

GIL,同步与异步
Python GIL
1、GIL全局解释器锁
2、GIL全局解释器锁VS互斥锁
3、定时器
1、GIL全局解释器锁:
GIL全局解释器锁是一把互斥锁,都是让多个并发线程同一时间只能由一个执行
有了GIL的存在,同一进程内的多个线程同一时间只能有一个在运行,意味着在Cpython中一个进程下多个线程无法实现并行=>意味着无法利用多核优势
但不影响并发的实现
注意:保护不同的数据安全,就应该加不同的锁
为何要用GIL:
因为Cpython解释器自带垃圾回收机制,并不是让线程安全的。(原因在于垃圾回收机制会将线程马上要引用值前,回收一个当前并没有绑定的值,线程后面将引用时无法查找到)(Cpython解释器的代码会收到参数,而参数是线程)
如何使用:
GIL是加在Cpython解释器之上,GIL可以比喻成执行权限,同一进程下的所有线程都是先在抢GIL,拿到执行权限,然后将代码交给解释器的代码去执行,保证python解释器同一时间只能执行一个任务的代码
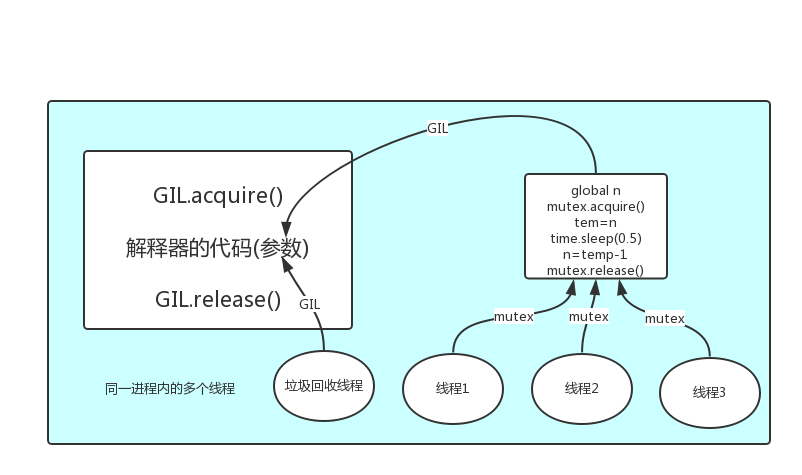
2、GIL全局解释器锁VS互斥锁

GIL保护的是解释器级的数据,保护用户自己的数据则需要自己加锁处理
一切都由操作系统监视,最开始所有线程抢GIL,抢到后如果没有用户设锁,那么遇到IO后,操作系统会将线程的cpu拿走,Cpython解释器释放其GIL,其他线程可以继续抢GIL执行。当前面那个被系统解放GIL的线程再次抢到GIL时,会接着上次被解放的地方继续运行下去。
如果用户有加互斥锁:
那么最开始的时候还是一样都先抢GIL全局解释器锁,抢到的运行到用户的互斥锁地方拿到锁后遇到IO会进行睡眠,此时操作系统会将GIL全局解释器锁释放,别的线程抢到遇到用户的互斥锁没法继续运行下去,因为互斥锁被睡眠的线程拿着,所以他们会被操作系统释放GIL继续抢,一直到睡眠的线程运行结束释放互斥锁后其他抢到GIL全局解释器锁的线程才可以从互斥锁地方运行下去。
(即GIL相当于执行权限,会在任务无法执行的情况,被强行释放
自定义互斥锁即便时无法执行,也不会自动释放)
4、有两种并发解决方案:
多进程:计算密集型
多线程:IO密集型
计算密集型
from multiprocessing import Process from threading import Thread import os,time def work1(): res=0 for i in range(100000): res*=i def work2(): res=0 for i in range(100000): res*=i def work3(): res=0 for i in range(100000): res*=i def work4(): res=0 for i in range(100000): res*=i def work5(): res=0 for i in range(100000): res*=i def work6(): res=0 for i in range(100000): res*=i def work7(): res=0 for i in range(100000): res*=i def work8(): res=0 for i in range(100000): res*=i if __name__ == '__main__': # print(os.cpu_count()) #本机为4核 start=time.time() # p1=Process(target=work1) # p2=Process(target=work2) # p3=Process(target=work2) # p4=Process(target=work2) # p5=Process(target=work2) # p6=Process(target=work2) # p7=Process(target=work2) # p8=Process(target=work2) p1=Thread(target=work1) p2=Thread(target=work2) p3=Thread(target=work2) p4=Thread(target=work2) p5=Thread(target=work2) p6=Thread(target=work2) p7=Thread(target=work2) p8=Thread(target=work2) p1.start() p2.start() p3.start() p4.start() p5.start() p6.start() p7.start() p8.start() p1.join() p2.join() p3.join() p4.join() p5.join() p6.join() p7.join() p8.join() stop=time.time() print("run time is %s" %(stop-start)) 计算密集型 在运算简单情况下线程比进程快,但是程序中的运算都是相对 复杂,所以多进程要比多线程强
IO密集型
from multiprocessing import Process from threading import Thread import os,time def work1(): time.sleep(5) def work2(): time.sleep(5) def work3(): time.sleep(5) def work4(): time.sleep(5) def work5(): time.sleep(5) def work6(): time.sleep(5) def work7(): time.sleep(5) def work8(): time.sleep(5) if __name__ == '__main__': # print(os.cpu_count()) #本机为4核 start=time.time() p1=Process(target=work1) p2=Process(target=work2) p3=Process(target=work2) p4=Process(target=work2) p5=Process(target=work2) p6=Process(target=work2) p7=Process(target=work2) p8=Process(target=work2) # p1=Thread(target=work1) # p2=Thread(target=work2) # p3=Thread(target=work2) # p4=Thread(target=work2) # p5=Thread(target=work2) # p6=Thread(target=work2) # p7=Thread(target=work2) # p8=Thread(target=work2) p1.start() p2.start() p3.start() p4.start() p5.start() p6.start() p7.start() p8.start() p1.join() p2.join() p3.join() p4.join() p5.join() p6.join() p7.join() p8.join() stop=time.time() print("run time is %s" %(stop-start))
定时器
from threading import Timer,current_thread def task(x): print("%s run ...." %x) print(current_thread().name) if __name__ == '__main__': t=Timer(3,task,args=(10,))#第一个是时间秒数,第二个是函数名,第三个是传入值 t.start() print("主")
进程优先级别:
import queue # 队列:先进先出 q=queue.Queue(3) q.put(1) q.put(2) q.put(3) print(q.get()) print(q.get()) print(q.get()) # 堆栈:先进后出 q=queue.LifoQueue() q.put(1) q.put(2) q.put(3) print(q.get()) print(q.get()) print(q.get()) # 优先级队列:优先级高先出来,数字越小,优先级越高 q=queue.PriorityQueue() q.put((3,'data1')) q.put((-10,'data2')) q.put((11,'data3')) print(q.get()) print(q.get()) print(q.get()) 打印顺序: -10 3 11
1、什么时候用池:
池的功能是限制启动的进程数或线程数,
什么时候应该限制
当并发的任务数远远超过了计算机的承受能力时,既无法一次性开启过多的进程数或者线程数时,就应该用池的概念将开启的进程数或者线程数限制在计算机可承受的范围内
2、同步vs异步
同步、异步指的是提交任务的两种方式
同步:提交完任务后就在原地等待,直到任务运行完毕后拿回到任务的返回值,再继续运行下一行代码
异步:提交完任务(绑定一个回调函数)后根本就不在原地等待,直接运行下一行代码,等到任务有返回值后会自动触发回调函数
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor import os import time import random def task(n): print("%s run..." %os.getpid()) time.sleep(10) return n**2 def parse(res): print("...") if __name__ == '__main__': pool=ProcessPoolExecutor(9)#进程池默认是4,代表一次性回复个数, # 超过回复个数,后面谁空谁回复 l=[] for i in range(1,12): future = pool.submit(task,i) l.append(future) pool.shutdown(wait=True)#shutdown关闭进程池入口 for future in l: print(future.result()) print("主") 要运行结束后获得结果,放在父进程中效果不够理想


from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor import os import time import random def task(n): print("%s run..." %os.getpid()) time.sleep(10) return n**2 def parse(future): time.sleep(1) res=future.result() print("%s 处理了 %s" %(os.getpid(),res)) if __name__ == '__main__': pool=ProcessPoolExecutor(9)#进程池默认是4,代表一次性回复个数, # 超过回复个数,后面谁空谁回复 start=time.time() for i in range(1,12): future = pool.submit(task,i) future.add_done_callback(parse)#parse会在futrue有返回值时立刻触发, pool.shutdown(wait=True)#shutdown关闭进程池入口 stop=time.time() print("主",os.getpid(),(stop-start))
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor import os import time import random def task(n): print("%s run..." %os.getpid()) time.sleep(10) return n**2 def parse(future): time.sleep(1) res=future.result() print("%s 处理了 %s" %(os.getpid(),res)) if __name__ == '__main__': pool=ThreadPoolExecutor(9)# 线程池是cpu*5个数,代表一次性回复个数, # 超过回复个数,后面谁空谁回复 start=time.time() for i in range(1,12): future = pool.submit(task,i) future.add_done_callback(parse)#parse会在futrue有返回值时立刻触发, pool.shutdown(wait=True)#shutdown关闭进程池入口 stop=time.time() print("主",os.getpid(),(stop-start))
通过对比在有IO的情况下,线程要比进程快

