SpringDataJpa使用原生sql
1. jpa中的count小坑
在SpringDataJpa中repository层的@Query注解内写原生sql,如果有传入Pageable分页查询,即分页数据的pageSize大于原生sql查询出的数据,程序会正常运行,因为此时一页就可以包含所有的数据,不需要使用分页。但是一旦pageSize小于等于数据库内的数据,此时一页就装不小所有的数据,jpa就会执行一条count数据,但此时使用的是原生sql,jpa就无法识别,因为其底层使用的是对象的方式。
错误信息回显:

原生sql分页查询出现的问题信息
这个问题可能是jpa底层未进行很好的封装,添加了nativeQuery =true应该就应该在分页查询的时候也依旧使用原生sql,而不应该采用jpa封装好的分页查询数据。
所以此时就需要告诉jpa,分页查询数据的时候,依旧使用原生sql,有两种方式注解内添加countProjection和countQuery,推荐使用countProjection,因为countQuery会重新使用一条sql,这样会导致整个注解内的sql语句太多了。
我贴两张解决方案图:
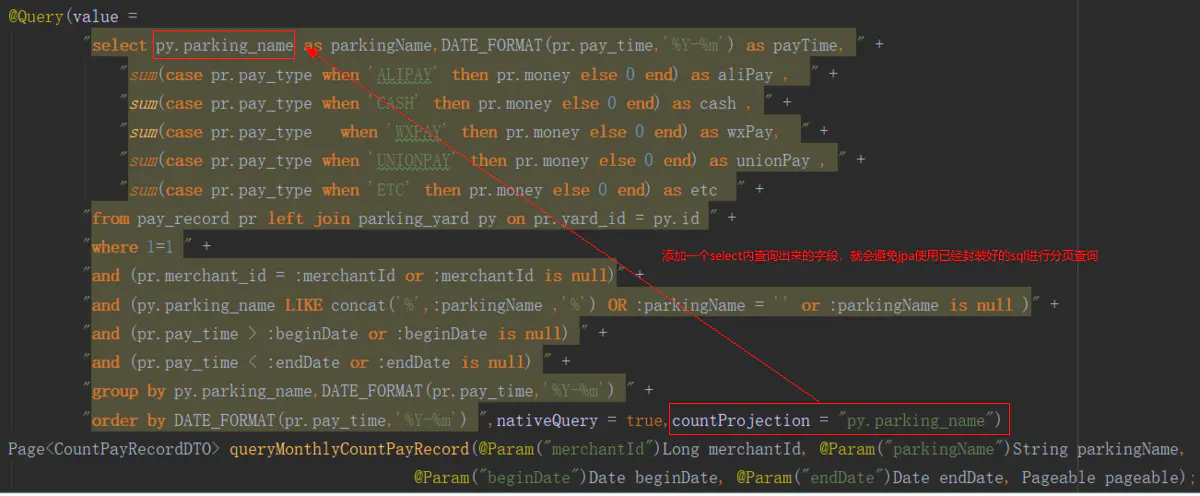
countProjection解决方案
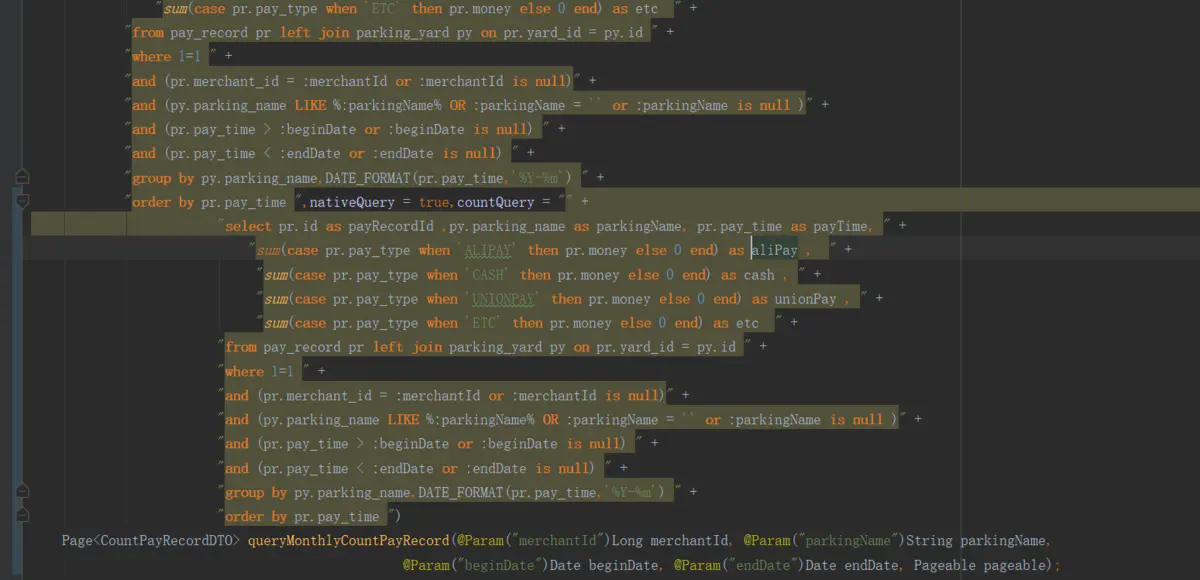
countQuery解决方案
2. jpa中的like模糊查询
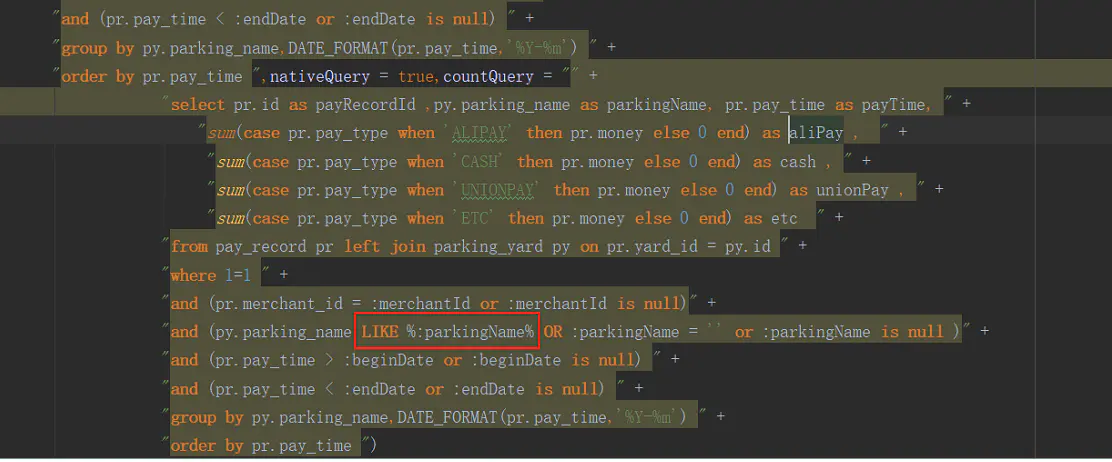
在jpa中使用原生sql,进行模糊查询的时候,需要拼接"%",否则jpa无法识别,无法进行like模糊查询。
错误做法:
like模糊查询错误做法
正确做法:有两种方法sql内使用concat拼接、业务层拼接,concat拼接会导致代码的移植性低,业务层拼接字符串会使代码不美观。
使用mysql的concat区

业务层拼接

 浙公网安备 33010602011771号
浙公网安备 33010602011771号