Python之collections模块的使用
collections模块的作用
collections模块包含除内置类型list\dict\tuple以外的其他容器数据类型。
一、collections.ChainMap连接字典
1、搜索多个字典的示例


import collections a = {'a': 'A', 'c': 'C'} b = {'b': 'B', 'c': 'D'} m = collections.ChainMap(a, b) print('Individual Values') print('a = {}'.format(m['a'])) print('b = {}'.format(m['b'])) print('c = {}'.format(m['c'])) print() print('Keys = {}'.format(list(m.keys()))) print('Values = {}'.format(list(m.values()))) print() print('Items:') for k, v in m.items(): print('{} = {}'.format(k, v)) print() print('"d" in m: {}'.format(('d' in m)))
运行效果
Individual Values a = A b = B c = C Keys = ['b', 'c', 'a'] Values = ['B', 'C', 'A'] Items: b = B c = C a = A "d" in m: False
2、排序字典,重新获取key-value的示例
import collections a = {'a': 'A', 'c': 'C'} b = {'b': 'B', 'c': 'D'} m = collections.ChainMap(a, b) print(m.maps) print('c = {}\n'.format(m['c'])) # 用key排序字典 m.maps = list(reversed(m.maps)) print(m.maps) print('c = {}'.format(m['c']))
运行效果
[{'a': 'A', 'c': 'C'}, {'b': 'B', 'c': 'D'}]
c = C
[{'b': 'B', 'c': 'D'}, {'a': 'A', 'c': 'C'}]
c = D
3、连接字典数据的修改的示例
import collections a = {'a': 'A', 'c': 'C'} b = {'b': 'B', 'c': 'D'} m = collections.ChainMap(a, b) print('Before: {}'.format(m['c'])) a['c'] = 'E' print('After : {}'.format(m['c']))
运行效果
Before: C
After : E
4、连接字典数据的修改其实字典也会被修改示例
import collections a = {'a': 'A', 'c': 'C'} b = {'b': 'B', 'c': 'D'} m = collections.ChainMap(a, b) print('Before:', m) m['c'] = 'E' print('After :', m) print('a:', a)
运行效果
Before: ChainMap({'a': 'A', 'c': 'C'}, {'b': 'B', 'c': 'D'})
After : ChainMap({'a': 'A', 'c': 'E'}, {'b': 'B', 'c': 'D'})
a: {'a': 'A', 'c': 'E'}
5、新建一个子节点,方便修改字典连的示例
import collections a = {'a': 'A', 'c': 'C'} b = {'b': 'B', 'c': 'D'} m1 = collections.ChainMap(a, b) m2 = m1.new_child() print('m1 before:', m1) print('m2 before:', m2) m2['c'] = 'E' print('m1 after:', m1) print('m2 after:', m2)
运行效果
m1 before: ChainMap({'a': 'A', 'c': 'C'}, {'b': 'B', 'c': 'D'})
m2 before: ChainMap({}, {'a': 'A', 'c': 'C'}, {'b': 'B', 'c': 'D'})
m1 after: ChainMap({'a': 'A', 'c': 'C'}, {'b': 'B', 'c': 'D'})
m2 after: ChainMap({'c': 'E'}, {'a': 'A', 'c': 'C'}, {'b': 'B', 'c': 'D'})
6、新建一个子节点,并且传参数,直接进行修改的示例
import collections a = {'a': 'A', 'c': 'C'} b = {'b': 'B', 'c': 'D'} c = {'c': 'E'} m1 = collections.ChainMap(a, b) m2 = m1.new_child(c) print('m1["c"] = {}'.format(m1['c'])) print('m2["c"] = {}'.format(m2['c']))
运行效果
m1["c"] = C m2["c"] = E
二、统计Hashable对象的次数
Counter是一个容器,可以统计相同值出现的次数。
7、初始化Counter容器
import collections print(collections.Counter(['a', 'b', 'c', 'a', 'b', 'b'])) print(collections.Counter({'a': 2, 'b': 3, 'c': 1})) print(collections.Counter(a=2, b=3, c=1))
运行效果
Counter({'b': 3, 'a': 2, 'c': 1})
Counter({'b': 3, 'a': 2, 'c': 1})
Counter({'b': 3, 'a': 2, 'c': 1})
8、初始化空的Counter容器,需要update来进行更新
import collections c = collections.Counter() print('Initial :', c) c.update('abcdaab') print('Sequence:', c) c.update({'a': 1, 'd': 5}) print('Dict :', c)
运行效果
Initial : Counter() Sequence: Counter({'a': 3, 'b': 2, 'c': 1, 'd': 1}) Dict : Counter({'d': 6, 'a': 4, 'b': 2, 'c': 1})
9、给一批数据,统计各元素访问的次数
import collections c = collections.Counter('abcdaab') for letter in 'abcde': print('{} : {}'.format(letter, c[letter]))
运行效果
a : 3 b : 2 c : 1 d : 1 e : 0
10、elements()返回迭代器里面是所有的元素
import collections c = collections.Counter('extremely') c['z'] = 0 print(c) print(list(c.elements()))
运行效果
Counter({'e': 3, 'x': 1, 't': 1, 'r': 1, 'm': 1, 'l': 1, 'y': 1, 'z': 0})
['e', 'e', 'e', 'x', 't', 'r', 'm', 'l', 'y']
11、most_common(N),返回出现次数最多的前N个的示例
import collections c = collections.Counter() with open('words', 'rt',encoding='utf-8') as f: for line in f: c.update(line.rstrip().lower()) print('Most common:') for letter, count in c.most_common(3): print('{}: {:>7}'.format(letter, count))
运行效果
Most common: : 674 e: 397 t: 396
12、Counter容器的算术运算
import collections c1 = collections.Counter(['a', 'b', 'c', 'a', 'b', 'b']) c2 = collections.Counter('alphabet') print('C1:', c1) print('C2:', c2) print('\nCombined counts:') print(c1 + c2) print('\nSubtraction:') print(c1 - c2) print('\nIntersection (taking positive minimums):') print(c1 & c2) print('\nUnion (taking maximums):') print(c1 | c2)
运行效果
C1: Counter({'b': 3, 'a': 2, 'c': 1})
C2: Counter({'a': 2, 'l': 1, 'p': 1, 'h': 1, 'b': 1, 'e': 1, 't': 1})
Combined counts:
Counter({'a': 4, 'b': 4, 'c': 1, 'l': 1, 'p': 1, 'h': 1, 'e': 1, 't': 1})
Subtraction:
Counter({'b': 2, 'c': 1})
Intersection (taking positive minimums):
Counter({'a': 2, 'b': 1})
Union (taking maximums):
Counter({'b': 3, 'a': 2, 'c': 1, 'l': 1, 'p': 1, 'h': 1, 'e': 1, 't': 1})
三、defaultdict设置一个字典默认的返回值
13、defaultdict设置一个字典默认的返回值
import collections def default_factory(): return 'default value' d = collections.defaultdict(default_factory, foo='bar') print('d:', d) print('foo =>', d['foo']) print('bar =>', d['bar'])
运行效果
d: defaultdict(<function default_factory at 0x0000024D18064288>, {'foo': 'bar'})
foo => bar
bar => default value
四、双端队列
作用:
双端队列或deque支持从任意一端增加和删除元素。更为常用的两种结构(即栈和队列)就是双端队列的退化形式,它们的输入和输出被限制在某一端。
14、双端队列创建、删除、获取数据
import collections d = collections.deque('abcdefg') print('Deque:', d) print('Length:', len(d)) print('Left end:', d[0]) print('Right end:', d[-1]) d.remove('c') print('remove(c):', d)
运行效果
Deque: deque(['a', 'b', 'c', 'd', 'e', 'f', 'g']) Length: 7 Left end: a Right end: g remove(c): deque(['a', 'b', 'd', 'e', 'f', 'g'])
15、双端队列的左,右端数据的增加示例
import collections # 增加元素到双端队列的右端 d1 = collections.deque() d1.extend('abcdefg') print('extend :', d1) d1.append('h') print('append :', d1) # 增加元素到双端队列的左端 d2 = collections.deque() d2.extendleft(range(6)) print('extendleft:', d2) d2.appendleft(6) print('appendleft:', d2)
运行效果
extend : deque(['a', 'b', 'c', 'd', 'e', 'f', 'g']) append : deque(['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']) extendleft: deque([5, 4, 3, 2, 1, 0]) appendleft: deque([6, 5, 4, 3, 2, 1, 0])
16、双端队列左,右端数据的获取
import collections print('从右往左取:') d = collections.deque('abcdefg') while True: try: print(d.pop(), end='') except IndexError: break print() print('\n从左往右取:') d = collections.deque(range(6)) while True: try: print(d.popleft(), end='') except IndexError: break print()
运行效果
从右往左取:
gfedcba
从左往右取:
012345
17、双端队列是线程安全的示例
import collections import threading import time candle = collections.deque(range(5)) def burn(direction, nextSource): while True: try: next = nextSource() except IndexError: break else: print('{:>8}: {}'.format(direction, next)) time.sleep(0.1) print('{:>8} done'.format(direction)) return left = threading.Thread(target=burn,args=('Left', candle.popleft)) right = threading.Thread(target=burn,args=('Right', candle.pop)) left.start() right.start() left.join() right.join()
运行效果
Left: 0 Right: 4 Left: 1 Right: 3 Left: 2 Right done Left done
18、双端队列旋转,规则,正数:右出左进,负数:左出右进
import collections d = collections.deque(range(10)) print('Normal :', d) d = collections.deque(range(10)) d.rotate(2) print('Right rotation:', d) d = collections.deque(range(10)) d.rotate(-2) print('Left rotation :', d)
运行效果
Normal : deque([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) Right rotation: deque([8, 9, 0, 1, 2, 3, 4, 5, 6, 7]) Left rotation : deque([2, 3, 4, 5, 6, 7, 8, 9, 0, 1])
19、双端队列设置存储最多的数量
import collections import random # 设置随机种子,这样我们每次运行脚本时都会看到相同的输出 random.seed(1) d1 = collections.deque(maxlen=3) d2 = collections.deque(maxlen=3) for i in range(5): n = random.randint(0, 100) print('n =', n) d1.append(n) d2.appendleft(n) print('D1:', d1) print('D2:', d2)
运行效果
n = 17 D1: deque([17], maxlen=3) D2: deque([17], maxlen=3) n = 72 D1: deque([17, 72], maxlen=3) D2: deque([72, 17], maxlen=3) n = 97 D1: deque([17, 72, 97], maxlen=3) D2: deque([97, 72, 17], maxlen=3) n = 8 D1: deque([72, 97, 8], maxlen=3) D2: deque([8, 97, 72], maxlen=3) n = 32 D1: deque([97, 8, 32], maxlen=3) D2: deque([32, 8, 97], maxlen=3)
五、带命名字段的元组子类
20、普通元组的取值方式
# 取整个元组 bob = ('Bob', 30, 'male') print('Representation:', bob) # 取元级第一个元素 jane = ('Jane', 29, 'female') print('\nField by index:', jane[0]) # 使用*号,打印整体的元组 print('\nFields by index:') for p in [bob, jane]: print('{} is a {} year old {}'.format(*p))
运行效果
Representation: ('Bob', 30, 'male') Field by index: Jane Fields by index: Bob is a 30 year old male Jane is a 29 year old female
21、定义命令字段的元组。collections.namedtuple(元组名字, '字段1 字段2')
import collections Person = collections.namedtuple('Person', 'name age') bob = Person(name='Bob', age=30) print('\nRepresentation:', bob) jane = Person(name='Jane', age=29) print('\nField by name:', jane.name) print('\nFields by index:') for p in [bob, jane]: print('{} is {} years old'.format(*p))
运行效果
Representation: Person(name='Bob', age=30) Field by name: Jane Fields by index: Bob is 30 years old Jane is 29 years old
22、命令元组属性是不可以修改的示例
import collections Person = collections.namedtuple('Person', 'name age') pat = Person(name='Pat', age=12) print('\nRepresentation:', pat) pat.age = 21
运行效果
Representation: Person(name='Pat', age=12)
23、命令元组属性名有重复的时候,异常的处理
import collections try: collections.namedtuple('Person', 'name class age') except ValueError as err: print(err) try: collections.namedtuple('Person', 'name age age') except ValueError as err: print(err)
运行效果
Type names and field names cannot be a keyword: 'class' Encountered duplicate field name: 'age'
24、对非法字段名重复进行做下标的处理
import collections with_class = collections.namedtuple( 'Person', 'name class age', rename=True) print(with_class._fields) two_ages = collections.namedtuple( 'Person', 'name age age', rename=True) print(two_ages._fields)
运行效果
('name', '_1', 'age') ('name', 'age', '_2')
25、查看指定命令元组对象,可调用的字段名
import collections Person = collections.namedtuple('Person', 'name age') bob = Person(name='Bob', age=30) print('Representation:', bob) print('Fields:', bob._fields)
运行效果
Representation: Person(name='Bob', age=30) Fields: ('name', 'age')
26、查看指定命令元组对象,可调用的字段名,以有序字典返回
import collections Person = collections.namedtuple('Person', 'name age') bob = Person(name='Bob', age=30) print('Representation:', bob) print('As Dictionary:', bob._asdict())
运行效果
Representation: Person(name='Bob', age=30) As Dictionary: OrderedDict([('name', 'Bob'), ('age', 30)])
27、可命名元组数据的修改,其实就是修改内存对象
import collections Person = collections.namedtuple('Person', 'name age') bob = Person(name='Bob', age=30) print('\nBefore:', bob) bob2 = bob._replace(name='Robert') print('After:', bob2) print('Same?:', bob is bob2)
运行效果
Before: Person(name='Bob', age=30) After: Person(name='Robert', age=30) Same?: False
六、有序字典
28、普通字典和排序字典的创建
import collections print('普通字典:') d = {} d['a'] = 'A' d['b'] = 'B' d['c'] = 'C' for k, v in d.items(): print(k, v) print('\n排序字典:') d = collections.OrderedDict() d['a'] = 'A' d['b'] = 'B' d['c'] = 'C' for k, v in d.items(): print(k, v)
运行效果
普通字典:
a A
b B
c C
排序字典:
a A
b B
c C
29、分别创建两个普通字典和排序字典对象内存地址的比较
import collections print('dict :', end=' ') d1 = {} d1['a'] = 'A' d1['b'] = 'B' d1['c'] = 'C' d2 = {} d2['c'] = 'C' d2['b'] = 'B' d2['a'] = 'A' print(d1 == d2) print('OrderedDict:', end=' ') d1 = collections.OrderedDict() d1['a'] = 'A' d1['b'] = 'B' d1['c'] = 'C' d2 = collections.OrderedDict() d2['c'] = 'C' d2['b'] = 'B' d2['a'] = 'A' print(d1 == d2)
运行效果
dict : True
OrderedDict: False
总结:
有序字典,比较对象是否相等,还要判断排序的顺序
30、排序字典元素对象的移动
import collections d = collections.OrderedDict( [('a', 'A'), ('b', 'B'), ('c', 'C')] ) print('Before:') for k, v in d.items(): print(k, v) d.move_to_end('b') print('\nmove_to_end():') for k, v in d.items(): print(k, v) d.move_to_end('b', last=False) print('\nmove_to_end(last=False):') for k, v in d.items(): print(k, v)
运行效果
Before: a A b B c C move_to_end(): a A c C b B move_to_end(last=False): b B a A c C
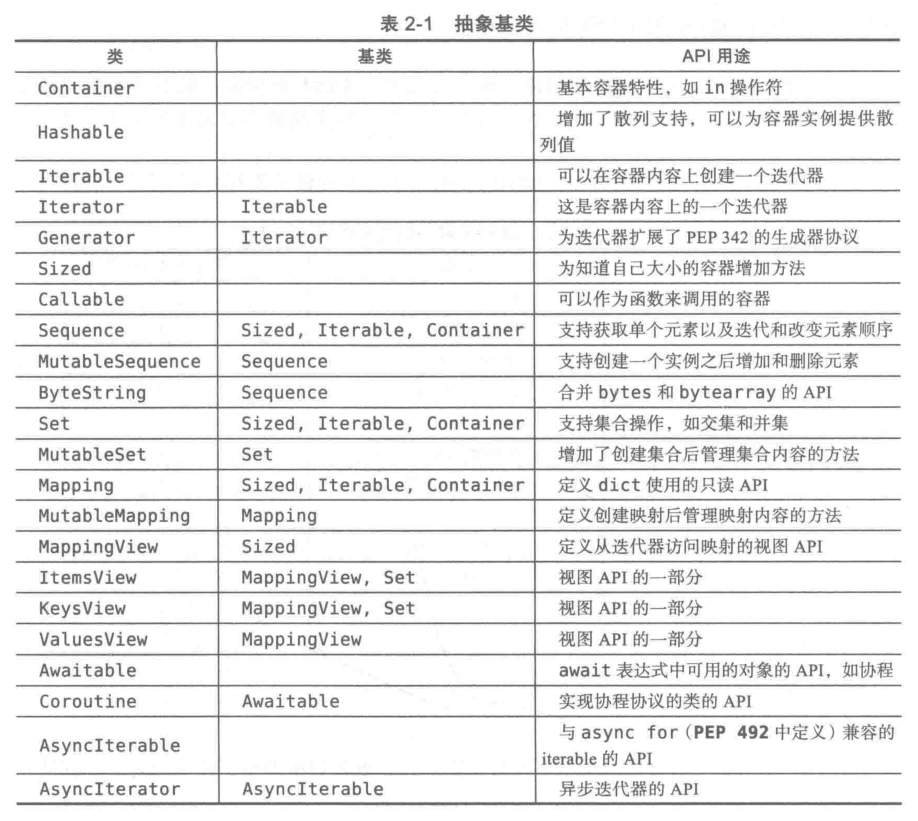
七、容器的抽象基类(collections.abc)
作用:
该collections.abc模块包含抽象基类,这些基类定义了Python内置并由collections模块提供的容器数据结构的API 。有关类别及其用途的列表,请参见下表。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号