
Java的JVM的内存可以分为3个区:堆(heap)、栈(stack)和静态区(method)。
一、Java内存区域概念
堆区:堆主要存放Java在运行过程中new出来的对象和数组以及对象的实例变量,凡是通过new生成的对象都存放在堆中,jvm只有一个堆区被所有线程共享,对于堆中的对象生命周期的管理由Java虚拟机的垃圾回收机制GC进行回收和统一管理。
栈区:栈主要存放在运行期间用到的一些局部变量(基本数据类型的变量)或者是指向其他对象的一些引用,当一段代码或者一个方法调用完毕后,栈中为这段代码所提供的基本数据类型或者对象的引用立即被释放;另外需注意的是栈中存放变量的值是可以共享的,优先在栈中寻找是否有相同变量的值,如果有直接指向这个值,如果没有则另外分配。每个线程包含一个栈区,每个栈中的数据都是私有的,其他栈不能访问。
静态区:存放类中以static声明的静态成员变量
方法区:主要存放一些代码段以供类调用的时候所共用。
常量区:存放字符串常量和基本类型常量(public static final),
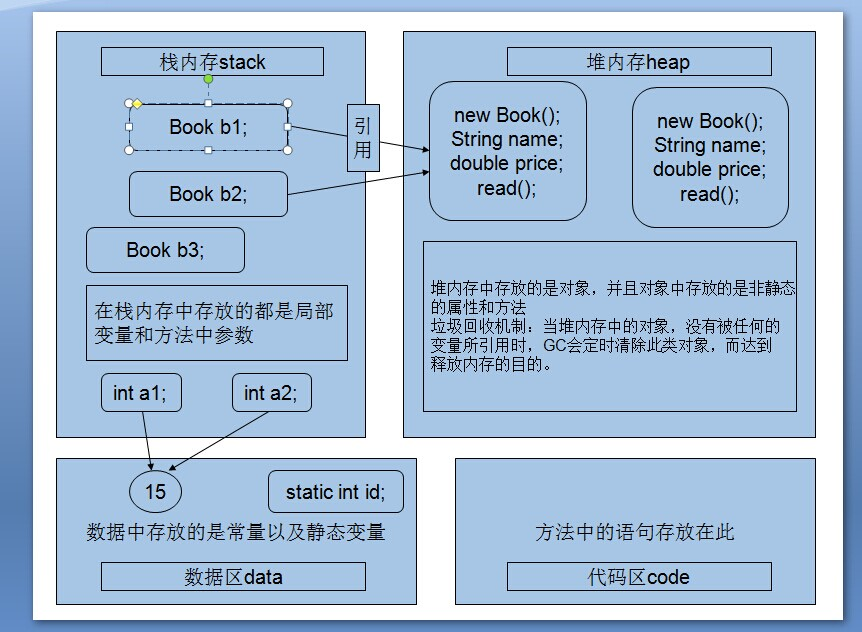
堆和栈的区别
- 栈(stack)与堆(heap)都是Java用来在Ram中存放数据的地方。Java自动管理栈和堆,程序员不能直接地设置栈或堆。
- 栈中存放局部变量(基本类型的变量)和对象的引用。栈的优势是,存取速度比堆要快,仅次于寄存器,栈数据可以共享。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。栈是跟随线程的,有线程就有栈。
- 堆中存放对象,包括对象变量以及对象方法。堆的优势是可以动态地分配内存大小,生存期也不必事先告诉编译器,Java的垃圾收集器会自动收走这些不再使用的数据。但缺点是,由于要在运行时动态分配内存,存取速度较慢。堆是跟随JVM的,有JVM就有堆内存。
为什么把堆和栈区分出来
- 从软件设计的角度上来看,栈代表了处理逻辑,而堆代表了数据。这样分开,使得处理逻辑更为清晰。分而治之的思想。这种隔离、模块化的思想在软件设计的方方面面都有体现;
- 堆与栈的分离,使得堆中的内容可以被多个栈共享(也可以理解为多个线程访问同一个对象)。这种共享的收益是很多的。一方面这种共享提供了一种有效的数据交互方式(如:共享内存),另一方面,堆中的共享常量和缓存可以被所有栈访问,节省了空间;
- 栈因为运行时的需要,比如保存系统运行的上下文,需要进行地址段的划分。由于栈只能向上增长,因此就会限制住栈存储内容的能力。而堆不同,堆中的对象是可以根据需要动态增长的,因此栈和堆的拆分,使得动态增长成为可能,相应栈中只需记录堆中的一个地址即可;
- 面向对象就是堆和栈的完美结合。其实,面向对象方式的程序与以前结构化的程序在执行上没有任何区别。但是,面向对象的引入,使得对待问题的思考方式发生了改变,而更接近于自然方式的思考。当我们把对象拆开,你会发现,对象的属性其实就是数据,存放在堆中;而对象的行为(方法),就是运行逻辑,放在栈中。我们在编写对象的时候,其实即编写了数据结构,也编写的处理数据的逻辑。
二、Java内存区域实例解析
/* Java内存存储机制 */ public class Ram { public static void main(String[] args) { String a = "a"; String tempa="a"; String b = "b"; String c = "c"; String abc = "abc"; String a_b_c = "a"+"b"+"c"; String a_b = a+b; String ab = "ab"; String newabc = new String("abc"); String abcintern = newabc.intern(); final String finalb = "b"; String a_b2 = "a"+finalb; System.out.println(tempa==a);//在栈中共享同一个值,共同指向常量池的字符串a System.out.println(newabc==abc);//newabc指向的是堆中的一个引用,abc是在位于栈中的string对象的一个引用变量,然后在常量池中寻找字符串abc System.out.println(a_b==ab);//a_b是在运行期字符串的引用,而ab则是在编译期间就指定了 /*a_b_c在编译期间就将常量字符串连接到一起,所以他们指向同一个字符串常量,而且"a"+"b"+"c", 首先a和b组装成一个常量ab放于常量池中,然后ab和c组装在一起放于常量池中,然后将abc的地址赋给了a_b_c, 由于String是不可变的,所以产生了很多临时变量。 */ System.out.println(a_b_c==abc); System.out.println(abcintern==abc);//调用intern()方法则将abc字符串放入了字符串常量池,返回值则是直接指向常量池中的字符串常量值所以相等 System.out.println(ab==a_b2);//finalb是因为声明为final修饰符它在编译时被解析为常量值的一个本地拷贝存储到自己的常量池中,相当于"a"+"b" } }

小结
- 分清什么是实例什么是对象。Class a= new Class();此时a叫实例,而不能说a是对象。实例在栈中,对象在堆中,操作实例实际上是通过实例的指针间接操作对象。多个实例可以指向同一个对象。
- 栈中的数据和堆中的数据销毁并不是同步的。方法一旦结束,栈中的局部变量立即销毁,但是堆中对象不一定销毁。因为可能有其他变量也指向了这个对象,直到栈中没有变量指向堆中的对象时,它才销毁,而且还不是马上销毁,要等垃圾回收扫描时才可以被销毁。
- 以上的栈、堆、代码段、数据段等等都是相对于应用程序而言的。每一个应用程序都对应唯一的一个JVM实例,每一个JVM实例都有自己的内存区域,互不影响。并且这些内存区域是所有线程共享的。这里提到的栈和堆都是整体上的概念,这些堆栈还可以细分。
- 类的成员变量在不同对象中各不相同,都有自己的存储空间(成员变量在堆中的对象中)。而类的方法却是该类的所有对象共享的,只有一套,对象使用方法的时候方法才被压入栈,方法不使用则不占用内存。
三、内存相关知识点
Java是如何管理内存的
其中包括分配和释放两部分:
分配:内存的分配是由程序完成的,程序员需要通过关键字new为每个对象申请内存空间(基本类型除外),所有的对象都在堆(Heap)中分配空间。
释放:对象的释放是由垃圾回收机制决定和执行的,这样做确实简化了程序员的工作。但同时,它也加重了JVM的工作。因为,GC为了能够正确释放对象,GC必须监控每一个对象的运行状态,包括对象的申请、引用、被引用、赋值等,GC都需要进行监控。
Java的内存泄漏
在java中,内存泄漏就是存在一些被分配的对象,这些对象有下面两个特点,首先,这些对象是可达的,即在有向图中,存在通路可以与其相连(也就是说仍存在该内存对象的引用);其次,这些对象是无用的,即程序以后不会再使用这些对象。如果对象满足这两个条件,这些对象就可以判定为Java中的内存泄漏,这些对象不会被GC所回收,然而它却占用内存。
Java中数据在内存是如何存储的
1、基本数据类型
Java的基本类型数据有八种,分别为int、short、long、byte、float、double、boolean、char。这个类型的数据定义基本是通过int a = 1等这样的形式来定义的,这里 a 是一个指向 int 类型的引用,指向3这个字面值。这些字面值的数据,由于大小可知,生存期可知(这些字面值定义在某个程序块里面,程序块退出后,字段值就消失了),出于追求速度的原因,就存在于栈中。另外,栈有一个很重要的特性,就是存储在栈中的数据可共享。
2、对象
在Java中,创建一个对象包括对象的声明和实例化两部分,这里定义一个类
public class Rectangle { double width; double height; public Rectangle( double w, double h){ w = width; h = height; } }
- 声明对象时的内存模型:用Rectangle rect;声明一个对象rect时,将在栈内存为对象的引用变量rect分配内存空间,但Rectangle的值为空,这里称rect是一个空对象。空对象不能使用,因为它还没有引用任何实体
- 对象实例化时的内存模型:当执行rect=new Rectangle(3,5);时,会做两件事情,在堆内存中为类的成员变量width,height分配内存,并将其初始化为各数据类型的默认值;接着进行显式初始化;最后调用成员方法,为成员变量赋值。返回堆内存中对象的引用(相当于首地址)给引用变量rect,以后就可以通过rect来引用堆内存中的对象了。
3、创建多个不同的对象实例
一个类可以使用new运算符来创建多个不同的对象实例,这些对象实例在堆中被分配不同的内存空间,改变其中一个对象的状态不会影响其他对象的状态。
例如:Rectangle r1= new Rectangle(3,5); Rectangle r2= new Rectangle(4,6);此时,将在堆内存中分别为两个对象的成员变量分配内存空间,两个对象在堆内存中占据的空间是互不相同的。
例如:Rectangle r1=new Rectangle(3,5); Rectangle r2=r1; 此时,则在堆内存中创建了一个对象实例,在栈内存中创建了两个对象引用,两个对象引用指向同一个对象实例。
4、包装类
基本类型都有对应的包装类:如int对应Integer类,double对应Double类等,基本类型的定义都是直接在栈中,如果用包装类来创建对象,就和普通对象一样了。例如:int i=0;i直接存储在栈中。Integer i(i此时是对象)= new Integer(5);这样,i对象数据存储在堆中,i的引用存储在栈中,通过栈中的引用来操作对象。Integer i = 100类似Integer i = Integer.valueOf(100)的操作。
5、String
String是一个特殊的包装类数据。可以用以下两种方式创建:String str = new String(“abc”);String str = “abc”;
第一种创建方式,和普通对象的的创建过程一样;
第二种创建方式,java内部将此语句转化为以下几个步骤:(1)先定义一个名为str的对String类的对象引用变量:String str;(2)在栈中查找有没有存放值为”abc”的地址,如果没有,则开辟一个存放字面值为”abc”地址,接着创建一个新的String类的对象o,并将o的字符串值指向这个地址,而且在栈这个地址旁边记下这个引用的对象o。如果已经有了值为”abc”的地址,则查找对象o,并回o的地址。(3)将str指向对象o的地址。
6、数组
当定义一个数组,int x[];或int[] x;时,在栈内存中创建一个数组引用,通过该引用(即数组名)来引用数组。x=new int[3];将在堆内存中分配3个保存 int型数据的空间,堆内存的首地址放到栈内存中,每个数组元素被初始化为0。
7、静态变量
用static的修饰的变量和方法,实际上是指定了这些变量和方法在内存中的”固定位置”-static storage,可以理解为所有实例对象共有的内存空间。static变量有点类似于C中的全局变量的概念;静态表示的是内存的共享,就是它的每一个实例都指向同一个内存地址。把static拿来,就是告诉JVM它是静态的,它的引用(含间接引用)都是指向同一个位置,在那个地方,你把它改了,它就不会变成原样,你把它清理了,它就不会回来了。
那静态变量与方法是在什么时候初始化的呢?对于两种不同的类属性,static属性与instance属性,初始化的时机是不同的。instance属性在创建实例的时候初始化,static属性在类加载,也就是第一次用到这个类的时候初始化,对于后来的实例的创建,不再次进行初始化。
Java的内存管理实例
Java程序的多个部分(方法,变量,对象)驻留在内存中以下两个位置:即堆和栈,现在我们只关心三类事物:实例变量,局部变量和对象:实例变量和对象驻留在堆上,局部变量驻留在栈上。
垃圾回收机制
问题一:什么叫垃圾回收机制?
垃圾回收是一种动态存储管理技术,它自动地释放不再被程序引用的对象,按照特定的垃圾收集算法来实现资源自动回收的功能。当一个对象不再被引用的时候,内存回收它占领的空间,以便空间被后来的新对象使用,以免造成内存泄露。
问题二:java的垃圾回收有什么特点?
jAVA语言不允许程序员直接控制内存空间的使用。内存空间的分配和回收都是由JRE负责在后台自动进行的,尤其是无用内存空间的回收操作(garbagecollection,也称垃圾回收),只能由运行环境提供的一个超级线程进行监测和控制。
问题三:垃圾回收器什么时候会运行?
一般是在CPU空闲或空间不足时自动进行垃圾回收,而程序员无法精确控制垃圾回收的时机和顺序等。、
问题四:什么样的对象符合垃圾回收条件?
当没有任何获得线程能访问一个对象时,该对象就符合垃圾回收条件。
问题五:垃圾回收器是怎样工作的?
垃圾回收器如发现一个对象不能被任何活线程访问时,他将认为该对象符合删除条件,就将其加入回收队列,但不是立即销毁对象,何时销毁并释放内存是无法预知的。垃圾回收不能强制执行,然而java提供了一些方法(如:System.gc()方法),允许你请求JVM执行垃圾回收,而不是要求,虚拟机会尽其所能满足请求,但是不能保证JVM从内存中删除所有不用的对象。
问题六:一个java程序能够耗尽内存吗?
可以。垃圾收集系统尝试在对象不被使用时把他们从内存中删除。然而,如果保持太多活的对象,系统则可能会耗尽内存。垃圾回收器不能保证有足够的内存,只能保证可用内存尽可能的得到高效的管理。
问题七:如何显示的使对象符合垃圾回收条件?
(1)空引用:当对象没有对他可到达引用时,他就符合垃圾回收的条件。也就是说如果没有对他的引用,删除对象的引用就可以达到目的,因此我们可以把引用变量设置为null,来符合垃圾回收的条件。
- StringBuffer sb = new StringBuffer("hello");
- System.out.println(sb);
- sb= null;
(2)重新为引用变量赋值:可以通过设置引用变量引用另一个对象来解除该引用变量与一个对象间的引用关系。
StringBuffer sb1 = new StringBuffer(“hello”);
StringBuffer sb2 = new StringBuffer(“goodbye”);
System.out.println(sb1);
sb1=sb2;//此时”hello”符合回收条件
(3)方法内创建的对象:所创建的局部变量仅在该方法的作用期间内存在。一旦该方法返回,在这个方法内创建的对象就符合垃圾收集条件。有一种明显的例外情况,就是方法的返回对象。
- public static void main(String[] args) {
- Date d = getDate();
- System.out.println("d="+d);
- }
- private static Date getDate() {
- Date d2 = new Date();
- StringBuffer now = new StringBuffer(d2.toString());
- System.out.println(now);
- return d2;
- }
(4)隔离引用:这种情况中,被回收的对象仍具有引用,这种情况称作隔离岛。若存在这两个实例,他们互相引用,并且这两个对象的所有其他引用都删除,其他任何线程无法访问这两个对象中的任意一个。也可以符合垃圾回收条件。
- public class Island {
- Island i;
- public static void main(String[] args) {
- Island i2 = new Island();
- Island i3 = new Island();
- Island i4 = new Island();
- i2. i =i3;
- i3. i =i4;
- i4. i =i2;
- i2= null;
- i3= null;
- i4= null;
- }
- }
问题八:垃圾收集前进行清理——finalize()方法
java提供了一种机制,使你能够在对象刚要被垃圾回收之前运行一些代码。这段代码位于名为finalize()的方法内,所有类从Object类继承这个方法。由于不能保证垃圾回收器会删除某个对象。因此放在finalize()中的代码无法保证运行。因此建议不要重写finalize();
如何让程序变得更加健壮
1、尽早释放无用对象的引用。
好的办法是使用临时变量的时候,让引用变量在退出活动域后,自动设置为null,暗示垃圾收集器来收集该对象,防止发生内存泄露。对于仍然有指针指向的实例,jvm就不会回收该资源,因为垃圾回收会将值为null的对象作为垃圾,提高GC回收机制效率;
2、定义字符串应该尽量使用String str=”hello”;的形式,避免使用String str = new String(“hello”);的形式。因为要使用内容相同的字符串,不必每次都new一个String。
3、我们的程序里不可避免大量使用字符串处理,避免使用String,应大量使用StringBuffer,因为String被设计成不可变(immutable)类,所以它的所有对象都是不可变对象,
4、尽量少用静态变量,因为静态变量是全局的,GC不会回收的;
5、尽量避免在类的构造函数里创建、初始化大量的对象,防止在调用其自身类的构造器时造成不必要的内存资源浪费,尤其是大对象,JVM会突然需要大量内存,这时必然会触发GC优化系统内存环境;显示的声明数组空间,而且申请数量还极大。
6、尽量在合适的场景下使用对象池技术以提高系统性能,缩减缩减开销,但是要注意对象池的尺寸不宜过大,及时清除无效对象释放内存资源,综合考虑应用运行环境的内存资源限制,避免过高估计运行环境所提供内存资源的数量。
7、大集合对象拥有大数据量的业务对象的时候,可以考虑分块进行处理,然后解决一块释放一块的策略。
8、不要在经常调用的方法中创建对象,尤其是忌讳在循环中创建对象。可以适当的使用hashtable,vector创建一组对象容器,然后从容器中去取那些对象,而不用每次new之后又丢弃。
9、一般都是发生在开启大型文件或跟数据库一次拿了太多的数据,造成Out Of Memory Error的状况,这时就大概要计算一下数据量的最大值是多少,并且设定所需最小及最大的内存空间值。
10、尽量少用finalize函数,因为finalize()会加大GC的工作量,而GC相当于耗费系统的计算能力。
11、不要过滥使用哈希表,有一定开发经验的开发人员经常会使用hash表(hash表在JDK中的一个实现就是HashMap)来缓存一些数据,从而提高系统的运行速度。比如使用HashMap缓存一些物料信息、人员信息等基础资料,这在提高系统速度的同时也加大了系统的内存占用,特别是当缓存的资料比较多的时候。其实我们可以使用操作系统中的缓存的概念来解决这个问题,也就是给被缓存的分配一个一定大小的缓存容器,按照一定的算法淘汰不需要继续缓存的对象,这样一方面会因为进行了对象缓存而提高了系统的运行效率,同时由于缓存容器不是无限制扩大,从而也减少了系统的内存占用。现在有很多开源的缓存实现项目,比如ehcache、oscache等,这些项目都实现了FIFO 、MRU等常见的缓存算法。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号