1、搜索简介
1.1、基础知识
1.1.1、什么是搜索引擎
所谓的 搜索引擎(Search Engine),通常指的是收集了 几千万到几十亿个条数据,为了方便后续精确查询,我们为这些数据的多个词(关键词)进行索引,建立索引数据库的全文搜索引擎。
这样,当用户查找某个关键词的时候,所有在页面内容中包含了该关键词的网页都将作为搜索结果被搜出来。
1.1.2、应用场景
搜索与推荐:
搜索 - 用户在网上,主动根据关键字去搜索相关的数据
推荐 - 网站程序,根据用户日常的搜索习惯,通过分析用户的行为数据,主动推送一些用户感兴趣的事情。 - 提供各种用户感兴趣的网站入口,便于用户快速获取相关信息,一般是爬虫爬取的数据。
定向搜索 - 搜索特定领域的内容,一般是网站自身根据产品设计的样式,结构化存储的数据。 - 根据用户搜索的历史或者关键字,自动弹出或者扩展类似的关键字,提高用户搜索的效率。
普通搜索 - 用户输入数据然后正常的搜索。
相关搜索 - 默认提供的其他关联网站的入口。
1.2、常见方案
1.2.1、Lucene
一个开放源代码的全文检索引擎工具包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。
目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎.
- 本质上,只是一个索引与搜索类库。
- 官网:https://lucene.apache.org/
1.2.2、Solr
一个基于Java5开发的一个高性能的企业级搜索应用服务器。
它在Lucene的基础上进行了扩展,提供了更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。
- Solr是Lucene面向企业搜索应用的搜索平台
- 官网:https://solr.apache.org/
1.2.3、Nutch
一个由Java实现的,开放源代码的web搜索引擎。主要用于收集网页数据,然后对其进行分析,建立索引,以提供相应的接口来对其网页数据进行查询的一套工具。
底层使用了Hadoop来做分布式计算与存储,索引使用了Solr分布式索引框架来做
- 高度可扩展、高度可扩展的网络爬虫工具。
- 官网:https://nutch.apache.org/
1.2.4、ElasticSearch
跟Solr一样,一个建立在全文搜索引擎 Apache Lucene™ 基础上的搜索引擎,它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。
可以用于分布式实时文件存储,实时分析的分布式搜索引擎、处理PB级别的结构化或非结构化数据等。
- Elasticsearch 是一个分布式、RESTful 风格的搜索和数据存储及分析引擎。
- 官网:https://www.elastic.co/cn/elasticsearch/
1.2.5、其它解决方案
Katta
- 基于 Lucene 的,支持分布式,可扩展,具有容错功能,准实时的搜索方案。 /index
- Map/Reduce 模式的,分布式建索引方案,可以跟 Katta 配合使用。 - 基于 Lucene 的一系列经过验证的解决方案,支持分布式,可扩展,丰富的功能实现
- 包括 准实时搜索,facet 搜索实现,机器学习算法,摘要存储库 ,数据库模式包装 等等 - 一个基于 Apache Solr 和 Apache Cassandra 的实时分布式搜索引擎。 - 在hbase存储上封装使用Lucene来创建索引,从而利用HBase的大数据存储以及分布式性能。
2、搜索原理
2.1、搜索结构
2.1.1、结构图
2.1.2、结构说明
搜索引擎基本结构一般包括:搜索器、索引器、检索器、用户接口等四个功能模块。
搜索器:
也叫爬虫,是搜索引擎用来爬行和抓取网页的一个自动程序,在互联网上爬行抓取相关数据页面,为了方便内部的后续操作,将获取的原始内容需要转换为专用部件才能供搜索引擎使用。
- 获取内容(Acquire Content) + 建立文档(Build Document)
- 文档分析(Analyze Document) + 文档索引(Idenx Document) - 搜索接口(Search Interface) + 建立查询(Build Query) - 搜索查询(Run Query) + 展现结果(Render Results)
2.2、内部逻辑
2.2.1、Lucene说明
Lucene是apache软件基金会下的一个开放源代码的全文检索引擎工具包。提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标
系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
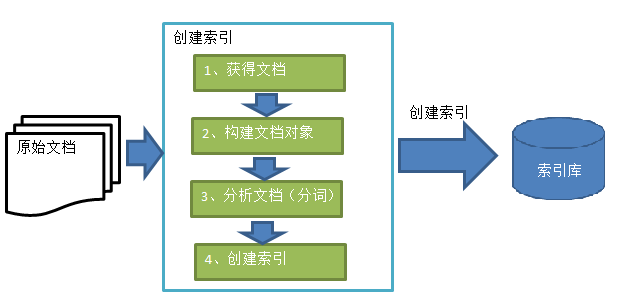
2.2.2、【创建索引】流程图与解析
获取文档
Lucene不提供信息采集的类库,需要自己编写一个爬虫程序实现信息采集,也可以通过一些开源软件实现信息采集
建立文档
在索引前需要将原始内容创建成文档(Document),文档中包括一个一个的域(Field),域中存储内容
分析文档
将原始内容创建为包含域(Field)的文档(document),需要再对域中的内容进行分析,分析的过程是经过对原始文档提取单词、将字母转为小写、去除标点符号、去除停用词等过程生成最终的语汇单元,可以
将语汇单元理解为一个一个的单词。
- 每个单词叫做一个Term,不同的域中拆分出来的相同的单词是不同的term。term中包含两部分一部分是文档的域名,另一部分是单词的内容。
创建索引
对所有文档分析得出的语汇单元进行索引,索引的目的是为了搜索,最终要实现只搜索被索引的语汇单元从而找到Document(文档)
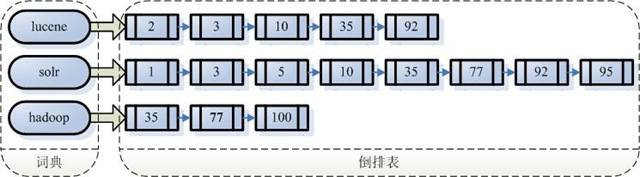
- 创建索引是对语汇单元索引,通过词语找文档id,相较于传统数据的根据id找内容的索引,我们将这种索引的结构叫倒排索引结构
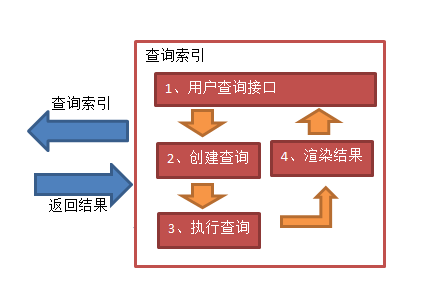
2.2.2、【查询索引】流程图与解析
搜索接口
用户输入关键字我们的存储引擎不支持,所以需要将搜索的信息进行格式化转换成搜索引擎支持的查询对象
Lucene不提供制作用户搜索界面的功能,需要根据自己的需求开发搜索界面。
建立查询
查询对象中可以指定查询要搜索的Field文档域、查询关键字等,查询对象会生成具体的查询语法
搜索查询
根据查询语法在倒排索引词典表中分别找出对应搜索词的索引,从而找到索引所链接的文档链表
展现结果
以一个友好的界面将查询结果展示给用户,用户根据搜索结果找自己想要的信息
2.3、搜索解析
2.3.1、多样化查询
索引存储
Lucene在进行搜索查询的时候,它是通过为搜索到的文档进行计算得分来确定查询结果文档的相似度或者优先级,我们可以基于计算格式的改造,来对查询结果进行自定义的操作。Lucene得分计算公式如下所示:
score(q,d) = coord(q,d)·queryNorm(q)·∑(tf(t in d)·idf(t) ^2·t.getBoost()·norm(t,d))
2.3.2、搜索查询常用的类
Lucene 根据不同的业务场景,实现了多种定制好的模块方法,我们直接使用这些方法,就可以实现各种场景的搜索查询的功能。常见的方法如下:
类 查询特点
TermQuery 指定项查询
RangeQuery 数值范围查询
TermRangeQuery 指定项范围搜索
PrefixQuery 字符串搜索
BooleanQuery 组合查询
PhraseQuery 短语搜索
WildcardQuery 通配符查询
FuzzyQuery 类似项搜索
MatchNoDocsQuery 不匹配文档
QueryParser 解析查询表达式
MultiPhraseQuery 多短语查询
MultiFieldQueryParser 多fileld解析查询
2.4、java代码示例
2.4.1、存储示例
索引信息它是以文档的样式来进行保存的,为了在查询的时候,更方便的查询结果顺序,会对文件的信息进行存储等操作。
// 创建一个索引的语法分析
IndexWriter writer = new IndexWriter(“/data/index/”, new StandardAnalyzer(), true );
// 新建一个索引文档对象
Document doc = new Document();
// 为Document的Field域增加搜索的title属性
doc.add(new Field("title", "搜索的标题", Field.Store.YES, Field.Index.ANALYZED));
// 为Document的Field域增加搜索的content属性
doc.add(new Field("content", "搜索的内容", Field.Store.YES, Field.Index.ANALYZED));
// 索引信息写入到标准的文档里 -- 先写入到一个临时的 segment 里
writer.addDocument(doc);
// 对索引进行优化 -- 将多个segment合并到一个
writer.optimize();
// 关闭索引文件创建
writer.close();
2.4.2、查询示例
// 指定输入项内容进行查询
@Test
public void testTermQuery() throws Exception {
// 指定索引文件
Directory directory = FSDirectory.open(new File("/path/to/index").toPath());
// 读取文件
IndexReader indexReader = DirectoryReader.open(directory);
// 创建索引信息
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
// 创建索引搜索对象 -- 各种查询方法的应用地方
// Term 表示文档的一个词语,是搜索的最小单位,包括两部分:词语及该词语所出现的field。
Query query = new TermQuery(new Term("title", "helloworld"));
// Query query = new WildcardQuery(new Term(“title”, "he"));
// 执行查询
TopDocs topDocs = indexSearcher.search(query, 10);
// 共查询到的document个数
System.out.println("查询结果总数量:" + topDocs.totalHits);
// 遍历查询结果
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
Document document = indexSearcher.doc(scoreDoc.doc);
System.out.println(document.get( "key_name"));
}
// 关闭indexreader
indexSearcher.getIndexReader().close();
}
3、数据流程
3.1、基础知识
3.1.1、生命周期
3.1.2、发展现状
着公司业务的发展,我们所提供的产品规模越来越大,功能越来越多、架构越来越复杂。而到了这个时候,我们往往对产品的交付质量和项目的持续稳定运行的要求越来越高,虽然我们通过各种开发框架、开发模型、
持续交付、DevOps等等,各种方法和手段来提高我们产品的质量,而且可以在一定程度上满足我们的需求。但是我们知道,对于任何一种产品来说,把它制造出来的时间和它运行的时间,这两者相差太多了。可以这么
说,一个产品的效益完全是由后续持续运行的过程中产生的价值来决定的。所以就需要我们有专业的人员对产品的运营阶段进行高质量的运营维护,从而保证产品在后续阶段持续稳定的盈利下去。
那怎么才能高质量的维护呢?简单来说,就是需要我们时刻的掌握到产品的运行过程中所产生的数据,这些数据包括硬件设备、系统性能、软件运行、趋势数据等等,根据我们对产品业务的熟悉程度,设定一定的指标,
当出现某些指标异常的时候,我们就采取一定的手段进行处理,从而保证产品项目软件的持续运营下去。而这个动作就是我们平常所说的 "数据采集与处理"。
3.1.3、采集数据
物理层:文件、设备等
代理层:nginx、haproxy等
web层:nginx、apache、tomcat等
数据库层:mysql、mongodb、redis等
存储层:ceph、k8s、docker等
...
3.2、流程解析
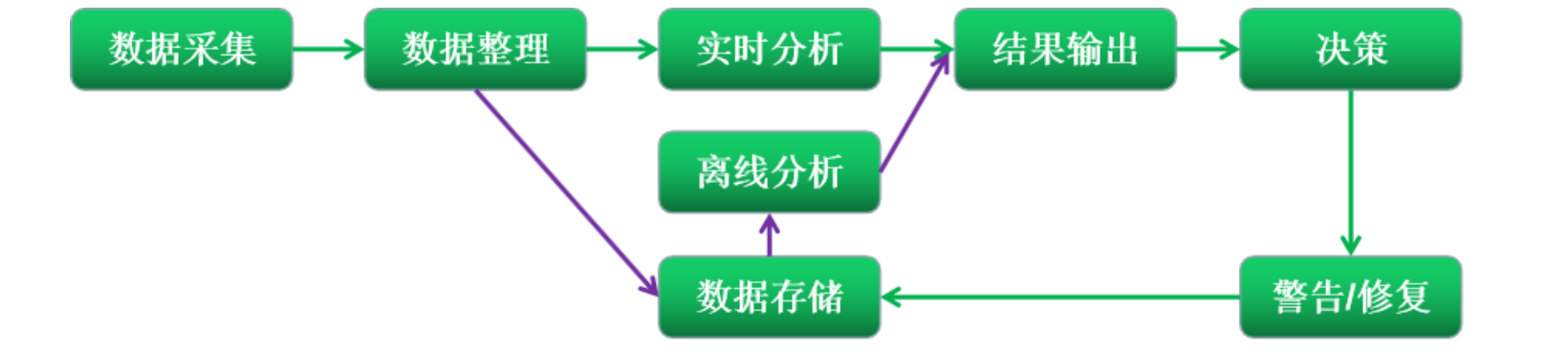
3.2.1、数据流程图
3.2.2、数据流说明
① 数据采集:根据业务的特性,采取多种方式,进行对一些针对性的数据进行采集
② 数据整理:对上报后的数据源进行收集、清洗、整理
③ 实时分析:对某些重要的核心的业务数据,进行实时分析
④ 离线分析:对普通的数据、非紧急的业务数据进行存储,后续进行相应的分析
⑤ 结果输出:将实时分析和离线分析后的数据结果展现出来,供决策参考
⑥ 问题决策:根据当前业务情况,人工或者自动方式对输出的结构进行分析,并判定下一步的行动(警告或修复),
同时将其决策记录保存下来,以便为后序决策提供依据,也就是说:采集、传输、存储、分析、警告这几部分是非常必要的。
3.3、方案梳理
在这个流程图中涉及到两种场景:实时分析与离线分析,如果需要使用市面上的开源解决方案来实现的话,有两套方案比较有优势: + Kafka + 分布式存储
中数据量场景下,实时的数据多一些 + Flume + Kafka + Hadoop(Hive + HBase)
大数据量场景下,离线的数据多一些





【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY