

使用reques爬取同学的博客


import urllib.request import sys import gzip from lxml import etree print(sys.getdefaultencoding()) with open('student2.txt', 'r', encoding='utf-8') as f1: stuUrls = eval(f1.read()) f1.close headers = { 'Host': 'www.cnblogs.com', 'Connection': 'keep-alive', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.9' } # 判断是否还有下一页 isNextPage = r'下一页' # 根据url和伪装的header获取网页源代码 def getHtml(url, headers): request = urllib.request.Request(url=url, headers=headers) page = urllib.request.urlopen(request) html = page.read() return html # 解压 def ungzip(data): data = gzip.decompress(data) return data # print(data) # 解析网页 def download(url): page = 1 articleInfoRe = set() while True: url0 = url + f'/default.html?page={page}' html = getHtml(url0, headers) data = ungzip(html).decode('utf-8') dom = etree.HTML(data) # 获取第一页的数据 # nextPage = dom.xpath('.//div[@class="pager"] ') postTitle2href = dom.xpath('.//a[@class="postTitle2"]/@href') postTitle2 = dom.xpath('.//a[@class="postTitle2"]/text()') for i in range(len(postTitle2)): article = postTitle2[i] article = str(article).rstrip('\n') href = str(postTitle2href[i]) articleInfoRe.add((article, href)) page = page + 1 if page == 5: break for article, href in articleInfoRe: print(article + '\t' + href) def main(): for key, value in stuUrls.items(): print('\n' + key + '\t\t' + key + '\t\t' + key + '\t\t' + key + '\t\t' + key + '\t\t' + '\n') url = value download(url) if __name__ == '__main__': main()
同学的博客列表:

爬取结果: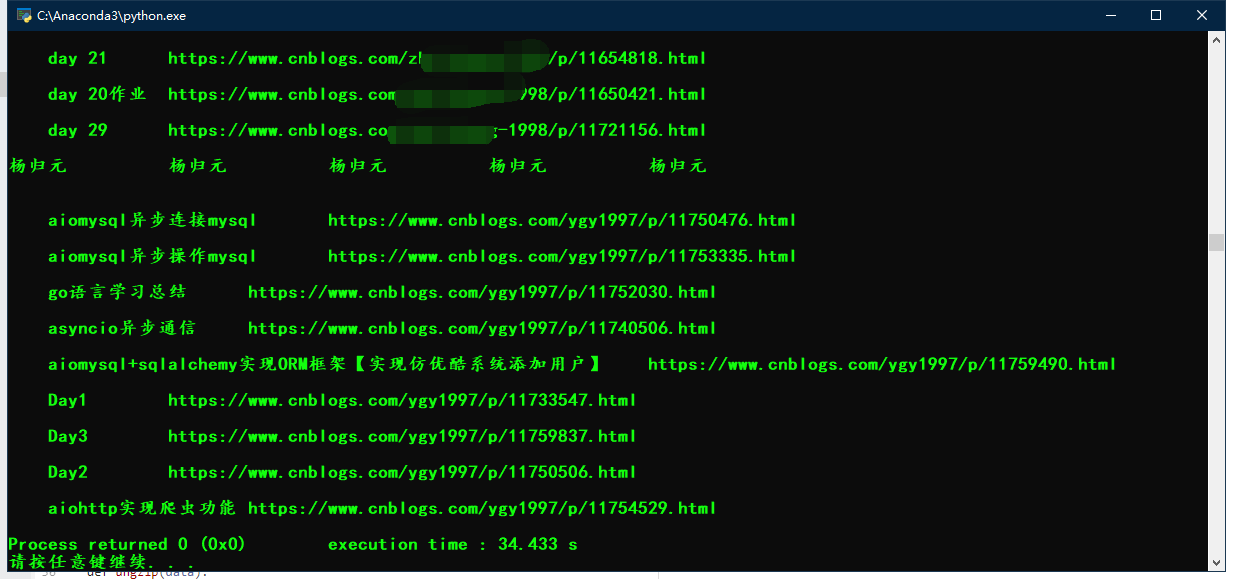
学习总结:
1.利用了set去重
2.xpath:[.//节点名[属性=属性值]/]+text()获取文本值 (或者+@属性 获取属性值)
3.遍历每一行:
with open('student.txt', 'r', encoding='utf-8') as f:
strList = f.readlines()
for stu in strList:
print(stu)
4.添加header
headers = {
'Host': 'www.cnblogs.com',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9'
}
5.打印默认编码:sys.getdefaultencoding()
