flume基本概念及相关参数详解
1、flume是分布式的日志收集系统,把手机来的数据传送到目的地去
2、flume传输的数据的基本单位是 event,如果是文本文件,通常是一行记录。
event代表着一个数据流的最小完整单元,由零个或多个header和正文组成,header类似于http头,包含时间的时间戳或者来源服务器主机名等。
3、flume里面有个核心概念,叫做agent,agent是一个java进程,运行在日志收集节点。
4、agent里面包含3个核心组件:source、channel、sink.
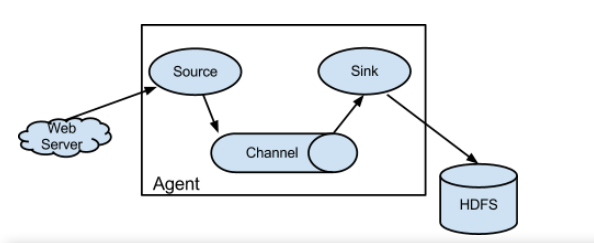
说明:
-
source组件是专用于收集日志的,可以处理各种格式的日志数据 ,包括avro、thrift、exec、jms、spooling、directory、netcat、 sequence、 generator、syslog、http、legacy、自定义。source组件把数据收集来以后,临时存放在channel中。
-
channel组件是在agent中专用于临时存储数据的,可以存放在memory、jdbc、file、自定义。channel中的数据只有在sink发送成功之后才会被删除。
-
sink组件是用于把数据发送到目的地的组件,目的地包括hdfs、logger、avro、thrift、ipc、file、null、solr、自定义
5、在整个数据传输过程中,流动的是event。事务保证是event级别。
6、flume可以支持多级flume的agent,支持扇入(fan-in)、扇出(fan-out)
注意:
1、一个source写event到一个或者多个channels中。
2、一个channel是event从source传输到sink的等候区;
3、一个sink只可以从一个channel中接收events;
4、一个agent可以有多个source、channel和sink
7、组件类型说明
source:


channel:


sink:

8、参数配置详解
Server:
(1) SpoolDirectoryTailFileSource:默认是按行读取,可以保证数据的完整性,即使flume重启或者被杀掉。
(2) trackerDir:存储处理文件相关的元数据的目录,如果不是绝对路径,那么将是spoolDir的相对路径。
(3) consumeOrder:转换文件的顺序 oldest|youngest|random
(4)batchSize:批量传输到Channel的粒度
(5)inputCharset:反序列化实验的字符集
(6) decodeErrorPolicy:如果解析失败的字符时应该如何处理,默认是FAIL,还可以选择IGNORE和REPLACE,FAIL时会抛出Exception,flume整个进程会阻塞在这,IGNORE会忽略此字符,REPLACE会用另一个字符替代。
(7)deserializer:这种反序列化器会将输入的文件的每行生成一个event
(8)deserializer.maxLineLength:默认是2048,大于这个字符数的行将被截断
(9)avro type:支持Avro协议(实际上是Avro RPC),内置支持
(10)sinkgroups:通过sink组来选择当中优先级高的哪个作为被激活的sink.没有负载平衡处理,只是做到容灾。其中包括了两个sink,两个sink分别指向不同的flume-agent
(11)memory channel:如果虚拟机或机器重新启动,任何缓冲区中的数据将丢失。
(12)最好不要一个flume agent配置多个端口【影响性能】,配在一台机子上通过端口区分,一旦死机,全盘崩溃
Client:
(1)producer.max.request.size:每次producer请求的最大的字节数
(2)useLocalTimeStamp:是否使用本地时间戳
(3) rollInterval:多久生成一个新文件,若为0,则一直为一个文件。
(4)rollSize:每个文件滚动大小
(5)rollCount:若为0表示文件的滚动与event数量无关
(6)idleTimeout:如果文件在hdfs.idleTimeout秒的时间里都是闲置的,没有任何数据写入,那么当前文件关闭,滚动到下一个文件
(7)transactionCapacity:事务容量,Channel每次提交的Event数量
Taildir与spooltailfiledirectory:taildir不能自动识别新文件;不支持文件名修改,容易重复上传;taildir不支持断点续传。
Flume采集流程:
往文件中写内容,触发flume agent server 的spoolTailFiledirectory,这样内容就会通过flume agent server到memory channel中,在
通过failover机制选择优先级高的sink去输出,最终输出的地方,由最后一环的flume配置中sink.type决定,可以是kafka,hdfs等等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号