《剑指offer》题解(Python版本)
- 《剑指offer》题解(Python版本)
- 1.使用Python实现单例模式
- 2.二维数组中的查找
- 3.替换空格
- 4.从尾到头打印单链表
- 5.重建二叉树
- 6.用两个栈实现队列
- 7.旋转数组中的最小数字
- 8.斐波那契数列
- 9.二进制中1的个数
- 10.数值的整数次方
- 11.打印1到最大的n位数
- 12.O(1)时间删除链表结点
- 13.调整数组顺序使奇数位于偶数前面
- 14.链表中倒数第k个结点
- 15.反转链表
- 16.合并两个排序的链表
- 17.树的子结构
- 18.二叉树的镜像
- 19.顺时针打印矩阵
- 20.包含min函数的栈
- 21.栈的压入弹出队列
- 22.从上往下打印二叉树
- 23.二叉搜索树的后序遍历
- 24.二叉树中和为某一路径值
- 25.复杂链表的复制
- 26.二叉搜索树与双向链表
- 27.字符串的排列
- 28.数组中出现次数超过一半的数
- 29.最小的k个数
- 30.连续子数组的最大和
- 31.从1到n整数中1出现的次数
- 32.把数组排成最小数
- 33.丑数
- 34.第一个只出现一次的字符
- 35.数组中的逆序对
- 36.两个链表第一个公共节点
- 37.数字在排序数组中出现的次数
- 38.二叉树的深度
- 39.判断是否是平衡二叉树
- 40.数组中只出现一次的数字
- 41.和为s的两个数字
- 42.和为s的连续正数序列
- 43.翻转单词顺序
- 44.左旋转字符串
- 45.n个骰子的点数
- 45.扑克牌中的顺子
- 46.圆圈中最后剩下的数字
- 47.求1+2+...n
- 48.不用加减乘除做加法
- 49.把字符串转换成整数
- 50.树中两个节点的公共节点
- 补充
《剑指offer》题解(Python版本)
1.使用Python实现单例模式
方法一 使用new实现单例模式
- new(clas[,...]) 通常被用在不可变类(int,str,),是一个类实例化后首先调用的方法,后面有参数原封不动地传给init方法,对参数定义时不用加self,需要一个实参对象作为返回值,在继承一个不可变类,又需要重写时才用new,重新定义后,需要return一个类对象,可以是父类,也可以是重写后的类。
- 如果子类定义和父类同名的属性或方法,父类的属性或方法就会被覆盖,此刻想再调用未被绑定的父类的方法,用父类名.方法名,或者super().需要调用的父类方法名,super()函数可以不用给出基类的名字,所以改变了类继承关系,改变class语句里的父类即可
class SingleTon(object):
_instance = {}
def __new__(cls, *args, **kwargs):
if cls not in cls._instance:
cls._instance[cls] = super(SingleTon, cls).__new__(cls, *args, **kwargs)
# print cls._instance
return cls._instance[cls]
class MyClass(SingleTon):
class_val = 22
def __init__(self, val):
self.val = val
def obj_fun(self):
print self.val, 'obj_fun'
@staticmethod
def static_fun():
print 'staticmethod'
@classmethod
def class_fun(cls):
print cls.class_val, 'classmethod'
if __name__ == '__main__':
a = MyClass(1)
b = MyClass(2)
print(a is b) # True
print(id(a), id(b)) # 4367665424 4367665424
# 类型验证
print type(a) # <class '__main__.MyClass'>
print type(b) # <class '__main__.MyClass'>
方法二使用装饰器实现单例模式
from functools import wraps
def single_ton(cls):
_instance = {}
'''
装饰器装饰过的函数,函数名会变成single,
加上 @wraps(cls)可以避免。
希望装饰器就可以用于任意目标函数,
可以传入可变参数*args和关键字参数**kwargs。
'''
@wraps(cls)
def single(*args, **kwargs):
if cls not in _instance:
_instance[cls] = cls(*args, **kwargs)
return _instance[cls]
return single
@single_ton
class SingleTon(object):
val = 123
def __init__(self, a):
self.a = a
if __name__ == '__main__':
s = SingleTon(1)
t = SingleTon(2)
print(s is t) #True
print(s.a, t.a) #1 1
print(s.val, t.val) #123 123
方法三 使用模块实现单例模式
可以使用模块创建单例模式,然后在其他模块中导入该单例
# use_module.py
class SingleTon(object):
def __init__(self, val):
self.val = val
single = SingleTon(2)
# test_module.py
from use_module import single
a = single
b = single
print(a.val, b.val)
print(a is b)
a.val = 233
print(a.val, b.val)
2.二维数组中的查找
在一个 n * m的二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。
示例:
现有矩阵 matrix 如下:
[
[1, 4, 7, 11, 15],
[2, 5, 8, 12, 19],
[3, 6, 9, 16, 22],
[10, 13, 14, 17, 24],
[18, 21, 23, 26, 30]
]
给定 target = 5,返回 true。
给定 target = 20,返回 false
思路:从左下角开始比较,左下角是最大行最小列,目标值比左下角值大,列号+1,目标值比左下角值小,行号-1
class Solution(object):
def findNumberIn2DArray(self, matrix, target):
"""
:type matrix: List[List[int]]
:type target: int
:rtype: bool
"""
if not matrix:
return False
rows, cols = len(matrix), len(matrix[0])
row, col = rows - 1, 0
while row >= 0 and col <= cols - 1:
if matrix[row][col] == target:
return True
#左下角值比目标值大,行号-1
elif matrix[row][col] > target:
row -= 1
#左下角值比目标值小,列号-1
else:
col += 1
return False
if __name__=="__main__":
s=Solution()
print(s.findNumberIn2DArray([
[1, 4, 7, 11, 15],
[2, 5, 8, 12, 19],
[3, 6, 9, 16, 22],
[10, 13, 14, 17, 24],
[18, 21, 23, 26, 30]
],5))
3.替换空格
请实现一个函数,把字符串 s 中的每个空格替换成"%20"。
示例 1:
输入:s = "We are happy."
输出:"We%20are%20happy."
方法1:直接使用Python字符串的内置函数replace
s.replace(' ', '20%')
方法2:插入排序
- 初始化一个 list ,记为 res ;
- 遍历列表 s 中的每个字符 c :
当 c 为空格时:向 res 后添加字符串 "%20" ;
当 c 不为空格时:向 res 后添加字符 c ;- 将列表 res 转化为字符串并返回。
class Solution:
def replaceSpace(self, s: str) -> str:
res = []
for c in s:
#当 c 为空格时:向 res 后添加字符串 "%20"
if c == ' ':
res.append("%20")
#当 c 不为空格时:向 res 后添加字符 c
else:
res.append(c)
return "".join(res)
if __name__=="__main__":
s=Solution()
print(s.replaceSpace("We are happy."))
#We%20are%20happy.
4.从尾到头打印单链表
输入一个链表的头节点,从尾到头反过来返回每个节点的值(用数组返回)。
示例 1:
输入:head = [1,3,2]
输出:[2,3,1]
在遍历一个链表的时候,将值依次放入到一个list中,遍历结束后,翻转list输出
# Definition for singly-linked list.
class ListNode:
def __init__(self, x):
self.val = x
self.next = None
class Solution:
def reversePrint(self, head: ListNode):
stack=[]
while head:
stack.append(head.val)
head = head.next
if stack!=[]:
return(stack[::-1])
else:
return stack
s=Solution()
node=ListNode(1)
node.next=ListNode(2)
node.next.next=ListNode(3)
node.next.next.next=ListNode(4)
print(s.reversePrint(node))
#[4, 3, 2, 1]
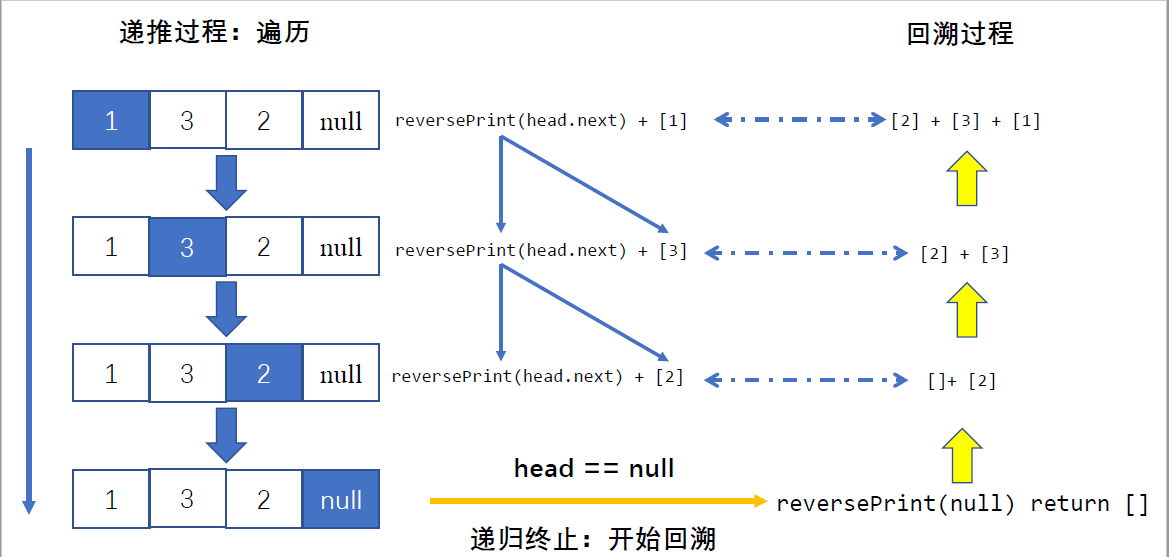
递归+回溯:
- 递推阶段: 每次传入 head.next ,以 head == None(即走过链表尾部节点)为递归终止条件,此时返回空列表 [] 。
- 回溯阶段: 利用 Python 语言特性,递归回溯时每次返回 当前 list + 当前节点值 [head.val] ,即可实现节点的倒序输出。
# Definition for singly-linked list.
class ListNode:
def __init__(self, x):
self.val = x
self.next = None
class Solution:
def reversePrint(self, head: ListNode):
return self.reversePrint(head.next) + [head.val] if head else []
s=Solution()
node=ListNode(1)
node.next=ListNode(2)
node.next.next=ListNode(3)
node.next.next.next=ListNode(4)
print(s.reversePrint(node))
#[4, 3, 2, 1]
5.重建二叉树
输入某二叉树的前序遍历和中序遍历的结果,请重建该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。
例如,给出
前序遍历 preorder = [3,9,20,15,7]
中序遍历 inorder = [9,3,15,20,7]
返回如下的二叉树:
3
/
9 20
/
15 7
递归:
前序遍历+中序遍历:
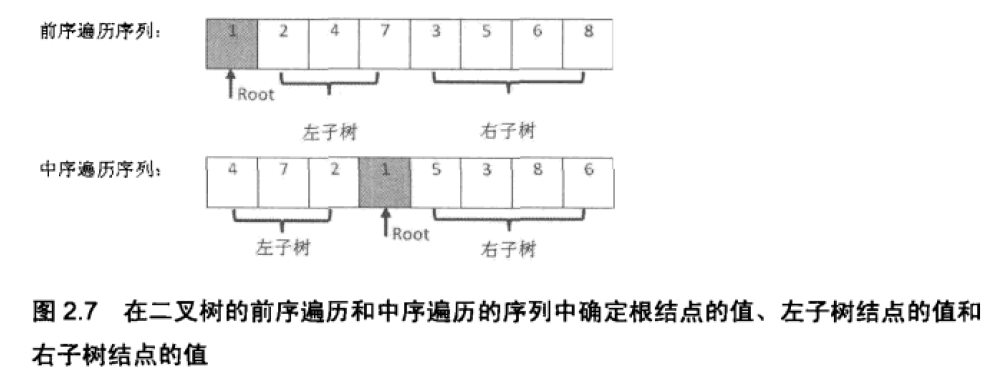
- 前序遍历特点: 节点按照 [ 根节点 | 左子树 | 右子树 ] 排序,以题目示例为例:[ 3 | 9 | 20 15 7 ]
中序遍历特点: 节点按照 [ 左子树 | 根节点 | 右子树 ] 排序,以题目示例为例:[ 9 | 3 | 15 20 7 ]- 前序遍历的首个元素即为根节点
root的值,然后在中序遍历序列中寻找根节点root的值的位置- 从中序遍历序列的起始位置到根结点的值的位置(不包含)为根结点左子树的中序遍历序列,从中序遍历序列的根结点的值的位置(不包含)到结束位置为根结点右子树的中序遍历序列. 从前序遍历序列的第二个元素开始的根结点左子树结点数个元素的子序列为根结点左子树的前序遍历序列,从下一个元素开始,直到结束位置的子序列为根结点右子树的前序遍历序列.
- 构建根节点
root的左子树和右子树: 通过调用buildTree()方法开启下一层递归,给新建的树添加左子树和右子树
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def buildTree(self, preorder: List[int], inorder: List[int]) -> TreeNode:
if not preorder or not inorder:
return None
if len(preorder) != len(inorder):
return None
root = preorder[0]#第一个为根节点
rootNode = TreeNode(root)#创建树
pos = inorder.index(root)#在中序中找到对应索引值
#索引中序遍历中左右子树位置
inorder_left = inorder[:pos]
inorder_right = inorder[pos+1:]
#索引前序遍历中左右子树位置
preorder_left = preorder[1:1+pos]
preorder_right = preorder[pos+1:]
node_left = self.buildTree(preorder_left , inorder_left) #递归左子树
node_right= self.buildTree(preorder_right , inorder_right) #递归右子树
rootNode.left = node_left#添加左子树
rootNode.right = node_right#添加右子树
return rootNode
#层序遍历打印二叉树,bfs
s=Solution()
resu=s.buildTree([ 3,9,20,15,7],[9, 3,15,20,7 ])
def levelOrder(root: TreeNode):
queue = []
res = []
if root == None:
return res
queue.append(root)
while queue:
newNode = queue.pop(0)
res.append(newNode.val)
if newNode.left != None:
queue.append(newNode.left)
if newNode.right != None:
queue.append(newNode.right)
return res
print(levelOrder(resu)) #[3, 9, 20, 15, 7]
6.用两个栈实现队列
用两个栈实现一个队列。队列的声明如下,请实现它的两个函数 appendTail 和 deleteHead ,分别完成在队列尾部插入整数和在队列头部删除整数的功能。(若队列中没有元素,deleteHead 操作返回 -1 )
示例 :
输入:
["CQueue","appendTail","deleteHead","deleteHead"]
[[],[3],[],[]]
输出:[null,null,3,-1]
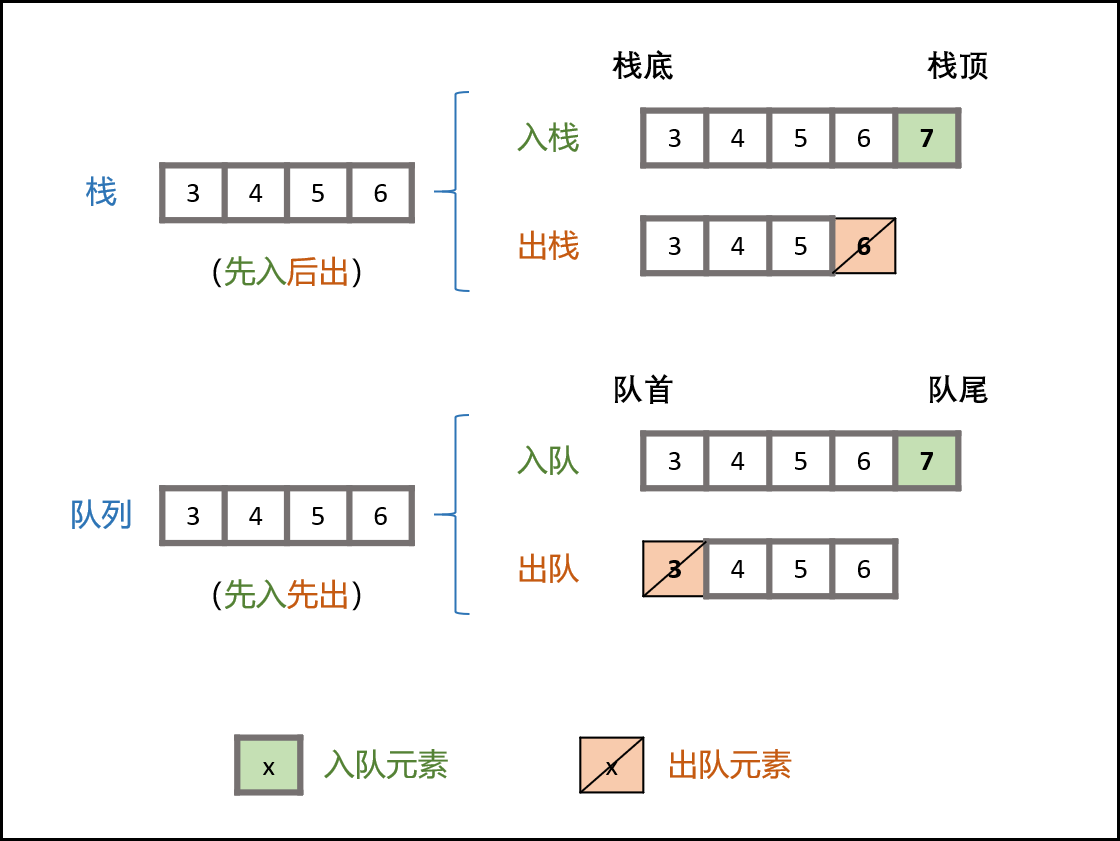
栈的先进后出特性:
- 栈无法实现队列功能: 栈底元素(对应队首元素)无法直接删除,需要将上方所有元素出栈。
- 双栈可实现列表倒序: 设有含三个元素的栈 A = [1,2,3]和空栈 B = []。若循环执行 A元素出栈并添加入栈 B ,直到栈 A为空,则 A = [], B = [3,2,1] ,即 栈 B 元素实现栈 A元素倒序 。
- 利用栈 B删除队首元素: 倒序后,B执行出栈则相当于删除了 A 的栈底元素,即对应队首元素。
class CQueue:
def __init__(self):
self.stack1=[]
self.stack2=[]
#在队列尾部插入整数
def appendTail(self, value: int) -> None:
self.stack1.append(value)
#在队列头部删除整数
def deleteHead(self) -> int:
if self.stack2:
return self.stack2.pop()
#将1的出栈循环放入2,则2是1的倒序,2出栈就成了1的队列
while self.stack1:
self.stack2.append(self.stack1.pop())
return self.stack2.pop() if self.stack2 else -1
c=CQueue()
print(c.appendTail(3)) #None
print(c.deleteHead()) #3
print(c.deleteHead()) #-1
7.旋转数组中的最小数字
把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。输入一个递增排序的数组的一个旋转,输出旋转数组的最小元素。例如,数组 [3,4,5,1,2] 为 [1,2,3,4,5] 的一个旋转,该数组的最小值为1。
示例 1:
输入:[3,4,5,1,2]
输出:1
二分查找:
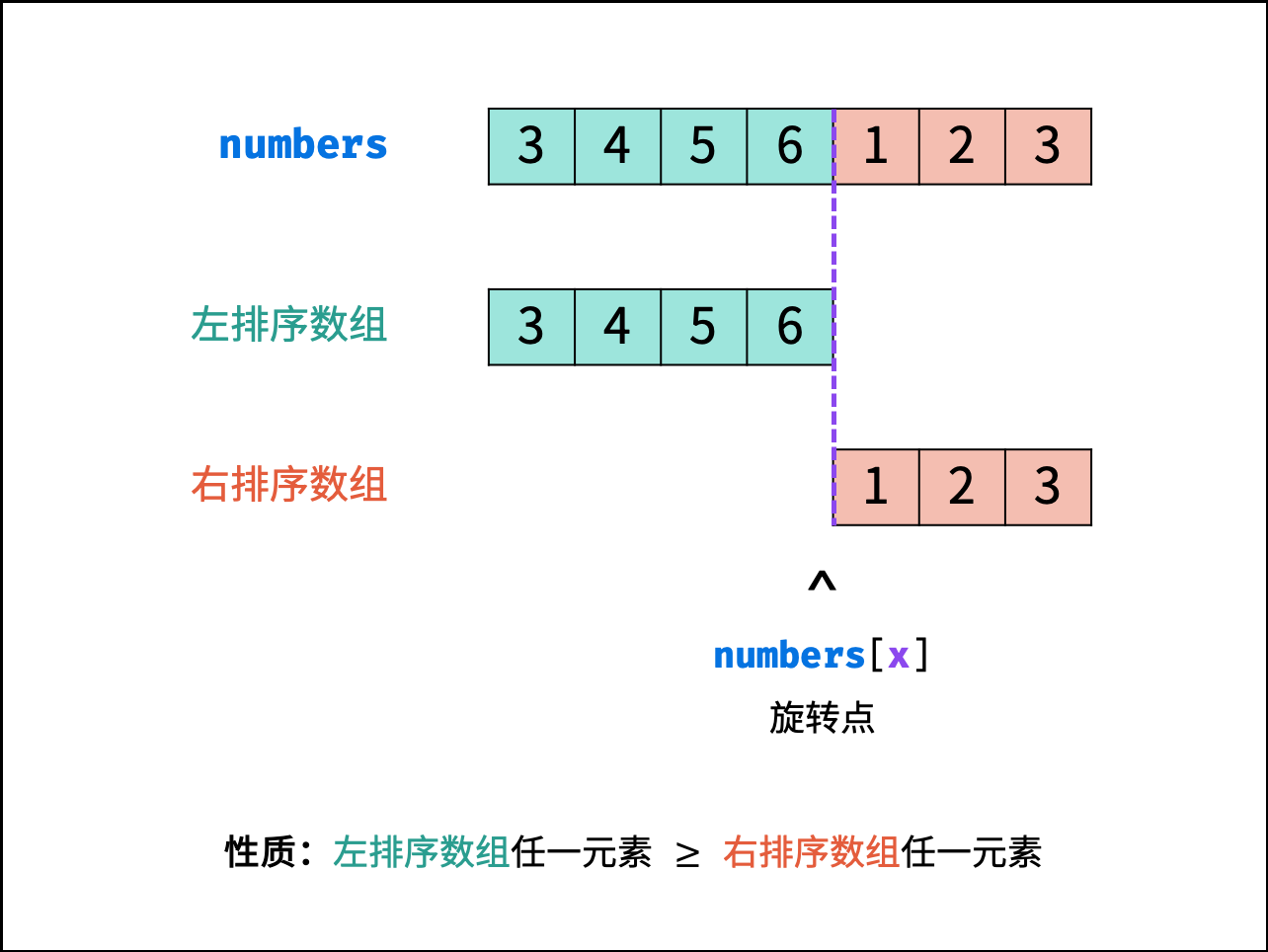
寻找旋转数组的最小元素即为寻找 右排序数组 的首个元素 nums[x] ,称 x为 旋转点 。
- 初始化: 声明 i, j双指针分别指向 nums 数组左右两端;
循环二分: 设 m = (i + j) / 2为每次二分的中点( "/" 代表向下取整除法,因此恒有 i≤m<j ),可分为以下三种情况:- 当 nums[m] > nums[j] 时: m一定在 左排序数组 中,即旋转点 x一定在 [m + 1, j]闭区间内,因此执行 i = m + 1;
- 当 nums[m] < nums[j]: mm一定在 右排序数组 中,即旋转点 x 一定在[i, m]闭区间内,因此执行 j = m; 当 nums[m] = nums[j]时: 无法判断 m 在哪个排序数组中,即无法判断旋转点 x 在 [i, m]还是 [m + 1, j]区间中。解决方案: 执行 j = j - 1 缩小判断范围。 返回值: 当 i = j 时跳出二分循环,并返回 旋转点的值 nums[i]即可
class Solution:
def minArray(self, numbers) -> int:
i, j = 0, len(numbers) - 1
while i < j:
#每次二分的中点
m = (i + j) // 2
#旋转点 x在 [m + 1, j]闭区间内
if numbers[m] > numbers[j]:
i = m + 1
#旋转点x在[i, m]闭区间内
elif numbers[m] < numbers[j]:
j = m
#无法判断旋转点 x 在 [i, m]还是 [m + 1, j]区间中
else: j -= 1
return numbers[i]
if __name__=='__main__':
s=Solution()
print(s.minArray([3,4,5,1,2]))#1
8.斐波那契数列
写一个函数,输入 n ,求斐波那契(Fibonacci)数列的第 n 项。斐波那契数列的定义如下:
F(0) = 0, F(1) = 1
F(N) = F(N - 1) + F(N - 2), 其中 N > 1.
斐波那契数列由 0 和 1 开始,之后的斐波那契数就是由之前的两数相加而得出。
答案需要取模 1e9+7(1000000007),如计算初始结果为:1000000008,请返回 1
动态规划:
创建长度为n+1的数组dp,令dp[0]=0,dp[1]=1。除前两项外,数组中某项的值为其前两项的和,据此由前到后依次求出各项的值,最后一项即为所求
class Solution:
def fib(self, n: int) -> int:
a, b = 0, 1
for _ in range(n):
a, b = b, a + b
return a % 1000000007
if __name__=='__main__':
s=Solution()
print(s.fib(3)) #2
递归:
return fib(n-1) + fib(n-2)
边界:n0,return 0
n1,return1
class Solution:
def fib(self, n: int) -> int:
if n == 0:
return 0
if n == 1:
return 1
return self.fib(n-1) + self.fib(n-2)
if __name__=='__main__':
s=Solution()
print(s.fib(3)) #2
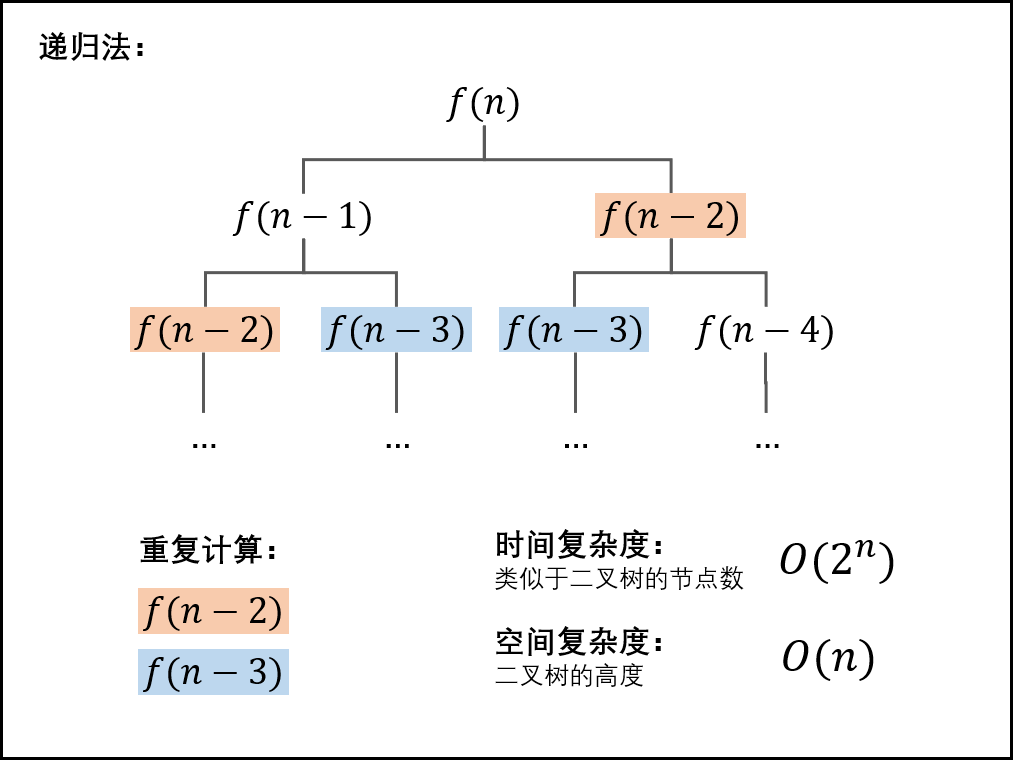
带备忘录的递归解法:
在递归法的基础上,新建一个长度为 n的数组,用于在递归时存储 f(0) 至 f(n)的数字值,重复遇到某数字则直接从数组取用,避免了重复的递归计算。
class Solution:
def fib(self, n: int) -> int:
my_dic = {0: 0, 1: 1}
def my_fib(n):
if n in my_dic:
return my_dic[n]
#运用字典,查看是否遇到重复数字
if n - 2 not in my_dic:
my_dic[n - 2] = my_fib(n - 2)
if n - 1 not in my_dic:
my_dic[n - 1] = my_fib(n - 1)
my_dic[n] = (my_dic[n - 2] + my_dic[n - 1]) % 1000000007
return my_dic[n]
return my_fib(n)
if __name__=='__main__':
s=Solution()
print(s.fib(3)) #2
9.二进制中1的个数
请实现一个函数,输入一个整数,输出该数二进制表示中 1 的个数。例如,把 9 表示成二进制是 1001,有 2 位是 1。因此,如果输入 9,则该函数输出 2。
示例 :
输入:00000000000000000000000000001011
输出:3
解释:输入的二进制串 00000000000000000000000000001011 中,共有三位为 '1'。
按位与:
二进制整数,将它-1与它本身&,会把这个整数最右边的1变成0,直到全0为止,有多少1就可以循环多少次。对于负数,将最高位的符号取反得到补码,通常采用和0xffffffff相与得到
class Solution:
def num_of_1(self,n):
if n<0:
n=n&0xffffffff
ret = 0
while n:
ret += 1
n = n & n - 1
return ret
if __name__=='__main__':
s=Solution()
print(s.num_of_1(11)) #3
10.数值的整数次方
实现函数double Power(double base, int exponent),求base的exponent次方。不得使用库函数,同时不需要考虑大数问题。
示例 :
输入: 2.00000, 10
输出: 1024.00000
快速幂:
- 对于任何十进制正整数 nn ,设其二进制为 “\(b~m~b_3b_2b_1b\) "( \(b_i\)为二进制某位值,\(i \in [1,m]\) ),则有:
- 二进制转十进制: \(n = 1b_1 + 2b_2 + 4b_3 + ... + 2^{m-1}b_m\)(即二进制转十进制公式) ;
- 幂的二进制展开: \(x^n = x^{1b_1 + 2b_2 + 4b_3 + ... + 2^{m-1}b_m} = x^{1b_1}x^{2b_2}x^{4b_3}...x^{2^{m-1}b_m}\);
- 根据以上推导,可把计算 \(x^n\)x 转化为解决以下两个问题:
- 计算 \(x^1, x^2, x^4, ..., x^{2^{m-1}}\)的值: 循环赋值操作 \(x = x^2\)即可;
- 获取二进制各位 \(b_1, b_2, b_3, ..., b_m\)的值: 循环执行以下操作即可。
- n&1 (与操作): 判断 n二进制最右一位是否为1
- n>>1(移位操作): n右移一位(可理解为删除最后一位)。
- 因此,应用以上操作,可在循环中依次计算 \(x^{2^{0}b_1}, x^{2^{1}b_2}, ..., x^{2^{m-1}b_m}\)的值,并将所有 \(x^{2^{i-1}b_i}\)累计相乘即可。
- 当 \(b_i = 0\)时:\(x^{2^{i-1}b_i} = 1\);
- 当 \(b_i = 1\)时:\(x^{2^{i-1}b_i} = x^{2^{i-1}}\);

class Solution:
def myPow(self, x: float, n: int) -> float:
if x == 0: return 0
res = 1
#当 n < 0时:把问题转化至n≥0 的范围内
if n < 0:
x, n = 1 / x, -n
while n:
#判断二进制形式最后一位是否为1,为1与为1,为0与为0,==n%2
if n & 1:
res *= x
x *= x
#二进制形式右移一位,=n//2
n >>= 1
return res
if __name__=='__main__':
s=Solution()
print(s.myPow(2,3)) #8
递归+二分推导:
二分推导: \(x^n = x^{n/2} \times x^{n/2} = (x^2)^{n/2}\) ,令 n/2 为整数,则需要分为奇偶两种情况(设向下取整除法符号为 "//" ):
- 当 n为偶数: \(x^n = (x^2)^{n//2}\);
- 当 n为奇数: \(x^n = x(x^2)^{n//2}\)即会多出一项 x ;
class Solution:
def myPow(self, x: float, n: int) -> float:
if n == 0:
return 1
if n < 0:
return 1 / self.myPow(x, -n)
# 如果是奇数
if n & 1:
return x * self.myPow(x, n - 1)
# 如果是偶数
return self.myPow(x * x, n // 2)
if __name__=='__main__':
s=Solution()
print(s.myPow(2,3)) #8
11.打印1到最大的n位数
输入数字 n,按顺序打印出从 1 到最大的 n 位十进制数。比如输入 3,则打印出 1、2、3 一直到最大的 3 位数 999。
示例 :
输入: n = 1
输出: [1,2,3,4,5,6,7,8,9]
先使用
range()方法生成可迭代对象,再使用list()方法转化为列表并返回即可
class Solution:
def printNumbers(self, n: int) :
return list(range(1, 10 ** n))
if __name__=='__main__':
s=Solution()
print(s.printNumbers(1)) #[1, 2, 3, 4, 5, 6, 7, 8, 9]
大数越界情况下:
表示大数的变量类型:
无论是 short / int / long ... 任意变量类型,数字的取值范围都是有限的。因此,大数的表示应用字符串 String 类型。生成数字的字符串集:
使用 int 类型时,每轮可通过 +1生成下个数字,而此方法无法应用至 String 类型。并且, String 类型的数字的进位操作效率较低,例如 "9999" 至 "10000" 需要从个位到千位循环判断,进位 4 次。观察可知,生成的列表实际上是 n位 00 - 99 的 全排列 ,因此可避开进位操作,通过递归生成数字的 String 列表。
- 递归生成全排列:
基于分治算法的思想,先固定高位,向低位递归,当个位已被固定时,添加数字的字符串。例如当 n = 2时(数字范围 1 - 99),固定十位为 00 - 99 ,按顺序依次开启递归,固定个位 00 - 99 ,终止递归并添加数字字符串。- 删除高位多余0:高位为0时不用遍历来设置高位。
class Solution:
def printNumbers(self, n: int) :
def dfs(x,begin0):
if x == n: # 终止条件:已固定完所有位
s=''.join(num) # 拼接 num
if s:
res.append(int(s)) # 将拼接 的num转成int类型 并添加至 res 尾部
return
for i in range(10): # 遍历 0 - 9
if begin0 and i!=0: #删除高位多余的0
begin0=False
if not begin0:
num[x] = str(i) # 固定第 x 位为 i
dfs(x + 1,begin0) # 开启固定第 x + 1 位
begin0 = True
num = [''] * n # 起始数字定义为 n 个 空字符组成的字符列表
res = [] # 数字字符串列表
dfs(0,begin0) # 开启全排列递归
return res # 拼接所有数字字符串,使用逗号隔开,并返回
if __name__=='__main__':
s=Solution()
print(s.printNumbers(1)) #[1, 2, 3, 4, 5, 6, 7, 8, 9]
12.O(1)时间删除链表结点
给定单向链表的头指针和一个要删除的节点的值,定义一个函数删除该节点。
返回删除后的链表的头节点。
示例 :
输入: head = [4,5,1,9], val = 5
输出: [4,1,9]
解释: 给定你链表中值为 5 的第二个节点,那么在调用了你的函数之后,该链表应变为 4 -> 1 -> 9.
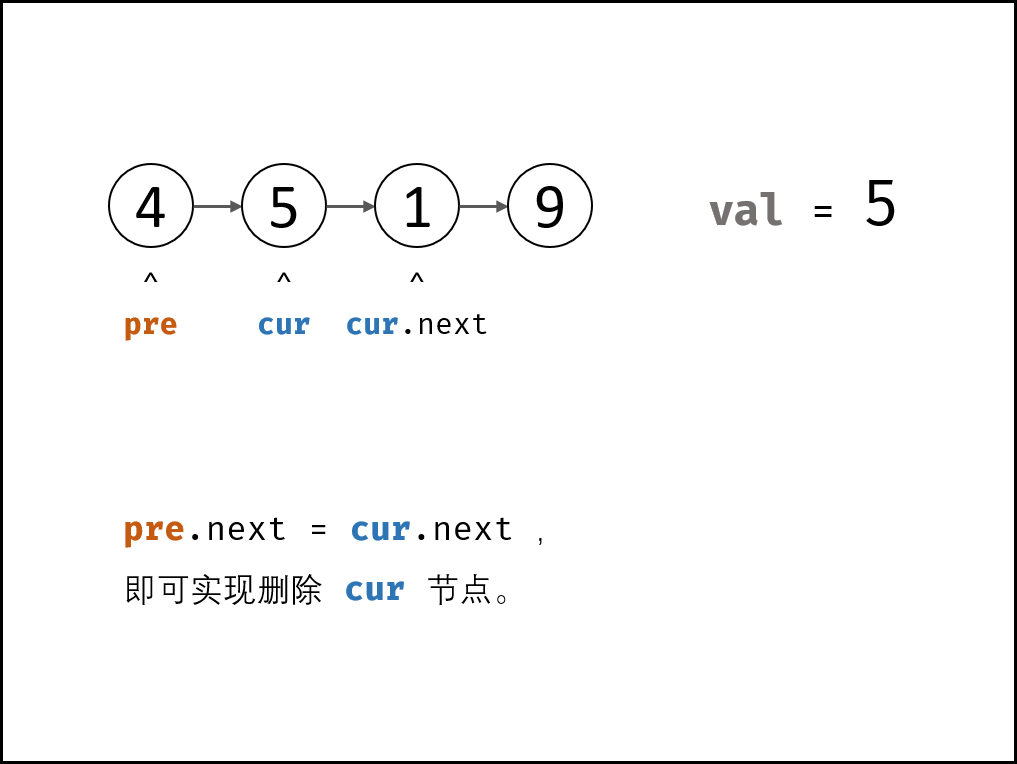
双指针:
- 特例处理: 当应删除头节点 head 时,直接返回 head.next 即可。
- 初始化: pre = head , cur = head.next 。
- 定位节点: 当 cur 为空 或 cur 节点值等于 val 时跳出。
- 保存当前节点索引,即 pre = cur 。
- 遍历下一节点,即 cur = cur.next 。
- 删除节点: 若 cur 指向某节点,则执行 pre.next = cur.next 。(若 cur 指向 nullnull ,代表链表中不包含值为 val 的节点。
- 返回值: 返回链表头部节点 head 即可
# Definition for singly-linked list.
class ListNode:
def __init__(self, x):
self.val = x
self.next = None
class Solution:
def deleteNode(self, head: ListNode, val: int) -> ListNode:
#当应删除头节点 head 时,直接返回 head.next 即可
if head.val==val:
return head.next
pre, cur = head, head.next
#当 cur 为空 或 cur 节点值等于 val 时跳出
while cur and cur.val != val:
pre, cur = cur, cur.next #1. 保存当前节点索引,遍历下一节点
#若 cur 指向某节点,删除结点
if cur.val==val:
pre.next = cur.next
return head
s=Solution()
node=ListNode(1)
node.next=ListNode(2)
node.next.next=ListNode(3)
node.next.next.next=ListNode(4)
resu=s.deleteNode(node,3)
#从头到尾打印链表
def reversePrint(head: ListNode):
stack = []
while head:
stack.append(head.val)
head = head.next
return stack
print(reversePrint(resu))#[1, 2, 4]
13.调整数组顺序使奇数位于偶数前面
输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有奇数位于数组的前半部分,所有偶数位于数组的后半部分。
示例:
输入:nums = [1,2,3,4]
输出:[1,3,2,4]
注:[3,1,2,4] 也是正确的答案之一
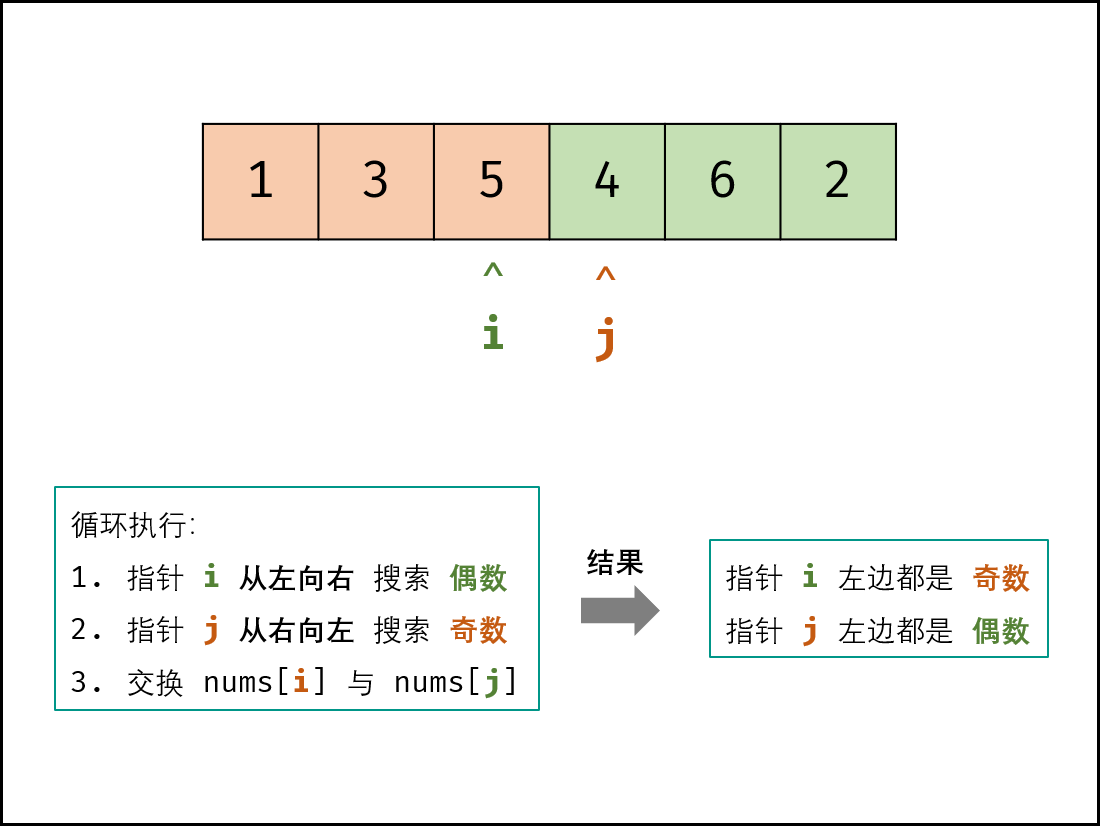
双指针:
- 初始化: i, j双指针,分别指向数组 nums左右两端;
- 循环交换: 当 i = j时跳出;
- 指针 i遇到奇数则执行 i = i + 1跳过,直到找到偶数;
- 指针 j遇到偶数则执行 j = j - 1 跳过,直到找到奇数;
- 交换 nums[i] 和 nums[j]值;
- 返回值: 返回已修改的 numsnums 数组
class Solution:
def exchange(self, nums):
i, j = 0, len(nums) - 1
while i < j:
#指针 i遇到奇数则执行 i = i + 1跳过,直到找到偶数
while i < j and nums[i] & 1 == 1: i += 1
#指针 j遇到偶数则执行 j = j - 1 跳过,直到找到奇数
while i < j and nums[j] & 1 == 0: j -= 1
nums[i], nums[j] = nums[j], nums[i]
return nums
if __name__=='__main__':
s=Solution()
print(s.exchange([1,2,3,4])) #[1, 3, 2, 4]
sorted()排序:偶数%2=0,奇数%2=1,1-偶数%2=1排在后头,奇数%2=0排在前头,可以实现奇数在前,偶数在后
class Solution:
def exchange(self, nums):
return sorted(nums,key=lambda x:1-x%2)
if __name__=='__main__':
s=Solution()
print(s.exchange([1,2,3,4])) #[1, 3, 2, 4]
14.链表中倒数第k个结点
输入一个链表,输出该链表中倒数第k个节点。为了符合大多数人的习惯,本题从1开始计数,即链表的尾节点是倒数第1个节点。例如,一个链表有6个节点,从头节点开始,它们的值依次是1、2、3、4、5、6。这个链表的倒数第3个节点是值为4的节点。
示例:
给定一个链表: 1->2->3->4->5, 和 k = 2.
返回链表 4->5.
快慢指针:
- 初始化: 前指针 former 、后指针 latter ,双指针都指向头节点 head 。
- 构建双指针距离: 前指针 former 先向前走 k 步(结束后,双指针 former 和 latter 间相距 k 步)。
- 双指针共同移动: 循环中,双指针 former 和 latter 每轮都向前走一步,直至 former 走过链表 尾节点 时跳出(跳出后, latter 与尾节点距离为 k-1,即 latter 指向倒数第 k个节点)。
- 返回值: 返回 latter 即可
# Definition for singly-linked list.
class ListNode:
def __init__(self, x):
self.val = x
self.next = None
class Solution:
def getKthFromEnd(self, head: ListNode, k: int) -> ListNode:
former, latter = head, head
#前指针 former 先向前走 k 步
for _ in range(k):
former = former.next
#循环中,双指针 former 和 latter 每轮都向前走一步,到former为空时
while former:
former, latter = former.next, latter.next
#latter指向倒数第 k 个节点
return latter
#生成链表
s=Solution()
node=ListNode(1)
node.next=ListNode(2)
node.next.next=ListNode(3)
node.next.next.next=ListNode(4)
node.next.next.next.next=ListNode(5)
resu=s.getKthFromEnd(node,2)
#从头到尾打印链表
def reversePrint(head: ListNode):
stack = []
while head:
stack.append(head.val)
head = head.next
return stack
print(reversePrint(resu))#[4, 5]
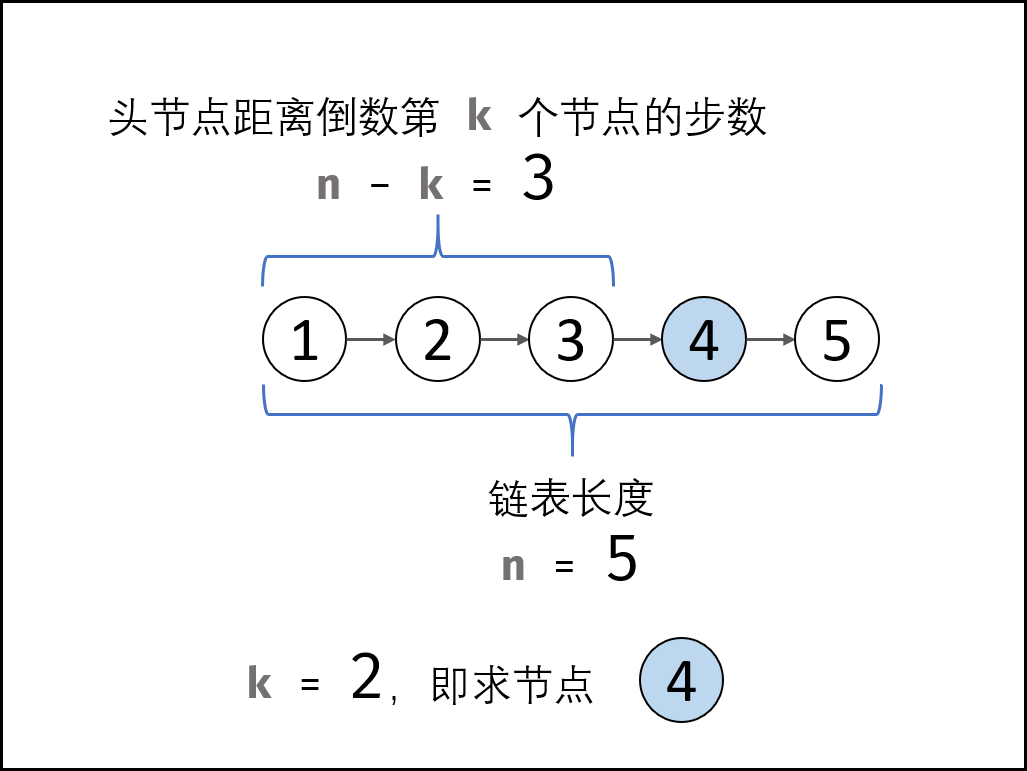
遍历+指针:
- 先遍历统计链表长度,记为 n;
- 设置一个指针走 (n-k)步,即可找到链表倒数第 k个节点
# Definition for singly-linked list.
class ListNode:
def __init__(self, x):
self.val = x
self.next = None
class Solution:
def getKthFromEnd(self, head: ListNode, k: int) -> ListNode:
count = 0
node = head
# 遍历链表长度count
while node:
count += 1
node = node.next
former = head
n = count - k
# 设置一个指针走count-k步骤
while n:
former = former.next
n -= 1
return former
#生成链表
s=Solution()
node=ListNode(1)
node.next=ListNode(2)
node.next.next=ListNode(3)
node.next.next.next=ListNode(4)
node.next.next.next.next=ListNode(5)
resu=s.getKthFromEnd(node,2)
#从头到尾打印链表
def reversePrint(head: ListNode):
stack = []
while head:
stack.append(head.val)
head = head.next
return stack
print(reversePrint(resu))#[4, 5]
15.反转链表
定义一个函数,输入一个链表的头节点,反转该链表并输出反转后链表的头节点。
示例:
输入: 1->2->3->4->5->NULL
输出: 5->4->3->2->1->NULL
双指针:
- 一个指针pre指向null做前一节点,另一个指针cur指向链表head表头,做当前节点
- 循环遍历链表,当前节点为空时结束循环
- 当前节点cur的下个节点指向前一个节点pre
- 指针pre用作新生成的一个链表当前节点,另一个指针cur用于源链表遍历
- 更新新链表,返回新表表头pre

# Definition for singly-linked list.
class ListNode:
def __init__(self, x):
self.val = x
self.next = None
class Solution:
# 双指针,一个指针用作新生成的一个链表当前节点,另一个指针用于源链表遍历
def reverseList(self, head: ListNode) -> ListNode:
pre=None
cur=head
#当前节点为空时结束循环
while cur:
#单值赋值需要临时变量,多值赋值不用
#cur.next, pre, cur = pre, cur, cur.next
# 这个临时节点就相当于一个副本
temp=cur.next
#当前节点的下个节点指向前一个节点
cur.next=pre
#保存当前节点
pre=cur
#遍历下个节点
cur=temp
#当前节点为空,前一个节点是遍历的最后一个节点
return pre
#生成链表
s=Solution()
node=ListNode(1)
node.next=ListNode(2)
node.next.next=ListNode(3)
node.next.next.next=ListNode(4)
node.next.next.next.next=ListNode(5)
resu=s.reverseList(node)
#从头到尾打印链表
def reversePrint(head: ListNode):
stack = []
while head:
stack.append(head.val)
head = head.next
return stack
print(reversePrint(resu))#[5, 4, 3, 2, 1]
16.合并两个排序的链表
输入两个递增排序的链表,合并这两个链表并使新链表中的节点仍然是递增排序的。
示例1:
输入:1->2->4, 1->3->4
输出:1->1->2->3->4->4
双指针:
根据题目描述, 链表 \(l_1\), \(l_2\)是 递增 的,因此容易想到使用双指针\(l_1\), \(l_2\)遍历两链表,根据 \(l_1\).vall 和 \(l_2.\)vall 的大小关系确定节点添加顺序,两节点指针交替前进,直至遍历完毕。
引入伪头节点: 由于初始状态合并链表中无节点,因此循环第一轮时无法将节点添加到合并链表中。解决方案:初始化一个辅助节点 dump作为合并链表的伪头节点,将各节点添加至 dump后。
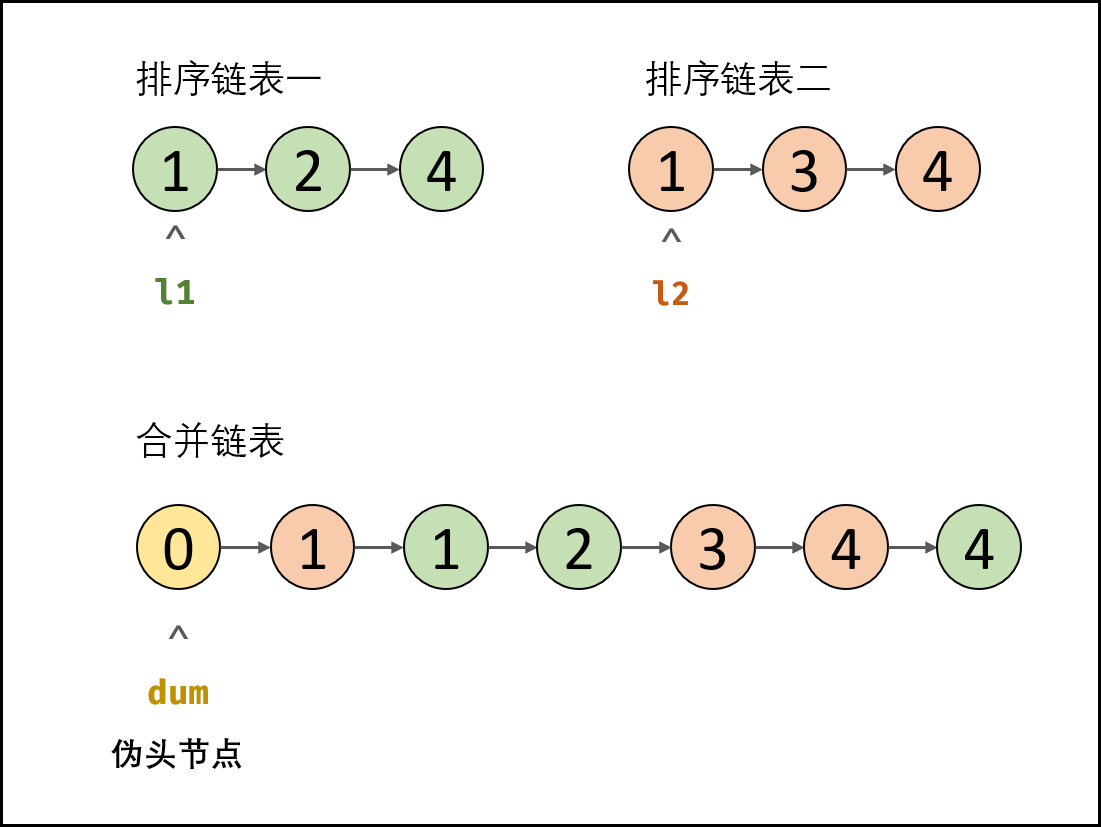
- 初始化: 伪头节点 dump,节点 cur指向 dump 。
- 循环合并:
- 当\(l_1\)或 \(l_2\)为空时跳出;
- 当 \(l_1.vall <l_2.vall\)时: cur 的后继节点指定为 \(l_1\),并 \(l_1\)向前走一步;
- 当 \(l_1.val \geq l_2.vall\) 时: cur的后继节点指定为 \(l_2\),并 \(l_2\) 向前走一步 ;
- 节点 cur向前走一步,即 cur = cur.next 。
- 合并剩余尾部: 跳出时有两种情况,即 \(l_1\)为空 或 \(l_2\)为空。
- 若 \(l_1 \ne nulll\) : 将 \(l_1\)添加至节点 cur 之后;
- 否则: 将 \(l_2\)添加至节点 cur 之后。
- 返回值: 合并链表在伪头节点 dump之后,因此返回 dump.next 即可
# Definition for singly-linked list.
class ListNode:
def __init__(self, x):
self.val = x
self.next = None
#合并两个排序列表
class Solution:
def mergeTwoLists(self, l1: ListNode, l2: ListNode) -> ListNode:
cur=dump=ListNode(0)
while l1 and l2:
if l1.val<l2.val:
#下一节点指向较小的节点
cur.next=l1
l1=l1.next
else:
cur.next=l2
l2=l2.next
#节点 cur向前走一步
cur=cur.next
#若 l1!=None: 将 l1添加至节点 cur 之后
cur.next=l1 if l1 else l2
return dump.next
#生成链表
s=Solution()
node1=ListNode(1)
node1.next=ListNode(2)
node1.next.next=ListNode(4)
node2=ListNode(1)
node2.next=ListNode(3)
node2.next.next=ListNode(4)
resu=s.mergeTwoLists(node1,node2)
#从头到尾打印链表
def reversePrint(head: ListNode):
stack = []
while head:
stack.append(head.val)
head = head.next
return stack
print(reversePrint(resu))#[1, 1, 2, 3, 4, 4]
17.树的子结构
输入两棵二叉树A和B,判断B是不是A的子结构。(约定空树不是任意一个树的子结构)
B是A的子结构, 即 A中有出现和B相同的结构和节点值。
例如:
给定的树 A:
3
/ \
4 5
/
1 2
给定的树 B:
4
/
1
返回 true,因为 B 与 A 的一个子树拥有相同的结构和节点值。
先序遍历+递归:
- 序遍历树 A 中的每个节点\(n_A\) ;(对应函数 isSubStructure(A, B))
- 判断树 A中 以\(n_A\) 为根节点的子树 是否包含树 B 。(对应函数 recur(A, B))
- recur(A, B) 函数:
- 终止条件:
当节点 B为空:说明树 B 已匹配完成(越过叶子节点),因此返回 true ;
当节点 A为空:说明已经越过树 A 叶子节点,即匹配失败,返回 false ;
当节点 A和 B 的值不同:说明匹配失败,返回 false ;- 返回值:
判断 A 和 B的左子节点是否相等,即 recur(A.left, B.left) ;
判断 A和 B 的右子节点是否相等,即 recur(A.right, B.right) ;- isSubStructure(A, B) 函数:
- 特例处理: 当 树 A为空 或 树 B 为空 时,直接返回 false;
- 返回值: 若树 B是树 A 的子结构,则必满足以下三种情况之一,因此用或 || 连接;
以 节点 A为根节点的子树 包含树 B ,对应 recur(A, B);
树 B是 树 A左子树 的子结构,对应 isSubStructure(A.left, B);
树 B是 树 A右子树 的子结构,对应 isSubStructure(A.right, B);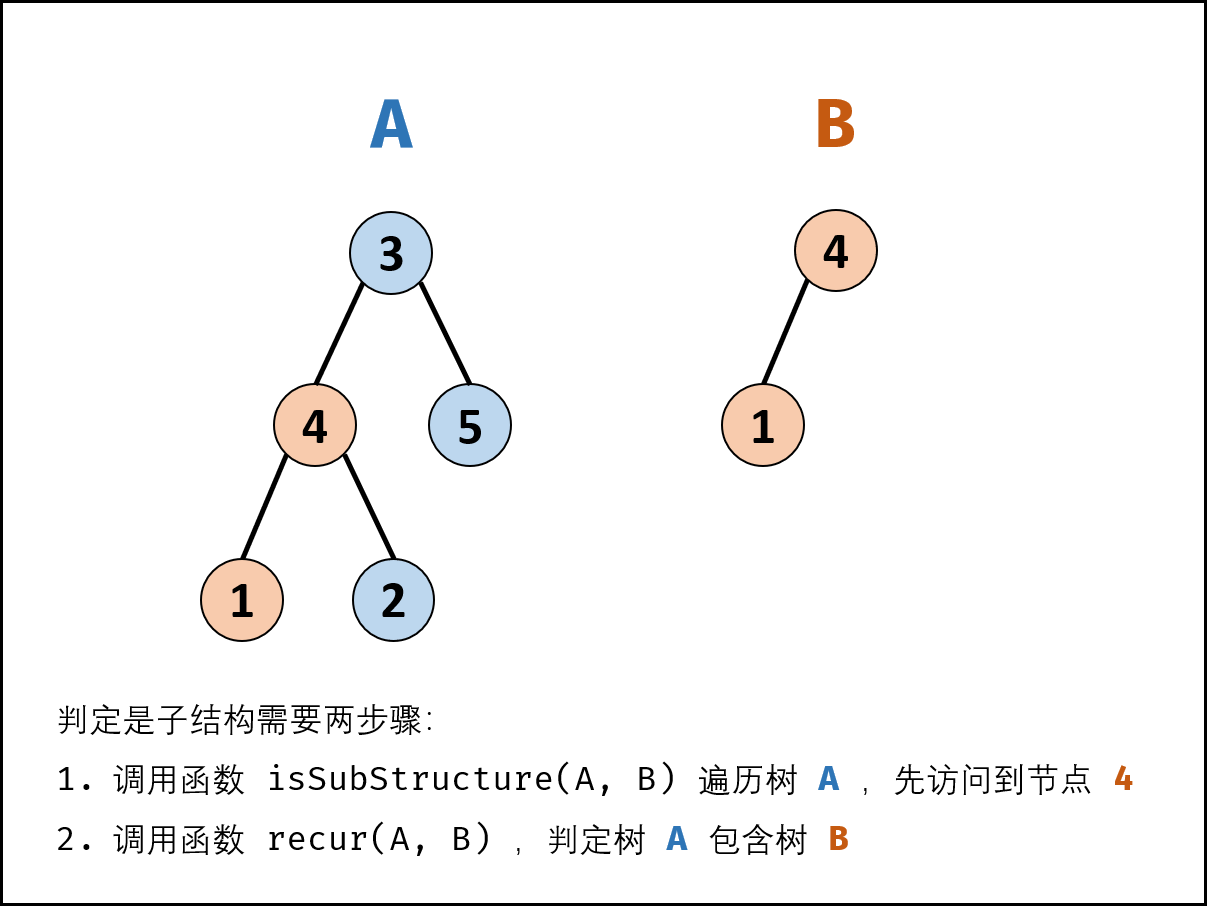
#定义树
class TreeNode:
def __init__(self, x):
self.val = x
self.left = None
self.right = None
#判断B是否是A子树
class Solution:
def isSubStructure(self, A: TreeNode, B: TreeNode) -> bool:
def recur(A, B):
#B全递归完成空,此时B前面的值都与A相等,是子树
if not B:
return True
#A的值先递归完了,B的值还剩,A中无完全与B相等
if not A or A.val != B.val:
return False
#A,B值相等时递归左右子树
return recur(A.left, B.left) and recur(A.right, B.right)
#A、B都存在且满足以节点A为根节点的子树包含树 B,树 B是 树 A左/右子树 的子结构条件之一
return bool(A and B) and (recur(A, B) or self.isSubStructure(A.left, B) or self.isSubStructure(A.right, B))
#生成二叉树
s=Solution()
node1=TreeNode(3)
node1.left=TreeNode(4)
node1.right=TreeNode(5)
node1.left.left=TreeNode(1)
node1.left.right=TreeNode(2)
node2=TreeNode(4)
node2.left=TreeNode(1)
print(s.isSubStructure(node1,node2)) #True
18.二叉树的镜像
请完成一个函数,输入一个二叉树,该函数输出它的镜像。
例如输入:
4
/
2 7
/ \ /
1 3 6 9
镜像输出:
4
/
7 2
/ \ /
9 6 3 1
递归:
- 终止条件: 当节点 root为空时(即越过叶节点),则返回 null;
- 开启递归 右子节点 mirrorTree(root.right),并将返回值作为 root的 左子节点 。
开启递归 左子节点 mirrorTree(tmp) ,并将返回值作为 root的 右子节点- 返回值: 返回当前节点 rootroo**t
#定义树
class TreeNode:
def __init__(self, x):
self.val = x
self.left = None
self.right = None
#二叉树镜像
class Solution:
def mirrorTree(self, root: TreeNode) -> TreeNode:
if not root: return
#递归并交换左右节点
root.left, root.right = self.mirrorTree(root.right), self.mirrorTree(root.left)
return root
#生成二叉树
s=Solution()
node1=TreeNode(4)
node1.left=TreeNode(2)
node1.right=TreeNode(7)
node1.left.left=TreeNode(1)
node1.left.right=TreeNode(3)
node1.right.left=TreeNode(6)
node1.right.right=TreeNode(9)
resu=s.mirrorTree(node1)
#层序遍历打印二叉树,bfs
def levelOrder(root: TreeNode):
queue = []
res = []
if root == None:
return res
queue.append(root)
while queue:
newNode = queue.pop(0)
res.append(newNode.val)
if newNode.left != None:
queue.append(newNode.left)
if newNode.right != None:
queue.append(newNode.right)
return res
print(levelOrder(resu))#[4, 7, 2, 9, 6, 3, 1]
19.顺时针打印矩阵
输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字。
示例 1:
输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
输出:[1,2,3,6,9,8,7,4,5]
示例 2:
设定边界:
空值处理: 当 matrix 为空时,直接返回空列表 [] 即可。
初始化: 矩阵 左、右、上、下 四个边界 l , r , t , b ,用于打印的结果列表 res 。
循环打印: “从左向右、从上向下、从右向左、从下向上” 四个方向循环,每个方向打印中做以下三件事 (各方向的具体信息见下表) ;
根据边界打印,即将元素按顺序添加至列表 res 尾部;
边界向内收缩 11 (代表已被打印);
判断是否打印完毕(边界是否相遇),若打印完毕则跳出。
返回值: 返回 res 即可。打印方向 、1. 根据边界打印 2. 边界向内收缩 3. 是否打印完毕
从左向右 左边界l ,右边界 r 上边界 t 加 1 是否 t > b
从上向下 上边界 t ,下边界b 右边界 r 减 1 是否 l > r
从右向左 右边界 r ,左边界l 下边界 b 减 1 是否 t > b
从下向上 下边界 b ,上边界t 左边界 l 加 1 是否 l > r
class Solution:
def spiralOrder(self, matrix:[[int]]) -> [int]:
if not matrix: return []
l, r, t, b, res = 0, len(matrix[0]) - 1, 0, len(matrix) - 1, []
while True:
#从左到右到达上右边界,向下+1
for i in range(l, r + 1):
res.append(matrix[t][i]) # left to right
t += 1
if t > b: break
# 从上往下到达右下边界,向右-1
for i in range(t, b + 1):
res.append(matrix[i][r]) # top to bottom
r -= 1
if l > r: break
# 从右往左到达左下边界(每次向右-1),向下-1
for i in range(r, l - 1, -1):
res.append(matrix[b][i]) # right to left
b -= 1
if t > b: break
# 从下到上到达左上边界(每次向下-1),向上-1
for i in range(b, t - 1, -1):
res.append(matrix[i][l]) # bottom to top
l += 1
if l > r: break
return res
#测试用例
if __name__=='__main__':
s=Solution()
print(s.spiralOrder([[1,2,3],[4,5,6],[7,8,9]]))#[1,2,3,6,9,8,7,4,5]
20.包含min函数的栈
定义栈的数据结构,请在该类型中实现一个能够得到栈的最小元素的 min 函数在该栈中,调用 min、push 及 pop 的时间复杂度都是 O(1)。
示例:
MinStack minStack = new MinStack();
minStack.push(-2);
minStack.push(0);
minStack.push(-3);
minStack.min(); --> 返回 -3.
minStack.pop();
minStack.top(); --> 返回 0.
minStack.min(); --> 返回 -2.
辅助栈:
一个常规列表实现栈的操作外,再开一个辅助栈用于保存当前的最小信息
- 入栈操作:当辅助栈为空或者辅助栈顶元素小于新元素时,辅助栈入栈;否则无视
- 出栈操作:当常规栈中待出栈的元素等于辅助栈顶元素时,辅助栈出栈一个元素,代表当前的最小值出队或者次数减1
- 栈顶操作:仅需从常规栈顶取元素即可
- 最小值操作:因为辅助栈中维护的都是当前状态下的最小值,所以从辅助栈顶取元素即可
#包含min函数的栈
class MinStack():
def __init__(self):
self.stack=[]
self.mini=[]
#入栈
def push(self, x: int) -> None:
self.stack.append(x)
if self.mini and self.mini[-1]<x:
self.mini.append(self.mini[-1])
else:
self.mini.append(x)
#出栈
def pop(self) -> None:
if not self.stack:
return
x = self.stack.pop()
if self.mini and self.mini[-1] == x:
self.mini.pop()
#栈顶
def top(self) -> int:
if self.stack:
return self.stack[-1]
return None
#最小值
def min(self) -> int:
if self.mini:
return self.mini[-1]
return None
if __name__=='__main__':
m=MinStack()
m.push(-2)
m.push(0)
m.push(-3)
print(m.min())#-3
m.pop()
print(m.top())#0
print(m.min())#-2
21.栈的压入弹出队列
输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否为该栈的弹出顺序。假设压入栈的所有数字均不相等。例如,序列 {1,2,3,4,5} 是某栈的压栈序列,序列 {4,5,3,2,1} 是该压栈序列对应的一个弹出序列,但 {4,3,5,1,2} 就不可能是该压栈序列的弹出序列。
示例 1:
输入:pushed = [1,2,3,4,5], popped = [4,5,3,2,1]
输出:true
解释:我们可以按以下顺序执行:
push(1), push(2), push(3), push(4), pop() -> 4,
push(5), pop() -> 5, pop() -> 3, pop() -> 2, pop() -> 1
用一个辅助栈 stack ,模拟 压入 / 弹出操作的排列
- 初始化: 辅助栈 stack ,弹出序列的索引 i ;
- 遍历压栈序列: 各元素记为 num ;元素 num 入栈;
- 循环出栈:若 stack 的栈顶元素 == 弹出序列元素 popped[i],则执行出栈与 i++;
- stack为空,则此弹出序列合法
#栈的压入弹出序列
class Solution():
def validateStackSequences(self, pushed, popped) -> bool:
#辅助栈stack模拟出栈
stack, i = [], 0
for num in pushed:
stack.append(num) # num 入栈
while stack and stack[-1] == popped[i]: # 循环判断与出栈
stack.pop()
i += 1
return not stack
if __name__=='__main__':
s=Solution()
print(s.validateStackSequences([1,2,3,4,5],[4,5,3,2,1]))#True
print(s.validateStackSequences([1, 2, 3, 4, 5], [4, 5, 3, 1, 2]))#False
22.从上往下打印二叉树
从上到下打印出二叉树的每个节点,同一层的节点按照从左到右的顺序打印。
示例:
给定二叉树: [3,9,20,null,null,15,7],
3
/
9 20
/
15 7
返回:
[3,9,20,15,7]
层序遍历 BFS+递归
- 特例处理: 当树的根节点为空,则直接返回空列表 [] ;
- 初始化: 打印结果列表 res = [] ,包含根节点的队列 queue = [root] ;
- queue 为空时跳出;
- 出队: 队首元素出队,记为 newNode;
- 打印: 将 newNode.val 添加至列表 res 尾部;
- 添加子节点: 若 newNode 的左(右)子节点不为空,则将左(右)子节点加入队列 queue ;
- 返回值: 返回打印结果列表 res 即可。
#定义树
class TreeNode:
def __init__(self, x):
self.val = x
self.left = None
self.right = None
#层序遍历打印二叉树,bfs
class Solution():
#用一个辅助栈queue前序遍历二叉树,通过newNode将其队首出栈,实现层序遍历
#将val的值放入结果栈res中
def levelOrder(self,root: TreeNode):
queue = []
res = []
if root == None:
return res
queue.append(root)
while queue:
newNode = queue.pop(0)
res.append(newNode.val)
if newNode.left != None:
queue.append(newNode.left)
if newNode.right != None:
queue.append(newNode.right)
return res
#生成二叉树
s=Solution()
node1=TreeNode(3)
node1.left=TreeNode(9)
node1.right=TreeNode(20)
node1.right.left=TreeNode(15)
node1.right.right=TreeNode(7)
print(s.levelOrder(node1))#[3, 9, 20, 15, 7]
23.二叉搜索树的后序遍历
输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历结果。如果是则返回 true,否则返回 false。假设输入的数组的任意两个数字都互不相同。
参考以下这颗二叉搜索树:
5
/ \
2 6
/
1 3
示例 :
输入: [1,6,3,2,5] 输出: false
输入: [1,3,2,6,5] 输出: true
递归+分治:
后序遍历定义: [ 左子树 | 右子树 | 根节点 ] ,即遍历顺序为 “左、右、根” 。
二叉搜索树定义: 左子树中所有节点的值 << 根节点的值;右子树中所有节点的值 >> 根节点的值;其左、右子树也分别为二叉搜索树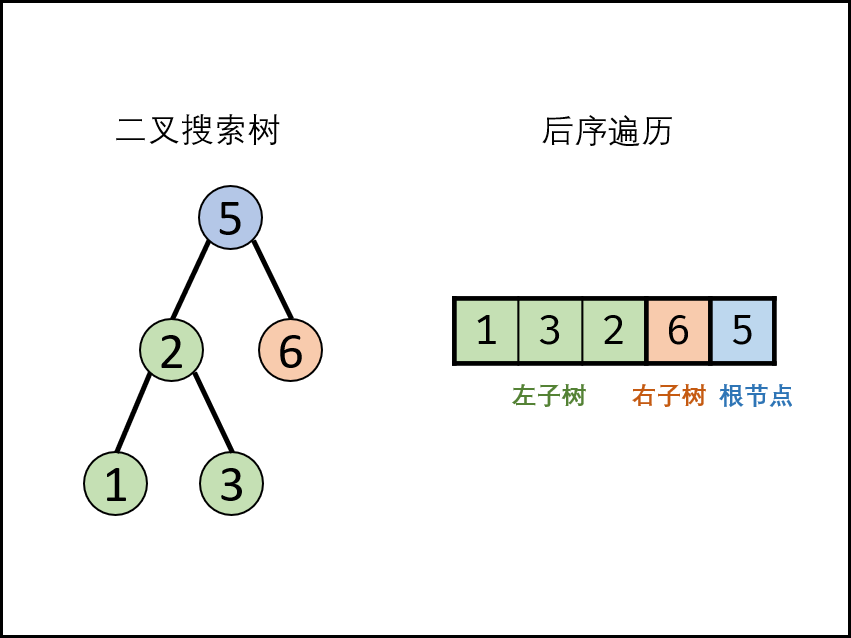
- 终止条件: 当 i≥j ,说明此子树节点数量 ≤1 ,无需判别正确性,因此直接返回 true ;
- 递推工作:
- 划分左右子树: 遍历后序遍历的 \([i, j]\) 区间元素,寻找 第一个大于根节点 的节点,索引记为 m。此时,可划分出左子树区间 \([i,m-1]\) 、右子树区间 \([m, j - 1]\) 、根节点索引 j。
- 判断是否为二叉搜索树:
左子树区间 内\([i,m-1]\)的所有节点都应 <postorder[j]。而第 1.划分左右子树 步骤已经保证左子树区间的正确性,因此只需要判断右子树区间即可。
右子树区间 \([m, j - 1]\)内的所有节点都应 > postorder[j]。实现方式为遍历,当遇到 \leq \(postorder[j]≤postorder[j]\) 的节点则跳出;则可通过 p = j判断是否为二叉搜索树。- 返回值: 所有子树都需正确才可判定正确,因此使用 与逻辑符 and 连接。
p = j : 判断 此树 是否正确。
recur(i, m - 1): 判断 此树的左子树 是否正确。
recur(m, j - 1): 判断 此树的右子树 是否正确
#定义树
class TreeNode:
def __init__(self, x):
self.val = x
self.left = None
self.right = None
#二叉搜索树后序遍历
class Solution():
def verifyPostorder(self, postorder) -> bool:
def recur(i, j):
if i >= j:
return True
p = i
#最右节点是根节点,通过遍历,查找出第一个比根大的节点,记为m
while postorder[p] < postorder[j]:
p += 1
m = p
#继续向后遍历,看右子树区间是不是都比跟节点大
#右子树区间开头第一个比根大,左子树区间都比根小
while postorder[p] > postorder[j]:
p += 1
#此树,此树左子树,右子树都正确才正确
return p == j and recur(i, m - 1) and recur(m, j - 1)
return recur(0, len(postorder) - 1)
s=Solution()
print(s.verifyPostorder([1,6,3,2,5]))#False
print(s.verifyPostorder([1,3,2,6,5]))#True
24.二叉树中和为某一路径值
输入一棵二叉树和一个整数,打印出二叉树中节点值的和为输入整数的所有路径。从树的根节点开始往下一直到叶节点所经过的节点形成一条路径。
示例:
给定如下二叉树,以及目标和 sum = 22,
5
/ \
4 8
/ / \
11 13 4
/ \ / \
7 2 5 1
返回:
[
[5,4,11,2],
[5,8,4,5]
]
先序遍历+递归回溯:
先序遍历: 按照 “根、左、右” 的顺序,遍历树的所有节点。
路径记录: 在先序遍历中,记录从根节点到当前节点的路径。当路径为 ① 根节点到叶节点形成的路径 且 ② 各节点值的和等于目标值 sum 时,将此路径加入结果列表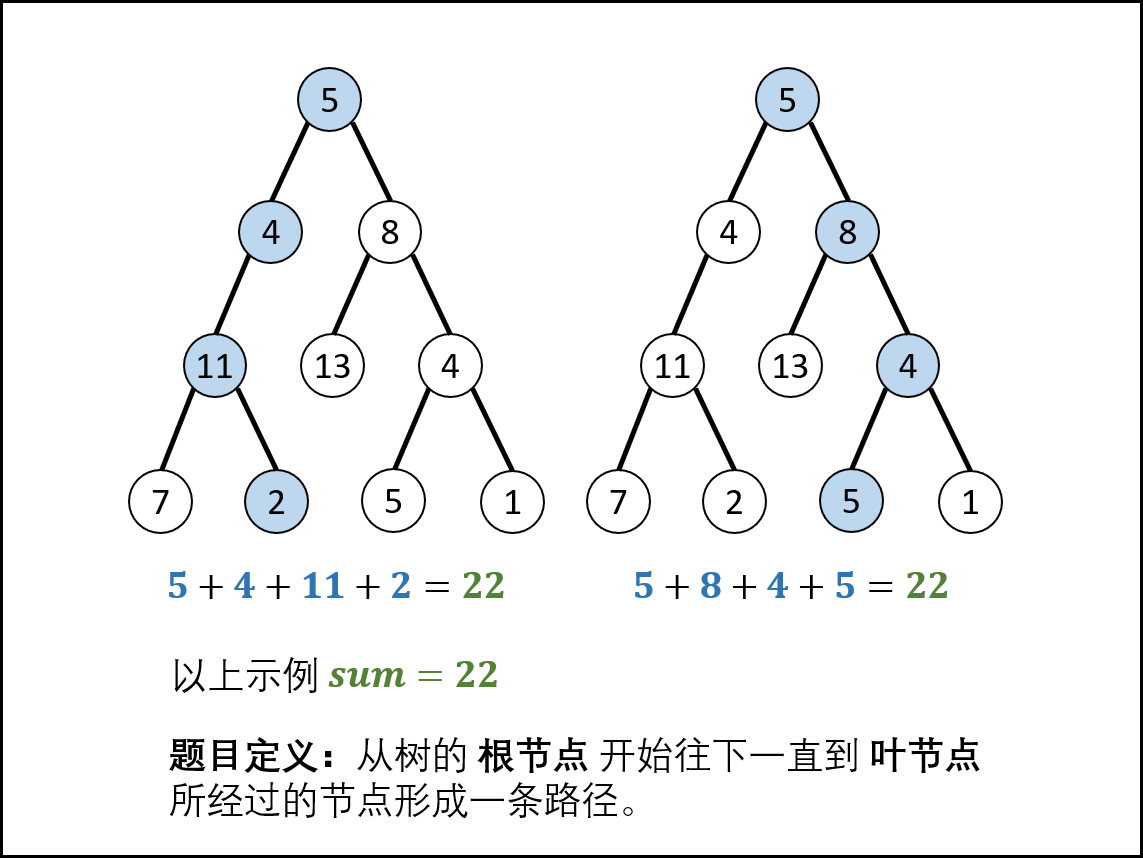
pathSum(root, sum) 函数:
- 初始化: 结果列表 res ,路径列表 path 。
- 返回值: 返回 res 即可。
recur(root, tar) 函数:(多个递归函数,主要避免递归时把res,path重置为[])
- 递推参数: 当前节点 root ,当前目标值 tar 。
- 终止条件: 若节点 root 为空,则直接返回。
- 递推工作:
- 路径更新: 将当前节点值 root.val 加入路径 path ;
- 目标值更新: tar = tar - root.val(即目标值 tar 从 sum 减至 00 );
- 路径记录: 当 ① root 为叶节点 且 ② 路径和等于目标值 ,则将此路径 path 加入 res 。
- 先序遍历: 递归左 / 右子节点。
- 路径恢复: 向上回溯前,需要将当前节点从路径 path 中删除,即执行 path.pop()
#定义树
class TreeNode:
def __init__(self, x):
self.val = x
self.left = None
self.right = None
class Solution:
def pathSum(self, root: TreeNode, sum: int) :
#记录结果、路径
res, path = [], []
def recur(root, tar):
if not root: return
#记录路径
path.append(root.val)
tar -= root.val
#路径达到目标值,保存到结果
if tar == 0 and not root.left and not root.right:
res.append(list(path))
#先序遍历树
recur(root.left, tar)
recur(root.right, tar)
#在路径中删除当前节点,向上回溯
path.pop()
recur(root, sum)
return res
#生成二叉树
node1=TreeNode(5)
node1.left=TreeNode(4)
node1.right=TreeNode(8)
node1.left.left=TreeNode(11)
node1.right.left=TreeNode(13)
node1.right.right=TreeNode(4)
node1.left.left.left=TreeNode(7)
node1.left.left.right=TreeNode(2)
node1.right.right.left=TreeNode(5)
node1.right.right.right=TreeNode(1)
s=Solution()
print(s.pathSum(node1,22))#[[5, 4, 11, 2], [5, 8, 4, 5]]
25.复杂链表的复制
请实现 copyRandomList 函数,复制一个复杂链表。在复杂链表中,每个节点除了有一个 next 指针指向下一个节点,还有一个 random 指针指向链表中的任意节点或者 null。
示例 :

输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
DFS深度查询+hashmap
- 从头结点 head 开始拷贝;
- 由于一个结点可能被多个指针指到,因此如果该结点已被拷贝,则不需要重复拷贝;
- 如果还没拷贝该结点,则创建一个新的结点进行拷贝,并将拷贝过的结点保存在哈希表中;
- 使用递归拷贝所有的 next 结点,再递归拷贝所有的 random 结点
#定义链表
class Node:
def __init__(self, x, next=None, random=None):
self.val = x
self.next = next
self.random = random
class Solution:
def copyRandomList(self, head) :
def dfs(head):
if not head: return None
if head in visited:
return visited[head]
# 创建新结点
copy = Node(head.val, None, None)
#新节点记录在hash表中
visited[head] = copy
#递归遍历链表
copy.next = dfs(head.next)
copy.random = dfs(head.random)
return copy
visited = {}
return dfs(head)
#生成复杂链表
node1=Node(7)
node1.next=Node(13)
node1.random=Node(None)
node1.next.next=Node(11)
node1.next.random=Node(7)
node1.next.next.next=Node(10)
node1.next.next.random=Node(1)
node1.next.next.next.next=Node(1)
node1.next.next.next.random=Node(11)
node1.next.next.next.next.random=Node(7)
s=Solution()
reu=s.copyRandomList(node1)
#打印复杂链表
stack1=[]
def Clone(head):
stack2 = []
if not head:
return
newNode = Node(head.val)
stack2.append(newNode.val)
stack1.append(stack2)
newNode.random = Clone(head.random)
newNode.next = Clone(head.next)
return stack1
print(Clone(reu))#[[7], [None], [13], [7], [11], [1], [10], [11], [1], [7]]
26.二叉搜索树与双向链表
输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的循环双向链表。要求不能创建任何新的节点,只能调整树中节点指针的指向。
以下面的二叉搜索树为例:
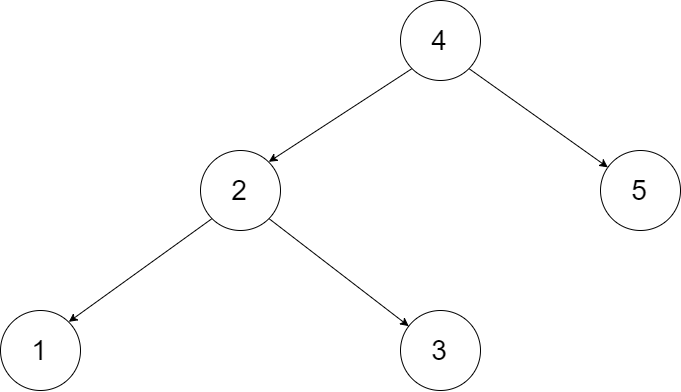
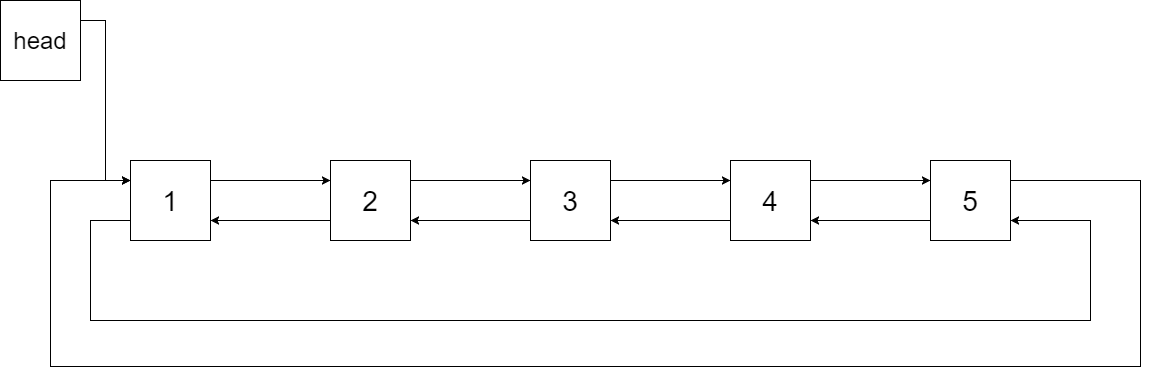
将这个二叉搜索树转化为双向循环链表。链表中的每个节点都有一个前驱和后继指针。对于双向循环链表,第一个节点的前驱是最后一个节点,最后一个节点的后继是第一个节点。
下图展示了上面的二叉搜索树转化成的链表。“head” 表示指向链表中有最小元素的节点。
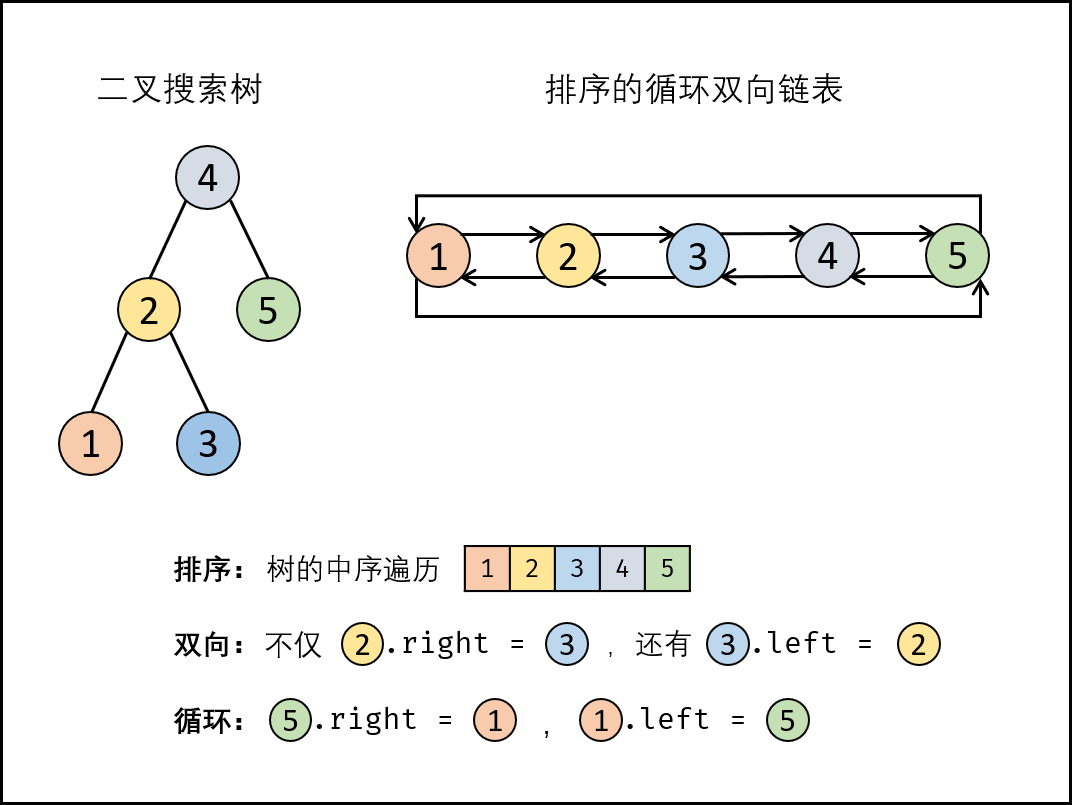
中序遍历+双指针
- 排序链表: 节点应从小到大排序,因此应使用 中序遍历 “从小到大”访问树的节点;
- 双向链表: 在构建相邻节点(设前驱节点 pre ,当前节点 cur )关系时,不仅应 pre.right = cur ,也应 cur.left = pre 。
- 循环链表: 设链表头节点 head和尾节点 tail ,则应构建 head.left = tail 和 tail.right = head
#定义树:
class TreeNode:
def __init__(self, val, left=None, right=None):
self.val = val
self.left = left
self.right = right
class Solution:
def treeToDoublyList(self, root: 'Node') -> 'Node':
def dfs(cur):
if not cur:
return
dfs(cur.left)# 递归左子树
if self.pre:# 修改节点引用
self.pre.right,cur.left=cur,self.pre
else:# prepre 为空时,正在访问头节点
self.head=cur
self.pre=cur # 保存 当前节点cur
dfs(cur.right)# 递归右子树
if not root:
return
self.pre=None
dfs(root)
#self.head.left,self.pre.right=self.pre,self.head#循环链表头尾
return self.head
#生成树
node1=TreeNode(5)
node1.left=TreeNode(2)
node1.right=TreeNode(6)
node1.left.left=TreeNode(1)
node1.left.right=TreeNode(3)
s=Solution()
resu=s.treeToDoublyList(node1)
#从头到尾打印链表
def reversePrint(head):
stack = []
while head:
stack.append(head.val)
head = head.right
return stack
print(reversePrint(resu))#[1, 2, 3, 5, 6]
27.字符串的排列
输入一个字符串,打印出该字符串中字符的所有排列。
你可以以任意顺序返回这个字符串数组,但里面不能有重复元素。
示例:
输入:s = "abc"
输出:["abc","acb","bac","bca","cab","cba"]
递归剪枝(重复continue)+回溯(字符交换)
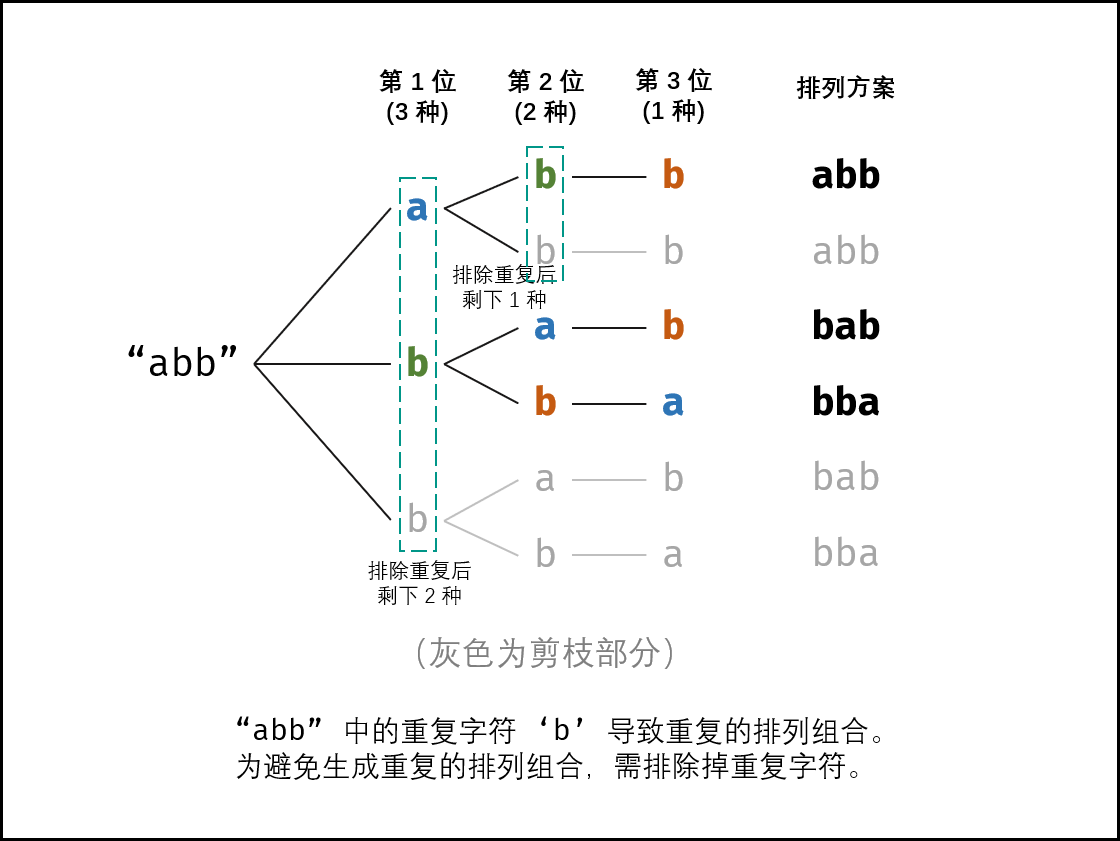
- 终止条件: 当 x = len(c) - 1x=len(c)−1 时,代表所有位已固定(最后一位只有 11 种情况),则将当前组合 c 转化为字符串并加入 res,并返回;
- 递推参数: 当前固定位 x ;
- 递推工作: 初始化一个 Set ,用于排除重复的字符;将第 x位字符与 \(i \in [x, len(c)]\) 字符分别交换,并进入下层递归;
- 剪枝: 若 c[i]在 Set 中,代表其是重复字符,因此“剪枝”;
将 c[i]加入 Set ,以便之后遇到重复字符时剪枝;- 固定字符: 将字符 c[i] 和 c[x]交换,即固定 c[i]为当前位字符;
- 开启下层递归: 调用 dfs(x + 1) ,即开始固定第 x + 1个字符;
- 还原交换: 将字符 c[i]和 c[x]交换(还原之前的交换)
class Solution:
def permutation(self, s: str) :
c, res = list(s), []
def dfs(x):
if x == len(c) - 1:
res.append(''.join(c)) # 添加排列方案
return
dic = set()
for i in range(x,len(c)):
if c[i] in dic:
continue # 重复,因此剪枝
dic.add(c[i])
c[i], c[x] = c[x], c[i] #交换,将 c[i] 固定在第 x 位
dfs(x + 1) # 开启固定第 x + 1 位字符
c[i], c[x] = c[x], c[i] # 恢复交换
dfs(0)
return res
if __name__=='__main__':
s=Solution()
print(s.permutation('abb'))#['abb', 'bab', 'bba']
28.数组中出现次数超过一半的数
数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字。
你可以假设数组是非空的,并且给定的数组总是存在多数元素。
示例 :
输入: [1, 2, 3, 2, 2, 2, 5, 4, 2]
输出: 2
用sorted()排序后,找中间位
class Solution(object):
def majorityElement(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
if not nums:
return None
nums.sort()
return nums[len(nums) //2]
if __name__=='__main__':
s=Solution()
print(s.majorityElement([1, 2, 3, 2, 2, 2, 5, 4, 2]))#2
摩尔投票法:
- 票数和: 由于众数出现的次数超过数组长度的一半;若记 众数 的票数为 +1 ,非众数 的票数为 -1− ,则一定有所有数字的 票数和 > 0 。
- 票数正负抵消: 设数组 nums 中的众数为 x ,数组长度为 n。若 nums 的前 a个数字的 票数和 = 0 ,则 数组后 (n-a) 个数字的 票数和一定仍 >0 (即后 (n-a)个数字的 众数仍为 x )
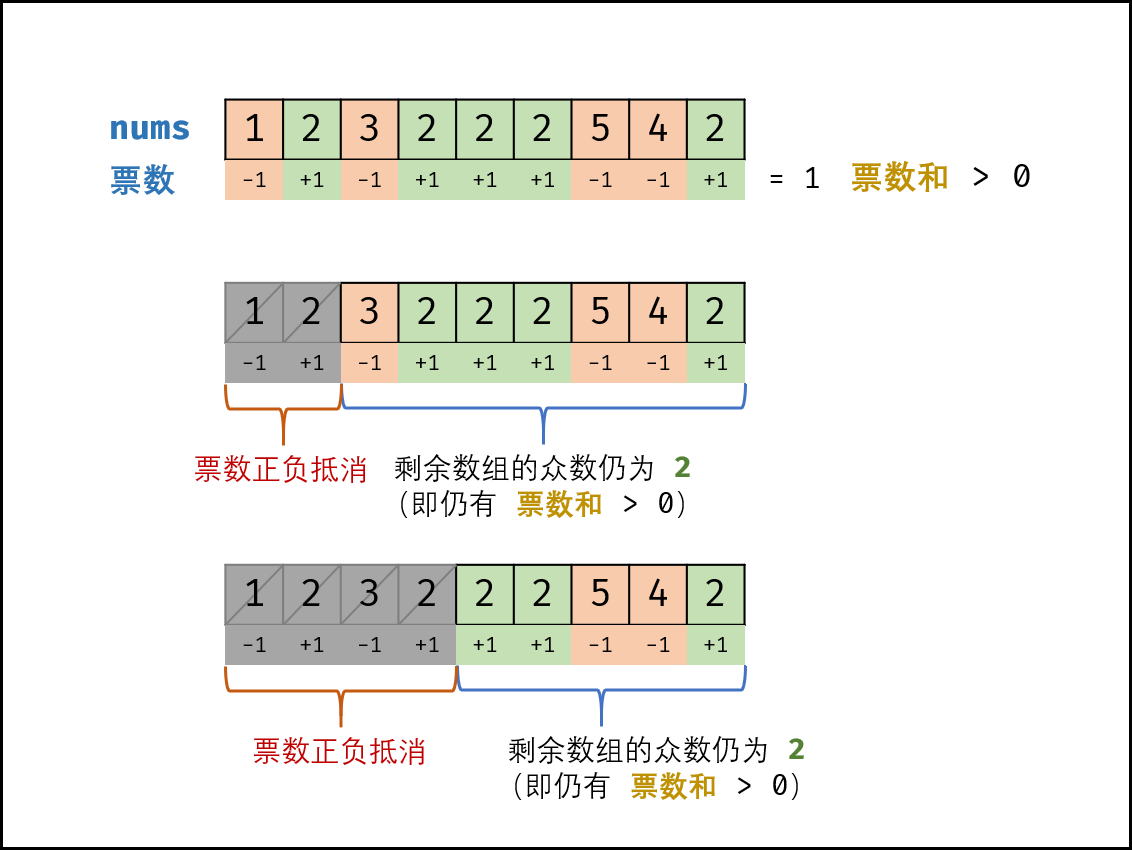
class Solution:
def majorityElement(self, nums: List[int]) -> int:
votes = 0
for num in nums:
#初始化众数是第一个数,抵消后设下一个为众数
if votes == 0:
x = num
#遍历数组,和众数相等+1,不相等-1
votes += 1 if num == x else -1
return x
if __name__=='__main__':
s=Solution()
print(s.majorityElement([1, 2, 3, 2, 2, 2, 5, 4, 2]))#2
29.最小的k个数
输入整数数组 arr ,找出其中最小的 k 个数。例如,输入4、5、1、6、2、7、3、8这8个数字,则最小的4个数字是1、2、3、4。
示例 :
输入:arr = [3,2,1], k = 2
输出:[1,2] 或者 [2,1]
构建大顶堆
堆分为大顶堆和小顶堆,满足Key[i]>=Key[2i+1]&&key>=key[2i+2]称为大顶堆,满足 Key[i]<=key[2i+1]&&Key[i]<=key[2i+2]称为小顶堆
大顶堆:每个结点的值都大于或等于其左右孩子结点的值。
小顶堆:每个结点的值都小于或等于其左右孩子结点的值一般我们说
topK问题,就可以用大顶堆或小顶堆来实现,
最大的 K 个:小顶堆
最小的 K 个:大顶堆
- 对于每一个节点而言,他的左孩子节点编号时\(2 * (index+1)\),右孩子节点编号是\(2 * (index+2)\)
- 【非叶子节点下标=节点个数//2-1 :即若root从0开始,则 从 0~节点个数//2-1 这个闭区间范围内都是非叶子节点,节点个数//2-1之后就是叶子节点了】
- 大顶堆的维护:自底向上的维护,对于叶子节点而言没有左孩子右孩子,因为大顶堆要求左孩子右孩子都小于父节点,所以不考虑叶子节点,直接从非叶子节点开始.
- 大顶堆的建立总结:从非叶子节点开始维护,维护的过程中根据大顶堆的性质(节点元素大于左右节点元素的值)判断当前节点应该处于大顶堆的什么位置。
- 取数组前k个元素初始化堆,从最后一个非叶结点开始到根结点来构建最大堆
- 遍历剩下的n-k个元素
- 当某个元素大于堆顶元素时,直接抛弃
- 当某个元素小于堆顶元素时,替换堆顶元素,再从堆顶重新构建最大堆
class Solution:
def getLeastNumbers(self, arr, k: int):
if not arr or k == 0:
return []
if len(arr) <= k:
return arr
#初始化一个k个元素的堆
heap = arr[:k]
#初始化堆的函数
def buildMaxHeap(pos):
#左节点不能大于构建的堆大小
while pos * 2 + 1 < k:
#初始化最大元素为左孩子
max_pos = pos * 2 + 1
if pos * 2 + 2 < k and heap[pos * 2 + 2] > heap[pos * 2 + 1]:#存在右节点,且右节点大于左节点
max_pos += 1#取最大元素为右孩子的值
#当前节点比最大元素小,交换
if heap[pos] < heap[max_pos]:
heap[pos], heap[max_pos] = heap[max_pos], heap[pos]
pos = max_pos#更新当前节点
else:
break
#模拟k个节点的堆结构,从非叶子节点k // 2-1开始维护
for i in range(k // 2-1, -1, -1):
buildMaxHeap(i)
#遍历剩下的n-k个数,判断是否添加进堆
for i in range(k, len(arr)):
#比堆顶元素小,替换堆顶元素,再从堆顶重新构建大顶堆
if arr[i] < heap[0]:
heap[0] = arr[i]
buildMaxHeap(0)
#否则,抛弃
else:
continue
#遍历完后再返回堆就是
return heap
if __name__=='__main__':
s=Solution()
print(s.getLeastNumbers([1, 5, 3,7,4],2))#【1,3】
30.连续子数组的最大和
输入一个整型数组,数组中的一个或连续多个整数组成一个子数组。求所有子数组的和的最大值。
要求时间复杂度为O(n)。
示例1:
输入: nums = [-2,1,-3,4,-1,2,1,-5,4]
输出: 6
解释: 连续子数组 [4,-1,2,1] 的和最大,为 6。
动态规划:
- 状态定义: 设动态规划列表 dp ,dp[i] 代表以元素 nums[i]为结尾的连续子数组最大和。
- 为何定义最大和 dp[i] 中必须包含元素 nums[i]:保证 dp[i]递推到 dp[i+1]的正确性;如果不包含 nums[i] ,递推时则不满足题目的 连续子数组 要求。
- 转移方程: 若 \(dp[i-1] \leq 0\),说明 dp[i - 1] 对 dp[i] 产生负贡献,即 dp[i-1] + nums[i]还不如 nums[i]本身大。
- 当 \(dp[i - 1] > 0\) 时:执行 dp[i] = dp[i-1] + nums[i] ;
当 \(dp[i - 1] \leq 0\) 时:执行 dp[i] = nums[i];
初始状态: dp[0] = nums[0],即以 nums[0] 结尾的连续子数组最大和为 nums[0] 。- 返回值: 返回 dpdp 列表中的最大值,代表全局最大值。
- 由于 dp[i]dp[i] 只与 dp[i-1]dp[i−1] 和 nums[i]nums[i] 有关系,因此可以将原数组 numsnums 用作 dpdp 列表,即直接在 numsnums 上修改即可。
class Solution:
def maxSubArray(self, nums) -> int:
for i in range(1, len(nums)):
#nums[i-1]>0执行nums[i]+=nums[i-1]nums[i-1]<0执行nums[i]=nums[i],
nums[i] += max(nums[i - 1], 0)
return max(nums)
if __name__=='__main__':
s=Solution()
print(s.maxSubArray( [-2,1,-3,4,-1,2,1,-5,4]))#6
31.从1到n整数中1出现的次数
输入一个整数 n ,求1~n这n个整数的十进制表示中1出现的次数。
例如,输入12,1~12这些整数中包含1 的数字有1、10、11和12,1一共出现了5次。
示例 :
输入:n = 12
输出:5
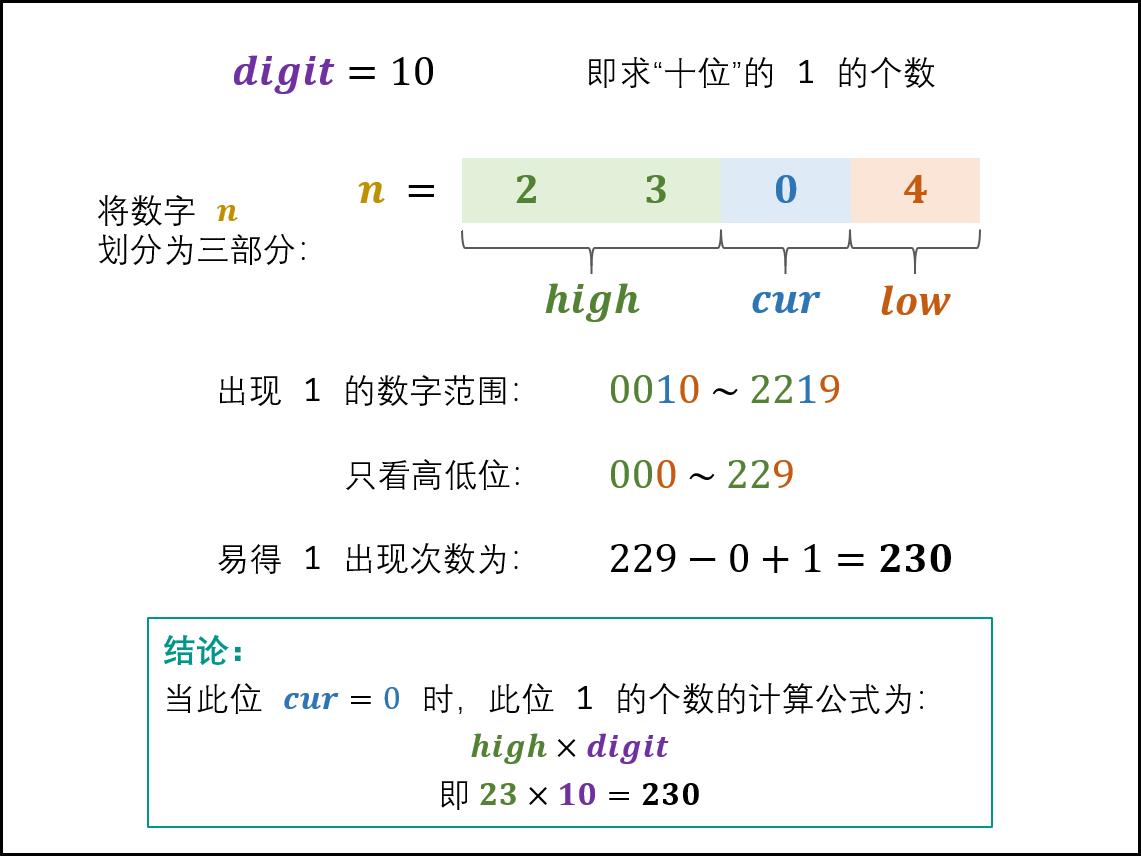
根据当前位 cur值的不同,分为以下三种情况:
当 cur = 0 时: 此位 1 的出现次数只由高位 high决定,计算公式为:
high×digit如下图所示,以 n = 2304 为例,求 digit = 10 (即十位)的 1 出现次数。
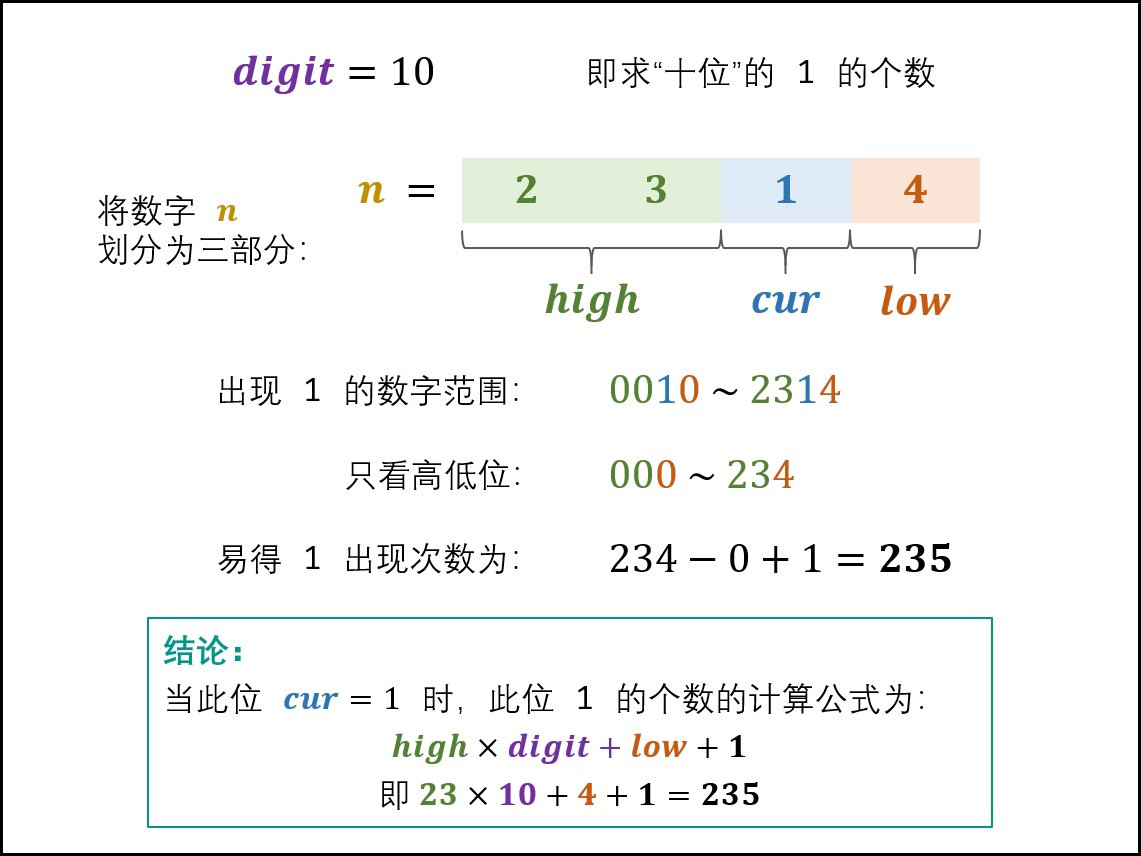
当 cur = 1 时: 此位 1的出现次数由高位 high 和低位 low决定,计算公式为:
\(high×digit+low+1\)如下图所示,以 n = 2314 为例,求 digit = 10(即十位)的 1出现次数。
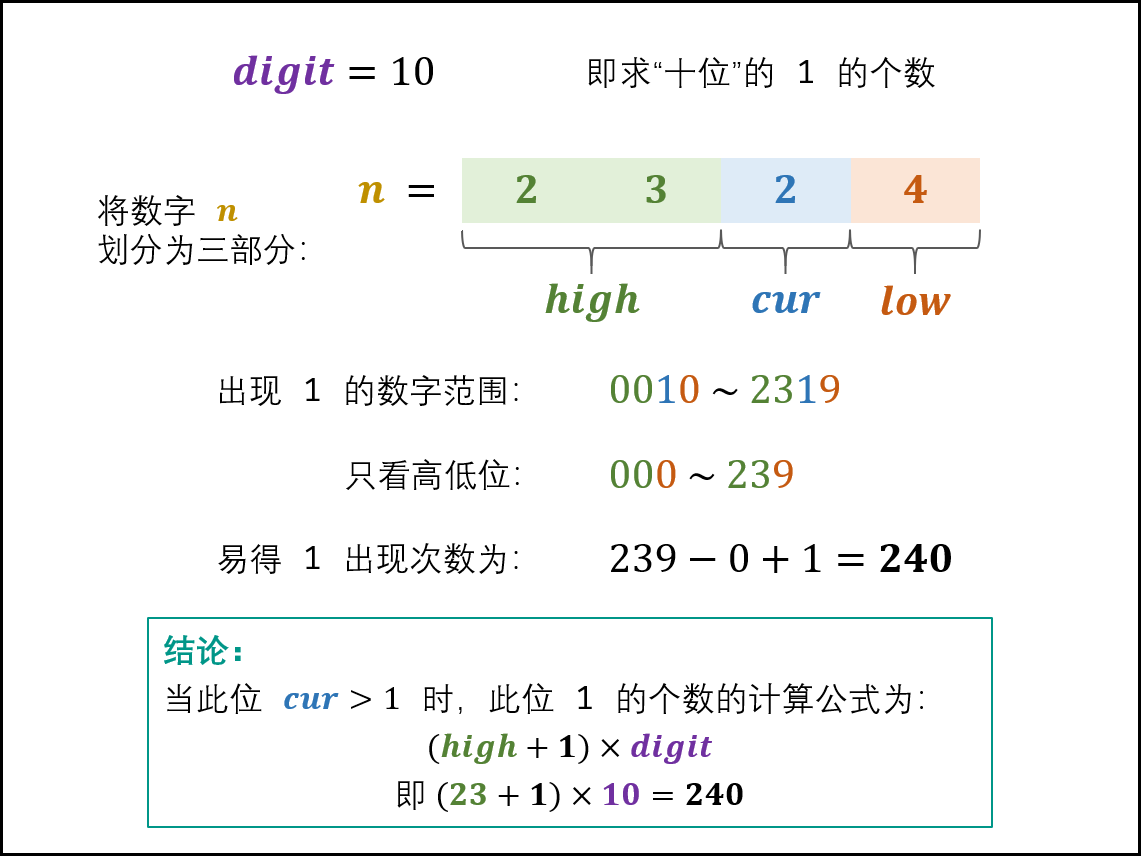
当 cur=2,3,⋯,9 时: 此位 1的出现次数只由高位 high 决定,计算公式为:
\((high+1)×digit\)如下图所示,以 n = 2324 为例,求 digit = 10(即十位)的 1 出现次数。
class Solution:
def countDigitOne(self, n: int) -> int:
digit, res = 1, 0
#初始化高位,当前位,低位
high, cur, low = n // 10, n % 10, 0
while high != 0 or cur != 0:
#当前位为0,只与高位和位因子有关
if cur == 0:
res += high * digit
#当前位为1,low+1为当前位开始所有的1的数量,high * digit为高位出现的1的数量
elif cur == 1:
res += high * digit + low + 1
#当前位为其他数,只与高位和位因子有关
else:
res += (high + 1) * digit
low += cur * digit#低位每次是当前位向先进一位
cur = high % 10#当前位每次为上轮高位的最低位
high //= 10#高位每次删除最低位
digit *= 10#位因子每轮*10
return res
if __name__=='__main__':
s=Solution()
print(s.countDigitOne(12))#5
32.把数组排成最小数
输入一个非负整数数组,把数组里所有数字拼接起来排成一个数,打印能拼接出的所有数字中最小的一个。
示例 :
输入: [10,2]
输出: "102"
双指针排序
- 把原列表转换成字符串列表
- 双指针,i指向前一个数,j指向后一个数
- 有小的排序,交换前后数位置
- 列表转换成字符串返回
class Solution:
def minNumber(self, nums) -> str:
#把原列表转换成字符串列表
nums = list(map(str, nums))
#双指针,指向前一个数,j指向后一个数
for i in range(len(nums) - 1):
for j in range(i + 1, len(nums)):
#有小的排序,交换前后数位置
if nums[i] + nums[j] > nums[j] + nums[i]:
nums[i], nums[j] = nums[j], nums[i]
#列表转换成字符串返回
return ''.join(nums)
if __name__=='__main__':
s=Solution()
print(s.minNumber([10,2]))#102
快速排序:
- 从无序队列中挑取一个元素,把无序队列分割成独立的两部分
- 分割:重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面(与基准值相等的数可以到任何一边)。在这个分割结束之后,对基准值的排序就已经完成
- 定义两个游标,分别指向0和末尾位置
- 让右边游标往左移动,目的是找到小于mid的值,放到left游标位置
- 让左边游标往右移动,目的是找到大于mid的值,放到right游标位置
- 递归处理左边的数据和右边的数据
class Solution:
def minNumber(self, nums) -> str:
#把原列表转换成字符串列表
nums = list(map(str, nums))
self.quick_sort(nums, 0, len(nums) - 1)
return ''.join(nums)
#定义快速排序
def quick_sort(self,li, start, end):
# 分治 一分为二
# start=end ,证明要处理的数据只有一个
# start>end ,证明右边没有数据
if start >= end:
return
# 定义两个游标,分别指向0和末尾位置
left = start
right = end
# 把0位置的数据,认为是中间值
mid = li[left]
while left < right:
# 让右边游标往左移动,目的是找到小于mid的值,放到left游标位置
while left < right and self.is_larger(li[right],mid):
right -= 1
li[left] = li[right]
# 让左边游标往右移动,目的是找到大于mid的值,放到right游标位置
while left < right and self.is_larger(mid,li[left]):
left += 1
li[right] = li[left]
# while结束后,把mid放到中间位置,left=right
li[left] = mid
# 递归处理mid左边的数据
self.quick_sort(li, start, right-1)
# 递归mid处理右边的数据
self.quick_sort(li, left+1 , end)
#区分字符串大小函数
def is_larger(self, str1, str2):
return (str1 + str2) > (str2 + str1)
if __name__=='__main__':
s=Solution()
print(s.minNumber([10,2]))#102
33.丑数
把只包含质因子 2、3 和 5 的数称作丑数(Ugly Number)。求按从小到大的顺序的第 n 个丑数。
示例:
输入: n = 10
输出: 12
解释: 1, 2, 3, 4, 5, 6, 8, 9, 10, 12 是前 10 个丑数
动态规划:
状态定义: 设动态规划列表 dp,dp[i] 代表第 i + 1个丑数。
转移方程:
当索引 a, b, c 满足以下条件时, dp[i]为三种情况的最小值;
每轮计算 dp[i]后,需要更新索引 a, b, c 的值,使其始终满足方程条件。实现方法:分别独立判断 dp[i]和 dp[a]×2 ,dp[b]×3 ,dp[c]×5 的大小关系,若相等则将对应索引 a b , c加 1 。\(dp[a]×2>dp[i−1]≥dp[a−1]×2\)
\(dp[b]×3>dp[i−1]≥dp[b−1]×3\)
\(dp[c]×5>dp[i−1]≥dp[c−1]×5\)
\(dp[i]=min(dp[a]×2,dp[b]×3,dp[c]×5)\)初始状态: dp[0] = 1,即第一个丑数为 1;
返回值: dp[n-1] ,即返回第 n个丑数
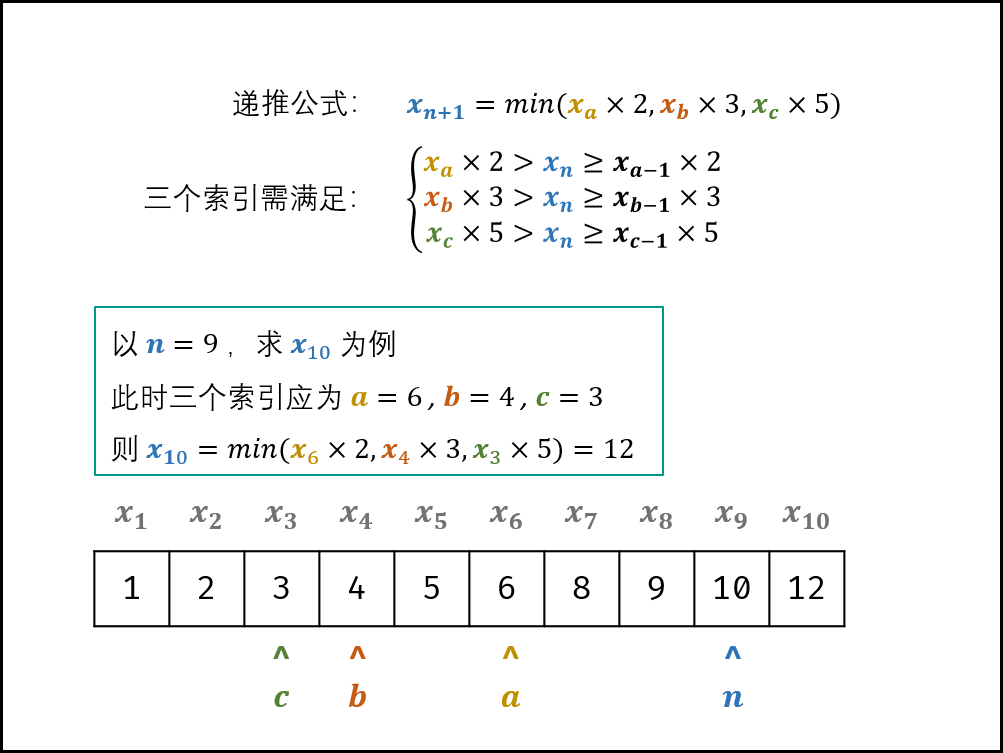
class Solution:
def nthUglyNumber(self, n: int) -> int:
#初始化前n位丑数都为1
dp, a, b, c = [1] *n, 0, 0, 0
for i in range(1, n):
#dp[i]是满足丑数索引情况下的最小值
n2, n3, n5 = dp[a] * 2, dp[b] * 3, dp[c] * 5
dp[i] = min(n2, n3, n5)
#更新索引
if dp[i] == n2: a += 1
if dp[i] == n3: b += 1
if dp[i] == n5: c += 1
#索引的第n-1位是第n位丑数
return dp[-1]
if __name__=='__main__':
s=Solution()
print(s.nthUglyNumber(10))#12
34.第一个只出现一次的字符
在字符串 s 中找出第一个只出现一次的字符。如果没有,返回一个单空格。 s 只包含小写字母。
示例:
s = "abaccdeff"
返回 "b"
s = ""
返回 " "
哈希表:
- 遍历字符串
s,使用哈希表统计 “各字符数量是否 > 1>1 ”。- 再遍历字符串
s,在哈希表中找到首个 “数量为 11 的字符”,并返回
class Solution:
def firstUniqChar(self, s: str) -> str:
if not s:
return -1
#使用字典存储字符数量
count = {}
for i in s:
if i not in count:
count[i] = 1
else:
count[i]+=1
#遍历字典,找到数量为1
for j in count:
if count.get(j) == 1 :
return j
return ''
if __name__=='__main__':
s=Solution()
print(s.firstUniqChar("abaccdeff"))#b
35.数组中的逆序对
在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。输入一个数组,求出这个数组中的逆序对的总数。
示例 :
输入: [7,5,6,4]
输出: 5
归并排序:
- 归并排序的过程会将左右数组都变成有序的升序数组
- 左数组当前值比右数组当前值小,左数组前面的值都比右数组当前值小,无逆序对
- 左数组当前值比右数组当前值大,左数组之后的值都比右数组当前值大,都是逆序,逆序数为len(left)-i
class Solution:
def reversePairs(self, nums) -> int:
if not nums:
return 0
l = 0
r = len(nums) - 1
self.cnt = 0
def merge(l, r):
#当待排序序列中只剩下一个数字时,也就是l == r,终止递归
if l == r:
return [nums[l]]
#从底层逐步向上合并
else:
mid = (r - l) // 2 + l
left = merge(l, mid)
right = merge(mid + 1, r)
i = j = 0
ans = []
while i < len(left) and j < len(right):
#左数组当前值比右数组当前值小,左数组前面的值都比右数组当前值小,无逆序对
if left[i] <= right[j]:
ans.append(left[i])
i += 1
#左数组当前值比右数组当前值大,左数组之后的值都比右数组当前值大,都是逆序,逆序数为len(left)-i
else:
self.cnt += len(left) - i
ans.append(right[j])
j += 1
if i != len(left):
ans += left[i:]
if j != len(right):
ans += right[j:]
return ans
merge(l, r)
return self.cnt
if __name__=='__main__':
s=Solution()
print(s.reversePairs([7,5,6,4]))#5
36.两个链表第一个公共节点
输入两个链表,找出它们的第一个公共节点。
如下面的两个链表:

在节点 c1 开始相交。
双指针:
使用两个指针 node1,node2 分别指向两个链表 headA,headB 的头结点,然后同时分别逐结点遍历,当 node1 到达链表 headA 的末尾时,重新定位到链表 headB 的头结点;当 node2 到达链表 headB 的末尾时,重新定位到链表 headA 的头结点。
这样,当它们相遇时,所指向的结点就是第一个公共结点
#定义链表
class ListNode:
def __init__(self, x):
self.val = x
self.next = None
class Solution():
'''def getIntersectionNode(self, link1: ListNode, link2: ListNode):
if not link1 or not link2:
return None
length1 = length2 = 0
move1, move2 = link1, link2
while move1: # 获取链表长度
length1 += 1
move1 = move1.next
while move2:
length2 += 1
move2 = move2.next
while length1 > length2: # 长链表先走多的长度
length1 -= 1
link1 = link1.next
while length2 > length1:
length2 -= 1
link2 = link2.next
while link1: # 链表一起走
if link1 == link2:
return link1
link1, link2 = link1.next, link2.next
return None'''
def getIntersectionNode(self, headA: ListNode, headB: ListNode) -> ListNode:
node1, node2 = headA, headB
while node1 != node2:
node1 = node1.next if node1 else headB
node2 = node2.next if node2 else headA
return node1
37.数字在排序数组中出现的次数
统计一个数字在排序数组中出现的次数。
示例 :
输入: nums = [5,7,7,8,8,10], target = 8
输出: 2
二分查找:
- 初始化: 左边界 i = 0 ,右边界 j = len(nums) - 1 。
- 循环二分: 当闭区间 \([i, j]\) 无元素时跳出;
- 计算中点 m = (i + j) / 2(向下取整);
- 若 nums[m] < target,则 target在闭区间 \([m + 1, j]\) 中,因此执行 i = m + 1;
- 若 nums[m] > target ,则 target 在闭区间 \([i, m - 1]\) 中,因此执行 j = m - 1;
- 若 nums[m] = target ,则右边界 right在闭区间\([m + 1, j]\) 中;左边界 left 在闭区间 \([m + 1, j]\) 中。因此分为以下两种情况:
若查找 右边界 right ,则执行 i = m + 1 ;(跳出时 i指向右边界)
若查找 左边界 left ,则执行 j = m - 1 ;(跳出时 j指向左边界)- 返回值: 应用两次二分,分别查找 right 和 left ,最终返回 right - left - 1即可
[5,7,7,8,8,10]
38.二叉树的深度
输入一棵二叉树的根节点,求该树的深度。从根节点到叶节点依次经过的节点(含根、叶节点)形成树的一条路径,最长路径的长度为树的深度。
例如:
给定二叉树 [3,9,20,null,null,15,7],
3
/
9 20
/
15 7
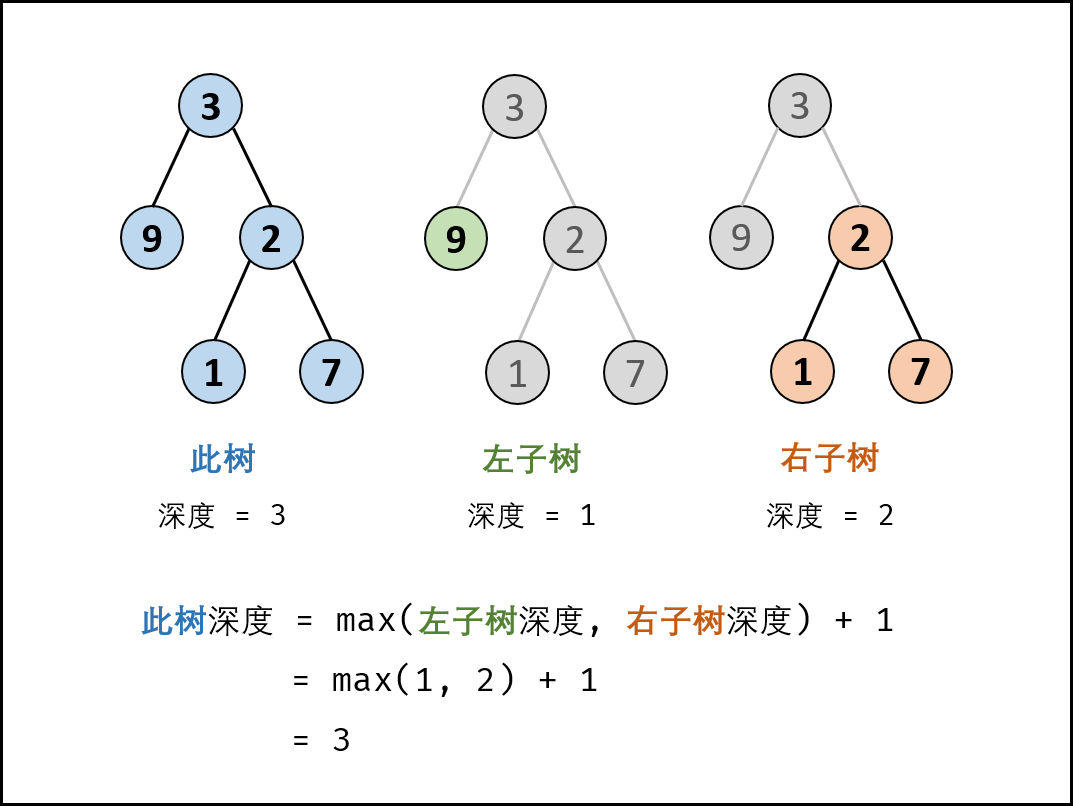
后序遍历(左右根):
- 终止条件: 当 root 为空,说明已越过叶节点,因此返回 深度 00 。
- 递推工作: 本质上是对树做后序遍历。
计算节点 root 的 左子树的深度 ,即调用 maxDepth(root.left);
计算节点 root 的 右子树的深度 ,即调用 maxDepth(root.right)- 树的深度 等于 左子树的深度 与 右子树的深度 中的 最大值 +1
#定义树:
class TreeNode:
def __init__(self, val, left=None, right=None):
self.val = val
self.left = left
self.right = right
class Solution:
def maxDepth(self, root: TreeNode) -> int:
if not root: return 0
return max(self.maxDepth(root.left), self.maxDepth(root.right)) + 1
#生成树
node1=TreeNode(5)
node1.left=TreeNode(9)
node1.right=TreeNode(20)
node1.right.left=TreeNode(15)
node1.right.right=TreeNode(7)
s=Solution()
print(s.maxDepth(node1))#3
39.判断是否是平衡二叉树
输入一棵二叉树的根节点,判断该树是不是平衡二叉树。如果某二叉树中任意节点的左右子树的深度相差不超过1,那么它就是一棵平衡二叉树。
示例 1:
给定二叉树 [3,9,20,null,null,15,7]
3
/
9 20
/
15 7
后序遍历+剪枝
recur(root) 函数:
- 返回值:
当节点root 左 / 右子树的深度差≤1 :则返回当前子树的深度,即节点 root 的左 / 右子树的深度最大值 +1 ( max(left, right) + 1 );
当节点root 左 / 右子树的深度差 > 2:则返回 -1,代表 此子树不是平衡树 。- 终止条件:
当 root 为空:说明越过叶节点,因此返回高度 0 ;
当左(右)子树深度为 -1 :代表此树的 左(右)子树 不是平衡树,因此剪枝,直接返回 -1
#定义树:
class TreeNode:
def __init__(self, val, left=None, right=None):
self.val = val
self.left = left
self.right = right
class Solution:
def isBalanced(self, root: TreeNode) -> bool:
def recur(root):
if not root: return 0
left = recur(root.left)
if left == -1: return -1
right = recur(root.right)
if right == -1: return -1
return max(left, right) + 1 if abs(left - right) <= 1 else -1
return recur(root) != -1
#生成树
node1=TreeNode(5)
node1.left=TreeNode(9)
node1.right=TreeNode(20)
node1.right.left=TreeNode(15)
node1.right.right=TreeNode(7)
s=Solution()
print(s.isBalanced(node1))#True
40.数组中只出现一次的数字
一个整型数组 nums 里除两个数字之外,其他数字都出现了两次。请写程序找出这两个只出现一次的数字。要求时间复杂度是O(n),空间复杂度是O(1)。
示例 :
输入:nums = [4,1,4,6]
输出:[1,6] 或 [6,1]
位运算
异或的性质
两个数字异或的结果a^b是将 a 和 b 的二进制每一位进行运算,得出的数字。 运算的逻辑是
如果同一位的数字相同则为 0,不同则为 1
- 先对所有数字进行一次异或,得到两个出现一次的数字的异或值。
- 在异或结果中找到任意为 1 的位。
- 根据这一位对所有的数字进行分组。
- 在每个组内进行异或操作,得到两个数字
import functools
class Solution:
def singleNumbers(self, nums) :
#先对所有数字进行一次异或,得到两个出现一次的数字的异或值
ret = functools.reduce(lambda x, y: x ^ y, nums)
div = 1
#rec位是0while不结束,继续左移位
while div & ret == 0:
div <<= 1
#找到第一个为1的位
a, b = 0, 0
#a,b对应不同数字
for n in nums:
#与这位同为1的分到同一组,相同的数字被分到一组
if n & div:
a ^= n
#与这位同为0的分到同一组,相同的数字被分到一组
else:
b ^= n
return [a, b]
if __name__=='__main__':
s=Solution()
print(s.singleNumbers(nums = [4,1,4,6]))#[1, 6]
41.和为s的两个数字
输入一个递增排序的数组和一个数字s,在数组中查找两个数,使得它们的和正好是s。如果有多对数字的和等于s,则输出任意一对即可。
示例 :
输入:nums = [2,7,11,15], target = 9
输出:[2,7] 或者 [7,2]
对撞双指针:
- 初始化: 双指针 i , j分别指向数组 nums的左右两端 (俗称对撞双指针)。
- 循环搜索: 当双指针相遇时跳出;
- 计算和 s = nums[i] + nums[j];
若 s > targets ,则指针 j向左移动,即执行 j = j - 1;
若 s < targets ,则指针 i向右移动,即执行 i = i + 1;
若 s = targets ,立即返回数组 [nums[i], nums[j]] ;- 返回空数组,代表无和为 target的数字组合
class Solution:
def twoSum(self, nums, target):
i, j = 0, len(nums) - 1
while i < j:
s = nums[i] + nums[j]
if s > target: j -= 1
elif s < target: i += 1
else: return nums[i], nums[j]
return []
if __name__=='__main__':
s=Solution()
print(s.twoSum([2,7,11,15],9))#(2, 7)
42.和为s的连续正数序列
输入一个正整数 target ,输出所有和为 target 的连续正整数序列(至少含有两个数)。
序列内的数字由小到大排列,不同序列按照首个数字从小到大排列。
示例 :
输入:target = 9
输出:[[2,3,4],[4,5]]
滑动窗口:
- 当窗口的和小于 target 的时候,窗口的和需要增加,所以要扩大窗口,窗口的右边界向右移,窗口多一个j值,要加上
- 当窗口的和大于 target 的时候,窗口的和需要减少,所以要缩小窗口,窗口的左边界向右移,窗口少一个i值,要减去
- 当窗口的和恰好等于 target 的时候,我们需要记录此时的结果。设此时的窗口为 [i, j),那么我们已经找到了一个 i开头的序列,也是唯一一个 i开头的序列,接下来需要找 i+1 开头的序列,所以窗口的左边界要向右移动
class Solution:
def findContinuousSequence(self, target: int):
i = 1 # 滑动窗口的左边界
j = 1 # 滑动窗口的右边界
sum = 0 # 滑动窗口中数字的和
res = []
#必须有两个数,左边界比target // 2大,+右边界(至少左边界+1)一定比target大
while i <= target // 2:
if sum < target:
# 右边界向右移动
sum += j
j += 1
elif sum > target:
# 左边界向右移动
sum -= i
i += 1
else:
# 记录结果
arr = list(range(i, j))
res.append(arr)
# 左边界向右移动
sum -= i
i += 1
return res
if __name__=='__main__':
s=Solution()
print(s.findContinuousSequence(9))#[[2, 3, 4], [4, 5]]
43.翻转单词顺序
输入一个英文句子,翻转句子中单词的顺序,但单词内字符的顺序不变。为简单起见,标点符号和普通字母一样处理。例如输入字符串"I am a student. ",则输出"student. a am I"。
示例 :
输入: "the sky is blue"
输出: "blue is sky the"
双指针:
- 倒序遍历字符串 s ,记录单词左右索引边界 i , j;
- 每确定一个单词的边界,则将其添加至单词列表 res;
- 索引i从右往左搜索首个空格
- 添加单词:首个空格之后的位置到右边界的位置
- I搜索下一个不是空格的位置,找到单词的右边界,将下个单词右边界j设置成i
- 最终,将单词列表拼接为字符串,并返回即可
class Solution:
def reverseWords(self, s: str) -> str:
s = s.strip() # 删除首尾空格
i = j = len(s) - 1#倒序遍历字符串
res = []
while i >= 0:
while i >= 0 and s[i] != ' ':
i -= 1 # 搜索首个空格
res.append(s[i + 1: j + 1]) # 添加单词
while s[i] == ' ':
i -= 1 # 跳过单词间空格
j = i # j 指向下个单词的尾字符
return ' '.join(res) # 拼接并返回
if __name__=='__main__':
s=Solution()
print(s.reverseWords("the sky is blue"))#blue is sky the
44.左旋转字符串
字符串的左旋转操作是把字符串前面的若干个字符转移到字符串的尾部。请定义一个函数实现字符串左旋转操作的功能。比如,输入字符串"abcdefg"和数字2,该函数将返回左旋转两位得到的结果"cdefgab"。
示例 :
输入: s = "abcdefg", k = 2
输出: "cdefgab"
切片:
获取字符串 s[n:]s[n:] 切片和 s[:n]s[:n] 切片,使用 "++" 运算符拼接并返回即可
class Solution:
def reverseLeftWords(self, s: str, n: int) -> str:
return s[n:] + s[:n]
if __name__=='__main__':
s=Solution()
print(s.reverseLeftWords("abcdefg",2))#cdefgab
45.n个骰子的点数
把n个骰子扔在地上,所有骰子朝上一面的点数之和为s。输入n,打印出s的所有可能的值出现的概率。
你需要用一个浮点数数组返回答案,其中第 i 个元素代表这 n 个骰子所能掷出的点数集合中第 i 小的那个的概率。
示例 :
输入: 1
输出: [0.16667,0.16667,0.16667,0.16667,0.16667,0.16667]
动态规划:
- n个骰子,一共有6**n种情况
- n=1, 和为s的情况有 F(n,s)=1 s=1,2,3,4,5,6
- n>1 , F(n,s) = F(n-1,s-1)+F(n-1,s-2) +F(n-1,s-3)+F(n-1,s-4)+F(n-1,s-5)+F(n-1,s-6)
可以看作是从前(n-1)个骰子投完之后的状态转移过来。
其中F(N,S)表示投第N个骰子时,点数和为S的次数
class Solution:
def twoSum(self, n: int):
#初始化二维数组,行为n个骰子,列为n个骰子一面朝上的点数和有6*n+1种可能
dp = [[0 for j in range(6*n+1)]for i in range(n+1)]
#初始化0个骰子,和为0的次数为1
dp[0][0]=1
#第n个骰子
for i in range(1,n+1):
#第n个骰子点数和为6*n
for j in range(i,6*i+1):
for k in range(1,7):
if j-k>=0:
#F(n,s) = F(n-1,s-1)+F(n-1,s-2) +F(n-1,s-3)+F(n-1,s-4)+F(n-1,s-5)+F(n-1,s-6)
dp[i][j]+=dp[i-1][j-k]
print(dp)#[[1, 0, 0, 0, 0, 0, 0], [0, 1, 1, 1, 1, 1, 1]]
#dp[n][n:]第n个骰子,和为s的次数,x从中取和/总的和的可能(1/6)**n
res = list(map(lambda x:x*(1/6)**n,dp[n][n:]))
return res
if __name__=='__main__':
s=Solution()
print(s.twoSum(1))#[0.16667,0.16667,0.16667,0.16667,0.16667,0.16667]
45.扑克牌中的顺子
从扑克牌中随机抽5张牌,判断是不是一个顺子,即这5张牌是不是连续的。2~10为数字本身,A为1,J为11,Q为12,K为13,而大、小王为 0 ,可以看成任意数字。A 不能视为 14。
示例 :
输入: [1,2,3,4,5]
输出: True
集合:
- 除大小王外,所有牌 无重复 ;
- 设此 55 张牌中最大的牌为 max,最小的牌为 min (大小王除外),则需满足:
max - min < 5
max−min<5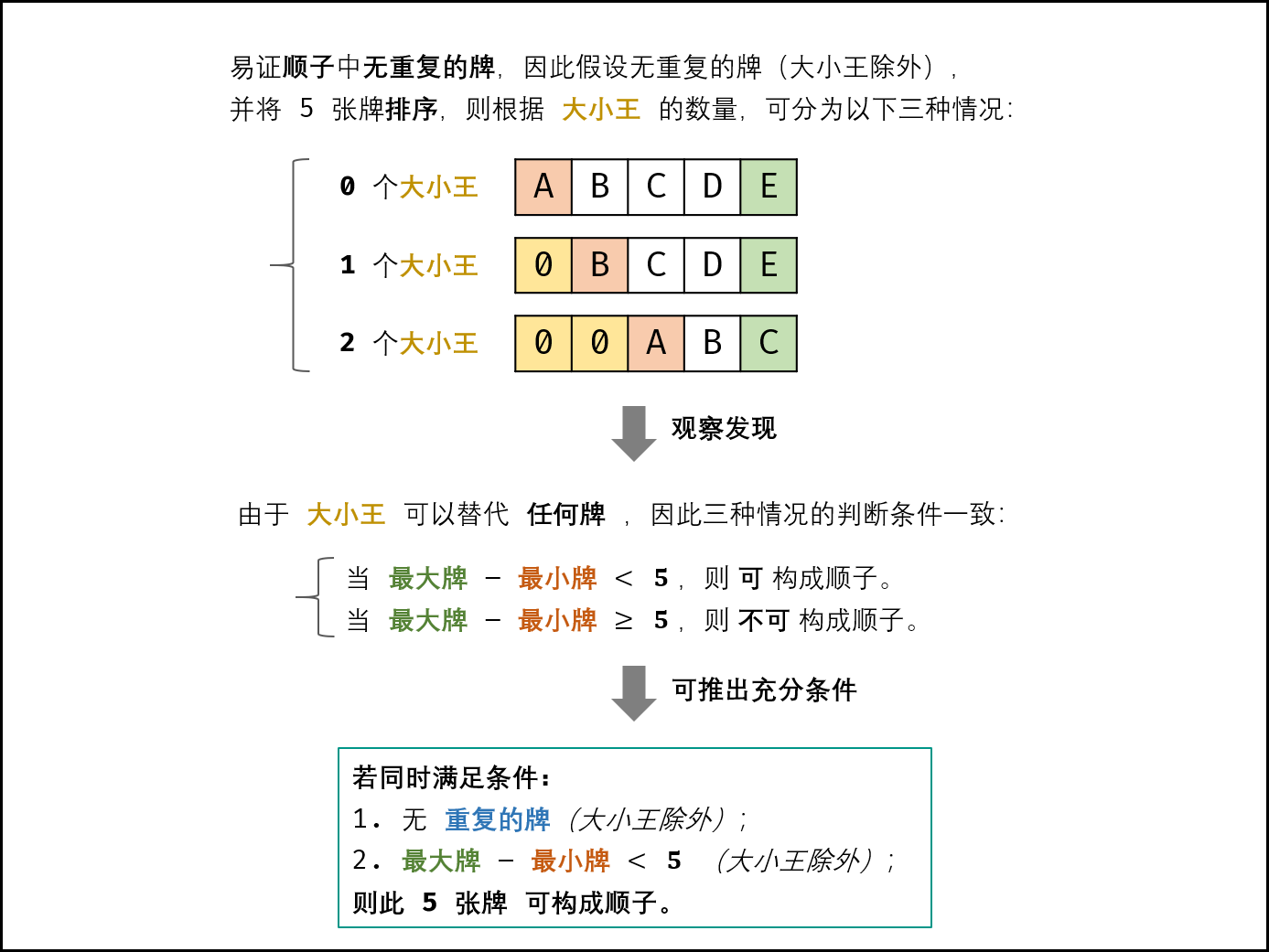
class Solution:
def isStraight(self, nums) -> bool:
repeat = set()
ma, mi = 0, 14
for num in nums:
if num == 0: continue # 跳过大小王
ma = max(ma, num) # 最大牌
mi = min(mi, num) # 最小牌
if num in repeat:
return False # 若有重复,提前返回 false
repeat.add(num) # 添加牌至 Set
return ma-mi<5
if __name__=='__main__':
s=Solution()
print(s.isStraight([1,2,3,4,5]))#True
46.圆圈中最后剩下的数字
0,1,,n-1这n个数字排成一个圆圈,从数字0开始,每次从这个圆圈里删除第m个数字。求出这个圆圈里剩下的最后一个数字。
例如,0、1、2、3、4这5个数字组成一个圆圈,从数字0开始每次删除第3个数字,则删除的前4个数字依次是2、0、4、1,因此最后剩下的数字是3。
示例 :
输入: n = 5, m = 3
输出: 3
递归:
- 找到f(n,start=0)和f(n-1,start=0)的关系
- 从 f(n - m) 场景下删除的第一个数的序号是 (m - 1) % n,记为k,那么 f(n - 1, m) 场景将使用被删除数字的下一个数,即序号 m % n 作为它的 0 序号,记为k+1
- f(n,start=0)=f(n-1,start = k+1)=(f(n-1,start=0)+k+1)=(f(n-1,start=0)+m%n)
- 设
f(n - 1, m)的结果为x,f(n-1,start=0)x即则f(n,start=0)=x+m%n- 由于
m % n + x可能会超过 n 的范围,所以我们再取一次模f(n , m) = (m % n + x) % n = (m + x) % n
class Solution:
def lastRemaining(self, n: int, m: int) -> int:
return self.f(n, m)
def f(self, n, m):
if n == 0:
return 0
#设 f(n - 1, m) 的结果为 x
x = self.f(n - 1, m)
#f(n,m)的结果为(x+f(n - 1, m)开始序列m%n)取模%n
return (m + x) % n
if __name__=='__main__':
s=Solution()
print(s.lastRemaining(5,3))#3
47.求1+2+...n
求 1+2+...+n ,要求不能使用乘除法、for、while、if、else、switch、case等关键字及条件判断语句(A?B:C)。
示例 :
输入: n = 3
输出: 6
递归+逻辑运算符的短路:
- 常见的逻辑运算符有三种,即 “与 and”,“或 or”,“非 ! ” ;而其有重要的短路效应,如下所示:
if(A and B) // 若 A 为 false ,则 B 的判断不会执行(即短路),直接判定 A and B 为 false
if(A or B) // 若 A 为 true ,则 B 的判断不会执行(即短路),直接判定 A or B 为 true
- n > 1 and sumNums(n - 1) // 当 n = 1 时 n > 1 不成立 ,此时 “短路” ,终止后续递归
class Solution:
def __init__(self):
self.res = 0
def sumNums(self, n: int) -> int:
#n=1时终止递归
n > 1 and self.sumNums(n - 1)
self.res += n
return self.res
#return reduce(lambda x,y: x+y, range(1,n+1))
if __name__=='__main__':
s=Solution()
print(s.lastRemaining(5,3))#3
48.不用加减乘除做加法
写一个函数,求两个整数之和,要求在函数体内不得使用 “+”、“-”、“*”、“/” 四则运算符号。
示例:
输入: a = 1, b = 1
输出: 2
位运算:
设两数字的二进制形式 a, b ,其求和 s = a + b ,a(i)代表 a 的二进制第 i位,则分为以下四种情况:
a(i) b(i) 无进位和 n(i) 进位 c(i+1) 00 00 00 00 00 11 11 00 11 00 11 00 11 11 00 11
- 观察发现,无进位和 与 异或运算 规律相同(相同为0,不同为1,进位 和 与运算 规律相同(并需左移一位)。因此,无进位和 n 与进位 c 的计算公式如下;
\[\begin{cases} n=a⊕b\\ c=a\&b<<1 \end{cases} \]
即可将 s = a + b 转化为:\(s = a + b \Rightarrow s = n + c\)
循环求 n 和 c ,直至进位 c = 0 ;此时 s = n ,返回 n即可
获取负数的补码: 需要将数字与十六进制数 0xffffffff 相与。可理解为舍去此数字 32 位以上的数字(将 32 位以上都变为 0 ),从无限长度变为一个 32 位整数。
返回前数字还原: 若补码 a为负数( 0x7fffffff 是最大的正数的补码 ),需执行 ~(a ^ x) 操作,将补码还原至 Python 的存储格式。 a ^ x 运算将 1 至 32 位按位取反; ~ 运算是将整个数字取反;因此, ~(a ^ x) 是将 32 位以上的位取反,1 至 32 位不变
class Solution:
def add(self, a: int, b: int) -> int:
x = 0xffffffff
a, b = a & x, b & x
#进位为0,跳出循环
while b != 0:
#非进位和进位
a, b = (a ^ b), (a & b) << 1 & x
#结果为负数,还原补码
return a if a <= 0x7fffffff else ~(a ^ x)
if __name__=='__main__':
s=Solution()
print(s.add(5,-7))#-2
49.把字符串转换成整数
写一个函数 StrToInt,实现把字符串转换成整数这个功能。不能使用 atoi 或者其他类似的库函数。
首先,该函数会根据需要丢弃无用的开头空格字符,直到寻找到第一个非空格的字符为止。
当我们寻找到的第一个非空字符为正或者负号时,则将该符号与之后面尽可能多的连续数字组合起来,作为该整数的正负号;假如第一个非空字符是数字,则直接将其与之后连续的数字字符组合起来,形成整数。
该字符串除了有效的整数部分之后也可能会存在多余的字符,这些字符可以被忽略,它们对于函数不应该造成影响。
注意:假如该字符串中的第一个非空格字符不是一个有效整数字符、字符串为空或字符串仅包含空白字符时,则你的函数不需要进行转换。
在任何情况下,若函数不能进行有效的转换时,请返回 0。
说明:
假设我们的环境只能存储 32 位大小的有符号整数,那么其数值范围为 [−231, 231 − 1]。如果数值超过这个范围,请返回 INT_MAX (231 − 1) 或 INT_MIN (−231) 。
示例 1:
输入: "42"
输出: 42
首部空格: 删除之即可;
符号位: 三种情况,即 ''+'' , ''−'' , ''无符号" ;新建一个变量保存符号位,返回前判断正负即可。
非数字字符: 遇到首个非数字的字符时,应立即返回。
数字字符:
字符转数字: “此数字的 ASCII 码” 与 “ 00 的 ASCII 码” 相减即可;
数字拼接: 若从左向右遍历数字,设当前位字符为 c,当前位数字为 x ,数字结果为 res ,则数字拼接公式为:
\(res = 10 \times res + x\)\(x = ascii(c) - ascii('0')\)
在每轮数字拼接前,判断 resres 在此轮拼接后是否超过 2147483647 ,若超过则加上符号位直接返回。
设数字拼接边界 bndry = 2147483647 // 10 = 214748364 ,则以下两种情况越界:\[\begin{cases} res > bndry & 情况一:执行拼接 10 \times res \geq 2147483650 越界 \\ res = bndry, x > 7 & 情况二:拼接后是 2147483648 或 2147483649 越界 \\ \end{cases} \]
class Solution:
def strToInt(self, str: str) -> int:
str = str.strip() # 删除首尾空格
if not str: return 0 # 字符串为空则直接返回
res, i, sign = 0, 1, 1
int_max, int_min, bndry = 2 ** 31 - 1, -2 ** 31, 2 ** 31 // 10
if str[0] == '-': sign = -1 # 保存负号
elif str[0] != '+': i = 0 # 若无符号位,需从 i = 0 开始数字拼接
for c in str[i:]:
if not '0' <= c <= '9' : break # 遇到非数字的字符则跳出
if res > bndry or res == bndry and c > '7':
return int_max if sign == 1 else int_min # 数字越界处理
res = 10 * res + ord(c) - ord('0') # 数字拼接
return sign * res
if __name__=='__main__':
s=Solution()
print(s.strToInt("-42l56j90"))#-42
50.树中两个节点的公共节点
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉树: root = [3,5,1,6,2,0,8,null,null,7,4]
示例 :
输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出: 3
解释: 节点 5 和节点 1 的最近公共祖先是节点 3。
祖先的定义: 若节点 p 在节点 root 的左(右)子树中,或 p = root,则称 root 是 p 的祖先。
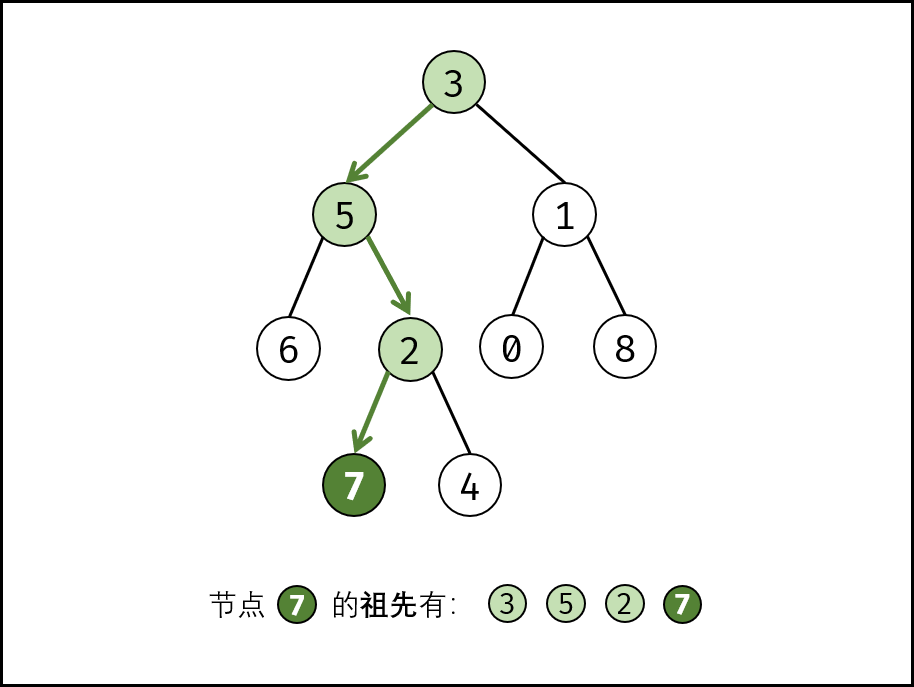
最近公共祖先的定义: 设节点 root为节点 p, q的某公共祖先,若其左子节点 root.left 和右子节点 root.right都不是 p,q 的公共祖先,则称 root 是 “最近的公共祖先” 。
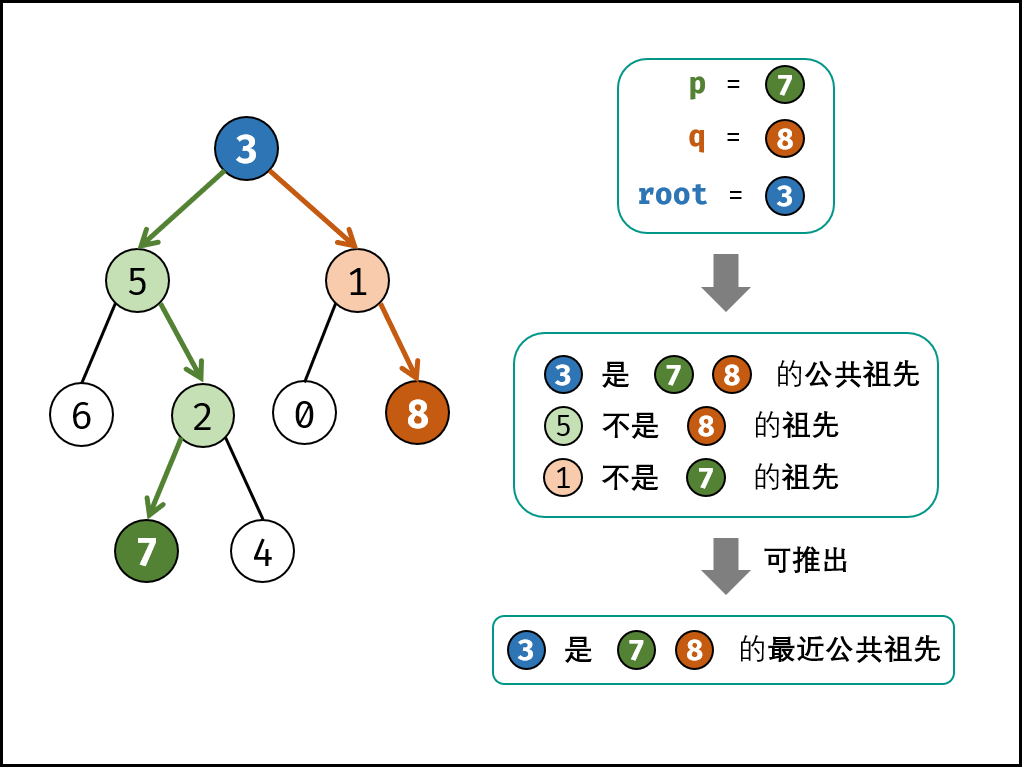
根据以上定义,若 root 是 p, q 的 最近公共祖先 ,则只可能为以下情况之一:
- p 和 q在 root 的子树中,且分列 root 的 异侧(即分别在左、右子树中);
- p = root ,且 q 在 root 的左或右子树中(q 在 root 的左或右子树中,root是q的祖先,p = root,root是的祖先,所以root是公共祖先);
- q = root ,且 p 在 root的左或右子树中
- 终止条件:
当越过叶节点,则直接返回 null ;
当 root 等于 p, q,则直接返回 root ;- 递推工作:
开启递归左子节点,返回值记为 left ;
开启递归右子节点,返回值记为 right ;- 返回值: 根据 left和 righ ,可展开为四种情况;
- 当 left 和 right 同时为空 :说明 root 的左 / 右子树中都不包含 p,q ,返回 null;
- 当 leftl 和 right 同时不为空 :说明 p, q分列在 root 的 异侧 (分别在 左 / 右子树),因此 root 为最近公共祖先,返回 root;
- 当 left 为空 ,right 不为空 :p,q都不在 root的左子树中,直接返回 righ 。具体可分为两种情况:
p,q 其中一个在 root的 右子树 中,此时 right指向 p(假设为 p);
p,q 两节点都在 root 的 右子树 中,此时的 right 指向 最近公共祖先节点 ;
当 left不为空 , right为空 :与情况 3. 同理;
class TreeNode:
def __init__(self, x):
self.val = x
self.left = None
self.right = None
class Solution:
def lowestCommonAncestor(self, root: TreeNode, p: TreeNode, q: TreeNode) -> TreeNode:
if not root or root == p or root == q:#不为空,且有一个点是最近公共祖先
return root
left = self.lowestCommonAncestor(root.left, p, q)#递归左子树
right = self.lowestCommonAncestor(root.right, p, q)#递归右子树
if not left and not right:
return # root 的左 / 右子树中都不包含 p,q
if not left:
return right # p,q都不在 root的左子树中.
if not right:
return left # p,q都不在 root的右子树中.
return root # p, q分列在 root 的 异侧,root 为最近公共祖先
补充
1.环形链表入口
给定一个链表,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。
说明:不允许修改给定的链表。
示例 1:
输入:head = [3,2,0,-4], pos = 1
输出:tail connects to node index 1
解释:链表中有一个环,其尾部连接到第二个节点。
快慢指针:
双指针第一次相遇: 设两指针 fast,slow 指向链表头部 head,fast 每轮走 2 步,slow 每轮走 1步;
第一种结果: fast 指针走过链表末端,说明链表无环,直接返回 null;
TIPS: 若有环,两指针一定会相遇。因为每走 11 轮,fast 与 slow 的间距 +1+1,fast 终会追上 slow;
第二种结果: 当fast == slow时, 两指针在环中 第一次相遇 。下面分析此时fast 与 slow走过的 步数关系 :
- 设链表共有 a+b个节点,其中 链表头部到链表入口 有 a 个节点(不计链表入口节点), 链表环 有 b个节点(这里需要注意,a 和 b是未知数,例如图解上链表 a=4 b=5);
- 设两指针分别走了 f,s 步,则有:fast 走的步数是slow步数的 2倍,即 f = 2s;(解析: fast 每轮走 2 步)
fast 比 slow多走了 n个环的长度,即 f = s + nb;( 解析: 双指针都走过 a步,然后在环内绕圈直到重合,重合时 fast 比 slow 多走 环的长度整数倍 );
以上两式相减得:f = 2nb,s = nb,即fast和slow 指针分别走了 2n,n个 环的周长 (注意: n是未知数,不同链表的情况不同)。- 如果让指针从链表头部一直向前走并统计步数k,那么所有 走到链表入口节点时的步数 是:k=a+nb(先走 a 步到入口节点,之后每绕 1 圈环( b步)都会再次到入口节点)。
而目前,slow 指针走过的步数为 nb 步。因此,我们只要想办法让 slow 再走 a 步停下来,就可以到环的入口。
双指针第二次相遇:
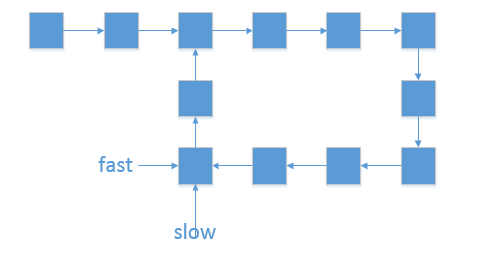
- slow指针 位置不变 ,将fast指针重新 指向链表头部节点 ;slow和fast同时每轮向前走 1 步;
- TIPS:此时 f = 0,s = nb ;
- 当 fast 指针走到f = a 步时,slow 指针走到步s = a+nb,此时 两指针重合,并同时指向链表环入口 。
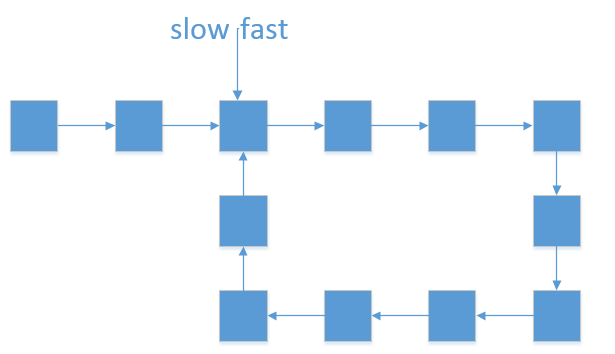
- 返回slow指针指向的节点。
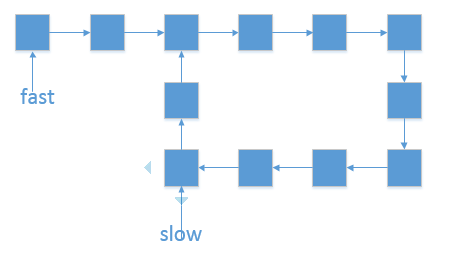
# Definition for singly-linked list.
class ListNode:
def __init__(self, x):
self.val = x
self.next = None
class Solution(object):
def detectCycle(self, head):
fast, slow = head, head
while True:
#fast走过链表末端,无环
if not (fast and fast.next): return
#fast走两步,slow走一步
fast, slow = fast.next.next, slow.next
#快慢指针相遇,f=2s=s+nb=2nb,慢指针走nb(b表示环节点)
if fast == slow: break
#fast指向链表头节点0
fast = head
while fast != slow:
#fast=a,slow=a+nb时相遇,相遇点为a点(环入口)
fast, slow = fast.next, slow.next
return fast
2.LRU缓存机制
设计LRU缓存结构,该结构在构造时确定大小,假设大小为K,并有如下两个功能
- set(key, value):将记录(key, value)插入该结构
- get(key):返回key对应的value值
[要求]
- set和get方法的时间复杂度为O(1)
- 某个key的set或get操作一旦发生,认为这个key的记录成了最常使用的。
- 当缓存的大小超过K时,移除最不经常使用的记录,即set或get最久远的。
若opt=1,接下来两个整数x, y,表示set(x, y)
若opt=2,接下来一个整数x,表示get(x),若x未出现过或已被移除,则返回-1
对于每个操作2,输出一个答案
示例1
输入
[[1,1,1],[1,2,2],[1,3,2],[2,1],[1,4,4],[2,2]],3
输出
[1,-1]
说明
第一次操作后:最常使用的记录为("1", 1)
第二次操作后:最常使用的记录为("2", 2),("1", 1)变为最不常用的
第三次操作后:最常使用的记录为("3", 2),("1", 1)还是最不常用的
第四次操作后:最常用的记录为("1", 1),("2", 2)变为最不常用的
第五次操作后:大小超过了3,所以移除此时最不常使用的记录("2", 2),加入记录("4", 4),并且为最常使用的记录,然后("3", 2)变为最不常使用的记录
LRU 缓存机制可以通过哈希表辅以双向链表实现,我们用一个哈希表和一个双向链表维护所有在缓存中的键值对。
双向链表按照被使用的顺序存储了这些键值对,靠近头部的键值对是最近使用的,而靠近尾部的键值对是最久未使用的。
哈希表即为普通的哈希映射(HashMap),通过缓存数据的键映射到其在双向链表中的位置。
这样以来,我们首先使用哈希表进行定位,找出缓存项在双向链表中的位置,随后将其移动到双向链表的头部,即可在 O(1)的时间内完成 get 或者 put 操作。具体的方法如下:
- 对于 get 操作,首先判断 key 是否存在:
- 如果 key 不存在,则返回 -1;
- 如果 key 存在,则 key 对应的节点是最近被使用的节点。通过哈希表定位到该节点在双向链表中的位置,并将其移动到双向链表的头部,最后返回该节点的值。
- 对于 put 操作,首先判断 key 是否存在:
- 如果 key 不存在,使用 key 和 value 创建一个新的节点,在双向链表的头部添加该节点,并将 key 和该节点添加进哈希表中。然后判断双向链表的节点数是否超出容量,如果超出容量,则删除双向链表的尾部节点,并删除哈希表中对应的项;
- 如果 key 存在,则与 get 操作类似,先通过哈希表定位,再将对应的节点的值更新为 value,并将该节点移到双向链表的头部。
#
# lru design
# @param operators int整型二维数组 the ops
# @param k int整型 the k
# @return int整型一维数组
#
#定义双向链表
class Node:
def __init__(self, key=0, value=0):
self.key = key
self.value = value
self.next = None
self.prev = None
class Solution:
#初始化存储为0,
def __init__(self):
self.size = 0
#双向链表靠近头部的键值对是最近使用的,而靠近尾部的键值对是最久未使用的
self.head = Node()
self.tail = Node()
self.head.next = self.tail
self.tail.prev = self.head
#hash表:通过缓存数据的键映射到其在双向链表中的位置
self.hash_map = {}
def put(self, key, value, k):
# key存在
if key in self.hash_map:
#设置新的键值
self.hash_map[key].value = value
#将该键在链表中位置删除,移到链表头部最常使用的
self.move_to_head(self.hash_map[key])
# key not exists
else:
# 缓存大小小于k
if self.size < k:
#设置的值映射到其在双向链表中的位置
self.hash_map[key] = Node(key, value)
#设置的值存储到hash表头中,成为最常使用记录
self.add_head(self.hash_map[key])
#缓存大小加1
self.size += 1
# 缓存大小大于k
else:
#移除链表末尾最不常使用的记录
self.remove_node(self.tail.prev)
self.hash_map[key] = Node(key, value)
self.add_head(self.hash_map[key])
def get(self, key):
# key not exists
if key not in self.hash_map:
return -1
# key存在,该键在链表中位置删除,移到链表头部成最常使用的
self.move_to_head(self.hash_map[key])
#返回键值
return self.hash_map[key].value
#记录移到链表头部成最常使用的
def move_to_head(self, node):
#删除记录在链表中原来位置
node.prev.next = node.next
node.next.prev = node.prev
#记录放到head和原来head.next中间,使之成为新的链表头部
node.next = self.head.next
node.prev = self.head
#保存记录,更新链表
self.head.next = node
node.next.prev = node
#记录存到链表头部
def add_head(self, node):
node.next = self.head.next
node.prev = self.head
self.head.next = node
node.next.prev = node
def remove_node(self, node):
node.next.prev = node.prev
node.prev.next = node.next
self.hash_map.pop(node.key)
def LRU(self, operators, k):
# write code here
res = []
for i in range(len(operators)):
if operators[i][0] == 1:
self.put(operators[i][1], operators[i][2], k)
else:
res.append(self.get(operators[i][1]))
return res
s=Solution()
print(s.LRU([[1,1,1],[1,2,2],[1,3,2],[2,1],[1,4,4],[2,2]],3))#[1, -1]
3.不同的子序列
给定一个字符串 S 和一个字符串 T,计算在 S 的子序列中 T 出现的个数。
一个字符串的一个子序列是指,通过删除一些(也可以不删除)字符且不干扰剩余字符相对位置所组成的新字符串。(例如,"ACE" 是 "ABCDE" 的一个子序列,而 "AEC" 不是)
题目数据保证答案符合 32 位带符号整数范围。
示例 :
输入:S = "rabbbit", T = "rabbit"
输出:3
解释:
如下图所示, 有 3 种可以从 S 中得到 "rabbit" 的方案。
(上箭头符号 ^ 表示选取的字母)
rabbbit
^^^^ ^^
rabbbit
^^ ^^^^
rabbbit
^^^ ^^^
动态规划:
- 设定
dp[i][j]为t的前i个字符可以由s的前j个字符组成多少个- 当
s[j] == t[i]时:
- 取S[j],那么当前情况总数,应该和字符串S的前j-1个字符所构成的子序列中出现字符串T的前i-1个字符的情况总数相等。
- 不取S[j],那么当前情况总数,应该和字符串S的前j-1个字符所构成的子序列中出现字符串T的前i个字符的情况总数相等。
- 转移方程为
dp[i][j] = dp[i-1][j-1] + dp[i][j-1]- 当
s[j] != t[i]时和不取S[j]的情况相同,转移方程为dp[i][j] = dp[i][j-1]
class Solution():
def numDistinct(self, s: str, t: str) -> int:
n1 = len(s)
n2 = len(t)
#dp[i][j]为t的前i个字符可以由s的前j个字符组成的最多个数
dp = [[0] * (n1 + 1) for _ in range(n2 + 1)]
for j in range(n1 + 1):
#初始化t第一个元素是空时,都是s子序列,所以第一行都是1
dp[0][j] = 1
for i in range(1, n2 + 1):
for j in range(1, n1 + 1):
#i-1是n2,t的最后一个元素
if t[i - 1] == s[j - 1]:
dp[i][j] = dp[i - 1][j - 1] + dp[i][j - 1]
else:
dp[i][j] = dp[i][j - 1]
#print(dp)
return dp[-1][-1]
if __name__=='__main__':
s=Solution()
print(s.numDistinct("rabbbit","rabbit"))#3

