MyBatis
Mybatis官方文档:https://mybatis.org/mybatis-3/zh/index.html
启用日志
1. MyBatis支持的日志
-
SLF4J
-
Apache Commons Logging
-
Log4j 2
-
Log4j (deprecated since 3.5.9)
-
JDK logging
<dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> </dependency>


log4j.rootLogger=ERROR, stdout # log4j.logger是固定的,a.b.c是命名空间的名字可以只写一部分。 log4j.logger.a.b.c=TRACE log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%5p [%t] - %m%n
2. log4j2
<dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-core</artifactId> <version>2.17.2</version> </dependency>
<?xml version="1.0" encoding="utf-8" ?> <Configuration > <Appenders> <Console name="Console" target="SYSTEM_OUT"> <PatternLayout pattern="%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n"/> </Console> </Appenders> <Loggers> <Root level="info"> <AppenderRef ref="Console"/> </Root> <!-- namespace的值 --> <logger name="a.b.c" level="debug"></logger> </Loggers> </Configuration>
3. SLF4j
<!--slf4j整合log4j的依赖,版本要和slf4j的版本对应 --> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.36</version> </dependency> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> </dependency>
配置文件同log4j配置文件
<dependencies> <!-- SLF4j整合Log4j2的依赖 --> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-slf4j-impl</artifactId> <version>2.17.2</version> </dependency> <!-- Log4j2工具的依赖--> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-core</artifactId> <version>2.17.2</version> </dependency> </dependencies>
配置文件同log4j2配置文件
一、别名
在核心配置文件中使用<typeAliases>标签配置别名。
别名可以用于映射文件中的resultType属性。
1.直接配置别名
<typeAliases> <!-- type:类型全限定路径 alias:别名名称 --> <typeAlias type="com.gsy.pojo.People" alias="p"></typeAlias> <typeAlias type="com.gsy.pojo.People" alias="p2"></typeAlias> </typeAliases>
注意:同一个类可以有多个别名;
且在使用时不区分大小写;
设置了别名后,类的全限定名依然有效。
2.扫描包配置别名
<typeAliases> <!-- 指定包 --> <package name="com.gsy.pojo"/> </typeAliases>
MyBatis在解析xml文件时会将指定的包中所有实体类配置别名为类名
注意:使用这种方式时严格区分大小写;
可以与直接配置别名混用。
3.MyBatis内置的别名
| 别名 | 映射的类型 | 别名 | 映射的类型 | 别名 | 映射的类型 | ||
|---|---|---|---|---|---|---|---|
| _byte | byte | string | String | date | Date | ||
| _long | long | byte | Byte | decimal | BigDecimal | ||
| _short | short | long | Long | bigdecimal | BigDecimal | ||
| _int | int | short | Short | object | Object | ||
| _integer | int | int | Integer | map | Map | ||
| _double | double | integer | Integer | hashmap | HashMap | ||
| _float | float | double | Double | list | List | ||
| _boolean | boolean | float | Float | arraylist | ArrayList | ||
| boolean | Boolean | collection | Collection | ||||
| iterator |
二、结果集映射的方式(面)
-
auto mapping:自动映射。当列名或列的别名与实体类属性名相同时不需要做额外配置。
-
resultMap:手动定义映射关系。
-
1.Auto Mapping(自动映射)
这要求resultType指定的类的属性与查询结果返回字段相对应,字段名和属性名不一致就无法映射。
2.resultMap
当数据库表中字段名和类的属性名不一致,就需要手动指定才能完成映射。
<mapper namespace="a.b.c"> <!-- type:数据库中每行数据对应的实体类型,支持别名 --> <!-- id:自定义名称--> <resultMap id="myid" type="People2"> <!-- id标签定义主键列和属性的映射关系关系 --> <!-- property 类中属性名称,区分大小写--> <!-- column 表中列名--> <id property="peoId" column="peo_id"/> <!-- result标签定义非主键列和属性的映射关系--> <result property="peoName" column="peo_name"/> </resultMap> <!-- resultMap的值必须和resultMap的id相同 --> <select id="myid" resultMap="myid"> select * from tb_people </select> </mapper>
这时就不需要resultType了,直接用配置好的resultMap。
resultMap支持继承,
<resultMap id="myid2" type="People2" extends="myid"> </resultMap>
3.camel case
MyBatis可以自动驼峰命名转换
<settings> <!-- 开启驼峰转换 --> <setting name="mapUnderscoreToCamelCase" value="true"/> </settings>
三、接口绑定
MyBatis提供了一种接口绑定方案,通过SqlSession的getMapper方法产生接口的动态代理对象(该接口的实现类)。然后通过对象调用接口中提供的功能。
1.resource
<!--配置mapper映射--> <mappers> <mapper resource="com/gsy/dao/UserMapper.xml"/> </mappers>
2.class
<mappers> <mapper class="com.gsy.dao.UserMapper"/> </mappers>
注意
这种方式要求接口和映射文件输出到target目录后都在同一个文件夹且同名;
映射文件中的namespace命名空间为接口的全限定名,statement的id必须跟接口的方法名一致
(底层通过反射找到对应的方法,封装了sqlSession.xxx(namespace+id)进行绑定)
即:
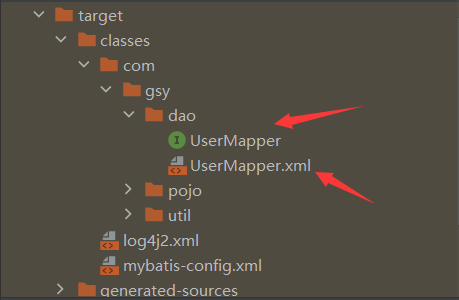
两种解决方式:
1.将映射文件放和接口放在同一个包,然后在pom.xml中配置深度资源拷贝插件。
2.在resource目录下建立相同的路径,注意由于是路径,所以不要用com.gsy.dao,而是com/gsy/dao
放在同一个文件夹且必须同名的原因:
MyBatis底层会直接将绑定的class中的 . 转换为 / 再拼接 .xml 去拿映射文件

3. package
<mappers> <package name="com.gsy.dao"/> </mappers>
使用该方式注意事项同使用class绑定。
使用package扫描包的方式 Mybatis会将指定的包中所有接口都进行注册。
4.使用
无需再通过sqlSession根据namespace+id调用方法了
通过sqlSession.getMapper(class<?>) 获取对应接口的实现类然后调用方法即可。
四、接口绑定的参数传递
Map类型当做参数时,在映射文件中通过Map的key进行获取value值。
Mybatis会自动创建Map的key:
-
如果接口中方法没有使用注解定义名称,MyBatis使用内置名称作为key。MaBatis会在底层生成对应的参数名:arg0、arg1、param1、param2、其中arg0和param1的值都是同一个参数,以此类推。
规则:arg0、arg1、argM(M为从0开始的数字,和方法参数顺序对应)或param1、param2、paramN(N为从1开始的数字,和方法参数顺序对应)。
-
五、主键回填
-
使用
<selectKey>子标签编写SQL进行回填属性值。 -
使用
<select>
1. selectKey
<insert id="insert1"> <selectKey keyProperty="id" resultType="int"> select @@identity </selectKey> insert into people values(default,#{name},#{address}) </insert>
- resultType:SQL查询到的结果类型。
- select @@identity:是MySQL内置的全局变量表示获取到自增主键值。
2. 自动主键回填
<insert id="insert2" useGeneratedKeys="true" keyProperty="id"> insert into people values(default,#{name},#{address}) </insert>
六、动态SQL
1. if标签
mapper映射文件通过if进行判断参数的属性是否为null。
<if>
<select id="selectIf" resultType="People"> select * from people where 1=1 <if test="name!=null"> and name=#{name} </if> <if test="address!=null"> and address=#{address} </if> </select>
name!=null : OGNL 表达式,直接写属性名可以获取到属性值。不需要添加${}或#{}。
name=#{name} 中name是表中的列名。#{name}是MyBatis获取参数对象属性值的写法(之前学习的)。
2. choose标签
choose标签相当于Java中的switch...case....default。(if..else...if+default)
在choose标签里面可以有多个when标签和一个otherwise(可以省略)标签。只要里面有一个when成立了后面的when和otherwise就不执行了。
<select id="selectIf" resultType="People"> select * from people where 1=1 <choose> <when test="name!=null"> and name=#{name} </when> <when test="address!=null"> and address=#{address} </when> <otherwise> // do something </otherwise> </choose> </select>
3. trim标签
trim作为很多其它标签的底层。
无论是开头操作还是结尾的操作,都是先去掉容,后添加。
trim只会对里面的子内容进行操作。如果子内容为空则不进行任何操作。
后添加的内容会有空格。
特例:
如果内部字符串为要去掉的字符串,去掉后认为内容不为空,prefix依然添加。
trim标签包含四个属性:
- prefix:只要子内容不是空字符串(""),就在子内容前面添加特定字符串。
- prefixOverrides:如果子内容是以某个内容开头,去掉这个内容。
- suffix:只要内容不是空字符串(""),就在子内容后面添加特定字符串。
- suffixOverrides:如果里面内容以某个内容结尾,就去掉这个内容。
<select id="selectIf" resultType="People"> select * from people <trim prefix="where" prefixOverrides="and"> <if test="name!=null"> and name=#{name} </if> <if test="address!=null"> and address=#{address} </if> </trim> </select>
4. where标签
- 如果里面内容不为空串,在里面内容最前面添加where。
<select id="selectIf" resultType="People"> select * from people <where> <if test="name!=null"> and name=#{name} </if> <if test="address!=null"> and address=#{address} </if> </where> </select>
5. set标签
set标签是专门用在修改SQL中的,属于trim的简化版,带有下面功能:
- 如果子内容不为空串,在最前面添加set。
<update id="update"> update people <set> <if test="name!=null"> name=#{name}, </if> <if test="address!=null"> address=#{address}, </if> id=#{id} </set> where id = #{id} </update>
注意:set结束标签的后面的id=#{id}是非常重要的,不能不写。因为set在解析时,如果里面为空串,是不会在前面添加set的,对于SQL的修改来说,没有set关键字是不正确的语法。
6. foreach标签
foreach标签表示循环,主要用在in查询或批量新增的情况。
<select id="selectByIds" resultType="People"> select * from people where id in <foreach collection="array" open="(" close=")" item="id" separator=","> #{id} </foreach> </select>
collection:要遍历的数组或集合对象。
1. 如果参数没有使用@Param注解:arg0或array或list。
2. 如果使用@Param注解,使用注解的名称或param1。
open:遍历结束在前面添加的字符串。
close:遍历结束在后面添加的字符串。
item:迭代变量。在foreach标签里面#{迭代变量}获取到循环过程中迭代变量的值。
separator:分隔符。在每次循环中间添加的分割字符串。
index:迭代的索引。从0开始的数字。
7. bind标签
bind标签表示对传递进来的参数重新赋值。最多的使用场景为模糊查询。通过bind可以不用在Java代码中对属性添加%。
<select id="selectLike" resultType="People"> <bind name="name" value="'%'+name+'%'"/> select * from people where name like #{name} </select>
PS:
模糊查询另一种写法为使用SQL中的CONCAT函数,将%与参数拼接进行查询
例如:
<select id="selectPeopleByLike" resultType="people"> select * from people <where> <if test="name!=null"> and name like concat('%',#{name},'%') </if> <if test="address!=null"> and address like concat('%',#{address},'%') </if> </where> </select>
8. sql和include标签
对于多次重复使用且比较冗余的sql代码可以使用sql标签作为SQL片段
使用时用include标签引入即可
<sql id="mysqlpart"> id,name,address </sql> <select id="selectSQL" resultType="People"> select <include refid="mysqlpart"></include> from people </select>
include引入的内容和sql片段中的完全一致。
七、MyBatis常用注解
MyBatis的注解通过全局配置文件<mappers>
<mappers> <mapper class="com.gsy.mapper.PeopleMapper"></mapper> </mappers>
-
如果一个Mapper接口中既有注解又有mapper.xml定义SQL。可以在全局配置文件中通过
<package>进行加载。这种方式和之前的接口绑定方案的配置是一样的。也就是说MyBatis在扫描这个包的时候就可以加载到注解。
<mappers> <package name="com.bjsxt.mapper"/> </mappers>
在MyBatis中注解都是写在Mapper接口的方法上中,所有的注解都在org.apache.ibatis.annotations包中,常见注解:
| 解释 | |
|---|---|
| @Select | 查询 |
| @Insert | 新增 |
| @Delete | 删除 |
| @Update | 修改 |
| @SelectKey | 主键回填 |
| @SelectProvider | 调用SQL构建器。查询专用 |
| @DeleteProvider | 调用SQL构建器。删除专用 |
| @UpdateProvider | 调用SQL构建器。修改专用 |
| @INSERTProvider | 调用SQL构建器。删除专用 |
| @Param |
1. CRUD
public interface PeopleMapper { @Select("select * from people") List<People> selectAll(); @Insert("insert into people values(default,#{name},#{address})") int insert(People peo); @Delete("delete from people where id=#{id}") int deleteById(int id); @Update("update people set name=#{name},address=#{address} where id=#{id}") int updateById(People peo); }
2. 主键回填
使用注解时,主键回填需要通过@SelectKey注解。
该注解中:必有属性
keyProperty:表示回填属性名。
statement:执行的sql。
before:表示是否在@Insert的SQL之前执行。
resultType:表示statement对应SQL执行结果。
@Insert("insert into people values(default,#{name},#{address})")
@SelectKey(keyProperty = "id",statement = "select @@identity",before = false,resultType = Integer.class)
int insert(People people);
3. SQL构建器(Provider)
如果SQL较长还想使用注解,可以使用SQL构建器
MyBatis的SQL构建器赋予了程序员在Java类中编写SQL的方式。把以前写在注解参数中的复杂SQL转移到了类的方法中进行书写。
3.1 直接写SQL
-
type:编写SQL的类。
-
@SelectProvider(type = MySQLProvider.class,method = "selectprovider") List<People> select(People peo);
下面代码并不是必须写成多行,只是为了演示当SQL比较复杂时都是分多行写的效果。
public class MySQLProvider { public String selectprovider(){ return "select *" + " from people" + " where name=#{name} and address like #{address}" + " order by id desc"; } }
看起来写的不是特别费劲,但是一定要注意关键字前后都有空格。上面代码每行前面都有空格,其实这点非常不友好。
3.2 使用SQL类
里面需要注意的点:
- 如果多个条件可以放在一个where中,也可以放在多个连续where中(放在多个where方法中不需要and关键字)。
import org.apache.ibatis.jdbc.SQL; public class MySQLProvider { public String selectprovider2(){ return "select *" + "from people" + "where name=#{name} and address like #{address}" + "order by id desc"; } public String selectprovider(){ return new SQL() .SELECT("*") .FROM("people") .WHERE("name=#{name}") // 没有and,多个并列条件使用WHERE方法 .WHERE("address like #{address}") .ORDER_BY("id desc") .toString(); } }
4. 使用注解进行结果映射
@Result注解:
column:数据库列
property:属性名
@Results(value = { @Result(column = "peo_id",property = "id",id = true), @Result(column = "peo_name",property = "name") }) @Select("select * from tb_people where peo_name=#{name}") List<People> select2(People peo);
八、多表查询(面)
表之间关系分为:一对一、一对多、多对多。这三种关系又细分为单向和双向。
在MyBatis框架中只有两种情况:当前表对应另外表是一行数据还是多行数据。转换到实体类上:当前实体类包含其它实体类一个对象还是多个对象。
-
如果一个实体类关联另一个实体类的一个对象使用
<association>。<resultMap id="empMap" type="com.gsy.pojo.Emp"> <id property="eid" column="eid"/> <result property="name" column="ename"/> <result property="deptId" column="dept_id"/> <association property="dept" javaType="com.gsy.pojo.Dept"> <id property="did" column="did"/> <result property="name" column="dname"/> <result property="addr" column="addr"/> </association> </resultMap> <select id="allEmpAndDept" resultMap="empMap"> select eid,ename,dept_id,did,dname,addr from emp , dept where dept_id=did </select>
-
如果一个实体类关联一个实体类的List集合对象,需要使用
<collection>。<resultMap id="deptMap" type="Dept"> <id column="did" property="did"/> <result column="dname" property="name"/> <result column="addr" property="addr"/> <collection property="list" ofType="Map"> <id column="eid" property="eid"/> <result column="ename" property="name"/> </collection> </resultMap> <select id="allDeptAndEmp" resultMap="deptMap"> select eid,ename,dept_id,did,dname,addr from emp , dept where dept_id=did </select>
一对多就用collection ,也可以这样写。oftype用来将 JavaBean(或字段)属性的类型和集合存储的类型区分开来。
<collection property="list" javaType="java.util.List" ofType="Dept">
-
-
联合查询方式:
优点:一次查询。
缺点:SQL相对复杂。不支持延迟加载。
-
业务装配(N+1的一种)
优点:手动实现,灵活度高。
缺点:代码复杂。
-
N+1方式:
优点:SQL简单。支持延迟加载。
select e_id,e_name,e_d_id,d_id,d_name from dept,emp where d_id=e_d_id
2. 业务装配
N+1查询方式,在进行操作时需要先分析出最终想要的结果需要包含对于两张表的单表查询语句是什么。
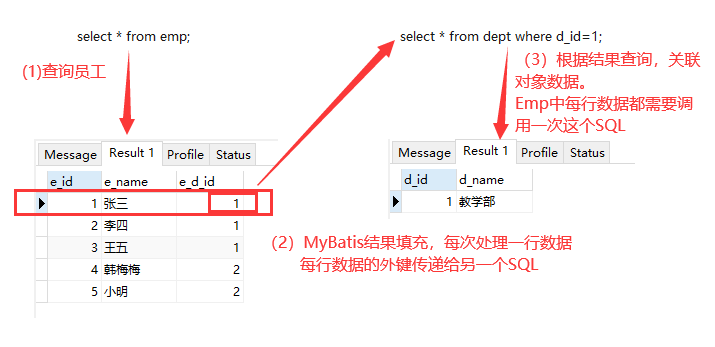
<resultMap id="empMap2" type="Emp"> <id column="e_id" property="id"/> <result column="e_name" property="name"/> <!-- 此处依然使用association填充单个对象属性值.property和javaTye依然需要写 --> <!-- select 调用另一个查询的路径,同一个映射文件中,前面namespace可以省略--> <!-- column: 当前SQL查询结果哪个列值当做参数传递过去。如果是多个参数{"key":column,"key2":column2}--> <association property="dept" javaType="Dept" select="com.gsy.mapper.DeptMapper.selectById" column="e_d_id"></association> </resultMap>
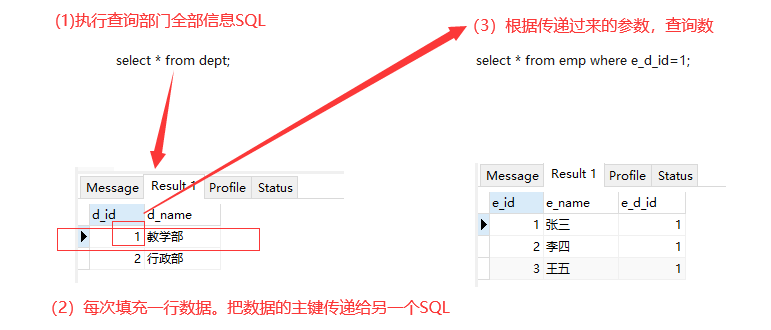
<resultMap id="deptMap3" type="Dept"> <id column="d_id" property="id"></id> <result column="d_name" property="name"></result> <!-- 加载集合类型属性时依然使用collection标签,property和ofType依然存在 --> <!-- select 调用另一个查询的路径,同一个映射文件中,前面namespace可以省略--> <!-- column 当前查询哪个列的值作为参数传递给另一个参数--> <collection property="list" ofType="Emp" select="com.bjsxt.mapper.EmpMapper.selectByEid" column="d_id"/> </resultMap> <select id="selectAllN1" resultMap="deptMap3"> select * from dept </select>
九、延迟加载(面)
只能使用在多表联合查询的N+1方式中。
1. 启用延迟加载
全局配置。整个项目所有N+1位置都生效。
局部配置。只配置某个N+1位置。
| 解释说明 | 可取值 | 默认值 | |
|---|---|---|---|
| lazyLoadingEnabled | 延迟加载的全局开关。当开启时,所有关联对象都会延迟加载。 特定关联关系中可通过设置 fetchType 属性来覆盖该项的开关状态。 |
true | false |
全局配置方式
从3.4.1版本开始需要在MyBatis全局配置文件里面配置lazyLoadingEnabled=true即可在当前项目所有N+1的位置开启延迟加载。
<settings> <setting name="lazyLoadingEnabled" value="true"/> </settings>
局部配置方式:
<resultMap id="empMap2" type="Emp"> <id column="e_id" property="id"/> <result column="e_name" property="name"/> <association property="dept" javaType="Dept" select="com.bjsxt.mapper.DeptMapper.selectById" column="e_d_id" fetchType="lazy"></association> </resultMap> <select id="selectAllN1" resultMap="empMap2"> select e_id,e_name,e_d_id from emp </select>
十一、缓存(面)
-
一级存储是SqlSession上的缓存。
-
二级缓存是在SqlSessionFactory(namespace)上的缓存。
-
1. 一级缓存
一级缓存想要生效,必须同时满足3个条件:
1. 同一个SqlSession对象。
2. 同一个select标签。本质为底层同一个JDBC的Statemen对象。
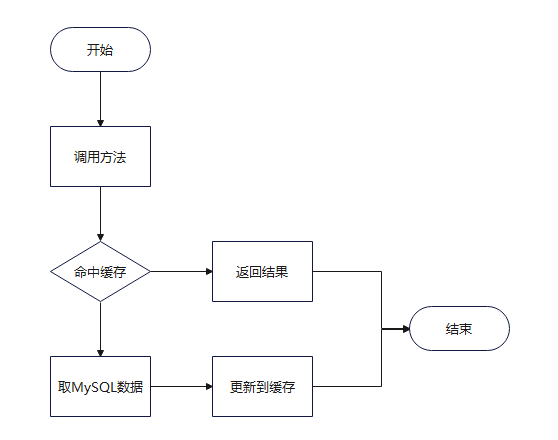
1.2 一级缓存流程
一级缓存执行流程:默认开启
1.根据调用的接口中的方法 + SQL语句 + ... 建立了缓存的 key
2.从一级缓存(localCache)中获取key对应的数据
无:从数据库查询,将查询结果存储到一级缓存中,(key,数据),返回查询到的数据
有:直接返回一级缓存中获取到的数据
3.一级缓存基于SqlSession,使用同一个SqlSession一级缓存生效
4.执行了写操作会先清除缓存再执行写入操作。
注意:清除一级缓存
1.commit() rollback()
2.insert() update() delete()
3.close()
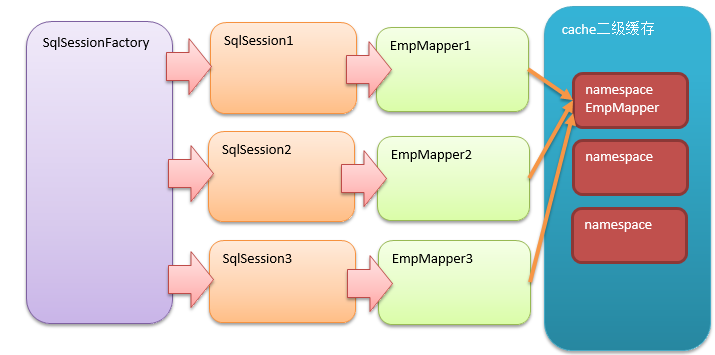
2. 二级缓存
二级缓存是以namespace为标记的缓存,可能要借助磁盘,磁盘上的缓存,可以由一个SqlSessionFactory创建的SqlSession之间共享缓存数据,默认并不开启。
同一个SqlSessionFactory对象。
同一个方法(<select>)。
SQL完全相同。
重要提示:
二级缓存默认不开启,需要手动开启。
<settings> <setting name="cacheEnabled" value="true"/> </settings>
使用<cache/>配置时,
<mapper namespace="com.bjsxt.mapper.EmpMapper"> <cache/> </mapper>
二级缓存未必完全使用内存,有可能占用硬盘存储,缓存中存储的JavaBean对象必须实现序列化接口
public class Dept implements Serializable { }

MyBatis的二级缓存的缓存介质有多种多样,而并不一定是在内存中,所以需要对JavaBean对象实现序列化接口。
二级缓存是以 namespace 为单位的,不同 namespace 下的操作互不影响。
查询数据顺序 二级-->一级--->数据库--->把数据保存到一级,当sqlsession关闭或者提交的时候,把一级缓存中数据刷新到二级缓存中。
执行了DML操作,会清空一级缓存,所以数据变更不可能到达二级缓存中。
<cache type="" readOnly="" eviction=""flushInterval=""size=""blocking=""/>
| 含义 | 默认值 | |
|---|---|---|
| type | 自定义缓存类,要求实现org.apache.ibatis.cache.Cache接口 | null |
| readOnly | 是否只读true:给所有调用者返回缓存对象的相同实例。因此这些对象不能被修改。这提供了很重要的性能优势。false:会返回缓存对象的拷贝(通过序列化) 。这会慢一些,但是安全 | false |
| eviction | 缓存策略LRU(默认) – 最近最少使用的:移除最长时间不被使用的对象。FIFO – 先进先出:按对象进入缓存的顺序来移除它们。SOFT – 软引用:基于垃圾回收器状态和软引用规则移除对象。WEAK – 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。 | LRU |
| flushInterval | 刷新间隔,毫秒为单位。 | null |
| size | 缓存对象个数。 |
如果在加入Cache元素的前提下让个别select 元素不使用缓存,可以使用useCache属性,设置为false。useCache控制当前sql语句是否启用缓存,
<select id="findByEmpno" resultType="emp" useCache="true" flushCache="false">
2.2 二级缓存执行流程
二级缓存执行流程:手动开启(映射文件中通过 <cache/>开启)
select标签中设置useCache="false"表示select标签不使用二级缓存
每一个映射文件对应着一个映射文件的二级缓存
有效范围:同一个映射文件中的SQL
1.根据调用的接口中的方法 + select语句 + ... 建立了缓存的 key
2.从当前映射文件的二级缓存(真正存储二级缓存数据的集合:Cache接口实现类PerpetualCache的cache属性[本质为map集合])中根据key获取对应数据
无:
1.从一级缓存(localCache)中获取key对应的数据
无:从数据库查询,将查询结果存储到一级缓存中,(key,数据),返回查询到的数据
有:直接返回一级缓存中获取到的数据
2.添加到二级缓(临时存储缓存数据的集合:Cache接口实现类TransactionalCache的entriesToAddOnCommit属性[本质为map集合])存中,返回数据
3.执行了,commit(),close() 将临时缓存map集合(entriesToAddOnCommit)中数据存储到真正存储缓存map集合(cache)中
有:直接返回二级缓存中的数据
注意:清除二级缓存
添加,修改,删除
1. 四大核心接口
-
Executor执行器,执行器负责整个SQL执行过程的总体控制。默认SimpleExecutor执行器。
-
StatementHandler语句处理器,语句处理器负责和JDBC层具体交互,包括prepare语句,执行语句,以及调用ParameterHandler.parameterize()。默认是PreparedStatementHandler。
-
ParameterHandler参数处理器,参数处理器,负责PreparedStatement入参的具体设置。默认使用DefaultParameterHandler。
-
执行顺序图
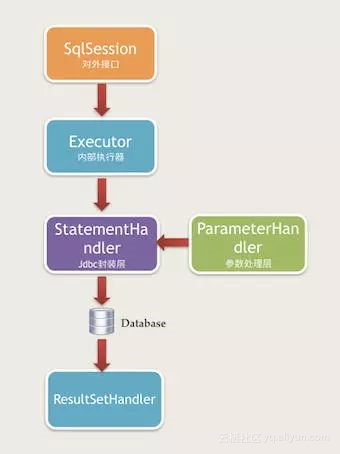
(2)实例化StatementHandler,进行SQL预处理
(3)使用ParameterHandler设置参数
(4)使用StatementHandler执行SQL
对应JDBC代码

十三、执行器类型(面)
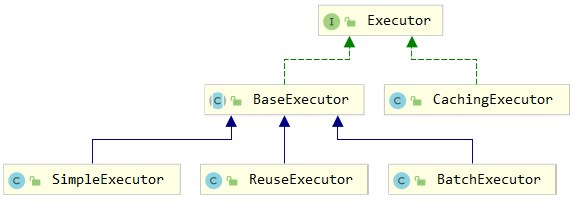
MyBatis的执行器都实现了Executor接口。作用是控制SQL执行的流程。
-
-
SimpleExecutor:默认的执行器类型。每次执行query和update(DML)都会重新创建Statement对象。
-
ReuseExecutor:执行器会重用预处理语句。不会每一次调用都去创建一个新的 Statement 对象,而是会重复利用以前创建好的(如果SQL相同的话)。
-
BatchExecutor:用在update(DML)操作中。所有SQL一次性提交。适用于批量操作。
-
-
也可以在全局配置文件中通过<settings>中defaultExecutorType 进行全局设置(不推荐)。
执行器主要控制的就是Statement对SQL如何进行操作。
有效范围:同一个SqlSession对象
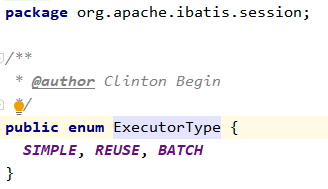

由于底层的批量操作只支持DML操作,所以BatchExecutor也主要用在批量新增、批量删除、批量修改中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号