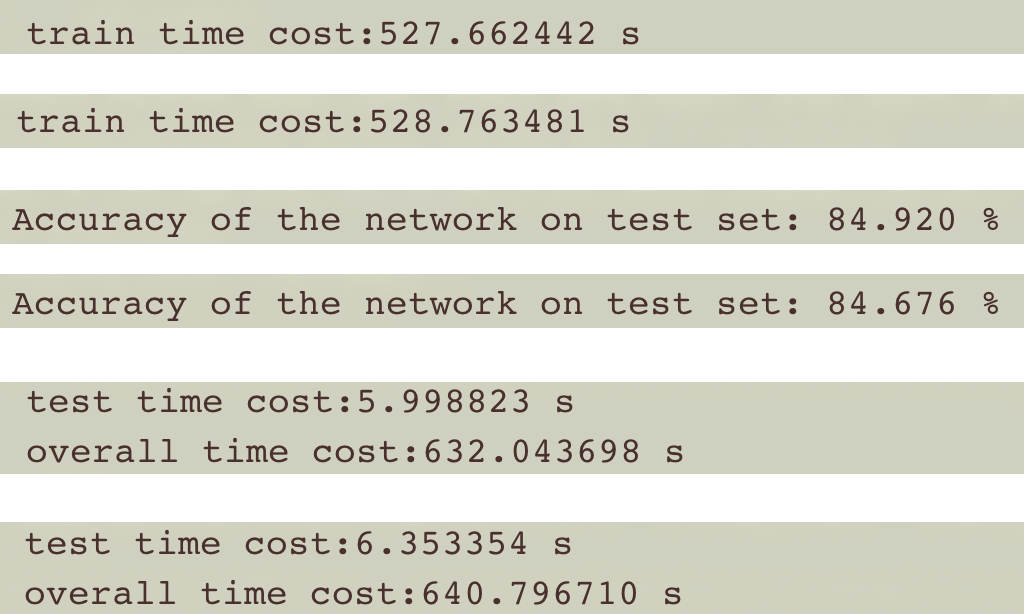
相比DataParallel,DistributedDataParallel训练时间缩减了好几倍!推荐大家使用分布式数据并行
源码详见我的github: TextCNN_parallel
----------------------------------------------------
参考:https://blog.csdn.net/zwqjoy/article/details/89415933
https://www.ctolib.com/tczhangzhi-pytorch-distributed.html
https://www.telesens.co/2019/04/04/distributed-data-parallel-training-using-pytorch-on-aws/ https://zhuanlan.zhihu.com/p/76638962 👍
__EOF__
作 者:fnangle
出 处:https://www.cnblogs.com/yh-blog/p/12877922.html
关于博主:编程路上的小学生,热爱技术,喜欢专研。评论和私信会在第一时间回复。或者直接私信我。
版权声明:署名 - 非商业性使用 - 禁止演绎,协议普通文本 | 协议法律文本。
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
2019-05-14 ImportError: DLL load failed: 找不到指定的模块;ImportError: numpy.core.multiarray failed to import 报错解决