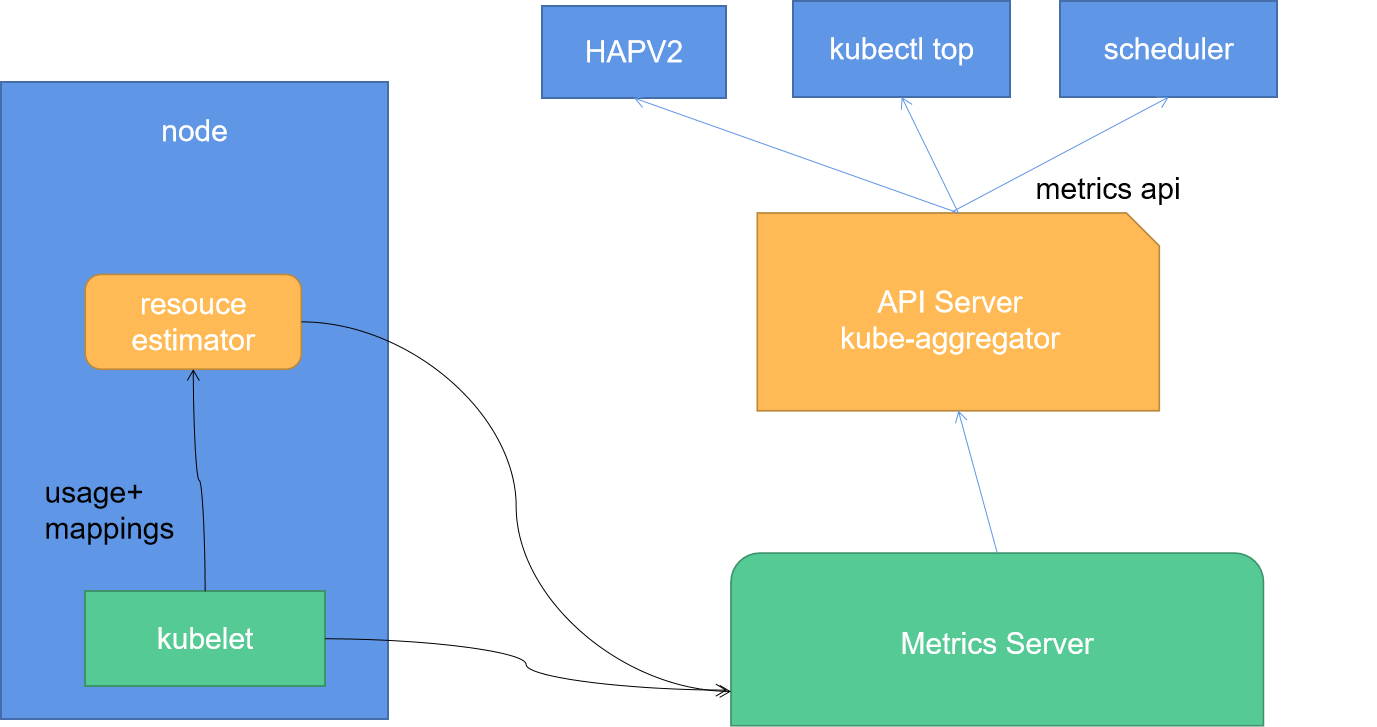
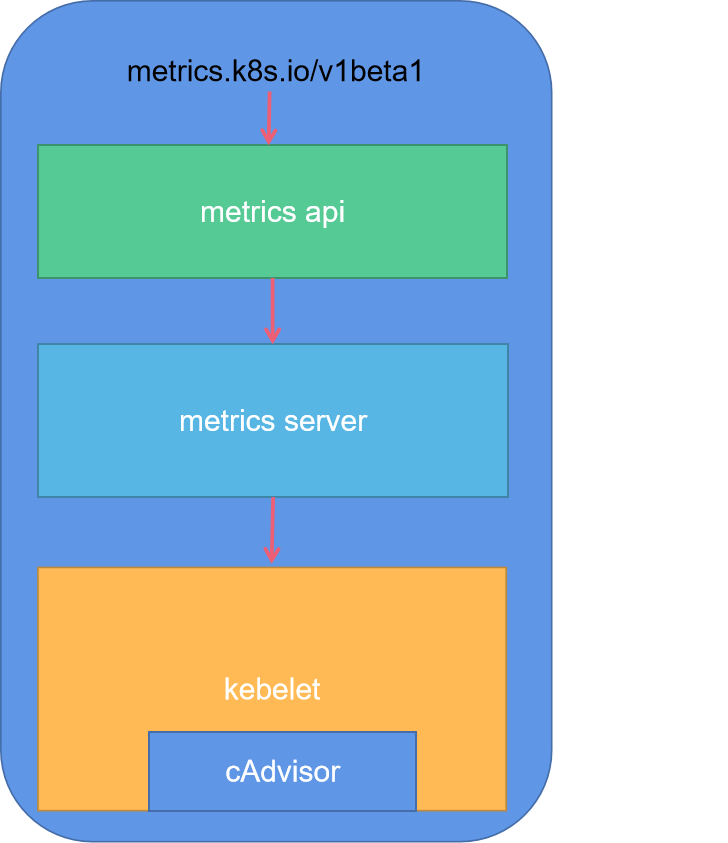
在k8s的系统上包含了各种各样的指标数据,早期的k8s系统,为kubelet集成了一个CAdvsior工具可以获取kubelet所在节点上的相关指标,包括容器指标。但是CAdvsior的缺陷在于,我们仅能够获取,指定
节点上的指标信息,而无法获取集群管理的统一指标。
比如,在k8s集群中,提供了一些监控用的命令,比如top,通过它可以汇总节点上的相关统计信息。由于没有默认情况下,k8s没有提供专用的metrics接口,所以这个命令无法正常使用。
~]# kubectl top node
error: Metrics API not available
虽然k8s已经内嵌了CAdvsior,但是没有集群级别的资源对象能够汇总这些所有的指标数据,并通过相关资源对象的api接口暴露出去。
kubectl api-resources | grep metrics
]# kubectl apply -f components.yaml
serviceaccount/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
service/metrics-server created
deployment.apps/metrics-server created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
1、报错信息
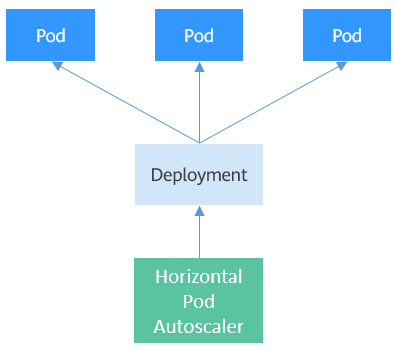
]# kubectl describe hpa scalar
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedGetResourceMetric 12s (x2 over 27s) horizontal-pod-autoscaler failed to get cpu utilization: unable to get metrics for resource
cpu: unable to fetch metrics from resource metrics API: the server could not find the requested resource (get pods.metrics.k8s.io)
Warning FailedComputeMetricsReplicas 12s (x2 over 27s) horizontal-pod-autoscaler invalid metrics (1 invalid out of 1), first error is: failed to get cpu
resource metric value: failed to get cpu utilization: unable to get metrics for resource cpu: unable to fetch metrics from resource metrics API: the server could not find the requested resource (get pods.metrics.k8s.io)
2、报错信息,TARGETS显示unknown
]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
deployment-hpa Deployment/deployment-hpa <unknown>/50% 1101 106m
以上原因:没有安装metrics-server导致的。
]# kubectl get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
deployment-hpa 1/111 114m
]# kubectl get pods
NAME READY STATUS RESTARTS AGE
deployment-hpa-88878d778-d8hn9 1/1 Running 0 114m



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· AI与.NET技术实操系列(六):基于图像分类模型对图像进行分类