Python之re模块的使用
re模块的作用
正则表达式是用一种形式化语法描述的文本匹配模式。模式会被解释为一组指令,然后执行这些指今并提供一个字符串作为输入,
将生成一个匹配子集或者生成原字符串的一个修改版本。
1、查找文本中的模式,re.search()


import re pattern = 'this' text = 'Does this text match the pattern?' match = re.search(pattern, text) s = match.start() e = match.end() print('Found "{}"\nin "{}"\nfrom {} to {} ("{}")'.format( match.re.pattern, match.string, s, e, text[s:e]))
运行效果
Found "this" in "Does this text match the pattern?" from 5 to 9 ("this")
2、编译表达式匹配模式,re.search()
import re # Precompile the patterns regexes = [ re.compile(p) for p in ['this', 'that'] ] text = 'Does this text match the pattern?' print('Text: {!r}\n'.format(text)) for regex in regexes: print('Seeking "{}" ->'.format(regex.pattern), end=' ') if regex.search(text): print('match!') else: print('no match')
运行效果
Text: 'Does this text match the pattern?' Seeking "this" -> match! Seeking "that" -> no match
3、多重匹配模式,re.findall()
import re text = 'abbaaabbbbaaaaa' pattern = 'ab' for match in re.findall(pattern, text): print('Found {!r}'.format(match))
运行效果
['ab', 'ab'] Found 'ab' Found 'ab'
4、多重匹配模式,返回迭代器,re.finditer()
import re text = 'abbaaabbbbaaaaa' pattern = 'ab' for match in re.finditer(pattern, text): s = match.start() e = match.end() print('Found {!r} at {:d}:{:d}'.format( text[s:e], s, e))
运行效果
Found 'ab' at 0:2 Found 'ab' at 5:7
5、定制一个匹配的函数,将匹配不到的用点号替换
import re def test_patterns(text, patterns): """给源文本和模式列表,查找文本中每个模式的匹配,并将它们打印到stdout""" # 查找文本中的每个模式并打印结果 for pattern, desc in patterns: print("'{}' ({})\n".format(pattern, desc)) print(" '{}'".format(text)) for match in re.finditer(pattern, text): s = match.start() e = match.end() substr = text[s:e] n_backslashes = text[:s].count('\\') prefix = '.' * (s + n_backslashes) print(" {}'{}'".format(prefix, substr)) print() return if __name__ == '__main__': test_patterns('abbaaabbbbaaaaa', [('ab', "'a' followed by 'b'"), ])
运行效果
'ab' ('a' followed by 'b') 'abbaaabbbbaaaaa' 'ab' .....'ab'
6、重复匹配
import re def test_patterns(text, patterns): """给源文本和模式列表,查找文本中每个模式的匹配,并将它们打印到stdout""" # 查找文本中的每个模式并打印结果 for pattern, desc in patterns: print("'{}' ({})\n".format(pattern, desc)) print(" '{}'".format(text)) for match in re.finditer(pattern, text): s = match.start() e = match.end() substr = text[s:e] n_backslashes = text[:s].count('\\') prefix = '.' * (s + n_backslashes) print(" {}'{}'".format(prefix, substr)) print() return test_patterns( 'abbaabbba', [('ab*', 'a followed by zero or more b'), ('ab+', 'a followed by one or more b'), ('ab?', 'a followed by zero or one b'), ('ab{3}', 'a followed by three b'), ('ab{2,3}', 'a followed by two to three b')], )
运行效果
'ab*' (a followed by zero or more b) 'abbaabbba' 'abb' ...'a' ....'abbb' ........'a' 'ab+' (a followed by one or more b) 'abbaabbba' 'abb' ....'abbb' 'ab?' (a followed by zero or one b) 'abbaabbba' 'ab' ...'a' ....'ab' ........'a' 'ab{3}' (a followed by three b) 'abbaabbba' ....'abbb' 'ab{2,3}' (a followed by two to three b) 'abbaabbba' 'abb' ....'abbb' #总结 * : 0次或多次 + : 1次或多次 ? : 0次或1次 {n} : 最大N次 {n:m}:最大M次和最小N次
7、关闭贪婪匹配
import re def test_patterns(text, patterns): """给源文本和模式列表,查找文本中每个模式的匹配,并将它们打印到stdout""" # 查找文本中的每个模式并打印结果 for pattern, desc in patterns: print("'{}' ({})\n".format(pattern, desc)) print(" '{}'".format(text)) for match in re.finditer(pattern, text): s = match.start() e = match.end() substr = text[s:e] n_backslashes = text[:s].count('\\') prefix = '.' * (s + n_backslashes) print(" {}'{}'".format(prefix, substr)) print() return test_patterns( 'abbaabbba', [('ab*?', 'a followed by zero or more b'), ('ab+?', 'a followed by one or more b'), ('ab??', 'a followed by zero or one b'), ('ab{3}?', 'a followed by three b'), ('ab{2,3}?', 'a followed by two to three b')], )
运行效果
'ab*?' (a followed by zero or more b) 'abbaabbba' 'a' ...'a' ....'a' ........'a' 'ab+?' (a followed by one or more b) 'abbaabbba' 'ab' ....'ab' 'ab??' (a followed by zero or one b) 'abbaabbba' 'a' ...'a' ....'a' ........'a' 'ab{3}?' (a followed by three b) 'abbaabbba' ....'abbb' 'ab{2,3}?' (a followed by two to three b) 'abbaabbba' 'abb' ....'abb'
8、字符集合的匹配
import re def test_patterns(text, patterns): """给源文本和模式列表,查找文本中每个模式的匹配,并将它们打印到stdout""" # 查找文本中的每个模式并打印结果 for pattern, desc in patterns: print("'{}' ({})\n".format(pattern, desc)) print(" '{}'".format(text)) for match in re.finditer(pattern, text): s = match.start() e = match.end() substr = text[s:e] n_backslashes = text[:s].count('\\') prefix = '.' * (s + n_backslashes) print(" {}'{}'".format(prefix, substr)) print() return test_patterns( 'abbaabbba', [('[ab]', 'either a or b'), ('a[ab]+', 'a followed by 1 or more a or b'), ('a[ab]+?', 'a followed by 1 or more a or b, not greedy')], )
运行效果
'[ab]' (either a or b) 'abbaabbba' 'a' .'b' ..'b' ...'a' ....'a' .....'b' ......'b' .......'b' ........'a' 'a[ab]+' (a followed by 1 or more a or b) 'abbaabbba' 'abbaabbba' 'a[ab]+?' (a followed by 1 or more a or b, not greedy) 'abbaabbba' 'ab' ...'aa'
9、排除字符集的匹配
import re def test_patterns(text, patterns): """给源文本和模式列表,查找文本中每个模式的匹配,并将它们打印到stdout""" # 查找文本中的每个模式并打印结果 for pattern, desc in patterns: print("'{}' ({})\n".format(pattern, desc)) print(" '{}'".format(text)) for match in re.finditer(pattern, text): s = match.start() e = match.end() substr = text[s:e] n_backslashes = text[:s].count('\\') prefix = '.' * (s + n_backslashes) print(" {}'{}'".format(prefix, substr)) print() return test_patterns( 'This is some text -- with punctuation.', [('[^-. ]+', 'sequences without -, ., or space')], )
运行效果
'[^-. ]+' (sequences without -, ., or space) 'This is some text -- with punctuation.' 'This' .....'is' ........'some' .............'text' .....................'with' ..........................'punctuation'
10、字符区间定义一个字符集范围匹配
import re def test_patterns(text, patterns): """给源文本和模式列表,查找文本中每个模式的匹配,并将它们打印到stdout""" # 查找文本中的每个模式并打印结果 for pattern, desc in patterns: print("'{}' ({})\n".format(pattern, desc)) print(" '{}'".format(text)) for match in re.finditer(pattern, text): s = match.start() e = match.end() substr = text[s:e] n_backslashes = text[:s].count('\\') prefix = '.' * (s + n_backslashes) print(" {}'{}'".format(prefix, substr)) print() return test_patterns( 'This is some text -- with punctuation.', [('[a-z]+', 'sequences of lowercase letters'), ('[A-Z]+', 'sequences of uppercase letters'), ('[a-zA-Z]+', 'sequences of letters of either case'), ('[A-Z][a-z]+', 'one uppercase followed by lowercase')], )
运行效果
'[a-z]+' (sequences of lowercase letters) 'This is some text -- with punctuation.' .'his' .....'is' ........'some' .............'text' .....................'with' ..........................'punctuation' '[A-Z]+' (sequences of uppercase letters) 'This is some text -- with punctuation.' 'T' '[a-zA-Z]+' (sequences of letters of either case) 'This is some text -- with punctuation.' 'This' .....'is' ........'some' .............'text' .....................'with' ..........................'punctuation' '[A-Z][a-z]+' (one uppercase followed by lowercase) 'This is some text -- with punctuation.' 'This'
11、指定占位符匹配
import re def test_patterns(text, patterns): """给源文本和模式列表,查找文本中每个模式的匹配,并将它们打印到stdout""" # 查找文本中的每个模式并打印结果 for pattern, desc in patterns: print("'{}' ({})\n".format(pattern, desc)) print(" '{}'".format(text)) for match in re.finditer(pattern, text): s = match.start() e = match.end() substr = text[s:e] n_backslashes = text[:s].count('\\') prefix = '.' * (s + n_backslashes) print(" {}'{}'".format(prefix, substr)) print() return test_patterns( 'abbaabbba', [('a.', 'a followed by any one character'), ('b.', 'b followed by any one character'), ('a.*b', 'a followed by anything, ending in b'), ('a.*?b', 'a followed by anything, ending in b')], )
运行效果
'a.' (a followed by any one character) 'abbaabbba' 'ab' ...'aa' 'b.' (b followed by any one character) 'abbaabbba' .'bb' .....'bb' .......'ba' 'a.*b' (a followed by anything, ending in b) 'abbaabbba' 'abbaabbb' 'a.*?b' (a followed by anything, ending in b) 'abbaabbba' 'ab' ...'aab'
12、转义码
| Code | Meaning |
|---|---|
\d |
数字 |
\D |
非数字 |
\s |
空白字符(制表符、空格、换行等) |
\S |
非空白字符 |
\w |
字母数字 |
\W |
非字母数字 |
import re def test_patterns(text, patterns): """给源文本和模式列表,查找文本中每个模式的匹配,并将它们打印到stdout""" # 查找文本中的每个模式并打印结果 for pattern, desc in patterns: print("'{}' ({})\n".format(pattern, desc)) print(" '{}'".format(text)) for match in re.finditer(pattern, text): s = match.start() e = match.end() substr = text[s:e] n_backslashes = text[:s].count('\\') prefix = '.' * (s + n_backslashes) print(" {}'{}'".format(prefix, substr)) print() return test_patterns( 'A prime #1 example!', [(r'\d+', 'sequence of digits'), (r'\D+', 'sequence of non-digits'), (r'\s+', 'sequence of whitespace'), (r'\S+', 'sequence of non-whitespace'), (r'\w+', 'alphanumeric characters'), (r'\W+', 'non-alphanumeric')], )
运行效果
'\d+' (sequence of digits) 'A prime #1 example!' .........'1' '\D+' (sequence of non-digits) 'A prime #1 example!' 'A prime #' ..........' example!' '\s+' (sequence of whitespace) 'A prime #1 example!' .' ' .......' ' ..........' ' '\S+' (sequence of non-whitespace) 'A prime #1 example!' 'A' ..'prime' ........'#1' ...........'example!' '\w+' (alphanumeric characters) 'A prime #1 example!' 'A' ..'prime' .........'1' ...........'example' '\W+' (non-alphanumeric) 'A prime #1 example!' .' ' .......' #' ..........' ' ..................'!'
13、转义匹配特殊符号
import re def test_patterns(text, patterns): """给源文本和模式列表,查找文本中每个模式的匹配,并将它们打印到stdout""" # 查找文本中的每个模式并打印结果 for pattern, desc in patterns: print("'{}' ({})\n".format(pattern, desc)) print(" '{}'".format(text)) for match in re.finditer(pattern, text): s = match.start() e = match.end() substr = text[s:e] n_backslashes = text[:s].count('\\') prefix = '.' * (s + n_backslashes) print(" {}'{}'".format(prefix, substr)) print() return test_patterns( r'\d+ \D+ \s+', [(r'\\.\+', 'escape code')], )
运行效果
'\\.\+' (escape code) '\d+ \D+ \s+' '\d+' .....'\D+' ..........'\s+'
14、定位匹配字符串
| 代码 | 含义 |
|---|---|
^ |
行开头 |
$ |
行末尾 |
\A |
字符串开头 |
\Z |
字符串末尾 |
\b |
单词开头或结尾处的空字符串 |
\B |
空字符串,不在单词的开头或结尾 |
import re def test_patterns(text, patterns): """给源文本和模式列表,查找文本中每个模式的匹配,并将它们打印到stdout""" # 查找文本中的每个模式并打印结果 for pattern, desc in patterns: print("'{}' ({})\n".format(pattern, desc)) print(" '{}'".format(text)) for match in re.finditer(pattern, text): s = match.start() e = match.end() substr = text[s:e] n_backslashes = text[:s].count('\\') prefix = '.' * (s + n_backslashes) print(" {}'{}'".format(prefix, substr)) print() return test_patterns( 'This is some text -- with punctuation.', [(r'^\w+', 'word at start of string'), (r'\A\w+', 'word at start of string'), (r'\w+\S*$', 'word near end of string'), (r'\w+\S*\Z', 'word near end of string'), (r'\w*t\w*', 'word containing t'), (r'\bt\w+', 't at start of word'), (r'\w+t\b', 't at end of word'), (r'\Bt\B', 't, not start or end of word')], )
运行效果
'^\w+' (word at start of string) 'This is some text -- with punctuation.' 'This' '\A\w+' (word at start of string) 'This is some text -- with punctuation.' 'This' '\w+\S*$' (word near end of string) 'This is some text -- with punctuation.' ..........................'punctuation.' '\w+\S*\Z' (word near end of string) 'This is some text -- with punctuation.' ..........................'punctuation.' '\w*t\w*' (word containing t) 'This is some text -- with punctuation.' .............'text' .....................'with' ..........................'punctuation' '\bt\w+' (t at start of word) 'This is some text -- with punctuation.' .............'text' '\w+t\b' (t at end of word) 'This is some text -- with punctuation.' .............'text' '\Bt\B' (t, not start or end of word) 'This is some text -- with punctuation.' .......................'t' ..............................'t' .................................'t'
15、限定搜索
re.match() : 从开头去匹配
re.search() : 从开头到结尾匹配
import re text = 'This is some text -- with punctuation.' pattern = 'is' print('Text :', text) print('Pattern:', pattern) m = re.match(pattern, text) print('Match :', m) s = re.search(pattern, text) print('Search :', s)
运行效果
Text : This is some text -- with punctuation. Pattern: is Match : None Search : <re.Match object; span=(2, 4), match='is'>
16、re.fullmatch() : 要求整个输入字符串与模式匹配
import re text = 'This is some text -- with punctuation.' pattern = 'is' print('Text :', text) print('Pattern :', pattern) m = re.search(pattern, text) print('Search :', m) s = re.fullmatch(pattern, text) print('Full match :', s)
运行效果
Text : This is some text -- with punctuation. Pattern : is Search : <re.Match object; span=(2, 4), match='is'> Full match : None
17、编译正则表达式,指定位置搜索匹配模式
import re text = 'This is some text -- with punctuation.' pattern = re.compile(r'\b\w*is\w*\b') # \b : 匹配一个单词边界 # \w : 匹配字母数字及下划线 print('Text:', text) print() pos = 0 while True: match = pattern.search(text, pos) if not match: break s = match.start() e = match.end() print(' {:>2d} : {:>2d} = "{}"'.format( s, e - 1, text[s:e])) # 在文本中前进,以便下一次搜索 pos = e
运行效果
Text: This is some text -- with punctuation. 0 : 3 = "This" 5 : 6 = "is"
18、用小括号模式来定义组
import re def test_patterns(text, patterns): """给源文本和模式列表,查找文本中每个模式的匹配,并将它们打印到stdout""" # 查找文本中的每个模式并打印结果 for pattern, desc in patterns: print("'{}' ({})\n".format(pattern, desc)) print(" '{}'".format(text)) for match in re.finditer(pattern, text): s = match.start() e = match.end() substr = text[s:e] n_backslashes = text[:s].count('\\') prefix = '.' * (s + n_backslashes) print(" {}'{}'".format(prefix, substr)) print() return test_patterns( 'abbaaabbbbaaaaa', [('a(ab)', 'a followed by literal ab'), ('a(a*b*)', 'a followed by 0-n a and 0-n b'), ('a(ab)*', 'a followed by 0-n ab'), ('a(ab)+', 'a followed by 1-n ab')], )
运行效果
'a(ab)' (a followed by literal ab) 'abbaaabbbbaaaaa' ....'aab' 'a(a*b*)' (a followed by 0-n a and 0-n b) 'abbaaabbbbaaaaa' 'abb' ...'aaabbbb' ..........'aaaaa' 'a(ab)*' (a followed by 0-n ab) 'abbaaabbbbaaaaa' 'a' ...'a' ....'aab' ..........'a' ...........'a' ............'a' .............'a' ..............'a' 'a(ab)+' (a followed by 1-n ab) 'abbaaabbbbaaaaa' ....'aab'
19、使用groups(),获取分组的元素
import re text = 'This is some text -- with punctuation.' print(text) print() patterns = [ (r'^(\w+)', 'word at start of string'), (r'(\w+)\S*$', 'word at end, with optional punctuation'), (r'(\bt\w+)\W+(\w+)', 'word starting with t, another word'), (r'(\w+t)\b', 'word ending with t'), ] for pattern, desc in patterns: regex = re.compile(pattern) match = regex.search(text) print("'{}' ({})\n".format(pattern, desc)) print(' ', match.groups()) print()
运行效果
This is some text -- with punctuation. '^(\w+)' (word at start of string) ('This',) '(\w+)\S*$' (word at end, with optional punctuation) ('punctuation',) '(\bt\w+)\W+(\w+)' (word starting with t, another word) ('text', 'with') '(\w+t)\b' (word ending with t) ('text',)
20、使用单个组匹配,通过组id获取对应的值,0:表示获取匹配所有的元素,1:表示正式表达式第一个括号,以此类推
import re text = 'This is some text -- with punctuation.' print('Input text :', text) # word starting with 't' then another word regex = re.compile(r'(\bt\w+)\W+(\w+)') print('Pattern :', regex.pattern) match = regex.search(text) print('Entire match :', match.group(0)) print('Word starting with "t":', match.group(1)) print('Word after "t" word :', match.group(2))
运行效果
Input text : This is some text -- with punctuation. Pattern : (\bt\w+)\W+(\w+) Entire match : text -- with Word starting with "t": text Word after "t" word : with
21、命令组名,通过组名获取取,这个是python扩展的功能,可以返回字典类型或元组类型
import re text = 'This is some text -- with punctuation.' print(text) print() patterns = [ r'^(?P<first_word>\w+)', r'(?P<last_word>\w+)\S*$', r'(?P<t_word>\bt\w+)\W+(?P<other_word>\w+)', r'(?P<ends_with_t>\w+t)\b', ] for pattern in patterns: regex = re.compile(pattern) match = regex.search(text) print("'{}'".format(pattern)) print(' ', match.groups()) print(' ', match.groupdict()) print()
运行效果
This is some text -- with punctuation. '^(?P<first_word>\w+)' ('This',) {'first_word': 'This'} '(?P<last_word>\w+)\S*$' ('punctuation',) {'last_word': 'punctuation'} '(?P<t_word>\bt\w+)\W+(?P<other_word>\w+)' ('text', 'with') {'t_word': 'text', 'other_word': 'with'} '(?P<ends_with_t>\w+t)\b' ('text',) {'ends_with_t': 'text'}
22、更新test_patterns(),会显示一个模式匹配的编号组和命名组
import re def test_patterns(text, patterns): for pattern, desc in patterns: print('{!r} ({})\n'.format(pattern, desc)) print(' {!r}'.format(text)) for match in re.finditer(pattern, text): s = match.start() e = match.end() prefix = ' ' * (s) print( ' {}{!r}{} '.format(prefix, text[s:e], ' ' * (len(text) - e)), end=' ', ) print(match.groups()) if match.groupdict(): print('{}{}'.format( ' ' * (len(text) - s), match.groupdict()), ) print() return test_patterns( 'abbaabbba', [(r'a((a*)(b*))', 'a followed by 0-n a and 0-n b')], )
运行效果
'a((a*)(b*))' (a followed by 0-n a and 0-n b) 'abbaabbba' 'abb' ('bb', '', 'bb') 'aabbb' ('abbb', 'a', 'bbb') 'a' ('', '', '')
23、组分匹配或的关系
import re def test_patterns(text, patterns): for pattern, desc in patterns: print('{!r} ({})\n'.format(pattern, desc)) print(' {!r}'.format(text)) for match in re.finditer(pattern, text): s = match.start() e = match.end() prefix = ' ' * (s) print( ' {}{!r}{} '.format(prefix, text[s:e], ' ' * (len(text) - e)), end=' ', ) print(match.groups()) if match.groupdict(): print('{}{}'.format( ' ' * (len(text) - s), match.groupdict()), ) print() return test_patterns( 'abbaabbba', [(r'a((a+)|(b+))', 'a then seq. of a or seq. of b'), (r'a((a|b)+)', 'a then seq. of [ab]')], )
运行效果
'a((a+)|(b+))' (a then seq. of a or seq. of b) 'abbaabbba' 'abb' ('bb', None, 'bb') 'aa' ('a', 'a', None) 'a((a|b)+)' (a then seq. of [ab]) 'abbaabbba' 'abbaabbba' ('bbaabbba', 'a')
24、非捕获分组,即取出正常分组的第一组元素,语法: (?:正则表达式)
import re def test_patterns(text, patterns): for pattern, desc in patterns: print('{!r} ({})\n'.format(pattern, desc)) print(' {!r}'.format(text)) for match in re.finditer(pattern, text): s = match.start() e = match.end() prefix = ' ' * (s) print( ' {}{!r}{} '.format(prefix, text[s:e], ' ' * (len(text) - e)), end=' ', ) print(match.groups()) if match.groupdict(): print('{}{}'.format( ' ' * (len(text) - s), match.groupdict()), ) print() return test_patterns( 'abbaabbba', [(r'a((a+)|(b+))', 'capturing form'), (r'a((?:a+)|(?:b+))', 'noncapturing')], )
运行效果
'a((a+)|(b+))' (capturing form) 'abbaabbba' 'abb' ('bb', None, 'bb') 'aa' ('a', 'a', None) 'a((?:a+)|(?:b+))' (noncapturing) 'abbaabbba' 'abb' ('bb',) 'aa' ('a',)
25、搜索选项,忽略大小写的匹配
import re text = 'This is some text -- with punctuation.' pattern = r'\bT\w+' with_case = re.compile(pattern) without_case = re.compile(pattern, re.IGNORECASE) print('Text:\n {!r}'.format(text)) print('Pattern:\n {}'.format(pattern)) print('Case-sensitive:') for match in with_case.findall(text): print(' {!r}'.format(match)) print('Case-insensitive:') for match in without_case.findall(text): print(' {!r}'.format(match))
运行效果
Text: 'This is some text -- with punctuation.' Pattern: \bT\w+ Case-sensitive: 'This' Case-insensitive: 'This' 'text'
26、搜索选项,多行匹配,即文本有回车符,当多行来进行匹配
import re text = 'This is some text -- with punctuation.\nA second line.' pattern = r'(^\w+)|(\w+\S*$)' single_line = re.compile(pattern) multiline = re.compile(pattern, re.MULTILINE) print('Text:\n {!r}'.format(text)) print('Pattern:\n {}'.format(pattern)) print('Single Line :') for match in single_line.findall(text): print(' {!r}'.format(match)) print('Multline :') for match in multiline.findall(text): print(' {!r}'.format(match))
运行效果
Text: 'This is some text -- with punctuation.\nA second line.' Pattern: (^\w+)|(\w+\S*$) Single Line : ('This', '') ('', 'line.') Multline : ('This', '') ('', 'punctuation.') ('A', '') ('', 'line.')
27、搜索选项,多行匹配,利用点的符号,当多行来进行匹配
import re text = 'This is some text -- with punctuation.\nA second line.' pattern = r'.+' no_newlines = re.compile(pattern) dotall = re.compile(pattern, re.DOTALL) print('Text:\n {!r}'.format(text)) print('Pattern:\n {}'.format(pattern)) print('No newlines :') for match in no_newlines.findall(text): print(' {!r}'.format(match)) print('Dotall :') for match in dotall.findall(text): print(' {!r}'.format(match))
运行效果
Text: 'This is some text -- with punctuation.\nA second line.' Pattern: .+ No newlines : 'This is some text -- with punctuation.' 'A second line.' Dotall : 'This is some text -- with punctuation.\nA second line.'
28、指示匹配的编码,默认是使用unicode,可以指定匹配ASCII码
import re text = u'Français złoty Österreich' pattern = r'\w+' ascii_pattern = re.compile(pattern, re.ASCII) unicode_pattern = re.compile(pattern) print('Text :', text) print('Pattern :', pattern) print('ASCII :', list(ascii_pattern.findall(text))) print('Unicode :', list(unicode_pattern.findall(text)))
运行效果
Text : Français złoty Österreich Pattern : \w+ ASCII : ['Fran', 'ais', 'z', 'oty', 'sterreich'] Unicode : ['Français', 'złoty', 'Österreich']
29、邮箱格式的复杂匹配
import re address = re.compile('[\w\d.+-]+@([\w\d.]+\.)+(com|org|edu)') candidates = [ u'first.last@example.com', u'first.last+category@gmail.com', u'valid-address@mail.example.com', u'not-valid@example.foo', ] for candidate in candidates: match = address.search(candidate) print('{:<30} {}'.format( candidate, 'Matches' if match else 'No match') )
运行效果
first.last@example.com Matches first.last+category@gmail.com Matches valid-address@mail.example.com Matches not-valid@example.foo No match
30、格式化正则表达式邮箱格式的匹配
import re address = re.compile( ''' [\w\d.+-]+ # username @ ([\w\d.]+\.)+ # domain name prefix (com|org|edu) # TODO: support more top-level domains ''', re.VERBOSE) candidates = [ u'first.last@example.com', u'first.last+category@gmail.com', u'valid-address@mail.example.com', u'not-valid@example.foo', ] for candidate in candidates: match = address.search(candidate) print('{:<30} {}'.format( candidate, 'Matches' if match else 'No match'), )
运行效果
first.last@example.com Matches first.last+category@gmail.com Matches valid-address@mail.example.com Matches not-valid@example.foo No match
31、定义组的别名和正则表达式的注释
import re address = re.compile( ''' # A name is made up of letters, and may include "." # for title abbreviations and middle initials. ((?P<name> ([\w.,]+\s+)*[\w.,]+) \s* # Email addresses are wrapped in angle # brackets < >, but only if a name is # found, so keep the start bracket in this # group. < )? # the entire name is optional # The address itself: username@domain.tld (?P<email> [\w\d.+-]+ # username @ ([\w\d.]+\.)+ # domain name prefix (com|org|edu) # limit the allowed top-level domains ) >? # optional closing angle bracket ''', re.VERBOSE) candidates = [ u'first.last@example.com', u'first.last+category@gmail.com', u'valid-address@mail.example.com', u'not-valid@example.foo', u'First Last <first.last@example.com>', u'No Brackets first.last@example.com', u'First Last', u'First Middle Last <first.last@example.com>', u'First M. Last <first.last@example.com>', u'<first.last@example.com>', ] for candidate in candidates: print('Candidate:', candidate) match = address.search(candidate) if match: print(' Name :', match.groupdict()['name']) print(' Email:', match.groupdict()['email']) else: print(' No match')
运行效果
Candidate: first.last@example.com Name : None Email: first.last@example.com Candidate: first.last+category@gmail.com Name : None Email: first.last+category@gmail.com Candidate: valid-address@mail.example.com Name : None Email: valid-address@mail.example.com Candidate: not-valid@example.foo No match Candidate: First Last <first.last@example.com> Name : First Last Email: first.last@example.com Candidate: No Brackets first.last@example.com Name : None Email: first.last@example.com Candidate: First Last No match Candidate: First Middle Last <first.last@example.com> Name : First Middle Last Email: first.last@example.com Candidate: First M. Last <first.last@example.com> Name : First M. Last Email: first.last@example.com Candidate: <first.last@example.com> Name : None Email: first.last@example.com
32、在编译模式,不会传入标志,解决方法:例如:忽略大小写匹配的模式
import re text = 'This is some text -- with punctuation.' pattern = r'(?i)\bT\w+' regex = re.compile(pattern) print('Text :', text) print('Pattern :', pattern) print('Matches :', regex.findall(text))
运行效果
Text : This is some text -- with punctuation. Pattern : (?i)\bT\w+ Matches : ['This', 'text']
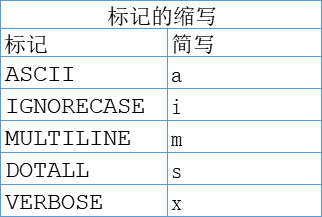
33、前向断言匹配,(?= pattern)
import re address = re.compile( ''' # A name is made up of letters, and may include "." # for title abbreviations and middle initials. ((?P<name> ([\w.,]+\s+)*[\w.,]+ ) \s+ ) # name is no longer optional # LOOKAHEAD # Email addresses are wrapped in angle brackets, but only # if both are present or neither is. (?= (<.*>$) # remainder wrapped in angle brackets | ([^<].*[^>]$) # remainder *not* wrapped in angle brackets ) <? # optional opening angle bracket # The address itself: username@domain.tld (?P<email> [\w\d.+-]+ # username @ ([\w\d.]+\.)+ # domain name prefix (com|org|edu) # limit the allowed top-level domains ) >? # optional closing angle bracket ''', re.VERBOSE) candidates = [ u'First Last <first.last@example.com>', u'No Brackets first.last@example.com', u'Open Bracket <first.last@example.com', u'Close Bracket first.last@example.com>', ] for candidate in candidates: print('Candidate:', candidate) match = address.search(candidate) if match: print(' Name :', match.groupdict()['name']) print(' Email:', match.groupdict()['email']) else: print(' No match')
运行效果
Candidate: First Last <first.last@example.com> Name : First Last Email: first.last@example.com Candidate: No Brackets first.last@example.com Name : No Brackets Email: first.last@example.com Candidate: Open Bracket <first.last@example.com No match Candidate: Close Bracket first.last@example.com> No match
34、前向断言取反匹配,(?= pattern)
import re address = re.compile( ''' ^ # An address: username@domain.tld # Ignore noreply addresses (?!noreply@.*$) [\w\d.+-]+ # username @ ([\w\d.]+\.)+ # domain name prefix (com|org|edu) # limit the allowed top-level domains $ ''', re.VERBOSE) candidates = [ u'first.last@example.com', u'noreply@example.com', ] for candidate in candidates: print('Candidate:', candidate) match = address.search(candidate) if match: print(' Match:', candidate[match.start():match.end()]) else: print(' No match')
运行效果
Candidate: first.last@example.com
Match: first.last@example.com
Candidate: noreply@example.com
No match
35、后向断言匹配,否定向后【(?<!pattern)】
import re address = re.compile( ''' ^ # An address: username@domain.tld [\w\d.+-]+ # username # Ignore noreply addresses (?<!noreply) @ ([\w\d.]+\.)+ # domain name prefix (com|org|edu) # limit the allowed top-level domains $ ''', re.VERBOSE) candidates = [ u'first.last@example.com', u'noreply@example.com', ] for candidate in candidates: print('Candidate:', candidate) match = address.search(candidate) if match: print(' Match:', candidate[match.start():match.end()]) else: print(' No match')
运行效果
Candidate: first.last@example.com
Match: first.last@example.com
Candidate: noreply@example.com
No match
36、后向断言匹配,肯定向后【(?<=pattern)】
import re twitter = re.compile( ''' # A twitter handle: @username (?<=@) ([\w\d_]+) # username ''', re.VERBOSE) text = '''This text includes two Twitter handles. One for @ThePSF, and one for the author, @doughellmann. ''' print(text) for match in twitter.findall(text): print('Handle:', match)
运行效果
This text includes two Twitter handles. One for @ThePSF, and one for the author, @doughellmann. Handle: ThePSF Handle: doughellmann
37、自引用表达式,采用\num进行分组,然后用group(num)获取值
import re address = re.compile( r''' # The regular name (\w+) # first name \s+ (([\w.]+)\s+)? # optional middle name or initial (\w+) # last name \s+ < # The address: first_name.last_name@domain.tld (?P<email> \1 # first name \. \4 # last name @ ([\w\d.]+\.)+ # domain name prefix (com|org|edu) # limit the allowed top-level domains ) > ''', re.VERBOSE | re.IGNORECASE) candidates = [ u'First Last <first.last@example.com>', u'Different Name <first.last@example.com>', u'First Middle Last <first.last@example.com>', u'First M. Last <first.last@example.com>', ] for candidate in candidates: print('Candidate:', candidate) match = address.search(candidate) if match: print(' Match name :', match.group(1), match.group(4)) print(' Match email:', match.group(5)) else: print(' No match')
运行效果
Candidate: First Last <first.last@example.com> Match name : First Last Match email: first.last@example.com Candidate: Different Name <first.last@example.com> No match Candidate: First Middle Last <first.last@example.com> Match name : First Last Match email: first.last@example.com Candidate: First M. Last <first.last@example.com> Match name : First Last Match email: first.last@example.com
38、自引用表达式,采用(?P=name) ,groupdict()['name'])
import re address = re.compile( ''' # The regular name (?P<first_name>\w+) \s+ (([\w.]+)\s+)? # optional middle name or initial (?P<last_name>\w+) \s+ < # The address: first_name.last_name@domain.tld (?P<email> (?P=first_name) \. (?P=last_name) @ ([\w\d.]+\.)+ # domain name prefix (com|org|edu) # limit the allowed top-level domains ) > ''', re.VERBOSE | re.IGNORECASE) candidates = [ u'First Last <first.last@example.com>', u'Different Name <first.last@example.com>', u'First Middle Last <first.last@example.com>', u'First M. Last <first.last@example.com>', ] for candidate in candidates: print('Candidate:', candidate) match = address.search(candidate) if match: print(' Match name :', match.groupdict()['first_name'], end=' ') print(match.groupdict()['last_name']) print(' Match email:', match.groupdict()['email']) else: print(' No match')
运行效果
Candidate: First Last <first.last@example.com> Match name : First Last Match email: first.last@example.com Candidate: Different Name <first.last@example.com> No match Candidate: First Middle Last <first.last@example.com> Match name : First Last Match email: first.last@example.com Candidate: First M. Last <first.last@example.com> Match name : First Last Match email: first.last@example.com
39、反向引用
语法:
(?P<brackets>(?=(<.*>$))) #匹配 | (?=([^<].*[^>]$)) #非匹配 )
import re address = re.compile( ''' ^ # A name is made up of letters, and may include "." # for title abbreviations and middle initials. (?P<name> ([\w.]+\s+)*[\w.]+ )? \s* # Email addresses are wrapped in angle brackets, but # only if a name is found. (?(name) # remainder wrapped in angle brackets because # there is a name (?P<brackets>(?=(<.*>$))) | # remainder does not include angle brackets without name (?=([^<].*[^>]$)) ) # Look for a bracket only if the look-ahead assertion # found both of them. (?(brackets)<|\s*) # The address itself: username@domain.tld (?P<email> [\w\d.+-]+ # username @ ([\w\d.]+\.)+ # domain name prefix (com|org|edu) # limit the allowed top-level domains ) # Look for a bracket only if the look-ahead assertion # found both of them. (?(brackets)>|\s*) $ ''', re.VERBOSE) candidates = [ u'First Last <first.last@example.com>', u'No Brackets first.last@example.com', u'Open Bracket <first.last@example.com', u'Close Bracket first.last@example.com>', u'no.brackets@example.com', ] for candidate in candidates: print('Candidate:', candidate) match = address.search(candidate) if match: print(' Match name :', match.groupdict()['name']) print(' Match email:', match.groupdict()['email']) else: print(' No match')
运行效果
Candidate: First Last <first.last@example.com> Match name : First Last Match email: first.last@example.com Candidate: No Brackets first.last@example.com No match Candidate: Open Bracket <first.last@example.com No match Candidate: Close Bracket first.last@example.com> No match Candidate: no.brackets@example.com Match name : None Match email: no.brackets@example.com
40、用模式修改字符串,sub('替换新的字符串',匹配结果):将匹配到的字符串,替换为新的字符串,再更新到原来的字符串
import re bold = re.compile(r'\*{2}(.*?)\*{2}') text = 'Make this **bold**. This **too**.' print('Text:', text) print('Bold:', bold.sub(r'<b>\1</b>', text))
运行效果
Text: Make this **bold**. This **too**. ['bold', 'too'] Bold: Make this <b>bold</b>. This <b>too</b>.
41、通过组的命名替换,\g<name>
import re bold = re.compile(r'\*{2}(?P<bold_text>.*?)\*{2}') text = 'Make this **bold**. This **too**.' print('Text:', text) print('Bold:', bold.sub(r'<b>\g<bold_text></b>', text))
运行效果
Text: Make this **bold**. This **too**.
Bold: Make this <b>bold</b>. This <b>too</b>.
42、通过组的命名替换字符串,定义count设置替换的次数
import re bold = re.compile(r'\*{2}(.*?)\*{2}') text = 'Make this **bold**. This **too**.' print('Text:', text) print('Bold:', bold.sub(r'<b>\1</b>', text, count=1))
运行效果
Text: Make this **bold**. This **too**.
Bold: Make this <b>bold</b>. This **too**.
43、subn()的使用,sub()与subn()的区别,subn()会返回替换结果和替换的次数
import re bold = re.compile(r'\*{2}(.*?)\*{2}') text = 'Make this **bold**. This **too**.' print('Text:', text) print('Bold:', bold.subn(r'<b>\1</b>', text))
运行效果
Text: Make this **bold**. This **too**. Bold: ('Make this <b>bold</b>. This <b>too</b>.', 2)
44、利用两个\n分割字符串取值,传统的方法
import re text = '''Paragraph one on two lines. Paragraph two. Paragraph three.''' for num, para in enumerate(re.findall(r'(.+?)\n{2,}', text, flags=re.DOTALL)): print(num, repr(para)) print()
运行效果
0 'Paragraph one\non two lines.' 1 'Paragraph two.'
45、利用正则表达对字符串进行分隔,此示例是以两个回车符为例进行切割
import re text = '''Paragraph one on two lines. Paragraph two. Paragraph three.''' print('With findall:') for num, para in enumerate(re.findall(r'(.+?)(\n{2,}|$)', text, flags=re.DOTALL)): print(num, repr(para)) print() print() print('With split:') for num, para in enumerate(re.split(r'\n{2,}', text)): print(num, repr(para)) print()
运行效果
With findall: 0 ('Paragraph one\non two lines.', '\n\n') 1 ('Paragraph two.', '\n\n\n') 2 ('Paragraph three.', '') With split: 0 'Paragraph one\non two lines.' 1 'Paragraph two.' 2 'Paragraph three.'
46、指定分组正则表达式切分字符串,并且返回匹配到的分割符
import re text = '''Paragraph one on two lines. Paragraph two. Paragraph three.''' print('With split:') for num, para in enumerate(re.split(r'(\n{2,})', text)): print(num, repr(para)) print()
运行效果
With split: 0 'Paragraph one\non two lines.' 1 '\n\n' 2 'Paragraph two.' 3 '\n\n\n' 4 'Paragraph three.'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号