Group by后加rollup、cube、Grouping_Sets的用法区别
一、相关分析
通常当聚合率和数据量没有大于一定程度时,对于不涉及Rollup、Cube、Grouping_Sets这三种操作的聚合很少出现GC问题。对于Rollup、Cube、Grouping_Sets操作可采用如下优化方法避免GC。
1、Rollup / Cube / Grouping_Sets时,某些场景下,如果多维度的字段比较多,内存或者GC会造成性能问题。特别的, 在实现这三种操作 时, 记录数会出现倍数的膨胀, 调优的时候请务必关注 GC 情况。 如果 GC性能情况表现不加, 建议用手动改动的方式调优, 通常是把这三种操作等价的用 UNION 多个子查询 SQL 的方式实现。 对 SQL 改写相当于是对它们计算内容的同语义翻译。
1、1Rollup的改写

对它等价的拆分改写结果如下,上下两个语句的结果相同:

1、2Cube改写


可以看出前三个的Union块的结果等同于一个Cube,所以还可以改写为

1、3Grouping Sets的改写

对它等价的拆分改写结果如下,上下两个语句的结果相同:

总结:可以按照以上所示的对三种操作的改写形式对语句展开优化,尽可能的减少因内存和GC引发的性能问题。但是,一般情况下,如果GC问题不是特别严重,就不用改写,否则会导致性能更差。
二、对比Group by、Cube、Rollup
Rollup运算符生成的结果集类似于Cube运算符生成的结果集。
CUBE和Rollup之间的具体区别:
v1、CUBE生成的结果集显示了所选列中值的所有组合的聚合
v2、Rollup生成的结果集显示了所选列中值的某一层次结构的聚合。
Rollup优点:
v1、Rollup返回单个结果集,而compute by返回多个结果集,而多个结果集会增加应用程序代码的复杂性。
v2、Rollup可以在服务器游标中使用,而compute by则不可以。
v3、查询优化器为Rollup生成的执行计算比为compute by生成的更为高效。
三、实例
-1、创建表 CREATE TABLE employee_part(department STRING,name STRING,salary int) CLUSTERED BY (department) INTO 7 BUCKETS STORED AS ORC tblproperties('transactional'='true'); --2、入数据 insert into employee_part values('A','ZHANG',100); insert into employee_part values('A','LI',200); insert into employee_part values('A','WANG',300); insert into employee_part values('A','DUAN',500); insert into employee_part values('B','DUAN',600 ); insert into employee_part values('B','DUAN',700); insert into employee_part values('A','ZHAO',400);
--3、Group by SELECT department,name,sum(salary)AS sum FROM employee_part GROUP BY department,name;
--4、Rollup SELECT department,name,sum(salary)AS sum FROM employee_part GROUP BY Rollup(department,name); 等价于 SELECT department,name,sum(salary)AS sum FROM employee_part GROUP BY department,name union SELECT department,'NULL',SUM(salary)AS sum FROM employee_part GROUP BY department union SELECT 'NULL','NULL',SUM(salary)AS sum FROM employee_part;
--5、CUBE SELECT department,name,sum(salary)AS sum FROM employee_part GROUP BY Cube(department,name); 等价于 SELECT department,name,sum(salary)AS sum FROM employee_part GROUP BY department,name union SELECT department,'NULL',SUM(salary)AS sum FROM employee_part GROUP BY department union SELECT 'NULL','NULL',SUM(salary)AS sum FROM employee_part UNION SELECT 'NULL', name, SUM(Salary) AS sum FROM employee_part GROUP BY name; 等价于 SELECT department,name,sum(salary)AS sum FROM employee_part GROUP BY Rollup(department,name) UNION SELECT 'NULL', name, SUM(Salary) AS sum FROM employee_part GROUP BY name;
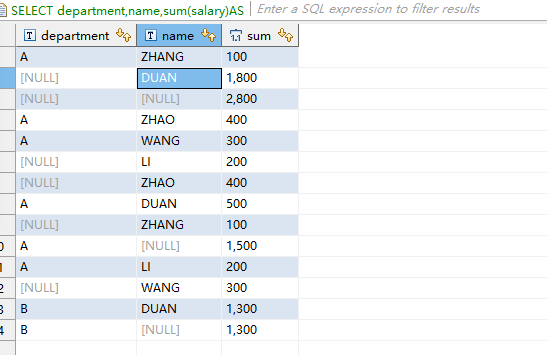
可以看出CUBE的结果集在Rollup结果集上多出了5行,这5行相当于在Rollup结果集上再union上以员工名字为group by 的结果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号