


Python爬虫——request实例:爬取网易云音乐华语男歌手top10歌曲
requests是python的一个HTTP客户端库,跟urllib,urllib2类似,但比那两个要简洁的多,至于request库的用法,
推荐一篇不错的博文:https://cuiqingcai.com/2556.html
话不多说,先说准备工作:
1,下载需要的库:request,BeautifulSoup( 解析html和xml字符串),xlwt(将爬取到的数据存入Excel表中)
2,至于BeautifulSoup 解析html方法,推荐一篇博文:http://blog.csdn.net/u013372487/article/details/51734047
3,re库,我们要用正则表达式来筛选爬取到的内容
好的,开始爬:
首先我们找到网易云音乐华语男歌手页面入口的URL:url = 'http://music.163.com/discover/artist/cat?id=1001'
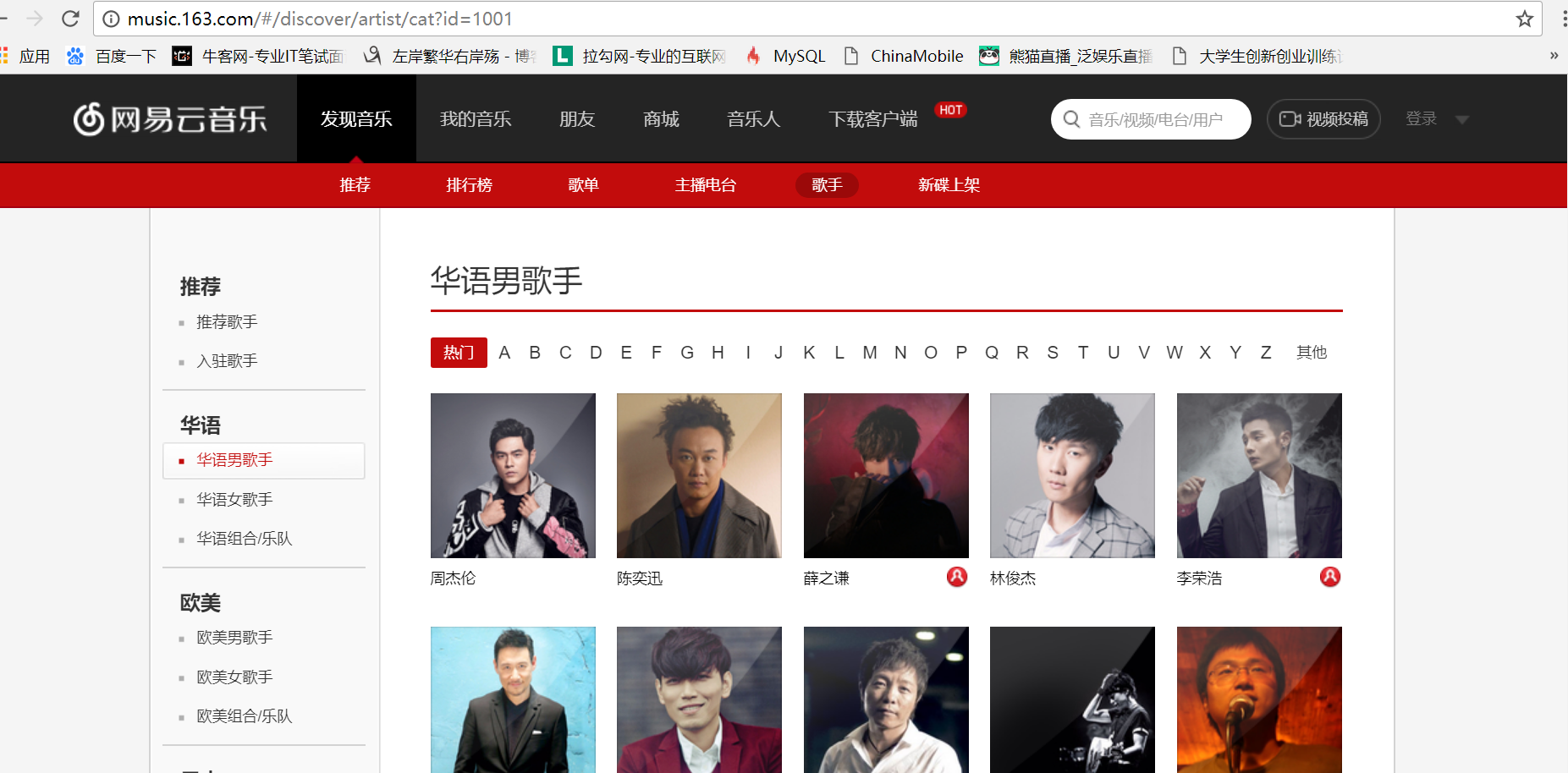
把整个网页爬取下来: html= requests.get(url).text
soup = BeautifulSoup(html,'html.parser'
我们要找到进入top10歌手页面的url,用浏览器的开发者工具,我们发现歌手的信息
都在<div class="u-cover u-cover-5">......</div>这个标签里面,如图:
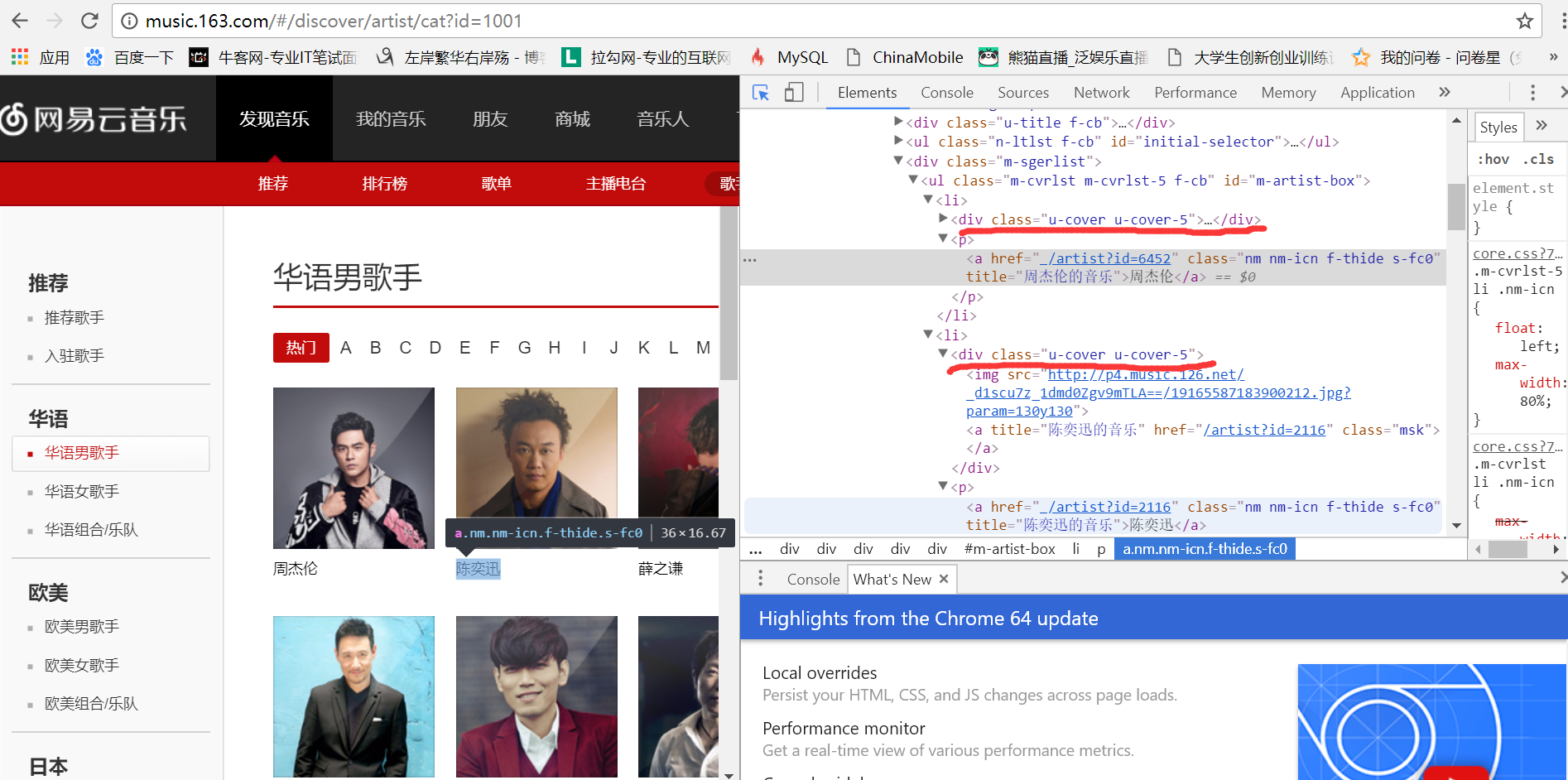
于是,我们把top10歌手的信息筛选出来:
top_10 = soup.find_all('div',attrs = {'class':'u-cover u-cover-5'})
singers = []
for i in top_10:
singers.append(re.findall(r'.*?<a class="msk" href="(/artist\?id=\d+)" title="(.*?)的音乐"></a>.*?',str(i))[0])
获取到歌手的信息后,依次进入歌手的界面,把他们的热门歌曲爬取并写入Excel表中,原理同上
附上完整代码:


1 import xlwt 2 import requests 3 from bs4 import BeautifulSoup 4 import re 5 6 url = 'http://music.163.com/discover/artist/cat?id=1001'#华语男歌手页面 7 r = requests.get(url) 8 r.raise_for_status() 9 r.encoding = r.apparent_encoding 10 html=r.text #获取整个网页 11 12 soup = BeautifulSoup(html,'html.parser') # 13 top_10 = soup.find_all('div',attrs = {'class':'u-cover u-cover-5'}) 14 #print(top_10) 15 16 singers = [] 17 for i in top_10: 18 singers.append(re.findall(r'.*?<a class="msk" href="(/artist\?id=\d+)" title="(.*?)的音乐"></a>.*?',str(i))[0]) 19 #print(singers) 20 21 url = 'http://music.163.com' 22 for singer in singers: 23 try: 24 new_url = url + str(singer[0]) 25 #print(new_url) 26 songs=requests.get(new_url).text 27 soup = BeautifulSoup(songs,'html.parser') 28 Info = soup.find_all('textarea',attrs = {'style':'display:none;'})[0] 29 songs_url_and_name = soup.find_all('ul',attrs = {'class':'f-hide'})[0] 30 #print(songs_url_and_name) 31 datas = [] 32 data1 = re.findall(r'"album".*?"name":"(.*?)".*?',str(Info.text)) 33 data2 = re.findall(r'.*?<li><a href="(/song\?id=\d+)">(.*?)</a></li>.*?',str(songs_url_and_name)) 34 35 for i in range(len(data2)): 36 datas.append([data2[i][1],data1[i],'http://music.163.com/#'+ str(data2[i][0])]) 37 #print(datas) 38 book = xlwt.Workbook() 39 sheet1=book.add_sheet('sheet1',cell_overwrite_ok = True) 40 sheet1.col(0).width = (25*256) 41 sheet1.col(1).width = (30*256) 42 sheet1.col(2).width = (40*256) 43 heads=['歌曲名称','专辑','歌曲链接'] 44 count=0 45 46 for head in heads: 47 sheet1.write(0,count,head) 48 count+=1 49 50 i=1 51 for data in datas: 52 j=0 53 for k in data: 54 sheet1.write(i,j,k) 55 j+=1 56 i+=1 57 book.save(str(singer[1])+'.xls')#括号里写存入的地址 58 59 except: 60 continue

