MyBatis-Plus
MyBatis-Plus官网:https://baomidou.com/
一、简介
1. 概述
MyBatis-Plus(简称 MP,是由baomidou(苞米豆)组织开源的)是一个基于 MyBatis 的增强工具,它对 Mybatis 的基础功能进行了增强,但未做任何改变。
使得我们可以在 Mybatis 开发的项目上直接进行升级为 Mybatis-plus,正如它对自己的定位,它能够帮助我们进一步简化开发过程,提高开发效率。
Mybatis-Plus 其实可以看作是对 Mybatis 的再一次封装,升级之后,对于单表的 CRUD 操作,调用 Mybatis-Plus 所提供的 API 就能够轻松实现,
此外还提供了各种查询方式、分页等行为。最最重要的,开发人员还不用去编写 XML,这就大大降低了开发难度。
2. 特性
-
-
损耗小:启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作。
-
强大的 CRUD 操作:内置通用 Mapper、通用 Service,仅仅通过少量配置即可实现单表大部分 CRUD 操作,更有强大的条件构造器,满足各类使用需求。
-
支持 Lambda 形式调用:通过 Lambda 表达式,方便的编写各类查询条件,无需再担心字段写错。
-
支持多种数据库:支持 MySQL、MariaDB、Oracle、DB2、H2、HSQL、SQLite、Postgre、SQLServer2005、SQLServer 等多种数据库。
-
支持主键自动生成:支持多达 4 种主键策略(内含分布式唯一 ID 生成器 - Sequence),可自由配置,完美解决主键问题。
-
支持 XML 热加载:Mapper 对应的 XML 支持热加载,对于简单的 CRUD 操作,甚至可以无 XML 启动。
-
支持 ActiveRecord 模式:支持 ActiveRecord 形式调用,实体类只需继承 Model 类即可进行强大的 CRUD 操作。
-
支持自定义全局通用操作:支持全局通用方法注入( Write once, use anywhere )。
-
支持关键词自动转义:支持数据库关键词(order、key......)自动转义,还可自定义关键词。
-
内置代码生成器:采用代码或者Maven 插件可快速生成 Mapper 、Model 、Service 、Controller 层代码,支持模板引擎,更有超多自定义配置等您来使用。
-
内置分页插件:基于 MyBatis 物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通 List 查询。
-
内置性能分析插件:可输出 Sql 语句以及其执行时间,建议开发测试时启用该功能,能快速揪出慢查询。
-
内置全局拦截插件:提供全表 delete 、 update 操作智能分析阻断,也可自定义拦截规则,预防误操作。
-
内置 Sql 注入剥离器
二、快速使用
1. 引入依赖
<dependencies> <!-- mybatis-plus框架 --> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.5.2</version> </dependency> <!--mysql数据库--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.26</version> </dependency> </dependencies>
2. 配置数据源
在application.yml/properties中配置数据源,此处省略
3. 创建实体类
4. 创建映射接口
需要继承BaseMapper<实体类名>,然后就可以直接使用了。
三、通用CRUD
1. 配置日志
使用SpringBoot默认的logback日志或MyBatis-plus集成的日志
MyBatis-Plus集成的日志:
mybatis-plus:
configuration:
#mybatis-plus日志控制台输出
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
global-config:
#关闭banner
banner: false
2. 插入操作
/** * 插入一条记录 * * @param entity 实体对象. */ int insert(T entity);
2.1 @TableId
| 名称 | @TableId |
|---|---|
| 类型 | 属性注解 |
| 位置 | 模型类中用于表示主键的属性定义上方 |
| 作用 | 设置当前类中主键属性的生成策略 |
| 相关属性 | value(默认):设置数据库表主键名称,字段名和属性名相同可以省略 type:设置主键属性的生成策略,值查照IdType的枚举值 |


/** * 生成ID类型枚举类 */ @Getter public enum IdType { /** * 数据库ID自增 * <p>该类型请确保数据库设置了 ID自增 否则无效</p> */ AUTO(0), /** * 该类型为未设置主键类型(注解里等于跟随全局,全局里约等于 INPUT) * 注解中指定为NONE使用全局的生成策略,默认使用雪花算法 */ NONE(1), /** * 用户输入ID * <p>该类型可以通过自己注册自动填充插件进行填充</p> */ INPUT(2), /* 以下2种类型、只有当插入对象ID 为空,才自动填充。 */ /** * 分配ID (主键类型为number或string) * 雪花算法生成id */ ASSIGN_ID(3), /** * 分配UUID (主键类型为 string) */ ASSIGN_UUID(4); }
-
AUTO:数据库ID自增,这种策略适合在数据库服务器只有1台的情况下使用,不可作为分布式ID使用。
-
NONE(默认): 跟随全局的设置(默认使用雪花算法)。
-
INPUT:手动输入或使用插件生成id。
-
ASSIGN_ID:可以在分布式的情况下使用,生成的是Long类型的数字,可以排序性能也高,但是生成的策略和服务器时间有关,如果修改了系统时间就有可能导致出现重复主键。
-
ASSIGN_UUID:可以在分布式的情况下使用,而且能够保证唯一,但是生成的主键是32位的字符串,长度过长占用空间而且还不能排序,查询性能也慢。
-
综上所述,每一种主键策略都有自己的优缺点,根据自己项目业务的实际情况来选择使用才是最明智的选择。
-
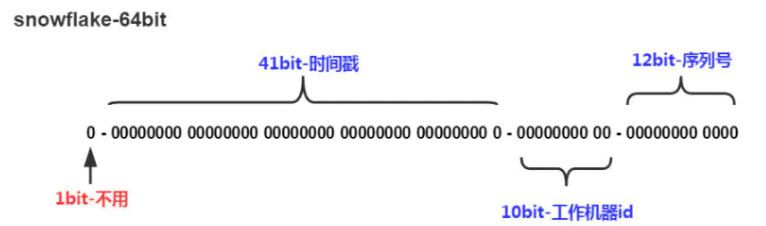
雪花算法(SnowFlake),是Twitter官方给出的算法实现 是用Scala写的。其生成的结果是一个64bit大小整数,它的结构如下图:
-
1bit,不用,因为二进制中最高位是符号位,1表示负数,0表示正数。生成的id一般都是用整数,所以最高位固定为0。
-
41bit-时间戳,用来记录时间戳,毫秒级。
-
10bit-工作机器id,用来记录工作机器id,其中高位5bit是数据中心ID其取值范围0-31,低位5bit是工作节点ID其取值范围0-31,两个组合起来最多可以容纳1024个节点。
-
序列号占用12bit,每个节点每毫秒0开始不断累加,最多可以累加到4095,一共可以产生4096个ID。
2.2 修改id生成策略
1. 局部配置
@TableId(type = IdType.AUTO) id自增策略
用在实体类的属性上
2. 全局配置
配置文件中配置:
mybatis-plus:
global-config:
db-config:
id-type: auto
注意:使用自增策略要求数据库中开启自动递增
2.3 映射匹配设置
1. @TableFiled
| @TableField | |
|---|---|
| 类型 | 属性注解 |
| 位置 | 模型类属性定义上方 |
| 作用 | 设置当前属性对应的数据库表中的字段关系 |
| 相关属性 | value(默认):设置数据库表字段名称 exist:设置属性在数据库表字段中是否存在,默认为true,此属性不能与value合并使用 |
2. @TableName
实体类与表名不一致可以手动指定表名。
| 名称 | @TableName |
|---|---|
| 类型 | 类注解 |
| 位置 | 模型类定义上方 |
| 作用 | 设置当前类对应于数据库表关系 |
| 相关属性 | value(默认):设置数据库表名称 |
也可以全局配置给实体类加上前缀:
mybatis-plus:
global-config:
db-config:
table-prefix: tbl_
3. 更新操作
在MP中有两种更新:根据Id更新,根据指定条件更新
3.1 根据Id更新
/** * 根据 ID 修改 * * @param entity 实体对象 */ int updateById(@Param(Constants.ENTITY) T entity);
直接传入实体类,根据尸体了的Id进行修改:
对于赋值了的属性进行修改,没有赋值的不进行修改。
3.2 根据条件更新
/** * 根据 whereEntity 条件,更新记录 * * @param entity 实体对象 (set 条件值,可以为 null) * @param updateWrapper 实体对象封装操作类(可以为 null,里面的 entity 用于生成 where 语句) */ int update(@Param(Constants.ENTITY) T entity, @Param(Constants.WRAPPER) Wrapper<T> updateWrapper)
wrapper是条件的包装类
在wrapper中设置好条件后作为参数直接传入方法即可。
例如:
@Test void contextLoads() { User user = new User(); //设置更新的字段 user.setEmail("Arvin@123.com"); UpdateWrapper<User> updateWrapper = new UpdateWrapper<>(); //设置更新的条件 updateWrapper.eq("uid", 6L); int i = userMapper.update(user, updateWrapper); }
结果:

也可以用updateWrapper.set()设置更新的字段
//设置更新的字段 updateWrapper.set("age", 28);
4. 删除操作
4.1 根据Id删除
/** * 根据 ID 删除 * * @param id 主键ID */ int deleteById(Serializable id); /** * 根据实体(ID)删除 * * @param entity 实体对象 * @since 3.4.4 */ int deleteById(T entity);
//方式一 userMapper.deleteById(1); //方式二 User user=new User(); user.setId=2; userMapper.deleteById(user);
4.2 根据条指定字段删除
/** * 根据 columnMap 条件,删除记录 * * @param columnMap 表字段 map 对象 */ int deleteByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap);
例:
@Test void contextLoads() { Map<String, Object> columnMap = new HashMap<>(); columnMap.put("uname","Jack"); columnMap.put("age",20); //将columnMap中的键值对设置为删除的条件,多个之间为and关系 int i = this.userMapper.deleteByMap(columnMap); }
结果:

4.3 根据指定条件(wrapper)删除
/** * 根据 entity 条件,删除记录 * * @param queryWrapper 实体对象封装操作类(可以为 null,里面的 entity 用于生成 where 语句) */ int delete(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
例:
@Test void contextLoads() { QueryWrapper<User> queryWrapper = new QueryWrapper<>(); queryWrapper.eq("uname", "Tom"); queryWrapper.eq("age", "28"); int i = userMapper.delete(queryWrapper); }
结果:

默认使用 AND 连接条件,如果用OR,调用 queryWrapper.or()即可。
4.4 根据id批量删除
/** * 删除(根据ID或实体 批量删除) * * @param idList 主键ID列表或实体列表(不能为 null 以及 empty) */ int deleteBatchIds(@Param(Constants.COLL) Collection<?> idList);
5. 查询操作
MP提供了多种查询操作,包括根据id查询、批量查询、查询单条数据、查询列表、分页查询等操作。
5.1 根据id查询
/** * 根据 ID 查询 * * @param id 主键ID */ T selectById(Serializable id);
测试:
@Test void contextLoads() { User user = userMapper.selectById(1L); } ==> Preparing: SELECT uid AS id,uname AS name,age,uemail AS email FROM tb_user WHERE uid=? ==> Parameters: 1(Long) <== Columns: id, name, age, email <== Row: 1, Jone, 18, test1@baomidou.com <== Total: 1
5.2 根据id批量查询
方法定义:
/** * 查询(根据ID 批量查询) * * @param idList 主键ID列表(不能为 null 以及 empty) */ List<T> selectBatchIds(@Param(Constants.COLL) Collection<? extends Serializable> idList);
测试:
@Test void contextLoads() { List<User> list = userMapper.selectBatchIds(Arrays.asList(1L, 2L)); } ==> Preparing: SELECT uid AS id,uname AS name,age,uemail AS email FROM tb_user WHERE uid IN ( ? , ? ) ==> Parameters: 1(Long), 2(Long) <== Columns: id, name, age, email <== Row: 1, Jone, 18, test1@baomidou.com <== Row: 2, Jack, 20, test2@baomidou.com <== Total: 2
5.3 查询一条数据
方法定义:
/** * 根据 entity 条件,查询一条记录 * <p>查询一条记录,例如 qw.last("limit 1") 限制取一条记录, 注意:多条数据会报异常</p> * * @param queryWrapper 实体对象封装操作类(可以为 null) */ default T selectOne(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper) { //... }
测试:
@Test void contextLoads() { QueryWrapper<User> queryWrapper = new QueryWrapper<>(); queryWrapper.eq("uname", "Jack"); queryWrapper.eq("age", 20); User user = userMapper.selectOne(queryWrapper); } ==> Preparing: SELECT uid AS id,uname AS name,age,uemail AS email FROM tb_user WHERE (uname = ? AND age = ?) ==> Parameters: Jack(String), 20(Integer) <== Columns: id, name, age, email <== Row: 2, Jack, 20, test2@baomidou.com <== Total: 1
5.4 查询记录数
方法定义:
/** * 根据 Wrapper 条件,查询总记录数 * * @param queryWrapper 实体对象封装操作类(可以为 null) */ Long selectCount(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
测试:
@Test void contextLoads() { Long aLong = userMapper.selectCount(null); } ==> Preparing: SELECT COUNT( * ) FROM tb_user ==> Parameters: <== Columns: COUNT( * ) <== Row: 6 <== Total: 1
5.5 查询多条数据
方法定义:
/** * 根据 entity 条件,查询全部记录 * * @param queryWrapper 实体对象封装操作类(可以为 null) */ List<T> selectList(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
测试:
@Test void contextLoads() { List<User> list = userMapper.selectList(null); } ==> Preparing: SELECT uid AS id,uname AS name,age,uemail AS email FROM tb_user ==> Parameters: <== Columns: id, name, age, email <== Row: 1, Jone, 18, test1@baomidou.com <== Row: ... <== Total: 6
5.6 分页查询
方法定义:
/** * 根据 entity 条件,查询全部记录(并翻页) * * @param page 分页查询条件(可以为 RowBounds.DEFAULT) * @param queryWrapper 实体对象封装操作类(可以为 null) */ <P extends IPage<T>> P selectPage(P page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
注意:必须配置mybatis拦截器才能生效。
//注解为配置类@Configuration,也可以在引导类@Import({MybatisPlusConfig.class}) @Configuration public class MybatisPlusConfig { //被Spring容器管理 @Bean public MybatisPlusInterceptor mybatisPlusInterceptor(){ //1 创建mp拦截器对象MybatisPlusInterceptor MybatisPlusInterceptor mpInterceptor=new MybatisPlusInterceptor(); //2 添加内置拦截器,参数为分页内置拦截器对象PaginationInnerInterceptor mpInterceptor.addInnerInterceptor(new PaginationInnerInterceptor()); return mpInterceptor; } }
测试:
@Test void contextLoads() { //1 创建IPage分页对象,设置分页参数,1为当前页码,2为每页显示的记录数 IPage<User> page=new Page<>(1,3); //2 执行分页查询 userMapper.selectPage(page,null); //3 获取分页结果,不配置拦截器就只能获取到current和size的数据,pages,total都是0,records是全部数据 System.out.println("当前页码值:"+page.getCurrent()); System.out.println("每页显示数:"+page.getSize()); System.out.println("一共多少页:"+page.getPages()); System.out.println("一共多少条数据:"+page.getTotal()); System.out.println("数据:"+page.getRecords()); }
在MP中有大量的配置,其中有一部分是Mybatis原生的配置,另一部分是MP的配置。
详情:https://mybatis.plus/config/
1. configLocation
MyBatis 配置文件位置,如果有单独的 MyBatis 配置,请将其路径配置到 configLocation 中。
Spring Boot:
mybatis-plus: config-location: classpath:mybatis-config.xml
2. mapperLocations
MyBatis Mapper 所对应的 XML 文件位置,如果您在 Mapper 中有自定义方法(XML 中有自定义实 现),需要进行该配置,告诉 Mapper 所对应的 XML 文件位置。
mybatis-plus: #Maven 多模块项目的扫描路径需以 classpath*: 开头 (即可以加载jar包下的 XML 文件) mapper-locations: classpath*:mybatis/*.xml
3. typeAliasesPackage
MyBaits 别名包扫描路径,通过该属性可以给包中的类注册别名,注册后在 Mapper 对应的 XML 文件 中可以直接使用类名,而不用使用全限定的类名(即 XML 中调用的时候不用包含包名)。
mybatis-plus: type-aliases-package: com.xxx.pojo
4. cacheEnabled
开启Mybatis二级缓存,默认为 true。
关闭二级缓存:
mybatis-plus:
configuration:
cache-enabled: false
五、DQL高级篇
增删改查四个操作中,查询是非常重要的也是非常复杂的操作。
1. 条件查询
1.1 条件查询的Wrapper包装器类
-
MyBatisPlus将书写复杂的SQL查询条件进行了封装,使用编程的形式完成查询条件的组合。
-
查询数据的时候,看到过一个
Wrapper类,这个类就是用来构建查询条件的,如下图所示:
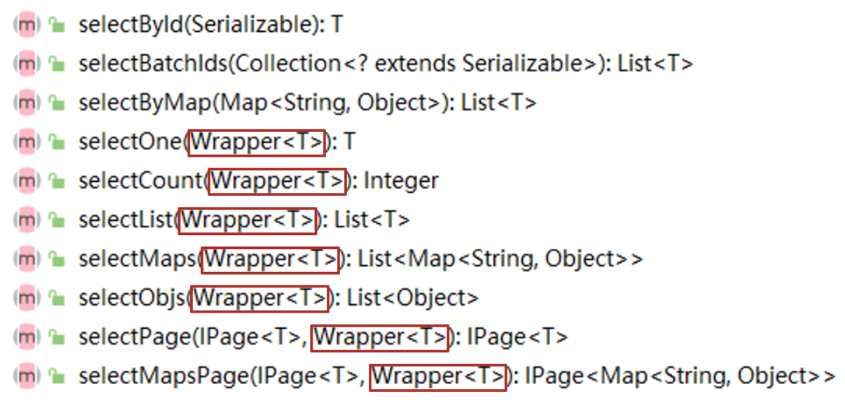
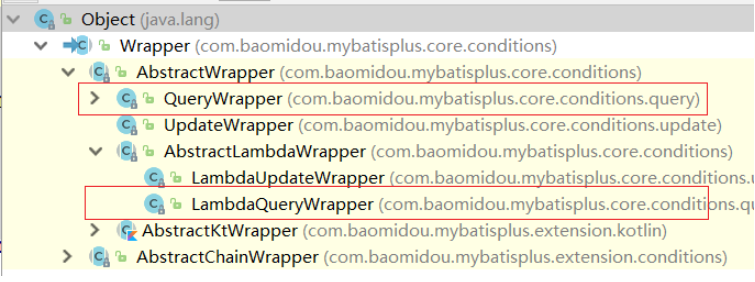
包装器Wrapper<T>是接口,实际开发中主要使用它的两个实现类:
-
QueryWrapper
-
LambdaQueryWrapper
两种方式各有优劣:
-
QueryWrapper存在属性名写错的危险,但是支持聚合、分组查询;
-
LambdaQueryWrapper没有属性名写错的危险,但不支持聚合、分组查询;
1.2 基本查询条件
-
alleq
-
全部eq或个别isNull
-
allEq({id:1,name:"Arvin",age:null})
--->id = 1 and name = 'Arvin' and age is null
-
-
eq
-
等于 =
-
-
ne
-
不等于 <>
-
-
gt
-
大于 >
-
-
ge
-
大于等于 >=
-
-
lt
-
小于 <
-
-
le
-
小于等于 <=
-
-
between
-
BETWEEN 值1 AND 值2
-
-
notBetween
-
NOT BETWEEN 值1 AND 值2
-
-
in
-
字段 IN (...)
-
-
notIn
-
字段 NOT IN (...)
-
-
like
-
like():前后加百分号,如 %J%
-
likeLeft():左边加百分号,如 %J
-
likeRight():后面加百分号,如 J%
-
1.3 构建条件查询
方法一(不建议):QueryWrapper
@Test void contextLoads() { QueryWrapper<User> queryWrapper = new QueryWrapper<>(); queryWrapper.eq("uname", "Tom").gt("age", 20); List<User> list = userMapper.selectList(queryWrapper); } ==> Preparing: SELECT uid AS id,uname AS name,age,uemail AS email FROM tb_user WHERE (uname = ? AND age > ?) ==> Parameters: Tom(String), 20(Integer) <== Columns: id, name, age, email <== Row: 3, Tom, 28, test3@baomidou.com <== Total: 1
方法二(推荐):LambdaQueryWrapper
@Test void contextLoads() { LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>(); wrapper.eq(User::getName, "Tom").gt(User::getAge, 20); List<User> list = userMapper.selectList(wrapper); } ==> Preparing: SELECT uid AS id,uname AS name,age,uemail AS email FROM tb_user WHERE (uname = ? AND age > ?) ==> Parameters: Tom(String), 20(Integer) <== Columns: id, name, age, email <== Row: 3, Tom, 28, test3@baomidou.com <== Total: 1
注意:默认使用and连接,使用or需要自己指定
@Test void contextLoads() { LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>(); wrapper.eq(User::getName, "Tom").or().gt(User::getAge, 20); List<User> list = userMapper.selectList(wrapper); } ==> Preparing: SELECT uid AS id,uname AS name,age,uemail AS email FROM tb_user WHERE (uname = ? OR age > ?) ==> Parameters: Tom(String), 20(Integer) <== Columns: id, name, age, email <== Row: 3, Tom, 28, test3@baomidou.com <== Row: 4, Sandy, 21, test4@baomidou.com <== Row: 5, Billie, 24, test5@baomidou.com <== Total: 3
2. 查询投影
-
目前我们在查询数据的时候,什么都没有做默认就是查询表中所有字段的内容。
-
查询投影:不查询所有字段,只查询出指定字段的数据。
方法一(推荐):使用Lambda
@Test void contextLoads() { LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>(); wrapper.eq(User::getName, "Tom").gt(User::getAge, 20); wrapper.select(User::getId, User::getName); List<User> list = userMapper.selectList(wrapper); } ==> Preparing: SELECT uid AS id,uname AS name FROM tb_user WHERE (uname = ? AND age > ?) ==> Parameters: Tom(String), 20(Integer) <== Columns: id, name <== Row: 3, Tom <== Total: 1
方法二(不建议):不用lambda
@Test void contextLoads() { QueryWrapper<User> queryWrapper = new QueryWrapper<>(); queryWrapper.eq("uname", "Tom").gt("age", 20); queryWrapper.select("uid", "uname"); List<User> list = userMapper.selectList(queryWrapper); } ==> Preparing: SELECT uid,uname FROM tb_user WHERE (uname = ? AND age > ?) ==> Parameters: Tom(String), 20(Integer) <== Columns: uid, uname <== Row: 3, Tom <== Total: 1
3. 逻辑删除
-
逻辑删除的本质其实是修改操作。
3.1 @TableLogic
| 名称 | @TableLogic |
|---|---|
| 类型 | 属性注解 |
| 位置 | 模型类中用于表示删除字段的属性定义上方 |
| 作用 | 标识该字段为进行逻辑删除的字段 |
| 相关属性 | value:逻辑未删除值 delval:逻辑删除值 |
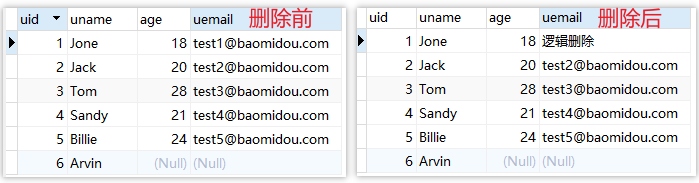
3.2 删除
@TableName("tb_user")
public class User {
@TableId(value = "uid", type = IdType.AUTO)
private Long id;
@TableField("uname")
private String name;
private Integer age;
@TableField("uemail")
@TableLogic(value = "test1@baomidou.com", delval = "逻辑删除")
private String email;
}
@Test
void contextLoads() {
int i = userMapper.deleteById(1L);
}
==> Preparing: UPDATE tb_user SET uemail='逻辑删除' WHERE uid=? AND uemail='test1@baomidou.com'
==> Parameters: 1(Long)
<== Updates: 1
4. 悲观锁与乐观锁
4.1 悲观锁
悲观锁在操作数据时比较悲观,每次更新数据的时候认为别的线程也会同时更新数据,所以每次更新数据是都会上锁,这样别的线程就会阻塞等待获取锁。
4.2 乐观锁
乐观锁在更新数据时非常乐观,认为别的线程不会同时更新数据,所以不会上锁,但是在更新之前会判断在此期间别的线程是否有更新过该数据。
4.2.1 乐观锁使用案例
-
假如有100个商品或者票在出售,为了能保证每个商品或者票只能被一个人购买,如何保证不会出现超买或者重复卖。
-
对于这一类问题,其实有很多的解决方案可以使用。
-
第一个最先想到的就是锁,锁在一台服务器中是可以解决的,但是如果在多台服务器下锁就没有办法控制,比如12306有两台服务器在进行卖票,在两台服务器上都添加锁的话,那也有可能会导致在同一时刻有两个线程在进行卖票,还是会出现并发问题。
-
我们接下来介绍的这种方式是针对于小型企业的解决方案,因为数据库本身的性能就是个瓶颈,如果对其并发量超过2000以上的就需要考虑其他的解决方案了。
4.2.2 乐观锁实现思路
-
数据库表中添加version列,比如默认值给1。
-
第一个线程要修改数据之前,取出记录时,获取当前数据库中的version=1。
-
第二个线程要修改数据之前,取出记录时,获取当前数据库中的version=1。
-
第一个线程执行更新时,set version = newVersion where version = oldVersion
-
newVersion = version+1 [2]
-
oldVersion = version [1]
-
-
第二个线程执行更新时,set version = newVersion where version = oldVersion
-
newVersion = version+1 [2]
-
oldVersion = version [1]
-
4.2.3 乐观锁实现
-
添加version属性,添加@Version注解
@TableName("tb_user")
public class User {
@TableId(value = "uid", type = IdType.AUTO)
private Long id;
@TableField("uname")
private String name;
private Integer age;
@TableField("uemail")
private String email;
@Version
private Integer version;
}
-
配置mybatis拦截器
@Configuration public class MpConfig { @Bean public MybatisPlusInterceptor mpInterceptor() { //1.定义Mp拦截器 MybatisPlusInterceptor mpInterceptor = new MybatisPlusInterceptor(); //2.添加乐观锁拦截器 mpInterceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor()); return mpInterceptor; } }
-
表中添加version字段
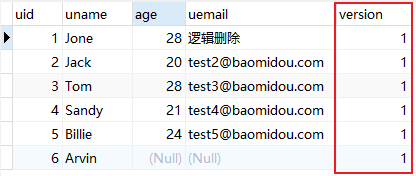
-
先查询version再更新操作
@Test void contextLoads() { User user = userMapper.selectById(2L); user.setAge(30); int i = userMapper.updateById(user); } ==> Preparing: SELECT uid AS id,uname AS name,age,uemail AS email,version FROM tb_user WHERE uid=? ==> Parameters: 2(Long) <== Columns: id, name, age, email, version <== Row: 2, Jack, 20, test2@baomidou.com, 1 <== Total: 1 ==> Preparing: UPDATE tb_user SET uname=?, age=?, uemail=?, version=? WHERE uid=? AND version=? ==> Parameters: Jack(String), 30(Integer), test2@baomidou.com(String), 2(Integer), 2(Long), 1(Integer) <== Updates: 1
六、Service的CRUD
1. 快速入门
-
IService<User> -
ServiceImpl<UserMapper, User>
public interface UserService extends IService<User> { } @Service public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService { }
2. 查询
2.1 Get
// 根据 ID 查询 T getById(Serializable id); // 根据 Wrapper,查询一条记录。结果集,如果是多个会抛出异常,随机取一条加上限制条件 wrapper.last("LIMIT 1") T getOne(Wrapper<T> queryWrapper); // 根据 Wrapper,查询一条记录,有多个 result 是否抛出异常 T getOne(Wrapper<T> queryWrapper, boolean throwEx); // 根据 Wrapper,查询一条记录 Map<String, Object> getMap(Wrapper<T> queryWrapper); // 根据 Wrapper,查询一条记录,转换函数 <V> V getObj(Wrapper<T> queryWrapper, Function<? super Object, V> mapper);
2.2 List
// 查询所有 List<T> list(); // 查询列表 List<T> list(Wrapper<T> queryWrapper); // 查询(根据ID 批量查询) Collection<T> listByIds(Collection<? extends Serializable> idList); // 查询(根据 columnMap 条件) Collection<T> listByMap(Map<String, Object> columnMap); // 查询所有列表 List<Map<String, Object>> listMaps(); // 查询列表 List<Map<String, Object>> listMaps(Wrapper<T> queryWrapper); // 查询全部记录 List<Object> listObjs(); // 查询全部记录 <V> List<V> listObjs(Function<? super Object, V> mapper); // 根据 Wrapper 条件,查询全部记录 List<Object> listObjs(Wrapper<T> queryWrapper); // 根据 Wrapper 条件,查询全部记录 <V> List<V> listObjs(Wrapper<T> queryWrapper, Function<? super Object, V> mapper);
2.3 Page
// 无条件分页查询 IPage<T> page(IPage<T> page); // 条件分页查询 IPage<T> page(IPage<T> page, Wrapper<T> queryWrapper); // 无条件分页查询 IPage<Map<String, Object>> pageMaps(IPage<T> page); // 条件分页查询 IPage<Map<String, Object>> pageMaps(IPage<T> page, Wrapper<T> queryWrapper);
2.4 Count
// 查询总记录数 int count(); // 根据 Wrapper 条件,查询总记录数 int count(Wrapper<T> queryWrapper);
2.5 Chain
// 链式查询 普通 QueryChainWrapper<T> query(); // 链式查询 lambda 式。注意:不支持 Kotlin LambdaQueryChainWrapper<T> lambdaQuery(); // 示例: query().eq("column", value).one(); lambdaQuery().eq(Entity::getId, value).list();
3. 添加
3.1 Save
// 插入一条记录(选择字段,策略插入) boolean save(T entity); // 插入(批量) boolean saveBatch(Collection<T> entityList); // 插入(批量) boolean saveBatch(Collection<T> entityList, int batchSize);
3.2 SaveOrUpdate
// TableId 注解存在更新记录,否插入一条记录 boolean saveOrUpdate(T entity); // 根据updateWrapper尝试更新,否继续执行saveOrUpdate(T)方法 boolean saveOrUpdate(T entity, Wrapper<T> updateWrapper); // 批量修改插入 boolean saveOrUpdateBatch(Collection<T> entityList); // 批量修改插入,插入批次数量 boolean saveOrUpdateBatch(Collection<T> entityList, int batchSize);
4. 删除
// 根据 entity 条件,删除记录 boolean remove(Wrapper<T> queryWrapper); // 根据 ID 删除 boolean removeById(Serializable id); // 根据 columnMap 条件,删除记录 boolean removeByMap(Map<String, Object> columnMap); // 删除(根据ID 批量删除) boolean removeByIds(Collection<? extends Serializable> idList);
5. 更新
// 根据 UpdateWrapper 条件,更新记录 需要设置sqlset boolean update(Wrapper<T> updateWrapper); // 根据 whereWrapper 条件,更新记录 boolean update(T updateEntity, Wrapper<T> whereWrapper); // 根据 ID 选择修改 boolean updateById(T entity); // 根据ID 批量更新 boolean updateBatchById(Collection<T> entityList); // 根据ID 批量更新 boolean updateBatchById(Collection<T> entityList, int batchSize);
七、ActiveRecord简介
1. 介绍
ActiveRecord属于ORM(对象关系映射)层,由Rails最早提出,遵循标准的ORM模型:表映射到记录,记录映射到对象,字段映射到对象属性。配合遵循的命名和配置惯例,能够很大程度的快速实现模型的操作,而且简洁易懂。
ActiveRecord的主要思想是: 每一个数据库表对应创建一个类,类的每一个对象实例对应于数据库中表的一行记录;通常 表的每个字段在类中都有相应的Field; ActiveRecord同时负责把自己持久化,在ActiveRecord中封装了对数据库的访问,即 CURD。
ActiveRecord是一种领域模型(Domain Model),封装了部分业务逻辑。
2. CRUD
class User extends Model<User>{ // fields... }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号