60、Prometheus-alertmanager、邮件告警配置
1、规则解析
1.1、规则简介
Prometheus支持两种类型的规则:记录规则和警报规则,它们可以进行配置,然后定期进行评估。 要将规则包含在Prometheus中,
需要先创建一个包含必要规则语句的文件,并让Prometheus通过Prometheus配置中的rule_fies字段加载该文件。
默认情况下,prometheus的规则文件使用YAML。
规则的使用流程是:首先创建一个满足规则标准的规则语句,然后发送SIGHUP给Prometheus进程,这时候,prometheus在运行时重新加载规则文件,从而让规则在prometheus运行环境中生效。
1.2、记录规则基础

记录规则的作用其实将我们之前的监控命令采用配置文件的方式进行编写,从而大大减轻我们的工作量。
最常用的场景就是,我们将预先计算经常需要或计算量大的复杂的PromQL语句指定为一个独立的metric监控项,这样我们在查询的时候就非常方便,
而且查询预计算结果通常比每次需要原始表达式都要快得多,尤其是对于仪表板特别有用,仪表板每次刷新时都需要重复查询相同的表达式。
总体来说,记录规则效果与我们编写shell脚本时候的变量名称一样。
规则文件的语法为: groups: [ - <rule_group> ]
1.2.1、规则文件样式
groups: - name: example interval: 10s rules: - record: job:http_inprogress_requests:sum expr: sum(http_inprogress_requests) by (job) labels: [ <labelname>: <labelvalue> ]
1.2.2、规则文件属性解析
name 规则组名,必须是唯一的 interval 定制规则执行的间隔时间 rules 设定规则具体信息 record 定制指标的名称 expr 执行成功的PromQL labels 为该规则设定标签
2、记录规则-实践
2.1、需求
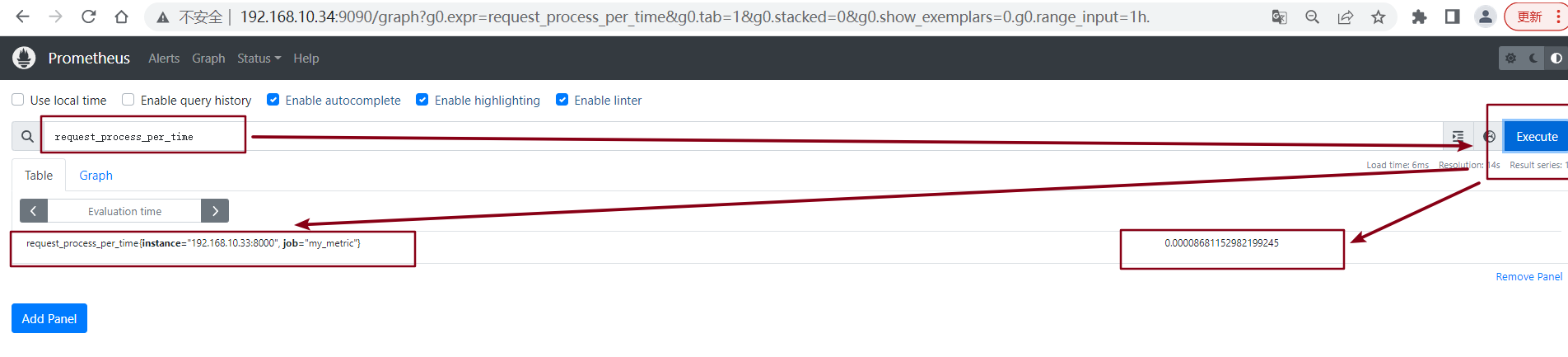
在Prometheus查询部分指标时需要通过将现有的规则组合成一个复杂的表达式,才能查询到对应的指标结果,比如在查询"自定义的指标请求处理时间"参考如下
request_processing_seconds_sum{instance="192.168.10.33:8000",job="my_metric"} / request_processing_seconds_count{instance="192.168.10.33:8000",job="my_metric"}
这个查询语句,写起来非常长,在我们graph绘图的时候,每次输入命令都是非常繁琐的,一长就容易出现问题。
2.2、配置记录规则
2.2.1、创建规则目录
mkdir /data/server/prometheus/rules && cd /data/server/prometheus/rules
2.2.2、编写rules记录规则文件
cat > metrics_request_rules.yaml<<'EOF' groups: - name: myrules rules: - record: request_process_per_time expr: request_processing_seconds_sum{instance="192.168.10.33:8000",job="my_metric"} / request_processing_seconds_count{instance="192.168.10.33:8000",job="my_metric"} EOF
2.2.3、检查语法是否正常
prometheus-server ~]# promtool check rules /data/server/prometheus/rules/metrics_request_rules.yaml Checking /data/server/prometheus/rules/metrics_request_rules.yaml SUCCESS: 1 rules found
2.2.4、prometheus.yml增加【记录规则文件】配置
]# vi /data/server/prometheus/etc/prometheus.yml ... rule_files: - "../rules/metrics_request_rules.yaml" ...
2.2.5、检查prometheus.yml语法是否正常
prometheus-server ~]# promtool check config /data/server/prometheus/etc/prometheus.yml Checking /data/server/prometheus/etc/prometheus.yml SUCCESS: 1 rule files found SUCCESS: /data/server/prometheus/etc/prometheus.yml is valid prometheus config file syntax Checking /data/server/prometheus/rules/metrics_request_rules.yaml SUCCESS: 1 rules found
2.2.6、重启prometheus服务
systemctl restart prometheus
2.2.7、到prometheus web页面查询rules

2.2.8、使用rules name查询数据
说明已经支持rule name查询
2.3、总结
规则解析 - 规则分类:记录规则、告警规则。 - 规则作用:提高PromQL查询效率。 规则实践 - 编写规则文件,检查规范,加载配置,测试效果。
3、告警环境部署
3.1、需求定位
3.1.1、工具简介
Prometheus作为一个大数据量场景下的监控平台来说,数据收集是核心功能,虽然监控数据可视化了,也非常容易观察到运行状态。
但是最能产生价值的地方就是对数据分析后的告警处理措施,因为我们很难做到时刻盯着监控并及时做出正确的决策,所以程序来帮巡检并自动告警,是保障业务稳定性的决定性措施。可以说任
何一个监控平台如果没有告警平台,那么他就逊色不少甚至都不能称之为平台。
对于Prometheus平台来说,它就集成了报警功能,该功能主要是利用Alertmanager这个组件来实现功能的。Alertmanager作为一个独立的组件,负责接收并处理来自Prometheus Server(也可以是其它的客户
端程序)的告警信息。Alertmanager可以对这些告警信息进行进一步的处理,比如当接收到大量重复告警时能够消除重复的告警信息,同时对告警信息进行分组并且路由到正确的通知方,Prometheus内置了对邮件,
Slack等多种通知方式的支持,同时还支持与Webhook的集成,以支持更多定制化的场景。
3.1.2、组件解析

3.2、告警特征

3.2.1、分组
分组机制可以将详细的告警信息合并成一个通知。在某些情况下,比如由于系统宕机导致大量的告警被同时触发,在这种情况下分组机制可以将这些被触发的告警合并为一个告警通知,避免一次性接受大量的告警通知,
而无法对问题进行快速定位。
告警分组,告警时间,以及告警的接受方式可以通过Alertmanager的配置文件进行配置。
3.2.2、抑制
抑制是指当某一告警发出后,可以停止重复发送由此告警引发的其它告警的机制。抑制机制同样通过Alertmanager的配置文件进行设置。
3.2.3、静默
静默提供了一个简单的机制可以快速根据标签对告警进行静默处理。如果接收到的告警符合静默的配置,Alertmanager则不会发送告警通知。静默设置需要在Alertmanager的Web页面上进行设置。
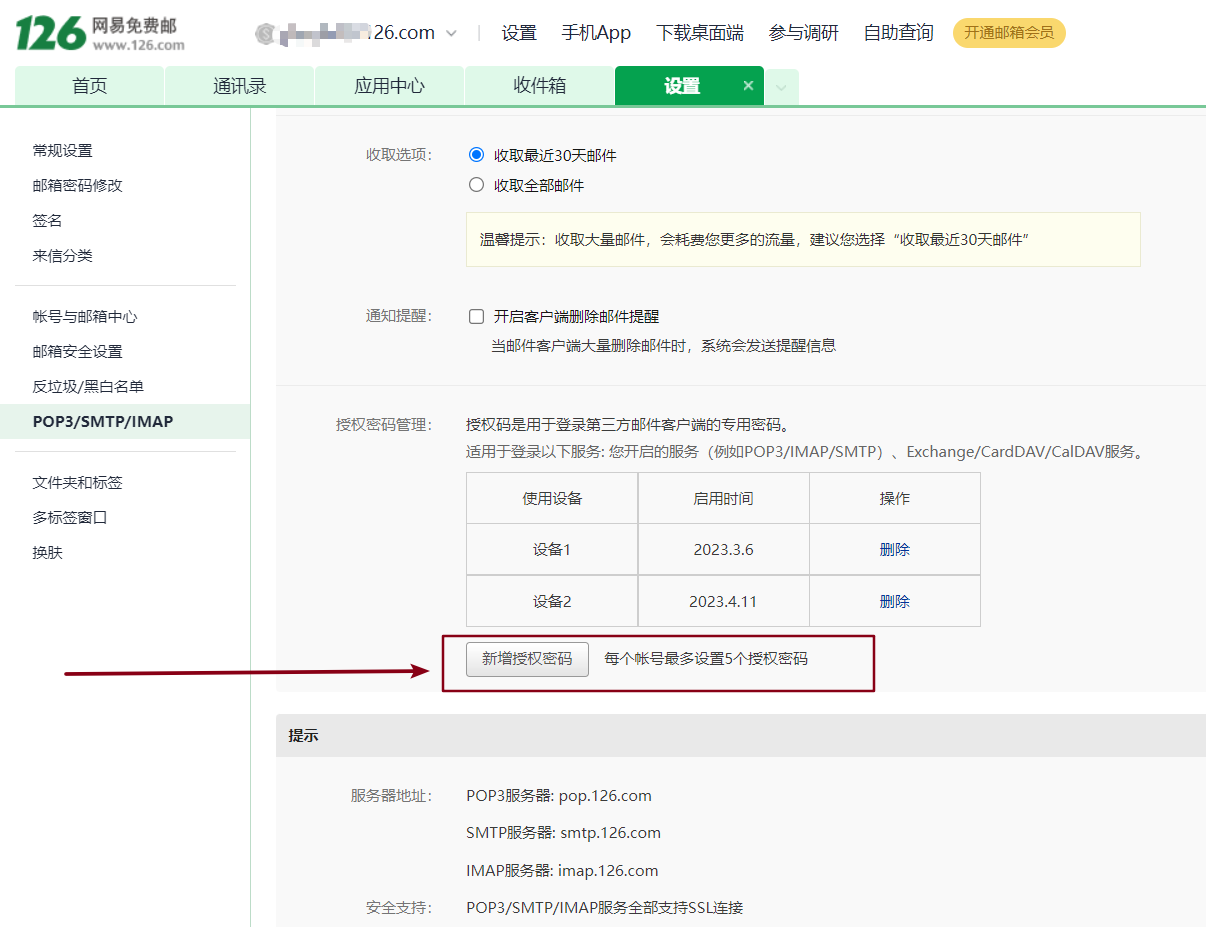
3.3、准备配置告警邮件的密码
3.4、部署alertmanager
3.4.1、软件下载
3.4.2、解压软件
tar xvf alertmanager-0.25.0.linux-amd64.tar.gz -C /data/server/ ln -s /data/server/alertmanager-0.25.0.linux-amd64 /data/server/alertmanager
3.4.3、配置准备工作
cd /data/server/alertmanager && mkdir {bin,etc,data} mv alertmanager bin/ mv alertmanager.yml etc/
mv amtool bin/
3.4.4.配置环境变量
cat >/etc/profile.d/alertmanager.sh<<'EOF' #!/bin/bash export ALERTMANAGER_HOME=/data/server/alertmanager export PATH=$PATH:$ALERTMANAGER_HOME/bin EOF source /etc/profile.d/alertmanager.sh
3.4.5、配置alertmanager.yml
]# vi /data/server/alertmanager/etc/alertmanager.yml # 全局配置【配置告警邮件地址】 global: resolve_timeout: 5m smtp_smarthost: 'smtp.126.com:25' smtp_from: 'pyygbh@126.com' smtp_auth_username: 'pyygbh@126.com' smtp_auth_password: 'BXDVLEAJEHMFQKTF' smtp_hello: '126.com' smtp_require_tls: false # 路由配置 route: group_by: ['alertname', 'cluster'] group_wait: 10s group_interval: 10s repeat_interval: 10s receiver: 'email' # 收信人员 receivers: - name: 'email' email_configs: - to: '277667028@qq.com' send_resolved: true # 规则主动失效措施,如果不想用的话可以取消掉 inhibit_rules: - source_match: severity: 'critical' target_match: severity: 'warning' equal: ['alertname', 'dev', 'instance']
# 属性解析: repeat_inerval配置项,用于降低告警收敛,减少报警,发送关键报警,对于email来说,此项不可以设置过低,否则将会由于邮件发送太多频繁,被smtp服务器拒绝
3.4.6、设置systemd
cat > /usr/lib/systemd/system/alertmanager.service <<'EOF' [Unit] Description=alertmanager project After=network.target [Service] Type=simple ExecStart=/data/server/alertmanager/bin/alertmanager --config.file=/data/server/alertmanager/etc/alertmanager.yml --storage.path=/data/server/alertmanager/data --web.listen-address=0.0.0.0:9093 Restart=on-failure [Install] WantedBy=multi-user.target EOF
# 属性解析:web.listen-address是与prometheus交互的端口
3.4.7、启动服务
systemctl daemon-reload systemctl start alertmanager systemctl enable alertmanager ]# netstat -tunlp | grep alert tcp6 0 0 :::9093 :::* LISTEN 25713/alertmanager # 与prometheus交互端口 tcp6 0 0 :::9094 :::* LISTEN 25713/alertmanager udp6 0 0 :::9094 :::* 25713/alertmanager
3.4.8、访问alertmanager的WEB页面
http://192.168.10.34:9093/

3.5、将alertmanager增加到prometheus
3.5.1、配置prometheus.yml
]# vi /data/server/prometheus/etc/prometheus.yml ... # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: - 192.168.10.34:9093 ...
3.5.2、检查语法是否正常
]# promtool check config /data/server/prometheus/etc/prometheus.yml Checking /data/server/prometheus/etc/prometheus.yml SUCCESS: 1 rule files found SUCCESS: /data/server/prometheus/etc/prometheus.yml is valid prometheus config file syntax Checking /data/server/prometheus/rules/metrics_request_rules.yaml SUCCESS: 1 rules found
3.5.3、重启prometheus服务
systemctl restart prometheus
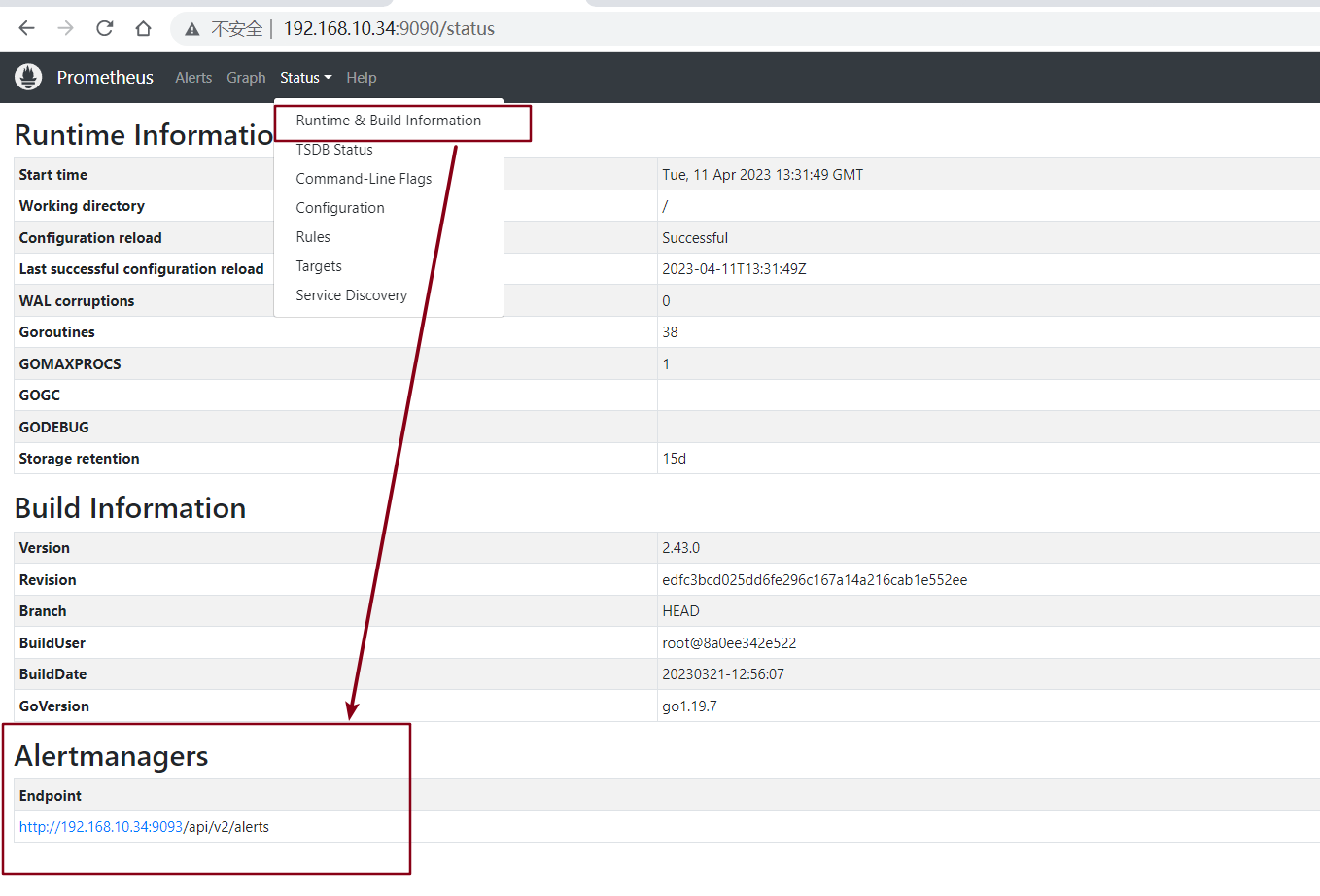
3.5.4、访问prometheus web页面
检查alertmanager是否注册成功
4、告警配置
4.1、告警规则
4.1.1、功能简介
警报规则使您可以基于Prometheus表达式语言表达式定义警报条件,并将有关触发警报的通知发送到外部服务。 只要警报表达式在给定的时间点生成一个或多个动作元素,警报就被视为这些元素的标签集处于活动状态。
警报规则在Prometheus中的基本配置方式与记录规则基本一致。
4.1.2、规则文件-示例
groups: - name: example rules: - alert: HighRequestLatency expr: job:request_latency_seconds:mean5m{job="myjob"} > 0.5 for: 10m labels: severity: page annotations: summary: "Instance {{ $labels.instance }} down" description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes." 属性解析: alert 定制告警的动作名称 for expr动作触发后,持续的时间,达到该条件就会告警 labels.severity 定义告警级别 annotations 自定义注释信息,注释信息中的变量需要从模板中或者系统中读取
4.2、告警规则的组成
在Prometheus中,还可以通过Group(告警组)对一组相关的告警进行统一定义。当然这些定义都是通过YAML文件来统一管理的。
4.2.1、告警名称
用户需要为告警规则命名,当然对于命名而言,需要能够直接表达出该告警的主要内容
4.2.2、告警规则
告警规则实际上主要由PromQL进行定义,其实际意义是当表达式(PromQL)查询结果持续多长时间(During)后出发告警
4.3、告警规则配置
4.3.1、需求
我们编写一个检查自定义metrics的接口的告警规则,在prometheus中我们可以借助于up指标来获取对应的状态效果,查询语句如下: up{instance="192.168.10.33:8000",job="my_metric"}
注意:如果结果是1表示服务正常,否则表示该接口的服务出现了问题。
4.3.2、编写规则配置文件
]# cat /data/server/prometheus/rules/metrics_request_rules.yaml groups: - name: myrules rules: - record: request_process_per_time expr: request_processing_seconds_sum{instance="192.168.10.33:8000",job="my_metric"} / request_processing_seconds_count{instance="192.168.10.33:8000",job="my_metric"} - name: flask_web rules: - alert: InstanceDown expr: up{instance="192.168.10.33:8000",job="my_metric"} == 0 for: 1m labels: severity: 1 annotations: summary: "Instance {{ $labels.instance }} 停止工作" description: "{{ $labels.instance }} job {{ $labels.job }} 已经停止1分钟以上" 属性解析: {{ $labels.<labelname> }} 要插入触发元素的标签值 {{ $value }} 要插入触发元素的数值表达式值这里的$name 都是来源于模板文件中的定制内容,如果不需要定制的变动信息,可以直接写普通的字符串
4.3.3、rules语法检查
]# promtool check rules /data/server/prometheus/rules/metrics_request_rules.yaml Checking /data/server/prometheus/rules/metrics_request_rules.yaml SUCCESS: 2 rules found
4.3.4、重启prometheus服务
systemctl restart prometheus
4.3.5、访问prometheus Web 查看rules的页面

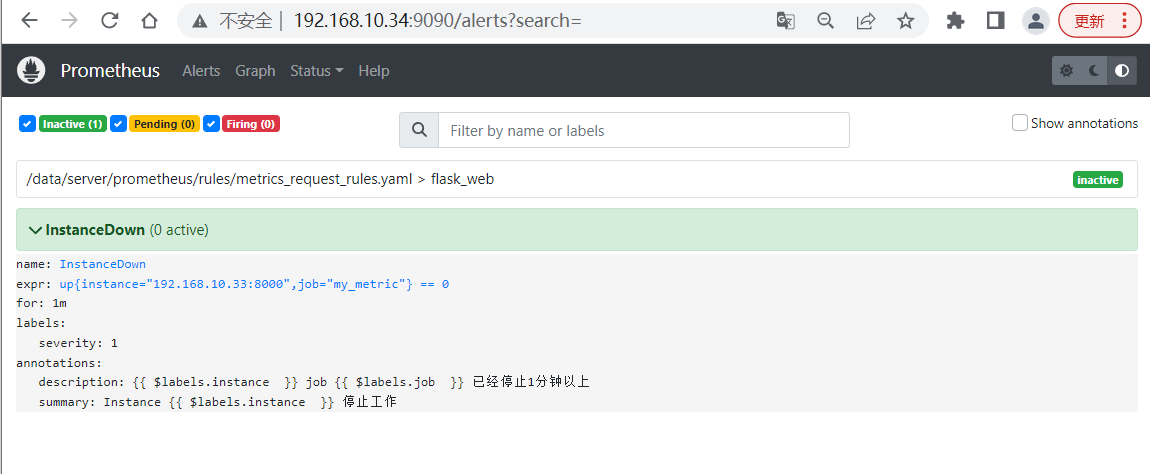
4.3.6、访问prometheus Web 查看alerts的页面
Inactive 正常效果。
Pending 已触发阈值,但未满足告警持续时间(即rule中的for字段)
Firing 已触发阈值且满足告警持续时间。
4.4、模拟触发告警
4.4.1、停止flask服务
]# ps -ef | grep python root 121999 75138 0 15:05 pts/1 00:03:03 python3 /opt/my_metrics/my_metric.py ]# kill -9 121999
4.4.2、此时是pending状态,还没有达到发送告警
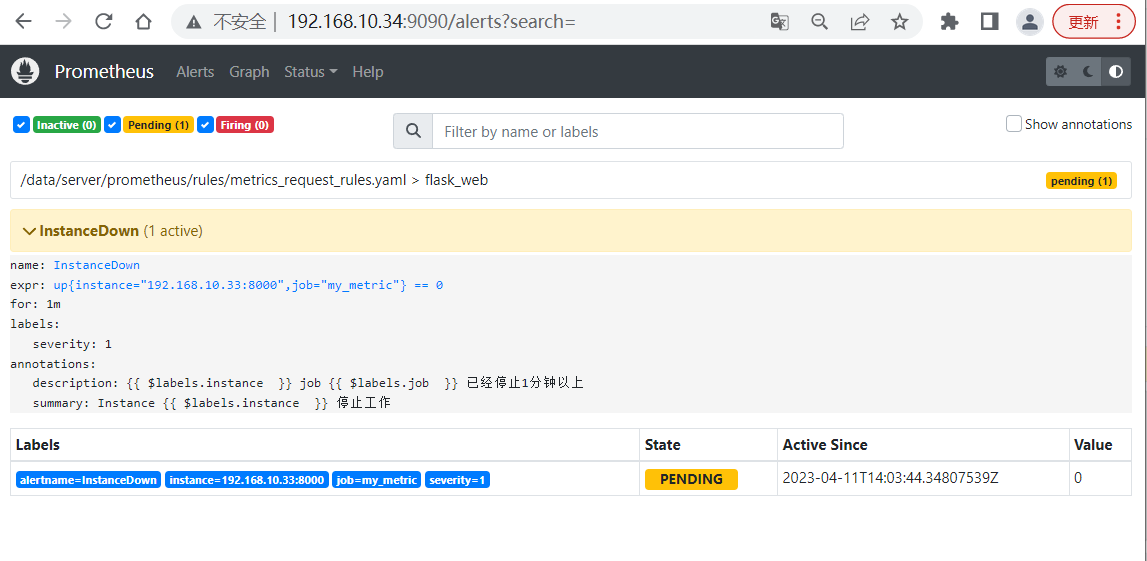
4.4.3、InstanceDown状态,已经发出告警

4.4.4、此时邮箱已经收到邮件

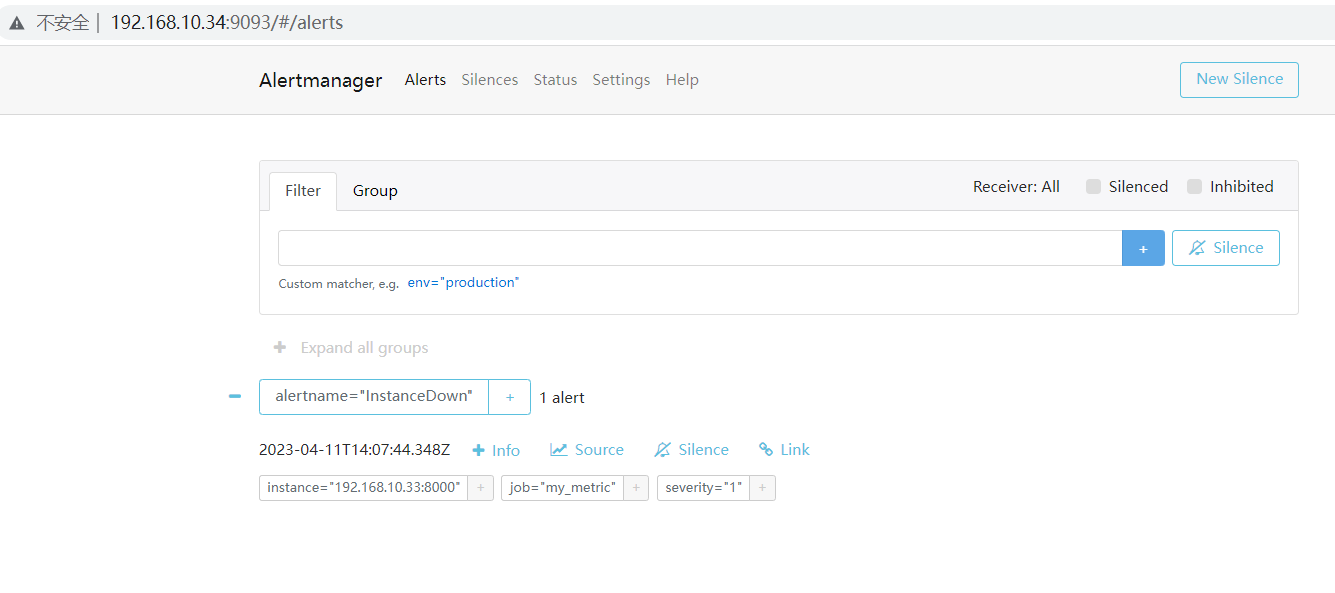
4.4.5、查询alertmanager状态
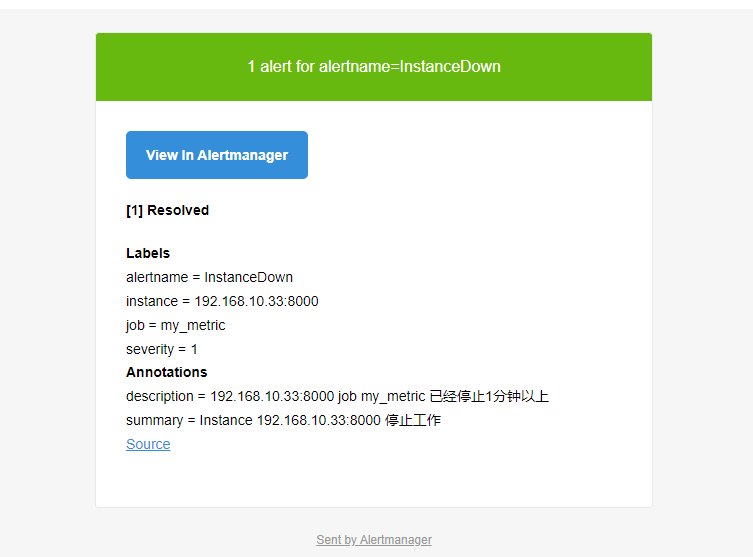
4.4.6、服务恢复也会收到邮件
4.5、总结
告警规则 - 基本规则与记录规则类型 - 特有属性:alert、expr、for、label、annotations 简单实践 - 规则定义、效果演示
5、告警模板配置
5.1、需求分析
5.1.1、案例需求
默认的告警信息有些太简单,我们可以借助于告警的模板信息,对告警的信息进行丰富增加。我们需要借助于alertmanager的模板功能来实现。
5.1.2、使用流程
1、分析关键信息
2、定制模板内容
3、prometheus加载模板文件
4、告警信息使用模板内容属性
5.2、定制邮件模板
5.2.1、编写邮件模板
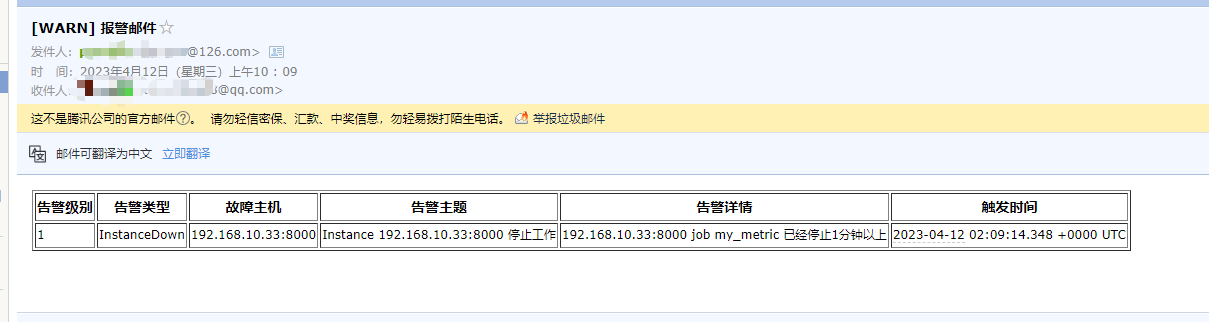
mkdir /data/server/alertmanager/email_template && cd /data/server/alertmanager/email_template cat >email.tmpl<<'EOF' {{ define "test.html" }} <table border="1"> <thead> <th>告警级别</th> <th>告警类型</th> <th>故障主机</th> <th>告警主题</th> <th>告警详情</th> <th>触发时间</th> </thead> <tbody> {{ range $i, $alert := .Alerts }} <tr> <td>{{ index $alert.Labels.severity }}</td> <td>{{ index $alert.Labels.alertname }}</td> <td>{{ index $alert.Labels.instance }}</td> <td>{{ index $alert.Annotations.summary }}</td> <td>{{ index $alert.Annotations.description }}</td> <td>{{ $alert.StartsAt }}</td> </tr> {{ end }} </tbody> </table> {{ end }} EOF 属性解析: {{ define "test.html" }} 表示定义了一个 test.html 模板文件,通过该名称在配置文件中应用。 此模板文件就是使用了大量的ajax模板语言。 $alert.xxx 其实是从默认的告警信息中提取出来的重要信息。
5.2.2、修改alertmanager.yml【即应用邮件模板】
]# vi /data/server/alertmanager/etc/alertmanager.yml # 全局配置【配置告警邮件地址】 global: resolve_timeout: 5m smtp_smarthost: 'smtp.126.com:25' smtp_from: '**ygbh@126.com' smtp_auth_username: 'pyygbh@126.com' smtp_auth_password: 'BXDVLEAJEH******' smtp_hello: '126.com' smtp_require_tls: false # 模板配置 templates: - '../email_template/*.tmpl' # 路由配置 route: group_by: ['alertname', 'cluster'] group_wait: 10s group_interval: 10s repeat_interval: 120s receiver: 'email' # 收信人员 receivers: - name: 'email' email_configs: - to: '277667028@qq.com' send_resolved: true html: '{{ template "test.html" . }}' headers: { Subject: "[WARN] 报警邮件" } # 规则主动失效措施,如果不想用的话可以取消掉 inhibit_rules: - source_match: severity: 'critical' target_match: severity: 'warning' equal: ['alertname', 'dev', 'instance'] 属性解析: {{}} 属性用于加载其它信息,所以应该使用单引号括住 {} 不需要使用单引号,否则服务启动不成功
5.2.3、检查语法是否正常
]# amtool check-config /data/server/alertmanager/etc/alertmanager.yml Checking '/data/server/alertmanager/etc/alertmanager.yml' SUCCESS Found: - global config - route - 1 inhibit rules - 1 receivers - 1 templates SUCCESS
5.2.4、重启alertmanager服务
systemctl restart alertmanager
5.2.5、重启prometheus服务
systemctl restart prometheus
5.4、关闭flask服务测试告警模板
5.4.1、关闭flask
直接kill -9 pid即可
5.4.2、邮件告警效果
5.5、总结
需求分析 - 定制自己的模板格式 - 基本流程:场景分析-模板内容-加载配置-告警规则 配置改造 - 定制模板、修改alertmanager、修改rules


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏
· Manus爆火,是硬核还是营销?