工作中常用的相似度算法以及特征提取算法
转:https://bbs.pediy.com/thread-266939.htm
目录:
一、概述。
二、基于可变长度特征的相似度。
1、两个字符串之间的相似度(最短编辑距离)。
2、从样本到变长特征。
(1) 强弱hash模型。
(2) 关键字密度模型。
三、基于固定长度特征的相似度。
1、修改的K-means算法。
2、从样本到定长特征。
(1) 基于数据频度的量化。
(2) 基于图片压缩的算法。
四、总结。
五、引用。
一、概述
在日常工作中,病毒分析师经常被要求在样本库里查找相似样本。比如在获得某APT组织的样本的情景下,希望查找其历史版本来确定组织的活动时间,从而追踪溯源,也希望查找样本的变种,来看一下恶意样本的影响范围。类似的工作往往会交给样本分析师(写样本分析报告的人)。样本分析师有很大概率根本就不知道怎么查找历史样本,也不知道怎么查找变种。归根结底,这是相似样本查找问题。希望本文可以抛砖引玉,让每个样本分析相关从业人员,都能够拥有自己的相似样本查找工具。
通过长期的工作总结,发现恶意样本的特征可分为两类,一类是可变长度的特征,一类是固定长度的特征。本教程会以这两条主线为线索,分别介绍两种相似度算法,四种提取特征算法。
二、基于可变长度特征的相似度
变长特征是指,从样本中提取的特征序列长度不固定。也就是说,应用此类算法,从每一类样本提取的特征序列长度都不相同。我们要针对不同长度的两个特征序列进行相似度比对。
在实际生活中,我们一眼能认出两个长短不一的字符串是不是相似的,如(【abcdefg、abcde】、【abcdrfg、qwertyui】),第一组相似性要比第二组相似性高一些。这两组字符串就可看作可变长度的特征序列。相比较的每一组字符串,都不强制要求长度相等。
1、两个字符串之间的相似度(最短编辑距离)
我们先抛开从样本生成特征的问题,先假设我们有两个样本(A、B),样本A生成了特征序列abcd,样本B生成了特征序列acd。这样我们就把两个样本相似度的问题,转化成了两个字符串之间相似度的问题。作为智能生物,我们很轻易的就能识别处两个复杂字符串所具有相似性。但是一旦把工作交给计算机,那么就需要算法来辅助了,而且字符串越复杂则计算过程越复杂。
为了解决这个复杂的问题,在1965年,俄罗斯数学家Vladimir Levenshtein提出了字符串的编辑距离,又称为Levenshtein距离[1]。编辑距离越小,则两个字符串的相似度越高。
对一个字符串一共有三种【字符操作】:插入一个字符、删除一个字符、替换一个字符。编辑距离指的是,从A字符串转换成B字符串的过程中,要发生多少次【字符操作】。
例如:
(abcde -> abcdf),如果abcde想要变成abcdf,则需要把字符串中的e替换成f。总计进行过一次【字符操作】,所以编辑距离是1。
(abcde -> hijkl),如果abcde想要变成hijkl,则需要替换hijkl中的全部字符。总计进行5次替换,所以编辑距离是5。
从相似性上来讲,由于(abcde -> abcdf)的最小编辑距离是1,而(abcde -> hijkl)的最小编辑距离是5,又由于1<5,所以【abcde、abcdf的相似性】比【abcde、hijkl的相似性】更高一些。上述就是计算机使用最小编辑距离算法理解相似性的过程。
接下来进入具体的算法环节:
严谨公式[2]:
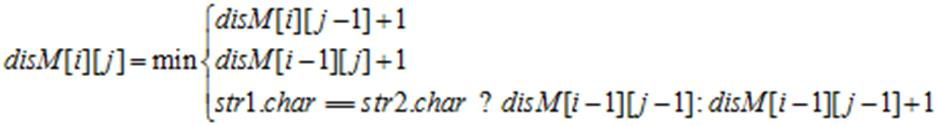
为了弄明白这个公式我们需要,做一个小游戏。
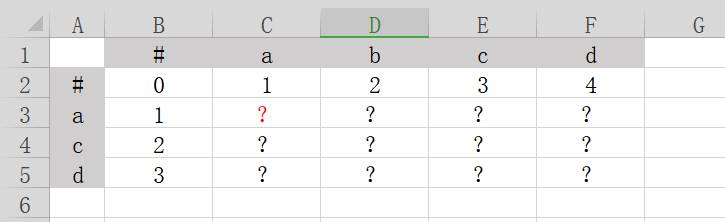
在上图的表格中,横列坐标是字符串abcd,纵列坐标是字符串acd。我们需要在标有问号的区域填写数字,把整张表填满。填表规则如下:
对于每一个问号(?)
1、取(?)所在格子向上一个格子的数值x,把数值x加1,记作(x+1)。
2、取(?)所在格子向左一个格子的数值y,把数值y加1,记作(y+1)。
3、取(?)所在格子向左上一个格子的数值z。比较上图中,格子所对应的,灰色区域中的字符是否相等。如相等,则不需要任何操作,记作z。如不相等,则把数值z加1,记作z+1。整体记作(z|z+1)。
4、比较(x+1)、(y+1)、(z|z+1)这三个数值,取三者中最小的,填入(?)。
例子:
比如要填写上图中红色问号的数值,需要:
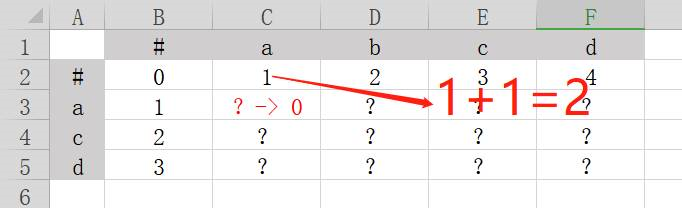
取红色问号向上一个格子数值x,x为1,所以(x+1)=2。
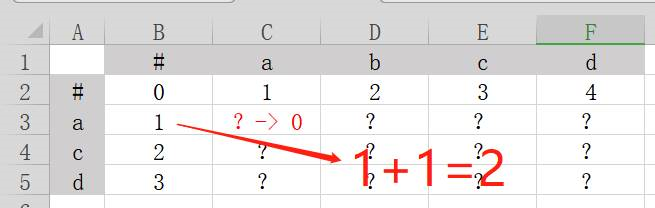
红色问号向左一个格子y为1,所以(y+1)=2。
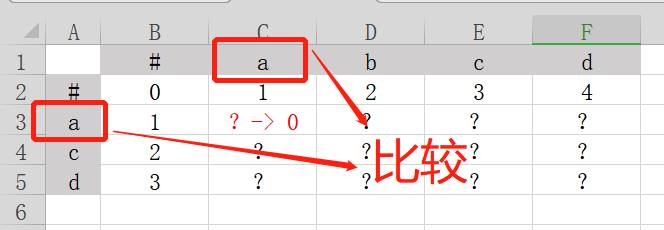
红色问号向左上一个格子z为0,所以z=0、z+1=1。又由于格子所对应的灰色区域中的字符相等,都为a,对应游戏规则第3条,所以(z|z+1)取z,所以(z|z+1)=0。
比较(x+1)=2、(y+1)=2、(z|z+1)=0。发现(z|z+1)=0数值最小,所以红色问号取0。
以此类推,我们把所有的问号都填满,如下图所示:
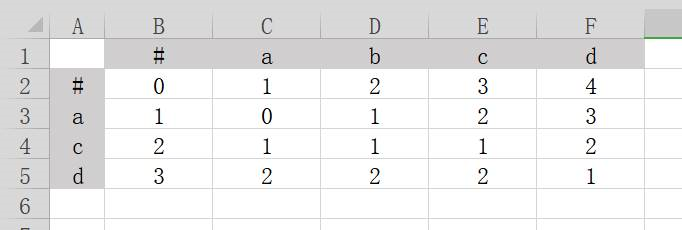
然后我们依照上图再做一个游戏,游戏规则是从坐标(0,0)开始,向右、向下,向右下,找寻这三个格子中的最小数值,并把它标红。如下图所示。
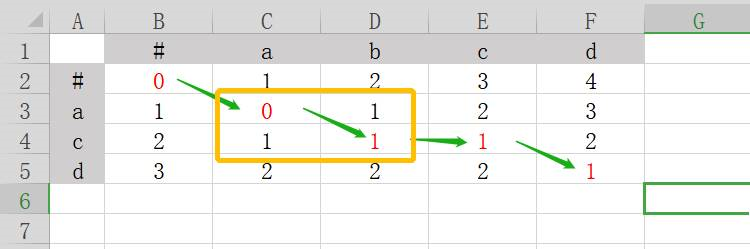
如上图所示,绿色的箭头就是其最短的编辑路径了。这点先放下一会再说。
我们先看被黄框框起来的部分,当按照【右、下、右下,三个格子中的最小数值】的规则进行到黄框中0的格子的时候,会发现右、下、右下这三个格子中都是1,貌似走哪个方向都可以,我们该如何选择呢?此时就需要动态权重登场了,在实际工作中,我们需要根据样本的特征来动态优化这个权重,在本例就直接规定右下的权重最高就可以了。
再回过头来看绿色的箭头,绿色的箭头为最短编辑路径,其作用如下[2]:
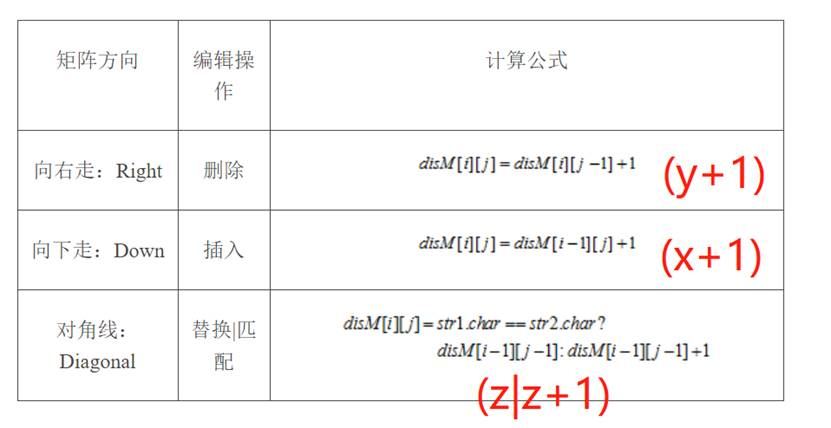
上图不仅说明了绿色箭头的作用,还说明了计算公式与游戏规则的对应关系。一切如图中所示,第一条公式对应着游戏第二条规则,第二条公式对应着游戏第一条规则,第三条公式对应着游戏第三条规则。所以整个公式就是用数学语言来描述的整个游戏规则。
我们按照表格图片中的【编辑操作】这一列,来操作一下:对于横列abcd字符串来说,忽略#字符,第一个字符a箭头是右下的,且与竖列的acd第一个字符串匹配,所以不做任何操作,此时总操作数为0。对于横列abcd字符串来说,第二个字符b箭头是向右的,意味着删除操作,所以对于横列abcd这个字符串来说需要把b这一个字符删除,此时总操作数自加1。以此类推,计算所有字符后,发现想把abcd变成acd,总操作数为1。由于abcd这4个字符一共有4次操作机会,但是只有一次实际操作过,所以abcd与acd的差异度为1/4,相似度则为1-1/4=75%。
2、从样本到变长特征。
有了求相似度的算法,还必须要有特征序列(向量)才行。我们当然可以把整个样本文件的数据当成特征序列来使用,但是会遇到几个问题:1、整个文件过于庞大,不利于存储。2、上述求相似度算法是和笛卡尔积具有相同复杂性的算法,所以如果把整个文件作为特征序列,计算过程将会变得十分缓慢。为了解决上述问题,我们需要对样本文件进行特征抽取。
(1) 强弱hash模型。
用弱hash对文件进行数据块提取,用强hash对数据块进行hash计算,得到特征元。
弱hash在本例采用Adler32算法。Adler32算法有一个很好的特性,就是可以快速的增加和裁剪数据,这样可以减少计算量,使整个模型更高效。比如我已经有了0到16这个区间段的Adler32 Hash,命名为A。我现在想计算0到17这个区间的Adler32 Hash,此时我只需要把第17位数据“加”到A的后面就好了,而不用重新计算0到17这个区间的数据,由于具有上述特性,所以adler算法又被称为滚动算法[3]。
强hash随意采用即可,本例中使用RSHash算法做演示。
通常在实际工作中,我们采用自己的一套算法来代替强弱hash算法。强弱hash会无差别对待数据,这样就失去了很多特异性。所以实际工作中,还需要自己编写专用的特征元生成算法,但是作为原理性解释,RSHash和Adler32算法足够了。
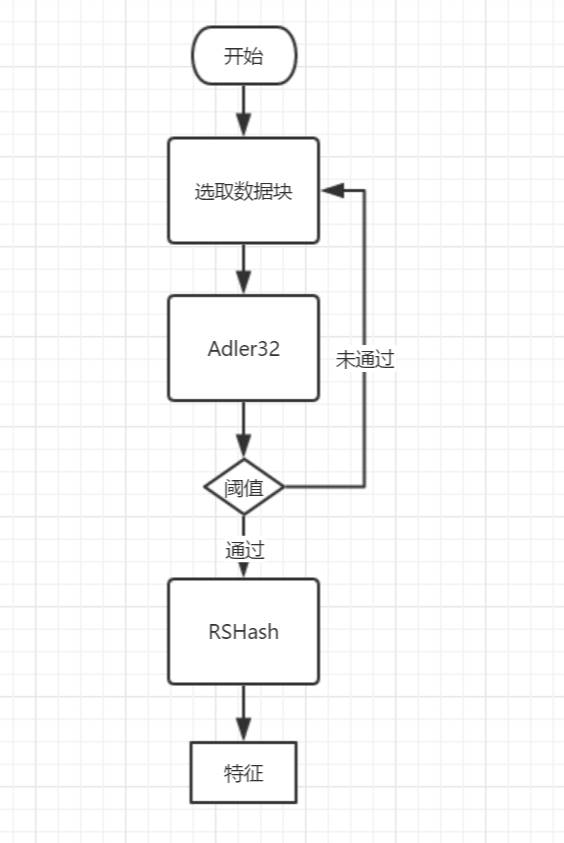
整个强弱hash模型流程如上图所示:
1、首先从起始地址0开始,取长度为len的数据块,命名为A0。
2、使用Adler32来计算A0的弱hash值。
3、然后我们定义一个阈值k,判断弱hash值是否满足阈值k。
① 当弱hash满足阈值k的时候。
对整个A0数据块进行RSHash运算,得到强hash,把这个强hash记录下来,作为整个特征序列的一个单位特征。
② 当弱hash不满足阈值k的时候。
重新选取数据块:以A0数据块起始地址+1为新起始点,长度为len不变,让A0=新数据块,然后重新进行步骤2,直到弱hash满足阈值k为止。
我们来简单介绍一下Adler32算法[3]:

上图为整个Adler32算法的计算步骤,图中D为具体的原始输入数据,n为数据的长度。
Adler32算法一共计算了两个值(A、B)。
A只是简单的将数据D的每一字节进行累加。
B则可以分成两步看:第一步计算D中每一个元素的tmp值,tmp =(D中的单个元素*(总长度n - 单个元素在D中序号)),第二步,把每一个元素的tmp相加。
然后再把A和B值拼接起来,就成了Adler32 Hash。
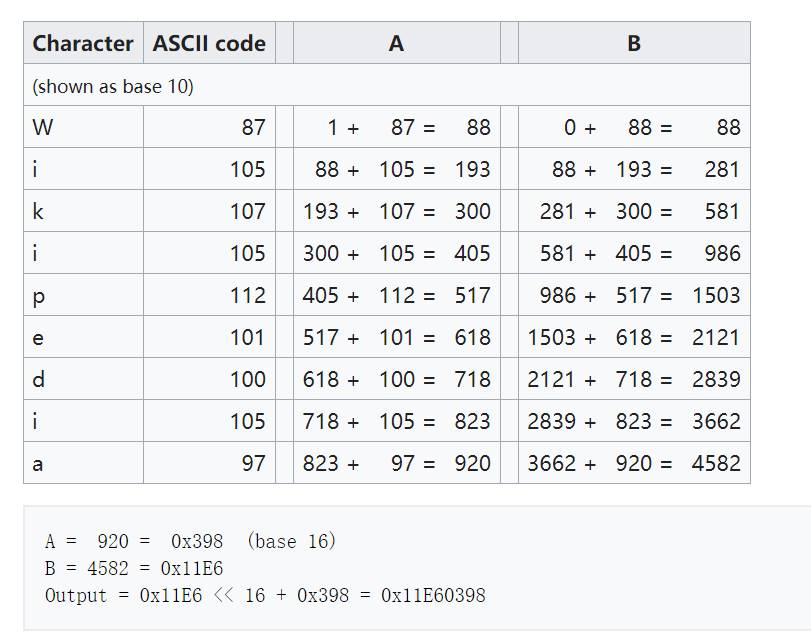
上图是把Wikipedia字符串计算成Adler32 Hash的计算过程。
使用Adler32有个好处,比如我想在字符串Wikipedia基础上计算ikipediaX,我们看到新的字符串在Wikipedia字符串的基础上,开头去掉了W,结尾加上了X。所以计算ikipediaX的Adler32 Hash,我们只需要:
1、在A上减去W的ascii,A = A - 87 = 833.
2、在B上减去(len - offset)倍的W的ascii。其中W的偏移为0,Wikipedia字符串长度为9,所以 B = B - (9 - 0)*87 = 3799
3、在A上加X的ascii,A = A + 88 = 921
4、在B上加上A,B = B + A = 4720
5、在把A和B拼接到一起,就完成了ikipediaX的Adler32 Hash计算。
有了Adler32算法,我们就可以快速的对样本进行滚动运算,然后根据每轮计算的结果,来确定是否要进行RSHash强Hash计算。
比如假设一个样本为:【ABCDEFGHIJKLMNOPQRSTUVWXYZ】
我定义要以(起始地址为0、数据长度为4)来计算Adler32 Hash,然后根据每一轮滚动运算的结果,来判断是否需要进行RSHash计算:
第一轮:【ABCD---------------------------------------】Adler32 不符合阈值,不计算RSHash
第二轮:【--BCDE--------------------------------------】Adler32符合阈值,计算RSHash
第三轮:【----CDEF------------------------------------】Adler32符合阈值,计算RSHash
第四轮:【------DEFG----------------------------------】Adler32不符合阈值,不计算RSHash
第五轮:.........
在每一轮计算Adler32 Hash后都会与阈值相比对,如果符合阈值,则计算RSHash,把RSHash的计算结果当作特征元,存入特征序列。
比如在第二轮,我计算【--BCDE--------------------------------------】的Adler32 Hash大于阈值0x6666666,
那么我将对【--BCDE--------------------------------------】进行RSHash运算。然后把每一个RSHash运算的结果拼接起来,组合成一个特征序列,这个特征序列就是【变长特征】序列。
RSHash hash是一个简单的强hash算法,其python实现如下:

如上图所示,RSHash是一个不可逆运算的简单hash算法,没什么可说的。
(2) 关键字密度模型。
关键字密度模型,是指根据统计关键字分布来划分区域,进行RSHash计算,获得特征序列的模型。上文提到,在我们在工作中会编写自己的算法,来替代(Adler32+阈值)算法给样本数据切块。重多替代算法中,关键字密度算法最为有代表性。
算法是一个程序的灵魂。在人工手动对样本提取特征的时候,我们经常会把一些特征点取在程序的算法上。如果能做到对文件切块的时候,正好把算法块切出来就好了。为了达到这个目的,我们需要先了解算法块与其他数据块的区别。
以Windows 64位为例:
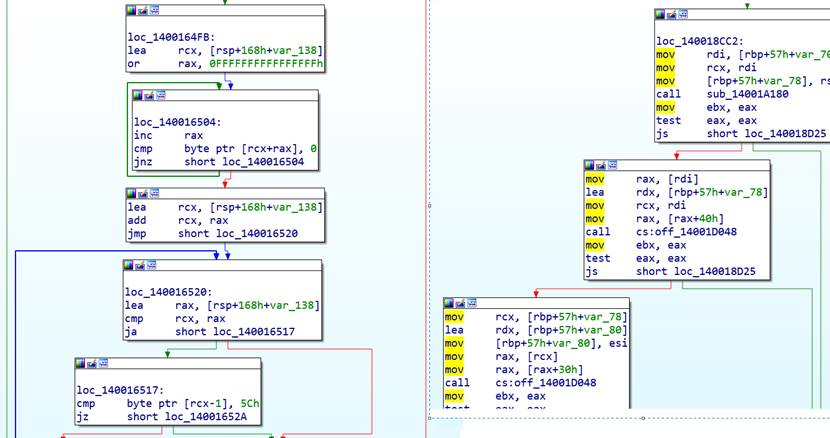 图片中,左侧为算法代码,右侧为正常的流程代码。我们会发现计算类型的指令(如add、inc、or..)在算法代码块中出现的频率,要远远高于在流程代码块中的频率。所以我们只要统计计算类型的指令密度,就能就能知道算法块的区域。
图片中,左侧为算法代码,右侧为正常的流程代码。我们会发现计算类型的指令(如add、inc、or..)在算法代码块中出现的频率,要远远高于在流程代码块中的频率。所以我们只要统计计算类型的指令密度,就能就能知道算法块的区域。
为了得到计算类型的指令密度,先假设计算类型的指令为2、3、4,其他类型的程序指令为1。我们看一个指令序列(数组):
A:(1、1、1、2、3、1、1、1、1、1、1、1、4、1、1、1)
我们需要对上面的指令序列做一些转换,转换规则如下:
1、定义一个与A数组同长度的,但是内容全部为0的序列B
B:(0、0、0、0、0、0、0、0、0、0、0、0、0、0、0、0)
2、在数组A中,对A中每一个位置上的数据进行比对,发现其为(2、3、4)的时候,则在B中相同的位置上+3,与这个位置相邻1的位置+2,与这个位置相邻2的位置+1。B:(0、+1、+2、+3、+2、+1、0、0、0、0、0、0、0、0、0、0)
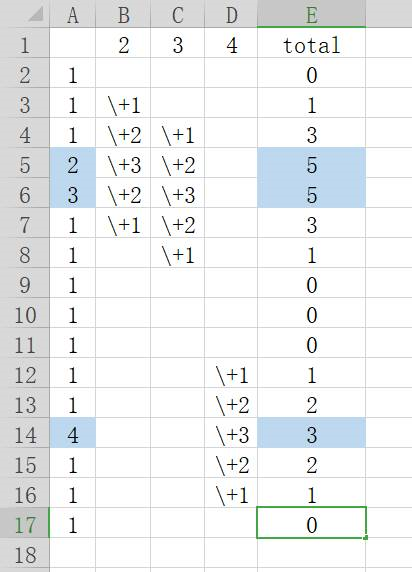
整个过程如上图所示,最后B被修改为:
(0、1、3、5、5、3、1、0、0、0、1、2、3、2、1、0)
这样我们就得到了一组加权数据,在B数据中连续的非0区间,就是对应着原数据A的计算指令区间。在区间中,最大值(和平均值)越大,则区间中计算指令越集中。明显,B数组中,蓝色区间的最大值5要比浅绿色区间的最大值3要大,所以蓝色区间的计算指令更集中,这也符合我们的直觉。
需要注意的是,在实际操作中,我们利用此算法会得到很多的非代码空间数据:
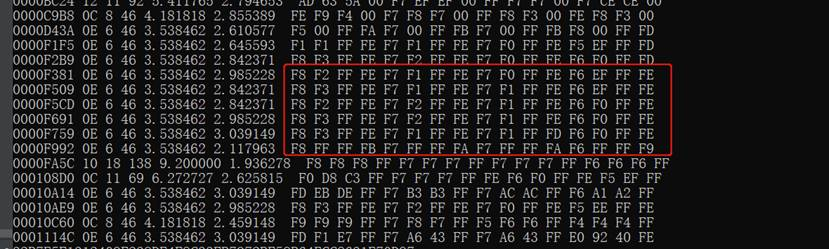
这将极大的影响准确性,有两个方法可以把他们过滤出去,一个是解析PE结构,只保留数据中的代码段。
另一个比较取巧的方法则是使用信息熵来过滤。


我们都知道信息熵是来评估封闭系统的混乱程度的,信息熵越高则封闭系统中的数据越混乱。我们从图中可以看到,垃圾数据的重复性是非常高的,所以其信息熵应该是处于相对较低的数值。所以我们只需要把信息熵较低的部分过滤出去就行。相对的,信息熵较高的代码段被保存了下来,这意味着这段区间的代码复杂程度较高,我们通过观察,认为这样的代码更优秀,更适合作为特征来使用。
三、基于固定长度特征的相似度。
固定长度特征,是指从样本文件中提出来的特征,长度固定。这类特征通常便于存储,计算快速。适合快速过滤样本,节省查找相似文件的时间。
先忽略从样本到特征序列的过程,假设我们已经得到了三个定长特征序列:
A:(1、2、3、4、5)
B:(7、8、3、4、5)
C:(11、12、13、14、15)
为了确定A、B、C三者的关系(A和B更相似一些,还是A和C更相似一些),我们需要用到修改的K-means算法。
1、修改的K-means算法。
严谨数学公式[4]:
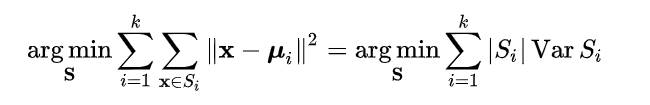
我们需要修改一下公式的定义,μ在原始定义里是平均值的意思,在本文中μ为一个给定的特征序列,比如例子里的序列A。如此做会让整个公式变得简单许多。如果想了解原始的K-means请阅读引用[4]。
修改后的公式很简单:
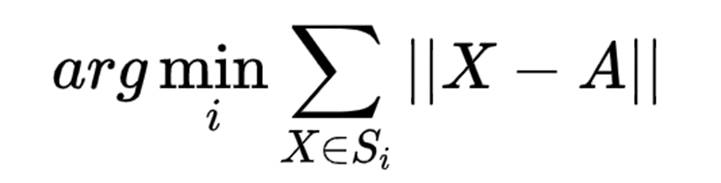
用我们的例子来解释公式:A为给定的一个特征序列,B和C为要参与计算的X序列。
1、我们需要用x序列中的每一位减去A中每一位。
2、然后把各位做减法的结果取平方后相加。
3、然后相加的结果再开方就是最终结果了。
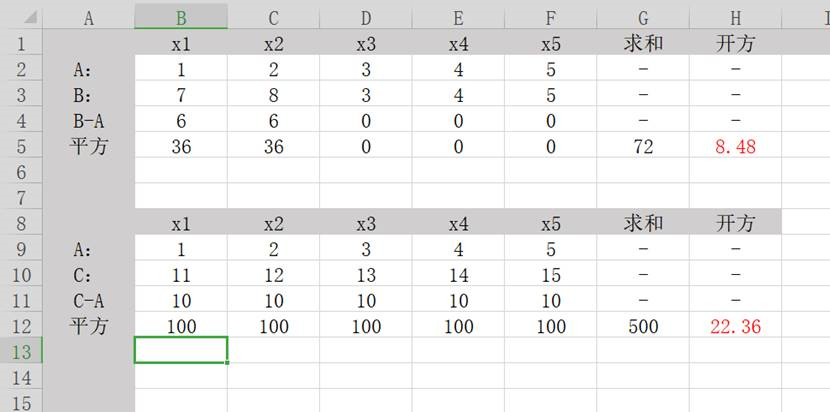
上图为整个计算经过,B与A的K-means为8.48,C与A的K-means为22.36。因为22.36 > 8.48,所以对于A来讲,B要比C更相似一些。这也符合我们的直觉。
在实际工作中,我们可以把这些K-means数值做一个从小到大的排序,K-means值越小的,说明两个样本越相似。我们可以按照自身需求,取top数据,比如取top 5000。
2、从样本到定长特征。
在这里介绍两个生成定长特征序列的算法,一个是基于频度的算法,另一个是基于图片压缩的算法。
基于频度的算法,是一个统计学算法,算法难度偏低。
基于图片压缩的算法,是基于矩阵特征分解和插补算法的压缩算法。涉及很多线性代数知识,所以这里只讲解他的python实现。感兴趣的同学可以搜索【矩阵特征】和【插补法】
(1) 基于数据频度的量化。
我们知道字节(byte)是计算机最小寻址单位,一个字节(byte)是8位(bit),所以一个字节存在着256种状态。数据频度统计,就是在统计这256种状态在样本中出现的频率。
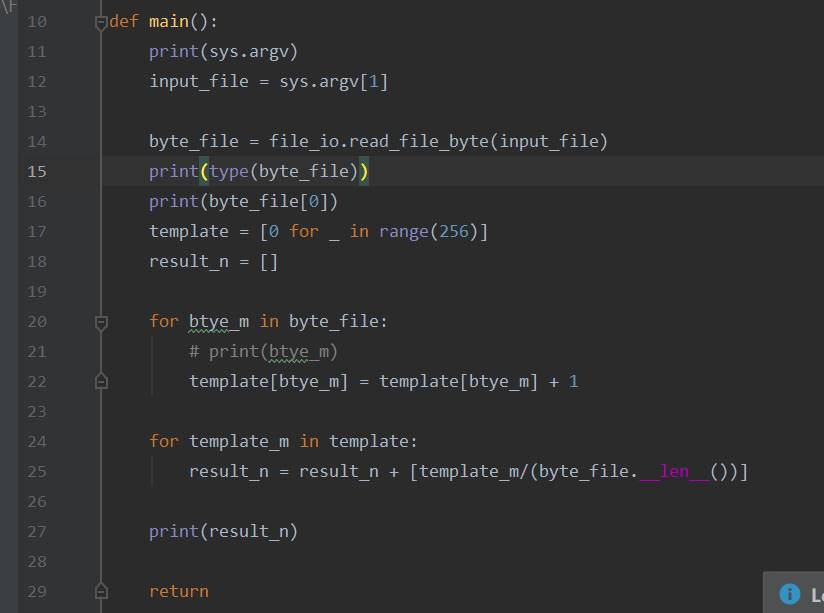
整个python代码如上图,图片中第一个for循环,是在对256个状态中的每个状态进行计数,比如样本文件中出现了66,就在template数组中66下标处累加1。第二个for循环是对template中的每一个数据除以样本的size(单位bytes),目的是为了得到256个状态中的每一个状态,在样本中出现的频率。
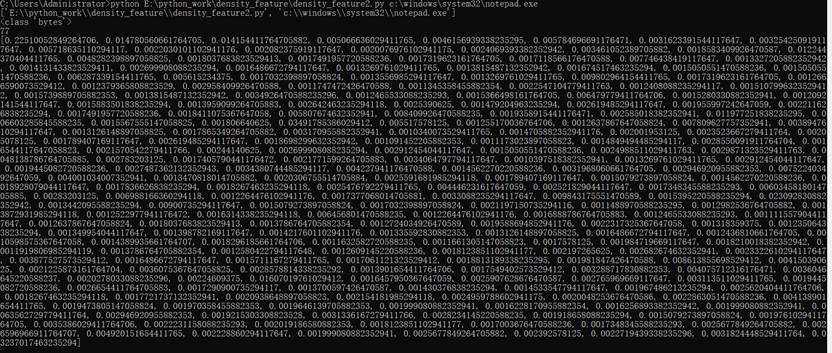
这些频率就是定长特征。配合上前文介绍的k-means,可以用作快速过滤出可能存在相似性的样本,可大大的减少后续流程的计算时间。
(2) 基于图片压缩的算法。
图片压缩算法的特性,保证了样本线性代数学特征的保留。我们先来看一下效果:
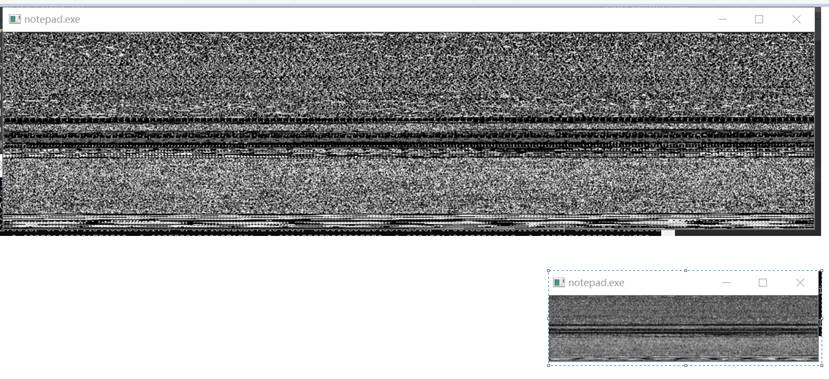
上图为notepad.exe的压缩前后对比效果。我们先把notepad.exe强制转换成图片,图片效果如上图的上半部分所示。然后再把notepad.exe的原始图片进行压缩,压缩后效果如上图的下半部分。我们可以看到压缩图片保留了原始图片的识别特征,可以分辨出这两张图片描绘的是同一样东西。
在实际操作中,我们希望我们的特征是1维的,所以要把图片的长或者高设置为1,其结果如下图。

在代码中:

如上图所示,图片压缩的原理虽然十分复杂,但是其python实现却是特别简单,cv2库的resize函数就可以。
四、总结。
本文描述的其实是一种查找相似样本的思想。无论是计算相似度的两个算法,还是生成特征的四个算法,他们都是能自由组合的。比如图片压缩算法配合上最短编辑距离也是可以做到查找相似度样本的。算法是死的,用法是活的。而且这里也是在抛砖引玉。所有的工具算法,都是为了解决实际问题才育孕而生,所以在面对实际问题中,在知其所以然的前提下,修改算法,才会更快速的解决所面临的问题。
引用:
[1] 最小编辑距离算法 Edit Distance(经典DP) https://blog.csdn.net/baodream/article/details/80417695
[2] 最小编辑距离 https://www.cnblogs.com/robert-dlut/p/4077540.html
[3] Adler-32 https://en.wikipedia.org/wiki/Adler-32
[4] k-means clustering https://en.wikipedia.org/wiki/K-means_clustering
附件下载地址

 浙公网安备 33010602011771号
浙公网安备 33010602011771号