Logstash学习之路(五)使用Logstash抽取mysql数据到kakfa
一、Logstash对接kafka测通
说明:
由于我这里kafka是伪分布式,且kafka在伪分布式下,已经集成了zookeeper。
1、先将zk启动,如果是在伪分布式下,kafka已经集成了zk
[root@master zookeeperData]# nohup /mnt/kafka/bin/zookeeper-server-start.sh /mnt/kafka/config/zookeeper.properties &
2、启动broker
[root@master mnt]# nohup /mnt/kafka/bin/kafka-server-start.sh /mnt/kafka/config/server.properties &
3、创建topic
[root@master bin]# ./kafka-topics.sh --create --zookeeper 192.168.200.100:2181 --topic test --partition 1 --replication-factor 1 Created topic "test".
4、创建消费者
[root@master bin]# ./kafka-console-consumer.sh --topic test --zookeeper localhost:2181
5、配置Logstash对接kafka的配置文件
input{ stdin{} } output{ kafka{ topic_id => "test" bootstrap_servers => "192.168.200.100:9092" # kafka的地址 # batch_size => 5 } stdout{ codec => rubydebug } }
6、测试
启动日志:
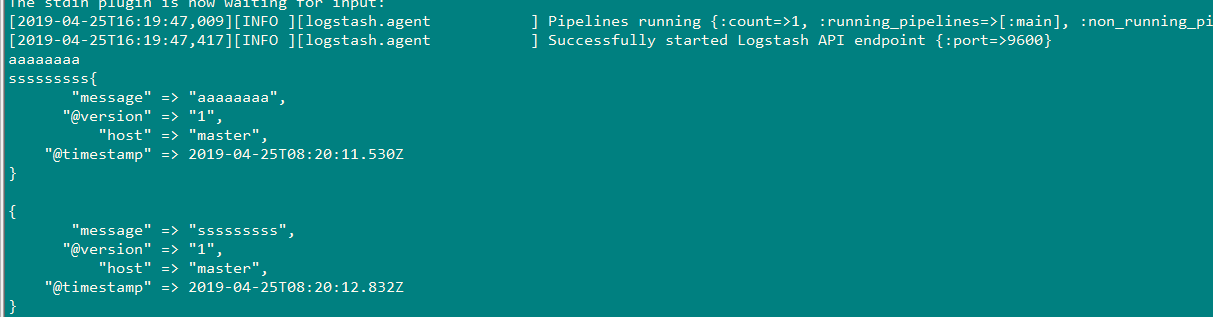
[root@master bin]# ./logstash -f kafka.conf Sending Logstash's logs to /mnt/logstash/logs which is now configured via log4j2.properties [2019-04-25T16:19:38,811][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified [2019-04-25T16:19:40,075][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"6.3.1"} [2019-04-25T16:19:46,274][INFO ][logstash.pipeline ] Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>2, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50} [2019-04-25T16:19:46,583][INFO ][org.apache.kafka.clients.producer.ProducerConfig] ProducerConfig values: acks = 1 batch.size = 16384 bootstrap.servers = [192.168.200.100:9092] buffer.memory = 33554432 client.id = compression.type = none connections.max.idle.ms = 540000 enable.idempotence = false interceptor.classes = [] key.serializer = class org.apache.kafka.common.serialization.StringSerializer linger.ms = 0 max.block.ms = 60000 max.in.flight.requests.per.connection = 5 max.request.size = 1048576 metadata.max.age.ms = 300000 metric.reporters = [] metrics.num.samples = 2 metrics.recording.level = INFO metrics.sample.window.ms = 30000 partitioner.class = class org.apache.kafka.clients.producer.internals.DefaultPartitioner receive.buffer.bytes = 32768 reconnect.backoff.max.ms = 10 reconnect.backoff.ms = 10 request.timeout.ms = 30000 retries = 0 retry.backoff.ms = 100 sasl.jaas.config = null sasl.kerberos.kinit.cmd = /usr/bin/kinit sasl.kerberos.min.time.before.relogin = 60000 sasl.kerberos.service.name = null sasl.kerberos.ticket.renew.jitter = 0.05 sasl.kerberos.ticket.renew.window.factor = 0.8 sasl.mechanism = GSSAPI security.protocol = PLAINTEXT send.buffer.bytes = 131072 ssl.cipher.suites = null ssl.enabled.protocols = [TLSv1.2, TLSv1.1, TLSv1] ssl.endpoint.identification.algorithm = null ssl.key.password = null ssl.keymanager.algorithm = SunX509 ssl.keystore.location = null ssl.keystore.password = null ssl.keystore.type = JKS ssl.protocol = TLS ssl.provider = null ssl.secure.random.implementation = null ssl.trustmanager.algorithm = PKIX ssl.truststore.location = null ssl.truststore.password = null ssl.truststore.type = JKS transaction.timeout.ms = 60000 transactional.id = null value.serializer = class org.apache.kafka.common.serialization.StringSerializer [2019-04-25T16:19:46,705][INFO ][org.apache.kafka.common.utils.AppInfoParser] Kafka version : 1.1.0 [2019-04-25T16:19:46,706][INFO ][org.apache.kafka.common.utils.AppInfoParser] Kafka commitId : fdcf75ea326b8e07 [2019-04-25T16:19:46,854][INFO ][logstash.pipeline ] Pipeline started successfully {:pipeline_id=>"main", :thread=>"#<Thread:0x11d30400 run>"} The stdin plugin is now waiting for input: [2019-04-25T16:19:47,009][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]} [2019-04-25T16:19:47,417][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}

二、使用Logstash抽取mysql数据到kafka
配置文件:
input { stdin {} jdbc { type => "jdbc" jdbc_connection_string => "jdbc:mysql://192.168.200.100:3306/yang?characterEncoding=UTF-8&autoReconnect=true" # 数据库连接账号密码; jdbc_user => "root" jdbc_password => "010209" # MySQL依赖包路径; jdbc_driver_library => "/mnt/mysql-connector-java-5.1.38.jar" # the name of the driver class for mysql jdbc_driver_class => "com.mysql.jdbc.Driver" statement => "SELECT * FROM `im`" } } output { kafka{ topic_id => "test" bootstrap_servers => "192.168.200.100:9092" # kafka的地址 batch_size => 5 } stdout { } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号