

Logstash学习之路(四)使用Logstash将mysql数据导入elasticsearch(单表同步、多表同步、全量同步、增量同步)
一、使用Logstash将mysql数据导入elasticsearch
1、在mysql中准备数据:
mysql> show tables; +----------------+ | Tables_in_yang | +----------------+ | im | +----------------+ 1 row in set (0.00 sec) mysql> select * from im; +----+------+ | id | name | +----+------+ | 2 | MSN | | 3 | QQ | +----+------+ 2 rows in set (0.00 sec)
2、简单实例配置文件准备:
[root@master bin]# cat mysqles.conf input { stdin {} jdbc { type => "jdbc" jdbc_connection_string => "jdbc:mysql://192.168.200.100:3306/yang?characterEncoding=UTF-8&autoReconnect=true" # 数据库连接账号密码; jdbc_user => "root" jdbc_password => "010209" # MySQL依赖包路径; jdbc_driver_library => "/mnt/mysql-connector-java-5.1.38.jar" # the name of the driver class for mysql jdbc_driver_class => "com.mysql.jdbc.Driver" statement => "SELECT * FROM `im`" } } output { elasticsearch { # 配置ES集群地址 hosts => ["192.168.200.100:9200"] # 索引名字,必须小写 index => "im" } stdout { } }
3、实例结果:
[root@master bin]# ./logstash -f mysqles.conf
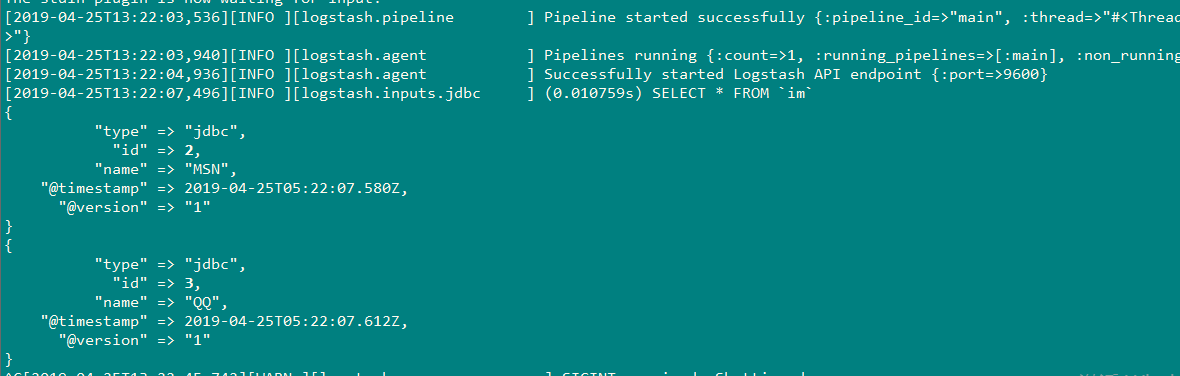

4、更多选项配置如下(单表同步):
input { stdin {} jdbc { type => "jdbc" # 数据库连接地址 jdbc_connection_string => "jdbc:mysql://192.168.1.1:3306/TestDB?characterEncoding=UTF-8&autoReconnect=true"" # 数据库连接账号密码; jdbc_user => "username" jdbc_password => "pwd" # MySQL依赖包路径; jdbc_driver_library => "mysql/mysql-connector-java-5.1.34.jar" # the name of the driver class for mysql jdbc_driver_class => "com.mysql.jdbc.Driver" # 数据库重连尝试次数 connection_retry_attempts => "3" # 判断数据库连接是否可用,默认false不开启 jdbc_validate_connection => "true" # 数据库连接可用校验超时时间,默认3600S jdbc_validation_timeout => "3600" # 开启分页查询(默认false不开启); jdbc_paging_enabled => "true" # 单次分页查询条数(默认100000,若字段较多且更新频率较高,建议调低此值); jdbc_page_size => "500" # statement为查询数据sql,如果sql较复杂,建议配通过statement_filepath配置sql文件的存放路径; # sql_last_value为内置的变量,存放上次查询结果中最后一条数据tracking_column的值,此处即为ModifyTime; # statement_filepath => "mysql/jdbc.sql" statement => "SELECT KeyId,TradeTime,OrderUserName,ModifyTime FROM `DetailTab` WHERE ModifyTime>= :sql_last_value order by ModifyTime asc" # 是否将字段名转换为小写,默认true(如果有数据序列化、反序列化需求,建议改为false); lowercase_column_names => false # Value can be any of: fatal,error,warn,info,debug,默认info; sql_log_level => warn # # 是否记录上次执行结果,true表示会将上次执行结果的tracking_column字段的值保存到last_run_metadata_path指定的文件中; record_last_run => true # 需要记录查询结果某字段的值时,此字段为true,否则默认tracking_column为timestamp的值; use_column_value => true # 需要记录的字段,用于增量同步,需是数据库字段 tracking_column => "ModifyTime" # Value can be any of: numeric,timestamp,Default value is "numeric" tracking_column_type => timestamp # record_last_run上次数据存放位置; last_run_metadata_path => "mysql/last_id.txt" # 是否清除last_run_metadata_path的记录,需要增量同步时此字段必须为false; clean_run => false # # 同步频率(分 时 天 月 年),默认每分钟同步一次; schedule => "* * * * *" } } filter { json { source => "message" remove_field => ["message"] } # convert 字段类型转换,将字段TotalMoney数据类型改为float; mutate { convert => { "TotalMoney" => "float" } } } output { elasticsearch { # 配置ES集群地址 hosts => ["192.168.1.1:9200", "192.168.1.2:9200", "192.168.1.3:9200"] # 索引名字,必须小写 index => "consumption" } stdout { codec => json_lines } }
5、多表同步:
多表配置和单表配置的区别在于input模块的jdbc模块有几个type,output模块就需对应有几个type;
input { stdin {} jdbc { # 多表同步时,表类型区分,建议命名为“库名_表名”,每个jdbc模块需对应一个type; type => "TestDB_DetailTab" # 其他配置此处省略,参考单表配置 # ... # ... # record_last_run上次数据存放位置; last_run_metadata_path => "mysql\last_id.txt" # 是否清除last_run_metadata_path的记录,需要增量同步时此字段必须为false; clean_run => false # # 同步频率(分 时 天 月 年),默认每分钟同步一次; schedule => "* * * * *" } jdbc { # 多表同步时,表类型区分,建议命名为“库名_表名”,每个jdbc模块需对应一个type; type => "TestDB_Tab2" # 多表同步时,last_run_metadata_path配置的路径应不一致,避免有影响; # 其他配置此处省略 # ... # ... } } filter { json { source => "message" remove_field => ["message"] } } output { # output模块的type需和jdbc模块的type一致 if [type] == "TestDB_DetailTab" { elasticsearch { # host => "192.168.1.1" # port => "9200" # 配置ES集群地址 hosts => ["192.168.1.1:9200", "192.168.1.2:9200", "192.168.1.3:9200"] # 索引名字,必须小写 index => "detailtab1" # 数据唯一索引(建议使用数据库KeyID) document_id => "%{KeyId}" } } if [type] == "TestDB_Tab2" { elasticsearch { # host => "192.168.1.1" # port => "9200" # 配置ES集群地址 hosts => ["192.168.1.1:9200", "192.168.1.2:9200", "192.168.1.3:9200"] # 索引名字,必须小写 index => "detailtab2" # 数据唯一索引(建议使用数据库KeyID) document_id => "%{KeyId}" } } stdout { codec => json_lines } }
二、使用logstash全量同步(1分钟同步一次)mysql数据导入到elasticsearch
配置如下:
input { stdin {} jdbc { type => "jdbc" jdbc_connection_string => "jdbc:mysql://192.168.200.100:3306/yang?characterEncoding=UTF-8&autoReconnect=true" # 数据库连接账号密码; jdbc_user => "root" jdbc_password => "010209" # MySQL依赖包路径; jdbc_driver_library => "/mnt/mysql-connector-java-5.1.38.jar" # the name of the driver class for mysql jdbc_driver_class => "com.mysql.jdbc.Driver" statement => "SELECT * FROM `im`" schedule => "* * * * *" } } output { elasticsearch { # 配置ES集群地址 hosts => ["192.168.200.100:9200"] # 索引名字,必须小写 index => "im" } stdout { } }
第一次同步结果:
[2019-04-25T14:39:03,194][INFO ][logstash.inputs.jdbc ] (0.100064s) SELECT * FROM `im` { "@version" => "1", "@timestamp" => 2019-04-25T06:39:03.338Z, "type" => "jdbc", "id" => 3, "name" => "QQ" } { "@version" => "1", "@timestamp" => 2019-04-25T06:39:03.309Z, "type" => "jdbc", "id" => 2, "name" => "MSN" }
向mysql插入数据后第二次同步:
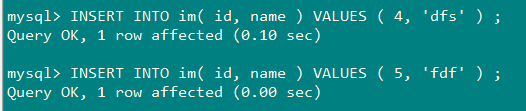
[2019-04-25T14:40:00,295][INFO ][logstash.inputs.jdbc ] (0.001956s) SELECT * FROM `im` { "@version" => "1", "@timestamp" => 2019-04-25T06:40:00.310Z, "type" => "jdbc", "id" => 2, "name" => "MSN" } { "@version" => "1", "@timestamp" => 2019-04-25T06:40:00.316Z, "type" => "jdbc", "id" => 3, "name" => "QQ" } { "@version" => "1", "@timestamp" => 2019-04-25T06:40:00.317Z, "type" => "jdbc", "id" => 4, "name" => "dfs" } { "@version" => "1", "@timestamp" => 2019-04-25T06:40:00.317Z, "type" => "jdbc", "id" => 5, "name" => "fdf" }
三、使用logstash增量同步(1分钟同步一次)mysql数据导入到elasticsearch
input { stdin {} jdbc { type => "jdbc" jdbc_connection_string => "jdbc:mysql://192.168.200.100:3306/yang?characterEncoding=UTF-8&autoReconnect=true" # 数据库连接账号密码; jdbc_user => "root" jdbc_password => "010209" # MySQL依赖包路径; jdbc_driver_library => "/mnt/mysql-connector-java-5.1.38.jar" # the name of the driver class for mysql jdbc_driver_class => "com.mysql.jdbc.Driver" #是否开启分页 jdbc_paging_enabled => "true" #分页条数 jdbc_page_size => "50000" # 执行的sql 文件路径+名称 #statement_filepath => "/data/my_sql2.sql" #SQL语句,也可以使用statement_filepath来指定想要执行的SQL statement => "SELECT * FROM `im` where id > :sql_last_value" #每一分钟做一次同步 schedule => "* * * * *" #是否将字段名转换为小写,默认true(如果有数据序列化、反序列化需求,建议改为false) lowercase_column_names => false # 是否记录上次执行结果,true表示会将上次执行结果的tracking_column字段的值保存到last_run_metadata_path指定的文件中; record_last_run => true # 需要记录查询结果某字段的值时,此字段为true,否则默认tracking_column为timestamp的值; use_column_value => true # 需要记录的字段,用于增量同步,需是数据库字段 tracking_column => "id" # record_last_run上次数据存放位置; last_run_metadata_path => "/mnt/sql_last_value" #是否将字段名转换为小写,默认true(如果有数据序列化、反序列化需求,建议改为false) clean_run => false } } output { elasticsearch { # 配置ES集群地址 hosts => ["192.168.200.100:9200"] # 索引名字,必须小写 index => "im" } stdout { } }
注意标红色的部分:这些配置是为了达到增量同步的目的,每次同步结束之后会记录最后一条数据的tracking_column列,比如我们这设置的是id,就会将这个值记录在last_run_metadata_path中。
下次在执行同步的时候会将这个值,赋给sql_last_value
说明:
由于我上一次最后sql_last_value文件中记录的id为5,当向mysql插入id=6的值时,结果:

插入id=8,7时;
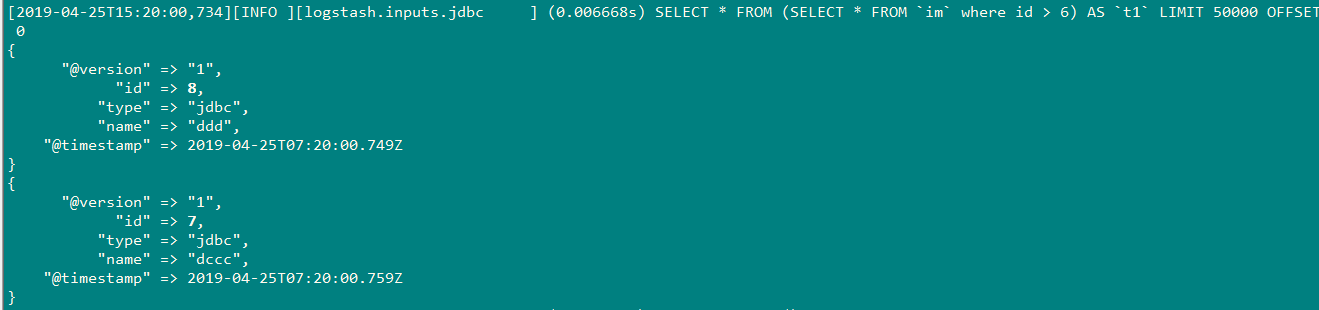
因为我插入的顺序,先插入id 为8,后插入id为7,因此最后一次记录的id为7,当我下一次插入id=9,10时,会重新导入id为8的值。

当我插入id=10的值后,结束,观察sql_last_value文件的最后记录:

结果:

